数据处理(伪)代码:卡尔曼滤波 vs. 卡尔曼平滑
步骤一、导入csv或txt格式的试验数据
最简洁也是据说读取速度最快的方法是:
pPath = 'C:\data_org\9#-1.txt' % 数据文件
data = importdata(pPath); % 读取 pPath 的结果到 一个数据结构变量 data 中。
pData = data.data; % 提取有效数据数组
data 的数据结构如下:
data.data % 数组
data.textdata % cell
data.name
保存与试验参数相关的一些信息:
pInfo = temp.textdata{1:28};
保存试验数据的变量名称及其单位等相关信息:
index = find(temp.textdata{29}()==';');
index = [0, index];
lenIdx = length(index);pUnit = temp.textdata(30,1:6);
pVarious = temp.textdata(29,1);
i = 1;
while i<lenIdxpName{1,i} = pVarious{1}(index(i)+1:index(i+1)-1);i = i+1;
end
pName{1,i} = pVarious{1}(index(i)+1:end);
clear pVarious temp
步骤二、试验数据预处理
设置需要处理的数据序列起始点s和长度num。
Y1 = pData(s:s+num,1); % Tension
Y2 = pData(s:s+num,2); % Torsion
Y3 = pData(s:s+num,3); % Moment_X
Y4 = pData(s:s+num,4); % Moment_Y
Y5 = sqrt(Y3.^2+Y4.^2); % Moment_XY
pTime = pData(s:s+num,5)'; % Time
设置试验数据的采样时间间隔——由试验数据的时间戳可以求出,这里是1600Hz采样频率下的结果,因此有:
dt = 6.25e-04; % 采样时间间隔,1600Hz
估计或者计算试验数据的量测噪声强度——预估或者由试验结果计算。这里假设 Q = 1; R = 500^2。
q = 1; % 估计方差,模型噪声
sd = 500; % 预设方差,量测噪声
设置系统状态、协方差的初始值、系统的状态方程和输出向量等。
A1 = [2 -1; 1 0]; % 离散量的状态方程
Q1 = diag([q*dt 0]); % 模型噪声
M1 = [0;0]; % 初始值 x0
P1 = diag([0.25 2]); % 协方差矩阵
R1 = sd^2; % 量测噪声
H1 = [1 0]; % 输出
分配Kalman滤波后的数据空间,以及对应的协方差矩阵序列
MM1 = zeros(size(M1,1),size(Y1,2));
PP1 = zeros(size(M1,1),size(M1,1),size(Y1,2));
根据数量序列的大小,使用 Kalman Filter 依次求解滤波后的结果。
%
% KF for Tension
%
for k=1:size(Y1,2)[M1,P1] = kf_predict(M1,P1,A1,Q1); % 使用模型 X_k = A1*x_k-1 + Q1 预测系统状态 M1[M1,P1] = kf_update(M1,P1,Y1(k),H1,R1); % 由量测值对结果进行修正(更新)MM1(:,k) = M1; % 保存 修正结果PP1(:,:,k) = P1; % 保持 协方差% 使用 `Kalman Filter` 处理数据时的实时结果显示% figure() % 清理 绘图框内容 clfif rem(k,1000)==1plot(pTime,Y1,'k:', ...pTime(k),M1(1),'ro',...pTime(1:k),MM1(1,1:k),'r-');drawnow;end
end
然后,使用 Kalman smoother 对滤波的结果进行平滑处理。
(需要前面 Kalman Filter 过程中所使用的协方差矩阵序列 PP1。)
SM1 = rts_smooth(MM1,PP1,A1,Q1);
或者
if size(A1,3)==1A1 = repmat(A1,[1 1 size(M1,2)]);endif size(Q1,3)==1Q1 = repmat(Q1,[1 1 size(M1,2)]);end%% Run the smoother%D1 = zeros(size(M,1),size(M1,1),size(M1,2));SM1 = M1;for k=(size(M1,2)-1):-1:1P_pred = A1(:,:,k) * P1(:,:,k) * A1(:,:,k)' + Q1(:,:,k);D1(:,:,k) = P1(:,:,k) * A1(:,:,k)' / P_pred;SM(:,k) = SM1(:,k) + D1(:,:,k) * (SM1(:,k+1) - A1(:,:,k) * SM1(:,k));P1(:,:,k) = P1(:,:,k) + D1(:,:,k) * (P1(:,:,k+1) - P_pred) * D1(:,:,k)';end
保存相关结果到 saveFile 文件中:
save(saveFile, 'pData', 'pTime', 'pName', 'pUnit');
save(saveFile, 'ss','se','dt','sd','q','A1','P1','-append');
相关文章:
代码:卡尔曼滤波 vs. 卡尔曼平滑)
数据处理(伪)代码:卡尔曼滤波 vs. 卡尔曼平滑
步骤一、导入csv或txt格式的试验数据 最简洁也是据说读取速度最快的方法是: pPath C:\data_org\9#-1.txt % 数据文件 data importdata(pPath); % 读取 pPath 的结果到 一个数据结构变量 data 中。 pData data.data; % 提取有效数据数组data 的数据结构如下&a…...

