CUDA code=700(cudaErrorIllegalAddress) 报错与排查方法
CUDA code=700(cudaErrorIllegalAddress) 报错与排查方法
最近笔者在调试自己写的 CUDA 代码时, 遇到了 code=700(cudaErrorIllegalAddress) 的报错, 在此记录一下排查和解决方法.
报错
报错是由 CUDA API 函数执行时产生的, 由 checkCudaErrors() 函数检测出(CUDA 常用错误检测实现, 如下所示).
template <typename T>
void check(T result, char const *const func, const char *const file,int const line) {if (result) {fprintf(stderr, "CUDA error at %s:%d code=%d(%s) \"%s\" \n", file, line,static_cast<unsigned int>(result), cudaGetErrorName(result), func);exit(EXIT_FAILURE);}
}
#define checkCudaErrors(val) check((val), #val, __FILE__, __LINE__)
代码运行时报错如下所示, 显示是执行 cudaMemGetInfo() 函数时错误.
huanghy@node8:~/CL/src/cuda/build$ ./example
[sample_cuda] start
[sample_kernel] grid_size:1, block_size:512, shm_size:6144
[sample_kernel] finished
CUDA error at /home/huanghy/CL/src/cuda/sample.cu:53 code=700(cudaErrorIllegalAddress) "cudaMemGetInfo(&freeMem, &totalMem)"
原因
简单查阅资料可知, code=700(cudaErrorIllegalAddress) 的报错原因是 “an illegal memory access was encountered”, 即"遇到了一个非法的内存访问".
大多数情况下, 该问题产生都与数组越界访问的情况有关, 但值得一提的是, 往往报错的地方并不是问题实际存在的地方, 而由之前的 kernel 代码中的错误访问导致的.
比如, 此处报错是在 API 函数cudaMemGetInfo() 执行时, 也有可能是在自己定义的 kernel 函数执行时, 但可能一直排查当前报错的 kernel 不能解决问题的.
排查
一个很好的排查上述问题, 也是对自己的 CUDA 代码进行内存访问检查的方法是使用 CUDA 的 compute-sanitizer 工具.
该工具功能很多, 其中一个功能就是进行内存检测.
使用如下指令进行内存检查:
compute-sanitizer --launch-timeout=0 --tool=memcheck ./example > opt.txt 2>&1
其中, ./example 为检测的可执行文件. 由于输出可能比较多, 所以这里重定向到文件中. --launch-timeout=0 是将等待 kernel 加载的时间设置为无限, 以避免 compute-sanitizer 出现终止的情况, 如下所示.
========= COMPUTE-SANITIZER
========= Error: No attachable process found. compute-sanitizer timed-out.
========= Default timeout can be adjusted with --launch-timeout. Awaiting target completion.
最终 compute-sanitizer 会输出检测到的内存访问错误, 如下所示:
========= COMPUTE-SANITIZER
[sample_cuda] start
[sample_kernel] grid_size:1, block_size:512, shm_size:6144
========= Invalid __global__ write of size 4 bytes
========= at 0x1190 in sample_kernel(int *, at::GenericPackedTensorAccessor<int, (unsigned long)1, at::RestrictPtrTraits, int>, at::GenericPackedTensorAccessor<int, (unsigned long)1, at::RestrictPtrTraits, int>, at::GenericPackedTensorAccessor<int, (unsigned long)1, at::RestrictPtrTraits, int>, at::GenericPackedTensorAccessor<int, (unsigned long)1, at::RestrictPtrTraits, int>, curandStateXORWOW *, unsigned int, int, unsigned int)
========= by thread (32,0,0) in block (0,0,0)
========= Address 0x7f40c00275a4 is out of bounds
========= and is 23,461 bytes after the nearest allocation at 0x7f40c001fc00 of size 7,680 bytes
========= Saved host backtrace up to driver entry point at kernel launch time
========= Host Frame: [0x305c18]
========= in /usr/lib/x86_64-linux-gnu/libcuda.so.1
========= Host Frame: [0x1488c]
========= in /usr/local/cuda-11.8/lib64/libcudart.so.11.0
========= Host Frame:cudaLaunchKernel [0x6c318]
========= in /usr/local/cuda-11.8/lib64/libcudart.so.11.0
========= Host Frame:cudaError cudaLaunchKernel<char>(char const*, dim3, dim3, void**, unsigned long, CUstream_st*) [0x1f2f7]
========= in /home/huanghy/CL/src/cuda/build/./example
========= Host Frame:__device_stub__Z23sample_kernelPiN2at27GenericPackedTensorAccessorIiLm1ENS0_17RestrictPtrTraitsEiEES3_S3_S3_P17curandStateXORWOWjij(int*, at::GenericPackedTensorAccessor<int, 1ul, at::RestrictPtrTraits, int>&, at::GenericPackedTensorAccessor<int, 1ul, at::RestrictPtrTraits, int>&, at::GenericPackedTensorAccessor<int, 1ul, at::RestrictPtrTraits, int>&, at::GenericPackedTensorAccessor<int, 1ul, at::RestrictPtrTraits, int>&, curandStateXORWOW*, unsigned int, int, unsigned int) [0x1aec2]
========= in /home/huanghy/CL/src/cuda/build/./example
