万字解读|怎样激活 TDengine 最高性价比?
不知不觉间,TDengine 已经 6 岁多了。在这 6 年多的时间里,我们从零开始,在一行又一行代码的淬炼下,TDengine 从 1.6 走过 2.0,终于走到如今的 3.0 时代。
自 2022 年下旬发布以来,经过我们不断地打磨优化之后,TDengine 3.0 在性能、功能、稳定性各个方面均有大幅提升,已经从一款时序数据库蜕变成为高性能、云原生、分布式的物联网、工业大数据平台。
如今这一平台下提供两大版本,分别是支持私有化部署的 TDengine Enterprise 以及全托管的物联网、工业大数据云服务 TDengine Cloud,这两大版本在开源版本 TDengine OSS 的功能基础上有更多加强,无论是个人开发者、中小企业还是大企业,都可轻松体验。
| 注意 | TDengine OSS(社区版)自 3.1.0.0 版本开始,仅支持主流操作系统的较新版本,包括 Ubuntu 18+/CentOS 7+/Ret Hat/Debian/CoreOS/FreeBSD/OpenSUSE/SUSE Linux/Fedora/macOS 等。除此之外,关于各种架构 CPU 的适配详情可以参考 支持平台列表 | TDengine 文档 | 涛思数据 。如果有其他操作系统及版本的需求,需 TDengine Enterprise(企业版)特殊支持。
我们建议,符合上述条件的开源用户全部迁移至 TDengine 3.0 版本上。在此基础之上,我们将为 TDengine 开源用户规划出三条以性价比为导向的产品使用规划路线。
但首先需要明确,我们“为什么”要做版本迁移:
- TDengine 3.0 是一款更加先进成熟的产品,除了性能功能变强以外,对各种复杂场景的适配性也更好,我们希望用户在拥有更优质产品体验的同时也更认可 TDengine 的产品能力。
- 由于 2.0 不再是 TDengine 主版本,不再拥有官方单独的维护团队,因此用户只能通过文档、过往资料以及彼此之间的互助来解决使用过程中产生的问题,可能会影响业务发展。
- 反过来讲,3.0 作为 TDengine 的主版本,我们十分重视用户的反馈,也会为用户提供更高质量的技术支持。
因此,除了官方文档以外,我们还为大家准备了大量技术文章,在体会 3.0 与 2.0 细节变化的同时,这些实操指导也能够帮助大家在最短时间内在本地完成自助式版本迁移。
接下来是,我们“怎样”完成版本迁移:
| 01 | 显然,最重要的内容就是 2.0 迁移至 3.0 的具体操作指导,可参考此篇文章:《如何把数据从 TDengine 2.x 迁移到 3.x ?》
| 02 | 3.0 和 2.0 在建表环节有很多底层变化,会直接影响后续使用效果,可参考:《体验 TDengine 3.0 高性能的第一步,请学会控制建表策略》
| 03 | 关于 TDengine 3.0 的集群功能,由于我们更换了一致性算法,因此在集群使用上会和 2.0 上有一些不同,可以参考:《如何用好强大的 TDengine 集群 ?先了解 RAFT 在 3.0 中的应用》
| 04 | 3.0 和 2.0 在数据 update 功能方面的变化可以参考:《TDengine 3.0 的 Update 功能和 2.0 有何区别?》
| 05 | 3.0 和 2.0 在数据库的参数体系上的变化,可以参考:《如何理解时序数据库 TDengine 3.0 的参数体系》
| 06 | 3.0 和 2.0 在 SQL 方面的变化,可以参考官方文档:语法变更 | TDengine 文档 | 涛思数据
| 07 | 3.0 和 2.0 在具体的连接器应用方面的变化,可以参考官方文档:连接器 | TDengine 文档 | 涛思数据
| 08 | 性能问题比较复杂,每个用户场景不同、涉及参数众多,即便是我们官方团队面对用户的性能问题也是需要很大的精力时间去排查优化的。因此我们提供了关于 3.0 TDengine 的数据文件架构,存储引擎工作原理的一系列文章,可以以下面这篇文章作为入口:《关于 3.0 和 2.0 的数据文件差异以及性能优化思路》
