语言模型编码中/英文句子格式详解
文章目录
- 前言
- 一、Bert的vocab.txt内容查看
- 二、BERT模型转换方法(vocab.txt)
- 三、vocab内容与模型转换对比
- 四、中文编码
- 总结
前言
最近一直在学习多模态大模型相关内容,特别是图像CV与语言LLM模型融合方法,如llama-1.5、blip、meta-transformer、glm等大模型。其语言模型的中文和英文句子如何编码成计算机识别符号,使我困惑。我查阅资料,也发现很少有博客全面说明。为此,我以该博客记录其整过过程,并附有对应代码供读者参考。
处理语言模型需要将英文或中文等字符表示成模型能识别的符号,为此不同模型会按照某些方法表示,但不同模型转计算机能识别思路是一致的。
一、Bert的vocab.txt内容查看
来源tokenization.py文件内容。
PRETRAINED_VOCAB_ARCHIVE_MAP = {'bert-base-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt",'bert-large-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-vocab.txt",'bert-base-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-vocab.txt",'bert-large-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased-vocab.txt",'bert-base-multilingual-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-uncased-vocab.txt",'bert-base-multilingual-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-vocab.txt",'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-vocab.txt",
}
vocab.txt内容:

上图是我截取vocab.txt的内容,基本很多有的符号/数字/运算符/中文/字母/单词等均在该txt文件夹中。
二、BERT模型转换方法(vocab.txt)
加入有2句话,分别为text01与text02(如下),他们会转换vocab.txt中已有的单词形式。其中需要留意:’##符号连接长单词在vocab.txt部件方式,如embeddings表示为['em','##bed','##ding','s']。同时,vocab.txt不存在单词部件会化成最小组件,单个字母(vocab.txt最小部件是字母)。
代码如下:
from pytorch_pretrained_bert import BertTokenizertokenizer = BertTokenizer.from_pretrained('../voccab.txt')text01 = "Here is the sentence I want embeddings for."
text02 = "wish for world peace."
marked_text = "[CLS] " + text01 + " [SEP] " + text02 + " [SEP]"
print('marked_text = ', marked_text)tokenized_text = tokenizer.tokenize(marked_text)
print('tokenized_text = ', tokenized_text)indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)for tup in zip(tokenized_text, indexed_tokens):print("tup = ", tup)
marked_text是将句子使用符号分开表示其句子含义;
tokenized_text表示将句子化成vocab.txt文件提供的部件,其中##bed有单独表示;
tup = (‘[CLS]’, 101)后的内容表示其符号对应的索引。
其结果如下:
marked_text = [CLS] Here is the sentence I want embeddings for. [SEP] wish for world peace. [SEP]
tokenized_text = ['[CLS]', 'here', 'is', 'the', 'sentence', 'i', 'want', 'em', '##bed', '##ding', '##s', 'for', '.', '[SEP]', 'wish', 'for', 'world', 'peace', '.', '[SEP]']tup = ('[CLS]', 101)
tup = ('here', 2182)
tup = ('is', 2003)
tup = ('the', 1996)
