基于SVM+TensorFlow+Django的酒店评论打分智能推荐系统——机器学习算法应用(含python工程源码)+数据集+模型(一)
目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python环境
- TensorFlow 环境
- 方法一
- 方法二
- 安装其他模块
- 安装MySQL 数据库
- 模块实现
- 1. 数据预处理
- 1)数据整合
- 2)文本清洗
- 3)文本分词
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
本项目以支持向量机(SVM)技术为核心,利用酒店评论数据集进行了情感分析模型的训练。通过使用Word2Vec生成词向量,该项目实现了一个打分推荐系统,其中服务器端提供数据,而客户端则查询数据。
首先,项目使用了酒店评论数据集,这些评论包括了来自不同用户的对酒店的评价。这些评论被用来训练情感分析模型,该模型能够分析文本并确定评论的情感极性,即正面、负面或中性。
其次,项目使用Word2Vec技术,将文本数据转换为词向量表示。这些词向量捕捉了不同词汇之间的语义关系,从而提高了文本分析的效果。这些词向量可以用于训练模型以进行情感分析。
在服务器端,项目提供了处理和存储酒店评论数据的功能。这意味着评论数据可以在服务器上进行管理、存储和更新。
在客户端,用户可以查询酒店评论数据,并获得关于特定酒店的情感分析结果。例如,用户可以输入酒店名称或位置,并获取该酒店的评论以及评论的情感分数,这有助于用户更好地了解其他人对酒店的评价。
总的来说,本项目基于SVM技术和Word2Vec词向量,提供了一个针对酒店评论情感的分析和打分推荐系统。这个系统可以帮助用户更好地了解酒店的口碑和评价,从而做出更明智的决策。
总体设计
本部分包括系统整体结构图和系统流程图。
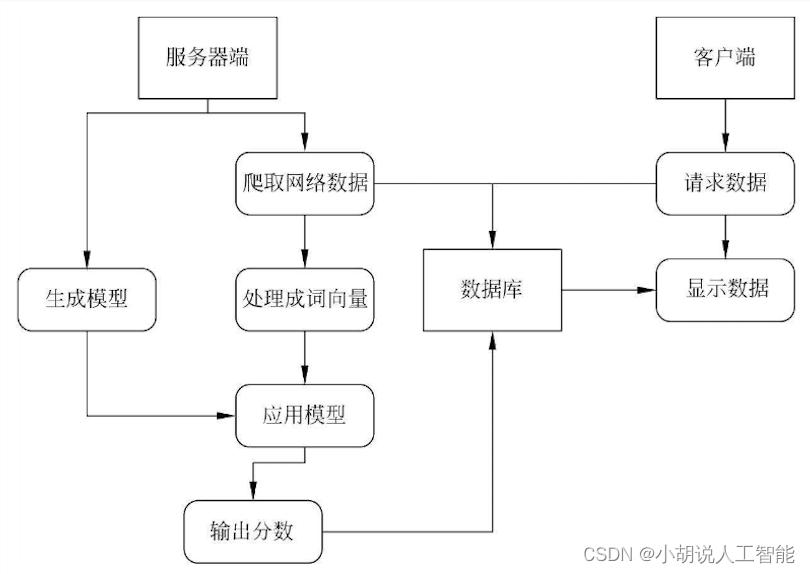
系统整体结构图
系统整体结构如图所示。
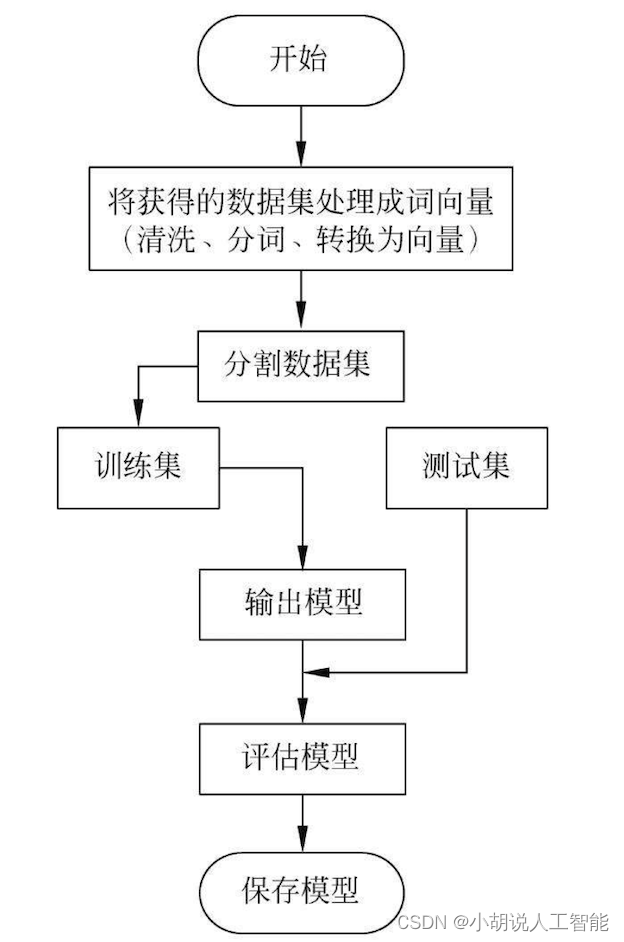
系统流程图
系统流程如图所示。
运行环境
本部分包括Python环境、TensorFlow环境、 安装模块、MySQL数据库。
Python环境
需要Python 3.6及以上配置,在Windows环境下推荐下载Anaconda完成Python所需环境的配置,下载地址为https://www.anaconda.com/,也可下载虚拟机在Linux环境下运行代码。
鼠标右击“我的电脑”,单击“属性”,选择高级系统设置。单击“环境变量”,找到系统变量中的Path,单击“编辑”然后新建,将Python解释器所在路径粘贴并确定。
TensorFlow 环境
安装方法如下:
方法一
打开Anaconda Prompt,输入清华仓库镜像。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config -set show_channel_urls yes
创建Python 3.6的环境,名称为TensorFlow,此时Python版本和后面TensorFlow的版本有匹配问题,此步选择Python 3.x。
