python库streamlit学习笔记
什么是streamlit?
Streamlit是一个免费的开源框架,用于快速构建和共享漂亮的机器学习和数据科学Web应用程序。它是一个基于Python的库,专为机器学习工程师设计。数据科学家或机器学习工程师不是网络开发人员,他们对花几周时间学习使用这些框架来构建网络应用程序不感兴趣。相反,他们需要一个更容易学习和使用的工具,只要它可以显示数据并收集建模所需的参数。Streamlit允许您仅用几行代码创建一个外观惊艳的应用程序。
数据科学家为何要使用Streamlit?
Streamlit最大的好处是,您甚至不需要了解Web开发的基础知识就可以开始或创建您的第一个Web应用程序。因此,如果你是一个对数据科学感兴趣的人,你想轻松、快速地部署你的模型,并且只需要几行代码,Streamlit是一个很好的选择。
使应用程序成功的一个重要方面是提供有效和直观的用户界面。许多现代的数据密集型应用程序都面临着快速构建有效用户界面的挑战,而无需采取复杂的步骤。Streamlit是一个很有前途的开源Python库,它使开发人员能够立即构建有吸引力的用户界面。
Streamlit是最简单的方法,尤其是对于没有前端知识的人来说,可以将他们的代码放到Web应用程序中:
- 没有前端(html,js,css)的经验或知识是必需的。
- 你不需要花费几天或几个月的时间来创建一个Web应用,你可以在几个小时甚至几分钟内创建一个非常漂亮的机器学习或数据科学应用。
- 它兼容大多数Python库(例如panda、matplotlib、seaborn、plotly、Keras、PyTorch、SymPy(latex))。
- 创建令人惊叹的Web应用程序需要更少的代码。
- 数据缓存简化并加速了计算。
如何使用Streamlit
在Windows上:
1.安装Anaconda并创建您的环境
2. 打开终端

在终端中键入以下命令以安装Streamlit:
pip install streamlit
测试安装是否正常:
streamlit hello

当您在终端中键入此命令时,应自动打开以下页面:

如何运行Streamlit代码
streamlit run file_name.py

精简命令易于编写和理解。只需一个简单的命令,您就可以显示文本、媒体、小部件、图形等。
使用Streamlit显示文本
首先,我们将了解如何向Streamlit应用添加文本,以及添加文本时使用的不同命令。
st.write():该函数用于向Web应用程序添加任何内容,从格式化字符串到matplotlib图中的图表、Altair图、plotly图、数据框、Keras模型等。
import streamlit as st
st.write("Hello ,let's learn how to build a streamlit app together")

st.title():此函数允许您添加应用程序的标题。st.header():此函数用于设置节的标题。st.markdown():该函数用于设置某个部分的降价。st.subheader():该函数用于设置一个小节的子标题。st.caption():该函数用于编写字幕。st.code():该函数用于设置代码。st.latex():该函数用于显示LaTeX格式的数学表达式。
st.title ("this is the app title")
st.header("this is the markdown")
st.markdown("this is the header")
st.subheader("this is the subheader")
st.caption("this is the caption")
st.code("x=2021")
st.latex(r''' a+a r^1+a r^2+a r^3 ''')

使用Streamlit显示图像、视频或音频文件
您无法找到像Streamlit功能那样简单的功能来显示图像、视频和音频文件。让我们来看看如何显示媒体与Streamlit!
st.image():该函数用于显示图像。st.audio ():此函数用于显示音频。st.video ():此函数用于显示视频。
st.image("kid.jpg")
st.audio("Audio.mp3")
st.video("video.mp4")

输入部件
小部件是最重要的用户界面组件。Streamlit有各种各样的小部件,可以让你通过按钮、滑块、文本输入等直接将交互性融入到你的应用程序中。
st.checkbox():该函数返回一个布尔值。选中该框时,返回True值,否则返回False值。st.button():该函数用于显示按钮控件。st.radio ():此函数用于显示单选按钮小部件。st.selectbox():该函数用于显示一个选择小部件。st.multiselect():该函数用于显示多选小部件。st.select _slider():此函数用于显示选择滑块小部件。st.slider():该函数用于显示滑块小部件。
st.checkbox('yes')
st.button('Click')
st.radio('Pick your gender',['Male','Female'])
st.selectbox('Pick your gender',['Male','Female'])
st.multiselect('choose a planet',['Jupiter', 'Mars', 'neptune'])
st.select_slider('Pick a mark', ['Bad', 'Good', 'Excellent'])
st.slider('Pick a number', 0,50)

