【PostgreSQL内核学习(十八)—— (数据库表参数)】
数据库表参数
- default_reloptions 函数
- 案例
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了《PostgresSQL数据库内核分析》一书,OpenGauss1.1.0 的开源代码和《OpenGauss数据库源码解析》一书以及OpenGauss社区学习文档
default_reloptions 函数
default_reloptions 函数是一个选项解析器,用于处理与数据库关系(表或视图)相关的选项。它接受一个包含关系选项的参数,然后解析和验证这些选项,将它们存储在一个特定的数据结构中(StdRdOptions)。这个函数的主要目的是允许用户或数据库管理员通过选项来自定义和配置关系的各种属性和行为,例如填充因子、自动化清理策略、安全性设置等。它是数据库系统中对关系配置的重要组成部分,以实现更好的性能和行为控制。
default_reloptions 函数的作用是接收传入的关系选项(以二进制形式表示),然后将这些选项解析和验证,最后将它们存储在一个特定的数据结构(StdRdOptions)中,以便在数据库系统中配置和管理关系的各种属性和行为,如填充因子、自动化清理策略、安全性设置等。这个函数允许数据库管理员或应用程序开发人员根据需要自定义和配置关系的行为和性能特性。
default_reloptions 函数源码如下所示:(路径:src/gausskernel/storage/access/common/reloptions.cpp)
/* * 为使用StdRdOptions的任何内容(例如fillfactor和autovacuum)提供选项解析器* reloptions:传入的关系选项,以二进制形式表示* validate:指示是否进行验证的标志* kind:关系选项的类型,通常是RELOPT_KIND_HEAP或RELOPT_KIND_TOAST*/
bytea *default_reloptions(Datum reloptions, bool validate, relopt_kind kind)
{relopt_value *options = NULL; // 存储解析后的选项值的数组StdRdOptions *rdopts = NULL; // 存储最终结果的数据结构int numoptions; // 选项数量static const relopt_parse_elt tab[] = {// 定义选项名称、类型和存储位置的映射数组// 每个元素包括选项名称、数据类型和在StdRdOptions结构中的偏移量// 用于将选项值解析到对应的字段中// 更多选项可以在这里添加{ "fillfactor", RELOPT_TYPE_INT, offsetof(StdRdOptions, fillfactor) },{ "autovacuum_enabled", RELOPT_TYPE_BOOL, offsetof(StdRdOptions, autovacuum) + offsetof(AutoVacOpts, enabled) },{ "autovacuum_vacuum_threshold", RELOPT_TYPE_INT,offsetof(StdRdOptions, autovacuum) + offsetof(AutoVacOpts, vacuum_threshold) },{ "autovacuum_analyze_threshold", RELOPT_TYPE_INT,offsetof(StdRdOptions, autovacuum) + offsetof(AutoVacOpts, analyze_threshold) },{ "autovacuum_vacuum_cost_delay", RELOPT_TYPE_INT,offsetof(StdRdOptions, autovacuum) + offsetof(AutoVacOpts, vacuum_cost_delay) },{ "autovacuum_vacuum_cost_limit", RELOPT_TYPE_INT,offsetof(StdRdOptions, autovacuum) + offsetof(AutoVacOpts, vacuum_cost_limit) },{ "autovacuum_freeze_min_age", RELOPT_TYPE_INT64,offsetof(StdRdOptions, autovacuum) + offsetof(AutoVacOpts, freeze_min_age) },{ "autovacuum_freeze_max_age", RELOPT_TYPE_INT64,offsetof(StdRdOptions, autovacuum) + offsetof(AutoVacOpts, freeze_max_age) },{ "autovacuum_freeze_table_age", RELOPT_TYPE_INT64,offsetof(StdRdOptions, autovacuum) + offsetof(AutoVacOpts, freeze_table_age) },{ "autovacuum_vacuum_scale_factor", RELOPT_TYPE_REAL,offsetof(StdRdOptions, autovacuum) + offsetof(AutoVacOpts, vacuum_scale_factor) },{ "autovacuum_analyze_scale_factor", RELOPT_TYPE_REAL,offsetof(StdRdOptions, autovacuum) + offsetof(AutoVacOpts, analyze_scale_factor) },{ "security_barrier", RELOPT_TYPE_BOOL, offsetof(StdRdOptions, security_barrier) },{ "enable_rowsecurity", RELOPT_TYPE_BOOL, offsetof(StdRdOptions, enable_rowsecurity) },{ "force_rowsecurity", RELOPT_TYPE_BOOL, offsetof(StdRdOptions, force_rowsecurity) },{ "enable_tsdb_delta", RELOPT_TYPE_BOOL, offsetof(StdRdOptions, enable_tsdb_delta) },{ "tsdb_deltamerge_interval", RELOPT_TYPE_INT, offsetof(StdRdOptions, tsdb_deltamerge_interval) },{ "tsdb_deltamerge_threshold", RELOPT_TYPE_INT, offsetof(StdRdOptions, tsdb_deltamerge_threshold) },{ "tsdb_deltainsert_threshold", RELOPT_TYPE_INT, offsetof(StdRdOptions, tsdb_deltainsert_threshold) },{ "max_batchrow", RELOPT_TYPE_INT, offsetof(StdRdOptions, max_batch_rows) },{ "deltarow_threshold", RELOPT_TYPE_INT, offsetof(StdRdOptions, delta_rows_threshold) },{ "partial_cluster_rows", RELOPT_TYPE_INT, offsetof(StdRdOptions, partial_cluster_rows) },{ "internal_mask", RELOPT_TYPE_INT, offsetof(StdRdOptions, internalMask) },{ "orientation", RELOPT_TYPE_STRING, offsetof(StdRdOptions, orientation) },{ "compression", RELOPT_TYPE_STRING, offsetof(StdRdOptions, compression) },{"table_access_method", RELOPT_TYPE_STRING, offsetof(StdRdOptions, table_access_method)},{ "ttl", RELOPT_TYPE_STRING, offsetof(StdRdOptions, ttl) },{ "period", RELOPT_TYPE_STRING, offsetof(StdRdOptions, period) },{ "string_optimize", RELOPT_TYPE_STRING, offsetof(StdRdOptions, string_optimize) },{ "partition_interval", RELOPT_TYPE_STRING, offsetof(StdRdOptions, partition_interval) },{ "time_column", RELOPT_TYPE_STRING, offsetof(StdRdOptions, time_column) },{ "ttl_interval", RELOPT_TYPE_STRING, offsetof(StdRdOptions, ttl_interval) },{ "gather_interval", RELOPT_TYPE_STRING, offsetof(StdRdOptions, gather_interval) },{ "version", RELOPT_TYPE_STRING, offsetof(StdRdOptions, version) },{ "compresslevel", RELOPT_TYPE_INT, offsetof(StdRdOptions, compresslevel) },{ "ignore_enable_hadoop_env", RELOPT_TYPE_BOOL, offsetof(StdRdOptions, ignore_enable_hadoop_env) },{ "append_mode", RELOPT_TYPE_STRING, offsetof(StdRdOptions, append_mode) },{ "merge_list", RELOPT_TYPE_STRING, offsetof(StdRdOptions, merge_list) },{ "rel_cn_oid", RELOPT_TYPE_INT, offsetof(StdRdOptions, rel_cn_oid) },{ "append_mode_internal", RELOPT_TYPE_INT, offsetof(StdRdOptions, append_mode_internal) },{ "start_ctid_internal", RELOPT_TYPE_STRING, offsetof(StdRdOptions, start_ctid_internal) },{ "end_ctid_internal", RELOPT_TYPE_STRING, offsetof(StdRdOptions, end_ctid_internal) },{ "user_catalog_table", RELOPT_TYPE_BOOL, offsetof(StdRdOptions, user_catalog_table) },{ "hashbucket", RELOPT_TYPE_BOOL, offsetof(StdRdOptions, hashbucket) },{ "primarynode", RELOPT_TYPE_BOOL, offsetof(StdRdOptions, primarynode) },{ "on_commit_delete_rows", RELOPT_TYPE_BOOL, offsetof(StdRdOptions, on_commit_delete_rows)},{ "wait_clean_gpi", RELOPT_TYPE_STRING, offsetof(StdRdOptions, wait_clean_gpi)}};// 解析传入的关系选项,将其存储在options数组中,并返回选项数量options = parseRelOptions(reloptions, validate, kind, &numoptions);/* if none set, we're done */// 如果没有设置任何选项,则返回NULLif (numoptions == 0)return NULL;// 为rdopts分配内存,根据StdRdOptions结构的大小以及选项数量rdopts = (StdRdOptions *)allocateReloptStruct(sizeof(StdRdOptions), options, numoptions);// 使用解析后的选项填充rdopts结构,将选项值分配到对应的字段中fillRelOptions((void *)rdopts, sizeof(StdRdOptions), options, numoptions, validate, tab, lengthof(tab));// 释放options数组中的字符串值的内存for (int i = 0; i < numoptions; i++) {if (options[i].gen->type == RELOPT_TYPE_STRING && options[i].isset)pfree(options[i].values.string_val);}pfree(options);// 返回结果,以bytea类型的数据返回StdRdOptions结构return (bytea *)rdopts;
}
其中,表(或关系)的选项的配置如下表所示:
| 参 数 | 含 义 |
|---|---|
| fillfactor | 设置表的填充因子,用于指定在表的数据页中保留多少空间,以便将来插入新行。 |
| autovacuum_enabled | 一个布尔值,指定是否启用了自动化清理和分析。 |
| autovacuum_vacuum_threshold | 自动清理操作的触发阈值,当表中的行数超过此阈值时,将执行自动清理操作。 |
| autovacuum_analyze_threshold | 自动分析操作的触发阈值,当表中的行数超过此阈值时,将执行自动分析操作。 |