========= Host Frame:sample_kernel(int*, at::GenericPackedTensorAccessor<int, 1ul, at::RestrictPtrTraits, int>, at::GenericPackedTensorAccessor<int, 1ul, at::RestrictPtrTraits, int>, at::GenericPackedTensorAccessor<int, 1ul, at::RestrictPtrTraits, int>, at::GenericPackedTensorAccessor<int, 1ul, at::RestrictPtrTraits, int>, curandStateXORWOW*, unsigned int, int, unsigned int) [0x1af3a]
========= in /home/huanghy/CL/src/cuda/build/./example
========= Host Frame:sample_cuda(std::vector<at::Tensor, std::allocator<at::Tensor> >&, std::vector<CSR, std::allocator<CSR> >&, at::Tensor&, CSR const&, unsigned int, unsigned int, unsigned int, unsigned long long) [0x1a57d]
========= in /home/huanghy/CL/src/cuda/build/./example
========= Host Frame:sample(std::vector<at::Tensor, std::allocator<at::Tensor> >&, std::vector<CSR, std::allocator<CSR> >&, at::Tensor&, CSR const&, unsigned int, unsigned int, unsigned int, unsigned long long) [0x18900]
========= in /home/huanghy/CL/src/cuda/build/./example
========= Host Frame:main [0x87d0]
========= in /home/huanghy/CL/src/cuda/build/./example
========= Host Frame:__libc_start_main [0x21c87]
========= in /lib/x86_64-linux-gnu/libc.so.6
========= Host Frame:_start [0x804a]
========= in /home/huanghy/CL/src/cuda/build/./example
=========
========= 下面有很多重复单不同 threadIdx 和 blockIdx 的报错, 在此省略
=========
[sample_kernel] finished
========= Program hit cudaErrorLaunchFailure (error 719) due to "unspecified launch failure" on CUDA API call to cudaMemGetInfo.
========= Saved host backtrace up to driver entry point at error
========= Host Frame: [0x4545f6]
========= in /usr/lib/x86_64-linux-gnu/libcuda.so.1
========= Host Frame:cudaMemGetInfo [0x533ab]
========= in /usr/local/cuda-11.8/lib64/libcudart.so.11.0
========= Host Frame:print_device_mem() [0x19796]
========= in /home/huanghy/CL/src/cuda/build/./example
========= Host Frame:sample_cuda(std::vector<at::Tensor, std::allocator<at::Tensor> >&, std::vector<CSR, std::allocator<CSR> >&, at::Tensor&, CSR const&, unsigned int, unsigned int, unsigned int, unsigned long long) [0x1a5bb]
========= in /home/huanghy/CL/src/cuda/build/./example
========= Host Frame:sample(std::vector<at::Tensor, std::allocator<at::Tensor> >&, std::vector<CSR, std::allocator<CSR> >&, at::Tensor&, CSR const&, unsigned int, unsigned int, unsigned int, unsigned long long) [0x18900]
========= in /home/huanghy/CL/src/cuda/build/./example
========= Host Frame:main [0x87d0]
========= in /home/huanghy/CL/src/cuda/build/./example
========= Host Frame:__libc_start_main [0x21c87]
========= in /lib/x86_64-linux-gnu/libc.so.6
========= Host Frame:_start [0x804a]
========= in /home/huanghy/CL/src/cuda/build/./example
=========
CUDA error at /home/huanghy/CL/src/cuda/sample.cu:53 code=719(cudaErrorLaunchFailure) "cudaMemGetInfo(&freeMem, &totalMem)"
========= Target application returned an error
========= ERROR SUMMARY: 34 errors
在输出中, compute-sanitizer 会指明在具体的哪个 kernel 函数中发生了越界访问, 并指明相关的 threadIdx 和 blockIdx 以及内存地址.
以上述输出为例, 可以看到是在 sample_kernel() 函数中 threadIdx 为 (32,0,0) blockIdx (0,0,0) 处出现了 Address 0x7f40c00275a4 is out of bounds 的越界访问问题.
虽然地址信息很难让我们确定具体越界访问的位置, 但是通过该工具的输出, 可以确定到具体的 kernel 函数, 对于问题排查已经有了很大帮助.
参考
- cuda - Unspecified launch failure on Memcpy - Stack Overflow
- Compute-sanitizer not quite a drop-in replacement of cuda-memcheck - CUDA Developer Tools / Compute Sanitizer - NVIDIA Developer Forums
相关文章:
 报错与排查方法)
CUDA code=700(cudaErrorIllegalAddress) 报错与排查方法
CUDA code700(cudaErrorIllegalAddress) 报错与排查方法 最近笔者在调试自己写的 CUDA 代码时, 遇到了 code700(cudaErrorIllegalAddress) 的报错, 在此记录一下排查和解决方法. 报错 报错是由 CUDA API 函数执行时产生的, 由 checkCudaErrors() 函数检测出(CUDA 常用错误检…...