st.number_input():此函数用于显示一个数字输入小部件。st.text_input():这个函数用于显示文本输入小部件。st.date _input():此函数用于显示一个日期输入小部件以选择日期。st.time_input():此函数用于显示时间输入小部件,以选择时间。st.text_area():这个函数用于显示一个文本输入小部件,其中包含多行文本。st.file_uploader():此函数用于显示一个文件上载器小部件。st.color_picker():该函数用于显示颜色选择器小部件以选择颜色。
st.number_input('Pick a number', 0,10)
st.text_input('Email address')
st.date_input('Travelling date')
st.time_input('School time')
st.text_area('Description')
st.file_uploader('Upload a photo')
st.color_picker('Choose your favorite color')

使用Streamlit显示进度和状态
现在,我们将了解如何向应用程序添加进度条和状态消息,例如错误和成功。
st.balloons():此函数用于显示庆祝用的气球。st.progress():该函数用于显示进度条。st.spinner():该函数用于显示执行过程中的临时等待消息。
st.balloons()
st.progress(10)
with st.spinner('Wait for it...'): time.sleep(10)

st.success():该函数用于显示成功消息。st.error():该函数用于显示错误消息。st.warnig():该函数用于显示警告消息。st.info ():此函数用于显示信息性消息。st.exception():该函数用于显示异常消息。
st.success("You did it !")
st.error("Error")
st.warnig("Warning")
st.info("It's easy to build a streamlit app")
st.exception(RuntimeError("RuntimeError exception"))

边栏和容器
您还可以在页面上创建侧栏或容器来组织应用。应用上页面的层次结构和排列方式会对用户体验产生很大影响。通过组织您的内容,您可以让访问者了解和浏览您的网站,这有助于他们找到他们正在寻找的东西,并增加他们将来返回的可能性。
边栏
将元素传递给st.sidebar()会使该元素固定在左侧,从而允许用户关注应用中的内容。
但是 st.spinner()和st.echo()不受st.sidebar支持。
如您所见,您可以在应用界面中创建一个侧边栏,并在其中放置元素,这将使您的应用更有条理、更易于理解。

容器
st.container()用于创建一个不可见的容器,您可以在其中放置元素,以便创建有用的排列和层次结构。

Streamlit用于显示图形
数据可视化通过将数据整理成更易于理解的格式、突出显示趋势和异常值来帮助讲述故事。一个好的可视化可以讲述一个故事,消除数据中的噪音并突出有用的信息。然而,这并不像修饰图表使其看起来更好或在信息图表的“信息”部分打个耳光那么简单。有效的数据可视化是形式和功能之间的微妙平衡。最简单的图表可能太过枯燥,无法吸引注意力或传达有力的信息,而最令人惊叹的可视化可能完全无法传达正确的信息。数据和视觉效果需要协同工作,将出色的分析和出色的故事讲述结合起来是一门艺术。
你认为在一个表/数据库文件中给你一百万个点的数据,并要求你仅仅通过查看该表中的数据来提供你的推断是可行的吗?除非你是超人,否则不可能。这就是我们利用数据可视化的时候–它通过地图或图表提供信息的可视环境,让我们清楚地了解信息的含义。这就是Streamlit可视化的强大功能。
st.pyplot():该函数用于显示matplotlib.pyplot图形。
import streamlit as st
import matplotlib.pyplot as plt
import numpy as np
rand=np.random.normal(1, 2, size=20)
fig, ax = plt.subplots()
ax.hist(rand, bins=15)
st.pyplot(fig)

st.line_chart():该函数用于显示折线图。
import streamlit as st
import pandas as pd
import numpy as np
df= pd.DataFrame(np.random.randn(10, 2),columns=['x', 'y'])
st.line_chart(df)

st.bar _chart():此函数用于显示条形图。
import streamlit as st
import pandas as pd
import numpy as np
df= pd.DataFrame(np.random.randn(10, 2),columns=['x', 'y'])
st.bar_chart(df)

st.area_chart():该函数用于显示面积图。
import streamlit as st
import pandas as pd
import numpy as np
df= pd.DataFrame(np.random.randn(10, 2),columns=['x', 'y'])
st.area_chart(df)

