联邦学习综述二
联邦学习漫画
联邦学习漫画链接: https://federated.withgoogle.com/
Federated Analytics: Collaborative Data Science without Data Collection
博客链接: https://blog.research.google/2020/05/federated-analytics-collaborative-data.html
本篇博客介绍了联邦分析,即将数据科学方法应用于分析存储在用户设备上本地的原始数据的实践。与联邦学习一样,它的工作原理是对每个设备的数据运行本地计算,并且只向产品工程师提供聚合结果(而不是来自特定设备的任何数据)。然而,与联邦学习不同,联邦分析旨在支持基本的数据科学需求。这篇文章描述了为追求联邦学习而开发的联邦分析的基本方法,我们如何将这些见解扩展到新领域,以及联邦技术的最新进展如何为不断增长的数据科学需求提供更好的准确性和隐私性。
-
通过安全聚合保护联合分析
- 安全聚合可以为联合分析应用程序提供更强的隐私属性,这种方法的隐私属性可以通过对更多人求和或通过向计数添加小的随机值(例如,支持差分隐私)来加强。
- 联合分析的方法是一个活跃的研究领域,已经超越了分析指标和计数。有时,使用联合学习训练 ML 模型可用于获取有关设备上数据的聚合见解,而无需任何原始数据离开设备。
Federated Learning Challenges Methods and Future Directions

链接: https://static.aminer.cn/storage/pdf/arxiv/19/1908/1908.07873.pdf
- 选自:IEEE Signal Processing Magazine
摘要
-
联邦学习涉及在远程设备或孤立的数据中心(如移动电话或医院)上训练统计模型,同时保持数据本地化。在本文中,讨论了联邦学习的独特特征和挑战,提供了当前方法的广泛概述,并概述了与广泛的研究社区相关的未来工作的几个方向。还考虑集中训练机器学习模型,但在本地提供服务和存储它们。讨论了联邦学习的几种情景:
- 智能手机
- 组织机构
- 物联网

联邦学习中最小化以下目标函数:

联邦学习的四种挑战
-
通信消耗大
- 原因
- 联邦网络可能由大量设备组成,例如,数百万智能手机,网络中的通信可能比本地计算慢许多个数量级。为了将模型拟合到联邦网络中的设备生成的数据中,因此有必要开发通信高效的方法,迭代地发送小消息或模型更新作为训练过程的一部分,而不是通过网络发送整个数据集。
- 关键
- 减少通信轮总数
- 减少每轮传输消息的大小
- 原因
-
系统异构性
- 原因
- 联邦网络中每个设备的存储、计算和通信能力可能因硬件(CPU、内存)、网络连接(3G、4G、5G、wifi)和电源(电池电量)的变化而有所不同。此外,每个设备的网络规模和系统相关约束通常会导致只有一小部分设备同时处于活动状态。
- 要求
- 预测少量的参与
- 容忍异构硬件
- 对网络中丢失的设备具有鲁棒性
- 原因
-
统计异构性
- 原因
- 设备经常在网络上以非相同的分布方式生成和收集数据,跨设备的数据点数量可能变化很大,并且可能存在捕获设备及其相关分布之间关系的底层结构。这种数据生成范式违背了分布式优化中经常使用的独立和同分布(IID)假设,增加了掉队者的可能性,并可能增加建模、分析和评估方面的复杂性。
- 解决方案
- 元学习
- 多任务
- 原因
-
隐私性
- 原因
- 联邦学习通过共享模型更新(例如,梯度信息)而不是原始数据,向保护每个设备上生成的数据迈出了一步。然而,在整个训练过程中沟通模型更新仍然会向第三方或中央服务器泄露敏感信息。
- 解决方法
- 安全多方计算
- 差分隐私
- 同态加密
- 原因
目前研究内容
-
通信效率
-
本地更新方法
-
Mini-batch 是一种在机器学习中常用的优化方法,它将训练数据集划分为小批次进行模型训练。这种方法相对于全批次训练和随机梯度下降(SGD)有一些独特的优势。
- 以下是一些使用 mini-batch 进行优化的常见方法:
- 小批次随机梯度下降(Mini-batch Stochastic Gradient Descent,Mini-batch SGD): 在每个训练迭代中,随机选择一小批量实例(小批次)来计算梯度,并使用这些梯度更新模型参数。这样可以减少计算成本,同时保持一定的随机性,有助于避免收敛到局部最小值。
- 动量优化(Momentum Optimization): 动量优化是在小批次 SGD 的基础上引入了动量概念。动量可以帮助加速收敛,并且在梯度方向改变时增加动量,有助于跳出局部最小值。常见的动量优化算法有 Momentum、Nesterov Momentum 等。
- 自适应学习率优化(Adaptive Learning Rate Optimization): 自适应学习率优化方法根据模型参数的梯度情况自适应地调整学习率。其中,常见的算法有 AdaGrad、RMSProp、Adam 等。这些方法能够根据参数的变化动态地调整学习率,从而提高模型的训练效果。
- 批标准化(Batch Normalization): 批标准化是一种将数据标准化的技术,在每个小批次上将输入数据进行标准化处理,这样可以加速网络的收敛速度,并且有助于模型的泛化能力。
-
FL最常用的方法是联邦平均(FedAvg),这是一种基于局部随机梯度下降(SGD)平均更新的方法。FedAvg在经验上表现得很好,特别是在非凸问题上,但它没有收敛性保证,并且在实际情况下,当数据是异构的时,它可能会发散。