conda create -n tensorflow python=3.6
有需要确认的地方,都输入y。在Anaconda Prompt中激活TensorFlow环境:
conda activate tensorflow
安装CPU版本的TensorFlow:
pip install -upgrade --ignore -installed tensorflow
测试代码如下:
import tensorflow as tf
hello = tf.constant( 'Hello, TensorFlow! ')
sess = tf.Session()
print sess.run(hello)
# 输出 b'Hello! TensorFlow'
安装完毕。
方法二
打开Anaconda Navigator,进入Environments 单击Create,在弹出的对话框中输入TensorFlow,选择合适的Python版本,创建好TensorFlow环境,然后进入TensorFlow环境,单击Not installed在搜索框内寻找需要用到的包。例如,TensorFlow,在右下方选择apply,测试是否安装成功。在Jupyter Notebook编辑器中输入以下代码:
import tensorflow as tf
hello = tf.constant( 'Hello, TensorFlow! ')
sess = tf.Session()
print sess.run(hello)
# 输出 b'Hello! TensorFlow'
能够输出hello TensorFlow,说明安装成功。
安装其他模块
在anaconda prompt中使用命令行切换到TensorFlow环境:
activate tensorflow
安装Scikit-learn模块:
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
安装jieba模块:
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
安装gensim模块:
pip install gensim -i https://pypi.tuna.tsinghua.edu.cn/simple
安装Django模块:
下载并解压Django,和Python安装在同一个根目录,进入Django目录,执行:
python setup.py install
Django被安装到Python的Lib下site packages。将这些目录添加到系统环境变量中: C:\Python33\Lib\site packages\django; C:\Python33\Scripts,使用Django的django -admin.py命令新建工程。
安装MySQL 数据库
下载MySQL安装并配置。在计算机高级属性的系统变量中写好MySQL所在位置,方便用命令行操作MySQL,在服务里启动数据库服务,登录数据库:
mysql -u root -P
创建数据库grades:
CREATE DATABASE grades;
在数据库里创建表单:

模块实现
本项目包括3个模块:数据预处理、模型训练及保存、模型测试,下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
数据集下载链接为https://www.aitechclub.com/data-detail?data_id=29,停用词典下载链接为http://www.datasoldier.net/archives/636。如果链接失效,可从本博客对应的工程源码中的模型训练目录下的data目录下载相关数据集。
1)数据整合
原始数据包含在两个文件夹中,每个文件夹各有2000条消极和2000条积极的评论,因此,需要先做评论数据整合,将两个评论放在.txt文档中。
#读取每一条文字内容
def getContent(fullname):f = open(fullname,'rb+')content = f.readlines()f.close()return content#将积极和消极评论分别写入两个文件中
for parent,dirnames,filenames in os.walk(rootdir): for filename in filenames:#使用getContent()函数,得到每条评论的具体内容content = getContent(rootdir + '\\' + filename)output.writelines(content)i = i+1output.close()
2)文本清洗
进行文本特殊符号(如表情)的清理删除。
#文本清洗
def clearTxt(line):if line != '':#去掉末尾的空格
line = line.strip()pun_num = string.punctuation + string.digitsintab = pun_numouttab = " "*len(pun_num)#去除所有标点和数字trantab = str.maketrans(intab, outtab)line = line.translate(trantab)#去除文本中的英文和数字line = re.sub("[a-zA-Z0-9]", "", line)#去除文本中的中文符号和英文符号line = re.sub("[\s+\.\!\/_,$%^*(+\"\';:“”.]+|[+——!==°【】,÷。??、 ~@#¥%……&*()]+", "", line)return line
3)文本分词
将分词后的文本转化为以高维向量表示的方式,这里使用微信中文语料训练的开源模型。
#进行文本分词
#引入jieba模块
import jieba
import jieba.analyse
import codecs,sys,string,re#文本分词
def sent2word(line):segList = jieba.cut(line,cut_all=False) segSentence = ''for word in segList:if word != '\t':segSentence += word + " "return segSentence.strip()
#删除分词后文本里的停用词
def delstopword(line,stopkey):wordList = line.split(' ') sentence = ''for word in wordList:word = word.strip()#spotkey是在主函数中获取的评论行数
#逐行删除,不破坏词所在每行的位置,始终保持每条评论的间隔if word not in stopkey:if word != '\t':sentence += word + " "return sentence.strip()
#载入模型
fdir = 'E:\word2vec\word2vec_from_weixin\word2vec'
inp = fdir + '\word2vec_wx'
model = gensim.models.Word2Vec.load(inp)
#把词语转化为词向量的函数
def getWordVecs(wordList,model):vecs = []for word in wordList:word = word.replace('\n','')#print wordtry:vecs.append(model[word])except KeyError:continuereturn np.array(vecs, dtype='float')
#转化为词向量
def buildVecs(filename,model):fileVecs = []with codecs.open(filename, 'rb', encoding='utf-8') as contents:for line in contents:wordList = line.split(' ')#调用getwordVecs()函数,获取每条评论的词向量vecs = getWordVecs(wordList,model)if len(vecs) >0:vecsArray = sum(np.array(vecs))/len(vecs) fileVecs.append(vecsArray)return fileVecs
#建立词向量表,其中积极的首列填充为1,消极的首列填充为0Y = np.concatenate((np.ones(len(posInput)), np.zeros(len(negInput))))X = posInput[:]for neg in negInput:X.append(neg)X = np.array(X)
相关其它博客
基于SVM+TensorFlow+Django的酒店评论打分智能推荐系统——机器学习算法应用(含python工程源码)+数据集+模型(二)
基于SVM+TensorFlow+Django的酒店评论打分智能推荐系统——机器学习算法应用(含python工程源码)+数据集+模型(三)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
相关文章:
基于SVM+TensorFlow+Django的酒店评论打分智能推荐系统——机器学习算法应用(含python工程源码)+数据集+模型(一)
目录 前言总体设计系统整体结构图系统流程图 运行环境Python环境TensorFlow 环境方法一方法二 安装其他模块安装MySQL 数据库 模块实现1. 数据预处理1)数据整合2)文本清洗3)文本分词 相关其它博客工程源代码下载其它资料下载 前言 本项目以支…...
Elasticsearch 分片内部原理—近实时搜索、持久化变更
目录 一、近实时搜索 refresh API 二、持久化变更 flush API 一、近实时搜索 随着按段(per-segment)搜索的发展,一个新的文档从索引到可被搜索的延迟显著降低了。新文档在几分钟之内即可被检索,但这样还是不够快。 磁盘在这…...

