文本生成图像简述4——扩散模型、自回归模型、生成对抗网络的对比调研
基于近年来图像处理和语言理解方面的技术突破,融合图像和文本处理的多模态任务获得了广泛的关注并取得了显著成功。
文本生成图像(text-to-image)是图像和文本处理的多模态任务的一项子任务,其根据给定文本生成符合描述的真实图像,具有巨大的应用潜力,如视觉推理、图像编辑、视频游戏、动画制作和计算机辅助设计。
目前,各种各样的模型已经开发用于文本到图像的生成,模型主要可以分为三大类:扩散模型(Diffusion Model)、自回归模型(Autoregressive Model)、生成对抗网络模型(Generative Adversarial Networks),下面梳理一些近几年重要的模型并对比这三种方法的优劣:
一、基本原理
1.1、扩散模型(Diffusion Model)
扩散模型是一类生成模型,其通过迭代去噪过程将高斯噪声转换为已知数据分布的样本,生成的图片具有较好的多样性和写实性。
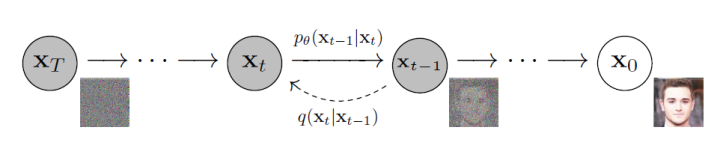
扩散过程逐步向原始图像添加高斯噪声,是一个固定的马尔科夫链过程,最后图像也被渐进变换为一个高斯噪声。而逆向过程则通过去噪一步步恢复原始图像,从而实现图像的生成。
随机输入一张高斯噪声显然不能按照人的意愿生成我们想要的内容,我们需要将一些具体的指导融入扩散模型中去,如:Classifier Guidance、Semantic Diffusion Guidance、Classifier-Free Guidance。
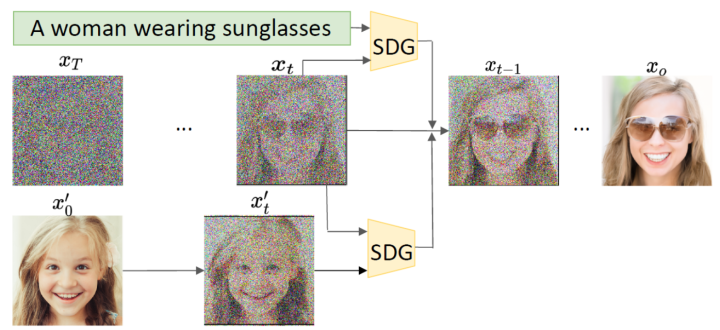
扩散模型在实现文本生成图像上大概有以下策略:
- 使用外部模型(分类器 or 广义的判别器)的输出作为引导条件来指导扩散模型的去噪过程,从而得到我们想要的输出;
- 直接把我们想要的引导条件 condition 也作为模型输入的一部分,从而让扩散模型见到这个条件后就可以直接生成我们想要的内容。
这两种想法可以将普通扩散模型改进为引导扩散模型(Guided Diffusion),并对生成的图像进行一定程度上的细粒度控制。
1.2、自回归模型(Autoregressive Model)
自回归模型模型利用其强大的注意力机制已成为序列相关建模的范例,受GPT模型在自然语言建模中的成功启发,图像GPT(iGPT)通过将展平图像序列视为离散标记,采用Transformer进行自回归图像生成。生成图像的合理性表明,Transformer模型能够模拟像素和高级属性(纹理、语义和比例)之间的空间关系。Transformer整体主要分为Encoder和Decoder两大部分,利用多头自注意力机制进行编码和解码。
