机器学习必修课 - 使用管道 Pipeline
目标:学习使用管道(pipeline)来提高机器学习代码的效率。
1. 运行环境:Google Colab
import pandas as pd
from sklearn.model_selection import train_test_split
!git clone https://github.com/JeffereyWu/Housing-prices-data.git
- 下载数据集
2. 加载房屋价格数据集,进行数据预处理,并将数据划分为训练集和验证集
# Read the data
X_full = pd.read_csv('/content/Housing-prices-data/train.csv', index_col='Id')
X_test_full = pd.read_csv('/content/Housing-prices-data/test.csv', index_col='Id')# Remove rows with missing target, separate target from predictors
X_full.dropna(axis=0, subset=['SalePrice'], inplace=True)
y = X_full.SalePrice
X_full.drop(['SalePrice'], axis=1, inplace=True)# Break off validation set from training data
X_train_full, X_valid_full, y_train, y_valid = train_test_split(X_full, y, train_size=0.8, test_size=0.2,random_state=0)
- 使用Pandas的
read_csv函数从指定路径读取训练集和测试集的CSV文件。index_col='Id'表示将数据集中的’Id’列作为索引列。 - 从
X_full数据中删除了带有缺失目标值的行,这是因为目标值(‘SalePrice’)是我们要预测的值,所以必须确保每个样本都有一个目标值。然后,将目标值从X_full数据中分离出来,存储在变量y中,并从X_full中删除了目标值列,以便将其视为预测特征。
3. 选择具有相对低基数(唯一值数量较少)的分类(categorical)列
# "Cardinality" means the number of unique values in a column
# Select categorical columns with relatively low cardinality (convenient but arbitrary)
categorical_cols = [cname for cname in X_train_full.columns ifX_train_full[cname].nunique() < 10 and X_train_full[cname].dtype == "object"]
- 识别具有相对较少不同类别的分类列,因为这些列更适合进行独热编码,而不会引入太多的新特征。
4. 选择数值型(numerical)列
# Select numerical columns
numerical_cols = [cname for cname in X_train_full.columns if X_train_full[cname].dtype in ['int64', 'float64']]
- 识别数据集中包含数值数据的列,因为这些列通常用于构建数值特征,并且需要用于训练和评估数值型机器学习模型。
5. 将数据集中的列限制在所选的分类(categorical)列和数值(numerical)列上
# Keep selected columns only
my_cols = categorical_cols + numerical_cols
X_train = X_train_full[my_cols].copy()
X_valid = X_valid_full[my_cols].copy()
X_test = X_test_full[my_cols].copy()
- 创建了一个名为my_cols的列表,其中包含了要保留的列名
- 使用
X_train_full[my_cols].copy()和X_valid_full[my_cols].copy()从原始训练数据集(X_train_full和X_valid_full)中创建了新的数据集(X_train和X_valid)。这两个数据集只包含了my_cols中列名所对应的列,其他列被丢弃了。最后,同样的操作也被应用到测试数据集上,创建了包含相同列的测试数据集X_test。
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
6. 准备数值型数据和分类型数据以供机器学习模型使用
# Preprocessing for numerical data
numerical_transformer = SimpleImputer(strategy='constant')# Preprocessing for categorical data
categorical_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')),('onehot', OneHotEncoder(handle_unknown='ignore'))
])# Bundle preprocessing for numerical and categorical data
preprocessor = ColumnTransformer(transformers=[('num', numerical_transformer, numerical_cols),('cat', categorical_transformer, categorical_cols)])
- 创建了一个名为
numerical_transformer的预处理器,用于处理数值型数据。在这里,使用了SimpleImputer,并设置了策略为’constant’,表示将缺失的数值数据填充为一个常数值。 - 使用
SimpleImputer来填充缺失值,策略为’most_frequent’,表示使用出现频率最高的值来填充缺失的分类数据。 - 使用