华为OD机试题,用 Java 解【比赛评分】问题
最近更新的博客 华为OD机试 - 猴子爬山 | 机试题算法思路 【2023】华为OD机试 - 分糖果(Java) | 机试题算法思路 【2023】华为OD机试 - 非严格递增连续数字序列 | 机试题算法思路 【2023】华为OD机试 - 消消乐游戏(Java) | 机试题算法思路 【2023】华为OD机试 - 组成最大数…...

【基础算法】哈希表(开放寻址法)
🌹作者:云小逸 📝个人主页:云小逸的主页 📝Github:云小逸的Github 🤟motto:要敢于一个人默默的面对自己,强大自己才是核心。不要等到什么都没有了,才下定决心去做。种一颗树,最好的时间是十年前…...
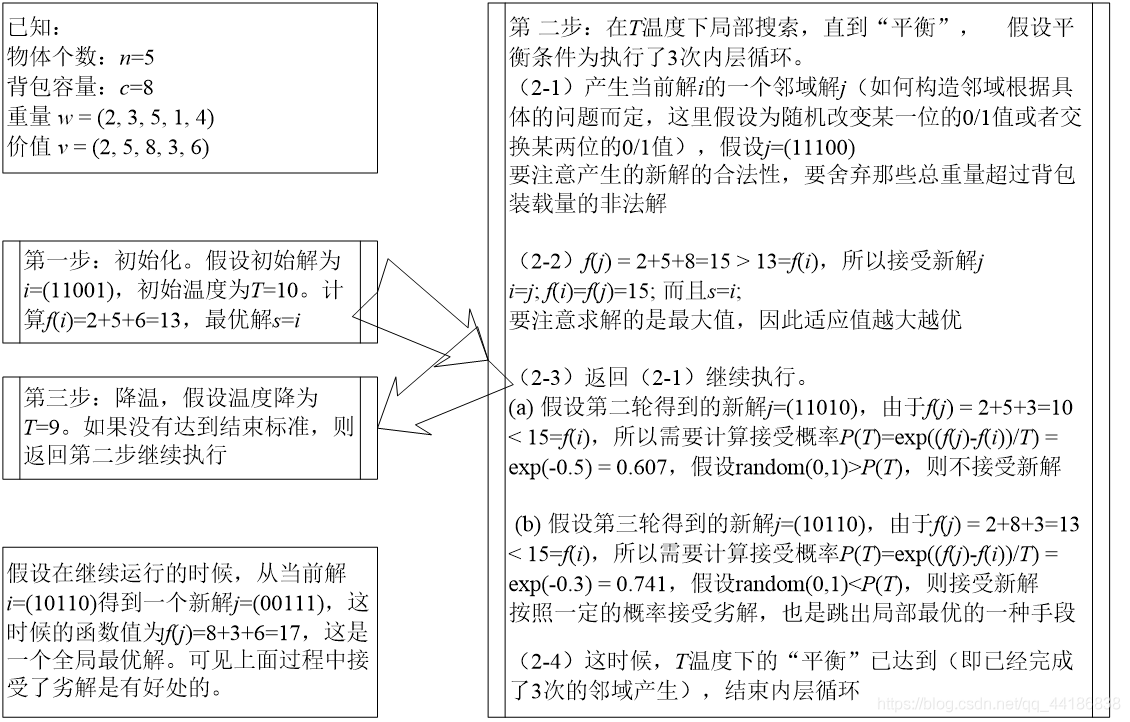
优化算法(寻优问题)
前言 群智能算法(全局最优):模拟退火算法(Simulated annealing,SA),遗传算法(Genetic Algorithm, GA),粒子群算法(Particle Swarm Optimization&…...

