Elasticsearch 分片内部原理—近实时搜索、持久化变更
目录
一、近实时搜索
refresh API
二、持久化变更
flush API
一、近实时搜索
随着按段(per-segment)搜索的发展,一个新的文档从索引到可被搜索的延迟显著降低了。新文档在几分钟之内即可被检索,但这样还是不够快。
磁盘在这里成为了瓶颈。提交(Commiting)一个新的段到磁盘需要一个 fsync 来确保段被物理性地写入磁盘,这样在断电的时候就不会丢失数据。 但是 fsync 操作代价很大; 如果每次索引一个文档都去执行一次的话会造成很大的性能问题。
我们需要的是一个更轻量的方式来使一个文档可被搜索,这意味着 fsync 要从整个过程中被移除。
在Elasticsearch和磁盘之间是文件系统缓存。 像之前描述的一样, 在内存索引缓冲区( Figure 19, “在内存缓冲区中包含了新文档的 Lucene 索引” )中的文档会被写入到一个新的段中( Figure 20, “缓冲区的内容已经被写入一个可被搜索的段中,但还没有进行提交” )。 但是这里新段会被先写入到文件系统缓存—这一步代价会比较低,稍后再被刷新到磁盘—这一步代价比较高。不过只要文件已经在缓存中, 就可以像其它文件一样被打开和读取了。
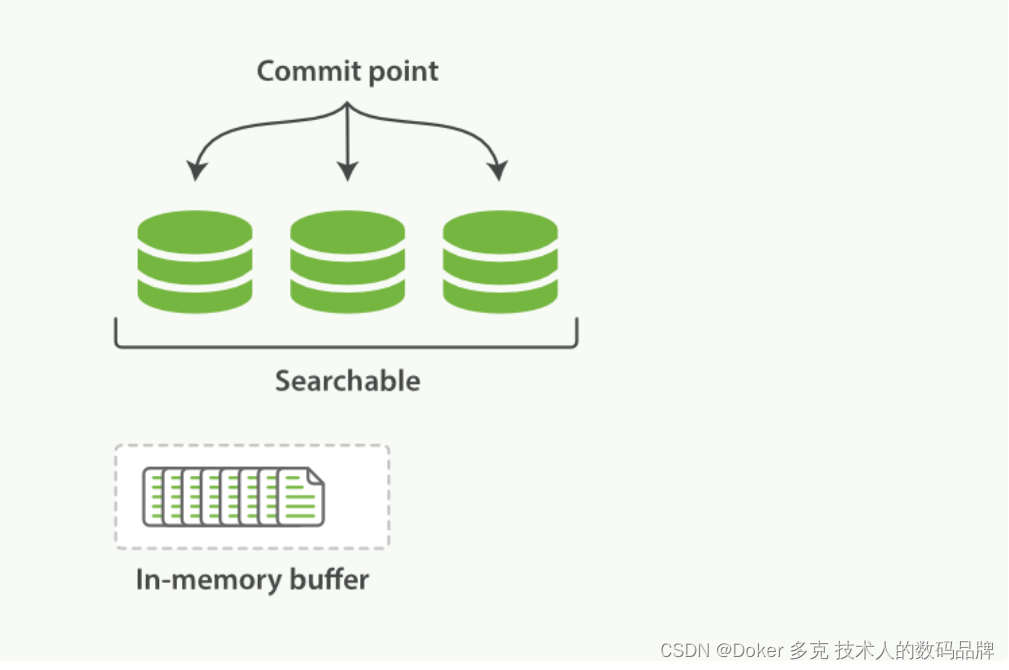
Figure 19. 在内存缓冲区中包含了新文档的 Lucene 索引
Lucene 允许新段被写入和打开—使其包含的文档在未进行一次完整提交时便对搜索可见。 这种方式比进行一次提交代价要小得多,并且在不影响性能的前提下可以被频繁地执行。
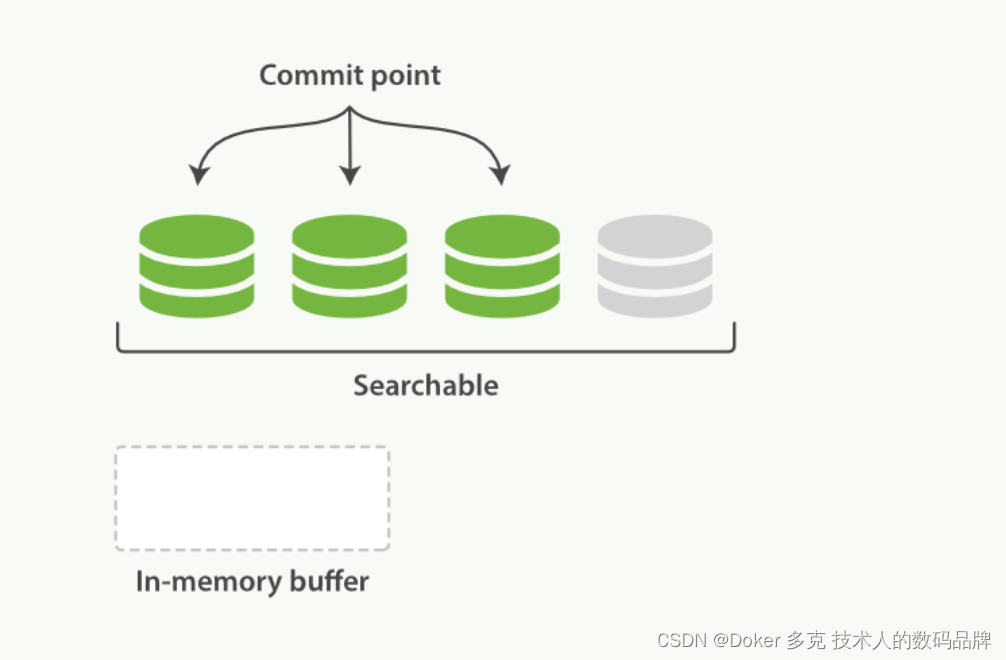
Figure 20. 缓冲区的内容已经被写入一个可被搜索的段中,但还没有进行提交
refresh API
在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 refresh 。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是 近 实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
这些行为可能会对新用户造成困惑: 他们索引了一个文档然后尝试搜索它,但却没有搜到。这个问题的解决办法是用 refresh API 执行一次手动刷新:
POST /_refresh