| 09 | 乱序数据对性能同样会产生干扰,原理如下,业务层需要尽量避免:《保护 TDengine 查询性能——3.0 如何大幅降低乱序数据干扰?》
如果你只是需要在原有 2.0 业务的基础上替换成 3.0 ,上述维度的技术内容基本可以满足你的需求了。但如果你还需要使用 3.0 的新功能,那也很方便,通过官方文档以及博客便可找到对应资料。
看起来,现在我们已经可以轻松地应用起 TDengine 3.0 了。
但实际上,我们还有更好的路线。
那就是选择 TDengine Cloud。
1 ► TDengine Cloud 将能完全解决运维层面的问题。你不需要再花时间去研究 TDengine 的连接配置、备份恢复、只需要专注于 TDengine 的使用即可。
2 ► 其次,TDengine Cloud 提供 7*24h 的专业技术服务,承诺 99.9% 的 Service Level Agreement,确保 TDengine 服务稳定运行(全托管模式)。
3 ► TDengine Cloud 内含企业级工具,可直接提供从 TDengine 2.0 到 3.0 环境的迁移支持。操作便捷性和性能较之开源版工具 taosdump 要胜出很多。
4 ► TDengine Cloud 完全按量计费,价格实惠,对于中小型规格的用户十分友好。通过 TDengine Cloud 的计费方案估算器,我们可以大致算出通用场景下项目所适合的套餐项目。比如:单副本,5 万测点,写入频率 1 秒 1 条的用户,通过计算器可知我们推荐的方案是基础版本,即每月只需要 1200 元,便可得到 TDengine 企业级的支持。而在正式购买之前,可以通过我们免费赠送的 600 元额度来试用 TDengine Cloud,直到评估出合适自己的套餐方案。
| 注意 | 查询带来的内存和 CPU 消耗完全取决于 SQL 类型和伴随业务需求的执行频率。所以如果资源不够,我们可以自行升级套餐。
总之,TDengine Cloud 基于友善的价格,在应对时序数据有效管理上,为你带来的是人力成本及运营成本大幅降低的全托管服务。
所以,以下便是我们为 TDengine 用户规划好的三种使用路线:
1. TDengine OSS(开源的时序数据库) 2.0 –> TDengine OSS 3.0
2. TDengine OSS 2.0 –> TDengine OSS 3.0 –> TDengine Enterprise/TDengine Cloud 3.0
3. TDengine OSS 2.0 –> TDengine Enterprise/TDengine Cloud 3.0
1 类用户仍然可以在工作时间内得到来自社区团队的咨询支持,但需要通过 taosdump 或者自己处理数据将其迁移至开源版 3.0 ,后续需自主完成日常的维护。在此期间,请尽量保证使用开源版的最新版本,尽量配合官方的步调。
对于 2 类用户,这是一种稳健的选择。仍然需要用户通过 taosdump 或者自己处理数据将其迁移至 3.0 版本。之后,经过一段时间的测试、应用、最终决定是否选择 TDengine Cloud(有私有化部署需求可以选择企业版)。
对于 3 类用户,该路线属于一步到位型。假如我们已经非常了解 TDengine 3.0 并且已经做足了相关测试,那么我们就可以直接购买 TDengine Cloud,通过 TDengine Cloud 的企业级迁移工具来迁移数据至云服务上,这样就省却很多中间的过渡工作了。(同上,有私有化部署需求可选择企业版)。
以中国地震台网中心的用户案例为例,这篇案例中 TDengine 3.0 的能力展现地淋漓尽致,在数据上就可以直观感受到——单集群可以处理每日 5000 亿行/900G 地震包数据。
所以,到底怎样才能激活 TDengine 的最高性价比呢 ?答案就是——拥抱 3.0 ,拥抱云原生。
了解更多 TDengine Database的具体细节,可在GitHub上查看相关源代码。
相关文章:

万字解读|怎样激活 TDengine 最高性价比?
不知不觉间,TDengine 已经 6 岁多了。在这 6 年多的时间里,我们从零开始,在一行又一行代码的淬炼下,TDengine 从 1.6 走过 2.0,终于走到如今的 3.0 时代。 自 2022 年下旬发布以来,经过我们不断地打磨优化…...

【目标检测】大图包括标签切分,并转换成txt格式
前言 遥感图像比较大,通常需要切分成小块再进行训练,之前写过一篇关于大图裁切和拼接的文章【目标检测】图像裁剪/标签可视化/图像拼接处理脚本,不过当时的工作流是先将大图切分成小图,再在小图上进行标注,于是就不考…...
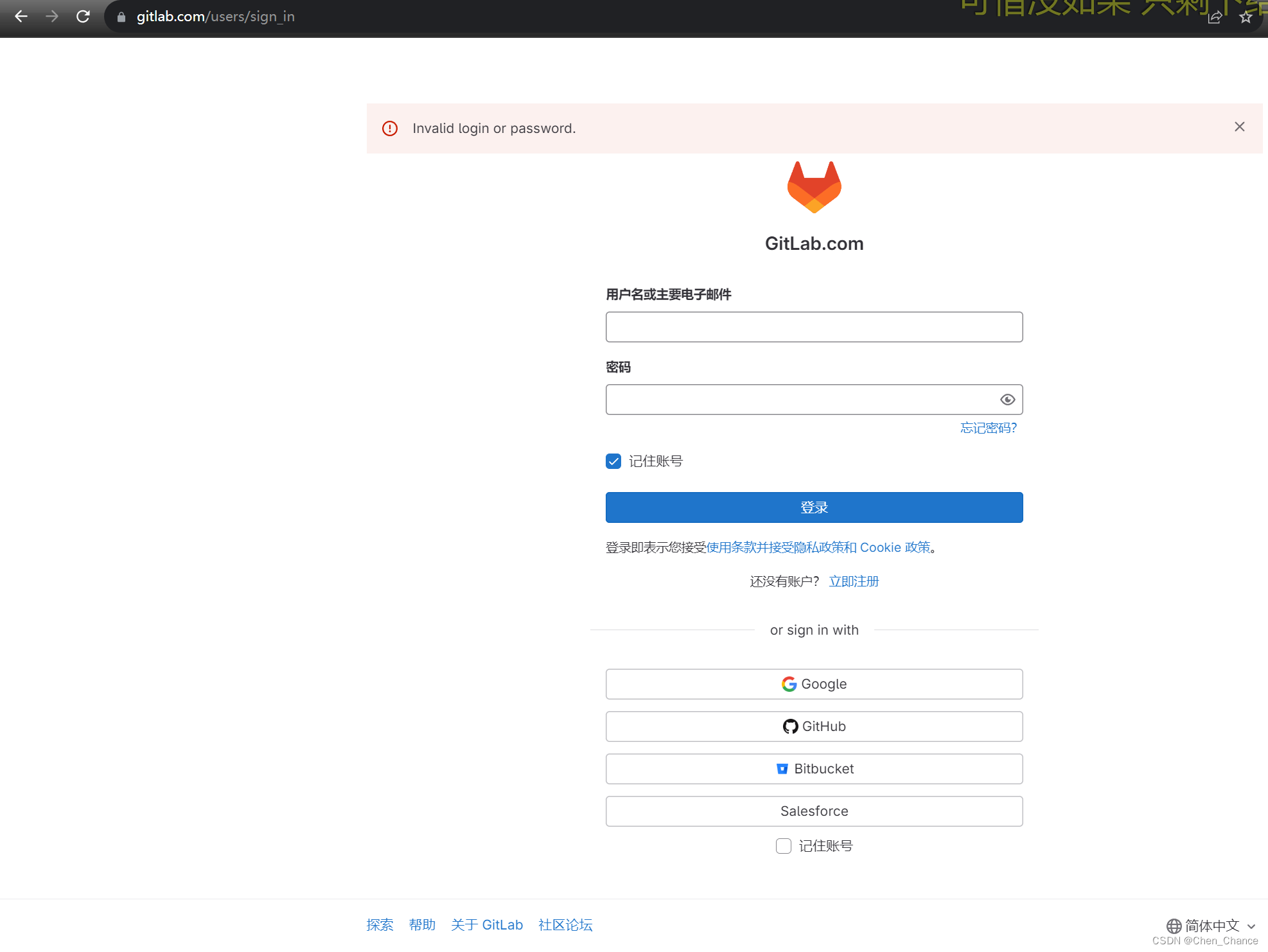
gitlab登录出现的Invalid login or password问题
前提 我是在一个项目里创建的gitlab账号,想在别的项目里登录或者官网登录发现怎么都登陆不上 原因 在GitLab中,有两种不同的账号类型:项目账号和个人账号(官网账号)。 项目账号:项目账号是在特定GitLab…...