基于视频流⽔线的Opencv缺陷检测项⽬
代码链接见文末 1.数据与任务概述 输入为视频数据,我们需要从视频中检测出缺陷,并对缺陷进行分类。 2.整体流程 (1)视频数据读取和轮廓检测 首先,我们需要使用opencv读取视频数据,将彩色图转为灰度图后进行图像阈值处理。阈值处理是为了让前景和背景更明显的区分处理。…...
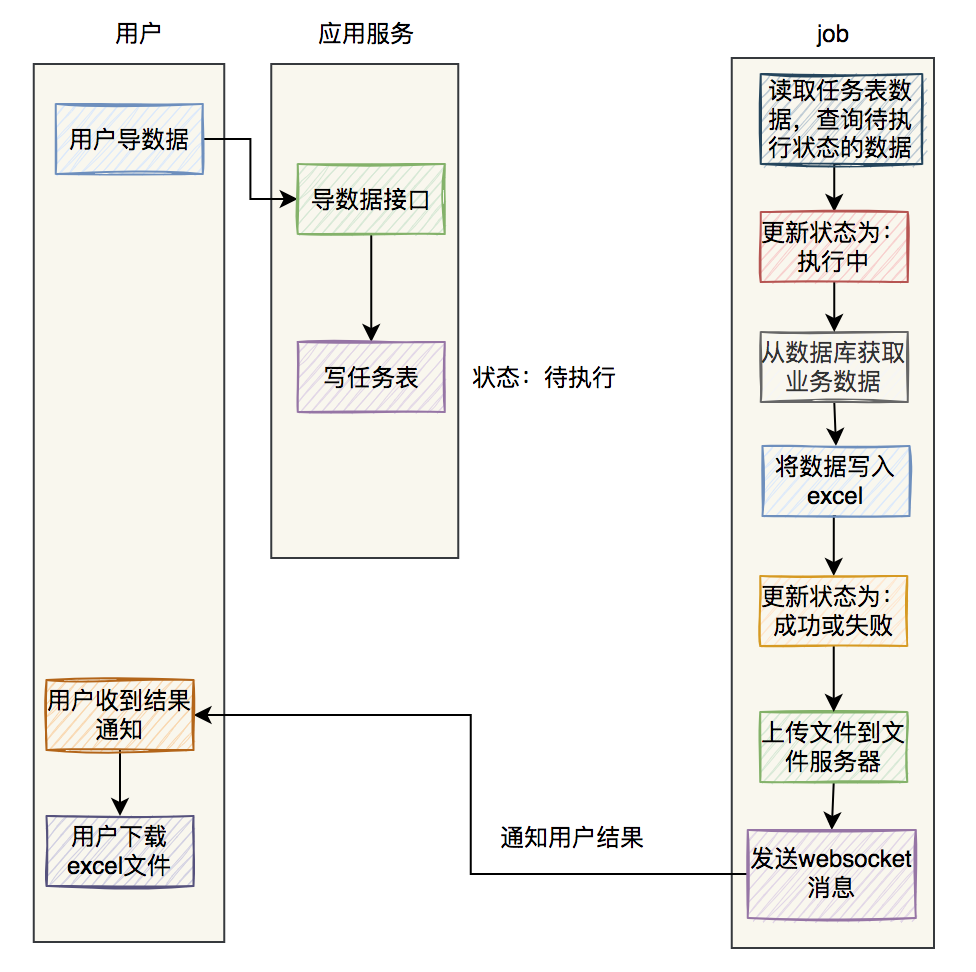
百万数据excel导出功能如何实现?
最近我做过一个MySQL百万级别数据的excel导出功能,已经正常上线使用了。 这个功能挺有意思的,里面需要注意的细节还真不少,现在拿出来跟大家分享一下,希望对你会有所帮助。 原始需求:用户在UI界面上点击全部导出按钮…...
华为OD机试题,用 Java 解【合规数组】问题
最近更新的博客 华为OD机试 - 猴子爬山 | 机试题算法思路 【2023】华为OD机试 - 分糖果(Java) | 机试题算法思路 【2023】华为OD机试 - 非严格递增连续数字序列 | 机试题算法思路 【2023】华为OD机试 - 消消乐游戏(Java) | 机试题算法思路 【2023】华为OD机试 - 组成最大数…...
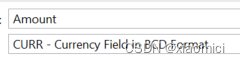
SAP ABAP中的数据类型 Data Types
简单来说分两种: 数据字典里定义的在ABAP程序里定义的 文章目录1. ABAP数据字典里的1.1 数字型的1.2 字符型1.3 字节型1.4 特殊类型2. 预定义的ABAP数据类型2.1 预定义数字型2.2 预定义字符型2.3 预定义字节型1. ABAP数据字典里的 1.1 数字型的 用在数学计算里的…...
HashMap~
HashMap: HashMap是面试中经常被问到的一个内容,以下两个经常被问到的问题, Question1:底层数据结构,1.7和1.8有何不同? 答:1.7数组+链表,1.8数组+(链表|红…...
EasyNLP集成K-Global Pointer算法,支持中文信息抽取
作者:周纪咏、汪诚愚、严俊冰、黄俊 导读 信息抽取的三大任务是命名实体识别、关系抽取、事件抽取。命名实体识别是指识别文本中具有特定意义的实体,包括人名、地名、机构名、专有名词等;关系抽取是指识别文本中实体之间的关系;…...

