Python 之 Pandas 生成时间戳范围、Pandas 的时期函数 Period() 和时间序列 - 重采样 resample
文章目录
- 一、生成时间戳范围
- 1. 指定值
- 2. 指定开始日期并设置期间数
- 3. 频率 freq
- 4. closed
- 二、Pandas 的时期函数 Period()
- 三、时间序列 - 重采样 resample
- 在开始之前,我们先导入 numpy 和 pandas 库,同时导入 python 内置的模块。
import pandas as pd
import numpy as np
import time
import datetime
一、生成时间戳范围
- 有时候,我们可能想要生成某个范围内的时间戳。例如,我想要生成 “2018-6-26” 这一天之后的 8 天时间戳,我们可以使用
date_range和bdate_range来完成时间戳范围的生成。 - 我们可以通过 date_range() 返回固定频率的 DatetimeIndex。
- 其语法模板如下:
date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
- 他返回等距时间点的范围(其中任意两个相邻点之间的差值由给定频率指定),以便它们都满足 start <[= ]x <[=] end,其中第一个和最后一个分别为。该范围内的第一个和最后一个时间点位于 freq 的边界(如果以频率字符串的形式给出)或对 freq 有效。
- 其参数含义如下:
- start 表示生成日期的左边界。
- end 表示生成日期的左边界。
- periods 表示要生成的周期数。
- freq 表示频率, default ‘D’ ,频率字符串可以有倍数,例如 ‘5H’。
- tz 表示时区用于返回本地化日期时间索引的时区名称,例如 “Asia/Hong_Kong”。默认情况下,生成的 DatetimeIndex 是时区初始索引。
- normalize: 默认 False, 在生成日期范围之前,将开始/结束日期标准化。
- name:默认 None 设置返回 DatetimeIndex name。
1. 指定值
- 默认是包含开始和结束时间,默认频率使用的 D(天)。
- 示例 1:我们生成从 20210101 到 20210108 之间以天为单位长度的时间戳。
pd.date_range(start='1/1/2021', end='1/08/2021')
#3DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04',
# '2021-01-05', '2021-01-06', '2021-01-07', '2021-01-08'],
# dtype='datetime64[ns]', freq='D')
- 示例 2:我们生成 2010 年到 2011 年之间以天为单位长度的时间戳。
pd.date_range(start='2010', end='2011')
#DatetimeIndex(['2010-01-01', '2010-01-02', '2010-01-03', '2010-01-04',
# '2010-01-05', '2010-01-06', '2010-01-07', '2010-01-08',
# '2010-01-09', '2010-01-10',
# ...
# '2010-12-23', '2010-12-24', '2010-12-25', '2010-12-26',
# '2010-12-27', '2010-12-28', '2010-12-29', '2010-12-30',
# '2010-12-31', '2011-01-01'],
# dtype='datetime64[ns]', length=366, freq='D')
2. 指定开始日期并设置期间数
- 我们也可以指定开始时间和中间经过几天。
pd.date_range(start='1/1/2018', periods=8)
#DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04',
# '2018-01-05', '2018-01-06', '2018-01-07', '2018-01-08'],
# dtype='datetime64[ns]', freq='D')
- 我们也可以指定开始、结束和期间,频率就会自动生成(线性间隔)。
- 例如,我们将开始定为 20180424,结束定为 20180427,期间定为 3,那么他就会自动以一天半为间隔进行时间戳的生成。
pd.date_range(start='2018-04-24', end='2018-04-27', periods=3)
#DatetimeIndex(['2018-04-24 00:00:00', '2018-04-25 12:00:00',
# '2018-04-27 00:00:00'],
# dtype='datetime64[ns]', freq=None)
- 如果我们不定义开始值,只定义结束值和期间,那么他会向前推导时间戳。
pd.date_range(end='2018-04-24', periods=4)
#DatetimeIndex(['2018-04-21', '2018-04-22', '2018-04-23', '2018-04-24'], #dtype='datetime64[ns]', freq='D')
3. 频率 freq
| freq | 描述 |
|---|---|
| Y | 年 |
| M | 月 |
| D | 日(默认) |
| T(MIN) | 分钟 |
| S | 秒 |
| L | 毫秒 |
| U | 微妙 |
| A-DEC | 每年指定月份的最后一个日历日 |
| W-MON | 指定每月的哪个星期开始 |
| WOM_2MON | 指定每个月的第几个星期的星期几开始(这里是第二个星期的星期一) |
| Q-DEC(Q-月) | 指定月为季度末,每个季度末最后一月的最后一个日历日 |
| B,(M,Q,A),S | 分别代表了工作日(以月为频率,以季度为频率,以年为频率),最接近月 |
| B | 工作日 |
- 其中,月和星期的缩写基本是英语的前三个字母大写为准。
- 其中,Q-月只有三种情况:1-4-7-10,2-5-8-11,3-6-9-12。
- 例如,我们可以通过 W-MON,从指定星期一开始算起。
pd.date_range('2022/1/1','2022/2/1', freq = 'W-MON')
#DatetimeIndex(['2022-01-03', '2022-01-10', '2022-01-17', '2022-01-24',
# '2022-01-31'],
# dtype='datetime64[ns]', freq='W-MON')
- 例如,我们可以通过 WOM-2MON,从每月的第二个星期一开始。
pd.date_range('2022/1/1','2022/5/1', freq = 'WOM-2MON')
#DatetimeIndex(['2022-01-10', '2022-02-14', '2022-03-14', '2022-04-11'], #dtype='datetime64[ns]', freq='WOM-2MON')
- 我们可以只返回时间范围内的工作日。
pd.date_range('2022/1/1','2022/1/5', freq = 'B')