st.altair_chart():该函数用于显示一个牛郎星图表。
import streamlit as st
import numpy as np
import pandas as pd
import altair as alt
df = pd.DataFrame(np.random.randn(500, 3), columns=['x','y','z'])
c = alt.Chart(df).mark_circle().encode(x='x', 'y'=y , size='z', color='z', tooltip=['x', 'y', 'z'])
st.altair_chart(c, use_container_width=True)

st.graphviz_chart():该函数用于显示图形对象,可以使用不同的节点和边来完成。
import streamlit as st
import graphviz as graphviz
st.graphviz_chart('''digraph { Big_shark -> Tuna Tuna -> Mackerel Mackerel -> Small_fishes Small_fishes -> Shrimp }''')

使用Streamlit显示地图
st.map ():此函数用于在应用中显示地图,但需要纬度和经度的值,这些值不应为null/NA。
import pandas as pd
import numpy as np
import streamlit as st
df = pd.DataFrame(np.random.randn(500, 2) / [50, 50] + [37.76, -122.4],columns=['lat', 'lon'])
st.map(df)

构建机器学习应用程序
在本节中,我将带你完成一个关于贷款预测的项目。
贷款的主要利润直接来自贷款利息。贷款公司在经过密集的核实和确认程序后发放贷款。然而,他们仍然没有保证,如果申请人能够偿还贷款没有困难。在本教程中,我们将构建一个预测模型(随机森林分类器)来预测申请人的贷款状态。我们的使命是准备一个Web应用程序,使其在生产中可用。
从导入应用所需的库开始:
import streamlit as st
import pandas as pd
import numpy as np
import pickle #to load a saved modelimport base64 #to open .gif files in streamlit app
在此应用程序中,我们将使用多个小部件作为滑块:侧边栏菜单中的selectbox和radio,我们将为此准备一些Python函数。这个例子将是一个简单的演示,有两页。在主页上,它将显示我们选择的数据,而Exploration页面将允许您在图中可视化变量,Prediction页面将包含带有一个名为Predict的按钮的变量,该按钮将允许您估计贷款状态。下面的代码在侧边栏中提供了一个selectbox,允许您选择页面。数据被缓存,因此不需要不断地重新加载。
@st.cache是一种缓存机制,可让您的应用在从Web加载数据、操作大型数据集或执行高成本计算时保持高性能。
@st.cache(suppress_st_warning=True)
def get_fvalue(val): feature_dict = {"No":1,"Yes":2} for key,value in feature_dict.items(): if val == key: return value
def get_value(val,my_dict): for key,value in my_dict.items(): if val == key: return value
app_mode = st.sidebar.selectbox('Select Page',['Home','Prediction']) #two pages

在主页中,我们将可视化:申请人收入和贷款金额的展示图片/数据集/直方图。
注意:我们将使用if/elif/else在页面之间切换。
我们将以变量数据的形式加载loan_dataset.csv,这样我们就可以在主页中显示其中的几行。
if app_mode=='Home': st.title('LOAN PREDICTION :') st.image('loan_image.jpg') st.markdown('Dataset :') data=pd.read_csv('loan_dataset.csv') st.write(data.head()) st.markdown('Applicant Income VS Loan Amount ') st.bar_chart(data[['ApplicantIncome','LoanAmount']].head(20))