华为OD机试 - 用连续自然数之和来表达整数 - 滑动窗口(Java 2023 B卷 100分)
目录 专栏导读一、题目描述二、输入描述三、输出描述四、解题思路五、Java算法源码六、效果展示1、输入2、输出 华为OD机试 2023B卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试(JAVA)真题(A卷B卷)》…...

玩转ChatGPT:图像识别(vol. 1)
一、写在前面 来了来了,终于给我的账号开放图像识别功能了,话不多说,直接开测!!! 二、开始尝鲜 (1)咒语: GPT回复: 这幅图显示了从2005年1月到2012年12月的…...

oracle 数据库实验三
(1)向 ORCL数据库添加一个重做日志文件组(组号为5),包含一个成员文件d:\redo05a.log,大小为4MB ; 要向Oracle数据库添加一个重做日志文件组,您可以执行以下步骤: 连接到数据库&…...

多线程并发篇---第五篇
系列文章目录 文章目录 系列文章目录一、什么是线程安全二、Thread类中的yield方法有什么作用?三、Java线程池中submit() 和 execute()方法有什么区别?一、什么是线程安全 线程安全就是说多线程访问同一段代码,不会产生不确定的结果。 又是一个理论的问题,各式各样的答案有…...

java实现权重随机获取值或对象
文章目录 场景TreeMap.tailMap方法简单分析使用随机值使用treemap实现权重取值将Int改为Double稍微准确一点,因为double随机的值更加多测试main方法 当权重的参数比较多,那么建议使用hutool封装的 场景 按照权重2,8给用户分组为A,B, TreeMap.tailMap方法 treeMap是一种基于红…...