OneHotEncoder来执行独热编码,将分类数据转换成二进制的形式,并且设置了handle_unknown='ignore',以处理在转换过程中遇到未知的分类值。 - 使用
ColumnTransformer来组合数值型和分类型数据的预处理器,将它们一起构建成一个整体的预处理过程。
7. 建立、训练和评估一个随机森林回归模型
# Define model
model = RandomForestRegressor(n_estimators=100, random_state=0)# Bundle preprocessing and modeling code in a pipeline
clf = Pipeline(steps=[('preprocessor', preprocessor),('model', model)])# Preprocessing of training data, fit model
clf.fit(X_train, y_train)# Preprocessing of validation data, get predictions
preds = clf.predict(X_valid)print('MAE:', mean_absolute_error(y_valid, preds))
- 创建了一个名为
model的机器学习模型。在这里,使用了随机森林回归模型,它是一个基于决策树的集成学习模型,包含了100颗决策树,并设置了随机种子random_state为0,以确保结果的可重复性。 - 创建了一个名为clf的机器学习管道(
Pipeline)。管道将数据预处理步骤(preprocessor)和模型训练步骤(model)捆绑在一起,确保数据首先被预处理,然后再用于模型训练。 - MAE是一种衡量模型预测误差的指标,其值越小表示模型的性能越好。
MAE: 17861.780102739725
8. 重新进行数据预处理和定义一个机器学习模型
# Preprocessing for numerical data
numerical_transformer = SimpleImputer(strategy='constant')# Preprocessing for categorical data
categorical_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='constant')),('onehot', OneHotEncoder(handle_unknown='ignore'))
])# Bundle preprocessing for numerical and categorical data
preprocessor = ColumnTransformer(transformers=[('num', numerical_transformer, numerical_cols),('cat', categorical_transformer, categorical_cols)])# Define model
model = RandomForestRegressor(n_estimators=100, random_state=0)
- 使用
SimpleImputer来填充分类型数据中的缺失值,策略改为’constant’,改用常数值填充。
# Bundle preprocessing and modeling code in a pipeline
my_pipeline = Pipeline(steps=[('preprocessor', preprocessor),('model', model)])# Preprocessing of training data, fit model
my_pipeline.fit(X_train, y_train)# Preprocessing of validation data, get predictions
preds = my_pipeline.predict(X_valid)# Evaluate the model
score = mean_absolute_error(y_valid, preds)
print('MAE:', score)
MAE: 17621.3197260274
9. 再一次进行数据预处理和定义一个机器学习模型
# 自定义数值型数据的预处理步骤
numerical_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='mean')), # 可以使用均值填充缺失值
])# 自定义分类型数据的预处理步骤
categorical_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')), # 使用最频繁的值填充缺失值('onehot', OneHotEncoder(handle_unknown='ignore')) # 执行独热编码
])# 定义自己的模型
model = RandomForestRegressor(n_estimators=200, random_state=42) # 增加决策树数量,设置随机种子# 将自定义的预处理和模型捆绑在一起
clf = Pipeline(steps=[('preprocessor', preprocessor),('model', model)])# 预处理训练数据,训练模型
clf.fit(X_train, y_train)# 预处理验证数据,获取预测结果
preds = clf.predict(X_valid)print('MAE:', mean_absolute_error(y_valid, preds))
MAE: 17468.0611130137
# Preprocessing of test data, fit model
preds_test = clf.predict(X_test)
# Save test predictions to file
output = pd.DataFrame({'Id': X_test.index,'SalePrice': preds_test})
output.to_csv('submission.csv', index=False)
相关文章:

机器学习必修课 - 使用管道 Pipeline
目标:学习使用管道(pipeline)来提高机器学习代码的效率。 1. 运行环境:Google Colab import pandas as pd from sklearn.model_selection import train_test_split!git clone https://github.com/JeffereyWu/Housing-prices-dat…...

WEB各类常用测试工具
一、单元测试/测试运行器 1、Jest 知名的 Java 单元测试工具,由 Facebook 开源,开箱即用。它在最基础层面被设计用于快速、简单地编写地道的 Java 测试,能自动模拟 require() 返回的 CommonJS 模块,并提供了包括内置的测试环境 …...

Naive UI 文档地址
最近几天官网访问不了,自己用github pages 部署了个 官网 github pages...

在CentOS7系统中安装MySQL5.7
第一步:下载MySQL包 > wget http://repo.mysql.com/mysql57-community-release-el7-10.noarch.rpm第二步:安装MySQL源 > rpm -Uvh mysql57-community-release-el7-10.noarch.rpm第三步:安装MySQL服务端 > yum install -y mysql-c…...
R语言通过接口获取网上数据平台的免费数据
大家好,我是带我去滑雪! 作为一名统计学专业的学生,时常和数据打交道,我深知数据的重要性。数据是实证研究的重要基础,每当在完成一篇科研论文中的实证研究部分时,我都能深刻体会实证研究最复杂、最耗时的工…...
【Docker内容大集合】Docker从认识到实践再到底层原理大汇总
前言 那么这里博主先安利一些干货满满的专栏了! 首先是博主的高质量博客的汇总,这个专栏里面的博客,都是博主最最用心写的一部分,干货满满,希望对大家有帮助。 高质量博客汇总https://blog.csdn.net/yu_cblog/categ…...
算法题:摆动序列
这道题是一道贪心算法题,如果前两个数是递增,则后面要递减,如果不符合则往后遍历,直到找到符合的。(完整题目附在了最后) 代码如下: class Solution(object):def wiggleMaxLength(self, nums):…...
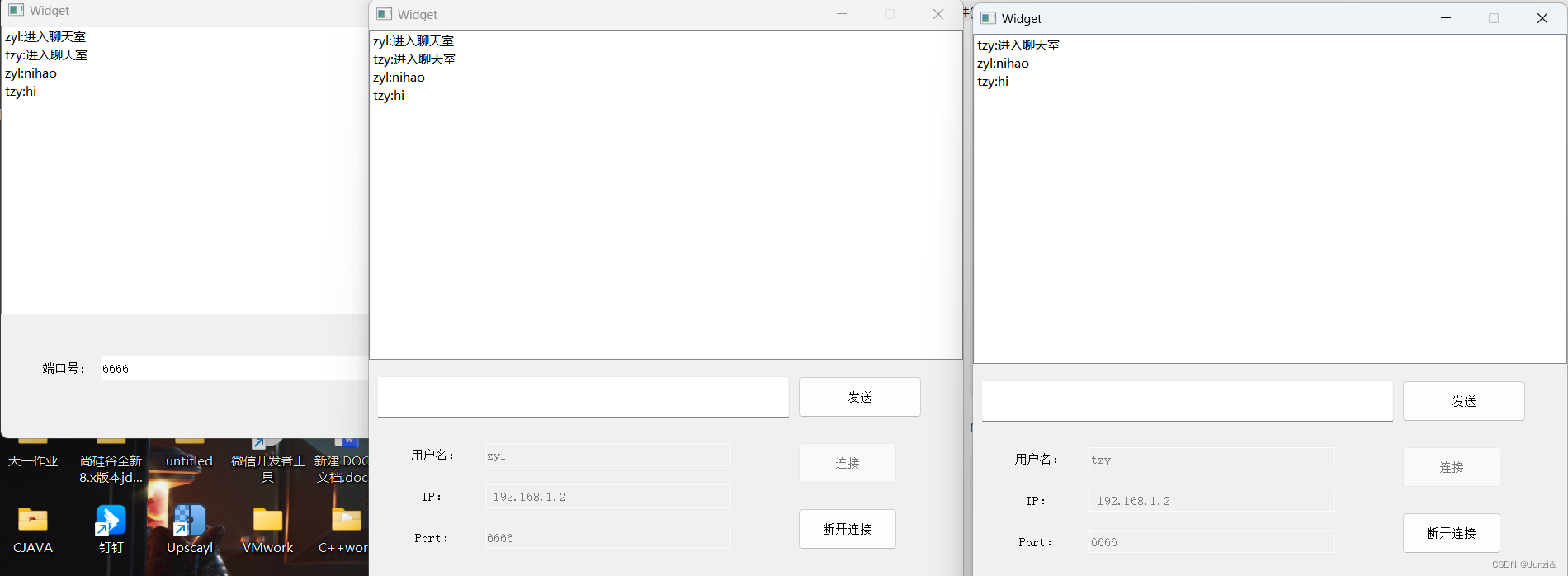
复习 --- QT服务器客户端
服务器: 头文件: #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include<QTcpServer> #include<QTcpSocket> #include<QMessageBox> #include<QDebug> #include<QList> #include<QListWidget> #in…...

Godot 官方2D游戏笔记(1):导入动画资源和添加节点
前言 Godot 官方给了我们2D游戏和3D游戏的案例,不过如果是独立开发者只用考虑2D游戏就可以了,因为2D游戏纯粹,我们只需要关注游戏的玩法即可。2D游戏的美术素材简单,交互逻辑简单,我们可以把更多的时间放在游戏的玩法…...

leetcode 热题 100
数组和字符串匹配 子串和子序列 原串:“abcabc” 子串:“abc”, 连续但不大于原串的字符串 子序列:“acc”, 字符来自原串且保持在原串中顺序不变的字符串 子排列: “aabbcc”, 字符来自原串且只能用1次,但可有不同排列顺序的字…...