然后在“预测”页中:
elif app_mode == 'Prediction': st.image('slider-short-3.jpg') st.subheader('Sir/Mme , YOU need to fill all necessary informations in order to get a reply to your loan request !') st.sidebar.header("Informations about the client :") gender_dict = {"Male":1,"Female":2} feature_dict = {"No":1,"Yes":2} edu={'Graduate':1,'Not Graduate':2} prop={'Rural':1,'Urban':2,'Semiurban':3} ApplicantIncome=st.sidebar.slider('ApplicantIncome',0,10000,0,) CoapplicantIncome=st.sidebar.slider('CoapplicantIncome',0,10000,0,) LoanAmount=st.sidebar.slider('LoanAmount in K$',9.0,700.0,200.0) Loan_Amount_Term=st.sidebar.selectbox('Loan_Amount_Term',(12.0,36.0,60.0,84.0,120.0,180.0,240.0,300.0,360.0)) Credit_History=st.sidebar.radio('Credit_History',(0.0,1.0)) Gender=st.sidebar.radio('Gender',tuple(gender_dict.keys())) Married=st.sidebar.radio('Married',tuple(feature_dict.keys())) Self_Employed=st.sidebar.radio('Self Employed',tuple(feature_dict.keys())) Dependents=st.sidebar.radio('Dependents',options=['0','1' , '2' , '3+']) Education=st.sidebar.radio('Education',tuple(edu.keys())) Property_Area=st.sidebar.radio('Property_Area',tuple(prop.keys())) class_0 , class_3 , class_1,class_2 = 0,0,0,0 if Dependents == '0': class_0 = 1 elif Dependents == '1': class_1 = 1 elif Dependents == '2' : class_2 = 1 else: class_3= 1 Rural,Urban,Semiurban=0,0,0 if Property_Area == 'Urban' : Urban = 1 elif Property_Area == 'Semiurban' : Semiurban = 1 else : Rural=1
我们编写了两个函数 获取值(val,my_dict) 以及 获取f值(val) 和字典 特征_字典 操纵 st.sidebar.radio ()带有非数值变量。这是可选的,你可以很容易地做这样的事情:
注意:机器学习算法无法处理分类变量。在数据集中,我做了一些特征工程。例如,Married列有两个变量“Yes”和“No”,我做了一个标签编码(看一看就能更好地理解),所以“NO”将等于1,“Yes”将等于2。函数get_fvalue(val)将根据客户端的选择轻松返回值(1/2)。函数get_value(val,my_dict)也是如此。这两个函数之间的区别在于,第一个函数适用于yes/no特征,而第二个函数适用于具有多个变量的一般情况(例如:性别)。
正如我们所看到的,变量Dependents有四个类别’0’,’ 1’,‘2’和’3+’,我们不能将这样的东西转换为一个数值变量,我们有’+3’,这意味着Dependents可以采取3,4,5 …我们做了一个One Hot Enconding(看一下就能更好地理解)因此,我们创建了一个包含四个元素的侧边栏单选框,每个元素都有一个二进制变量,如果客户端选择’0’,则class_0将等于1,其他元素将等于0。

我们还为Property_Area做了一个热编码,这就是为什么我们创建了3个变量(农村、城市、半城市),当农村取1时,其他变量将等于0。

所以我们已经看到了这两个-当我们标签或一个热编码我们的功能,以及如何处理它,以成功地创建一个工作的Streamlit应用程序。
data1={'Gender':Gender,'Married':Married,'Dependents':[class_0,class_1,class_2,class_3],'Education':Education,'ApplicantIncome':ApplicantIncome,'CoapplicantIncome':CoapplicantIncome,'Self Employed':Self_Employed,'LoanAmount':LoanAmount,'Loan_Amount_Term':Loan_Amount_Term,'Credit_History':Credit_History,'Property_Area':[Rural,Urban,Semiurban],} feature_list=[ApplicantIncome,CoapplicantIncome,LoanAmount,Loan_Amount_Term,Credit_History,get_value(Gender,gender_dict),get_fvalue(Married),data1['Dependents'][0],data1['Dependents'][1],data1['Dependents'][2],data1['Dependents'][3],get_value(Education,edu),get_fvalue(Self_Employed),data1['Property_Area'][0],data1['Property_Area'][1],data1['Property_Area'][2]] single_sample = np.array(feature_list).reshape(1,-1)
现在我们将变量存储在字典中,因为我们写了 获取值(val,my_dict) 以及 获取f值(val)来对付字典。之后,输入(客户端将在Streamlit应用程序中选择作为输入的内容)将排列在名为 特征列表 然后传递给一个名为 单样本。
注:要素的输入必须按照与数据集列相同的顺序排列(例如 已婚 不能接受…的输入 性别问题).
if st.button("Predict"): file_ = open("6m-rain.gif", "rb") contents = file_.read() data_url = base64.b64encode(contents).decode("utf-8") file_.close() file = open("green-cola-no.gif", "rb") contents = file.read() data_url_no = base64.b64encode(contents).decode("utf-8") file.close() loaded_model = pickle.load(open('Random_Forest.sav', 'rb')) prediction = loaded_model.predict(single_sample) if prediction[0] == 0 : st.error('According to our Calculations, you will not get the loan from Bank') st.markdown(f'<img src="data:image/gif;base64,{data_url_no}" alt="cat gif">',unsafe_allow_html=True,) elif prediction[0] == 1 : st.success('Congratulations!! you will get the loan from Bank') st.markdown(f'<img src="data:image/gif;base64,{data_url}" alt="cat gif">',unsafe_allow_html=True,)
最后,我们将在中加载保存的RandomForestClassifier模型 加载_模型 和它的预测,它是0或1(分类问题)在 预测。.gif文件将存储在 锉 以及 文件–。取决于的值 预测,我们将有两种情况,“成功”或“失败”,从银行获得贷款。
这是我们的预测页面:

相关文章:
python库streamlit学习笔记
什么是streamlit? Streamlit是一个免费的开源框架,用于快速构建和共享漂亮的机器学习和数据科学Web应用程序。它是一个基于Python的库,专为机器学习工程师设计。数据科学家或机器学习工程师不是网络开发人员,他们对花几周时间学习…...
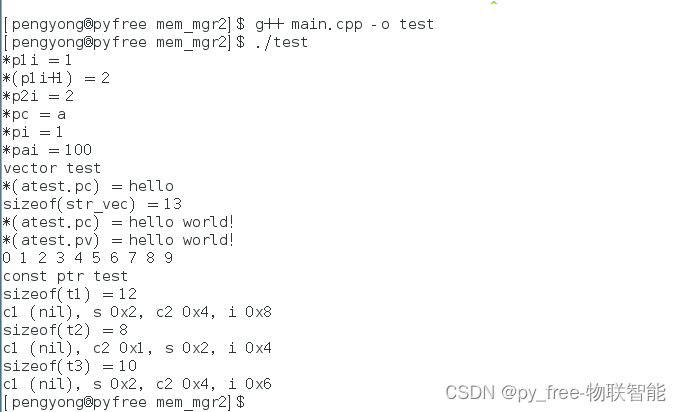
C/C++开发,无可避免的内存管理(篇一)-约束好跳脱的内存
一、养成内存管理好习惯 1.1 养成动态对象创建、调用及释放好习惯 开发者手动接管内存分配时,必须处理这两个任务。分配原始内存时,必须在该内存中构造对象;在释放该内存之前,必须保证适当地撤销这些对象。如果你的项目是c项目&am…...

在React项目中引入字体文件并使用
一、背景 设计稿里某些文字所用的字体,系统默认不支持。 比如设计需要的这个字体:EmerlandRegular,即使在css里将文字字体设置为他们,实际效果也显示不出来。 二、现象及原因 1、样式 2、期待效果 3、实际效果 实际上是因为这个…...
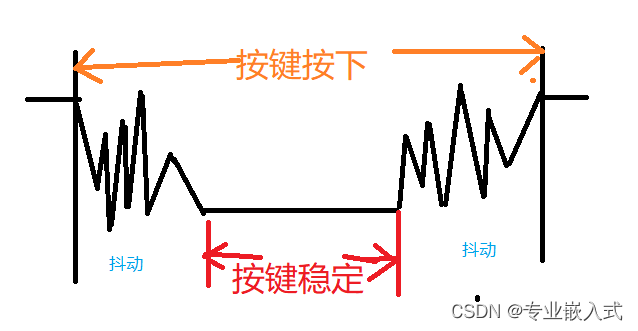
STM32 CubeMX按键点灯
本文代码使用 HAL 库。 文章目录前言一、按键原理图二、CubeMX 创建工程三、代码讲解:1. GPIO的输入HAL库函数:2. 消抖:3. 详细代码四,实验现象:总结前言 我们继续讲解 stm32 f103,这篇文章将详细 为大家讲…...

2023链动2+1模式到底是什么?带你了解核心规则
2023链动21模式到底是什么?带你了解核心规则 2023-02-24 梦龙 大家好,我是你们熟悉而又陌生的好朋友梦龙,一个创业期的年轻人 传统的直销模式产品低价高卖,消费者难以接受。虽然直销省去了传统流通渠道的中间环节,但…...

【Java面试八股文宝典之基础篇】备战2023 查缺补漏 你越早准备 越早成功!!!——Day14
大家好,我是陶然同学,软件工程大三今年实习。认识我的朋友们知道,我是科班出身,学的还行,但是对面试掌握不够,所以我将用这100多天更新Java面试题🙃🙃。 不敢苟同,相信大…...