tup = ('sentence', 6251)
tup = ('i', 1045)
tup = ('want', 2215)
tup = ('em', 7861)
tup = ('##bed', 8270)
tup = ('##ding', 4667)
tup = ('##s', 2015)
tup = ('for', 2005)
tup = ('.', 1012)
tup = ('[SEP]', 102)
tup = ('wish', 4299)
tup = ('for', 2005)
tup = ('world', 2088)
tup = ('peace', 3521)
tup = ('.', 1012)
tup = ('[SEP]', 102)
总结:最终词汇等内容转为对应的索引数字表达。
三、vocab内容与模型转换对比
从图中可知,vocab的索引值总比模型给出索引值小1,这是因为模型从0开始索引,而vocab展示内容从1开始,因此相差1。
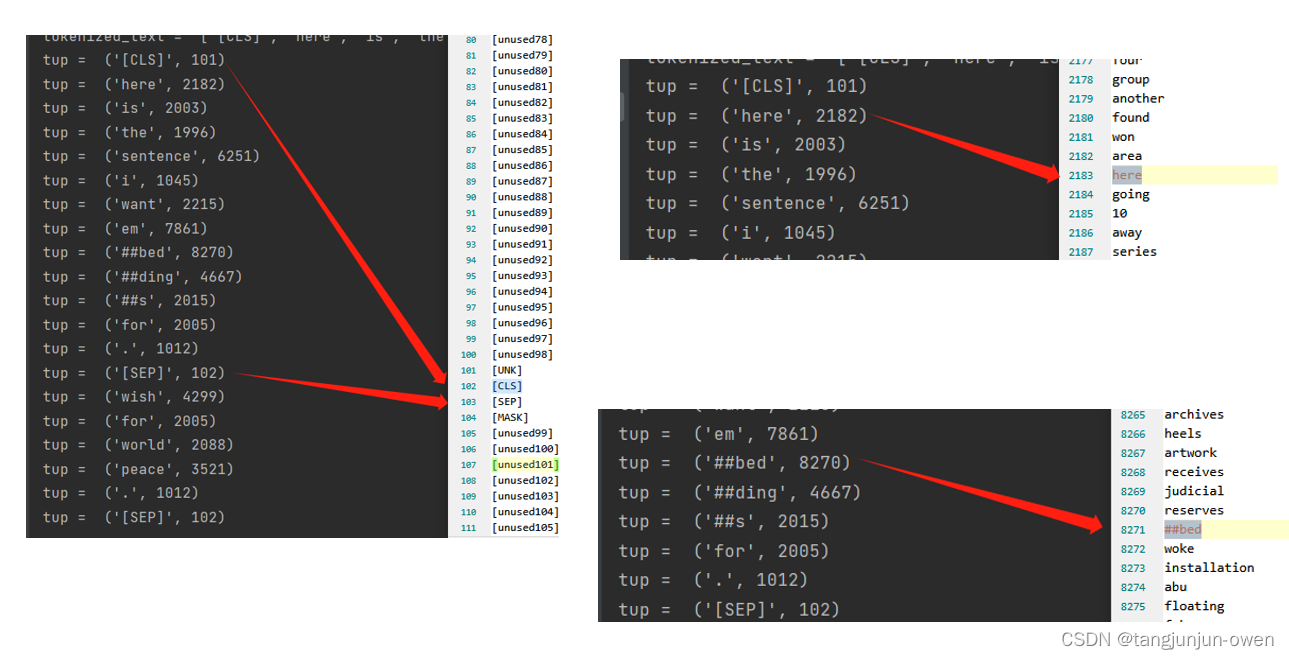
再次强调:模型对词汇编码实际为人为给出对应表(如:vocab.txt)所对应的索引,用索引值替换词语。
四、中文编码
以上内容已全部告知读者,模型如何编码句子。而该部分内容是拓展,使用中文编码,查看其结果。
代码如下:
from pytorch_pretrained_bert import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('../voccab.txt')
text01 = "the sentence I want embeddings for."
text02 = "愿世界和平。"
marked_text = "[CLS] " + text01 + " [SEP] " + text02 + " [SEP]"
print('marked_text = ', marked_text)
tokenized_text = tokenizer.tokenize(marked_text)
print('tokenized_text = ', tokenized_text)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
for tup in zip(tokenized_text, indexed_tokens):print("tup = ", tup)
结果如下:
marked_text = [CLS] the sentence I want embeddings for. [SEP] 愿世界和平。 [SEP]
tokenized_text = ['[CLS]', 'the', 'sentence', 'i', 'want', 'em', '##bed', '##ding', '##s', 'for', '.', '[SEP]', '[UNK]', '世', '[UNK]', '和', '平', '。', '[SEP]']
tup = ('[CLS]', 101)
tup = ('the', 1996)
tup = ('sentence', 6251)
tup = ('i', 1045)
tup = ('want', 2215)
tup = ('em', 7861)
tup = ('##bed', 8270)
tup = ('##ding', 4667)
tup = ('##s', 2015)
tup = ('for', 2005)
tup = ('.', 1012)
tup = ('[SEP]', 102)
tup = ('[UNK]', 100)
tup = ('世', 1745)
tup = ('[UNK]', 100)
tup = ('和', 1796)
tup = ('平', 1839)
tup = ('。', 1636)
tup = ('[SEP]', 102)图显示:
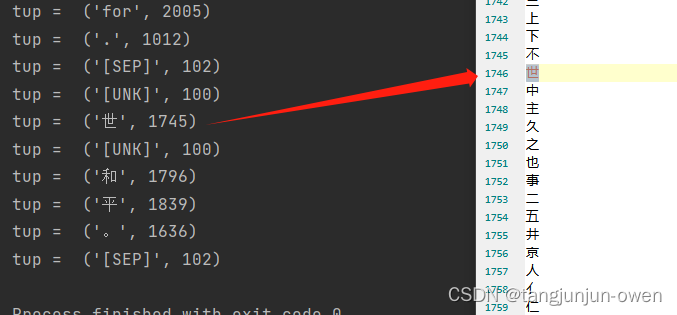
可发现,和上面英文句子编码是一样的。
总结
一句话,模型是根据提供对应表,将中/英文句子或符号编译成对应索引,被计算识别。
相关文章:
语言模型编码中/英文句子格式详解
文章目录 前言一、Bert的vocab.txt内容查看二、BERT模型转换方法(vocab.txt)三、vocab内容与模型转换对比四、中文编码总结 前言 最近一直在学习多模态大模型相关内容,特别是图像CV与语言LLM模型融合方法,如llama-1.5、blip、meta-transformer、glm等大…...
【Node.js】路由
基础使用 写法一: // server.js const http require(http); const fs require(fs); const route require(./route) http.createServer(function (req, res) {const myURL new URL(req.url, http://127.0.0.1)route(res, myURL.pathname)res.end() }).listen…...

