PyCharm搭建Scrapy环境
Scrapy入门
- 1、Scrapy概述
- 2、PyCharm搭建Scrapy环境
- 3、Scrapy使用四部曲
- 4、Scrapy入门案例
- 4.1、明确目标
- 4.2、制作爬虫
- 4.3、存储数据
- 4.4、运行爬虫
1、Scrapy概述
Scrapy是一个由Python语言开发的适用爬取网站数据、提取结构性数据的Web应用程序框架。主要用于数据挖掘、信息处理、数据存储和自动化测试等。通过Scrapy框架实现一个爬虫,只需要少量的代码,就能够快速的网络抓取
Scrapy框架5大组件(架构):

- Scrapy引擎(Scrapy Engine):Scrapy引擎是整个框架的核心,负责Spider、ItemPipeline、Downloader、Scheduler间的通讯、数据传递等
- 调度器(Scheduler):网页URL的优先队列,主要负责处理引擎发送的请求,并按一定方式排列调度,当引擎需要时,交还给引擎
- 下载器(Downloader):负责下载引擎发送的所有Requests请求资源,并将其获取到的Responses交还给引擎,由引擎交给Spider来处理
- 爬虫(Spider):用户定制的爬虫,用于从特定网页中提取信息(实体Item),负责处理所有Responses,从中提取数据,并将需要跟进的URL提交给引擎,再次进入调度器
- 实体管道(Item Pipeline):用于处理Spider中获取的实体,并进行后期处理(详细分析、过滤、持久化存储等)
其他组件:
- 下载中间件(Downloader Middlewares):一个可以自定义扩展下载功能的组件
- Spider中间件(Spider Middlewares):一个可以自定扩展和操作引擎和Spider间通信的组件
官方文档:https://docs.scrapy.org
入门文档:https://doc.scrapy.org/en/latest/intro/tutorial.html
2、PyCharm搭建Scrapy环境
1)新建一个爬虫项目ScrapyDemo
2)在Terminal终端安装所需模块
Scrapy基于Twisted,Twisted是一个异步网络框架,主要用于提高爬虫的下载速度
pip install scrapy
pip install twisted
如果报错:
ERROR: Failed building wheel for twisted
error: Microsoft Visual C++ 14.0 or greater is required
则需要下载对应的whl文件安装:
Python扩展包whl文件下载:https://www.lfd.uci.edu/~gohlke/pythonlibs/#
ctrl+f查找需要的whl文件,点击下载对应版本
安装:
pip install whl文件绝对路径
例如:
pip install F:\PyWhl\Twisted-20.3.0-cp38-cp38m-win_amd64.whl
3)在Terminal终端创建爬虫项目ScrapyDemo
scrapy startproject ScrapyDemo
生成项目目录结构
4)在spiders文件夹下创建核心爬虫文件SpiderDemo.py
最终项目结构及说明:
ScrapyDemo/ 爬虫项目├── ScrapyDemo/ 爬虫项目目录 │ ├── spiders/ 爬虫文件│ │ ├── __init__.py │ │ └── SpiderDemo.py 自定义核心功能文件│ ├── __init__.py │ ├── items.py 爬虫目标数据│ ├── middlewares.py 中间件、代理 │ ├── pipelines.py 管道,用于处理爬取的数据 │ └── settings.py 爬虫配置文件└── scrapy.cfg 项目配置文件
3、Scrapy使用四部曲
1)明确目标
明确爬虫的目标网站
明确需要爬取实体(属性):items.py
定义:属性名 = scrapy.Field()
2)制作爬虫
自定义爬虫核心功能文件:spiders/SpiderDemo.py
3)存储数据
设计管道存储爬取内容:settings.py、pipelines.py
4)运行爬虫
方式1:在Terminal终端执行(cmd执行需要切到项目根目录下)
scrapy crawl dangdang(爬虫名)
cmd切换操作:
切盘:F:
切换目录:cd A/B/...
方式2:在PyCharm执行文件
在爬虫项目目录下创建运行文件run.py,右键运行
4、Scrapy入门案例
4.1、明确目标
1)爬取当当网手机信息:https://category.dangdang.com/cid4004279.html
2)明确需要爬取实体属性:items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapy# 1)明确目标
# 1.2)明确需要爬取实体属性
class ScrapyDemoItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 名称name = scrapy.Field()# 价格price = scrapy.Field()
4.2、制作爬虫
SpiderDemo.py
# 入门案例# 1)明确目标
# 1.1)爬取当当网手机信息:https://category.dangdang.com/cid4004279.html# 2)制作爬虫
import scrapy
from scrapy.http import Response