项目管理过程组
项目管理有2条主线,一条是技术,一条是管理。项目过程由项目团队实施。一般术语以下两大类之一:一类是项目管理过程。另一类是面向产品的过程。在大多数情况下,大多数项目都有共同的项目管理过程。它们通过有目的的实施而互相联系起…...

python每日一练(5)
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...

经典循环命题:百钱百鸡
翁五钱一只,母三钱,小鸡三只一钱;百钱百鸡百鸡花百钱。 (本笔记适合能熟练应用for循环、会使if条件分支语句、能格式化字符输出的 coder 翻阅) 【学习的细节是欢悦的历程】 Python 官网:https://www.python.org/ Free:…...
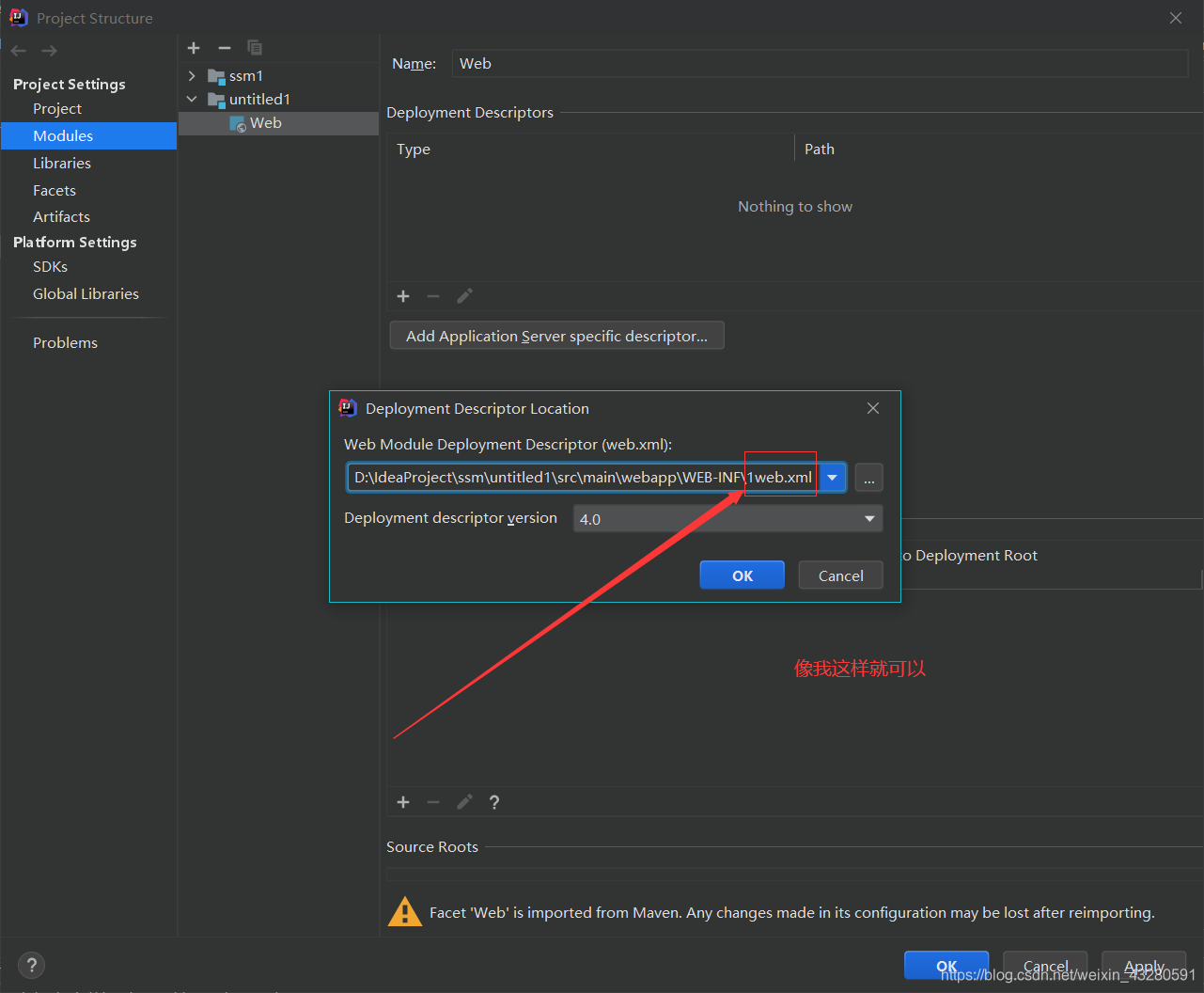
IDEA使用模板创建webapp时,web.xml文件版本过低的一种解决方法