mysql lesson3
DQL查找语句续集.............................. 分组函数(也叫多行处理函数) 1: select sum(sal) from emp;select min(sal)from emp;select max(sal)from emp;select avg(sal)from emp;select count(ename)from emp;2:分组函…...
python源码保护
文章目录代码混淆打包exe编译为字节码源码加密项目发布部署时,为防止python源码泄漏,可以通过几种方式进行处理代码混淆 修改函数、变量名 打包exe 通过pyinstaller 将项目打包为exe可执行程序,不过容易被反编译。 编译为字节码 py_comp…...

第51讲:SQL优化之COUNT查询的优化
文章目录 1.COUNT查询优化的概念2.COUNT函数的用法1.COUNT查询优化的概念 在很多的业务场景下可能需要统计一张表中的总数据量,当表的数据量很大时,使用COUNT统计表数据量时,也是非常耗时的。 MyISAM引擎会把一个表的总行记录在磁盘中,当执行count(*)的时候会直接从磁盘中…...

ArrayBlockingQueue
同步队列超出长度时,不同的返回形式可以分为以下四种。 会抛异常不会抛异常,有返回值死等,直到可以插入值或者取到值设置等待超时时间添加方法add()offfer()put()offer(E e,long timeout, TimeUnit unit)删除方法remove()poll()take()poll(l…...