K8S篇-搭建kubenetes集群
安装环境 这里使用pve虚拟机搭建三台centos机器,搭建过程参考: Centos篇-Centos Minimal安装 此次安装硬件配置 CPU:2C 内存:2G 存储:64G 环境说明 操作系统:Centos 7.9 内核版本:6.2.0-1.el7.elrepo…...
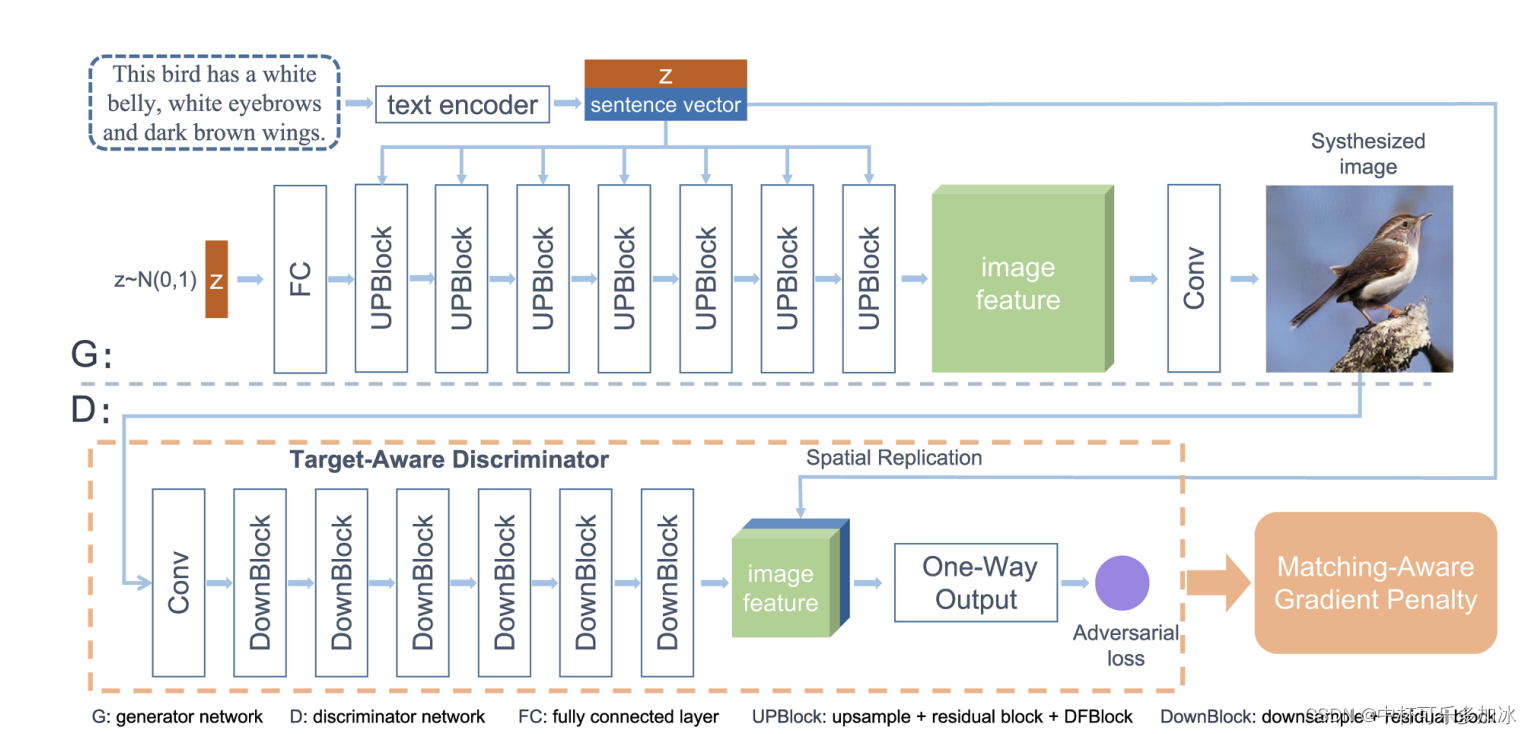
文本生成图像简述4——扩散模型、自回归模型、生成对抗网络的对比调研
基于近年来图像处理和语言理解方面的技术突破,融合图像和文本处理的多模态任务获得了广泛的关注并取得了显著成功。 文本生成图像(text-to-image)是图像和文本处理的多模态任务的一项子任务,其根据给定文本生成符合描述的真实图像…...