from ..items import ScrapyDemoItemclass SpiderDemo(scrapy.Spider):# 爬虫名称,运行爬虫时使用的值name = "dangdang"# 爬虫域,允许访问的域名allowed_domains = ['category.dangdang.com']# 爬虫地址:起始URL:第一次访问是域名start_urls = ['https://category.dangdang.com/cid4004279.html']# 翻页分析# 第1页:https://category.dangdang.com/cid4004279.html# 第2页:https://category.dangdang.com/pg2-cid4004279.html# 第3页:https://category.dangdang.com/pg3-cid4004279.html# ......page = 1# 请求响应处理def parse(self, response: Response):li_list = response.xpath('//ul[@id="component_47"]/li')for li in li_list:# 商品名称name = li.xpath('.//img/@alt').extract_first()print(name)# 商品价格price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()print(price)# 获取一个实体对象就交给管道pipelinesdemo = ScrapyDemoItem(name=name, price=price)# 封装item数据后,调用yield将控制权给管道,管道拿到item后返回该程序yield demo# 每一页爬取逻辑相同,只需要将执行下一页的请求再次调用parse()方法即可if self.page <= 10:self.page += 1url = rf"https://category.dangdang.com/pg{str(self.page)}-cid4004279.html"# scrapy.Request为scrapy的请求# yield中断yield scrapy.Request(url=url, callback=self.parse)
补充:Response对象的属性和方法
'''
1)获取响应的字符串
response.text
2)获取响应的二进制数据
response.body
3)解析响应内容
response.xpath()
'''
4.3、存储数据
settings.py
# Scrapy settings for ScrapyDemo project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html# 3)存储数据
# 3.1)爬虫配置、打开通道和添加通道# 爬虫项目名
BOT_NAME = "ScrapyDemo"SPIDER_MODULES = ["ScrapyDemo.spiders"]
NEWSPIDER_MODULE = "ScrapyDemo.spiders"# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = "ScrapyDemo (+http://www.yourdomain.com)"
# User-Agent配置
USER_AGENT = 'Mozilla/5.0'# Obey robots.txt rules
# 是否遵循机器人协议(默认True),为了避免一些爬取限制需要改为False
ROBOTSTXT_OBEY = False# Configure maximum concurrent requests performed by Scrapy (default: 16)
# 最大并发数
#CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# 下载延迟(单位:s),用于控制爬取的频率
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)
# 是否保存Cookies(默认False)
#COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# "Accept-Language": "en",
#}
# 请求头
DEFAULT_REQUEST_HEADERS = {"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Accept-Language": "en",
}# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# "ScrapyDemo.middlewares.ScrapydemoSpiderMiddleware": 543,
#}# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# "ScrapyDemo.middlewares.ScrapydemoDownloaderMiddleware": 543,
#}# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# "scrapy.extensions.telnet.TelnetConsole": None,
#}# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# "ScrapyDemo.pipelines.ScrapydemoPipeline": 300,