matlab 2ask 4ask 信号调制
1 matlab 2ask close all clear all clcL =1000;Rb=2822400;%码元速率 Fs =Rb*8; Fc=Rb*30;%载波频率 Ld =L*Fs/Rb;%产生载波信号 t =0:1/Fs:L/Rb;carrier&...
Python利用jieba分词提取字符串中的省市区(字符串无规则)
目录 背景库(jieba)代码拓展结尾 背景 今天的需求就是在一串字符串中提取包含,省、市、区,该字符串不是一个正常的地址;,如下字符串 "安徽省、浙江省、江苏省、上海市,冷运标快首重1kg价格xx元,1.01kg(含)-5kg(不含)续重价…...

MuLogin防关联浏览器帮您一键实现Facebook账号多开
导言: 在当今数字化时代,社交媒体应用程序的普及程度越来越高。Facebook作为全球最大的社交媒体平台之一,拥有数十亿的用户。然而,对于一些用户来说,只拥有一个Facebook账号可能无法满足他们的需求。有时,…...

【C语言】每日一题(半月斩)——day4
目录 选择题 1、设变量已正确定义,以下不能统计出一行中输入字符个数(不包含回车符)的程序段是( ) 2、运行以下程序后,如果从键盘上输入 65 14<回车> ,则输出结果为( &…...
 每次ssh进)
Are you sure you want to continue connecting (yes/no) 每次ssh进
Lunix scp等命令不需要输入yes确认方法_scp不需要确认-CSDN博客 方法一:连接时加入StrictHostKeyCheckingno ssh -o StrictHostKeyCheckingno root192.168.1.100 方法二:修改/etc/ssh/ssh_config配置文件,添加: StrictHostKeyC…...