POST /blogs/_refresh 刷新(Refresh)所有的索引。
只刷新(Refresh) blogs 索引。
尽管刷新是比提交轻量很多的操作,它还是会有性能开销。当写测试的时候, 手动刷新很有用,但是不要在生产环境下每次索引一个文档都去手动刷新。 相反,你的应用需要意识到 Elasticsearch 的近实时的性质,并接受它的不足。
并不是所有的情况都需要每秒刷新。可能你正在使用 Elasticsearch 索引大量的日志文件, 你可能想优化索引速度而不是近实时搜索, 可以通过设置 refresh_interval , 降低每个索引的刷新频率:
PUT /my_logs
{"settings": {"refresh_interval": "30s" }
}每30秒刷新 my_logs 索引。
refresh_interval 可以在既存索引上进行动态更新。 在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来:
PUT /my_logs/_settings
{ "refresh_interval": -1 } PUT /my_logs/_settings
{ "refresh_interval": "1s" } 关闭自动刷新。
每秒自动刷新。
二、持久化变更
如果没有用 fsync 把数据从文件系统缓存刷(flush)到硬盘,我们不能保证数据在断电甚至是程序正常退出之后依然存在。为了保证 Elasticsearch 的可靠性,需要确保数据变化被持久化到磁盘。
在动态更新索引,我们说一次完整的提交会将段刷到磁盘,并写入一个包含所有段列表的提交点。Elasticsearch 在启动或重新打开一个索引的过程中使用这个提交点来判断哪些段隶属于当前分片。
即使通过每秒刷新(refresh)实现了近实时搜索,我们仍然需要经常进行完整提交来确保能从失败中恢复。但在两次提交之间发生变化的文档怎么办?我们也不希望丢失掉这些数据。
Elasticsearch 增加了一个 translog ,或者叫事务日志,在每一次对 Elasticsearch 进行操作时均进行了日志记录。通过 translog ,整个流程看起来是下面这样:
-
一个文档被索引之后,就会被添加到内存缓冲区,并且 追加到了 translog 。
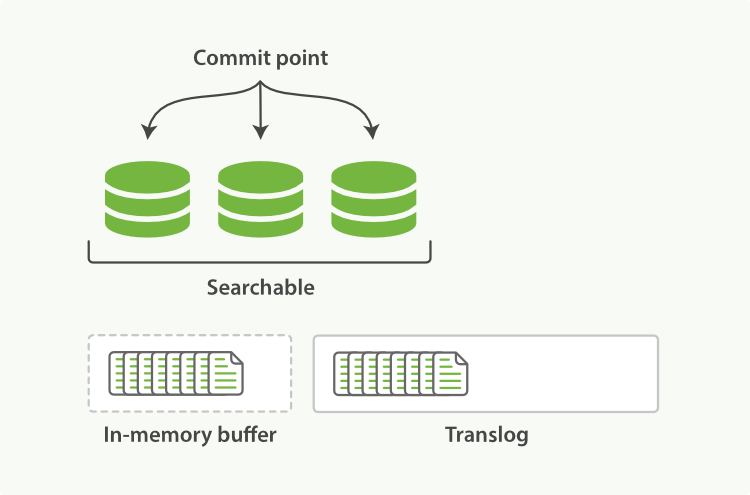
Figure 21. 新的文档被添加到内存缓冲区并且被追加到了事务日志