#DatetimeIndex(['2022-01-03', '2022-01-04', '2022-01-05'], dtype='datetime64[ns]', freq='B')
- 我们可以以小时为单位长度返回时间戳。
pd.date_range('2022/1/1','2022/1/2', freq = 'H')
- 我们可以以分钟为单位长度返回时间戳。
pd.date_range('2022/1/1 12:00','2022/1/1 12:10', freq = 'T')
- 我们可以以秒、毫秒和微秒为单位长度返回时间戳。
pd.date_range('2022/1/1 12:00:00','2022/1/1 12:00:10', freq = 'S')
pd.date_range('2022/1/1 12:00:00','2022/1/1 12:00:10', freq = 'L')
pd.date_range('2022/1/1 12:00:00','2022/1/1 12:00:10', freq = 'U')
- 我们可以通过 M 返回每月的最后一个日历日。
pd.date_range('2017','2018', freq = 'M')
#DatetimeIndex(['2017-01-31', '2017-02-28', '2017-03-31', '2017-04-30',
# '2017-05-31', '2017-06-30', '2017-07-31', '2017-08-31',
# '2017-09-30', '2017-10-31', '2017-11-30', '2017-12-31'],
# dtype='datetime64[ns]', freq='M')
- 我们可以通过 Q-月,返回每个季度末最后一月的最后一个日历日。
print(pd.date_range('2017','2020', freq = 'Q-DEC'))
#DatetimeIndex(['2017-03-31', '2017-06-30', '2017-09-30', '2017-12-31',
# '2018-03-31', '2018-06-30', '2018-09-30', '2018-12-31',
# '2019-03-31', '2019-06-30', '2019-09-30', '2019-12-31'],
# dtype='datetime64[ns]', freq='Q-DEC')
- 我们可以通过 A-月,返回每年指定月份的最后一个日历日。
print(pd.date_range('2017','2020', freq = 'A-DEC'))
#DatetimeIndex(['2017-12-31', '2018-12-31', '2019-12-31'], dtype='datetime64[ns]', freq='A-#DEC')
- 我们可以通过 BM 返回每的最后一个工作日,BQ-月返回每个季度末最后一月的最后一个工作日,BA-月返回每年指定月份的最后一个工作日。
pd.date_range('2017','2018', freq = 'BM')
pd.date_range('2017','2020', freq = 'BQ-DEC')
pd.date_range('2017','2020', freq = 'BA-DEC')
- 我们可以通过 pd.date_range() 指定时间频率(下面以 7 天,2 小时 30 分钟,2 月为例)。
print(pd.date_range('2017/1/1','2017/2/1', freq = '7D'))
print(pd.date_range('2017/1/1','2017/1/2', freq = '2h30min'))
print(pd.date_range('2017','2018', freq = '2M'))
4. closed
- closed 是觉得我们是否包含 start 值和 end 值,默认情况下是两个值都包含。
- 如果 closed 设置为 left,则表示不包含 end 值。
- 如果 closed 设置为 right,则表示不包含 start 值。
- 我们先生成初始数据,便于后续的观察。
pd.date_range(start='1/1/2021', end='1/08/2021')
#DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04',
# '2021-01-05', '2021-01-06', '2021-01-07', '2021-01-08'],
# dtype='datetime64[ns]', freq='D')
- 我们将 closed 设置为 left。
pd.date_range(start='1/1/2021', end='1/08/2021',closed='left')
#DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04',
# '2021-01-05', '2021-01-06', '2021-01-07'],
# dtype='datetime64[ns]', freq='D')
- 我们将 closed 设置为 right。
pd.date_range(start='1/1/2021', end='1/08/2021',closed='right')
#DatetimeIndex(['2021-01-02', '2021-01-03', '2021-01-04', '2021-01-05',
# '2021-01-06', '2021-01-07', '2021-01-08'],
# dtype='datetime64[ns]', freq='D')
- 我们可以通过
bdate_range(start=None, end=None, periods=None, freq='B')语法返回固定频率的 DatetimeIndex,默认频率为 B(工作日)。
pd.bdate_range(start='2022-01-01', end='2022-02-01')
#DatetimeIndex(['2022-01-03', '2022-01-04', '2022-01-05', '2022-01-06',
# '2022-01-07', '2022-01-10', '2022-01-11', '2022-01-12',
# '2022-01-13', '2022-01-14', '2022-01-17', '2022-01-18',
# '2022-01-19', '2022-01-20', '2022-01-21', '2022-01-24',
# '2022-01-25', '2022-01-26', '2022-01-27', '2022-01-28',
# '2022-01-31', '2022-02-01'],
# dtype='datetime64[ns]', freq='B')
二、Pandas 的时期函数 Period()
- 我们可以直接使用 period() 输出时期,他默认是 A-DEC(每年指定月份的最后一个日历日)。
p = pd.Period('2017')
p
Period('2017', 'A-DEC')
- 也可以对他的频率进行设置。
p = pd.Period('2017-1', freq = 'M')
print(p, type(p))
#2017-01 <class 'pandas._libs.tslibs.period.Period'>