| autovacuum_vacuum_cost_delay | 自动清理操作的成本延迟,以控制其执行速度。 |
| autovacuum_vacuum_cost_limit | 自动清理操作的成本限制,以控制资源消耗。 |
| autovacuum_freeze_min_age | 触发自动冻结的最小年龄,用于维护事务ID冻结的表。 |
| autovacuum_freeze_max_age | 触发自动冻结的最大年龄,用于维护事务ID冻结的表。 |
| autovacuum_freeze_table_age | 自动冻结表的年龄,用于维护事务ID冻结的表。 |
| autovacuum_vacuum_scale_factor | 自动清理的比例因子。 |
| autovacuum_analyze_scale_factor | 自动分析的比例因子。 |
| security_barrier | 一个布尔值,指定是否启用了安全屏障。 |
| enable_rowsecurity | 一个布尔值,指定是否启用了行级安全性。 |
| force_rowsecurity | 一个布尔值,指定是否强制启用了行级安全性。 |
| enable_tsdb_delta | 一个布尔值,指定是否启用了时序数据库(TSDB)的增量数据存储。 |
| tsdb_deltamerge_interval | TSDB增量数据合并的时间间隔。 |
| tsdb_deltamerge_threshold | TSDB增量数据合并的阈值。 |
| tsdb_deltainsert_threshold | TSDB增量数据插入的阈值。 |
| max_batchrow | 最大批量行数。 |
| deltarow_threshold | 增量行的阈值。 |
| partial_cluster_rows | 部分聚集行的数量。 |
| internal_mask | 内部掩码。 |
| orientation | 表的方向。 |
| compression | 数据的压缩方式。 |
| table_access_method | 表的访问方法。 |
| ttl | 表的生存时间。 |
| period | 表的周期。 |
| string_optimize | 字符串优化。 |
| partition_interval | 分区间隔。 |
| time_column | 时间列。 |
| ttl_interval | 生存时间间隔。 |
| gather_interval | 聚集间隔。 |
| version | 版本。 |
| compresslevel | 压缩级别。 |
| ignore_enable_hadoop_env | 是否忽略启用Hadoop环境。 |
| append_mode | 附加模式。 |
| merge_list | 合并列表。 |
| rel_cn_oid | 关系CN OID。 |
| append_mode_internal | 内部附加模式。 |
| start_ctid_internal | 内部起始CTID。 |
| end_ctid_internal | 内部结束CTID。 |
| user_catalog_table | 是否为用户目录表。 |
| hashbucket | 是否为哈希桶。 |
| primarynode | 是否为主节点。 |
| on_commit_delete_rows | 提交时删除行。 |
| wait_clean_gpi | 等待清理GPI。 |
这些选项配置了表的各种属性和行为,以满足特定的数据库需求。
案例
接下来,我们通过几个案例来观察其中的几个代表参数的实际作用,来了解一下这些参数的意义。具体案例如下:
1. 创建存储表,执行以下 SQL 语句:
CREATE TABLE test_table (id serial PRIMARY KEY,name text
) WITH (fillfactor = 70, -- 设置填充因子autovacuum_enabled = true, -- 启用自动清理和分析autovacuum_vacuum_threshold = 1000, -- 自动清理触发阈值autovacuum_analyze_threshold = 500, -- 自动分析触发阈值autovacuum_vacuum_cost_delay = 10, -- 自动清理成本延迟autovacuum_vacuum_cost_limit = 1000, -- 自动清理成本限制compression = 'lz4' -- 数据压缩方式
);postgres=# \d+ test_tableTable "public.test_table"Column | Type | Modifiers | Storage | Stats target | Description