-
刷新(refresh)使分片处于 Figure 22, “刷新(refresh)完成后, 缓存被清空但是事务日志不会”描述的状态,分片每秒被刷新(refresh)一次:
- 这些在内存缓冲区的文档被写入到一个新的段中,且没有进行
fsync操作。 - 这个段被打开,使其可被搜索。
- 内存缓冲区被清空。
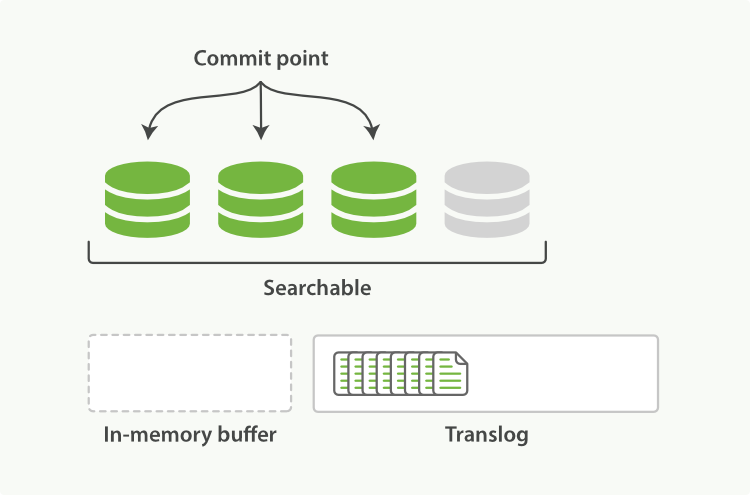
Figure 22. 刷新(refresh)完成后, 缓存被清空但是事务日志不会
- 这些在内存缓冲区的文档被写入到一个新的段中,且没有进行
-
这个进程继续工作,更多的文档被添加到内存缓冲区和追加到事务日志。
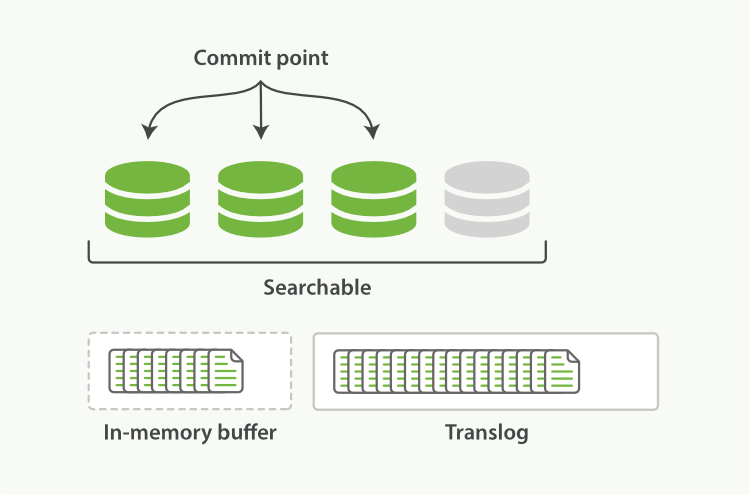
Figure 23. 事务日志不断积累文档
-
每隔一段时间—例如 translog 变得越来越大—索引被刷新(flush);一个新的 translog 被创建,并且一个全量提交被执行:
- 所有在内存缓冲区的文档都被写入一个新的段。
- 缓冲区被清空。
- 一个提交点被写入硬盘。
- 文件系统缓存通过
fsync被刷新(flush)。 - 老的 translog 被删除。
translog 提供所有还没有被刷到磁盘的操作的一个持久化纪录。当 Elasticsearch 启动的时候, 它会从磁盘中使用最后一个提交点去恢复已知的段,并且会重放 translog 中所有在最后一次提交后发生的变更操作。
translog 也被用来提供实时 CRUD 。当你试着通过ID查询、更新、删除一个文档,它会在尝试从相应的段中检索之前, 首先检查 translog 任何最近的变更。这意味着它总是能够实时地获取到文档的最新版本。
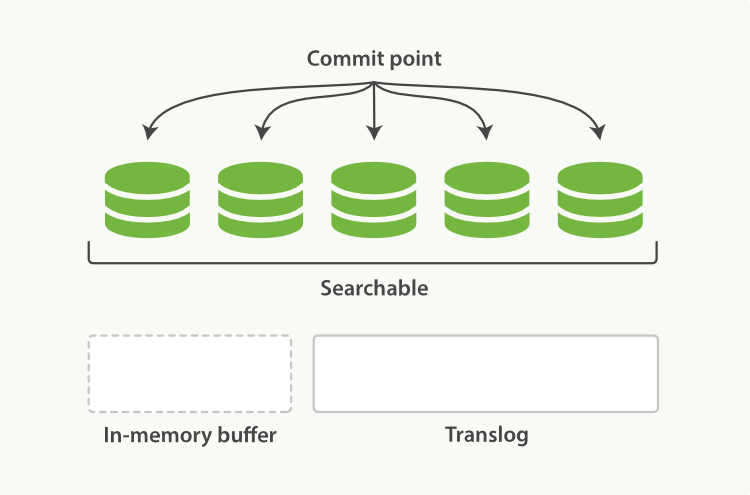
Figure 24. 在刷新(flush)之后,段被全量提交,并且事务日志被清空
flush API
这个执行一个提交并且截断 translog 的行为在 Elasticsearch 被称作一次 flush 。 分片每30分钟被自动刷新(flush),或者在 translog 太大的时候也会刷新。它可以用来 控制这些阈值:
flush API可以被用来执行一个手工的刷新(flush):
POST /blogs/_flush POST /_flush?wait_for_ongoing | 刷新(flush) | |