财务共享建设,为什么需要电子影像系统?
某集团作为投资性集团公司,业务遍布全国20多个省市,控股公司200余家,业务范围涉及火电、供热、风电、天然气天然气、水务、铁路、港口、酒店、地产等20多个细分行业。 伴随着集团企业的快速发展,某集团在管理中面临“点多、面广、…...
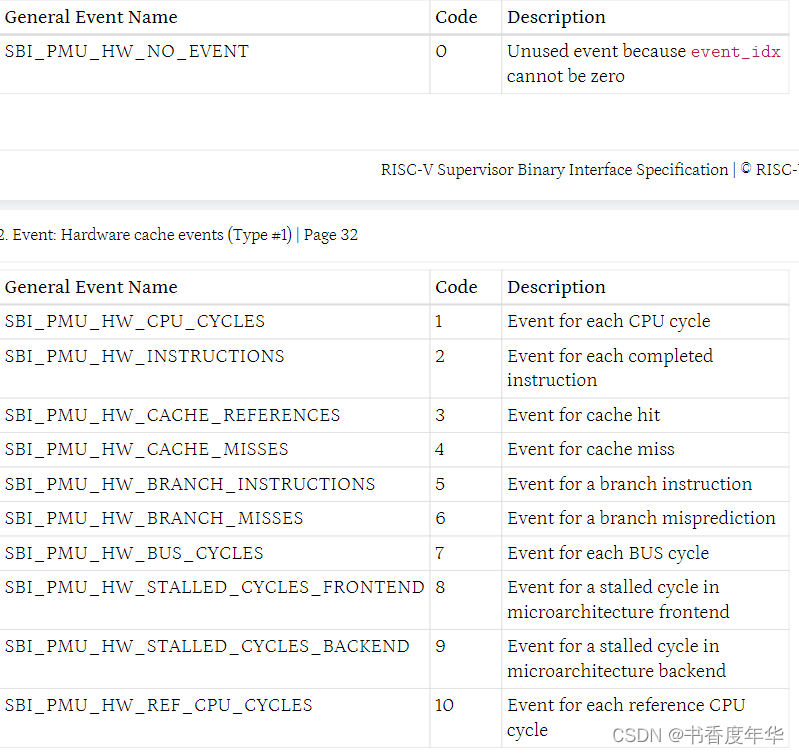
「RISC-V Arch」SBI 规范解读(下)
第六章 定时器扩展(EID #0x54494D45"TIME") 这个定时器扩展取代了遗留定时器扩展(EID #0x00),并遵循 v0.2 中定义的调用规约。 6.1 函数:设置定时器(FID #0) struct sbi…...

Android framework socketpair
简述 在Linux中,socketpair函数可以用于创建一对相互连接的、通信域为AF_UNIX的套接字,其中一个套接字可用于读取,另一个套接字可用于写入。可以使用这对套接字在同一进程内进行进程间通信(IPC)。 以下是使用socketp…...
腾讯在海外游戏和短视频广告领域的新增长机会
来源:猛兽财经 作者:猛兽财经 腾讯(00700)的收入在过去几个季度一直在下降,部分原因是由于新冠疫情导致的经济放缓以及中国监管机构对大型科技公司的监管收紧导致游戏行业萎缩造成的。 然而,猛兽财经认为,这些不利因素…...

查找该学号学生的成绩。
从键盘输入某班学生某门课的成绩(每班人数最多不超过40人),当输入为负值时,表示输入结束,试编程从键盘任意输入一个学号,查找该学号学生的成绩。**输入格式要求:"%ld"(学号) "%l…...

为Webpack5项目引入Buffer Polyfill
前言 最近在公司的一个项目中使用到了Webpack5, 然而在使用某个npm包的时候,出现了Buffer is not defined 这个问题,原因很明显了,因为浏览器运行时没有Buffer这个API,所以需要为浏览器引入Buffer Polyfill. Webpack5…...
【人工智能 AI 】您可以使用机器人流程自动化 (RPA) 实现自动化的 10 个业务流程:Robotic Process Automation (RPA)
摘:人类劳动正在被机器(例如在工业中)或计算机程序(适用于所有行业)所取代。 目录 10 processes you can robotise in your company您可以在公司中实现自动化的 10 个流程 Human employees or robotic workers?人类员工还是机器人工人? Robots take over headhunting…...
VMware ESXi 8.0b - 领先的裸机 Hypervisor (Dell HPE Custom Image update)
本站发布 Dell 和 HPE 定制版 ESXi 8.0b 镜像 请访问原文链接:https://sysin.org/blog/vmware-esxi-8/,查看最新版。原创作品,转载请保留出处。 作者主页:www.sysin.org 产品简介 VMware ESXi:专门构建的裸机 Hyper…...