- (1) 可以通过加减整数可以实现对 Period 的移动(默认是以月为单位进行加减)。
print(p + 1)
print(p - 2)
#2017-02
#2016-11
- (2) 如果两个 Period 对象拥有相同频率,则它们的差就是它们之间的单位数量。
p = pd.Period('2017-1', freq = 'M')
print(p, type(p))
pd.Period('2018', freq='M') - p
#2017-01 <class 'pandas._libs.tslibs.period.Period'>
#<12 * MonthEnds>
- (3) period_range 函数可用于创建规则的时期范围。
rng = pd.period_range('2021-1-1', '2021-6-1')
rng
#PeriodIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04',
# '2021-01-05', '2021-01-06', '2021-01-07', '2021-01-08',
# '2021-01-09', '2021-01-10',
# ...
# '2021-05-23', '2021-05-24', '2021-05-25', '2021-05-26',
# '2021-05-27', '2021-05-28', '2021-05-29', '2021-05-30',
# '2021-05-31', '2021-06-01'],
# dtype='period[D]', length=152, freq='D')
- (4) PeriodIndex 类的构造函数允许直接使用一组字符串表示一段时期。
- 这里需要注意的是,我们必须指定 freq。
values = ['200103', '200104', '200105']
index = pd.PeriodIndex(values, freq='M')
index
#PeriodIndex(['2001-03', '2001-04', '2001-05'], dtype='period[M]', freq='M')
- (5) 时期的频率转换 asfreq。
- freq 当中的 A-月表示每年指定月份的最后一个日历日。
p = pd.Period('2021', freq='A-DEC')
p
#Period('2021', 'A-DEC')
- 我们可以使用 asfreq 将时期的频率进行转换 M(月),通过设置 how 的参数为 start 或者 end 决定是起始还是结束。
p.asfreq('M')
#Period('2021-12', 'M')
- 我们将 how 设置为 start,也可写 how = ‘s’。
p.asfreq('M', how="start")
#Period('2021-01', 'M')
- 我们将 how 设置为 end,也可写 how = ‘e’。
p.asfreq('M', how="end")
#Period('2021-12', 'M')
- 也可以将 asfreq 转换为 s(秒)。
p.asfreq('H',how="s")
#Period('2021-01-01 00:00', 'H')
- (6) 对于 PeriodIndex 或 TimeSeries 的频率转换方式相同。
- 示例 1:
rng = pd.period_range('2006', '2009', freq='A-DEC')
rng
#PeriodIndex(['2006', '2007', '2008', '2009'], dtype='period[A-DEC]', freq='A-DEC')
- 示例 2:
ts = pd.Series(np.random.rand(len(rng)), rng)
ts
#2006 0.253270
#2007 0.369844
#2008 0.432757
#2009 0.290279
#Freq: A-DEC, dtype: float64
- 示例 3:
ts.asfreq('M', how='s')
#2006-01 0.253270
#2007-01 0.369844
#2008-01 0.432757
#2009-01 0.290279
#Freq: M, dtype: float64
- 示例 5:对 asfreq 的 how 参数不设置就默认为 end。
ts.asfreq('M')
#2006-12 0.253270
#2007-12 0.369844
#2008-12 0.432757
#2009-12 0.290279
#Freq: M, dtype: float64
- 示例 6:
ts2 = pd.Series(np.random.rand(len(rng)), index = rng.asfreq('D', how = 'start'))
ts2
#2006-01-01 0.906302
#2007-01-01 0.592067
#2008-01-01 0.715987
#2009-01-01 0.382779
#Freq: D, dtype: float64
- (7) 时间戳与时期之间的转换:pd.to_period()、pd.to_timestamp()。
- 我们通过生成一个从 20170101 开始,以月为间隔生成 10 个数据和从 2017 到 2018 以月为间隔的两个初始数据,便于后续的操作观察。
rng = pd.date_range('2017/1/1', periods = 10, freq = 'M')
prng = pd.period_range('2017','2018', freq = 'M')
print(rng)
print(prng)
#DatetimeIndex(['2017-01-31', '2017-02-28', '2017-03-31', '2017-04-30',
# '2017-05-31', '2017-06-30', '2017-07-31', '2017-08-31',
# '2017-09-30', '2017-10-31'],
# dtype='datetime64[ns]', freq='M')
#PeriodIndex(['2017-01', '2017-02', '2017-03', '2017-04', '2017-05', '2017-06',
# '2017-07', '2017-08', '2017-09', '2017-10', '2017-11', '2017-12',
# '2018-01'],
# dtype='period[M]', freq='M')
- 通过随机函数生成与 rng 长度个数相同的数据,并将标签设置为 rng。
ts1 = pd.Series(np.random.rand(len(rng)), index = rng)
ts1
#2017-01-31 0.088059
#2017-02-28 0.894889
#2017-03-31 0.700513
#2017-04-30 0.485417
#2017-05-31 0.868871
#2017-06-30 0.723924
#2017-07-31 0.422115
#2017-08-31 0.225944
#2017-09-30 0.816514
#2017-10-31 0.269220
#Freq: M, dtype: float64