#}# 项目管道
ITEM_PIPELINES = {# 管道可以有多个,后面的数字是优先级(范围:1-1000),值越小优先级越高# 爬取网页'scrapy_dangdang.pipelines.ScrapyDemoPipeline': 300,# 保存数据'scrapy_dangdang.pipelines.ScrapyDemoSinkPiepline': 301,
}# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = "httpcache"
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = "scrapy.extensions.httpcache.FilesystemCacheStorage"# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"# 设置日志输出等级(默认DEBUG)与日志存放的路径
LOG_LEVEL = 'INFO'
# LOG_FILE = "spider.log"
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter# 3)存储数据
# 3.2)使用管道存储数据
# 若使用管道,则必须在settings.py中开启管道import os
import csv# 爬取网页
class ScrapyDemoPipeline:# 数据item交给管道输出def process_item(self, item, spider):print(item)return item# 保存数据
class ScrapyDemoSinkPiepline:# item为yield后面的ScrapyDemoItem对象,字典类型def process_item(self, item, spider):with open(r'C:\Users\cc\Desktop\scrapy_test.csv', 'a', newline='', encoding='utf-8') as csvfile:# 定义表头fields = ['name', 'price']writer = csv.DictWriter(csvfile, fieldnames=fields)writer.writeheader()# 写入数据writer.writerow(item)
4.4、运行爬虫
run.py
# 4)运行爬虫from scrapy import cmdlinecmdline.execute('scrapy crawl dangdang'.split())
其他文件不动,本案例运行会报错:
ERROR: Twisted-20.3.0-cp38-cp38m-win_amd64.whl is not a supported wheel on this platform
builtins.ModuleNotFoundError: No module named 'scrapy_dangdang'
原因大概是Twisted版本兼容问题,暂未解决,后续补充
相关文章:
PyCharm搭建Scrapy环境
Scrapy入门 1、Scrapy概述2、PyCharm搭建Scrapy环境3、Scrapy使用四部曲4、Scrapy入门案例4.1、明确目标4.2、制作爬虫4.3、存储数据4.4、运行爬虫 1、Scrapy概述 Scrapy是一个由Python语言开发的适用爬取网站数据、提取结构性数据的Web应用程序框架。主要用于数据挖掘、信息处…...
TensorFlow的transformer类模型文件转换为pytorch
在进行transformer类模型的训练或开发时,我们会在GitHub、huggingface等平台上下载已有的模型文件。个人习惯用pytorch框架进行代码编写,然而很多时候在下载模型文件时,会遇到TensorFlow的模型,这是就涉及到转换的问题。 首先说一…...
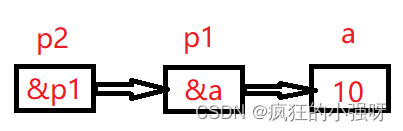
C++学习之指针和数组
指针和一维数组 一个数组包含若干元素,每个数组元素都在内存中占用存储单元,它们都有相应的地址。指针变量既可以指向变量,当然也可以指向数组元素。所谓数组元素的指针就是数组元素的地址。 eg: int a[6]; //定义一个整数数组a…...
什么是站内搜索引擎?如何在网站中加入站内搜索功能?
在当今数字时代,用户体验对于网站的成功起着至关重要的作用。提升用户体验和改善整体网站性能的一种方法是引入站内搜索引擎。站内搜索引擎是一种强大的工具,它的功能类似于Google或Bing等流行搜索引擎,但它专注于实施自己网站上的内容。用户…...
在派生类中定义一个虚函数、虚函数的静态解析)
【C++】面向对象编程(六)在派生类中定义一个虚函数、虚函数的静态解析
在派生类中定义一个虚函数 定义派生类时: 将基类中的虚函数覆盖掉:派生类提供新定义,所声明的函数原型必须完全符合基类所声明的函数原型(包括:参数列表、返回类型、常量性);原封不动继承基类…...
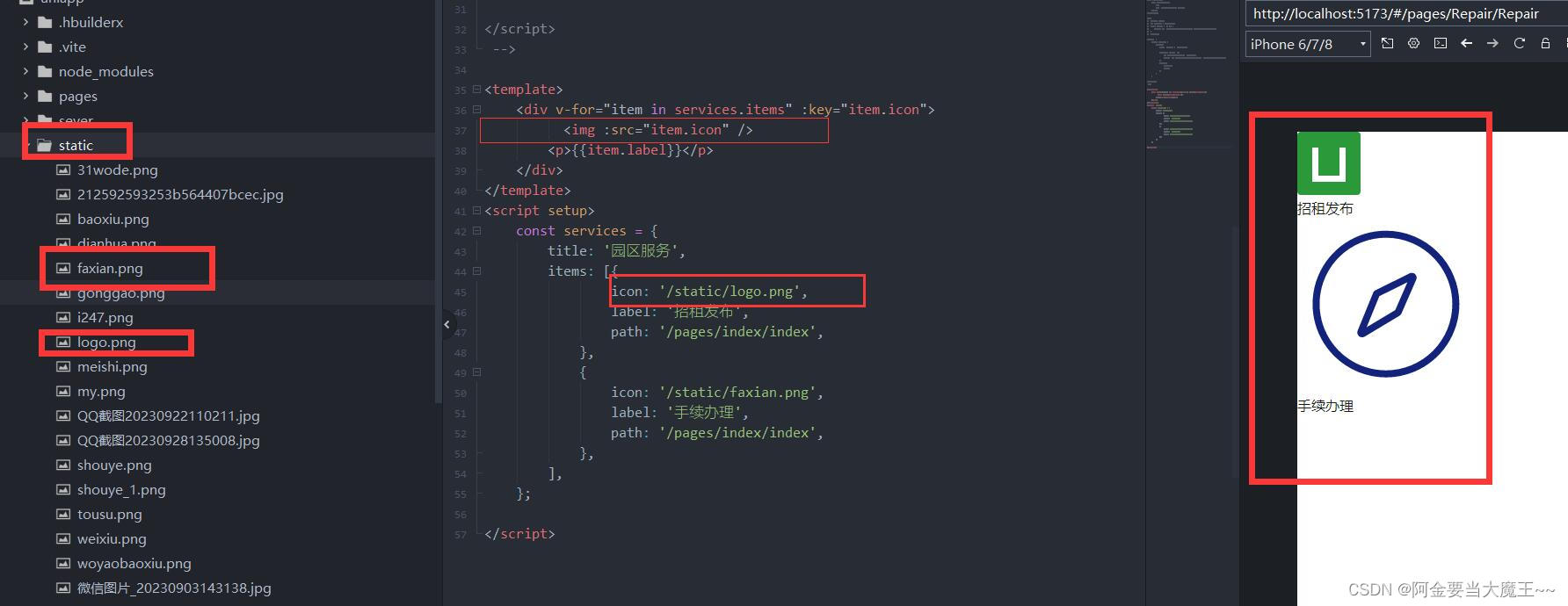
uniapp vue3 静态图片引入
方法一 从新定义路径 一定看好你图片的路径 代码 <template><div class"main">Main<img :src"getImg()" alt""></div> </template><!-- 方式一 // <script setup> // let imgName logo.png // cons…...