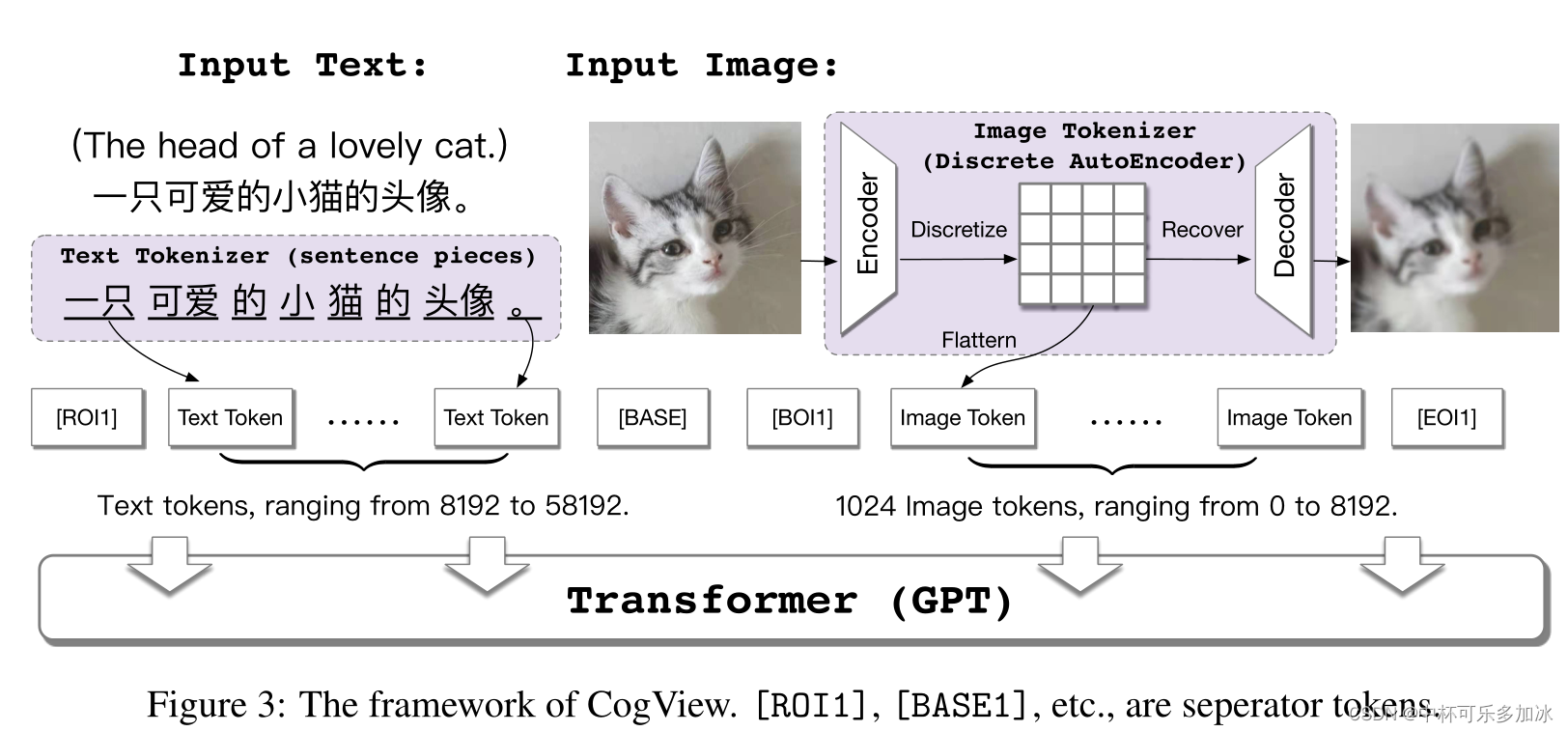
自回归模型在实现文本生成图像上大概有以下策略:
- 和VQ-VAE(矢量量化变分自动编码器)进行结合,首先将文本部分转换成token,利用的是已经比较成熟的SentencePiece模型;然后将图像部分通过一个离散化的AE(Auto-Encoder)转换为token,将文本token和图像token拼接到一起,之后输入到GPT模型中学习生成图像。
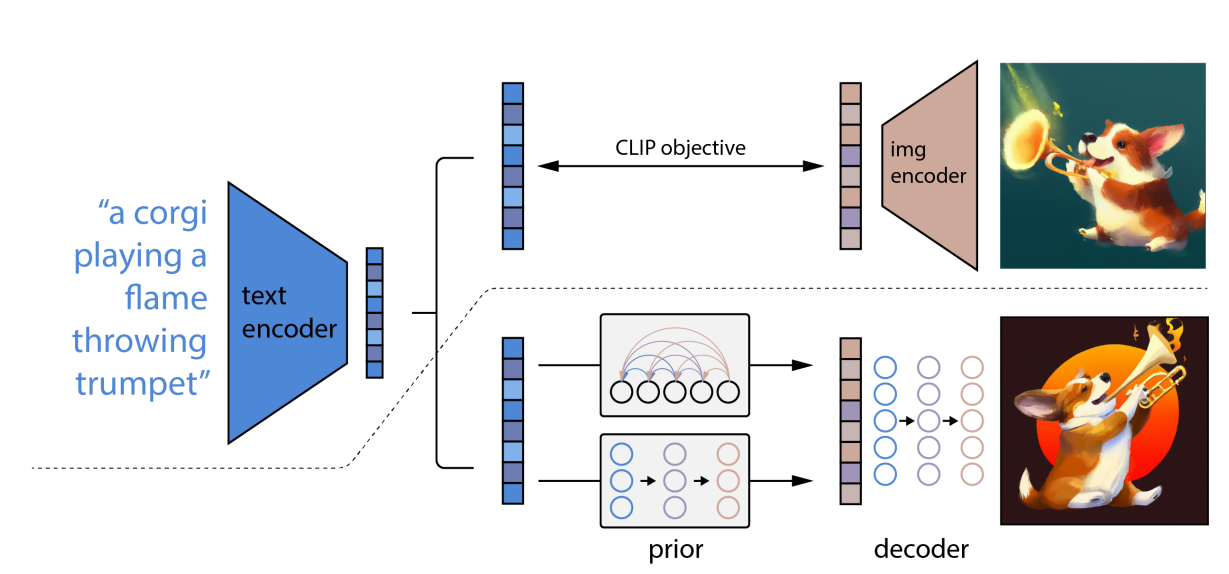
- 和CLIP结合。首先对于一幅没有文本标签的图像,使用 CLIP 的图像编码器,在语言-视觉(language-vision)联合嵌入空间中提取图像的 embedding。接着,将图像转换为 VQGAN 码本空间(codebook space)中的一系列离散标记(token)。最后,再训练一个自回归 Transformer,用它来将图像标记从 Transformer 的语言-视觉统一表示中映射出对应图像。经过这样的训练后,面对一串文本描述,Transformer 就可以根据从 CLIP 的文本编码器中提取的文本嵌入(text embedding)生成对应的图像标记(image tokens)了。
1.3、生成对抗网络模型(Generative Adversarial Networks)
生成对抗网络包含一个生成模型和一个判别模型。其中,生成模型负责捕捉样本数据的分布,而判别模型一般情况下是一个二分类器,判别输入是真实数据还是生成的样本。整个训练过程都是两者不断地进行相互博弈和优化。生成器不断得生成图像的分布不断接近真实图像分布,来达到欺骗判别器的目的,提高判别器的判别能力。判别器对真实图像和生成图像进行判别,来提高生成器的生成能力。
生成对抗网络实现文本生成图像主要分为三大部分:文本编码器、生成器和鉴别器。文本编码器由RNN或者Bi-LSTM组成,生成器可以做成堆叠结构或者单阶段生成结构,主要用于在满足文本信息语义的基础上生成图像,鉴别器用于鉴别生成器生成的图像是否为真和是否符合文本语义。
生成对抗网络模型在实现文本生成图像上主要有以下策略:
- 多阶段生成网络。由树状结构堆叠的多个生成器(G)和多个鉴别器(D)组成。从低分辨率到高分辨率的图像是从树的不同分支生成的。在每个分支上,生成器捕获该尺度的图像分布,鉴别器分辨来自该尺度样本的真假。对生成器进行联合训练以逼近多个分布,并且以交替方式对生成器和鉴别器进行训练。
- 单级生成网络。抛弃了堆叠结构,只使用一个生成器、一个鉴别器、一个预训练过的文本编码器。使用一系列包含仿射变换的UPBlock块学习文本与图像之间的映射关系,由文本生成图像特征。
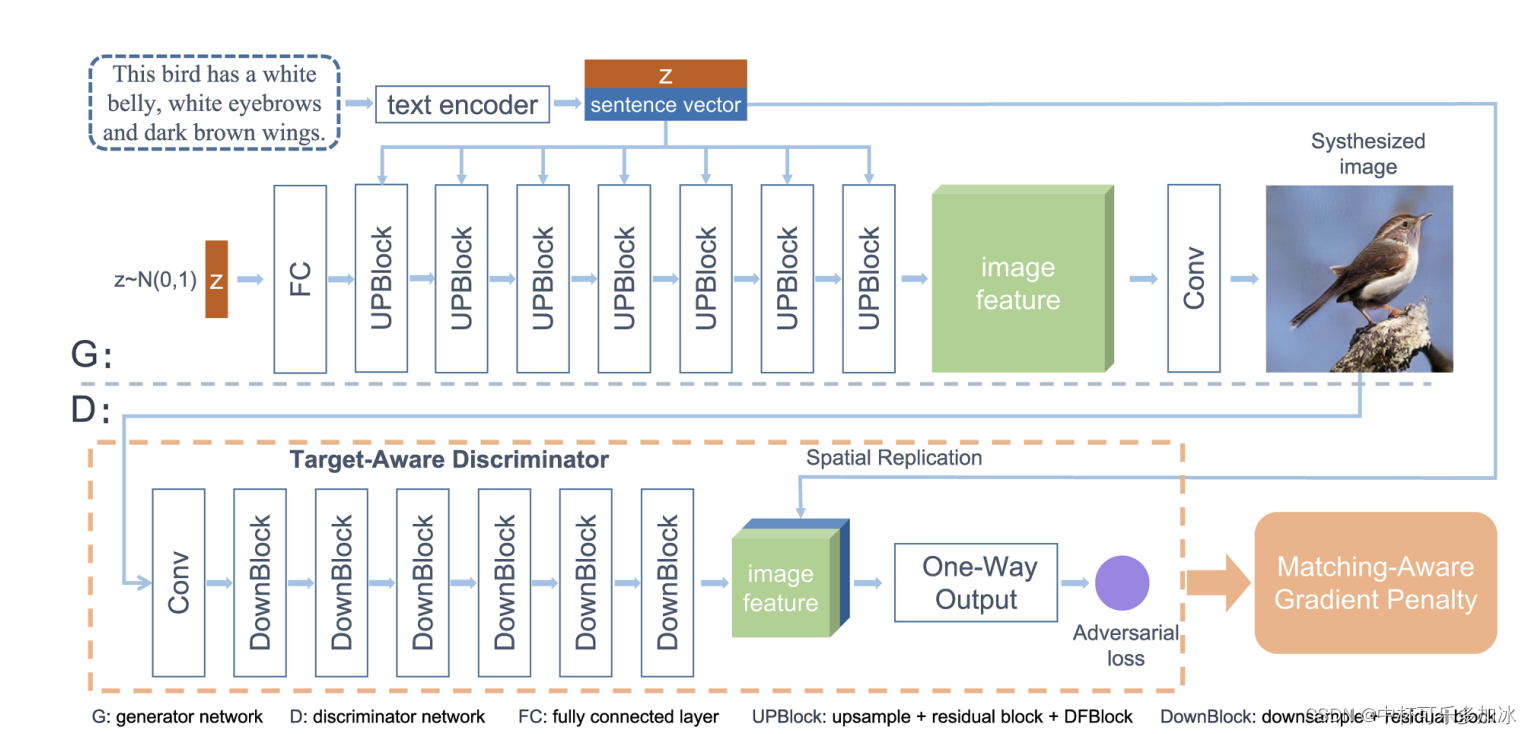