git本地创建分支并推送到远程
1. 创建本地分支并切换到该分支 比如我创建dev分支。git checkout -b相当于把两条命令git branch 分支名、git checkout分支名合成一条,来实现一条命令新建分支切换分支。 git checkout -b dev 2. 将dev分支推送到远程 -u参数与--set-upstream这一串是一个意思&am…...

手机待办事项app哪个好?
手机是日常很多人随身携带的设备,手机除了拥有通讯功能外,还能帮助大家高效管理日常工作,借助手机上的待办事项提醒APP可以快速地帮助大家规划日常事务,提高工作的效率。 过去,我也曾经在寻找一款能够将工作任务清晰罗…...
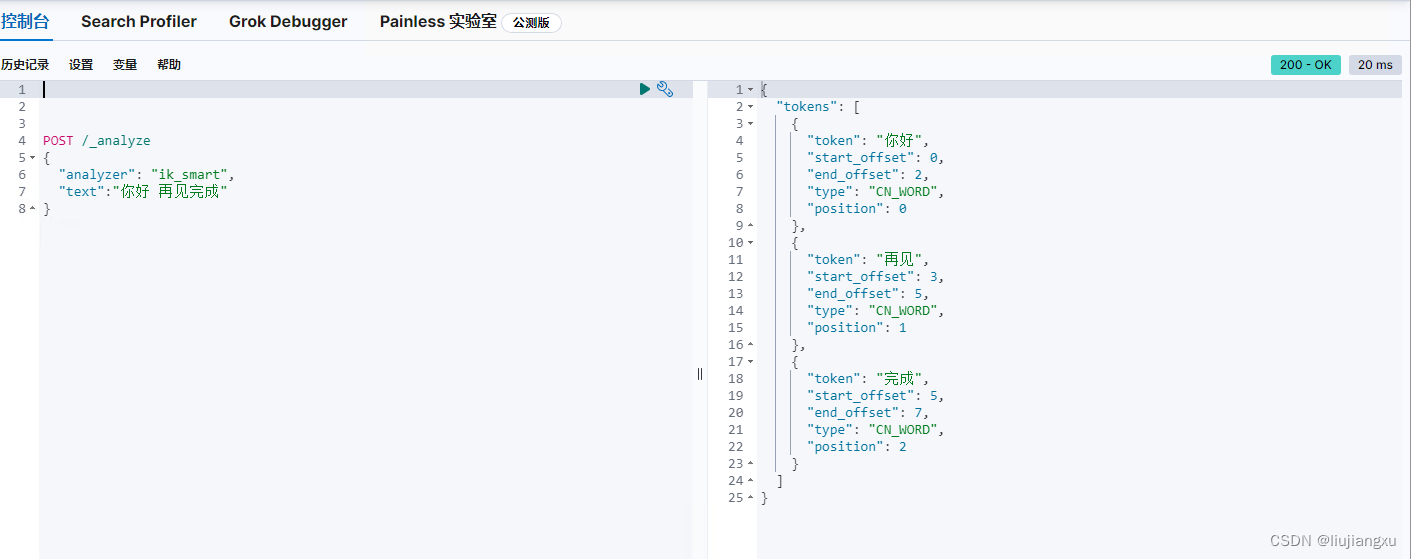
容器运行elasticsearch安装ik分词非root权限安装报错问题
有些应用默认不允许root用户运行,来确保应用的安全性,这也会导致我们使用docker run后一些操作问题,用es安装ik分词器举例(es版本8.9.0,analysis-ik版本8.9.0) 1. 容器启动elasticsearch 如挂载方式&…...