-
-
压缩方案和
-
在联邦学习中,压缩方案是一种常用的技术,用于减少在参与方之间传输的模型参数量,从而降低通信开销。
- 常见的联邦学习中的压缩方案和优化策略:
-
梯度压缩:参与方在本地计算模型参数的梯度,并将梯度进行压缩后再发送给中央服务器。常见的梯度压缩方法包括Top-k梯度压缩、量化梯度压缩、稀疏梯度压缩等。这些方法将梯度的大小进行压缩、量化或者稀疏化,从而减少传输的数据量。
-
模型参数压缩:将模型参数进行压缩,减少传输的数据量。常见的压缩方法包括权重剪枝(Weight Pruning)、低秩近似(Low-Rank Approximation)、矩阵分解(Matrix Factorization)等。这些方法通过减少模型参数的维度或者去除冗余的参数,从而降低传输的数据量。
-
分布式压缩:将模型参数分为多个部分,然后对每个部分进行压缩。这样可以将模型参数的压缩过程分布在不同的参与方中进行,从而减少单一参与方的计算和通信负担。常见的分布式压缩方法包括点对点压缩、分组压缩等。
-
选择性上传:参与方根据一定的策略选择是否上传模型参数或者压缩后的参数。比如,只有在模型参数的变化超过一定阈值时才上传,或者只有在本地模型的准确率达到一定要求时才上传。这样可以减少不必要的通信,提高整体的效率。
-
近似聚合:中央服务器在聚合参与方的参数时进行近似计算。常见的方法包括局部梯度聚合(Local Gradients Aggregation)和联邦平均(Federated Averaging)。通过在聚合过程中引入一定的近似算法,可以减少通信量和计算量。
-
-
分散训练
-
在联邦学习中,分散训练是一种常见的方法,用于在参与方之间分散地进行模型训练。相比于集中式训练,分散训练有以下特点:
- 模型训练在本地进行:在分散训练中,参与方分别在本地设备上进行模型训练,使用各自的数据进行参数更新。这样可以保护数据隐私,避免将数据集集中存储在中央服务器上。
- 局部模型参数的更新:每个参与方在本地计算模型的更新,只将更新后的参数传输到中央服务器。相比于传输整个模型参数,这种方式可以减少网络传输的数据量,降低通信开销。
- 模型参数的聚合:中央服务器负责收集参与方传输的更新参数,并对它们进行聚合,得到更新后的全局模型参数。常用的聚合方法包括加权平均、投票等。
- 迭代式的模型更新:分散训练通常是通过多轮迭代来完成模型的训练。在每一轮中,参与方根据自己的本地数据计算更新的模型参数,并将其传输给中央服务器。中央服务器根据接收到的参数进行聚合,并将聚合后的参数发送回参与方,用于下一轮的训练。
-
分散训练的优势在于可以在保护数据隐私的同时实现模型的训练。它适用于数据分散且无法集中存储的场景,例如医疗、金融等领域。然而,分散训练也面临一些挑战,例如网络传输不可靠、参与方之间的异构性等,需要借助一些优化策略和通信协议来解决这些问题,以提高训练效率和保证模型的准确性。

-
-
-
系统异构
-
异步通信
- 异步方案是一种有吸引力的方法来减少异构环境中的掉线者,特别是在共享内存系统中。然而,它们通常依赖于有界延迟假设来控制过时程度,对于设备k来说,这取决于自设备k从中央服务器取出以来更新的其他设备的数量。
- 依赖于有界延迟假设来控制过时的程度。
-
主动采样
- 在每一轮中服务器主动选择客户端(训练所参与的设备)
-
容错率
- 策略
- 编码计算
- 编码计算是通过引入算法冗余来容忍设备故障的另一种选择。最近的工作已经探索了使用代码来加速分布式机器学习训练。
- 故障忽略
- 编码计算
- 策略
-
-
统计异构
-
异构数据建模
-
对统计异质性进行建模(元学习、多任务学习),仅限于凸目标
-
将星形拓扑建模为贝叶斯网络,并在学习期间执行变分推理。空预处理非凸模型,但是推广到大型联邦网络是昂贵的。