网络与信息系统安全设计规范
1、总则 1.1、目的 为规范XXXXX单位信息系统安全设计过程,确保整个信息安全管理体系在信息安全设计阶段符合国家相关标准和要求,特制订本规范。 1.2、范围 本规范适用于XXXXX单位在信息安全设计阶段的要求和规范管理。 1.3、职责 网络安全与信息化…...
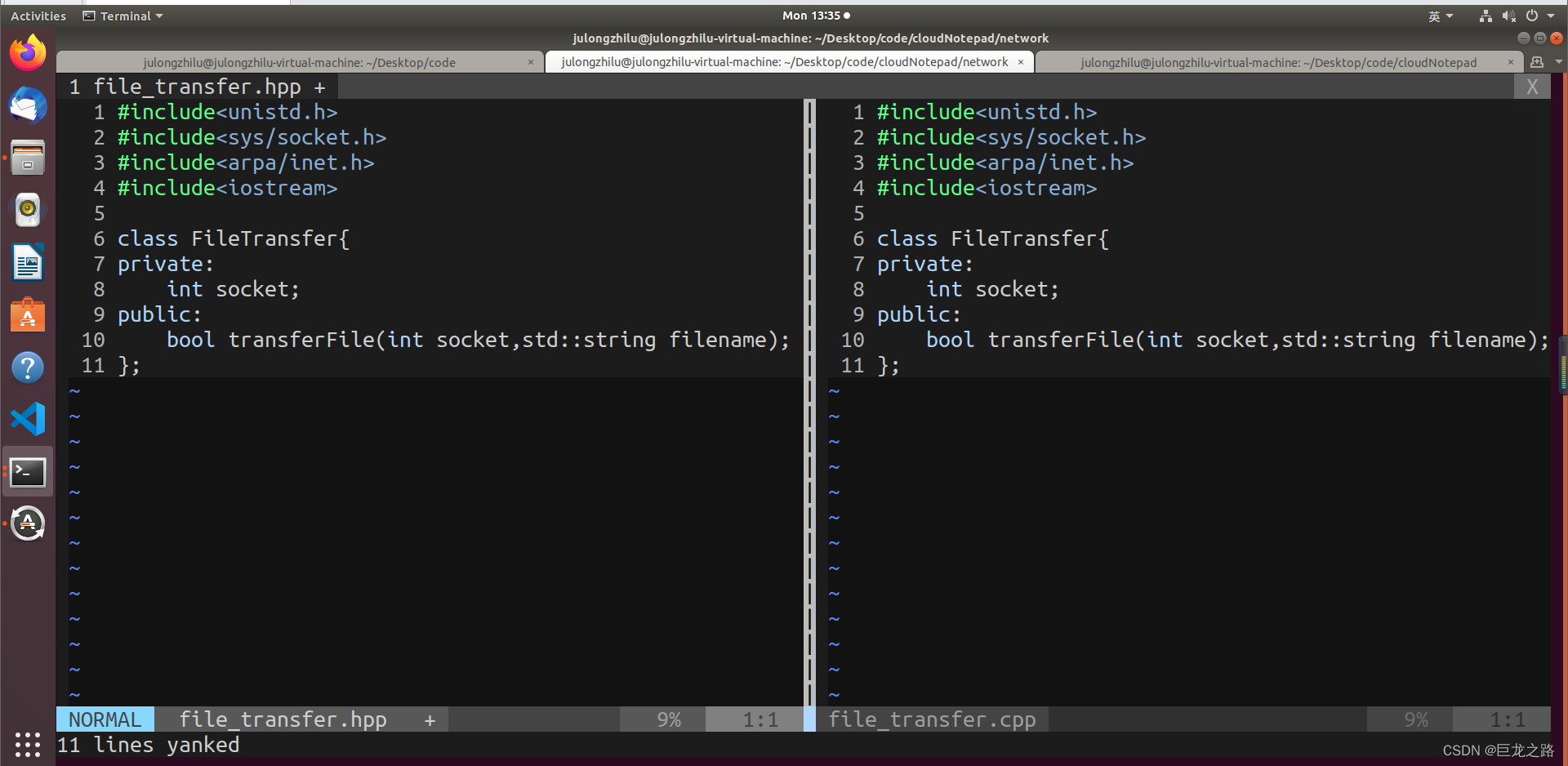
在Linux怎么用vim实现把一个文件里面的文本复制到另一个文件里面
2023年10月9日,周一下午 我昨天遇到了这个问题,但在网上没找到图文并茂的博客,于是我自己摸索出解决办法后,决定写一篇图文并茂的博客。 情景 假设现在我要用vim把file_transfer.cpp的内容复制到file_transfer.hpp里面 第一步 …...