- 我们可以将每月最后一日,转化为每月。to_period()参数为空, 推断每日频率(head 表示读取前五个数据)。
ts1.to_period().head()
#2017-01 0.088059
#2017-02 0.894889
#2017-03 0.700513
#2017-04 0.485417
#2017-05 0.868871
#Freq: M, dtype: float64
- 以和 rng 相同的方式通过随机函数生成 prng,并通过 head 读取他的前五个数据。
ts2 = pd.Series(np.random.rand(len(prng)), index = prng)
print(ts2.head())
#2017-01 0.766327
#2017-02 0.662090
#2017-03 0.653259
#2017-04 0.737125
#2017-05 0.530920
#Freq: M, dtype: float64
- 可以将其转换为时间戳。
print(ts2.to_timestamp().head())
#2017-01-01 0.766327
#2017-02-01 0.662090
#2017-03-01 0.653259
#2017-04-01 0.737125
#2017-05-01 0.530920
#Freq: MS, dtype: float64
三、时间序列 - 重采样 resample
- Pandas 中的 resample 函数,被叫做重新采样,是对原样本重新处理的一个方法,是一个对常规时间序列数据重新采样和频率转换的便捷的方法。
- 他的作用是重新取样时间序列数据。
- 对象必须具有类似 datetime 的索引(DatetimeIndex、PeriodIndex 或 TimedeltaIndex),或将类似 datetime 的值传递给 on 或 level 关键字。
- 其语法模板如下:
DataFrame.resample(rule, closed=None, label=None, level=None)
- 其部分参数含义如下:
- rule 表示目标转换的偏移量字符串或对象。
- closed 表示在降采样时,各时间段的哪一段是闭合的,‘right’ 或 ‘left’,默认‘right’。
- label 表示在降采样时,如何设置聚合值的标签,例如,9:30-9:35会被标记成9:30还是9:35,默认是 9:35。
- 我们可以生成从 20170101 开始的 12 个数,并以他为标签,通过函数生成对应的数据,
rng = pd.date_range('20170101', periods = 12)
ts = pd.Series(np.arange(12), index = rng)
print(ts)
#2017-01-01 0
#2017-01-02 1
#2017-01-03 2
#2017-01-04 3
#2017-01-05 4
#2017-01-06 5
#2017-01-07 6
#2017-01-08 7
#2017-01-09 8
#2017-01-10 9
#2017-01-11 10
#2017-01-12 11
Freq: D, dtype: int32
- 我们将序列下采样到 5 天的数据箱中(以 5 天为时间单位),并将放入数据箱的时间戳的值相加。
ts.resample('5D').sum()
#2017-01-01 10
#2017-01-06 35
#2017-01-11 21
#Freq: 5D, dtype: int32
- 我们就会得到一个新的聚合后的 Series,聚合方式为求和,当然,我们也可以生成其他的聚合方式。
print(ts.resample('5D').mean(),'→ 求平均值\n')
print(ts.resample('5D').max(),'→ 求最大值\n')
print(ts.resample('5D').min(),'→ 求最小值\n')
print(ts.resample('5D').median(),'→ 求中值\n')
print(ts.resample('5D').first(),'→ 返回第一个值\n')
print(ts.resample('5D').last(),'→ 返回最后一个值\n')
print(ts.resample('5D').ohlc(),'→ OHLC重采样\n')
- 知识点补充:
- OHLC 是金融领域的时间序列聚合方式,包括 open开盘、high 最大值、low 最小值、close 收盘。
- closed 表示各时间段哪一端是闭合(即包含)的,默认是右端闭合。
- 详解:这里 values 为 0-11,按照 5D 重采样,可以分为以下三类 [1,2,3,4,5],[6,7,8,9,10],[11,12]。
- left 表示指定间隔左边为结束,就是 [1,2,3,4,5],[6,7,8,9,10],[11,12]。
- right 表示指定间隔右边为结束,就是 [1],[2,3,4,5,6],[7,8,9,10,11],[12]。
- 我们将系列降采样到 5 天的箱中,但关闭箱间隔的左侧。
print(ts.resample('5D', closed = 'left').sum(), '→ left\n')
#2006-01-01 0.25327
#2006-01-06 NaN
#2006-01-11 NaN
#2006-01-16 NaN
#2006-01-21 NaN
# ...
#2009-12-11 NaN
#2009-12-16 NaN
#2009-12-21 NaN
#2009-12-26 NaN
#2009-12-31 NaN
#Freq: 5D, Length: 293, dtype: float64 → left
- 我们将系列降采样到 5 天的箱中,但关闭箱间隔的右侧。
print(ts.resample('5D', closed = 'right').sum(), '→ right\n')
#2005-12-27 NaN
#2006-01-01 0.25327
#2006-01-06 NaN
#2006-01-11 NaN
#2006-01-16 NaN
# ...
#2009-12-06 NaN
#2009-12-11 NaN
#2009-12-16 NaN
#2009-12-21 NaN
#2009-12-26 NaN
#Freq: 5D, Length: 293, dtype: float64 → right
相关文章:
 和时间序列 - 重采样 resample)
Python 之 Pandas 生成时间戳范围、Pandas 的时期函数 Period() 和时间序列 - 重采样 resample
文章目录一、生成时间戳范围1. 指定值2. 指定开始日期并设置期间数3. 频率 freq4. closed二、Pandas 的时期函数 Period()三、时间序列 - 重采样 resample在开始之前,我们先导入 numpy 和 pandas 库,同时导入 python 内置的模块。 import pandas as pd…...
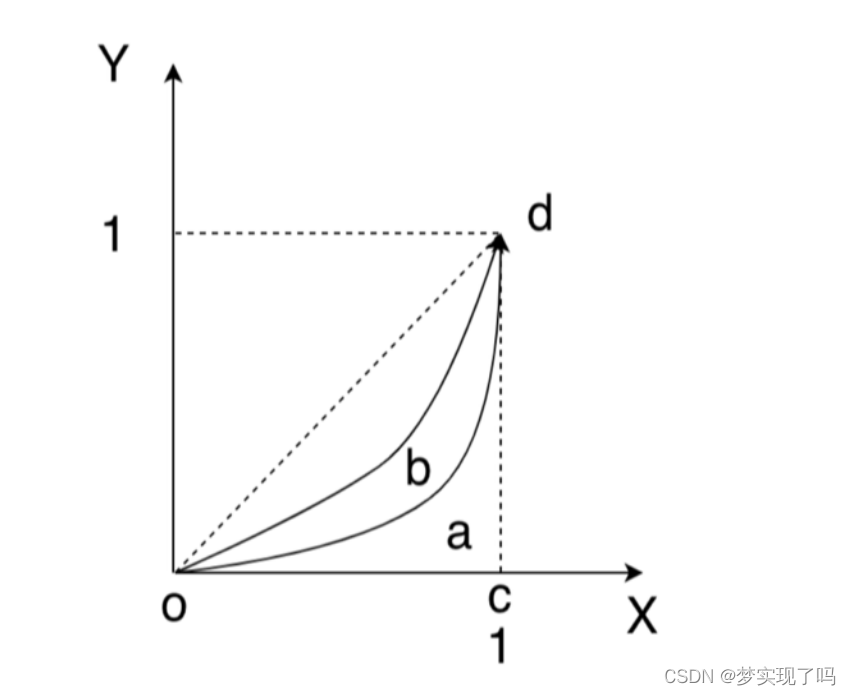
利用Python和Sprak求曲线与X轴上方的面积
有n组标本(1, 2, 3, 4), 每组由m个( , , ...)元素( , )组成(m值不定), . 各组样本的分布 曲线如下图所示. 通过程序近似实现各曲线与oc, cd直线围成的⾯积. 思路 可以将图像分成若干个梯形,每个梯形的底边长为(Xn1 - Xn-1),面积为矩形的一半,…...

