Scala第十九章节
Scala第十九章节
scala总目录
文档资料下载
章节目标
- 了解Actor的相关概述
- 掌握Actor发送和接收消息
- 掌握WordCount案例
1. Actor介绍
Scala中的Actor并发编程模型可以用来开发比Java线程效率更高的并发程序。我们学习Scala Actor的目的主要是为后续学习Akka做准备。
1.1 Java并发编程的问题
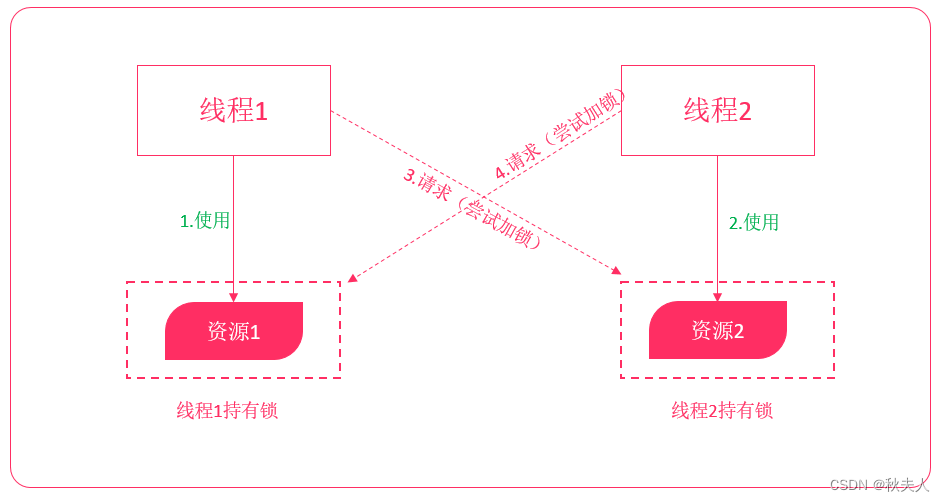
在Java并发编程中,每个对象都有一个逻辑监视器(monitor),可以用来控制对象的多线程访问。我们添加sychronized关键字来标记,需要进行同步加锁访问。这样,通过加锁的机制来确保同一时间只有一个线程访问共享数据。但这种方式存在资源争夺、以及死锁问题,程序越大问题越麻烦。
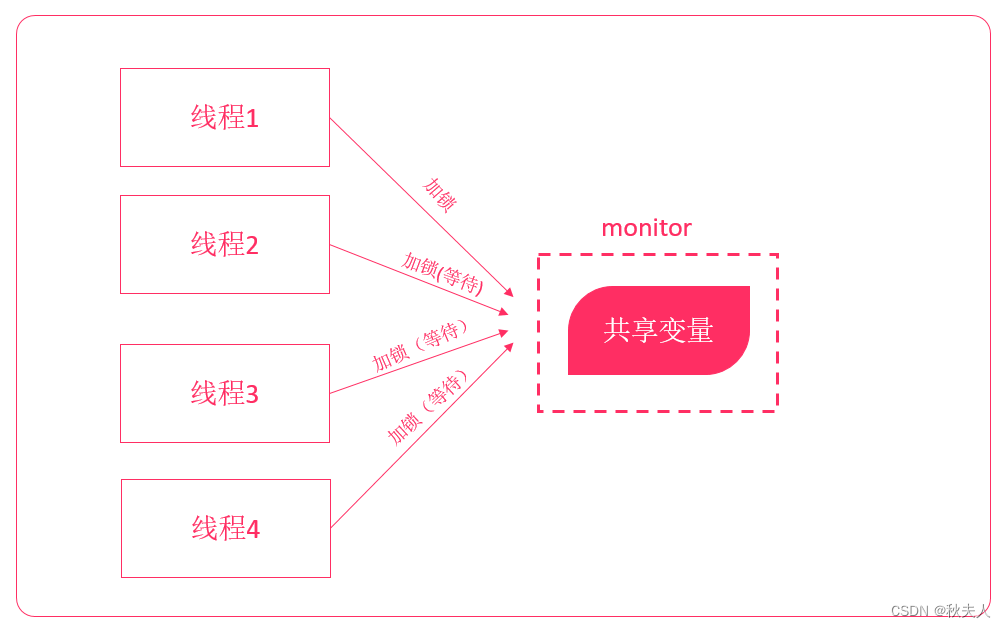
线程死锁
1.2 Actor并发编程模型
Actor并发编程模型,是Scala提供给程序员的一种与Java并发编程完全不一样的并发编程模型,是一种基于事件模型的并发机制。Actor并发编程模型是一种不共享数据,依赖消息传递的一种并发编程模式,有效避免资源争夺、死锁等情况。