期权账户怎么开通的?佣金最低多少?
场内期权的合约由交易所统一标准化定制,大家面对的同一个合约对应的价格都是一致的,比较公开透明。期权开户当天不能交易的,期权开户需要满足20日日均50万及半年交易经验即可操作。 个人投资者想要交易期权首先就得先开户,根据规…...
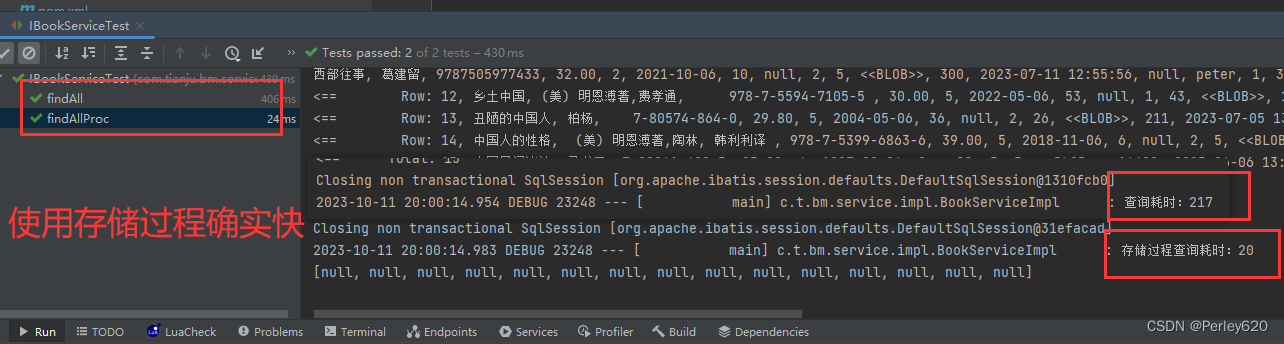
MySQL(存储过程,store procedure)——存储过程的前世今生 MySQL存储过程体验 MybatisPlus中使用存储过程
前言 SQL(Structured Query Language)是一种用于管理关系型数据库的标准化语言,它用于定义、操作和管理数据库中的数据。SQL是一种通用的语言,可以用于多种关系型数据库管理系统(RDBMS),如MySQ…...
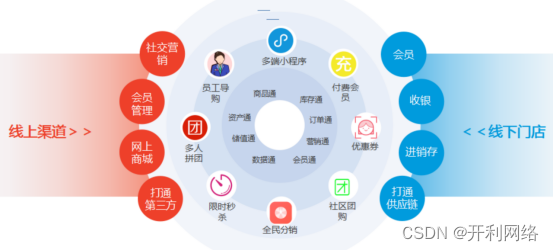
如何建立线上线下相结合的数字化新零售体系?
身处今数字化时代,建立线上线下相结合的数字化新零售体系是企业成功的关键。蚓链数字化营销系统致力于帮助企业实现数字化转型,打通线上线下销售渠道,提升品牌影响力和用户黏性,那么具体是如何建立的? 1. 搭建数字化中…...

python:xlwings 操作 Excel 加入图片
pip install xlwings ; xlwings-0.28.5-cp37-cp37m-win_amd64.whl (1.6 MB) 摘要:Make Excel fly: Interact with Excel from Python and vice versa. Requires: pywin32 编写 xlwings_test.py 如下 # -*- coding: utf-8 -*- """ xlwings 结合 …...