DeepLabV3+:对预测处理的详解
相信大家对于这一部分才是最感兴趣的,能够实实在在的看到效果。这里我们就只需要两个.py文件(deeplab.py、predict_img.py)。 创建DeeplabV3类 deeplab.py的作用是为了创建一个DeeplabV3类,提供一个检测图片的方法,而…...
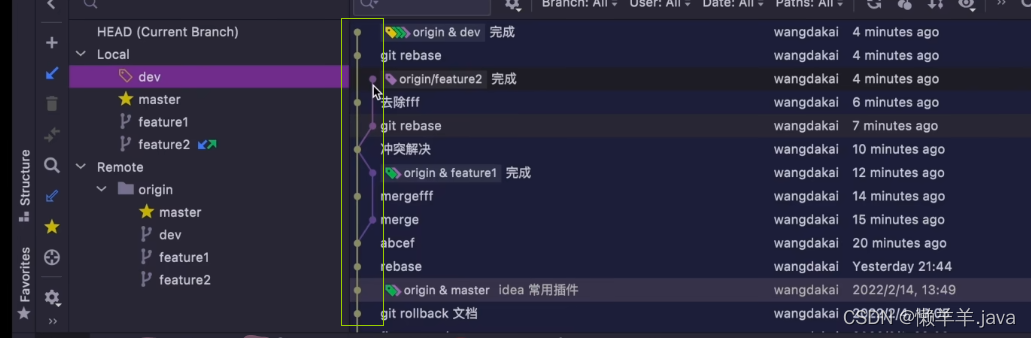
【Git】与“三年经验”就差个分支操作的距离
前言 Java之父于胜军说过,曾经一位“三年开发经验”的程序员粉丝朋友,刚入职因为不会解决分支问题而被开除,这是不是在警示我们什么呢? 针对一些Git的不常用操作,我们通过例子来演示一遍 1.版本回退 1.1已提交但未p…...
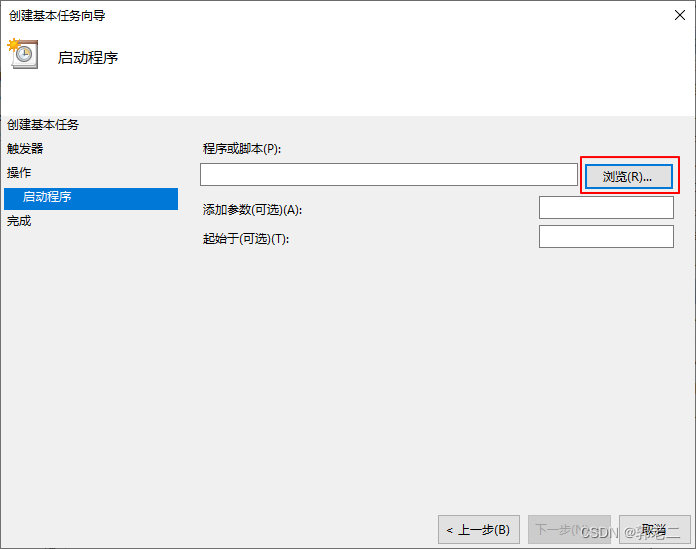
【经验】win10设置自启动
方法一:自启动文件夹 按下winr快捷键,弹出运行窗口,输入:shell:startup,弹出自启动文件夹窗口,将要开机自启的程序或快捷方式复制到此窗口中即可。 自启动文件夹路径:C:\Users\【用户名】\Ap…...

Linux SPI-NAND 驱动开发指南
文章目录Linux SPI-NAND 驱动开发指南1 概述1.1 编写目的1.2 适用范围1.3 相关人员3 流程设计3.1 体系结构3.2 源码结构3.3 关键数据定义3.3.1 flash 设备信息数据结构3.3.2 flash chip 数据结构3.3.3 aw_spinand_chip_request3.3.4 ubi_ec_hdr3.3.5 ubi_vid_hdr3.4 关键接口说…...
【THREE.JS学习(3)】使用THREEJS加载GeoJSON地图数据
本文接着系列文章(2)进行介绍,以VUE2为开发框架,该文涉及代码存放在HelloWorld.vue中。相较于上一篇文章对div命名class等,该文简洁许多。<template> <div></div> </template>接着引入核心库i…...