-
-
非iid数据的收敛保证
- 提出了FedProx
-
-
隐私性
出于隐私考虑,通常需要在联邦设置中将每个设备上的原始数据保存在本地。然而,在训练过程中共享模型更新等其他信息也会泄露敏感的用户信息
- 差分隐私
- 同态加密
- 多方计算和安全评估
联邦学习的隐私
- 要求
- 除了提供严格的隐私保证外,还需要开发计算成本低、通信效率高、能够容忍掉线设备的方法,而所有这些都不会过度损害准确性。
- 分类
- 全局隐私(对中央服务器以外的所有不受信任的第三方都是私有的)
- 局部隐私(对服务器也是私有的)

未来的路
-
极端通信方案
- 在联合学习中需要多少交流还有待观察。机器学习的优化方法可以容忍缺乏精度;这个误差实际上有助于泛化。虽然在传统的数据中心设置中已经探索了单点或分而治之的通信方案,但在大规模或统计异构网络中,这些方法的行为尚未得到很好的理解。
-
减少通信
-
新的异步模型
- 在联邦网络中,每个设备通常不专用于手头的任务,并且大多数设备在任何给定的迭代中都不活动。因此,值得研究这种更现实的以设备为中心的通信方案的影响,在这种方案中,每个设备可以决定何时“唤醒”并以事件触发的方式与中央服务器交互。
-
异构性的诊断
- 这激发了以下开放性问题:
- 是否存在简单的诊断来快速确定联邦网络中的先验异质性水平?
- 是否可以开发类似的诊断方法来量化系统相关异质性的数量?
- 是否可以利用当前或新的异质性定义来进一步改进联邦优化方法的收敛性?
- 这激发了以下开放性问题:
-
细小的隐私限制
- 在实践中,可能有必要在更细粒度的级别上定义隐私,因为隐私约束可能在不同设备之间,甚至在单个设备上的不同数据点之间有所不同。
-
超越监督学习
- 在联邦网络中解决监督学习之外的问题可能需要解决类似的可伸缩性、异构性和隐私方面的挑战。
-
产业化联邦学习
-
基准测试
- 由于联邦学习是一个新兴领域,我们正处于塑造这一领域发展的关键时刻,并确保它们基于现实世界的设置、假设和数据集。对于更广泛的研究团体来说,进一步建立在现有的实现和基准测试工具的基础上是至关重要的,以促进经验结果的可重复性和联邦学习新解决方案的传播。
-
基准测试
- 由于联邦学习是一个新兴领域,我们正处于塑造这一领域发展的关键时刻,并确保它们基于现实世界的设置、假设和数据集。对于更广泛的研究团体来说,进一步建立在现有的实现和基准测试工具的基础上是至关重要的,以促进经验结果的可重复性和联邦学习新解决方案的传播。
相关文章:
联邦学习综述二
联邦学习漫画 联邦学习漫画链接: https://federated.withgoogle.com/ Federated Analytics: Collaborative Data Science without Data Collection 博客链接: https://blog.research.google/2020/05/federated-analytics-collaborative-data.html 本篇博客介绍了联邦分析&a…...
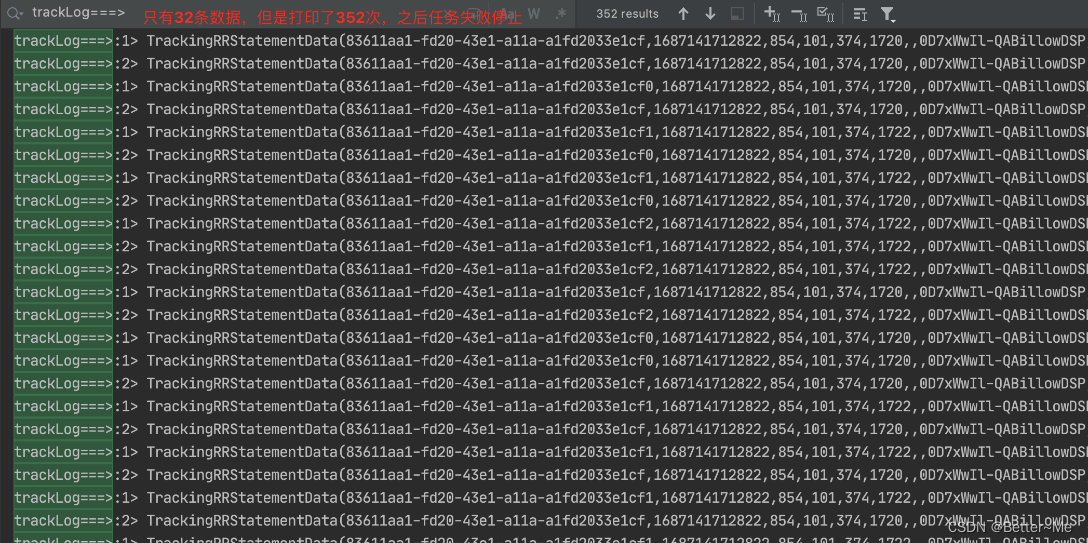
Idea本地跑flink任务时,总是重复消费kafka的数据(kafka->mysql)
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 Idea中执行任务时,没法看到JobManager的错误,以至于我以为是什么特殊的原因导致任务总是反复消费。在close方法中,增加日志,发现jdbc连接被关闭了。 重新…...