| 刷新(flush)所有的索引并且并且等待所有刷新在返回前完成。 |
你很少需要自己手动执行 flush 操作;通常情况下,自动刷新就足够了。
这就是说,在重启节点或关闭索引之前执行 flush 有益于你的索引。当 Elasticsearch 尝试恢复或重新打开一个索引, 它需要重放 translog 中所有的操作,所以如果日志越短,恢复越快。
Translog 有多安全?
translog 的目的是保证操作不会丢失。这引出了这个问题: Translog 有多安全?
在文件被 fsync 到磁盘前,被写入的文件在重启之后就会丢失。默认 translog 是每 5 秒被 fsync 刷新到硬盘, 或者在每次写请求完成之后执行(e.g. index, delete, update, bulk)。这个过程在主分片和复制分片都会发生。最终, 基本上,这意味着在整个请求被 fsync 到主分片和复制分片的translog之前,你的客户端不会得到一个 200 OK 响应。
在每次请求后都执行一个 fsync 会带来一些性能损失,尽管实践表明这种损失相对较小(特别是bulk导入,它在一次请求中平摊了大量文档的开销)。
但是对于一些大容量的偶尔丢失几秒数据问题也并不严重的集群,使用异步的 fsync 还是比较有益的。比如,写入的数据被缓存到内存中,再每5秒执行一次 fsync 。
这个行为可以通过设置 durability 参数为 async 来启用:
PUT /my_index/_settings
{"index.translog.durability": "async","index.translog.sync_interval": "5s"
}
这个选项可以针对索引单独设置,并且可以动态进行修改。如果你决定使用异步 translog 的话,你需要 保证 在发生crash时,丢失掉 sync_interval 时间段的数据也无所谓。请在决定前知晓这个特性。
如果你不确定这个行为的后果,最好是使用默认的参数( "index.translog.durability": "request" )来避免数据丢失。
相关文章:
Elasticsearch 分片内部原理—近实时搜索、持久化变更
目录 一、近实时搜索 refresh API 二、持久化变更 flush API 一、近实时搜索 随着按段(per-segment)搜索的发展,一个新的文档从索引到可被搜索的延迟显著降低了。新文档在几分钟之内即可被检索,但这样还是不够快。 磁盘在这…...