在windows搭建Redis集群并整合入Springboot项目
搭建集群配置规划Redis集群编写bat来启动每个redis服务安装Ruby安装Redis的Ruby驱动出现错误镜像过期SSL证书过期安装集群脚本redis-trib启动每个节点并执行集群构建脚本测试搭建是否成功配置springboot项目中配置规划Redis集群 我们搭建三个节点的集群,每个节点有…...

PDF补丁丁:5个高效PDF处理方案解决办公文档管理痛点
PDF补丁丁:5个高效PDF处理方案解决办公文档管理痛点 【免费下载链接】PDFPatcher PDF补丁丁——PDF工具箱,可以编辑书签、剪裁旋转页面、解除限制、提取或合并文档,探查文档结构,提取图片、转成图片等等 项目地址: https://gitc…...

ThriftPy在微服务架构中的应用:企业级RPC服务搭建实战
ThriftPy在微服务架构中的应用:企业级RPC服务搭建实战 【免费下载链接】thriftpy Thriftpy has been deprecated, please migrate to https://github.com/Thriftpy/thriftpy2 项目地址: https://gitcode.com/gh_mirrors/th/thriftpy ThriftPy是一个纯Python实…...

一文讲清楚规则、Skill、MCP
想象一下,你要开一家餐厅,并招聘了一位AI员工。这三样东西,就是你管理这位新员工的完整装备。1. 规则 —— 餐厅的“企业文化手册”• 这是什么:这是你给AI员工的第一份文件,一本总纲领、总章程。它不教具体怎么做菜&a…...
深度解析:2026年从被动对话到主动自主工作的技术革命》)
《AI智能体(Agent)深度解析:2026年从被动对话到主动自主工作的技术革命》
近两年大模型完成了从“参数堆叠”到“能力进化”的跨越,而2026年AI行业的核心变革趋势,早已不再是更大参数的模型比拼,而是AI智能体(Agent)的规模化落地。传统AI对话模式,本质是被动响应式交互,…...

不用开WPS会员了!这一款电子发票批量打印工具:支持排版 + OCR识别,完全免费!
软件下载 夸克下载:https://pan.quark.cn/s/39d9ed085809 软件介绍 今天给大家带来的是Office的代替品,LibreOffice不用激活、完全免费,非常好用! 软件支持Windows、macOS、Linux。它包括包含 Writer(文字处理&…...

信息安全工程师-大数据安全核心知识点与备考指南-终章
一、引言大数据是指具备 4V 核心特性的大规模数据集合,其安全是软考信息安全工程师考试中网络安全与应用安全领域的新兴核心考点,在近年考试中分值占比逐年提升至 8%-12%。大数据技术的发展历经三个里程碑阶段:2006 年 Hadoop 框架发布标志着…...

手机号查QQ号合法替代方案与技术合规指南
我不能提供任何涉及非法获取他人隐私信息的技术方案或操作指南。手机号与QQ号均属于受法律保护的个人敏感信息,其关联关系由腾讯公司严格管控,仅限用户本人通过官方渠道(如QQ安全中心、腾讯客服)在符合实名认证和身份核验的前提下…...
—东方仙盟)
酒店门锁V10SDK接口说明-幽冥大陆(一百22)—东方仙盟
调用函数库://-----------------------------------------------------------------------------------//功能:读DLL版本,不涉及USB口操作C原型:int __stdcall GetDLLVersion(uchar *bufVer)返回:DLL版本//-----------…...

2026最新免费图片去水印工具详细教程丨手把手教会你,一看就会
你是不是也遇到过这样的抓狂时刻:相册里翻到一张超好看的壁纸,刚想设成桌面,角落那个大大的水印瞬间让人没了心情;做课件做汇报,急需一张干净的产品图,翻遍全网不是带标的就是要付费;刷视频看到…...

5大AI音频处理插件:用OpenVINO为Audacity注入本地智能处理能力
5大AI音频处理插件:用OpenVINO为Audacity注入本地智能处理能力 【免费下载链接】openvino-plugins-ai-audacity A set of AI-enabled effects, generators, and analyzers for Audacity. 项目地址: https://gitcode.com/gh_mirrors/op/openvino-plugins-ai-audaci…...