关于hive的时间戳
unix_timestamp()和 from_unixtime()的2个都是格林威治时间 北京时间 格林威治时间8 from_unixtme 是可以进行自动时区转换的 (4.0新特性) 4.0之前可以通过from_utc_timestamp进行查询 如果时间戳为小数,是秒&#…...
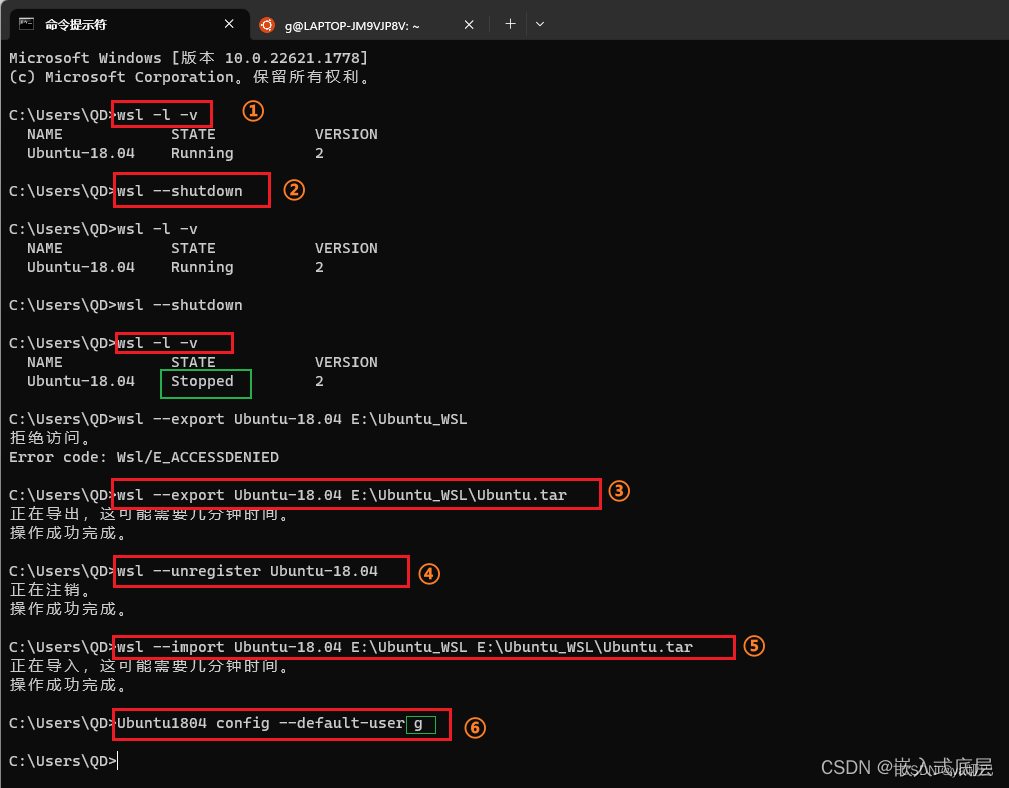
win10 wsl安装步骤
参考: 安装 WSL | Microsoft Learn 一、安装wsl 1.若要查看可通过在线商店下载的可用 Linux 发行版列表,请输入: wsl --list --online 或 wsl -l -o> wsl -l -o 以下是可安装的有效分发的列表。 使用 wsl.exe --install <Distro>…...

深入理解Spring Boot AOP:切面编程的优势与应用
在开发现代化的软件系统中,我们经常会遇到一些横切关注点(cross-cutting concerns),比如日志记录、安全控制、事务管理等。传统的面向对象编程(OOP)在处理这些关注点时往往需要在多个模块中重复编写相似的代…...
使用大模型提效程序员工作
引言 随着人工智能技术的不断发展,大模型在软件开发中的应用越来越广泛。 这些大模型,如GPT、文心一言、讯飞星火、盘古大模型等,可以帮助程序员提高工作效率,加快开发速度,并提供更好的用户体验。 本文将介绍我在实…...