UE4游戏客户端开发进阶学习指南
前言 两年多前写过一篇入门指南,教大家在短时间内快速入门UE4的使用,在知乎被很多人收藏了。如今鸡佬使用UE快三年了,是时候更新一下进阶版本的学习指南。本文对于读者的要求: 有一定的C基础已经入门UE,能够用蓝图和…...

javaee SpringMVC 乱码问题解决
方法一 在web.xml文件中注册过滤器 <!-- 注册过滤器 设置编码 --><filter><filter-name>CharacterEncodingFilter</filter-name><filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class><init-param&…...
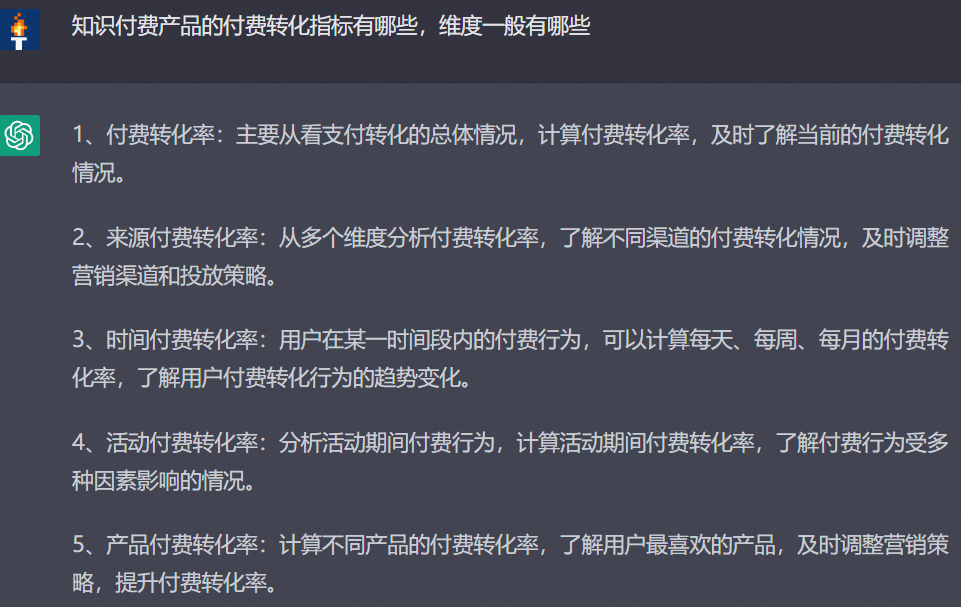
用ChatGPT做数据分析,提升10倍工作效率
目录 写报告分析框架报告框架指标体系设计 Excel 写报告 分析框架 拿到一个专题不知道怎么做?没关系,用ChatGPT列一下框架。 以上分析框架挺像那么回事,如果没思路的话,问问ChatGPT能起到找灵感的作用。 报告框架 报告的框架…...
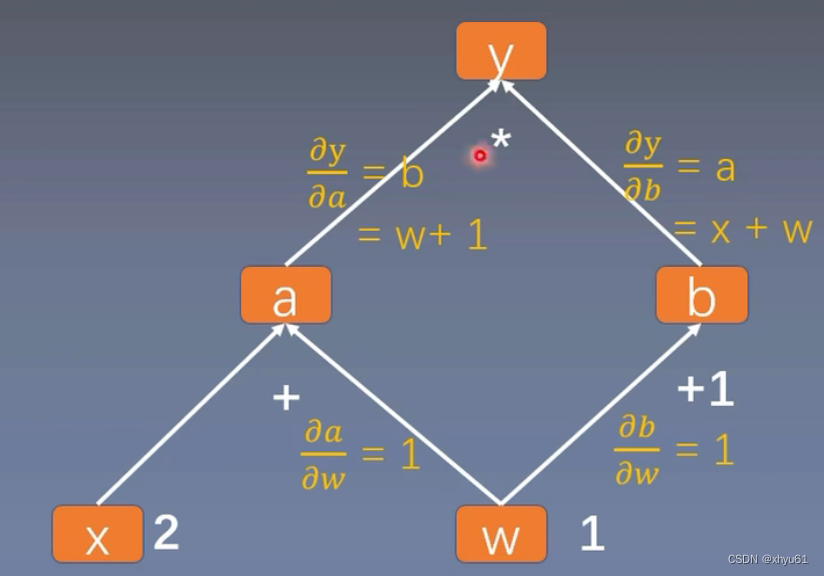
【Pytorch笔记】4.梯度计算
深度之眼官方账号 - 01-04-mp4-计算图与动态图机制 前置知识:计算图 可以参考我的笔记: 【学习笔记】计算机视觉与深度学习(2.全连接神经网络) 计算图 以这棵计算图为例。这个计算图中,叶子节点为x和w。 import torchw torch.tensor([1.]…...
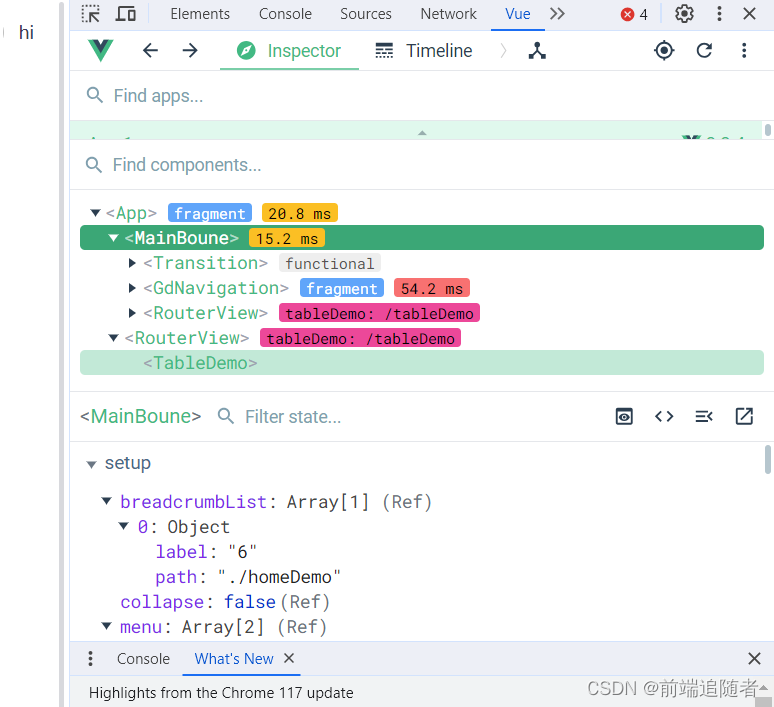
浏览器安装vue调试工具
下载扩展程序文件 下载链接:链接: 下载连接网盘地址, 提取码: 0u46,里面有两个crx,一个适用于vue2,一个适用于vue3,可根据vue版本选择不同的调试工具 crx安装扩展程序不成功,将文件改为rar文件然后解压 安装…...