CCAK—云审计知识证书学习
目录 一、CCAK云审计知识证书概述 二、云治理概述 三、云信任 四、构建云合规计划 <...
3.springcloudalibaba gateway项目搭建
文章目录 前言一、搭建gateway项目1.1 pom配置1.2 新增配置如下 二、新增server服务2.1 pom配置2.2新增测试接口如下 三、测试验证3.1 分别启动两个服务,查看nacos是否注册成功3.2 测试 总结 前言 前面已经完成了springcloudalibaba项目搭建,接下来搭建…...
Debezium日常分享系列之:Debezium 2.3.0.Final发布
Debezium日常分享系列之:Debezium 2.3.0.Final发布 一、重大改变二、PostgreSQL / MySQL 安全连接更改三、JDBC 存储编码更改四、新功能和改进五、Kubernetes 的 Debezium Server Operator六、新的通知子系统七、新的可扩展信号子系统八、JMX 信号和通知集成九、新的…...

js为什么是单线程?
基础 js为什么是单线程? 多线程问题 类比操作系统,多线程问题有: 单一资源多线程抢占,引起死锁问题;线程间同步数据问题; 总结 为了简单: 更简单的dom渲染。js可以操控dom,而一…...
centos安装redis教程
centos安装redis教程 安装的版本为centos7.9下的redis3.2.100版本 1.下载地址 Index of /releases/ 使用xftp将redis传上去。 2.解压 tar -zxvf 文件名.tar.gz 3.安装 首先,确保系统已经安装了GCC编译器和make工具。可以使用以下命令进行安装: sudo y…...
把短信验证码储存在Redis
校验短信验证码 接着上一篇博客https://blog.csdn.net/qq_42981638/article/details/94656441,成功实现可以发送短信验证码之后,一般可以把验证码存放在redis中,并且设置存放时间,一般短信验证码都是1分钟或者90s过期,…...

【已编译资料】基于正点原子alpha开发板的第三篇系统移植
系统移植的三大步骤如下: 系统uboot移植系统linux移植系统rootfs制作 一言难尽,踩了不少坑,当时只是想学习驱动开发,发现必须要将第三篇系统移植弄好才可以学习后面驱动,现将移植好的文件分享出来: 仓库&…...

地下城堡3魂之诗食谱,地下城堡3菜谱37种
地下城堡3魂之诗食谱大全,让你解锁制作各种美食的方法!不同的食材搭配不同的配方制作,食物效果和失效也迥异。但有时候我们可能会不知道如何制作这些食物,下面为您介绍地下城堡3菜谱37种。 关注【娱乐天梯】,获取内部福…...
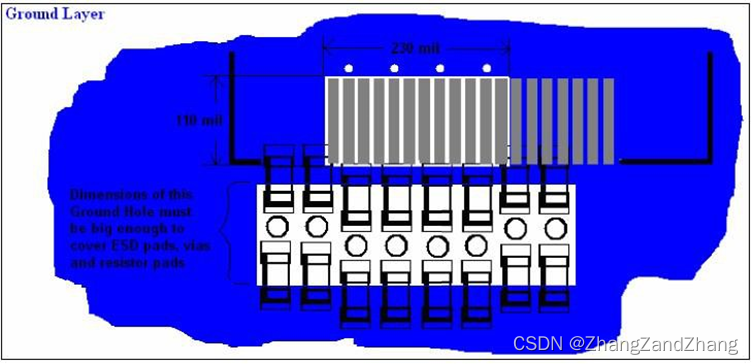
HDMI 基于 4 层 PCB 的布线指南
HDMI 基于 4 层 PCB 的布线指南 简介 HDMI 规范文件里面规定其差分线阻抗要求控制在 100Ω 15%,其中 Rev.1.3a 里面规定相对放宽了一些,容忍阻抗失控在 100Ω 25%范围内,不要超过 250ps。 通常,在 PCB 设计时,注意控…...