创建完成后的web.xml 文件,版本太低 <!DOCTYPE web-app PUBLIC"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN""http://java.sun.com/dtd/web-app_2_3.dtd" ><web-app><display-name>Archetype Created Web Appl…...
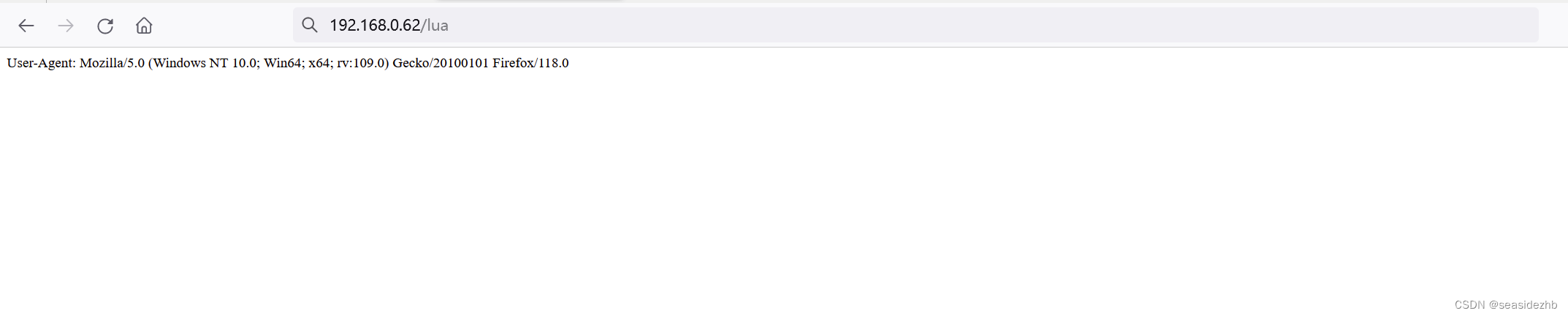
在Openresty中使用lua语言向请求浏览器返回请求头User-Agent里边的值
可以参考《Linux学习之Ubuntu 20.04在https://openresty.org下载源码安装Openresty 1.19.3.1,使用systemd管理OpenResty服务》安装Openresty。 然后把下边的内容写入到openresty配置文件/usr/local/openresty/nginx/conf/nginx.conf(根据实际情况进行选…...