C/C++学习 -- RSA算法
概述 RSA算法是一种广泛应用于数据加密与解密的非对称加密算法。它由三位数学家(Rivest、Shamir和Adleman)在1977年提出,因此得名。RSA算法的核心原理是基于大素数的数学问题的难解性,利用两个密钥来完成加密和解密操作。 特点 …...
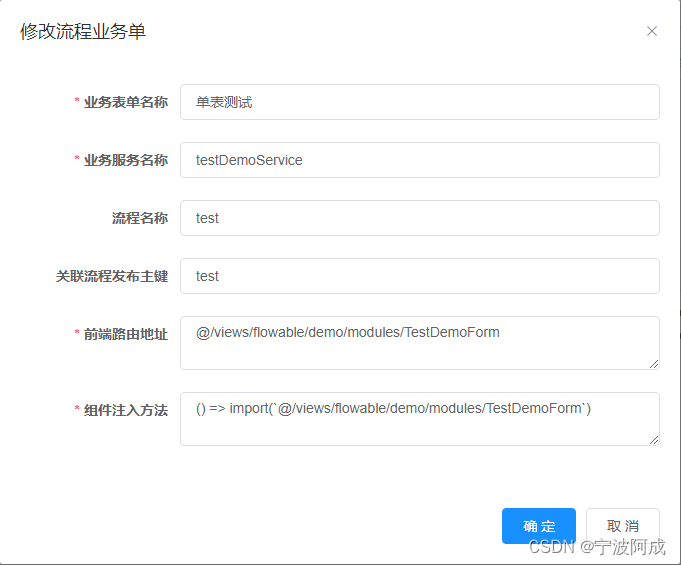
基于若依ruoyi-nbcio支持flowable流程增加自定义业务表单(一)
因为需要支持自定义业务表单的相关流程,所以需要建立相应的关联表 1、首先先建表wf_custom_form -- ---------------------------- -- Table structure for wf_custom_form -- ---------------------------- DROP TABLE IF EXISTS wf_custom_form; CREATE TABLE wf…...