1.3 Java并发编程对比Actor并发编程
| Java内置线程模型 | Scala Actor模型 |
|---|---|
| "共享数据-锁"模型 (share data and lock) | share nothing |
| 每个object有一个monitor,监视线程对共享数据的访问 | 不共享数据,Actor之间通过Message通讯 |
| 加锁代码使用synchronized标识 | |
| 死锁问题 | |
| 每个线程内部是顺序执行的 | 每个Actor内部是顺序执行的 |
注意:
scala在2.11.x版本中加入了Akka并发编程框架,老版本已经废弃。
Actor的编程模型和Akka很像,我们这里学习Actor的目的是为学习Akka做准备。
2. 创建Actor
我们可以通过类(class)或者单例对象(object), 继承Actor特质的方式, 来创建Actor对象.
2.1 步骤
- 定义class或object继承Actor特质
- 重写act方法
- 调用Actor的start方法执行Actor
注意: 每个Actor是并行执行的, 互不干扰.
2.2 案例一: 通过class实现
需求
- 创建两个Actor,一个Actor打印1-10,另一个Actor打印11-20
- 使用class继承Actor实现.(如果需要在程序中创建多个相同的Actor)
参考代码
import scala.actors.Actor//案例:Actor并发编程入门, 通过class创建Actor
object ClassDemo01 {//需求: 创建两个Actor,一个Actor打印1-10,另一个Actor打印11-20//1. 创建Actor1, 用来打印1~10的数字.class Actor1 extends Actor {override def act(): Unit = for (i <- 1 to 10) println("actor1: " + i)}//2. 创建Actor2, 用来打印11~20的数字.class Actor2 extends Actor {override def act(): Unit = for (i <- 11 to 20) println("actor2: " + i)}def main(args: Array[String]): Unit = {//3. 启动两个Actor.new Actor1().start()new Actor2().start()}
}
2.3 案例二: 通过object实现
需求
- 创建两个Actor,一个Actor打印1-10,另一个Actor打印11-20
- 使用object继承Actor实现.(如果在程序中只创建一个Actor)
参考代码
import scala.actors.Actor//案例:Actor并发编程入门, 通过object创建Actor
object ClassDemo02 {//需求: 创建两个Actor,一个Actor打印1-10,另一个Actor打印11-20//1. 创建Actor1, 用来打印1~10的数字.object Actor1 extends Actor {override def act(): Unit = for (i <- 1 to 10) println("actor1: " + i)}//2. 创建Actor2, 用来打印11~20的数字.object Actor2 extends Actor {override def act(): Unit = for (i <- 11 to 20) println("actor2: " + i)}def main(args: Array[String]): Unit = {//3. 启动两个Actor.Actor1.start()Actor2.start()}
}
2.4 Actor程序运行流程
- 调用start()方法启动Actor
- 自动执行act()方法
- 向Actor发送消息
- act方法执行完成后,程序会调用**exit()**方法结束程序执行.
3. 发送消息/接收消息
我们之前介绍Actor的时候,说过Actor是基于事件(消息)的并发编程模型,那么Actor是如何发送消息和接收消息的呢?
3.1 使用方式
3.1.1 发送消息
我们可以使用三种方式来发送消息:
| ! | 发送异步消息,没有返回值 |
|---|---|
| !? | 发送同步消息,等待返回值 |
| !! | 发送异步消息,返回值是Future[Any] |
例如:要给actor1发送一个异步字符串消息,使用以下代码:
actor1 ! "你好!"
3.1.2 接收消息
Actor中使用receive方法来接收消息,需要给receive方法传入一个偏函数
{case 变量名1:消息类型1 => 业务处理1case 变量名2:消息类型2 => 业务处理2...
}
注意: receive方法只接收一次消息,接收完后继续执行act方法
3.2 案例一: 发送及接收一句话
需求
- 创建两个Actor(ActorSender、ActorReceiver)
- ActorSender发送一个异步字符串消息给ActorReceiver
- ActorReceiver接收到该消息后,打印出来