利用机器学习(mediapipe),进行人手的21个3D手关节坐标检测
感知手的形状和动作的能力可能是在各种技术领域和平台上改善用户体验的重要组成部分。例如,它可以构成手语理解和手势控制的基础,并且还可以在增强现实中将数字内容和信息覆盖在物理世界之上。虽然自然而然地出现在人们手中,但是强大的实时手感知力无疑是一项具有挑战性的计…...
【添砖java】谁说编程第一步是hello world
编程第一步明明是下载编译器和配置环境(小声逼逼)。 Windows下的java环境安装: java的安装包分为两类,一类是JRE(Java Runtime Environmental),是一个独立的java运行环境;一类是JDK…...
el-table大数据量渲染卡顿问题
1、场景描述 在项目开发中,遇到在表格中一次性加载完的需求,且加载数量不少,有几百几千条,并且每条都可能有自己的下拉框,输入框来做编辑功能,此时普通的el-table肯定会导致浏览器卡死,那么怎么…...

MyBatis-Plus 实现分页的几种写法
简介MyBatis-Plus (opens new window)(简称 MP)是一个 MyBatis (opens new window)的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。快速开始添加依赖全新的 MyBatis-Plus 3.0 版本基于 JDK8ÿ…...

记一次Binder内存不足导致的应用被杀
每个进程的可用Binder内存大小是 1M-8KB 也就是900多KB 事情的起因的QA压测过程发生进程号变更,怀疑APP被杀掉过,于是开始看日志(实际后来模拟的时候可以发现app确实被杀掉了) APP的压测平台会上报进程号变更时间点,发…...