二、三种框架的对比
2.1、图像质量
在生成图像的质量上:扩散模型最好,自回归模型和生成对抗网络其次:
| 模型名 | 模型类型 | FID分数 |
|---|---|---|
| KNN-Diffusion | 扩散模型 | 16.66 |
| Stable Diffusion | 扩散模型 | 12.63 |
| GLIDE | 扩散模型 | 12.24 |
| DALL-E 2 | 扩散模型 | 10.39 |
| Imagen | 扩散模型 | 7.27 |
| Re-Imagen | 扩散模型 | 6.88 |
| DALL-E | 自回归模型 | 28 |
| CogView | 自回归模型 | 27.1 |
| CogView2 | 自回归模型 | 24.0 |
| Parti | 自回归模型 | 7.23 |
| StackGAN++ | 生成对抗网络 | 81.59 |
| AttnGAN | 生成对抗网络 | 35.49 |
| DM-GAN | 生成对抗网络 | 32.64 |
| DF-GAN | 生成对抗网络 | 21.42 |
| SSA-GAN | 生成对抗网络 | 19.37 |
2.2、参数量
在参数量的比较上,自回归模型和扩散模型参数量达到了十亿级别,属于自回归模型的Parti甚至达到了百亿级别的参数量,而生成对抗网络的模型参数量一般在千万级别,明显轻巧便捷。
| 模型名 | 模型类型 | 参数量(大概) |
|---|---|---|
| GLIDE | 扩散模型 | 35亿 |
| DALLE-2 | 扩散模型 | 35亿 |
| Imagen | 扩散模型 | 34亿 |
| Re-Imagen | 扩散模型 | 36亿 |
| DALLE | 自回归模型 | 120亿 |
| Cogview | 自回归模型 | 40亿 |
| Cogview2 | 自回归模型 | 60亿 |
| Parti | 自回归模型 | 200亿 |
| DFGAN | 生成对抗网络 | 0.19亿 |
2.3、易扩展性
在易扩展度的比较上,由于训练的计算成本小,且开源模型较多,生成对抗网络在文本生成图像的任务上仍然有很大的优势。而扩散模型和自回归模型的开源量较少,目前大多数都是大型公司(谷歌、Meta等)在研究,大型通用模型对设备的要求较高,在单张A100 GPU下,DALL-E需要18万小时,拥有200亿参数的 Parti 更是需要超过100万小时,成本高昂。
个人总结来说:
| 扩散模型 | 自回归模型 | 生成对抗网络 | |
|---|---|---|---|
| 图像质量 | 优 | 良+ | 良 |
| 参数量 | 中 | 差 | 优 |
| 易扩展性 | 中 | 中 | 优 |