如何应对量化交易,个人股票账户如何实现量化程序化自动交易
目前股票量化交易是对个人账户开放的,如果你没开通,可能是没有找对渠道,很多券商的手机客户端是包含某些简易版的策略交易,如网格策略,自动止盈止损等,这些策略交易虽然简单、灵活性差,但也是量…...
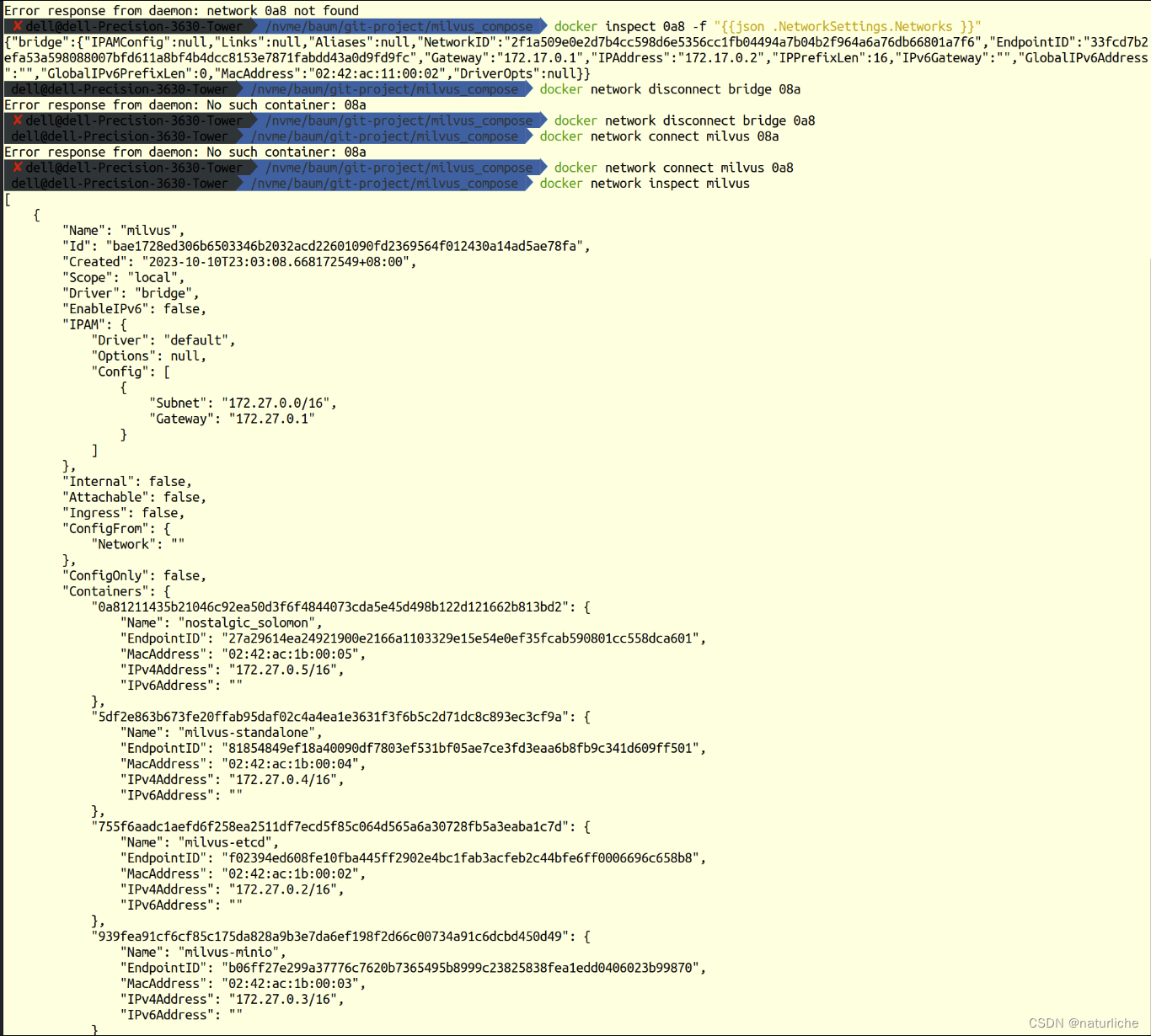
milvus测试
milvus测试 目标 其实,我应该弄明白他的输入输出分别是什么? 输入是图片,图片经过ml模型进行特征提取,再在milvus中进行存储或者检索 部署 ✘ delldell-Precision-3630-Tower /nvme/baum/git-project/milvus master …...
antd 表格getCheckboxProps禁用
需求:列表某些数据复选框禁用 实现效果图: 实现代码: <a-table :pagination"false" :row-selection"{ selectedRowKeys: selectedRowKeys, onChange: onSelectChange,getCheckboxProps:getCheckboxProps }" :column…...
京东商品列表数据接口,关键词搜索京东商品数据接口
在网页抓取方面,可以使用 Python、Java 等编程语言编写程序,通过模拟 HTTP 请求,获取京东网站上的商品页面。在数据提取方面,可以使用正则表达式、XPath 等方式从 HTML 代码中提取出有用的信息。值得注意的是,京东网站…...

Vue使用BMapGL,及marker简单使用
1、封装加载器 export function BMapLoader(ak) {return new Promise((resolve, reject) > {if (window.BMapGL) {resolve(window.BMapGL)} else {const script document.createElement(script)script.type text/javascriptscript.src https://api.map.baidu.com/api?v…...