华为OD机试 - 用连续自然数之和来表达整数 - 滑动窗口(Java 2023 B卷 100分)
目录 专栏导读一、题目描述二、输入描述三、输出描述四、解题思路五、Java算法源码六、效果展示1、输入2、输出 华为OD机试 2023B卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试(JAVA)真题(A卷B卷)》…...

玩转ChatGPT:图像识别(vol. 1)
一、写在前面 来了来了,终于给我的账号开放图像识别功能了,话不多说,直接开测!!! 二、开始尝鲜 (1)咒语: GPT回复: 这幅图显示了从2005年1月到2012年12月的…...

oracle 数据库实验三
(1)向 ORCL数据库添加一个重做日志文件组(组号为5),包含一个成员文件d:\redo05a.log,大小为4MB ; 要向Oracle数据库添加一个重做日志文件组,您可以执行以下步骤: 连接到数据库&…...

多线程并发篇---第五篇
系列文章目录 文章目录 系列文章目录一、什么是线程安全二、Thread类中的yield方法有什么作用?三、Java线程池中submit() 和 execute()方法有什么区别?一、什么是线程安全 线程安全就是说多线程访问同一段代码,不会产生不确定的结果。 又是一个理论的问题,各式各样的答案有…...

java实现权重随机获取值或对象
文章目录 场景TreeMap.tailMap方法简单分析使用随机值使用treemap实现权重取值将Int改为Double稍微准确一点,因为double随机的值更加多测试main方法 当权重的参数比较多,那么建议使用hutool封装的 场景 按照权重2,8给用户分组为A,B, TreeMap.tailMap方法 treeMap是一种基于红…...

期权账户怎么开通的?佣金最低多少?
场内期权的合约由交易所统一标准化定制,大家面对的同一个合约对应的价格都是一致的,比较公开透明。期权开户当天不能交易的,期权开户需要满足20日日均50万及半年交易经验即可操作。 个人投资者想要交易期权首先就得先开户,根据规…...
MySQL(存储过程,store procedure)——存储过程的前世今生 MySQL存储过程体验 MybatisPlus中使用存储过程
前言 SQL(Structured Query Language)是一种用于管理关系型数据库的标准化语言,它用于定义、操作和管理数据库中的数据。SQL是一种通用的语言,可以用于多种关系型数据库管理系统(RDBMS),如MySQ…...
如何建立线上线下相结合的数字化新零售体系?
身处今数字化时代,建立线上线下相结合的数字化新零售体系是企业成功的关键。蚓链数字化营销系统致力于帮助企业实现数字化转型,打通线上线下销售渠道,提升品牌影响力和用户黏性,那么具体是如何建立的? 1. 搭建数字化中…...

python:xlwings 操作 Excel 加入图片
pip install xlwings ; xlwings-0.28.5-cp37-cp37m-win_amd64.whl (1.6 MB) 摘要:Make Excel fly: Interact with Excel from Python and vice versa. Requires: pywin32 编写 xlwings_test.py 如下 # -*- coding: utf-8 -*- """ xlwings 结合 …...

关于hive的时间戳
unix_timestamp()和 from_unixtime()的2个都是格林威治时间 北京时间 格林威治时间8 from_unixtme 是可以进行自动时区转换的 (4.0新特性) 4.0之前可以通过from_utc_timestamp进行查询 如果时间戳为小数,是秒&#…...
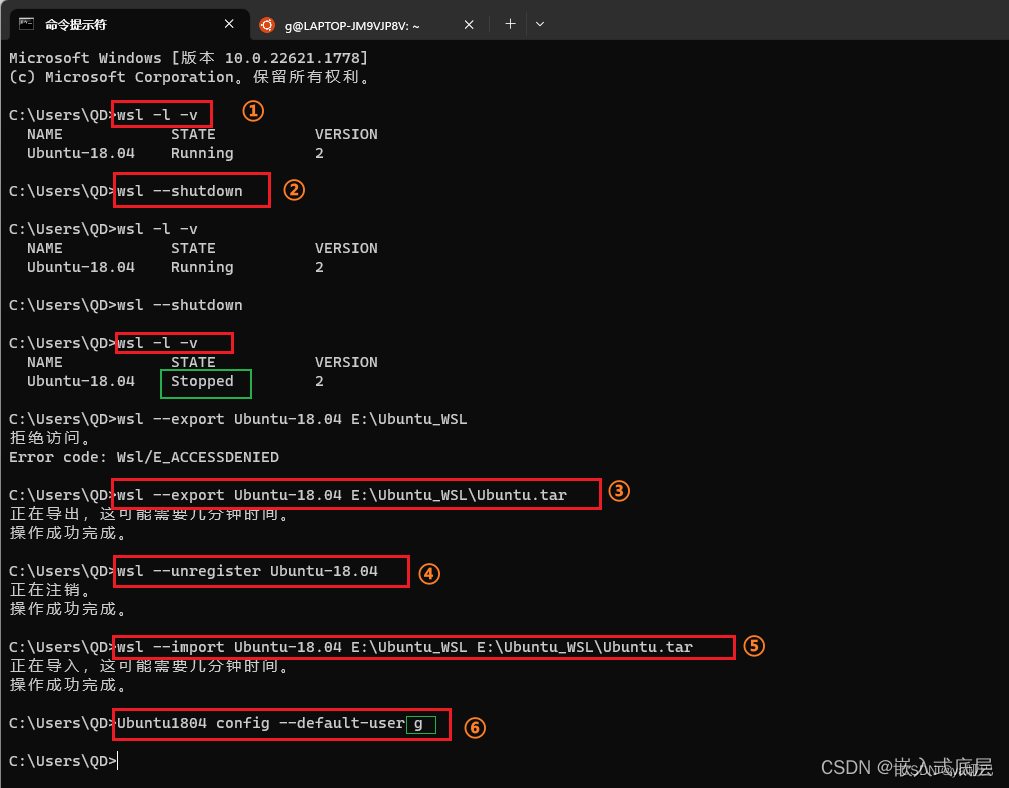
win10 wsl安装步骤
参考: 安装 WSL | Microsoft Learn 一、安装wsl 1.若要查看可通过在线商店下载的可用 Linux 发行版列表,请输入: wsl --list --online 或 wsl -l -o> wsl -l -o 以下是可安装的有效分发的列表。 使用 wsl.exe --install <Distro>…...