| 优势原因 | 逐渐添加/去除噪声的性质,只学习大规模的结构,不引入归纳偏差 | 更大的batch size、更多的隐藏层、Transformer的多头自注意力机制 | 生成器和判别器动态对抗的特点,避免了马尔科夫链式的学习机制,无需在学习过程中进行推断 |
| 优点 | 更好的可解释性,生成的质量高 | 生成质量较高,生成分布更加均匀 | 采样速度很快,灵活的设计框架 |
| 缺点 | 大量扩散步骤导致采样速度慢 | 需要将图像转为token进行自回归预测,采样速度慢 | 可解释性差,容易模式崩溃 |
三、生成性网络的三难困境
目前的生成式学习框架还不能同时满足三个关键要求,包括(i)高质量样本,(ii)模式覆盖和样本多样性,(iii)快速和低廉的计算成本。而这些要求往往是它们在现实问题中广泛采用所必需的,普遍来说:
- 扩散模型(Diffusion Model)可以生成质量比较高的图片,且具有较强的多样性,但是其应用在实践中非常昂贵;(满足i,ii,难以满足iii)
- 自回归模型(Autoregressive Model)可以达到较好的模式覆盖和样本多样性,但是其先验的学习使用的是文本到中间离散表征的映射导致其很难在低廉的计算成本下生成高质量样本,它们生成的输出模糊。往往产生不现实的、模糊的样本(满足i,但是难以同时满足ii,iii)
- 生成对抗网络(GANs)能够快速生成高质量样本,但模式覆盖率较差;(满足i,iii,但难以满足ii)
参考:
《TACKLING THE GENERATIVE LEARNING TRILEMMA WITH DENOISING DIFFUSION GANS》
《Retrieval-Augmented Multimodal Language Modeling》
https://blog.csdn.net/qq_32275289/article/details/126951463
https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/124641910
💡 最后
我们已经建立了🏤T2I研学社群,如果你还有其他疑问或者对🎓文本生成图像很感兴趣,可以私信我加入社群。
📝 加入社群 抱团学习:中杯可乐多加冰-采苓AI研习社
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝
相关文章:
文本生成图像简述4——扩散模型、自回归模型、生成对抗网络的对比调研
基于近年来图像处理和语言理解方面的技术突破,融合图像和文本处理的多模态任务获得了广泛的关注并取得了显著成功。 文本生成图像(text-to-image)是图像和文本处理的多模态任务的一项子任务,其根据给定文本生成符合描述的真实图像…...