Qwen2.5-14B-Instruct部署优化:像素剧本圣殿FlashAttention-2加速实测
Qwen2.5-14B-Instruct部署优化:像素剧本圣殿FlashAttention-2加速实测 1. 项目背景与优化目标 像素剧本圣殿是一款基于Qwen2.5-14B-Instruct深度微调的专业剧本创作工具。这款工具将AI推理能力与8-Bit复古美学相结合,为创作者提供沉浸式的剧本开发体验…...

ClassGraph安全封装绕过:Narcissus与JVM-Driver深度分析
ClassGraph安全封装绕过:Narcissus与JVM-Driver深度分析 【免费下载链接】classgraph An uber-fast parallelized Java classpath scanner and module scanner. 项目地址: https://gitcode.com/gh_mirrors/cl/classgraph ClassGraph作为一款超快速的并行化Ja…...

MS5611高精度气压温度传感器Arduino驱动库
1. 项目概述MS5611-Mike-Refactored 是一款面向嵌入式平台(特别是 Arduino 兼容生态)的 MS5611 高精度气压/温度传感器驱动库。该库并非简单封装,而是对 Korneliusz Jarzebski 原始实现的一次系统性重构与工程化增强。其核心目标是将一个基础…...

关于eclipse2019中导入克隆的web项目
分为导入项目和排查可能错误两个方面前言:本文主要总结个人在完成需要合作完成学习项目时,使用共享项目文件时“环境”问题导致的无法“跑通”,为此忙碌很久和豆包进行了“深入聊天”。决定对自己的问题进行总结,方便自己以后阅读…...

酶联免疫斑点技术原理与应用
一、技术背景与基本概念酶联免疫斑点技术Elispot是一种基于单细胞水平检测特异性抗体分泌细胞或细胞因子分泌细胞的免疫学检测方法。该技术结合了酶联免疫吸附测定(ELISA)的高灵敏度与斑点形成单元的可视化计数优势,能够在单个细胞层面实现功…...

如何用Python快速开发Android应用:Python for Android完整指南
如何用Python快速开发Android应用:Python for Android完整指南 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android 想要将Python技能扩展到移动开发领…...

利用快马ai快速原型开发openclaw类网页数据抓取chrome插件
利用AI快速原型开发OpenClaw类网页数据抓取Chrome插件 最近在做一个数据采集的小项目,需要从电商网站抓取商品信息。传统做法要手动写各种XPath和CSS选择器,费时费力。后来发现用InsCode(快马)平台的AI辅助开发,可以快速实现一个类似OpenCla…...

3种简单方法实现Windows与Linux双系统文件无缝共享的终极方案
3种简单方法实现Windows与Linux双系统文件无缝共享的终极方案 【免费下载链接】btrfs WinBtrfs - an open-source btrfs driver for Windows 项目地址: https://gitcode.com/gh_mirrors/bt/btrfs 跨平台文件共享一直是Windows与Linux双系统用户面临的核心痛点。你是否曾…...

不用Root!教你用ADB命令手动安装Google TTS中文语音包
免Root实现Google TTS中文语音引擎的完整部署指南 你是否遇到过在国产定制Android系统上无法使用Google文字转语音功能的困扰?许多厂商预装的语音引擎发音生硬,而Google TTS的中文语音包又常常因为系统限制无法正常安装。本文将带你绕过这些限制…...

【Python实战】AI自动整理文件:告别桌面混乱
用PythonAI打造一个桌面文件整理助手,让混乱的桌面瞬间清爽 一、痛点:桌面文件的"灾难现场" 我的桌面曾经是这样的: 截图、下载文件、临时文档混在一起 找文件要翻半天 重要文件被淹没在垃圾文件里 手动整理太麻烦,坚持…...