基于nodemailer实现邮件发送
概述 node中可用nodemailer实现邮件的发送。本文使用QQ邮箱实现邮件的发送。 实现效果 实现 1. QQ邮箱配置 首先需要开启POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务,如下图所示。 生成授权码 2. 发送邮件 发送邮件的代码比较简单,如下…...
—— (数据库表参数)】)
【PostgreSQL内核学习(十八)—— (数据库表参数)】
数据库表参数 default_reloptions 函数案例 声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。 本文主要参考了《PostgresSQL数据库内核…...
区块链的两个核心概念之一签名, 另一个是共识.
Alice的公私钥, 签名和验证签名仅仅确定了Alice对数字资产A所有权的宣言. 之后, Bob也可以用自己的私钥对资产A进行签名宣誓所有权。区块链中叫双花,即重复宣称所有权, 也称重复花费交易。这时候需要共识算法(集体成员pow或委员会代表pos监督…...
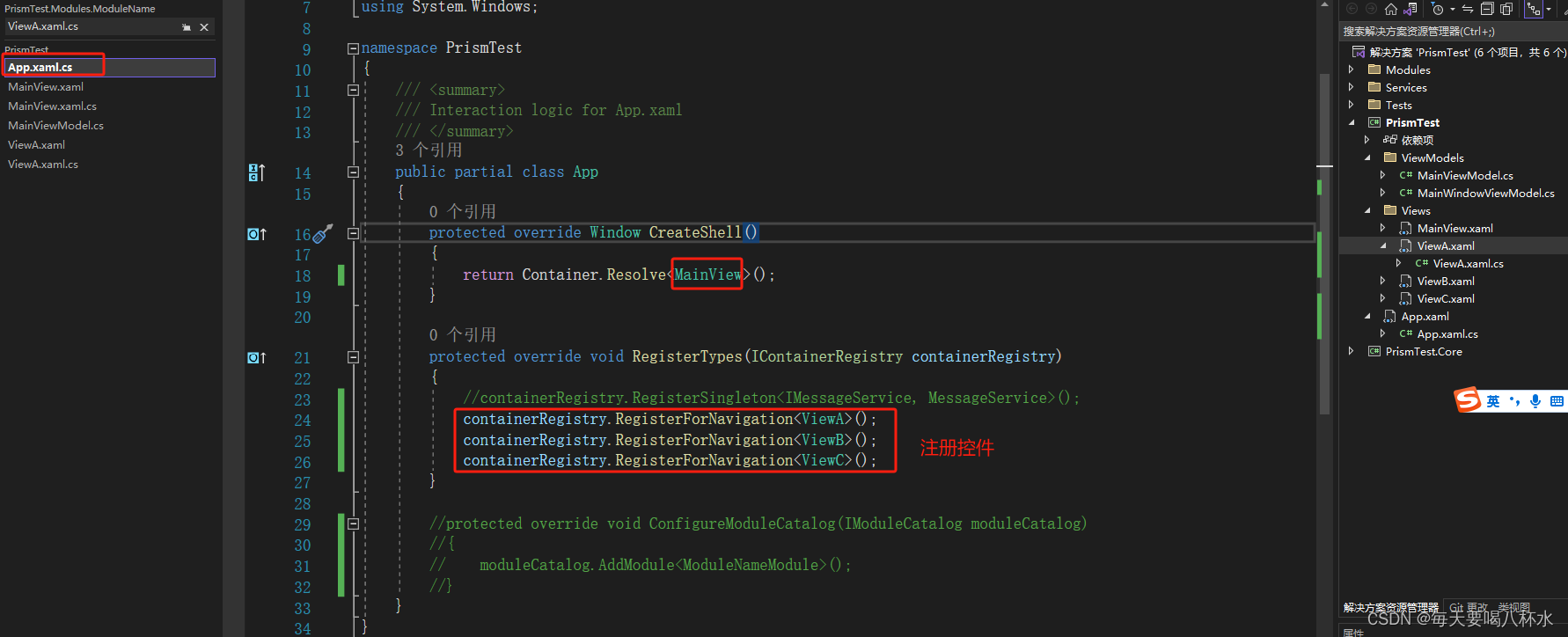
wpf中prism框架切换页面
主页面...
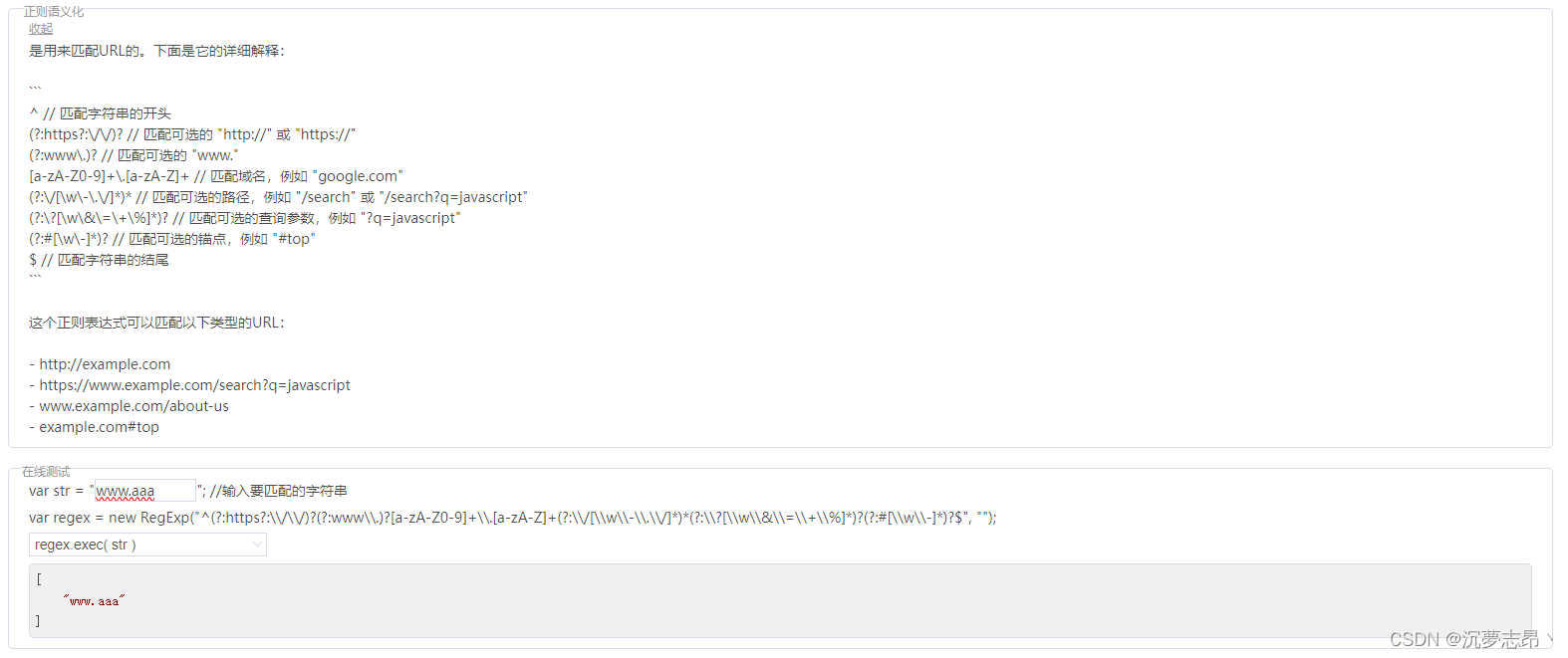
正则表达式(Regular Expression)学习网址分享