--------+---------+---------------------------------------------------------+----------+--------------+-------------id | integer | not null default nextval('test_table_id_seq'::regclass) | plain | |name | text | | extended | |
Has OIDs: no
Options: orientation=column, autovacuum_enabled=true, autovacuum_analyze_threshold=500, compression=low
2. 插入一些示例数据到列存储表中:
DO $$
DECLAREcounter INT := 1;
BEGINFOR counter IN 1..1500 LOOPINSERT INTO test_table (name) VALUES ('Item ' || counter);END LOOP;
END $$;postgres=# select * from test_table;id | name
------+-----------1 | Item 12 | Item 23 | Item 34 | Item 45 | Item 56 | Item 67 | Item 78 | Item 89 | Item 910 | Item 1011 | Item 1112 | Item 1213 | Item 1314 | Item 1415 | Item 1516 | Item 1617 | Item 1718 | Item 1819 | Item 1920 | Item 2021 | Item 2122 | Item 2223 | Item 2324 | Item 2425 | Item 2526 | Item 2627 | Item 2728 | Item 2829 | Item 2930 | Item 3031 | Item 3132 | Item 3233 | Item 3334 | Item 3435 | Item 3536 | Item 3637 | Item 3738 | Item 3839 | Item 39
--More--
3. 执行自动分析并查看统计信息:
SELECT schemaname,relname,last_vacuum,last_autovacuum,last_analyze,last_autoanalyze,vacuum_count,autovacuum_count,analyze_count,autoanalyze_count
FROM pg_stat_all_tables
WHERE relname = 'test_table';schemaname | relname | last_vacuum | last_autovacuum | last_analyze | last_autoanalyze | vacuum_count | autovacuum_count | anal
yze_count | autoanalyze_count
------------+------------+-------------+-----------------+-------------------------------+-------------------------------+--------------+------------------+-----
----------+-------------------public | test_table | | | 2023-10-07 11:32:20.377228+08 | 2023-10-07 11:32:20.377228+08 | 0 | 0 |1 | 1
(1 row)
可以看到,当表中的数据量达到自动分触发阈值时 autovacuum_analyze_threshold ,则会执行自动分析 autoanalyze。
4. 执行自动清理:
在PostgreSQL数据库中,自动触发autovacuum_vacuum_threshold选项所定义的自动清理(autovacuum)操作通常由数据库自身的内部机制控制。autovacuum_vacuum_threshold是一个配置选项,它定义了当表中的行数达到指定阈值时,自动触发VACUUM操作的条件。
要触发自动清理,需要满足以下条件:
- 表的行数超过了autovacuum_vacuum_threshold所定义的阈值。
- 自动清理(autovacuum)进程处于活动状态,通常是后台运行的自动清理进程。
自动清理进程会定期检查表的状态并根据一系列配置选项来决定是否执行VACUUM操作。autovacuum_vacuum_threshold只是其中之一。其他配置选项还包括autovacuum_analyze_threshold、autovacuum_freeze_max_age等,它们影响了自动清理的行为。
