掌握 BERT:自然语言处理 (NLP) 从初级到高级的综合指南(2)
BERT的先进技术
当您精通 BERT 后,就该探索先进技术以最大限度地发挥其潜力。在本章中,我们将深入研究微调、处理词汇外单词、领域适应,甚至从 BERT 中提取知识的策略。
微调策略:掌握适应
微调 BERT 需要仔细考虑。您不仅可以微调最终分类层,还可以微调中间层。这使得 BERT 能够更有效地适应您的特定任务。尝试不同的层和学习率以找到最佳组合。
处理词汇外 (OOV) 单词:驯服未知的单词
BERT 的词汇量不是无限的,因此它可能会遇到它无法识别的单词。处理 OOV 单词时,您可以使用 WordPiece 标记化将它们拆分为子单词。或者,您可以用特殊的标记替换它们,例如“[UNK]”表示未知。平衡 OOV 策略是一项可以通过练习提高的技能。
使用 BERT 进行领域适应:让 BERT 成为您的
BERT 虽然强大,但可能无法在每个领域都表现最佳。领域适应涉及对特定领域数据的 BERT 进行微调。通过将 BERT 暴露于特定领域的文本,它可以学习理解该领域的独特语言模式。这可以极大地提高其执行专门任务的性能。
BERT 的知识蒸馏:智慧的传承
知识蒸馏涉及训练较小的模型(学生)来模仿较大的预训练模型(教师)(如 BERT)的行为。这个紧凑的模型不仅可以学习老师的预测,还可以学习其信心和推理。当在资源受限的设备上部署 BERT 时,这种方法特别有用。
-
代码片段:使用拥抱面部变压器微调中间层
from transformers import BertForSequenceClassification, BertTokenizer
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
text = "Advanced fine-tuning with BERT."
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True)
outputs = model(**inputs, output_hidden_states=True)
intermediate_layer = outputs.hidden_states[6] # 7th layer
print(intermediate_layer)
此代码说明了使用 Hugging Face Transformer 微调 BERT 的中间层。提取中间层可以帮助针对特定任务更有效地微调 BERT。
当您探索这些先进技术时,您就正在掌握 BERT 的适应性和潜力。
最新发展和变体
随着自然语言处理 (NLP) 领域的发展,BERT 也在不断发展。在本章中,我们将探讨进一步增强 BERT 功能的最新发展和变体,包括 RoBERTa、ALBERT、DistilBERT 和 ELECTRA。
RoBERTa:超越 BERT 基础知识
RoBERTa 就像 BERT 聪明的兄弟姐妹。它采用更彻底的方法进行训练,涉及更大的批次、更多的数据和更多的训练步骤。这种增强的训练方案可以提高各种任务的语言理解和表现。
ALBERT:精简版 BERT
ALBERT 代表“精简版 BERT”。它的设计非常高效,使用参数共享技术来减少内存消耗。尽管尺寸较小,但 ALBERT 保留了 BERT 的功能,并且在资源有限时特别有用。
DistilBERT:紧凑但知识渊博
DistilBERT 是 BERT 的精简版本。它经过训练可以模仿 BERT 的行为,但参数较少。这使得 DistilBERT 更轻、更快,同时仍然保留了 BERT 的大部分性能。对于注重速度和效率的应用来说,这是一个不错的选择。
ELECTRA:高效地向 BERT 学习
ELECTRA 为培训引入了一个有趣的转折。 ELECTRA 不是预测屏蔽词,而是通过检测替换词是真实的还是人工生成的来进行训练。这种有效的方法使 ELECTRA 成为一种有前途的方法来训练大型模型,而无需完全计算成本。
-
代码片段:将 RoBERTa 与 Hugging Face Transformer 结合使用
from transformers import RobertaTokenizer, RobertaModel
import torch
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
model = RobertaModel.from_pretrained('roberta-base')
text = "RoBERTa is an advanced variant of BERT."
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True)
outputs = model(**inputs)
embeddings = outputs.last_hidden_state
print(embeddings)
此代码演示了如何使用 RoBERTa(BERT 的一种变体)使用 Hugging Face Transformer 生成上下文嵌入。
这些最新的发展和变体表明 BERT 的影响如何波及 NLP 领域,激发新的和增强的模型。
用于序列到序列任务的 BERT
在本章中,我们将探讨 BERT 最初是为理解单个句子而设计的,如何适用于更复杂的任务,例如序列到序列应用程序。我们将深入研究文本摘要、语言翻译,甚至它在对话式人工智能中的潜力。
用于文本摘要的 BERT:压缩信息
文本摘要涉及将较长文本的精髓提炼成较短的版本,同时保留其核心含义。尽管 BERT 不是专门为此构建的,但它仍然可以通过提供原始文本并使用它提供的上下文理解生成简洁的摘要来有效地使用。
用于语言翻译的 BERT:弥合语言差距
语言翻译涉及将文本从一种语言转换为另一种语言。虽然 BERT 本身不是翻译模型,但其上下文嵌入可以提高翻译模型的质量。通过理解单词的上下文,BERT 可以帮助在翻译过程中保留原文的细微差别。
对话式 AI 中的 BERT:理解对话
对话式人工智能不仅需要理解单个句子,还需要理解对话的流程。 BERT 的双向上下文在这里派上用场。它可以分析并生成上下文一致的响应,使其成为创建更具吸引力的聊天机器人和虚拟助手的宝贵工具。
-
代码片段:使用 BERT 和 Hugging Face Transformers 进行文本摘要
from transformers import BertTokenizer, BertForSequenceClassification
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
original_text = "Long text for summarization..."