正则表达式(Regular expressions,也叫REs、 regexs 或regex patterns),是一种文本模式,包括普通字符(例如,a 到z 之间的字母)和特殊字符(称为"元字符"…...
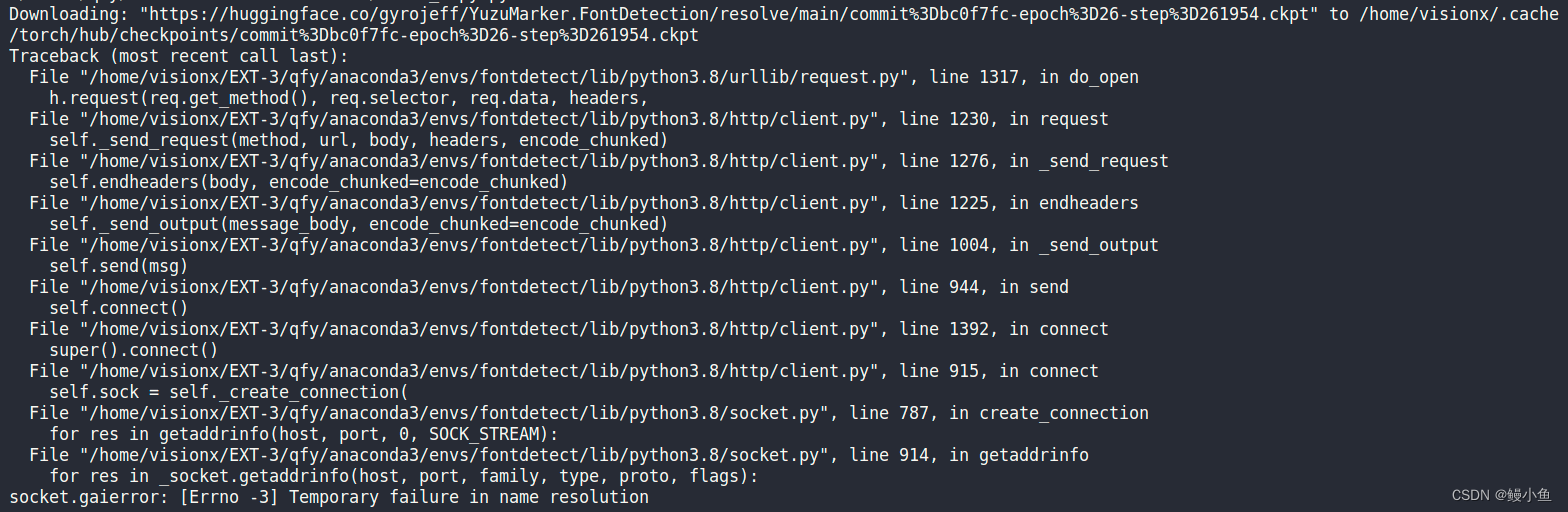
【已解决】socket.gaierror: [Errno -3] Temporary failure in name resolution
问题描述 今天在环境迁移的过程中遇到多个问题,包括ModuleNotFoundError: No module named flask,socket.gaierror: [Errno -3] Temporary failure in name resolution以及Downloading: "https://huggingface.co/gyrojeff/YuzuMarker.FontDetection…...
 报错与排查方法)
CUDA code=700(cudaErrorIllegalAddress) 报错与排查方法
CUDA code700(cudaErrorIllegalAddress) 报错与排查方法 最近笔者在调试自己写的 CUDA 代码时, 遇到了 code700(cudaErrorIllegalAddress) 的报错, 在此记录一下排查和解决方法. 报错 报错是由 CUDA API 函数执行时产生的, 由 checkCudaErrors() 函数检测出(CUDA 常用错误检…...