Java:SpringBoot 整合Spring-Retry实现错误重试
SpringBoot 整合Spring-Retry可以实现错误重试 目录引入依赖开启spring-retry使用重试注解Retryable 注解Backoff 注解测试参考引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactI…...

MyBatis学习笔记(二) —— 搭建MyBatis项目
2、搭建MyBatis 2.1、开发环境 IDE:idea 2019.2 构建工具:maven 3.5.4 MySQL版本:MySQL 8 MyBatis版本:MyBatis 3.5.7 MySQL不同版本的注意事项 1、驱动类 driver-class-name MySQL 5版本使用jdbc5驱动,驱动类使用…...

linux服务器上Docker中安装jenkins
前言 Jenkins是开源CI&CD软件领导者, 提供超过1000个插件来支持构建、部署、自动化, 满足任何项目的需要。 本文主要提供通过docker安装jenkins镜像,并配置nginx反向代理页面配置和使用。通过jenkins完成项目的自动部署。 我在安装之前…...

自考都有哪些科目?怎么搭配报考?
第一次自考科目搭配 先报理论课,熟悉学习和考试套路 参考搭配模式: 一、全报考公共课 公共课难度较低,通过率高,复习起来比较轻松。对于不确定考什么专业,后期想换专业的同学,考过公共课,…...

【燃烧机】模拟了燃烧机的热力学循环分析活塞动力学以及温度和压力变化对发动机效率的影响【含Matlab源码 15557期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab武动乾坤博客之家💞…...

Lindy流程自动化效果衰减真相:3年追踪数据显示,未做持续治理的企业6个月后效率回落至基线112%
更多请点击: https://codechina.net 第一章:Lindy流程自动化效果衰减真相:3年追踪数据显示,未做持续治理的企业6个月后效率回落至基线112% Lindy效应在流程自动化领域呈现显著反向特征:系统上线初期的效率跃升并非稳态…...

华实展厅出圈!大自然标识匠心打造,目视化呈现基建巨头的实力底气
当建筑的厚重与视觉的美感碰撞,当企业的成长与科技的便捷融合,华实建设集团企业展厅——由专业的长沙市大自然标识设计制作公司倾力打造,不仅是品牌形象的“窗口”,更是实力与文化的“立体名片”。长沙市大自然标识设计制作有限公…...

优化缺陷密度,核心是从“事后救火”转向“全程预防”
优化缺陷密度,核心是从“事后救火”转向“全程预防”,通过系统化的流程和工具,在生产代码中构建 “计划-执行-检查-改进”的持续优化闭环。📈 第一步:测量与评估,建立基线测量缺陷密度:按质量阶…...

Jupyter C内核:在Notebook中实现C语言交互式编程的完整指南
Jupyter C内核:在Notebook中实现C语言交互式编程的完整指南 【免费下载链接】jupyter-c-kernel Minimal Jupyter C kernel 项目地址: https://gitcode.com/gh_mirrors/ju/jupyter-c-kernel Jupyter C内核是一个开源项目,为Jupyter Notebook提供完…...

三星固件下载神器Bifrost:跨平台一站式解决方案深度解析
三星固件下载神器Bifrost:跨平台一站式解决方案深度解析 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost Bifrost是一款基于Kotlin Multiplatform构建…...

Excel MCP Server:革命性的无Excel数据处理引擎
Excel MCP Server:革命性的无Excel数据处理引擎 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 在数据处理领域,传统Excel依赖…...

3步快速上手OneMore:让你的OneNote效率翻倍的完整指南
3步快速上手OneMore:让你的OneNote效率翻倍的完整指南 【免费下载链接】OneMore A OneNote add-in with simple, yet powerful and useful features 项目地址: https://gitcode.com/gh_mirrors/on/OneMore OneMore是一款专为OneNote设计的免费增强插件&#…...

跨平台媒体采集方案:智能资源获取工具实战指南
跨平台媒体采集方案:智能资源获取工具实战指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否曾经遇到过这…...

ComfyUI-Impact-Pack V8:AI图像细节增强的终极指南
ComfyUI-Impact-Pack V8:AI图像细节增强的终极指南 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址: https://git…...