Zabbix4.0架构理解-zabbix的工作方式
目录 1.1、zabbix4.0架构图 1.2、zabbix的进程 1、 zabbix server 2、zabbix agent 3、 zabbix proxy 4、 java gateway 5、zabbix get 1.3、zabbix的几种工作方式 1、通过zabbix agent 2、通过zabbix proxy 3、通过 zabbix java gateway 4、其他 1.3、zabbix 数据走…...
MySQL中的一些非常实用的函数、语法
前言我最近几年用MYSQL数据库挺多的,发现了一些非常有用的小玩意,今天拿出来分享到大家,希望对你会有所帮助。1.group_concat在我们平常的工作中,使用group by进行分组的场景,是非常多的。比如想统计出用户表中&#x…...
RT-Thread移植到STM32F407
文章目录第一步:获取RT-Thread源码第二步:项目结构介绍第三步:拷贝示例代码到裸机工程第四步:删除无用文件第五步:修改工程目录结构第六步:添加工程文件路径第七步:编译第八步:修改配…...

VR全景到底有多全能?为何屡受关注?
告别两年的“冰封”时期,现在疫情放开已经有一段时间了,各个行业的市场和经济已经逐步回暖,但是疫情对广大群众造成的心理阴影还是迟迟未有退散。就拿去电影院看电影来说,以前看电影是看心情,现在看电影则是看环境&…...