项目管理过程组
项目管理有2条主线,一条是技术,一条是管理。项目过程由项目团队实施。一般术语以下两大类之一:一类是项目管理过程。另一类是面向产品的过程。在大多数情况下,大多数项目都有共同的项目管理过程。它们通过有目的的实施而互相联系起…...

python每日一练(5)
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...

经典循环命题:百钱百鸡
翁五钱一只,母三钱,小鸡三只一钱;百钱百鸡百鸡花百钱。 (本笔记适合能熟练应用for循环、会使if条件分支语句、能格式化字符输出的 coder 翻阅) 【学习的细节是欢悦的历程】 Python 官网:https://www.python.org/ Free:…...
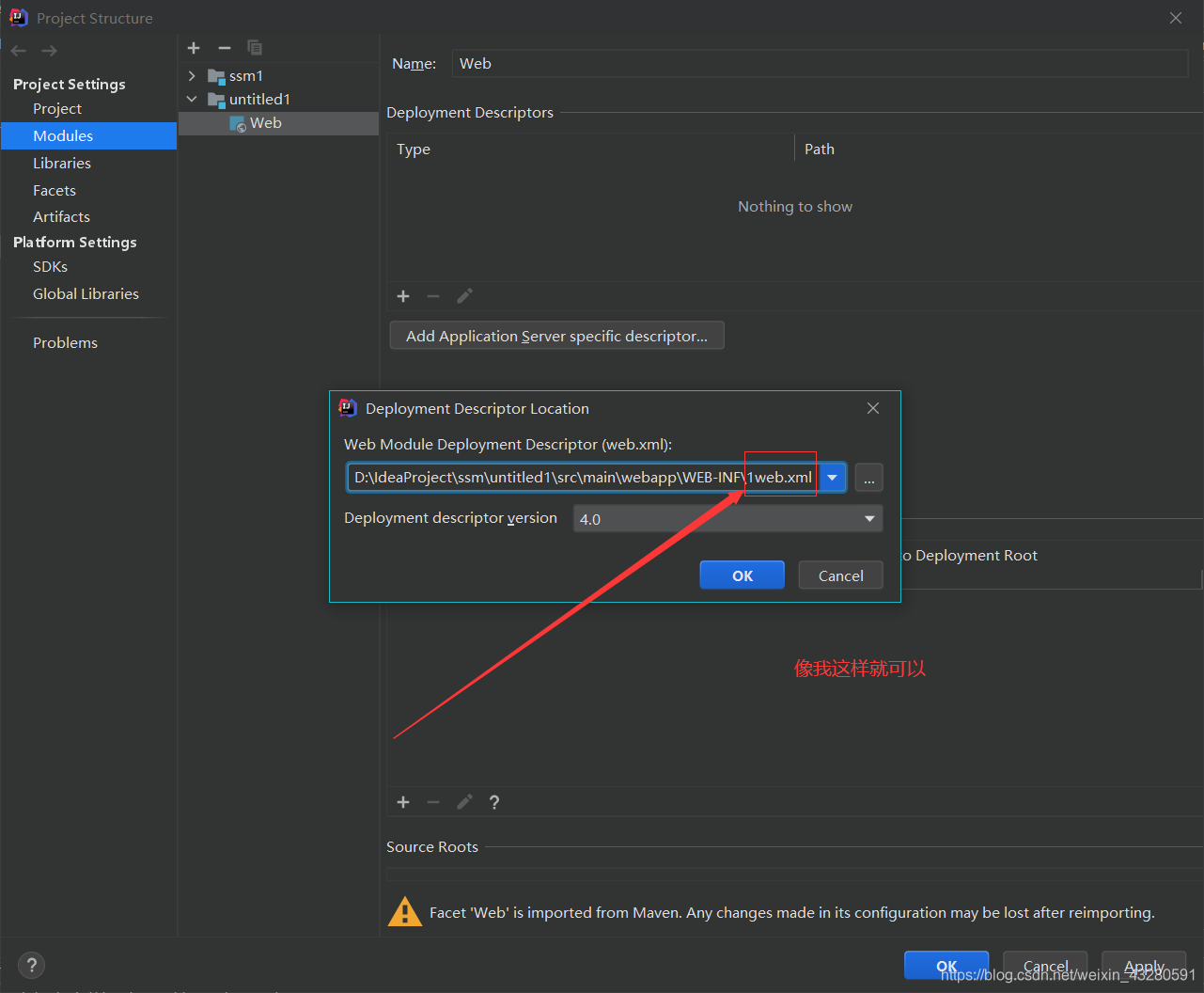
IDEA使用模板创建webapp时,web.xml文件版本过低的一种解决方法
创建完成后的web.xml 文件,版本太低 <!DOCTYPE web-app PUBLIC"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN""http://java.sun.com/dtd/web-app_2_3.dtd" ><web-app><display-name>Archetype Created Web Appl…...
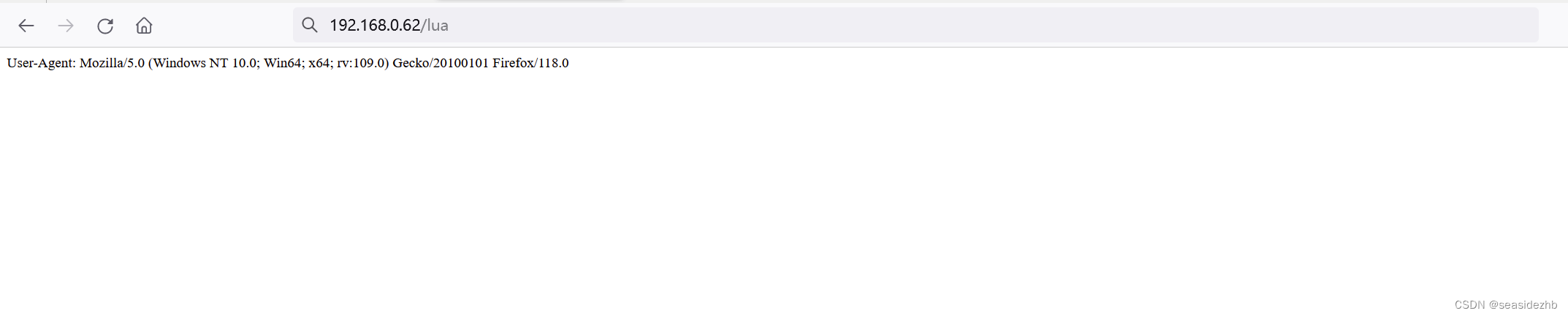
在Openresty中使用lua语言向请求浏览器返回请求头User-Agent里边的值