参考代码
//案例: 采用 异步无返回的形式, 发送消息.
object ClassDemo03 {//1. 创建发送消息的Actor, ActorSender, 发送一句话给ActorReceiverobject ActorSender extends Actor {override def act(): Unit = {//发送一句话给ActorReceiverActorReceiver ! "你好啊, 我是ActorSender!"//发送第二句话ActorReceiver ! "你叫什么名字呀? "}}//2. 创建接收消息的Actor, ActorReceiverobject ActorReceiver extends Actor {override def act(): Unit = {//接收发送过来的消息.receive {case x: String => println(x)}}}def main(args: Array[String]): Unit = {//3. 启动两个ActorActorSender.start()ActorReceiver.start()}
}
3.3 案例二: 持续发送和接收消息
如果我们想实现ActorSender一直发送消息, ActorReceiver能够一直接收消息,该怎么实现呢?
答: 我们只需要使用一个while(true)循环,不停地调用receive来接收消息就可以啦。
需求
- 创建两个Actor(ActorSender、ActorReceiver)
- ActorSender持续发送一个异步字符串消息给ActorReceiver
- ActorReceiver持续接收消息,并打印出来
参考代码
//案例:Actor 持续发送和接收消息.
object ClassDemo04 {//1. 创建发送消息的Actor, ActorSender, 发送一句话给ActorReceiverobject ActorSender extends Actor {override def act(): Unit = {while(true) {//发送一句话给ActorReceiverActorReceiver ! "你好啊, 我是ActorSender!"//休眠3秒.TimeUnit.SECONDS.sleep(3) //单位是: 秒}}}//2. 创建接收消息的Actor, ActorReceiverobject ActorReceiver extends Actor {override def act(): Unit = {//接收发送过来的消息, 持续接收.while(true) {receive {case x: String => println(x)}}}}def main(args: Array[String]): Unit = {//3. 启动两个ActorActorSender.start()ActorReceiver.start()}
}
3.4 案例三: 优化持续接收消息
上述代码,是用while循环来不断接收消息的, 这样做可能会遇到如下问题:
- 如果当前Actor没有接收到消息,线程就会处于阻塞状态
- 如果有很多的Actor,就有可能会导致很多线程都是处于阻塞状态
- 每次有新的消息来时,重新创建线程来处理
- 频繁的线程创建、销毁和切换,会影响运行效率
针对上述情况, 我们可以使用loop(), 结合react()来复用线程, 这种方式比while循环 + receive()更高效.
需求
- 创建两个Actor(ActorSender、ActorReceiver)
- ActorSender持续发送一个异步字符串消息给ActorReceiver
- ActorReceiver持续接收消息,并打印出来
注意: 使用loop + react重写上述案例.
参考代码
//案例: 使用loop + react循环接收消息.
object ClassDemo05 {//1. 创建发送消息的Actor, ActorSender, 发送一句话给ActorReceiverobject ActorSender extends Actor {override def act(): Unit = {while(true) {//发送一句话给ActorReceiverActorReceiver ! "你好啊, 我是ActorSender!"//休眠3秒.TimeUnit.SECONDS.sleep(3) //单位是: 秒}}}//2. 创建接收消息的Actor, ActorReceiverobject ActorReceiver extends Actor {override def act(): Unit = {//接收发送过来的消息, 持续接收.loop{react {case x: String => println(x)}}}}def main(args: Array[String]): Unit = {//3. 启动两个ActorActorSender.start()ActorReceiver.start()}
}
3.5 案例四: 发送和接收自定义消息
我们前面发送的消息都是字符串类型,Actor中也支持发送自定义消息,例如:使用样例类封装消息,然后进行发送处理。
3.5.1 示例一: 发送同步有返回消息
需求
- 创建一个MsgActor,并向它发送一个同步消息,该消息包含两个字段(id、message)
- MsgActor回复一个消息,该消息包含两个字段(message、name)
- 打印回复消息
注意:
- 使用
!?来发送同步消息- 在Actor的act方法中,可以使用sender获取发送者的Actor引用
参考代码
//案例: Actor发送和接收自定义消息, 采用 同步有返回的形式
object ClassDemo06 {//1. 定义两个样例类Message(表示发送数据), ReplyMessage(表示返回数据.)case class Message(id: Int, message: String) //自定义的发送消息 样例类case class ReplyMessage(message: String, name: String) //自定义的接收消息 样例类//2. 创建一个MsgActor,用来接收MainActor发送过来的消息, 并向它回复一条消息.object MsgActor extends Actor {override def act(): Unit = {//2.1 接收 主Actor(MainActor) 发送过来的消息.loop {react {//结合偏函数使用case Message(id, message) => println(s"我是MsgActor, 我收到的消息是: ${id}, ${message}")//2.2 给MainActor回复一条消息.//sender: 获取消息发送方的Actor对象sender ! ReplyMessage("我很不好, 熏死了!...", "车磊")}}}}def main(args: Array[String]): Unit = {//3. 开启MsgActorMsgActor.start()//4. 通过MainActor, 给MsgActor发送一个 Message对象.//采用 !? 同步有返回.val reply:Any = MsgActor !? Message(1, "你好啊, 我是MainActor, 我在给你发消息!")//resutl表示最终接收到的 返回消息.val result = reply.asInstanceOf[ReplyMessage]//5. 输出结果.println(result)}
}
3.5.2 示例二: 发送异步无返回消息
需求
创建一个MsgActor,并向它发送一个异步无返回消息,该消息包含两个字段(id, message)
注意: 使用
!发送异步无返回消息
参考代码
//案例: Actor发送和接收自定义消息, 采用 异步 无返回的形式
object ClassDemo07 {//1. 定义一个样例类Message(表示发送数据)case class Message(id: Int, message: String) //自定义的发送消息 样例类//2. 创建一个MsgActor,用来接收MainActor发送过来的消息, 并打印.object MsgActor extends Actor {override def act(): Unit = {//2.1 接收 主Actor(MainActor) 发送过来的消息.loop {react {//结合偏函数使用case Message(id, message) => println(s"我是MsgActor, 我收到的消息是: ${id}, ${message}")}}}}def main(args: Array[String]): Unit = {//3. 开启MsgActorMsgActor.start()//4. 通过MainActor, 给MsgActor发送一个 Message对象.//采用 ! 异步无返回MsgActor ! Message(1, "我是采用 异步无返回 的形式发送消息!")}
}
3.5.3 示例三: 发送异步有返回消息
需求
- 创建一个MsgActor,并向它发送一个异步有返回消息,该消息包含两个字段(id、message)
- MsgActor回复一个消息,该消息包含两个字段(message、name)
- 打印回复消息
注意:
- 使用
!!发送异步有返回消息- 发送后,返回类型为Future[Any]的对象
- Future表示异步返回数据的封装,虽获取到Future的返回值,但不一定有值,可能在将来某一时刻才会返回消息
- Future的isSet()可检查是否已经收到返回消息,apply()方法可获取返回数据
图解