Ae 效果:CC Lens
扭曲/CC Lens Distort/CC Lens CC Lens (CC 镜头)主要用于添加或移除摄像机镜头扭曲,比如桶形失真 Barrel、枕形失真 Pincushion以及鱼眼失真 Fisheye等。或者,用它来创建一些特殊的动画效果。 ◆ ◆ ◆ 效果属性说明 Center 中…...
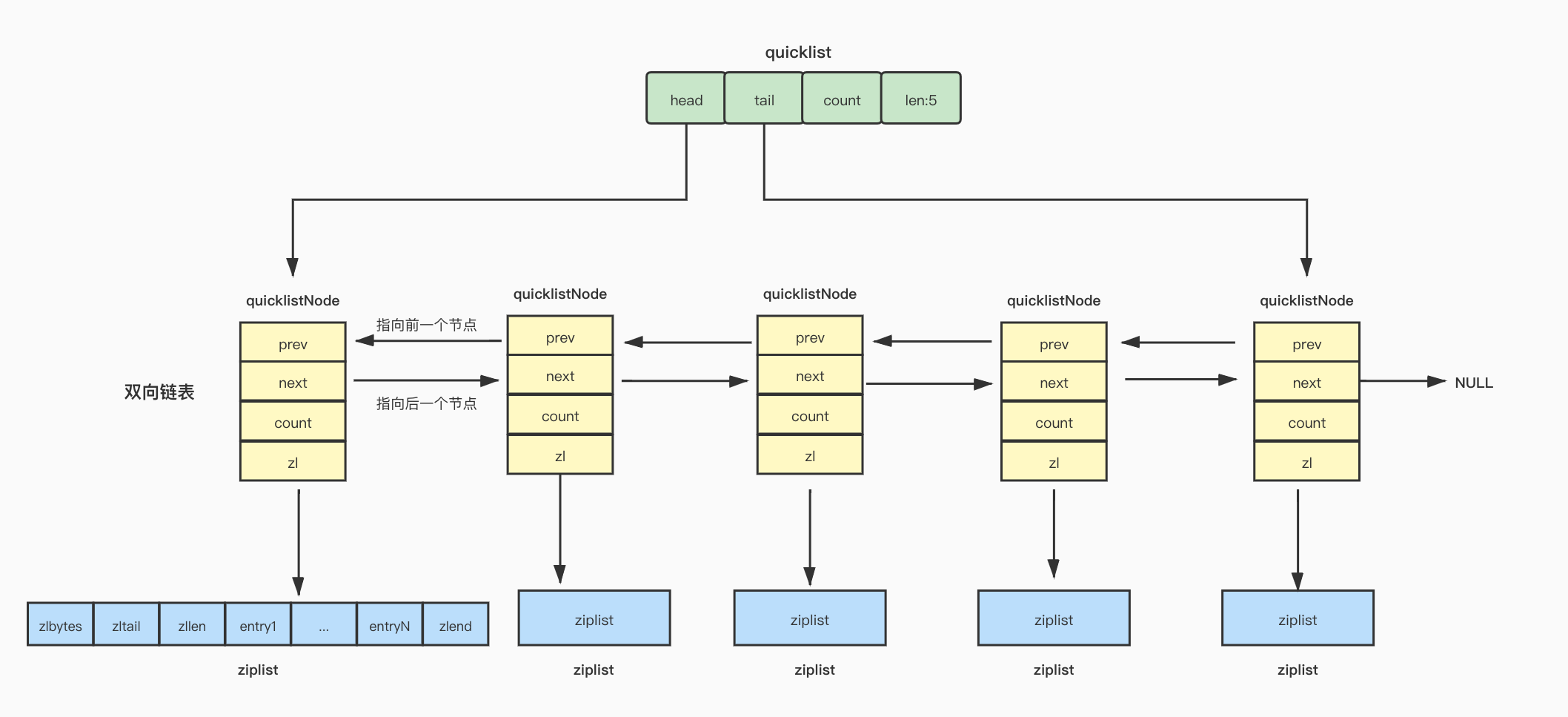
【Redis】基础数据结构-quicklist
Redis List 在Redis3.2版之前,Redis使用压缩列表和双向链表作为List的底层实现。当元素个数比较少并且元素长度比较小时,Redis使用压缩列表实现,否则Redis使用双向链表实现。 ziplist存在问题 不能保存过多的元素,否则查找复杂度…...