需要注意的是,autovacuum进程通常会在数据库空闲时执行自动清理操作,以避免干扰正在进行的活动查询和事务。此外,autovacuum的行为也可以通过其他配置选项进行微调,以满足特定应用场景的需求。
总之,要触发autovacuum_vacuum_threshold自动清理,需要确保表的行数达到了指定阈值,并确保autovacuum进程处于活动状态,它会自动监测并执行相应的清理操作。
SELECT schemaname,relname,last_vacuum,last_autovacuum,last_analyze,last_autoanalyze,vacuum_count,autovacuum_count,analyze_count,autoanalyze_count
FROM pg_stat_all_tables
WHERE relname = 'test_table';schemaname | relname | last_vacuum | last_autovacuum | last_analyze | last_autoanalyze | vacuum_count | autov
acuum_count | analyze_count | autoanalyze_count
------------+------------+-------------------------------+-----------------+-------------------------------+-------------------------------+--------------+------
------------+---------------+-------------------public | test_table | 2023-10-07 15:35:41.430136+08 |2023-10-07 15:35:41.430136+08| 2023-10-07 15:32:22.660942+08 | 2023-10-07 15:32:22.660942+08 | 1 |0 | 2 | 2
(1 row)
这里不一一列举表(或关系)的选项的配置的案例,如需要详细了解可以查询相关手册。
相关文章:
—— (数据库表参数)】)
【PostgreSQL内核学习(十八)—— (数据库表参数)】
数据库表参数 default_reloptions 函数案例 声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。 本文主要参考了《PostgresSQL数据库内核…...
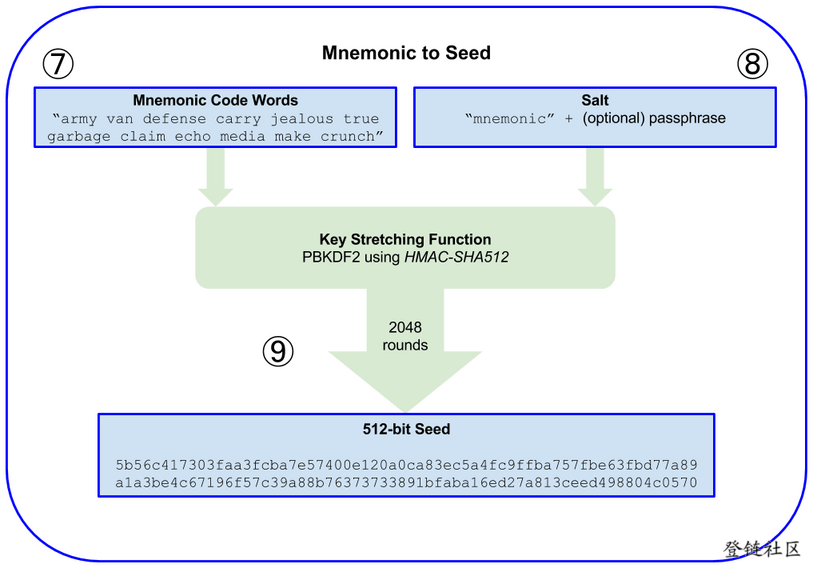
区块链的两个核心概念之一签名, 另一个是共识.
Alice的公私钥, 签名和验证签名仅仅确定了Alice对数字资产A所有权的宣言. 之后, Bob也可以用自己的私钥对资产A进行签名宣誓所有权。区块链中叫双花,即重复宣称所有权, 也称重复花费交易。这时候需要共识算法(集体成员pow或委员会代表pos监督…...
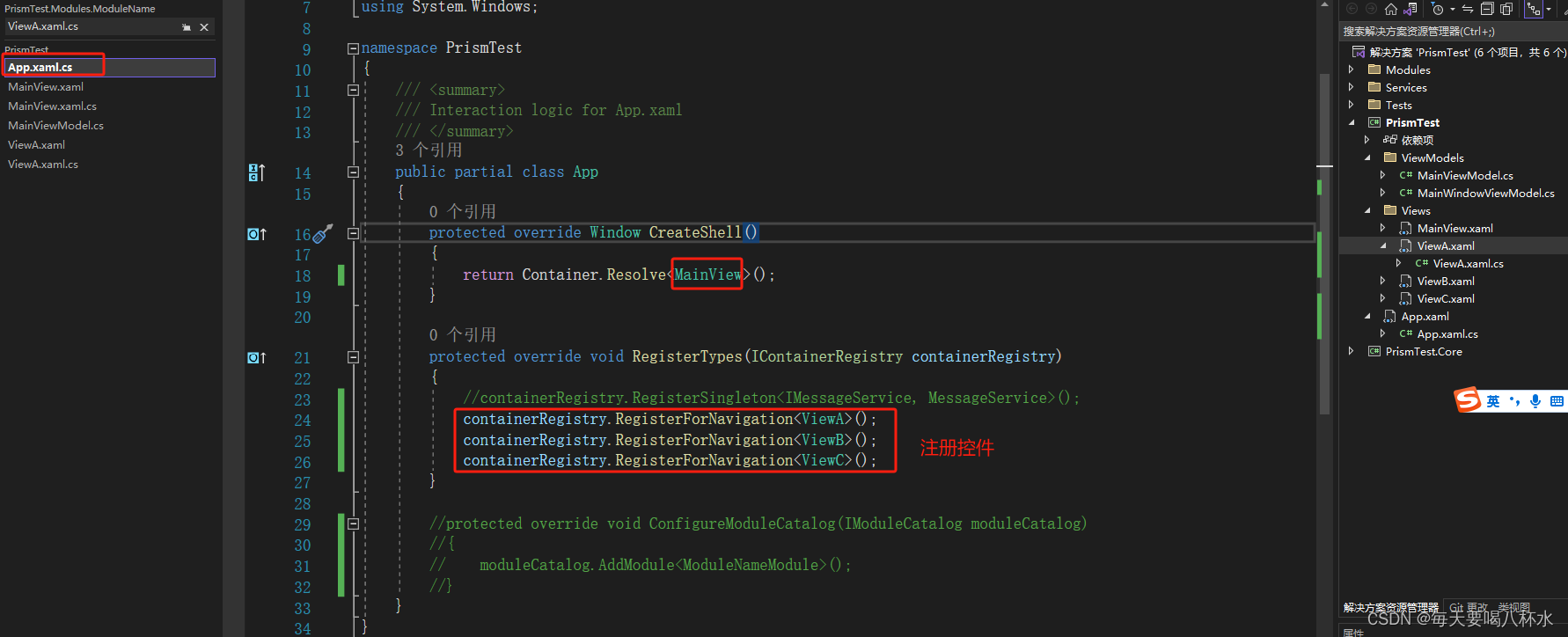
wpf中prism框架切换页面
主页面...
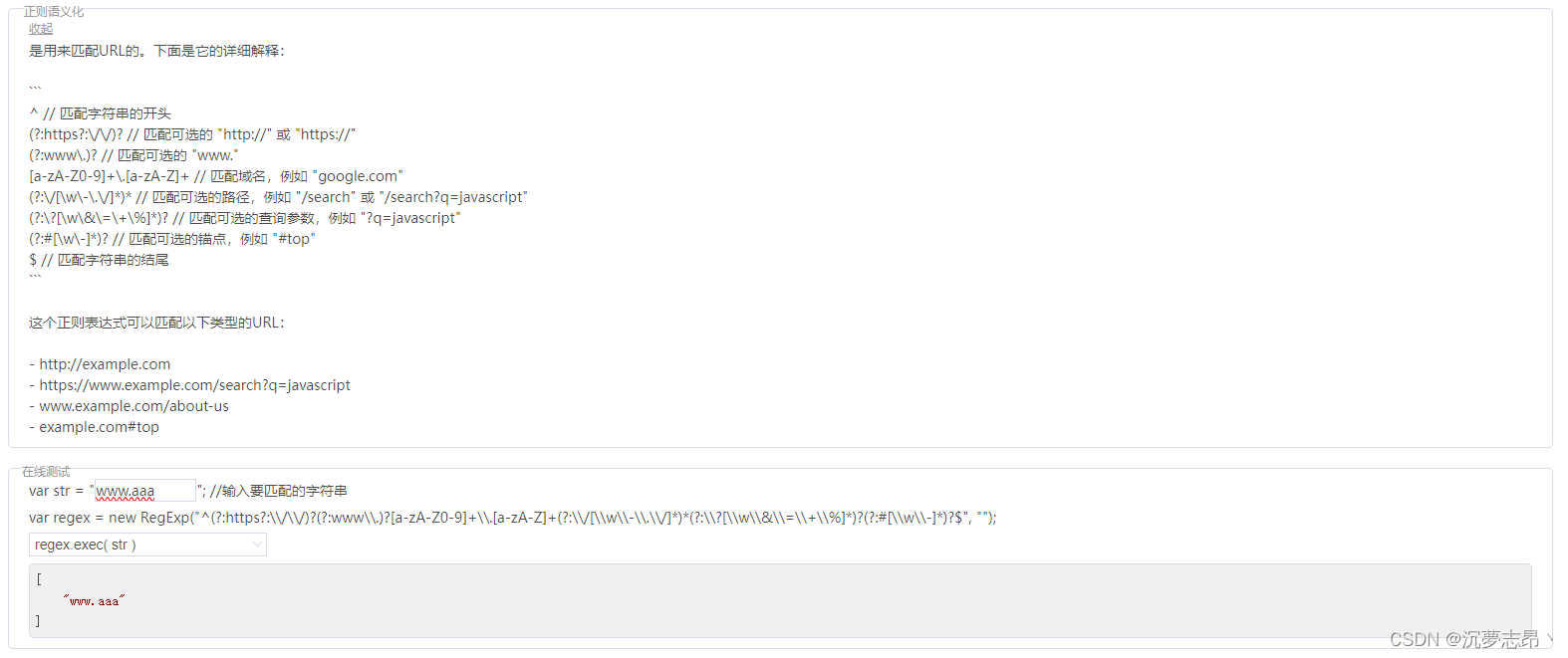
正则表达式(Regular Expression)学习网址分享
正则表达式(Regular expressions,也叫REs、 regexs 或regex patterns),是一种文本模式,包括普通字符(例如,a 到z 之间的字母)和特殊字符(称为"元字符"…...
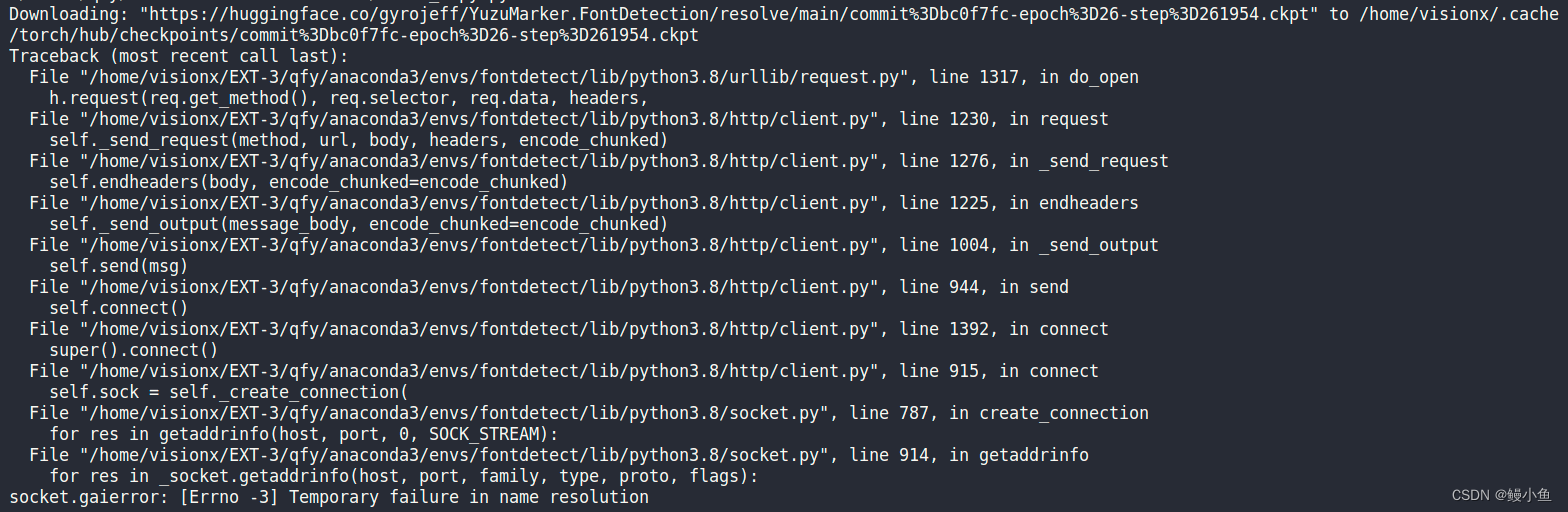
【已解决】socket.gaierror: [Errno -3] Temporary failure in name resolution
问题描述 今天在环境迁移的过程中遇到多个问题,包括ModuleNotFoundError: No module named flask,socket.gaierror: [Errno -3] Temporary failure in name resolution以及Downloading: "https://huggingface.co/gyrojeff/YuzuMarker.FontDetection…...
 报错与排查方法)
CUDA code=700(cudaErrorIllegalAddress) 报错与排查方法
CUDA code700(cudaErrorIllegalAddress) 报错与排查方法 最近笔者在调试自己写的 CUDA 代码时, 遇到了 code700(cudaErrorIllegalAddress) 的报错, 在此记录一下排查和解决方法. 报错 报错是由 CUDA API 函数执行时产生的, 由 checkCudaErrors() 函数检测出(CUDA 常用错误检…...