理解Go中的布尔逻辑
布尔数据类型(bool)可以是两个值之一,true或false。布尔值在编程中用于比较和控制程序流程。 布尔值表示与数学逻辑分支相关的真值,它指示计算机科学中的算法。布尔(Boolean)一词以数学家乔治布尔(George Boole)命名,总是以大写字母B开头。 …...
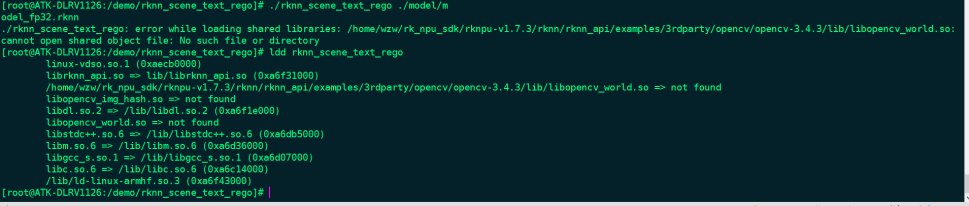
rv1126-rknpu-v1.7.3添加opencv库
rv1126所使用的rknn sdk里默认是不带opencv库的,官方所用的例程里也没有使用opencv,但是这样在进行图像处理的时候有点麻烦了,这里有两种办法: 一是先用python将所需要的图片处理好后在转化为bin格式文件,在使用c或c进行读取&…...

构建个人技能图谱:从结构化设计到自动化可视化的实践指南
1. 项目概述:一个技能图谱的诞生最近在GitHub上看到一个挺有意思的项目,叫dortort/skills。初看这个仓库名,你可能会有点懵,dortort是作者,那skills是什么?点进去一看,发现它不是一个具体的工具…...

MPLAB代码配置器实战:图形化配置PIC/AVR单片机外设,提升开发效率
1. 项目概述:为什么你需要关注MPLAB代码配置器如果你正在使用Microchip的PIC或AVR单片机,并且还在手动编写外设初始化代码、一遍遍翻阅数据手册核对寄存器位,那今天聊的这个工具,可能会让你有种“相见恨晚”的感觉。我说的就是MPL…...

多智能体涌现环境:从局部交互到群体智能的深度解析与实践
1. 项目概述:多智能体涌现环境的深度探索最近在复现和深入研究一个名为“multi-agent-emergence-environments”的开源项目,它来自OpenAI。这个项目名听起来有点学术,但它的核心思想非常迷人:在一个模拟的物理沙盒环境中ÿ…...

AI 能不能教孩子提问
AI 能不能教孩子提问 家长更该警惕的场景是:孩子一遇到卡点,就把题拍给 AI,等一个完整答案,然后连自己卡在哪里都说不出来。 这和用不用 AI 关系没那么简单。真正伤人的地方在于:孩子把困惑表达、假设尝试、错误修正这…...

企业级自动化运维平台OpenClaw:微内核插件化架构与实战部署指南
1. 项目概述:企业级开源自动化运维平台的构建最近在和一些做企业IT运维的朋友聊天,大家普遍提到一个痛点:随着业务系统越来越复杂,服务器、中间件、数据库的规模成倍增长,传统的运维方式已经力不从心。半夜被报警电话叫…...

多机驱动振动系统同步控制理论【附模型】
✨ 长期致力于振动机械、自同步、控制同步、GA-BP PID、定速比研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)GA-BP神经网络PID控制器设计及其参数自…...

Python驱动GitHub Actions状态监控:打造物理信号塔灯实时反馈CI/CD流水线
1. 项目概述与核心价值在团队协作开发中,持续集成与持续部署(CI/CD)的流水线状态是项目健康度的“晴雨表”。我们每天都会频繁地提交代码、触发构建,然后盯着GitHub Actions页面上那些或绿或红的标记。但问题在于,这种…...

4.AI大模型-幻觉、记忆、参数-大模型底层运行机制
内容参考于:图灵AI大模型全栈 幻觉: 大模型的幻觉主要有两种,一种是回答的答案和问的问题不搭边,就是说回答的答案是乱编的,是没有真实性的,另一种是给了AI正确的资料,但是AI并没有根据我们给的…...

FontForge:从零到一的免费字体设计全攻略
FontForge:从零到一的免费字体设计全攻略 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge 你是否曾经想过亲手设计一款属于自己的字体?也许你为…...

CANoe VN1640A的隐藏技能:CH5 I/O口实战应用,从采集电压到模拟传感器信号
CANoe VN1640A的CH5 I/O接口深度实战:从电压采集到传感器信号模拟 1. 揭开CH5接口的神秘面纱 在汽车电子测试领域,Vector的VN1640A接口模块以其稳定性和多功能性著称。大多数工程师熟悉其CAN/LIN通道的使用,却常常忽略了一个隐藏的宝藏——…...