QT 实现服务器客户端搭建
1. 服务器头文件 #ifndef SER_H #define SER_H#include <QWidget> #include<QTcpServer> //服务器头文件 #include<QTcpSocket> //客户端头文件 #include<QMessageBox> //消息对话框 #include<QList> //链表头文件QT_BEGIN_NAM…...
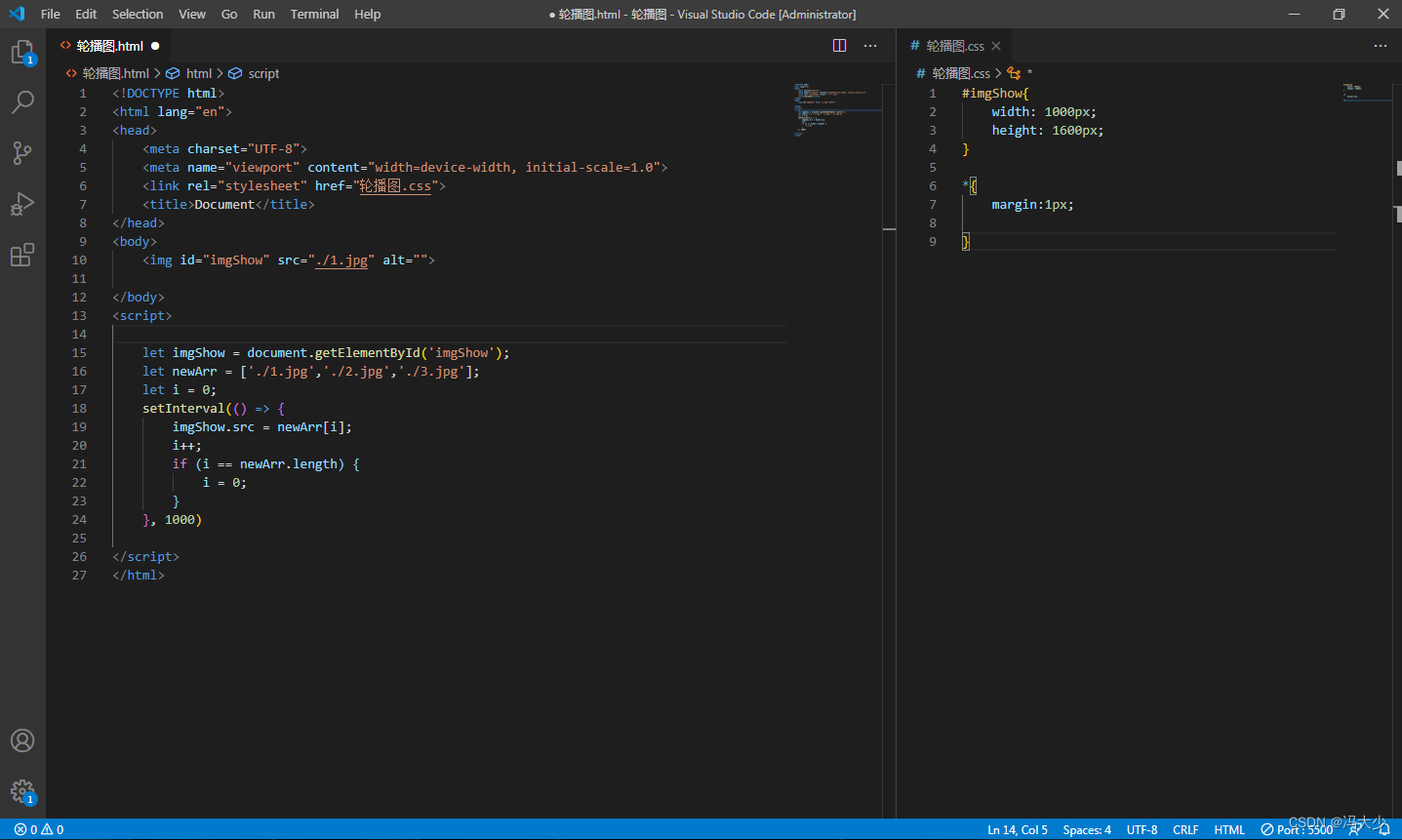
Javascript - 轮播图
轮播图也称banner图、广告图、焦点图、滑片。是指在一个模块或者窗口,通过鼠标点击或手指滑动后,可以看到多张图片。这些图片统称为轮播图,这个模块叫做轮播模块。可以通过运用 javascript去实现定时自动转换图片。以下通过一个小Demo演示如何运用Javascript实现。 <!DOCTYP…...