剑指 Offer 30. 包含min函数的栈
摘要 剑指 Offer 30. 包含min函数的栈 一、栈解析 package Stock;import java.util.Stack;/*** Classname JZ30min函数栈* Description TODO* Date 2023/2/24 18:59* Created by xjl*/ public class JZ30min函数栈 {/*** description 最小栈的含义是每次从栈中获取的数据都是…...
stm32f407探索者开发板(二十二)——通用定时器基本原理讲解
文章目录一、三种定时器的区别二、通用定时器特点2.1 功能特点描述2.2 计数器模式三、通用定时器工作过程四、附一、三种定时器的区别 STM32F40x系列总共最多有14个定时器 三种(4)STM32定时器区别 二、通用定时器特点 2.1 功能特点描述 STM3 F4的通…...

cmake 入门三 常用变量和指令
cmake常用变量 一、cmake 变量引用的方式: 前面我们已经提到了,使用${}进行变量的引用。在IF 等语句中,是直接使用变量名而不通过${}取值 二,cmake 自定义变量的方式: 主要有隐式定义和显式定义两种,一…...

Linux基础命令-find搜索文件位置
文章目录 find 命令介绍 语法格式 命令基本参数 参考实例 1)在root/data目录下搜索*.txt的文件名 2)搜索一天以内最后修改时间的文件;并将文件删除 3)搜索777权限的文件 4)搜索一天之前变动的文件复制到test…...
获取浏览器硬件资源的媒体数据(拍照、录音、录频、屏幕共享)
目录一、window.navigator 对象包含有关访问者浏览器的信息取二、MediaDevices1.使用麦克风2.使用摄像头(和音频一样)3.拍照4.录屏三、MediaRecorder(录制,可录制音频视屏)一、window.navigator 对象包含有关访问者浏览器的信息取 <!DOCTYPE html>…...

Java入门教程||Java 日期时间||Java 正则表达式
Java 日期时间java.util包提供了Date类来封装当前的日期和时间。Date类提供两个构造函数来实例化Date对象。第一个构造函数使用当前日期和时间来初始化对象。Date( )第二个构造函数接收一个参数,该参数是从1970年1月1日起的毫秒数。Date(long millisec)Date对象创建…...