项目管理过程组
项目管理有2条主线,一条是技术,一条是管理。项目过程由项目团队实施。一般术语以下两大类之一:一类是项目管理过程。另一类是面向产品的过程。在大多数情况下,大多数项目都有共同的项目管理过程。它们通过有目的的实施而互相联系起…...

python每日一练(5)
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...

经典循环命题:百钱百鸡
翁五钱一只,母三钱,小鸡三只一钱;百钱百鸡百鸡花百钱。 (本笔记适合能熟练应用for循环、会使if条件分支语句、能格式化字符输出的 coder 翻阅) 【学习的细节是欢悦的历程】 Python 官网:https://www.python.org/ Free:…...
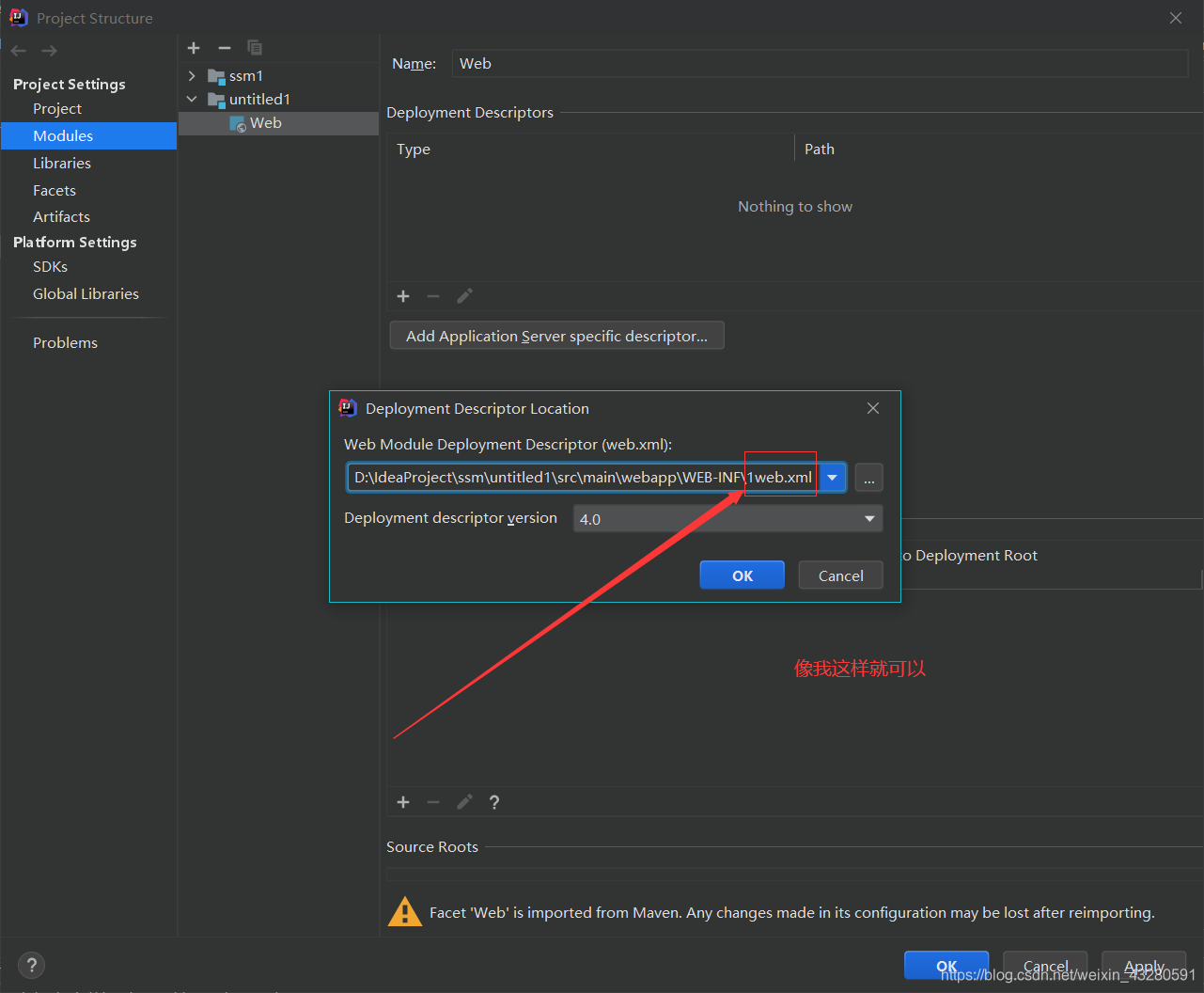
IDEA使用模板创建webapp时,web.xml文件版本过低的一种解决方法
创建完成后的web.xml 文件,版本太低 <!DOCTYPE web-app PUBLIC"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN""http://java.sun.com/dtd/web-app_2_3.dtd" ><web-app><display-name>Archetype Created Web Appl…...
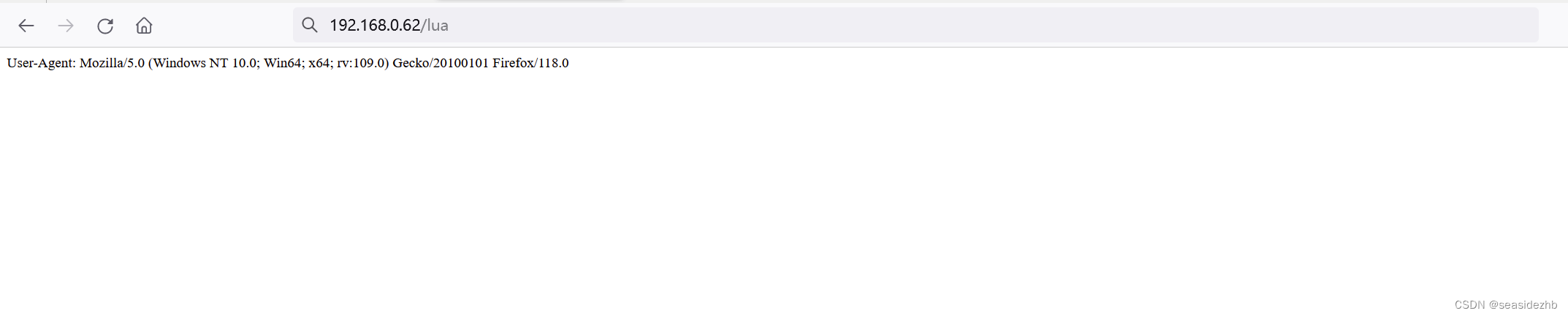
在Openresty中使用lua语言向请求浏览器返回请求头User-Agent里边的值
可以参考《Linux学习之Ubuntu 20.04在https://openresty.org下载源码安装Openresty 1.19.3.1,使用systemd管理OpenResty服务》安装Openresty。 然后把下边的内容写入到openresty配置文件/usr/local/openresty/nginx/conf/nginx.conf(根据实际情况进行选…...