可以参考《Linux学习之Ubuntu 20.04在https://openresty.org下载源码安装Openresty 1.19.3.1,使用systemd管理OpenResty服务》安装Openresty。 然后把下边的内容写入到openresty配置文件/usr/local/openresty/nginx/conf/nginx.conf(根据实际情况进行选…...

Hive面试常见基础问题
以下是一些Hive面试问题和答案: Hive是什么? 答:Hive是一个开源的数据仓库工具,用于处理和分析大规模结构化数据。它能够创建、修改和查询表结构,支持多种数据类型和查询操作,同时提供数据汇总和数据查询的…...
设计模式 - 观察者模式
目录 一. 前言 二. 实现 三. 优缺点 一. 前言 观察者模式属于行为型模式。在程序设计中,观察者模式通常由两个对象组成:观察者和被观察者。当被观察者状态发生改变时,它会通知所有的观察者对象,使他们能够及时做出响应…...

【自动驾驶】PETR/PETRv2/StreamPETR论文分析
1.PETR PETR网络结构如下,主要包括image-backbone, 3D Coordinates Generator, 3D Position Encoder, transformer Decoder 1.1 Images Backbone 采用resnet 或者 vovNet,下面的x表示concatenate 1.2 3D Coordinates Generator 坐标生成跟lss类似,假…...