Hive面试常见基础问题
以下是一些Hive面试问题和答案: Hive是什么? 答:Hive是一个开源的数据仓库工具,用于处理和分析大规模结构化数据。它能够创建、修改和查询表结构,支持多种数据类型和查询操作,同时提供数据汇总和数据查询的…...
设计模式 - 观察者模式
目录 一. 前言 二. 实现 三. 优缺点 一. 前言 观察者模式属于行为型模式。在程序设计中,观察者模式通常由两个对象组成:观察者和被观察者。当被观察者状态发生改变时,它会通知所有的观察者对象,使他们能够及时做出响应…...

【自动驾驶】PETR/PETRv2/StreamPETR论文分析
1.PETR PETR网络结构如下,主要包括image-backbone, 3D Coordinates Generator, 3D Position Encoder, transformer Decoder 1.1 Images Backbone 采用resnet 或者 vovNet,下面的x表示concatenate 1.2 3D Coordinates Generator 坐标生成跟lss类似,假…...

GPT实战系列-Baichuan2本地化部署实战方案
目录 一、百川2(Baichuan 2)模型介绍 二、资源需求 模型文件类型 推理的GPU资源要求 模型获取途径 国外: Huggingface 国内:ModelScope 三、部署安装 配置环境 安装过程...

用netty实现简易rpc
文章目录 rpc介绍:rpc调用流程:代码: rpc介绍: RPC是远程过程调用(Remote Procedure Call)的缩写形式。SAP系统RPC调用的原理其实很简单,有一些类似于三层构架的C/S系统,第三方的客户程序通过接…...

【计算机网络】第三章课后习题答案
习题目录: 【3-01】数据链路(即逻辑链路)与链路(即物理链路)有何区别?"链路接通了"与"数据链路接通了"的区别何在? 【3-02】数据链路层中的链路控制包括哪些功能…...

cesium 地图蒙版遮罩效果
示例代码 <!DOCTYPE html> <html lang"en"><head><!-- Use correct character set. --><meta charset"utf-8" /><!-- Tell IE to use the latest, best version. --><meta http-equiv"X-UA-Compatible"…...

根据前序遍历结果构造二叉搜索树
根据前序遍历结果构造二叉搜索树-力扣 1008 题 题目说明: 1.preorder 长度>1 2.preorder 没有重复值 直接插入 解题思路: 数组索引[0]的位置为根节点,与根节点开始比较,比根节点小的就往左边插,比根节点大的就往右…...

微信小程序指定某个元素强制重新渲染
之前写过 vue强制让某个元素重新渲染 利用了vue中的 v-if会控制元素是否挂载 以及 $nextTick 等待响应式更改生效再执行的特性 小程序也都有类似的方法 我们可以这样 wxml <view wx:if"{{min true}}">你好</view>用 wx:if 作用和v-if是一样的 js th…...
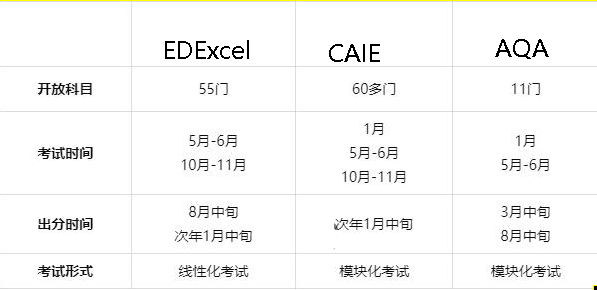
国际教材概念基础
各种区别 缩写 A-LEVEL(大学预科):General Certificate of Education Advanced Level AP:Advanced Placement(美国地区:美高AP) GCSE:General Certificate of Secondary Educati…...

2023全国大学生软件测试大赛开发者测试练习题满分答案(PairingHeap2023)
2023全国大学生软件测试大赛开发者测试练习题满分答案(PairingHeap2023) 题目详情题解代码(直接全部复制到test类中即可) 提示:该题只需要分支覆盖得分即可,不需要变异得分 题目详情 题解代码(…...