财务共享建设,为什么需要电子影像系统?
某集团作为投资性集团公司,业务遍布全国20多个省市,控股公司200余家,业务范围涉及火电、供热、风电、天然气天然气、水务、铁路、港口、酒店、地产等20多个细分行业。 伴随着集团企业的快速发展,某集团在管理中面临“点多、面广、…...
「RISC-V Arch」SBI 规范解读(下)
第六章 定时器扩展(EID #0x54494D45"TIME") 这个定时器扩展取代了遗留定时器扩展(EID #0x00),并遵循 v0.2 中定义的调用规约。 6.1 函数:设置定时器(FID #0) struct sbi…...

Android framework socketpair
简述 在Linux中,socketpair函数可以用于创建一对相互连接的、通信域为AF_UNIX的套接字,其中一个套接字可用于读取,另一个套接字可用于写入。可以使用这对套接字在同一进程内进行进程间通信(IPC)。 以下是使用socketp…...
腾讯在海外游戏和短视频广告领域的新增长机会
来源:猛兽财经 作者:猛兽财经 腾讯(00700)的收入在过去几个季度一直在下降,部分原因是由于新冠疫情导致的经济放缓以及中国监管机构对大型科技公司的监管收紧导致游戏行业萎缩造成的。 然而,猛兽财经认为,这些不利因素…...