仅用61行代码,你也能从零训练大模型
本文并非基于微调训练模型,而是从头开始训练出一个全新的大语言模型的硬核教程。看完本篇,你将了解训练出一个大模型的环境准备、数据准备,生成分词,模型训练、测试模型等环节分别需要做什么。AI 小白友好~文中代码可以直接实操运…...
Vue3目录结构与Yarn.lock 的版本锁定
Vue目录结构与Yarn.lock 的版本锁定 一、Vue3.0目录结构图总览 举个例子看vue的目录,一开始不知道该目录是什么意思目录里各个文件包里安放有什么,程序员在哪里操作该如何操作。 下图目录看Vue新项目 VS Code 打开文件包后出现一列目录 二、目录结构 1…...
内网渗透之哈希传递
文章目录 哈希传递(NTLM哈希)概念LMNTLM 原理利用hash传递获取域控RDP 总结 哈希传递(NTLM哈希) 内网渗透中找到域控IP后使用什么攻击手法拿下域控: 扫描域控开放端口。因为域控会开放远程连接:windows开…...

Haar cascade+opencv检测算法
Harr特征识别人脸 Haar cascade opencv步骤 读取包含人脸的图片使用haar模型识别人脸将识别的结果用矩形框画出来 构造haar检测器 :cv2.CascadeClassifier(具体检测模型文件) # 构造Haar检测器 # 级联分级机,cv2.CascadeClassifier():cv2的内置方法࿰…...