深入理解Spring Boot AOP:切面编程的优势与应用
在开发现代化的软件系统中,我们经常会遇到一些横切关注点(cross-cutting concerns),比如日志记录、安全控制、事务管理等。传统的面向对象编程(OOP)在处理这些关注点时往往需要在多个模块中重复编写相似的代…...
使用大模型提效程序员工作
引言 随着人工智能技术的不断发展,大模型在软件开发中的应用越来越广泛。 这些大模型,如GPT、文心一言、讯飞星火、盘古大模型等,可以帮助程序员提高工作效率,加快开发速度,并提供更好的用户体验。 本文将介绍我在实…...

如何应对量化交易,个人股票账户如何实现量化程序化自动交易
目前股票量化交易是对个人账户开放的,如果你没开通,可能是没有找对渠道,很多券商的手机客户端是包含某些简易版的策略交易,如网格策略,自动止盈止损等,这些策略交易虽然简单、灵活性差,但也是量…...
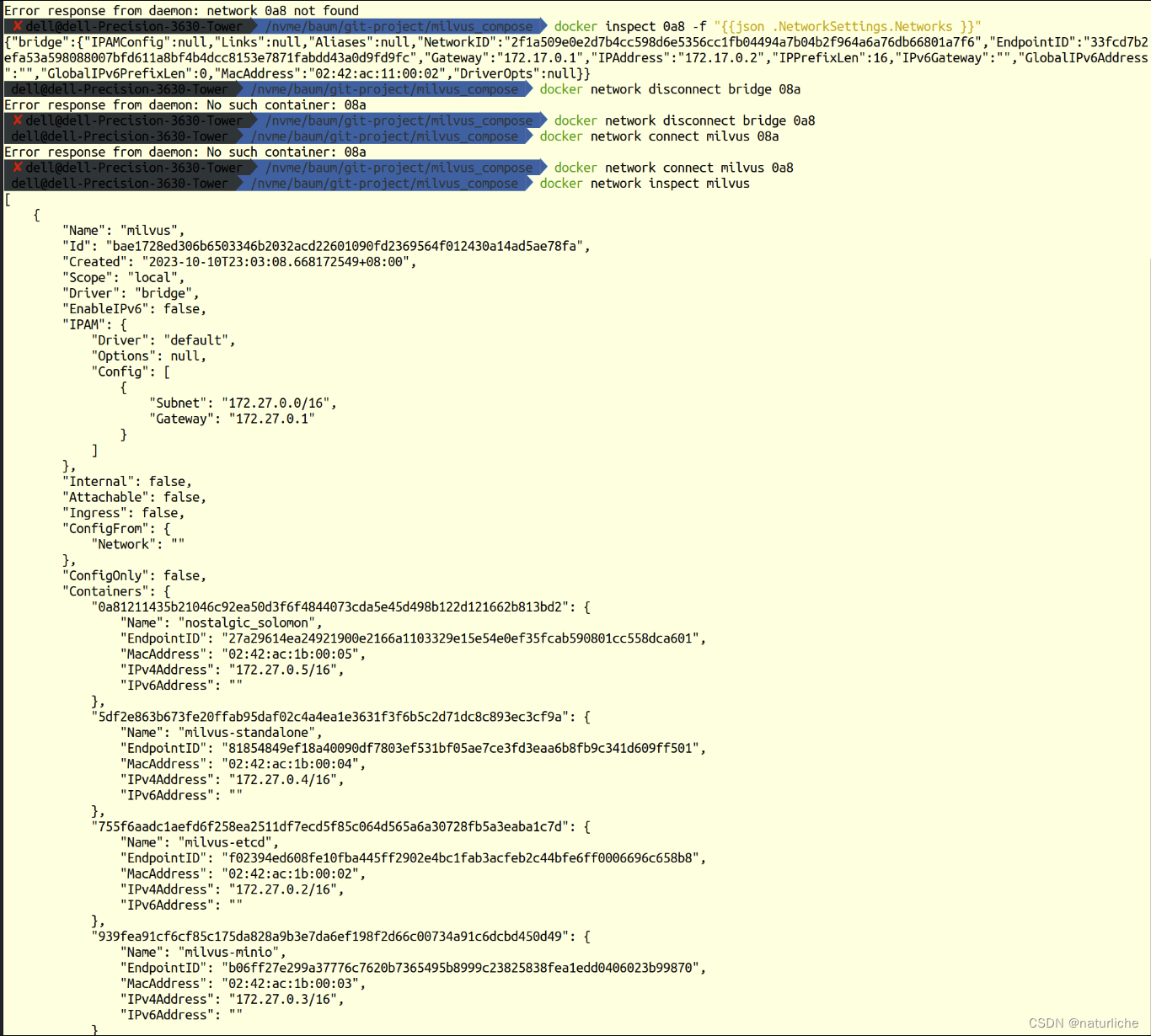
milvus测试