Hive面试常见基础问题
以下是一些Hive面试问题和答案: Hive是什么? 答:Hive是一个开源的数据仓库工具,用于处理和分析大规模结构化数据。它能够创建、修改和查询表结构,支持多种数据类型和查询操作,同时提供数据汇总和数据查询的…...
设计模式 - 观察者模式
目录 一. 前言 二. 实现 三. 优缺点 一. 前言 观察者模式属于行为型模式。在程序设计中,观察者模式通常由两个对象组成:观察者和被观察者。当被观察者状态发生改变时,它会通知所有的观察者对象,使他们能够及时做出响应…...

【自动驾驶】PETR/PETRv2/StreamPETR论文分析
1.PETR PETR网络结构如下,主要包括image-backbone, 3D Coordinates Generator, 3D Position Encoder, transformer Decoder 1.1 Images Backbone 采用resnet 或者 vovNet,下面的x表示concatenate 1.2 3D Coordinates Generator 坐标生成跟lss类似,假…...

GPT实战系列-Baichuan2本地化部署实战方案
目录 一、百川2(Baichuan 2)模型介绍 二、资源需求 模型文件类型 推理的GPU资源要求 模型获取途径 国外: Huggingface 国内:ModelScope 三、部署安装 配置环境 安装过程...

用netty实现简易rpc
文章目录 rpc介绍:rpc调用流程:代码: rpc介绍: RPC是远程过程调用(Remote Procedure Call)的缩写形式。SAP系统RPC调用的原理其实很简单,有一些类似于三层构架的C/S系统,第三方的客户程序通过接…...

【计算机网络】第三章课后习题答案
习题目录: 【3-01】数据链路(即逻辑链路)与链路(即物理链路)有何区别?"链路接通了"与"数据链路接通了"的区别何在? 【3-02】数据链路层中的链路控制包括哪些功能…...

cesium 地图蒙版遮罩效果
示例代码 <!DOCTYPE html> <html lang"en"><head><!-- Use correct character set. --><meta charset"utf-8" /><!-- Tell IE to use the latest, best version. --><meta http-equiv"X-UA-Compatible"…...

根据前序遍历结果构造二叉搜索树
根据前序遍历结果构造二叉搜索树-力扣 1008 题 题目说明: 1.preorder 长度>1 2.preorder 没有重复值 直接插入 解题思路: 数组索引[0]的位置为根节点,与根节点开始比较,比根节点小的就往左边插,比根节点大的就往右…...

微信小程序指定某个元素强制重新渲染
之前写过 vue强制让某个元素重新渲染 利用了vue中的 v-if会控制元素是否挂载 以及 $nextTick 等待响应式更改生效再执行的特性 小程序也都有类似的方法 我们可以这样 wxml <view wx:if"{{min true}}">你好</view>用 wx:if 作用和v-if是一样的 js th…...

CubeIDE用户看过来:当你的STM32板载CMSIS-DAP不被支持时,3种实用的替代烧录方案
CubeIDE用户实战指南:当CMSIS-DAP不被支持时的3种高效烧录方案 作为一名长期使用STM32CubeIDE的开发者,你一定遇到过这样的尴尬场景——手头的开发板明明集成了CMSIS-DAP仿真器,却因为CubeIDE的兼容性问题无法直接使用。这种"看得见却用…...

OpenClaw个人财务助手:Qwen3-14B分析消费记录生成报表
OpenClaw个人财务助手:Qwen3-14B分析消费记录生成报表 1. 为什么需要AI财务助手 上个月整理支付宝账单时,我盯着密密麻麻的消费记录发了半小时呆。餐饮、购物、交通的金额混在一起,根本分不清钱到底花在哪里。手动分类300多条记录后&#x…...

【AI实战项目】项目六:知识图谱构建与应用实战
分享一个大牛的人工智能教程。零基础!通俗易懂!风趣幽默!希望你也加入到人工智能的队伍中来!请轻击人工智能教程https://www.captainai.net/troubleshooter 项目背景: 在当今信息爆炸的时代,精准理解和应…...

火电行业低成本私有化 RAG 部署
全球 AI 算力市场正处于一场看不见的“围城”之中。 当苹果被曝出为了备战 iOS 18 的 AI 功能,疯狂扫货数千台 NVLX H100 GPU 集群,导致全球高端算力卡供货周期延长至 52 周以上时,对于传统重资产运营的行业——如火电企业——而言ÿ…...

通过“运行规程”智能体,让 RAG 秒变监盘专家!
在当今全球能源结构转型的宏大叙事下,火力发电厂正面临着前所未有的双重夹击:一边是波动性极大的新能源并网带来的调峰压力,另一边是极度严苛的碳排放法规。在集控室(Control Room)里,运行人员(…...
读懂?)
claw-code 源码详细分析:子系统目录地图——几十个顶层包如何用五条轴(会话 / 工具 / 扩展 / 入口 / 桥接)读懂?
范围:src/ 下 顶层包(含 */__init__.py 的目录)与 与会话/runtime 强相关的根模块;与 result/01_start.md 第十三节、「清单—路由—会话」叙事一致。1. 为什么用五条轴 src/ 里同时存在: 大量占位包(读 re…...
)
告别硬编码:用SqlSugar Expression动态构建多条件Left Join查询(附分页技巧)
告别硬编码:用SqlSugar Expression动态构建多条件Left Join查询(附分页技巧) 在后台管理系统开发中,数据列表查询是最常见的需求之一。面对复杂的多表关联、动态筛选条件和分页需求,很多开发者会陷入字符串拼接SQL的泥…...
,Harness Engineering 从入门到精通,收藏这一篇就够了!)
AI Agent 时代工程范式革命全解(非常详细),Harness Engineering 从入门到精通,收藏这一篇就够了!
如果你最近在关注 AI 编程领域,一定刷到过这个词:Harness Engineering。 这个新概念正在以惊人的速度取代 Prompt Engineering 和 Context Engineering,成为 AI Agent 工程优化的正解。 今天这篇文章,我用自己的理解帮你理清楚。…...

最小二乘问题详解15:束平差原理与基础实现
初始两帧的 E 矩阵分解可能存在错误解或尺度模糊;三角化结果受位姿误差和图像噪声影响;PnP 的位姿估计会继承并放大前期误差。 随着图像数量增加,这些局部误差会不断累积,导致最终重建结果出现尺度漂移、结构扭曲甚至拓扑错误。要…...

2025Reddit养号实战:3步打造高Karma账号矩阵
1. Reddit养号基础:为什么Karma值如此重要? 如果你刚接触Reddit,可能会对这个平台的"Karma系统"感到困惑。简单来说,Karma就像你在Reddit社区里的信用积分,它决定了你的发言权和影响力。我刚开始运营Reddit账…...