面试经典 150 题 1 —(数组 / 字符串)— 88. 合并两个有序数组
88. 合并两个有序数组 方法一: class Solution { public:void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {for(int i 0; i<n;i){nums1[mi] nums2[i];}sort(nums1.begin(),nums1.end());} };方法二: clas…...

【大数据 | 综合实践】大数据技术基础综合项目 - 基于GitHub API的数据采集与分析平台
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…...
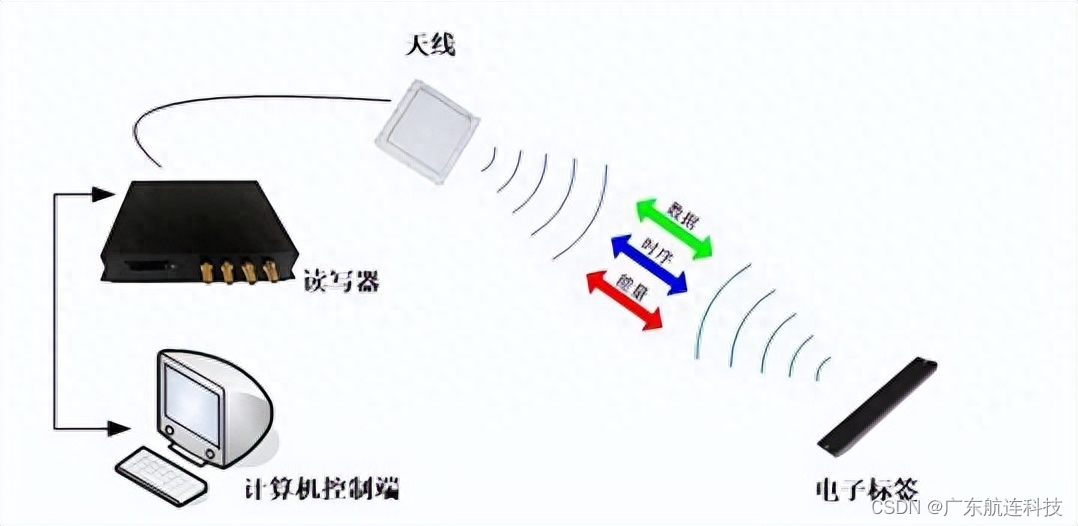
超高频RFID模具精细化生产管理方案
近二十年来,我国的模具行业经历了快速发展的阶段,然而,模具行业作为一个传统、复杂且竞争激烈的行业,企业往往以订单为导向,每个订单都需要进行新产品的开发,从客户需求分析、结构确定、报价、设计、物料准…...

FP-Growth算法全解析:理论基础与实战指导
目录 一、简介什么是频繁项集?什么是关联规则挖掘?FP-Growth算法与传统方法的对比Apriori算法Eclat算法 FP树:心脏部分 二、算法原理FP树的结构构建FP树第一步:扫描数据库并排序第二步:构建树 挖掘频繁项集优化&#x…...

Jmeter 分布式压测,你的系统能否承受高负载?
你可以使用 JMeter 来模拟高并发秒杀场景下的压力测试。这里有一个例子,它模拟了同时有 5000 个用户,循环 10 次的情况。 请求默认配置 token 配置 秒杀接口 结果分析 但是,实际企业中,这种压测方式根本不满足实际需求。下…...