milvus测试 目标 其实,我应该弄明白他的输入输出分别是什么? 输入是图片,图片经过ml模型进行特征提取,再在milvus中进行存储或者检索 部署 ✘ delldell-Precision-3630-Tower /nvme/baum/git-project/milvus master …...
antd 表格getCheckboxProps禁用
需求:列表某些数据复选框禁用 实现效果图: 实现代码: <a-table :pagination"false" :row-selection"{ selectedRowKeys: selectedRowKeys, onChange: onSelectChange,getCheckboxProps:getCheckboxProps }" :column…...
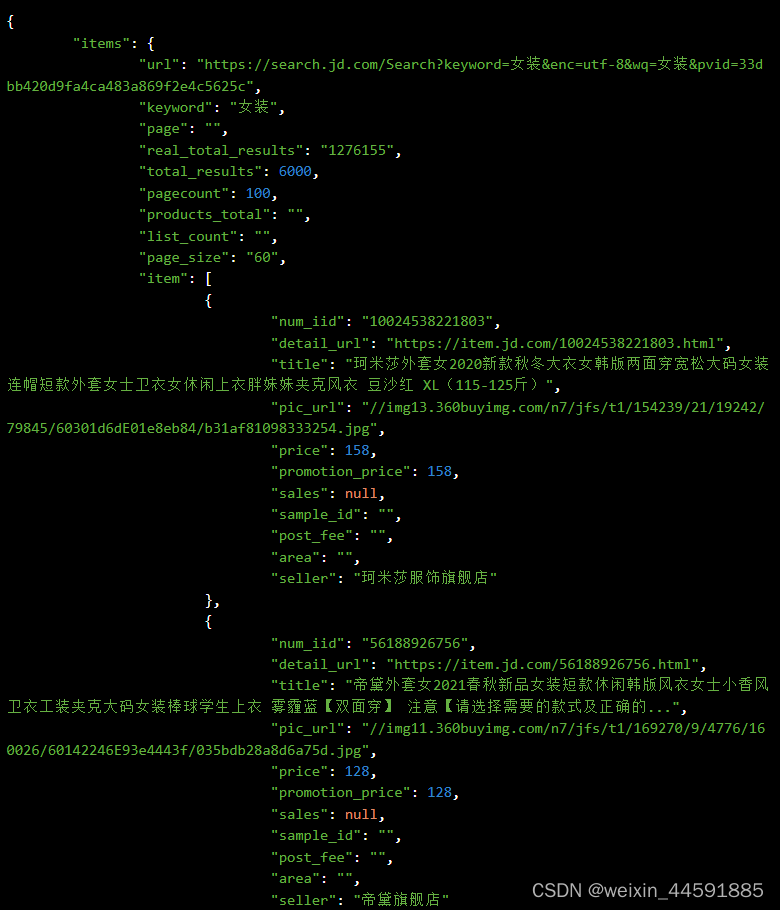
京东商品列表数据接口,关键词搜索京东商品数据接口
在网页抓取方面,可以使用 Python、Java 等编程语言编写程序,通过模拟 HTTP 请求,获取京东网站上的商品页面。在数据提取方面,可以使用正则表达式、XPath 等方式从 HTML 代码中提取出有用的信息。值得注意的是,京东网站…...