参考代码
//案例: Actor发送和接收自定义消息, 采用 异步有返回的形式
object ClassDemo08 {//1. 定义两个样例类Message(表示发送数据), ReplyMessage(表示返回数据.)case class Message(id: Int, message: String) //自定义的发送消息 样例类case class ReplyMessage(message: String, name: String) //自定义的接收消息 样例类//2. 创建一个MsgActor,用来接收MainActor发送过来的消息, 并向它回复一条消息.object MsgActor extends Actor {override def act(): Unit = {//2.1 接收 主Actor(MainActor) 发送过来的消息.loop {react {//结合偏函数使用case Message(id, message) => println(s"我是MsgActor, 我收到的消息是: ${id}, ${message}")//2.2 给MainActor回复一条消息.//sender: 获取消息发送方的Actor对象sender ! ReplyMessage("我很不好, 熏死了!...", "糖糖")}}}}def main(args: Array[String]): Unit = {//3. 开启MsgActorMsgActor.start()//4. 通过MainActor, 给MsgActor发送一个 Message对象.//采用 !! 异步有返回.val future: Future[Any] = MsgActor !! Message(1, "你好啊, 我是MainActor, 我在给你发消息!")//5. 因为future中不一定会立马有数据, 所以我们要校验.//Future的isSet()可检查是否已经收到返回消息,apply()方法可获取返回数据//!future.isSet表示: 没有接收到具体的返回消息, 就一直死循环.while(!future.isSet){}//通过Future的apply()方法来获取返回的数据.val result = future.apply().asInstanceOf[ReplyMessage]//5. 输出结果.println(result)}
}
4. 案例: WordCount
4.1 需求
接下来,我们要使用Actor并发编程模型实现多文件的单词统计。
案例介绍
给定几个文本文件(文本文件都是以空格分隔的),使用Actor并发编程来统计单词的数量.
思路分析
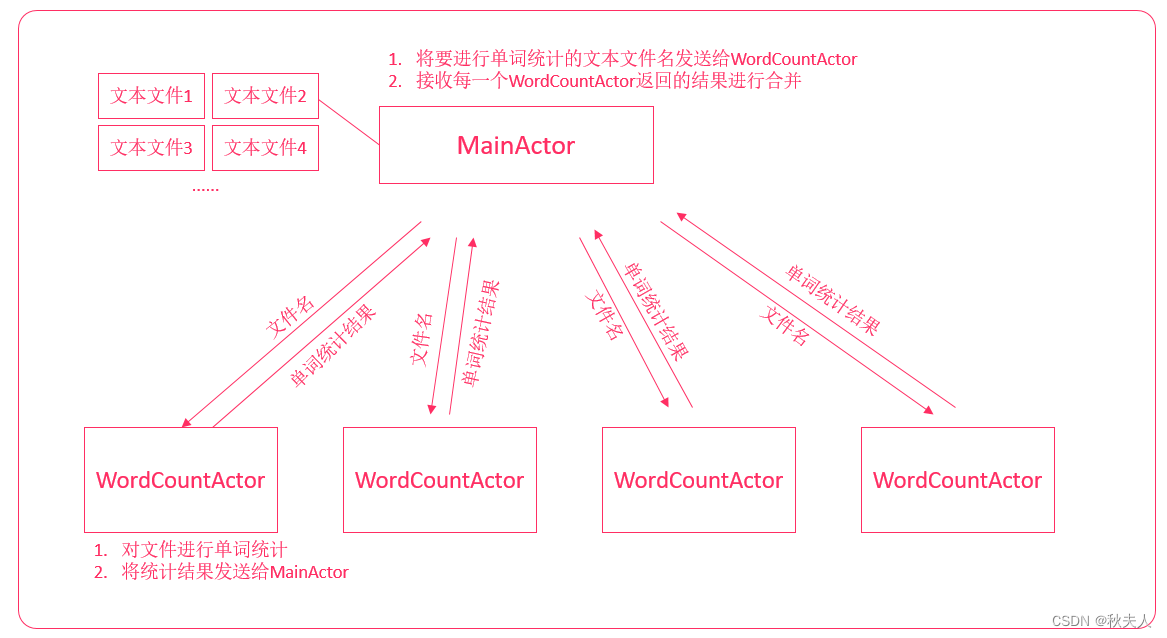
实现思路
- MainActor获取要进行单词统计的文件
- 根据文件数量创建对应的WordCountActor
- 将文件名封装为消息发送给WordCountActor
- WordCountActor接收消息,并统计单个文件的单词计数
- 将单词计数结果发送给MainActor
- MainActor等待所有的WordCountActor都已经成功返回消息,然后进行结果合并
4.2 步骤一: 获取文件列表
实现思路
-
在当前项目下的data文件夹下有: 1.txt, 2.txt两个文本文件, 具体存储内容如下:
1.txt文本文件存储内容如下:
hadoop sqoop hadoop hadoop hadoop flume hadoop hadoop hadoop spark2.txt文本文件存储内容如下:
flink hadoop hive hadoop sqoop hadoop hadoop hadoop hadoop spark -
获取上述两个文本文件的路径, 并将结果打印到控制台上.
参考代码
object MainActor {def main(args: Array[String]): Unit = {//1. 获取所有要统计的文件的路径.//1.1 定义变量dir, 记录保存所有文件的: 文件夹路径. ./data/var dir = "./data/"//1.2 获取该文件夹下, 所有的文件名.var fileNameList = new File(dir).list().toList //List("1.txt", "2.txt")//1.3 对获取到的文件名进行封装, 获取其全路径. ./data/1.txt ./data/2.txtvar fileDirList = fileNameList.map(dir + _)//println(fileDirList)}
}
4.3 步骤二: 创建WordCountActor
实现思路
- 根据文件数量创建对应个数的WordCountActor对象.
- 为了方便后续发送消息给Actor,将每个Actor与文件名关联在一起
实现步骤
- 创建WordCountActor
- 将文件列表转换为WordCountActor
- 为了后续方便发送消息给Actor,将Actor列表和文件列表拉链到一起
- 打印测试
参考代码
-
WordCountActor.scala文件中的代码
//2.1 先创建WordCountActor类, 用来获取WordCountActor对象. //创建WordCountActor类, 每一个WordCountActor对象, 统计一个文件. class WordCountActor extends Actor {override def act(): Unit = { } } -
MainActor.scala文件中的代码
object MainActor {def main(args: Array[String]): Unit = {//1. 获取所有要统计的文件的路径.//1.1 定义变量dir, 记录保存所有文件的: 文件夹路径. ./data/var dir = "./data/"//1.2 获取该文件夹下, 所有的文件名.var fileNameList = new File(dir).list().toList //List("1.txt", "2.txt")//1.3 对获取到的文件名进行封装, 获取其全路径. ./data/1.txt ./data/2.txtvar fileDirList = fileNameList.map(dir + _)//println(fileDirList)//2. 根据文件数量, 创建对应的WordCountActor对象.//2.1 先创建WordCountActor类, 用来获取WordCountActor对象.//2.2 根据文件数量, 创建对应的WordCountActor对象.val wordCountList = fileNameList.map(_ => new WordCountActor) //根据两个txt文件, 创建了两个wordCount对象.//println(wordCountList)//2.3 将WordCountActor和文件全路径关联起来val actorWithFile = wordCountList.zip(fileDirList) //WordCountActor -> ./data/1.txt , WordCountActor -> ./data/2.txtprintln(actorWithFile)} }
4.4 步骤三: 启动Actor/发送/接收任务消息
实现思路
启动所有WordCountActor对象,并发送单词统计任务消息给每个WordCountActor对象.
注意: 此处应
发送异步有返回消息
实现步骤
- 创建一个WordCountTask样例类消息,封装要进行单词计数的文件名
- 启动所有WordCountActor,并发送异步有返回消息
- 获取到所有的WordCountActor中返回的消息(封装到一个Future列表中)
- 在WordCountActor中接收并打印消息
参考代码
-
MessagePackage.scala文件中的代码
/*** 表示: MainActor 给每一个WordCountActor发送任务的 格式.* @param fileName 具体的要统计的 文件路径.*/ case class WordCountTask(fileName:String) -
MainActor.scala文件中的代码
object MainActor {def main(args: Array[String]): Unit = {//1. 获取所有要统计的文件的路径.//1.1 定义变量dir, 记录保存所有文件的: 文件夹路径. ./data/var dir = "./data/"//1.2 获取该文件夹下, 所有的文件名.var fileNameList = new File(dir).list().toList //List("1.txt", "2.txt")//1.3 对获取到的文件名进行封装, 获取其全路径. ./data/1.txt ./data/2.txtvar fileDirList = fileNameList.map(dir + _)//println(fileDirList)//2. 根据文件数量, 创建对应的WordCountActor对象.//2.1 先创建WordCountActor类, 用来获取WordCountActor对象.//2.2 根据文件数量, 创建对应的WordCountActor对象.val wordCountList = fileNameList.map(_ => new WordCountActor) //根据两个txt文件, 创建了两个wordCount对象.//println(wordCountList)//2.3 将WordCountActor和文件全路径关联起来val actorWithFile = wordCountList.zip(fileDirList) //WordCountActor -> ./data/1.txt , WordCountActor -> ./data/2.txtprintln(actorWithFile)//3. 启动WordCountActor, 并给每一个WordCountActor发送任务./*Map(spark -> 1, hadoop -> 7, sqoop -> 1, flume -> 1)Map(sqoop -> 1, flink -> 1, hadoop -> 6, spark -> 1, hive -> 1)*/val futureList: List[Future[Any]] = actorWithFile.map { //futureList: 记录的是所有WordCountActor统计的结果.keyVal => //keyVal的格式: WordCountActor -> ./data/1.txt//3.1 获取具体的要启动的WordCountActor对象.val actor = keyVal._1 //actor: WordCountActor//3.2 启动具体的WordCountActor.actor.start()//3.3 给每个WordCountActor发送具体的任务(文件路径) 异步有返回.val future: Future[Any] = actor !! WordCountTask(keyVal._2)future //记录的是某一个WordCountActor返回的统计结果.}} } -
WordCountActor.scala文件中的代码