什么是浮动密封?
浮动密封也称为机械面密封或双锥密封,是一种用于各种行业和应用的特殊类型的密封装置。它旨在提供有效的密封和保护,防止污染物的进入以及旋转设备中润滑剂或液体的润滑剂泄漏。 浮动密封件由相同的金属环组成,这些金属环称为密封环…...

浅析前端单元测试
对于前端来说,测试主要是对HTML、CSS、JavaScript进行测试,以确保代码的正常运行。 常见的测试有单元测试、集成测试、端到端(e2e)的测试。 单元测试:对程序中最小可测试单元进行测试。我们可以类比对汽车的测试&…...

保姆级教程:用Intel官方工具搞定Realsense D435深度不准和黑点问题
深度视觉优化实战:Intel RealSense D435深度校准全流程解析 刚拆封的RealSense D435摄像头在深度模式下出现零星黑点?深度图某些区域数值明显失真?这些问题往往不是硬件缺陷,而是出厂校准参数与实际使用环境不匹配导致的。作为计算…...

拾亩绿光纯亚麻籽微粉效果怎么样
很多人想通过亚麻籽补充营养,却常遇到传统亚麻籽难吸收、营养易流失的问题:直接嚼咽口感粗糙,普通研磨粉冲调结块,榨油后Omega-3等核心营养大量损耗。拾亩绿光纯亚麻籽微粉依托南京国英健康科技有限公司的专利技术,可解…...

基于物理信息神经网络与降阶模型的文物数字孪生保护框架
1. 项目概述:当文化遗产保护遇上科学计算与人工智能最近几年,我一直在关注一个交叉领域:如何用前沿的计算科学和人工智能技术,去解决那些看似传统、实则充满挑战的文物保护难题。这次分享的“基于SciML与数字孪生的文化遗产保护框…...

实测:2026 年国内直连 AI 一站式平台,聊天 / 绘画 / 论文 / 视频全搞定,不用翻墙不花冤枉钱
最近 AI 圈真的太卷了。ChatGPT 5.4、Gemini 3.1、Claude Code 轮番上新,多模态、长文本、代码 Auto Mode 一个比一个强。但普通用户想用明白,真的太折腾。先说说我踩过的三大坑,句句大实话网络糟心到崩溃官网打不开、地区不可用、加载转圈、…...

怎样高效清理电脑内存:3个实用技巧让你的电脑飞起来
怎样高效清理电脑内存:3个实用技巧让你的电脑飞起来 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memreduct 你是…...

移动安全架构:ECC加密与硬件加速实践解析
1. 移动安全架构的核心价值解析在2004年的移动通信市场,设备制造商正面临一个关键转折点。当时全球手机平均售价为163美元(智能手机高达360美元),而设备替换率预计将从2003年的22%增长到2009年的34%。在这个背景下,Cer…...

手把手教你用Makerbase VESC遥控你的电机:从硬件连接到APP配置的保姆级避坑指南
Makerbase VESC遥控电机全流程实战:从硬件对接到信号调优的深度指南 第一次拿到Makerbase VESC套件时,看着密密麻麻的接口和参数选项确实让人头皮发麻。作为过来人,我完全理解那种既兴奋又忐忑的心情——兴奋在于终于可以亲手打造自己的智能…...

通过API Key管理与审计日志功能加强企业级应用安全
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过API Key管理与审计日志功能加强企业级应用安全 将大模型能力集成到企业级应用,不仅关乎功能实现,更是一…...

如何通过命名规范降低代码维护成本:7个命名技巧提升长期项目质量
如何通过命名规范降低代码维护成本:7个命名技巧提升长期项目质量 【免费下载链接】naming-cheatsheet Comprehensive language-agnostic guidelines on variables naming. Home of the A/HC/LC pattern. 项目地址: https://gitcode.com/gh_mirrors/na/naming-chea…...

VirtualBox 6.1+ 搭配Win10:除了装系统,这些高效设置让你的虚拟机真正好用起来
VirtualBox 6.1 与Win10深度整合:解锁专业级虚拟化生产力的5个关键策略 当你已经成功在VirtualBox中安装好Windows 10虚拟机,这仅仅是虚拟化旅程的起点。真正的高手懂得如何将这个看似隔离的环境转变为无缝融入日常工作流的生产力引擎。本文将揭示那些鲜…...