GPT实战系列-Baichuan2本地化部署实战方案
目录 一、百川2(Baichuan 2)模型介绍 二、资源需求 模型文件类型 推理的GPU资源要求 模型获取途径 国外: Huggingface 国内:ModelScope 三、部署安装 配置环境 安装过程...

用netty实现简易rpc
文章目录 rpc介绍:rpc调用流程:代码: rpc介绍: RPC是远程过程调用(Remote Procedure Call)的缩写形式。SAP系统RPC调用的原理其实很简单,有一些类似于三层构架的C/S系统,第三方的客户程序通过接…...

【计算机网络】第三章课后习题答案
习题目录: 【3-01】数据链路(即逻辑链路)与链路(即物理链路)有何区别?"链路接通了"与"数据链路接通了"的区别何在? 【3-02】数据链路层中的链路控制包括哪些功能…...

OpenClaw宠物健康监测:Qwen2.5-VL-7B分析宠物照片发现异常
OpenClaw宠物健康监测:Qwen2.5-VL-7B分析宠物照片发现异常 1. 为什么需要AI宠物健康监测 作为一名养了三年猫的铲屎官,我经常担心错过宠物健康问题的早期信号。去年冬天,我家橘猫"橘子"突然食欲不振,带去医院才发现是…...

OpenClaw自动化测试:Qwen3-4B驱动接口回归验证
OpenClaw自动化测试:Qwen3-4B驱动接口回归验证 1. 为什么选择OpenClaw做自动化测试? 去年接手一个个人项目时,我遇到了一个典型问题:每次修改代码后,都要手动执行十几个接口测试用例。这种重复劳动不仅耗时ÿ…...

龙迅LT9211D芯片解析:如何实现MIPI与双端口LVDS的高效转换
1. 龙迅LT9211D芯片的核心价值 第一次接触龙迅LT9211D芯片是在一个车载显示项目上,当时客户要求实现4K视频从主控芯片到双屏显示的无损传输。这个看似简单的需求背后,其实隐藏着MIPI和LVDS两种信号标准的转换难题。LT9211D的出现完美解决了这个问题&…...

手把手教你用STM32CubeMX和HAL库驱动DW3000:从SPI配置到第一个测距Demo
零基础玩转DW3000:STM32CubeMXHAL库实现厘米级UWB测距全指南 当我们需要在仓库里快速定位某个货架上的商品,或是让扫地机器人精准识别家具位置时,传统GPS和蓝牙方案的精度往往捉襟见肘。这正是UWB(超宽带)技术大显身手…...

OAK-D-S2/FFC系列深度校准实战:从原理到提升精度的几个关键技巧
OAK-D-S2/FFC系列深度校准实战:从原理到提升精度的几个关键技巧 深度相机校准是计算机视觉领域的一项基础但至关重要的技术。对于OAK-D-S2和FFC系列这样的高性能设备,校准质量直接决定了深度图的精度和可靠性。本文将带您深入理解校准背后的数学原理&am…...

别只盯着TCP!拆解大疆源码里MQTT协议的双通道设计:BASIC与DRC到底有啥区别?
大疆源码中的MQTT双通道设计:BASIC与DRC的工程哲学 在分析大疆无人机开源项目的通信架构时,一个有趣的设计选择跃然眼前——MQTT协议同时运行在TCP和WebSocket两种传输层上。这种看似冗余的配置背后,隐藏着对物联网通信场景的深刻理解。本文将…...

手写数字识别在FPGA上的暴力美学
fpga实现cnn神经网络加速 手写字硬件加速 FPGA artix7-100t 纯verilog编写 神经网络硬件加速 使用ov5640摄像头dvp接口 verilog实现手写字识别 包括卷积层、全连接层、池化层、softmax,有效减轻误识别问题注意: 该项目并未使用到arm核,是使用传统…...

失业期PHP程序员极致利用时间的庖丁解
"失业期 PHP 程序员极致利用时间”,常被误解为“疯狂投简历”或“没日没夜地刷 LeetCode”。 但本质上,这是一场**“认知重构”与“资产增值”的特种战役**。 失业不是“空窗期”,而是上帝强行塞给你的**“全脱产战略转型期”**。 在在职…...

4大维度构建高可靠性加密货币自动交易系统
4大维度构建高可靠性加密货币自动交易系统 【免费下载链接】binance-trade-bot Automated cryptocurrency trading bot 项目地址: https://gitcode.com/gh_mirrors/bi/binance-trade-bot 一、价值定位:为什么专业交易者都在用自动化交易工具? 为…...

魔兽争霸3 Windows 11兼容性终极解决方案:让你的经典游戏重获新生
魔兽争霸3 Windows 11兼容性终极解决方案:让你的经典游戏重获新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在Windo…...