//2.1 先创建WordCountActor类, 用来获取WordCountActor对象. //创建WordCountActor类, 每一个WordCountActor对象, 统计一个文件. class WordCountActor extends Actor {override def act(): Unit = { loop {react {//3.4 接收具体的任务case WordCountTask(fileName) =>//3.5 打印具体的任务println(s"接收到的具体任务是: ${fileName}")}}} }
4.5 步骤四: 统计文件单词计数
实现思路
读取文件文本,并统计出来单词的数量。例如:
(hadoop, 3), (spark, 1)...
实现步骤
- 读取文件内容,并转换为列表
- 按照空格切割文本,并转换为一个一个的单词
- 为了方便进行计数,将单词转换为元组
- 按照单词进行分组,然后再进行聚合统计
- 打印聚合统计结果
参考代码
-
WordCountActor.scala文件中的代码
class WordCountActor extends Actor {override def act(): Unit = {//采用loop + react 方式接收数据.loop {react {//3.4 接收具体的任务case WordCountTask(fileName) =>//3.5 打印具体的任务println(s"接收到的具体任务是: ${fileName}")//4. 统计接收到的文件中的每个单词的数量.//4.1 获取指定文件中的所有的文件. List("hadoop sqoop hadoop","hadoop hadoop flume")val lineList = Source.fromFile(fileName).getLines().toList//4.2 将上述获取到的数据, 转换成一个一个的字符串. //List("hadoop", "sqoop", "hadoop","hadoop", "hadoop", "flume")val strList = lineList.flatMap(_.split(" "))//4.3 给每一个字符串后边都加上次数, 默认为1. //List("hadoop"->1, "sqoop"->1, "hadoop"->1, "hadoop"->1, "flume"->1)val wordAndCount = strList.map(_ -> 1)//4.4 按照 字符串内容分组. //"hadoop" -> List("hadoop"->1, "hadoop"->1), "sqoop" -> List("sqoop"->1)val groupMap = wordAndCount.groupBy(_._1)//4.5 对分组后的内容进行统计, 统计每个单词的总次数. "hadoop" -> 2, "sqoop" -> 1val wordCountMap = groupMap.map(keyVal => keyVal._1 -> keyVal._2.map(_._2).sum)//4.6 打印统计后的结果. println(wordCountMap)}}} }
4.6 步骤五: 返回结果给MainActor
实现思路
- 将单词计数的结果封装为一个样例类消息,并发送给MainActor
- MainActor等待所有WordCountActor均已返回后,获取到每个WordCountActor单词计算后的结果
实现步骤
- 定义一个样例类封装单词计数结果
- 将单词计数结果发送给MainActor
- MainActor中检测所有WordCountActor是否均已返回,如果均已返回,则获取并转换结果
- 打印结果
参考代码
-
MessagePackage.scala文件中的代码
/*** 表示: MainActor 给每一个WordCountActor发送任务的 格式.* @param fileName 具体的要统计的 文件路径.*/ case class WordCountTask(fileName:String)/*** 每个WordCountActor统计完的返回结果的: 格式* @param wordCountMap 具体的返回结果, 例如: Map("hadoop"->6, "sqoop"->1)*/ case class WordCountResult(wordCountMap:Map[String, Int]) -
WordCountActor.scala文件中的代码
class WordCountActor extends Actor {override def act(): Unit = {//采用loop + react 方式接收数据.loop {react {//3.4 接收具体的任务case WordCountTask(fileName) =>//3.5 打印具体的任务println(s"接收到的具体任务是: ${fileName}")//4. 统计接收到的文件中的每个单词的数量.//4.1 获取指定文件中的所有的文件. List("hadoop sqoop hadoop","hadoop hadoop flume")val lineList = Source.fromFile(fileName).getLines().toList//4.2 将上述获取到的数据, 转换成一个一个的字符串. List("hadoop", "sqoop", "hadoop","hadoop", "hadoop", "flume")val strList = lineList.flatMap(_.split(" "))//4.3 给每一个字符串后边都加上次数, 默认为1. List("hadoop"->1, "sqoop"->1, "hadoop"->1,"hadoop"->1, "hadoop"->1, "flume"->1)val wordAndCount = strList.map(_ -> 1)//4.4 按照 字符串内容分组. "hadoop" -> List("hadoop"->1, "hadoop"->1), "sqoop" -> List("sqoop"->1)val groupMap = wordAndCount.groupBy(_._1)//4.5 对分组后的内容进行统计, 统计每个单词的总次数. "hadoop" -> 2, "sqoop" -> 1val wordCountMap = groupMap.map(keyVal => keyVal._1 -> keyVal._2.map(_._2).sum)//4.6 把统计后的结果返回给: MainActor.sender ! WordCountResult(wordCountMap)}}} }
4.7 步骤六: 结果合并
实现思路
对接收到的所有单词计数进行合并。
参考代码
-
MainActor.scala文件中的代码
object MainActor {def main(args: Array[String]): Unit = {//1. 获取所有要统计的文件的路径.//1.1 定义变量dir, 记录保存所有文件的: 文件夹路径. ./data/var dir = "./data/"//1.2 获取该文件夹下, 所有的文件名.var fileNameList = new File(dir).list().toList //List("1.txt", "2.txt")//1.3 对获取到的文件名进行封装, 获取其全路径. ./data/1.txt ./data/2.txtvar fileDirList = fileNameList.map(dir + _)//println(fileDirList)//2. 根据文件数量, 创建对应的WordCountActor对象.//2.1 先创建WordCountActor类, 用来获取WordCountActor对象.//2.2 根据文件数量, 创建对应的WordCountActor对象.val wordCountList = fileNameList.map(_ => new WordCountActor) //根据两个txt文件, 创建了两个wordCount对象.//println(wordCountList)//2.3 将WordCountActor和文件全路径关联起来val actorWithFile = wordCountList.zip(fileDirList) //WordCountActor -> ./data/1.txt , WordCountActor -> ./data/2.txtprintln(actorWithFile)//3. 启动WordCountActor, 并给每一个WordCountActor发送任务./*Map(spark -> 1, hadoop -> 7, sqoop -> 1, flume -> 1)Map(sqoop -> 1, flink -> 1, hadoop -> 6, spark -> 1, hive -> 1)*/val futureList: List[Future[Any]] = actorWithFile.map { //futureList: 记录的是所有WordCountActor统计的结果.keyVal => //keyVal的格式: WordCountActor -> ./data/1.txt//3.1 获取具体的要启动的WordCountActor对象.val actor = keyVal._1 //actor: WordCountActor//3.2 启动具体的WordCountActor.actor.start()//3.3 给每个WordCountActor发送具体的任务(文件路径) 异步有返回.val future: Future[Any] = actor !! WordCountTask(keyVal._2)future //记录的是某一个WordCountActor返回的统计结果.}//5. MainActor对接收到的数据进行合并.//5.1 判断所有的future都有返回值后, 再往下执行.// 过滤没有返回值的future 不为0说明还有future没有收到值while(futureList.filter(!_.isSet).size != 0) {} //futureList: future1, future2//5.2 从每一个future中获取数据.//wordCountMap: List(Map(spark -> 1, hadoop -> 7, sqoop -> 1, flume -> 1), Map(sqoop -> 1, flink -> 1, hadoop -> 6, spark -> 1, hive -> 1))val wordCountMap = futureList.map(_.apply().asInstanceOf[WordCountResult].wordCountMap)//5.3 对获取的数据进行flatten, groupBy, map, 然后统计.val result = wordCountMap.flatten.groupBy(_._1).map(keyVal => keyVal._1 -> keyVal._2.map(_._2).sum)//5.4 打印结果println(result)} }
相关文章:
Scala第十九章节
Scala第十九章节 scala总目录 文档资料下载 章节目标 了解Actor的相关概述掌握Actor发送和接收消息掌握WordCount案例 1. Actor介绍 Scala中的Actor并发编程模型可以用来开发比Java线程效率更高的并发程序。我们学习Scala Actor的目的主要是为后续学习Akka做准备。 1.1 Ja…...