跨域请求方案整理实践
项目场景: 调用接口进行手机验证提示,项目需要调用其它域名的接口,导致前端提示跨域问题 问题描述 前端调用其他域名接口时报错提示: index.html#/StatisticalAnalysisOfVacancy:1 Access to XMLHttpRequest at http://xxxxx/CustomerService/template/examineMes…...
Git Pull failure 【add/commit】
操作页面 操作步骤 1. 打开项目所在 在.git目录下右击打开Git Bssh Here 2. git add . 3. git commit -m "提交" 4. 成功提交到本地, 这下就可以拉取代码了...
单链表习题(对应章节chapter2)
题目1:链表的中间结点 题目来源:leetcode链表的中间结点 第一种思路分析:考虑指针移动到相应的位置来做 参考代码:位置(/chapter2/c/middle-link-list-node/lc1.cc) #include <stdio.h> extern &qu…...

SQL创建新表
表的创建、修改与删除: 1.1 直接创建表:CREATE TABLE [IF NOT EXISTS] tb_name – 不存在才创建,存在就跳过 (column_name1 data_type1 – 列名和类型必选 [ PRIMARY KEY – 可选的约束,主键 | FOREIGN KEY – 外键,引…...

Python视频剪辑-Moviepy视频尺寸和颜色调整技巧
在视频编辑中,尺寸和颜色是两个不能忽视的重要因素。本文将从专业角度深入探讨如何通过MoviePy进行视频尺寸和颜色的调整,以及遮罩透明度的应用。 文章目录 视频尺寸变换函数裁剪视频指定区域裁剪视频像素为偶数视频增加边框缩小、放大视频视频颜色变换函数blackwhite 视频变…...

前端笔记:Create React App 初始化项目的几个关键文件解读
1 介绍 Create React App 是一个官方支持的方式,用于创建单页应用的 React 设置用于构建用户界面的 JAVASCRIPT 库主要用于构建 UI 2 项目结构 一个典型的 Create React App 项目结构如下: ├── package.json ├── public # 这…...

提高工作效率!本地部署Stackedit Markdown编辑器,并实现远程访问
文章目录 1. docker部署Stackedit2. 本地访问3. Linux 安装cpolar4. 配置Stackedit公网访问地址5. 公网远程访问Stackedit6. 固定Stackedit公网地址 StackEdit是一个受欢迎的Markdown编辑器,在GitHub上拥有20.7k Star!,它支持将Markdown笔记保…...

visual studio解决bug封装dll库
1.速度最大化 O2 2.设置输出目录 配置属性/常规/输出目录 链接器/常规/输出dll文件 链接器/调试/输出程序数据库pdb文件 链接器/高级/导入库 3.输出X86 X64分别对应的dll、lib、pdb 然后修改更新说明 更新说明格式如下: 4.将库提交到FTP每日更新库文档下 和测试交接…...
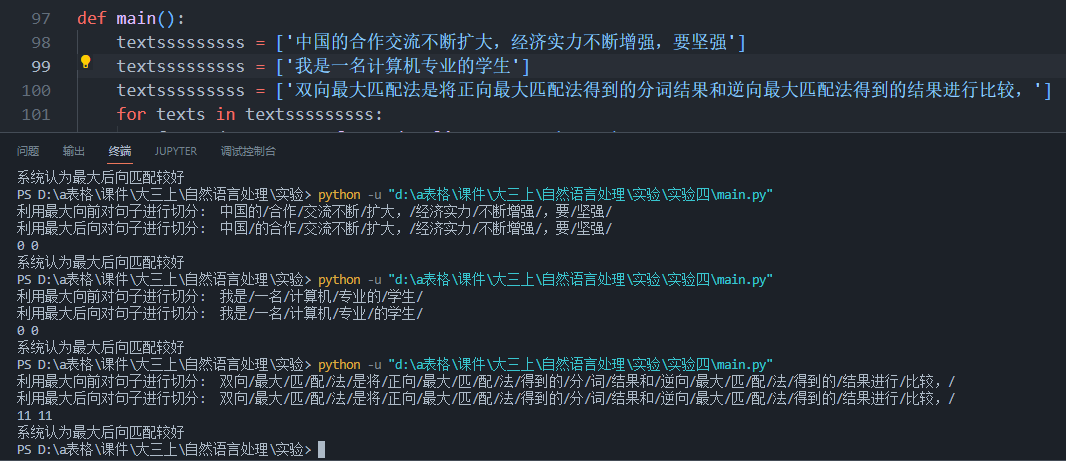
合肥工业大学自然语言处理实验报告
工程报告 目录 1 研究背景 4 2 工程目标 7 2.1 工程一 7 2.2 工程二 7 2.3 工程三 7 2.4 工程四 7 3 实验环境与工具 7 4 模型方法 8 4.1 n-gram模型 8 4.2 模型的平滑 9 4.2.1 Add-one 9 4.2.2 Add-k 9 4.2.3 Backoff 10 4.2.4 Interpolation 10 4.2.5 Absolute discounting 1…...
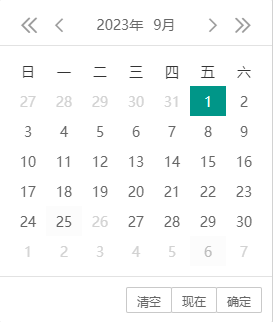
layui laydate实现日期选择并禁用指定的时间
最终实现禁用2023-9-26这天的效果 官网地址 日期和时间组件文档 - layui.laydate 下面是实现的代码 <!DOCTYPE html> <html> <head><meta charset"utf-8"><title>layDate快速使用</title><link rel"stylesheet"…...