查找该学号学生的成绩。
从键盘输入某班学生某门课的成绩(每班人数最多不超过40人),当输入为负值时,表示输入结束,试编程从键盘任意输入一个学号,查找该学号学生的成绩。**输入格式要求:"%ld"(学号) "%l…...

为Webpack5项目引入Buffer Polyfill
前言 最近在公司的一个项目中使用到了Webpack5, 然而在使用某个npm包的时候,出现了Buffer is not defined 这个问题,原因很明显了,因为浏览器运行时没有Buffer这个API,所以需要为浏览器引入Buffer Polyfill. Webpack5…...
【人工智能 AI 】您可以使用机器人流程自动化 (RPA) 实现自动化的 10 个业务流程:Robotic Process Automation (RPA)
摘:人类劳动正在被机器(例如在工业中)或计算机程序(适用于所有行业)所取代。 目录 10 processes you can robotise in your company您可以在公司中实现自动化的 10 个流程 Human employees or robotic workers?人类员工还是机器人工人? Robots take over headhunting…...
VMware ESXi 8.0b - 领先的裸机 Hypervisor (Dell HPE Custom Image update)
本站发布 Dell 和 HPE 定制版 ESXi 8.0b 镜像 请访问原文链接:https://sysin.org/blog/vmware-esxi-8/,查看最新版。原创作品,转载请保留出处。 作者主页:www.sysin.org 产品简介 VMware ESXi:专门构建的裸机 Hyper…...