kafka与hbase的区别
Kafka 和 HBase 是两个不同的分布式数据存储系统,它们可以在大数据应用中发挥不同的作用。 Kafka 是一个高吞吐量的分布式发布订阅消息系统,主要用于处理实时数据流。它具有以下特点: 高性能:Kafka 能够以非常高的吞吐量和低延迟…...

出栈序列的合法性
给定一个最大容量为 M 的堆栈,将 N 个数字按 1, 2, 3, ..., N 的顺序入栈,允许按任何顺序出栈,则哪些数字序列是不可能得到的?例如给定 M5、N7,则我们有可能得到{ 1, 2, 3, 4, 5, 6, 7 },但不可能得到{ 3, …...
unity操作_刚体 c#
刚体Rigidbody 首先在场景中创建一个Plane 位置重置一下 再创建一个Cube 充值 y0.5 我们可以看出创建的Cube 和 Plane都自带碰撞器 Plane用的是网格碰撞器 我们可以通过网格世界看到不同的网格碰撞器 发生碰撞(条件): 两个物体都有碰撞器 …...
介绍(Python示例))
网络编程中套接字(socket)介绍(Python示例)
网络编程中套接字(socket)介绍(Python示例) 网络编程就是同一计算机的进程间或者不同的联网计算机之间的通信(交换数据)。 那么,这两台计算机之间用什么传输数据呢?首先你肯定先需要…...

d3dcompiler_43.dll是什么文件?缺失d3dcompiler_43.dll文件修复与解决方法
今天我要和大家分享的是关于d3dcompiler_43.dll丢失的解决方法。我相信很多网友在使用电脑时都遇到过这个问题,那么接下来就让我们一起来探讨一下如何解决这个问题吧! 首先,让我们来了解一下d3dcompiler_43.dll文件的总体介绍。d3dcompiler_…...