MATLAB中syms函数使用
目录 语法 说明 示例 创建符号标量变量 创建符号标量变量的向量 创建符号标量变量矩阵 管理符号标量变量的假设 创建和评估符号函数 syms函数的作用是创建符号标量和函数,以及矩阵变量和函数。 语法 syms var1 ... varN syms var1 ... varN [n1 ... nM] …...
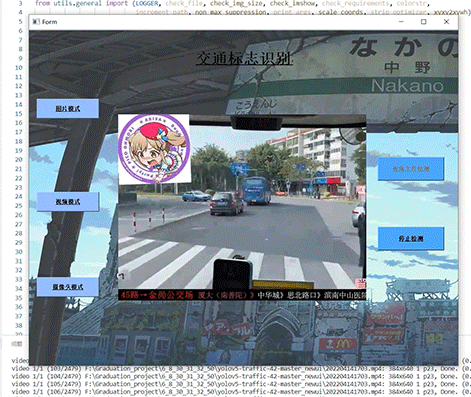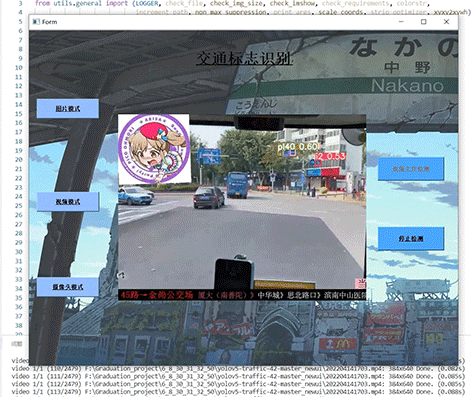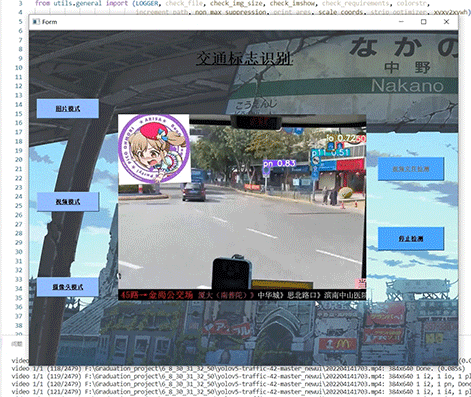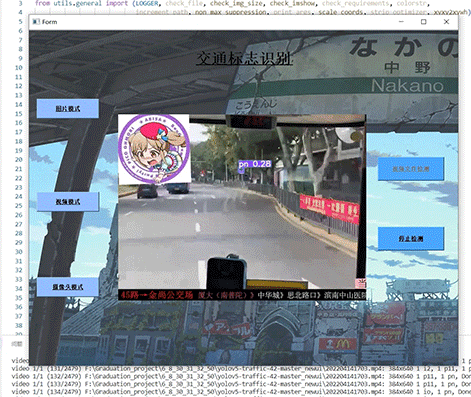
竞赛选题 深度学习 opencv python 实现中国交通标志识别_1
文章目录 0 前言1 yolov5实现中国交通标志检测2.算法原理2.1 算法简介2.2网络架构2.3 关键代码 3 数据集处理3.1 VOC格式介绍3.2 将中国交通标志检测数据集CCTSDB数据转换成VOC数据格式3.3 手动标注数据集 4 模型训练5 实现效果5.1 视频效果 6 最后 0 前言 🔥 优质…...