Java:SpringBoot 整合Spring-Retry实现错误重试
SpringBoot 整合Spring-Retry可以实现错误重试 目录引入依赖开启spring-retry使用重试注解Retryable 注解Backoff 注解测试参考引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactI…...

MyBatis学习笔记(二) —— 搭建MyBatis项目
2、搭建MyBatis 2.1、开发环境 IDE:idea 2019.2 构建工具:maven 3.5.4 MySQL版本:MySQL 8 MyBatis版本:MyBatis 3.5.7 MySQL不同版本的注意事项 1、驱动类 driver-class-name MySQL 5版本使用jdbc5驱动,驱动类使用…...

linux服务器上Docker中安装jenkins
前言 Jenkins是开源CI&CD软件领导者, 提供超过1000个插件来支持构建、部署、自动化, 满足任何项目的需要。 本文主要提供通过docker安装jenkins镜像,并配置nginx反向代理页面配置和使用。通过jenkins完成项目的自动部署。 我在安装之前…...

自考都有哪些科目?怎么搭配报考?
第一次自考科目搭配 先报理论课,熟悉学习和考试套路 参考搭配模式: 一、全报考公共课 公共课难度较低,通过率高,复习起来比较轻松。对于不确定考什么专业,后期想换专业的同学,考过公共课,…...
HIVE --- 高级查询
目录 CTE和嵌套查询 嵌套查询 关联查询(join) MapJoin MapJoin操作在Map端完成 开启MapJoin操作 MAPJOIN不支持的操作 union 数据交换(import/export) 数据排序 order by sort by distribute by cluster by CTE和嵌…...

【手撕源码】vue2.x双向数据绑定原理
🐱 个人主页:不叫猫先生 🙋♂️ 作者简介:前端领域新星创作者、阿里云专家博主,专注于前端各领域技术,共同学习共同进步,一起加油呀! 💫系列专栏:vue3从入门…...
Allegro如何显示层叠Options和Find操作界面
Allegro如何显示层叠Options和Find操作界面 Allegro常规有三大操作界面,层叠,Options和Find,如下图 软件第一次启动的时候,三大界面是关闭的,下面介绍如何把它们打开,具体操作步骤如下 点击菜单上的View点击Windows...
【数据结构】双向链表
目录 数据结构之双向链表:: List.h List.c 1.创建返回链表的头结点 2.双向链表初始化 3.双向链表打印 4.双向链表销毁 5.双向链表尾插 6.双向链表尾删 7.双向链表头插 8.双向链表头删 9.双向链表查找 10.双向链表在pos前插入 11.双向链表删除pos位置 12…...
Editor工具开发基础三:自定义组件菜单拓展 CustomEditor
一.创建脚本路径 创建脚本路径不再限制 一般写在自定义组件类的下边二.特性CustomEditor 定义主设计图面由自定义代码实现数组的编辑器。两个构造函数1.public CustomEditor(Type inspectedType);2.public CustomEditor(Type inspectedType, bool editorForChildClasses);参数意…...

拒绝摆烂!神仙网站Python自学,一路从入门闯到最后,边学边玩
前言给大家推荐3个边玩边学python的网站在刚接触编程,培养对其持续的兴趣是最最重要的事情辣!!!因为前期需要大量的基础代码知识积累,这个过程对于不少人来说还是挺枯燥的,很有可能学到一半就放弃了&#x…...