详解八大排序算法
文章目录前言排序算法插入排序直接插入排序:希尔排序(缩小增量排序)选择排序直接选择排序堆排序交换排序冒泡排序快速排序hoare版本挖坑法前后指针版本快速排序的非递归快速排序总结归并排序归并排序的非递归实现:计数排序排序算法复杂度及稳定性分析总结前言 本篇…...

python库streamlit学习笔记
什么是streamlit? Streamlit是一个免费的开源框架,用于快速构建和共享漂亮的机器学习和数据科学Web应用程序。它是一个基于Python的库,专为机器学习工程师设计。数据科学家或机器学习工程师不是网络开发人员,他们对花几周时间学习…...
C/C++开发,无可避免的内存管理(篇一)-约束好跳脱的内存
一、养成内存管理好习惯 1.1 养成动态对象创建、调用及释放好习惯 开发者手动接管内存分配时,必须处理这两个任务。分配原始内存时,必须在该内存中构造对象;在释放该内存之前,必须保证适当地撤销这些对象。如果你的项目是c项目&am…...

7z2john报错Compress::Raw::Lzma.pm缺失的原理与修复
1. 这不是你的错:当7z2john突然报错“Cant locate Compress::Raw::Lzma.pm”时,你其实只缺一个Perl模块刚打开终端准备提取7z压缩包里的密码哈希,7z2john archive.7z > hash.txt回车一敲,屏幕却猛地跳出一行红字:Ca…...

Windows右键菜单终极清理指南:用ContextMenuManager告别杂乱,重获高效桌面
Windows右键菜单终极清理指南:用ContextMenuManager告别杂乱,重获高效桌面 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 还在为Windows…...
)
AI大神吴恩达力荐,轻松入门大语言模型实战(附中文PDF+代码)
这本书由AI科普大神Jay Alammar与BERTopic算法作者Maarten Grootendorst联合撰写,是O’Reilly出版的LLM入门标杆指南,获吴恩达推荐。全书以图解方式讲解LLM原理、提示工程、文本分类生成、多模态应用及优化技术,分为理解原理、应用及优化三部…...

电玩城新政解读:价格趋势与消费避坑指南
行业现状:一场新规带来的市场洗牌最近,不少玩家发现,常去的那家电玩城变了——以前一块钱两个币,现在一块钱一个币,机器游戏规则也悄悄调整了。这背后,是2024年以来多地密集出台电玩城管理新规带来的连锁反…...

3000+戴森球计划工厂蓝图终极指南:从新手到大师的完全解决方案
3000戴森球计划工厂蓝图终极指南:从新手到大师的完全解决方案 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints 还在为戴森球计划中复杂的工厂布局而头疼吗&#…...

泉盛UV-K5/K6对讲机专业级固件定制与功能扩展指南
泉盛UV-K5/K6对讲机专业级固件定制与功能扩展指南 【免费下载链接】uv-k5-firmware-custom 全功能泉盛UV-K5/K6固件 Quansheng UV-K5/K6 Firmware 项目地址: https://gitcode.com/gh_mirrors/uvk5f/uv-k5-firmware-custom 泉盛UV-K5/K6对讲机LOSEHU固件是一款基于多个开…...

Arm开发中DSTREAM调试探针无法识别的排查指南
1. DSTREAM调试探针在Arm开发环境中不可选的排查指南当使用Arm Development Studio(Arm DS)进行嵌入式开发时,DSTREAM系列调试探针(包括DSTREAM-ST、DSTREAM-PT、DSTREAM-HT和DSTREAM-XT)偶尔会出现无法在开发环境中被…...

Topit:终极免费macOS窗口置顶工具,让工作效率飙升300%
Topit:终极免费macOS窗口置顶工具,让工作效率飙升300% 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否经常在macOS上同时处理多个…...

Claude Desktop Debian版开源协议解析:MIT与Apache 2.0双许可完全指南
Claude Desktop Debian版开源协议解析:MIT与Apache 2.0双许可完全指南 【免费下载链接】claude-desktop-debian Claude Desktop for Linux 项目地址: https://gitcode.com/GitHub_Trending/cl/claude-desktop-debian Claude Desktop Debian版是一款为Linux系…...

【国家级边缘AI项目总架构师内部复盘】:为什么92%的AI Agent边缘化失败?4个被忽视的实时性阈值与硬件协同校准公式
更多请点击: https://codechina.net 第一章:【国家级边缘AI项目总架构师内部复盘】:为什么92%的AI Agent边缘化失败?4个被忽视的实时性阈值与硬件协同校准公式 在2023–2024年覆盖17个省级工业物联网节点的国家级边缘AI落地验证中…...