Qt 关于mouseTracking鼠标追踪和tabletTracking平板追踪的几点官方说明
mouseTracking属性用于保存是否启用鼠标跟踪,缺省情况是不启用的。 没启用的情况下,对应部件只接收在鼠标移动同时至少一个鼠标按键按下时的鼠标移动事件。 启用鼠标跟踪的情况下,任何鼠标移动事件部件都会接收。 部件方法hasMouseTrackin…...
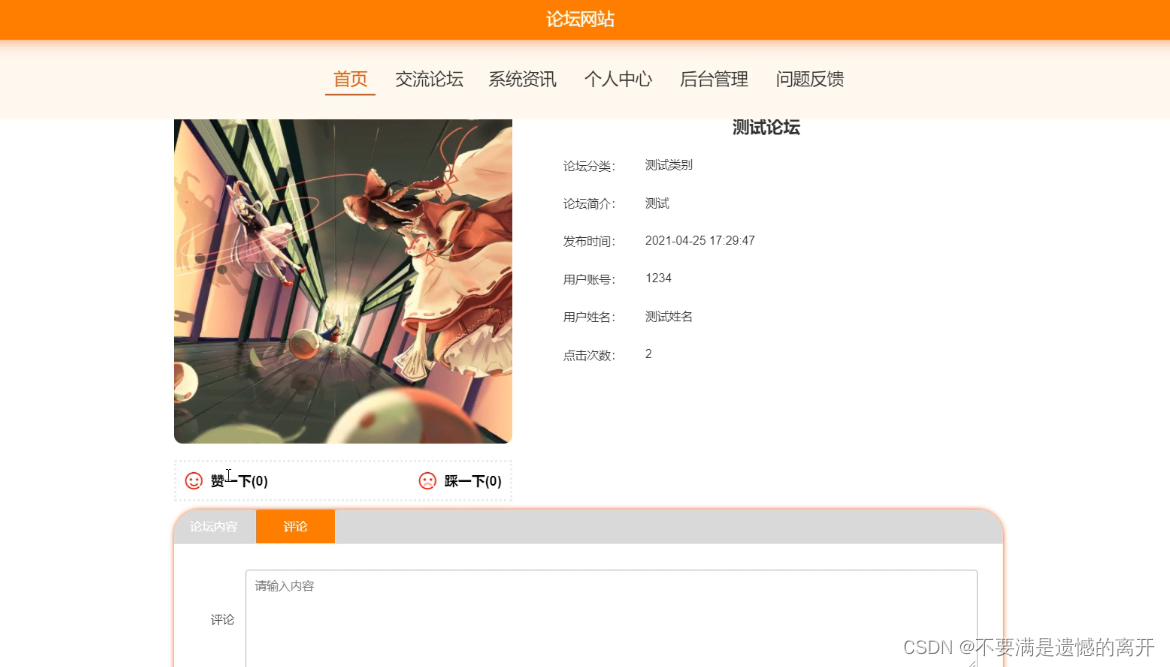
基于springboot的论坛网站
目录 前言 一、技术栈 二、系统功能介绍 用户信息管理 普通管理员管理 交流论坛 交流论坛评论 三、核心代码 1、登录模块 2、文件上传模块 3、代码封装 前言 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了…...
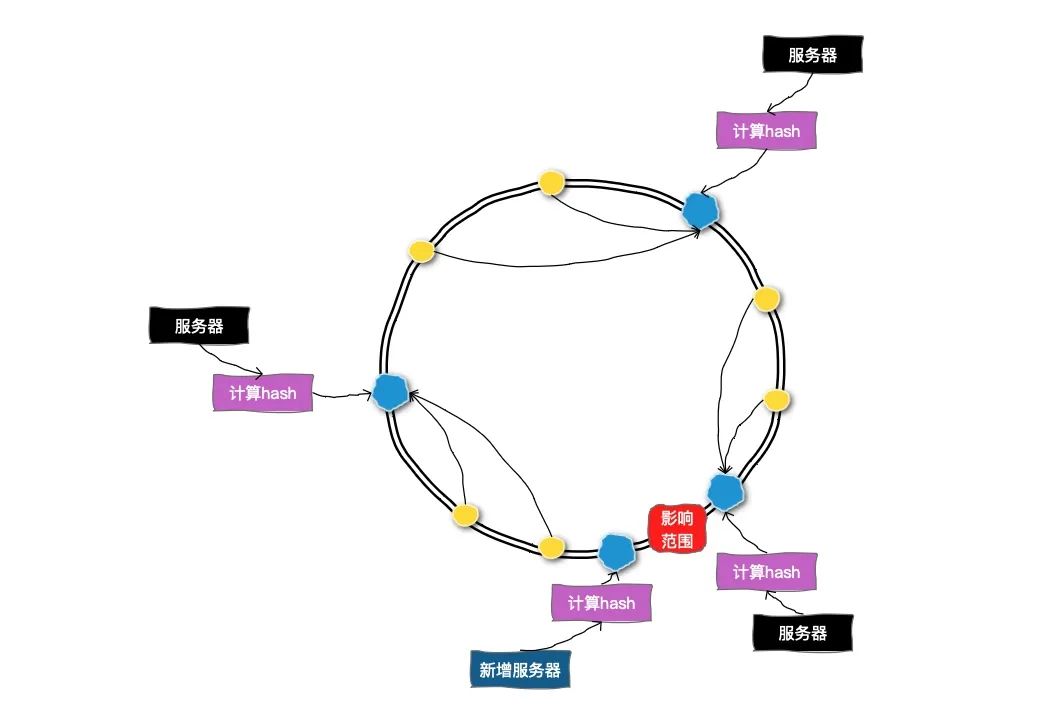
分库分表理论总结
一、概述 分库分表是在面对高并发、海量数量时常见的数据库层面的解决方案。通过把数据分散到不同的数据库中,使得单一数据库的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。比如:将电商数据库拆分为若干独立的数据…...