终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程
终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_mirrors/sp/…...

Ix开源平台:基于Kubernetes的私有云与家庭实验室一体化管理方案
1. 项目概述与核心价值最近在折腾一个叫Ix的开源项目,它来自ix-infrastructure这个组织。乍一看这个名字,你可能觉得有点抽象,但如果你对自托管、家庭实验室、私有云或者想找一个更现代、更易用的 TrueNAS 替代品感兴趣,那这个项目…...

JVM调优实战:让你的服务性能提升50%
一、背景 线上一个核心订单服务,QPS 3000左右,经常出现接口超时告警。监控显示: 平均RT: 180ms(要求<100ms)Full GC频率: 每天20次,每次STW 1.5sCPU使用率: 峰值85%服务规格: 8C16G,堆内存…...
)
【优化交叉口的绿灯时间】基于遗传算法的交通灯管理研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
)
【限时公开】后印象派专属--ar 16:9 --style raw --stylize 800参数组合包(含塞尚构图/修拉点彩/劳特累克动态线共12套已验证prompt模板)
更多请点击: https://intelliparadigm.com 第一章:后印象派艺术精神与Midjourney风格迁移的本质逻辑 后印象派并非对印象派的简单延续,而是对主观表达、结构重构与象征张力的自觉回归——梵高旋转的星云、塞尚凝练的几何体、高更原始的色域&…...

防火门安装与验收要点|闭门器、密封条、顺序器缺一不可
防火门安装与验收要点一、必备配件(缺一不可)闭门器:自动关门,火灾常态闭合防火密封条:遇火膨胀,隔烟阻火顺序器:双扇门专用,保证先后闭合二、安装要点门框墙体嵌实牢固,…...

C++定时器避坑指南:线程安全、资源泄漏与时间轮参数怎么调?一次讲清楚
C定时器避坑指南:线程安全、资源泄漏与时间轮参数调优实战 在分布式系统和高并发场景中,定时器如同系统的心跳机制,其稳定性直接决定服务可靠性。去年某电商平台大促期间,由于定时任务堆积导致的雪崩效应,造成近千万损…...

ncmdumpGUI:3步解决网易云音乐ncm格式播放限制的终极方案
ncmdumpGUI:3步解决网易云音乐ncm格式播放限制的终极方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经在网易云音乐下载了心爱的歌曲…...

DeepSeek LeetCode 2421. 好路径的数目 Python3实现
给你 Python3 版本的代码,思路和之前的 Java 实现一致: 完整代码 python class Solution: def numberOfGoodPaths(self, vals: List[int], edges: List[List[int]]) -> int: n len(vals) # 1. 构建邻接表 gr…...

开源机械爪OpenClaw:从设计到力控抓取的完整实现指南
1. 项目概述:从“OpenClaw”看开源机械爪的无限可能最近在逛GitHub的时候,发现了一个挺有意思的项目,叫“MeyerZhou/openclaw”。光看名字,你大概能猜到这是个关于机械爪的开源项目。没错,这是一个旨在提供低成本、模块…...