Vue使用BMapGL,及marker简单使用
1、封装加载器 export function BMapLoader(ak) {return new Promise((resolve, reject) > {if (window.BMapGL) {resolve(window.BMapGL)} else {const script document.createElement(script)script.type text/javascriptscript.src https://api.map.baidu.com/api?v…...

WuThreat身份安全云-TVD每日漏洞情报-2023-10-10
漏洞名称:Glibc ld.so本地权限提升漏洞 漏洞级别:高危 漏洞编号:CVE-2023-4911,CNNVD-202310-197 相关涉及:系统-ubuntu_22.04-glibc-*-Up to-(excluding)-2.35-0ubuntu3.4- 漏洞状态:POC 参考链接:https://tvd.wuthreat.com/#/listDetail?TVD_IDTVD-2023-24714 漏洞名称:D-L…...

OpenClaw浏览器自动化:千问3.5-27B驱动智能检索与内容聚合
OpenClaw浏览器自动化:千问3.5-27B驱动智能检索与内容聚合 1. 为什么需要浏览器自动化助手 作为一个经常需要做市场调研的技术人,我过去总是陷入这样的循环:打开十几个浏览器标签页,在不同平台间反复切换,手动复制粘…...

当AI真正“看懂“你的屏幕:GPT-5.4如何重新定义人机协作的边界
摘要: 2026年3月,OpenAI发布了GPT-5.4。这不是一次普通的模型迭代,而是一次能力边界的重新定义——它首次实现了原生的"计算机使用"能力,能在桌面上像人类一样点击按钮、填写表单、操作软件;它拥有五级可调的…...

遥感影像解译实战:从目视解译八要素到精准分类
1. 遥感影像解译的底层逻辑 第一次接触遥感影像时,我盯着屏幕上的彩色方块发懵——这堆像素点怎么能看出是森林还是农田?后来才发现,解译就像玩"大家来找茬",关键要掌握八要素这把万能钥匙。大小、形状、阴影、颜色、纹…...

Arduino轻量URL编解码库:RFC 3986兼容的嵌入式urlencode/urldecode实现
1. 项目概述URLCode 是一个专为 Arduino 平台设计的轻量级 URL 编解码库,其核心目标是提供符合 RFC 3986 标准的application/x-www-form-urlencoded格式字符串的编码(urlencode)与解码(urldecode)能力。该库不依赖 Ard…...

机器人双目视觉定位系统设计与开发
机器人双目视觉定位系统设计与开发 摘要 双目视觉定位技术是机器人感知环境、实现自主导航和精准操作的核心技术之一。本系统基于双目立体视觉原理,利用Matlab平台完成了从相机标定、图像采集、立体匹配到三维坐标解算的完整流程。系统采用张正友标定法获取相机内外参数,通…...

如何高效使用Dism++:Windows系统维护的终极解决方案
如何高效使用Dism:Windows系统维护的终极解决方案 【免费下载链接】Dism-Multi-language Dism Multi-language Support & BUG Report 项目地址: https://gitcode.com/gh_mirrors/di/Dism-Multi-language 你是否曾为Windows系统运行缓慢而烦恼?…...

从平台束缚到自由聆听:ncmdump如何让加密音乐重获新生?
从平台束缚到自由聆听:ncmdump如何让加密音乐重获新生? 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经遇到过这样的困境?在某个音乐平台精心收藏的歌单,却无法在车载音响上…...

Facebook Instant Game变现全攻略:如何通过广告和内购让你的HTML5游戏赚钱
Facebook Instant Game变现全攻略:如何通过广告和内购让你的HTML5游戏赚钱 在HTML5游戏开发领域,Facebook Instant Game已经成为不可忽视的平台。这个无需下载、即点即玩的游戏生态系统,为开发者提供了独特的变现机会。不同于传统应用商店30%…...
到2.1再到4.3(a):一次App Store审核“过山车”的实战复盘与破局)
从4.3(a)到2.1再到4.3(a):一次App Store审核“过山车”的实战复盘与破局
1. 当4.3(a)突然降临:一场没有预警的"Spam"风暴 那天早上我像往常一样打开邮箱,看到苹果审核团队的回复时,整个人瞬间清醒——醒目的"Guideline 4.3(a) - Design - Spam"像一盆冷水浇下来。这已经是我们的RPG游戏第三次提…...

仿真波形截图](https://example.com/waveform.jpg
永磁同步电机全速域无位置传感器控制仿真,高频注入改进滑膜控制,PMSM矢量控制仿真 1,在零低速域,采用无数字滤波器高频方波注入法,减少滤波的相位影响,且对凸极性要求不高; 2,在中高…...