RK3568平台开发系列讲解(外设篇)AP3216C 三合一环境传感器驱动
🚀返回专栏总目录 文章目录 一、AP3216C 简介二、AP3216C驱动程序2.1、设备树修改2.2、驱动程序沉淀、分享、成长,让自己和他人都能有所收获!😄 📢在本篇将介绍AP3216C 三合一环境传感器的驱动。 一、AP3216C 简介 AP3216C 是由敦南科技推出的一款传感器,其支持环境光…...

3分钟极速指南:网易云音乐无损FLAC批量下载神器
3分钟极速指南:网易云音乐无损FLAC批量下载神器 【免费下载链接】NeteaseCloudMusicFlac 根据网易云音乐的歌单, 下载flac无损音乐到本地.。 项目地址: https://gitcode.com/gh_mirrors/nete/NeteaseCloudMusicFlac 还在为寻找高品质音乐资源而烦恼吗&#x…...

Navicat Mac版无限重置试用期的终极指南:3种简单方法破解14天限制
Navicat Mac版无限重置试用期的终极指南:3种简单方法破解14天限制 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac …...

2026年,性价比超高的直播代运营供应商究竟哪家强?
在直播电商行业持续火爆的当下,众多品牌都希望借助直播代运营服务来提升销售业绩和品牌影响力。然而,市场上直播代运营供应商众多,质量参差不齐,如何选择一家性价比超高的供应商成为了品牌方的一大难题。今天,就为大家…...

【STM32F407 DSP实战】矩阵运算基础:从初始化到加减法与求逆的嵌入式实现
1. 为什么要在STM32F407上实现矩阵运算 在嵌入式开发中,矩阵运算可以说是无处不在。从简单的PID控制到复杂的图像处理算法,都离不开矩阵这个基础数据结构。就拿我最近做的一个四轴飞行器项目来说,姿态解算部分就需要频繁地进行矩阵乘法、求逆…...

LLM应用可观测性实战:基于OpenTelemetry与OpenLLMetry的监控方案
1. 项目概述:当LLM应用遇见可观测性如果你正在开发或维护一个基于大语言模型的应用,那么下面这个场景你一定不陌生:用户反馈说“AI助手刚才的回答很奇怪”,或者“昨天还能正常调用的功能今天突然报错了”。你打开日志,…...

AI代理协作平台agtx:用终端看板管理多AI编程工作流
1. 项目概述:一个能管理其他AI编程代理的终端看板如果你和我一样,每天要在Claude、Cursor、Codex这些AI编程工具之间来回切换,同时处理多个功能需求,那你肯定也经历过这种混乱:一个终端窗口里,Claude正在写…...

构建可信AI系统:从黑箱到透明决策的工程实践
1. 项目概述:当AI开始“思考”自己是谁最近和几个做AI安全的朋友聊天,大家不约而同地提到了一个越来越棘手的问题:我们怎么知道一个AI系统在“想”什么?或者说,我们怎么判断它给出的答案、做出的决策,是“可…...

数据流编排工具 diflowy:从核心概念到实战部署全解析
1. 项目概述:当“绿色”遇上“数据流编排” 最近在开源社区里,一个名为 green-dalii/diflowy 的项目引起了我的注意。乍一看这个名字, green-dalii 像是一个开发者或组织的标识,而 diflowy 则巧妙地融合了“data flow”&…...

Flutter中如何显示异步数据
在开发Flutter应用时,处理异步操作是非常常见的任务之一。许多时候,我们需要将异步操作的结果展示在用户界面上,比如从服务器获取数据或执行一些耗时的计算。本文将通过一个具体的实例,展示如何在Flutter中使用FutureBuilder来处理和显示异步数据。 问题背景 假设我们有一…...

DLSS Swapper:3个技巧彻底改变你的游戏性能优化体验
DLSS Swapper:3个技巧彻底改变你的游戏性能优化体验 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款革命性的游戏性能优化工具,它让你能够轻松管理NVIDIA DLSS、AMD FSR和Int…...