介绍一下tokens
“Tokens” 是一个计算机科学和自然语言处理领域常用的术语,通常用于表示文本中的最小单位。在这个上下文中,我将解释一下 “tokens” 的含义以及它们在不同领域中的用途: 自然语言处理 (NLP): 在自然语言处理中,“token” 是指文…...
机器学习、深度学习相关的项目集合【自行选择即可】
【基于YOLOv5的瓷砖瑕疵检测系统】 YOLOv5是一种目标检测算法,它是YOLO(You Only Look Once)系列模型的进化版本。YOLOv5是由Ultralytics开发的,基于一阶段目标检测的概念。其目标是在保持高准确率的同时提高目标检测的速度和效率…...
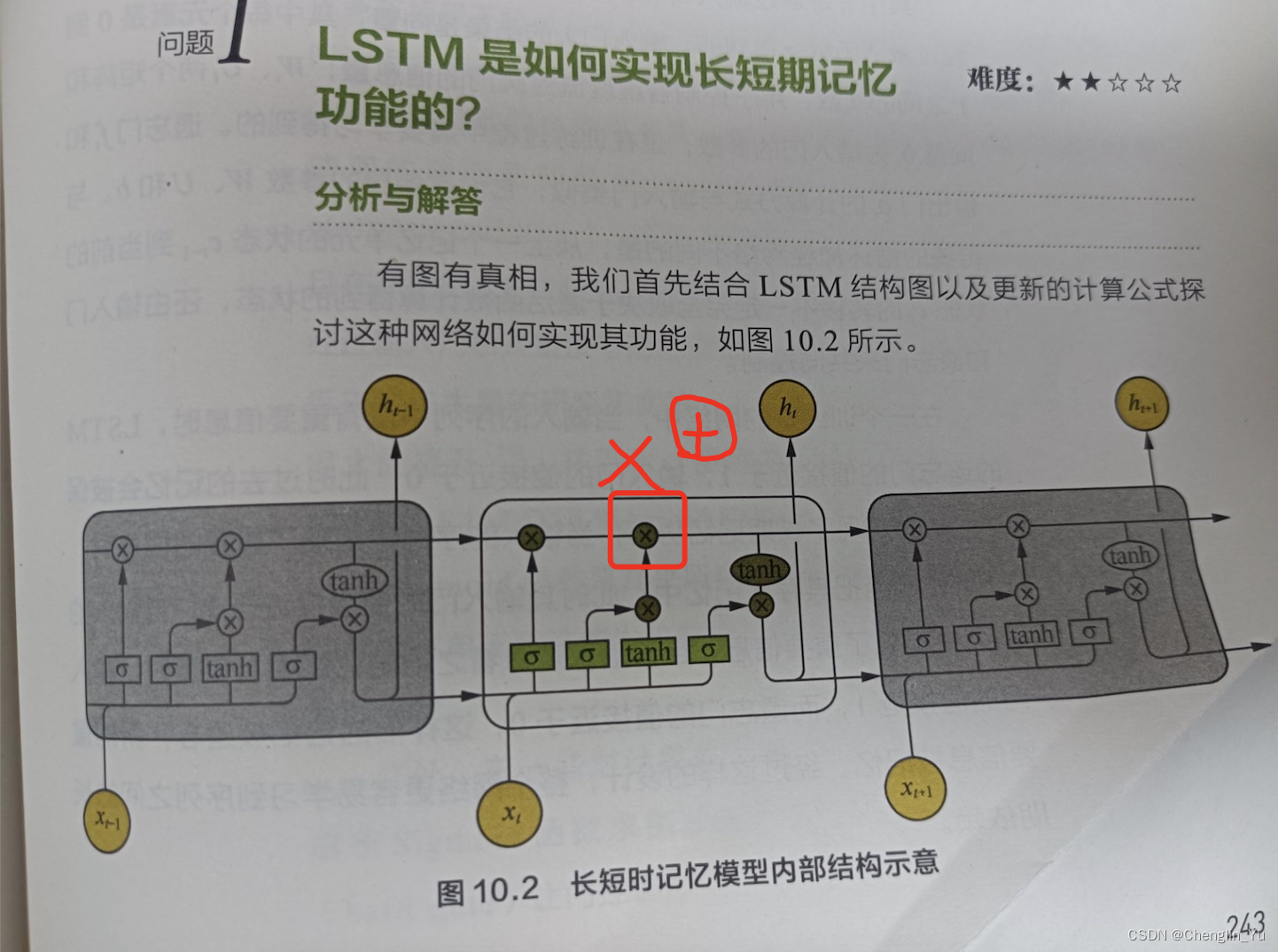
百面机器学习书刊纠错
百面机器学习书刊纠错 P243 LSTM内部结构图 2023-10-7 输入门的输出 和 candidate的输出 进行按元素乘积之后 要和 遗忘门*上一层的cell state之积进行相加。...

snabbt.js与Hammer.js集成终极指南:打造流畅触摸手势动画的10个技巧
snabbt.js与Hammer.js集成终极指南:打造流畅触摸手势动画的10个技巧 【免费下载链接】snabbt.js Fast animations with javascript and CSS transforms 项目地址: https://gitcode.com/gh_mirrors/sn/snabbt.js snabbt.js是一个轻量级JavaScript动画库&#…...