YOLOv7改进:SPD-Conv,低分辨率图像和小物体涨点明显,涨点神器!!!
💡💡💡本文属于原创独家改进:SPD-Conv,优势:处理低分辨率图像和小物体等更困难的任务时性能更优 SPD-Conv | 亲测在多个数据集实现暴力涨点,尤其是小物体检测你值得拥有,强烈推荐,独家首发; 收录: YOLOv7高阶自研专栏介绍: http://t.csdnimg.cn/tYI0c ✨…...
连接mysql数据库)
iris(golang)连接mysql数据库
连接mysql数据库 安装依赖 go get github.com/go-sql-driver/mysqlfunc LinkMySQL(){DB,_ : sql.Open("mysql","root:123456tcp(127.0.0.1:3306)/webgo_accout")//设置数据库最大连接数DB.SetConnMaxLifetime(100)//设置上数据库最大闲置连接数DB.SetMaxId…...
笔记)
C现代方法(第1、2章)笔记
文章目录 C现代方法笔记(chapter1&2)序言0.1 C标准0.2 现代方法 第1章 C语言概述1.1 C语言的历史1.1.1 起源1.1.2 标准化1.1.3 基于C的语言 1.2 C语言的优缺点1.2.1 C语言的优点1.2.2 C语言的缺点1.2.3 高效地使用C语言 第2章 C语言基本概念2.1 编写…...

练[CISCN2019 华东南赛区]Double Secret
[CISCN2019 华东南赛区]Double Secret 文章目录 [CISCN2019 华东南赛区]Double Secret掌握知识解题思路关键paylaod 掌握知识 flask框架报错源码泄露,使用脚本进行RC4加解,ssti使用内置函数进行模板注入 解题思路 打开网站链接,页面就一…...

『Linux - gcc / g++』c程序翻译过程
文章目录 前言预处理 -E编译 -S汇编 -c链接动静态链接 前言 在计算机中的每一个程序是由代码变化而来的,但是事实上来说,用 c/C 写出的代码是不能被计算机识别的,其中必须经过一系列的过程才能使这个代码能成功的被计算机识别; …...

苹果遭遇安全危机,应用商店曝出不良APP,或影响iPhone的销售
据澎湃新闻报道指苹果的App Store被曝出不良APP位居下载榜前列,这对于向来强调APP严格审核的苹果来说是巨大的打击,更影响向来被认为信息安全遥遥领先的名声,对当下正热销的iPhone15或造成打击。 据了解被曝的软件以“学习XX字母”为命名&…...
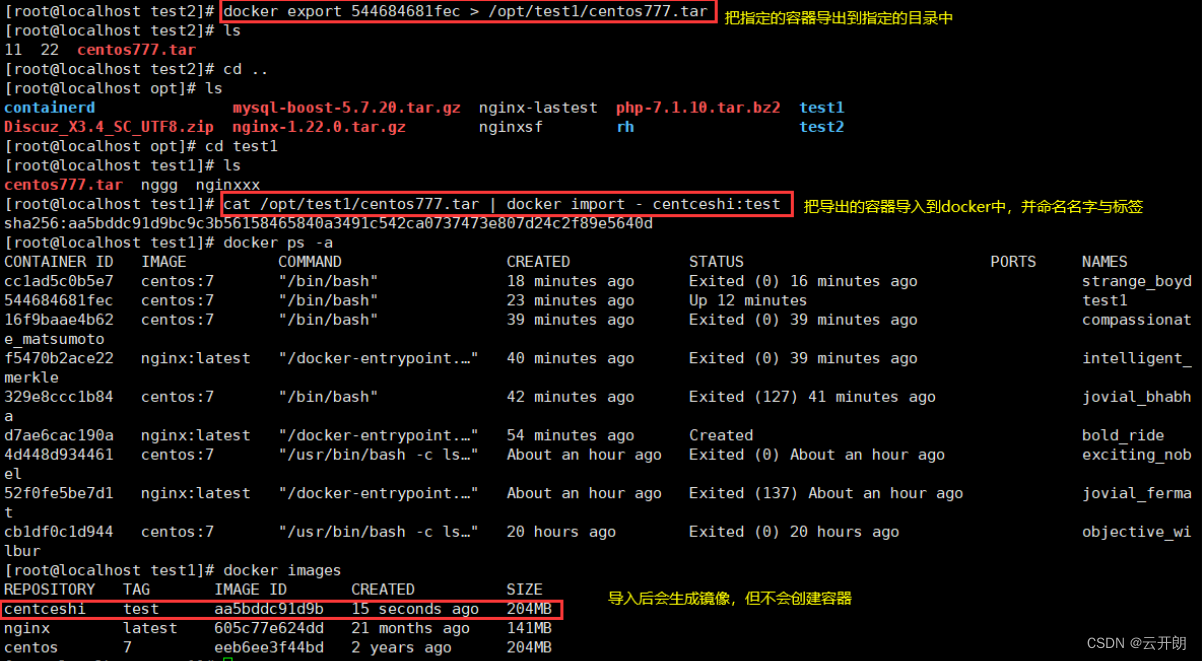
docker 基本操作
一、docker 概述 Docker是一个开源的应用容器引擎,基于go语言开发并遵循了apache2.0协议开源。 Docker是在Linux容器里运行应用的开源工具,是一种轻量级的“虚拟机”。 Docker 的容器技术可以在一台主机上轻松为任何应用创建一个轻量级的、可移植的、自…...