Linux基础命令-locate快速查找文件
文章目录 locate 命令介绍 语法格式 基本参数 参考实例 1)查找1.txt相关的文件 2)查找包含pass和txt都有的文件 3)只匹配文件名,有路径的情况下不进行匹配 4)匹配不区分大小写的文件 5&#…...

昇腾CANN runtime Stream 调度引擎:从命令队列到 AI Core 的执行链路
用户看到的是一行 torch.nn.functional.softmax(x),背后 runtime 要做:分配 Stream、入队命令、调度到 AI Core、等待完成、同步结果。如果这一行的延迟是 10μs,runtime 的调度开销必须 < 0.5μs——否则就是 5% 的性能损失。 runtime 的…...

Shutter Encoder:构建高效媒体工作流的FFmpeg图形化解决方案
Shutter Encoder:构建高效媒体工作流的FFmpeg图形化解决方案 【免费下载链接】shutter-encoder A professional video compression tool accessible to all, mostly based on FFmpeg. 项目地址: https://gitcode.com/gh_mirrors/sh/shutter-encoder 在数字媒…...

Unity XLua调试失败原因与sourceMapPathOverrides终极配置
1. 这不是“配个插件就能跑”的事:为什么90%的UnityXLua调试配置会卡在“找不到源码”上EmmyLua VSCode 调试 XLua,这个组合在Unity Lua热更项目里几乎是事实标准。但你有没有遇到过这样的场景:断点明明打在Lua文件里,VSCode也显…...

AI技术落地情报简报:面向执行层的模型选型与Prompt工程实战
1. 这不是一份普通 newsletter:它是一张AI领域的动态认知地图“This AI newsletter is all you need #61”——光看标题,你可能以为这又是一份泛泛而谈的AI资讯合集。但作为连续追踪该系列超过18个月、亲手拆解过其中52期原始内容、并用其指导过7个真实产…...

【Android】Hypic 醒图国际版 最新版-免登录
【Android】Hypic 醒图国际版 最新版-解锁永久会员-免登录 链接:https://pan.xunlei.com/s/VOtJaC8K4sK_rrqnINu3HULdA1?pwddfdj# Hypic醒图国际版是一款功能强大的照片编辑应用程序,专为满足专业摄影师和业余爱好者的多样化需求而设计。...

AR眼镜主板与光机定制:从核心需求到量产落地的硬件开发指南
1. 项目概述:从一块主板到一副眼镜的蜕变最近几年,AR(增强现实)智能眼镜从科幻概念逐渐走进现实,无论是工业巡检、远程协作,还是消费娱乐,都能看到它的身影。但很多人可能不知道,决定…...

气象水文耦合模式WRF-Hydro建模技术应用
WRF-Hydro模型是一个分布式水文模型,它基于WRF陆面过程部分独立发展而来,旨在模拟大气和水文相互作用及过程。该模型采用FORTRAN90开发,具有良好的扩展性和支持大规模并行计算的与传统水文模型相比,WRF-Hydro模型具有以下…...

安卓截屏限制FLAG_SECURE原理与MT管理器绕过实战
1. 截屏限制不是“锁”,而是“提示灯”——先破除一个普遍误解 很多人一看到“App禁止截屏”,第一反应是“这App在防我”,继而联想到银行类App、考试系统、视频平台的“安全策略”,甚至下意识觉得背后有某种“硬隔离”或“内核级防…...

利用 Taotoken 模型广场为你的智能客服场景选择最合适的大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 模型广场为你的智能客服场景选择最合适的大模型 智能客服是当前大模型技术落地最广泛的场景之一。无论是处理售前咨…...

新手必看,在Taotoken控制台五分钟完成API Key申请与基础配置
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手必看,在Taotoken控制台五分钟完成API Key申请与基础配置 对于初次接触大模型API的开发者来说,第一步往…...