OpenClaw云端体验指南:星图平台Qwen3-14B镜像+OpenClaw沙盒部署
OpenClaw云端体验指南:星图平台Qwen3-14B镜像OpenClaw沙盒部署 1. 为什么选择云端沙盒体验? 第一次接触OpenClaw时,我尝试在本地MacBook上部署,结果被复杂的依赖关系和环境配置劝退。直到发现星图平台的Qwen3-14B镜像OpenClaw沙…...

物联网设备上高德地图离线地图加载慢?5秒内快速加载的终极解决方案
物联网设备高德地图离线加载优化实战:从2分钟到5秒的进阶方案 在智能电表、车载终端、工业传感器等物联网设备中,离线地图的快速加载直接影响着用户体验与系统响应效率。我们曾遇到一个典型场景:某共享单车智能锁通过4G模块上报位置时&#x…...

解锁Intel GPU的CUDA能力:从零开始的跨硬件计算实践
解锁Intel GPU的CUDA能力:从零开始的跨硬件计算实践 【免费下载链接】ZLUDA CUDA on non-NVIDIA GPUs 项目地址: https://gitcode.com/GitHub_Trending/zl/ZLUDA 当实验室电脑只有Intel集成显卡却需要运行CUDA加速程序时,当笔记本的Iris Xe显卡面…...

UFS4.0协议之电源与信号完整性设计探析
1. UFS4.0协议的核心电源架构解析 第一次拆解UFS4.0存储芯片时,我被其电源系统的精密设计震撼到了。与早期版本相比,UFS4.0将供电网络细分为VCC(2.5V)、VCCQ(1.2V)和VCCQ2(1.8V)三级…...

别再手动整理了!用这个Python脚本,一键把TMM刮的演员图灌进Jellyfin
解放双手!Python自动化脚本实现TMM演员图无缝迁移至Jellyfin 每次打开Jellyfin看到那些缺失的演员头像,是不是总有种美中不足的感觉?作为影视库管理员,我们都希望自己的媒体库尽善尽美。但现实是,Jellyfin默认的演员图…...

quark-auto-save:自动化云存储管理的夸克网盘解决方案
quark-auto-save:自动化云存储管理的夸克网盘解决方案 【免费下载链接】quark_auto_save 夸克网盘签到、自动转存、命名整理、发推送提醒和刷新媒体库一条龙 项目地址: https://gitcode.com/gh_mirrors/qu/quark_auto_save 在数字化时代,云存储已…...

从Simulink仿真到Altium Designer画板:一个直流电机调速系统的完整诞生记
从算法仿真到电路实现:直流电机双闭环调速系统全流程实战 在实验室里调试电机控制系统时,最令人兴奋的时刻莫过于看到仿真曲线和实际示波器波形完美吻合的瞬间。作为电子工程师,我们每天都在与这种"虚实结合"的挑战打交道——如何在…...

Suno AI音乐生成避坑指南:从注册到出片,这5个细节决定你的歌好不好听
Suno AI音乐生成避坑指南:从注册到出片,这5个细节决定你的歌好不好听 第一次用Suno生成音乐时,我对着屏幕上那首旋律生硬、人声机械的"作品"哭笑不得——这和我脑海中的旋律相差十万八千里。直到反复调整了五个关键参数后ÿ…...

SiameseAOE中文-base效果展示:电商评论中‘音质/发货/满意’精准抽取案例
SiameseAOE中文-base效果展示:电商评论中‘音质/发货/满意’精准抽取案例 1. 引言:当AI学会“读心术” 想象一下,你是一家电商平台的运营人员,每天面对成千上万条用户评论。你想知道用户对“音质”的评价如何,对“发…...