ARM:使用汇编完成三个灯流水亮灭
1.汇编源代码 .text .global _start _start: 设置GPIOF寄存器的时钟使能LDR R0,0X50000A28LDR R1,[R0]ORR R1,R1,#(0x1<<5)STR R1,[R0]设置GPIOE寄存器的时钟使能LDR R0,0X50000A28LDR R1,[R0] 从r0为起始地址的4字节数据取出放在R1ORR R1,R1,#(0x1<<4) 第4位设…...
嵌入式养成计划-33--数据库-sqlite3
七十一、 数据库 71.1 数据库基本概念 数据(Data) 能够输入计算机并能被计算机程序识别和处理的信息集合数据库 (Database)数据库是在数据库管理系统管理和控制之下,存放在存储介质上的数据集合 常用的数据库 大型数…...

什么是大数据运维?大数据运维的职责
大数据运维是指管理、监控和维护大规模数据存储和处理平台的过程。它包含了对数据存储、处理、传输等方面的管理和维护,同时负责确保数据的安全性、可靠性和高效性。 大数据运维的职责包括以下几个方面: 确保大数据平台的高可用性和稳定性,…...

解决方案:AI赋能工业生产3.0,从工业“制造”到“智造”
视频监控技术是一种既成熟又广泛应用于工业制造领域的先进技术。它可以通过安装各种摄像头和传感器来监测整个生产流程,包括原材料的采购、加工、装配和物流等环节,从而实现对生产过程的实时监控和管理,以及对异常事件的及时预警和响应。 在…...

Android KeyStore 秘钥导入
源码参考: https://android.googlesource.com/platform/cts//master/tests/tests/keystore/src/android/keystore/cts/ImportWrappedKeyTest.java 辅助源码参考: https://android.googlesource.com/platform/frameworks/base//master/core/java/android…...

TDengine+OpenVINO+AIxBoard,助力时序数据分类
时间序列数据分析在工业,能源,医疗,交通,金融,零售等多个领域都有广泛应用。其中时间序列数据分类是分析时序数据的常见任务之一。本文将通过一个具体的案例,介绍 Intel 团队如何使用 TDengine 作为基础软件…...

设计模式——16. 迭代器模式
1. 说明 迭代器模式(Iterator Pattern)是一种行为型设计模式,它用于提供一种访问聚合对象(如列表、数组、集合等)元素的统一接口,而不需要了解底层数据结构的具体实现。迭代器模式将遍历聚合对象的操作封装在一个独立的迭代器对象中,这样可以隔离遍历算法和数据结构,使…...
)
【新手实用技能指南】OpenClaw 2.7.1 实用 Skill 技能全推荐(含安装包)
OpenClaw 实用 Skill 技能推荐|办公效率全面提升(新手必开) OpenClaw(小龙虾)的核心优势在于Skill 技能扩展,开启适配技能后,AI 可脱离单纯对话模式,自主完成各类电脑操作任务。本文…...
)
课程第四天(基础)
while 循环语句whilewhile(){}:当小括号条件成立了执行{}里面的东西,条件不成立的时候,循环就结束了格式:while (条件){(执行语句)}do...while格式:do{(执行语句)}while(…...

揭秘macOS独立滚动控制:Scroll Reverser如何巧妙解决输入设备冲突
揭秘macOS独立滚动控制:Scroll Reverser如何巧妙解决输入设备冲突 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经为macOS系统的滚动方向设置感到困扰&…...
)
别再自己编译了!Ubuntu 18.04下用apt一键安装Intel RealSense D435i驱动(附避坑指南)
告别编译烦恼:Ubuntu 18.04下Intel RealSense D435i驱动一键安装全攻略 在计算机视觉和机器人开发领域,Intel RealSense系列深度相机因其出色的性能和相对亲民的价格,成为了许多开发者的首选硬件。然而,对于初次在Linux系统下配置…...

如何轻松搞定浏览器视频下载:3步安装免费插件完全指南
如何轻松搞定浏览器视频下载:3步安装免费插件完全指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法保存网页视频而烦…...

如何3步完成B站视频转文字:开源工具Bili2text完整指南
如何3步完成B站视频转文字:开源工具Bili2text完整指南 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 在信息爆炸的时代,视频内容占据…...
(TODO))
蓝牙学习1(基础知识)(TODO)
https://mp.weixin.qq.com/s/qjKsxuF4TRrH5CWh8TOvzw 蓝牙点灯 1 蓝牙 蓝牙(Bluetooth)是一种短距离无线通信技术,用于在电子设备之间传输数据或建立语音连接。它采用2.4GHz ISM频段(2.402GHz–2.480GHz),…...

移动充电机器人AI边缘计算方案:从感知到精准对接的工程实践
1. 项目概述:当充电桩“活”了过来最近在跟进一个挺有意思的项目,跟几位做智慧园区和社区运营的朋友聊,他们都在头疼同一个问题:新能源车的充电焦虑,已经从“找不到桩”升级到了“桩被占着”。固定充电桩的利用率在高峰…...

连接池失效——高并发下的隐形杀手
连接池失效——高并发下的隐形杀手 系统挂了 现象:用户打开页面,一直转圈。5分钟后,页面报错。 错误日志: org.apache.tomcat.jdbc.pool.PoolExhaustedException: [http-nio-8080-exec-72] Timeout: Pool empty. Unable to fetch …...
)
QClaw 多智能体协同全攻略:总智能体统一调度子智能体(创建 + 调用 + 实操)
摘要 QClaw(腾讯龙虾 AI)自 v0.2.14 起接入Hermes 多智能体框架,支持创建1 个总智能体(主 Agent)+N 个子智能体(专业 Agent),由总智能体统一理解用户意图、拆解任务、调度子智能体执行并汇总结果,实现 “一个入口、分工协作、自动完成” 的复杂工作流。本文详解:是否…...