inputs = tokenizer(original_text, return_tensors='pt', padding=True, truncation=True)
summary_logits = model(**inputs).logits
summary = tokenizer.decode(torch.argmax(summary_logits, dim=1))
print("Summary:", summary)
此代码演示了使用 BERT 使用 Hugging Face Transformer 进行文本摘要。该模型通过预测输入文本中最相关的部分来生成摘要。
当您探索 BERT 在序列到序列任务中的功能时,您会发现它对超出其原始设计的各种应用程序的适应性。
常见的挑战和缓解措施
尽管 BERT 很强大,但它也面临着挑战。在本章中,我们将深入探讨您在使用 BERT 时可能遇到的一些常见问题,并提供克服这些问题的策略。从处理长文本到管理计算资源,我们都能满足您的需求。
挑战一:处理长文本
BERT 对输入有最大标记限制,长文本可能会被截断。为了缓解这种情况,您可以将文本拆分为可管理的块并单独处理它们。您需要仔细管理这些块之间的上下文,以确保有意义的结果。
-
代码片段:使用 BERT 处理长文本
max_seq_length = 512 # Max token limit for BERT
text = "Long text to be handled..."
text_chunks = [text[i:i + max_seq_length] for i in range(0, len(text), max_seq_length)]
for chunk in text_chunks:
inputs = tokenizer(chunk, return_tensors='pt', padding=True, truncation=True)
outputs = model(**inputs)
# Process outputs for each chunk
挑战二:资源密集型计算
BERT 模型,尤其是较大的模型,对计算的要求可能很高。为了解决这个问题,您可以使用混合精度训练等技术,这可以减少内存消耗并加快训练速度。此外,您可以考虑使用较小的模型或云资源来执行繁重的任务。
-
代码片段:使用 BERT 进行混合精度训练
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
with autocast():
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True)
outputs = model(**inputs)
loss = outputs.loss
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
挑战3:领域适应
虽然 BERT 用途广泛,但它在某些领域可能无法发挥最佳性能。为了解决这个问题,请针对特定领域的数据微调 BERT。通过将其暴露于目标领域的文本,BERT 将学会理解该领域特有的细微差别和术语。
-
代码片段:使用 BERT 进行域适应
domain_data = load_domain_specific_data() # Load domain-specific dataset
domain_model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
train_domain(domain_model, domain_data)
应对这些挑战可确保您能够有效地利用 BERT 的功能,无论遇到多么复杂的情况。在最后一章中,我们将反思这段旅程并探索语言模型领域未来潜在的发展。不断突破 BERT 所能实现的极限!
BERT 的 NLP 未来方向
当我们结束对 BERT 的探索时,让我们展望未来,一睹自然语言处理 (NLP) 的激动人心的发展方向。从多语言理解到跨模式学习,以下是一些有望塑造 NLP 格局的趋势。
多语言和跨语言理解
BERT 的力量不仅限于英语。研究人员正在将研究范围扩大到多种语言。通过用多种语言训练 BERT,我们可以增强其理解和生成不同语言文本的能力。
-
代码片段:带有 Hugging Face Transformer 的多语言 BERT
from transformers import BertTokenizer, BertModel
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
model = BertModel.from_pretrained('bert-base-multilingual-cased')
text = "BERT understands multiple languages!"
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True)
outputs = model(**inputs)
embeddings = outputs.last_hidden_state
print(embeddings)
跨模态学习:超越文本
BERT 的上下文理解不仅限于文本。新兴研究正在探索其在图像和音频等其他形式数据中的应用。这种跨模式学习有望通过连接多个来源的信息来获得更深入的见解。
终身学习:适应变化
BERT 目前的训练涉及静态数据集,但未来的 NLP 模型可能会适应不断发展的语言趋势。终身学习模式不断更新他们的知识,确保他们随着语言和环境的发展而保持相关性。
-
代码片段:使用 BERT 进行终身学习
from transformers import BertForSequenceClassification, BertTokenizer
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
new_data = load_latest_data() # Load updated dataset
for epoch in range(epochs):
train_lifelong(model, new_data)
聊天机器人的量子飞跃:更加人性化的对话
GPT-3 等 NLP 模型的进步向我们展示了与 AI 进行更自然对话的潜力。随着 BERT 对上下文和对话的理解不断提高,未来会出现更加逼真的交互。
NLP 的未来充满创新和可能性。当您拥抱这些趋势时,请记住,BERT 作为语言理解基石的遗产将继续塑造我们与技术以及彼此互动的方式。保持你的好奇心,探索前方的领域!
使用 Hugging Face Transformers 库实施 BERT
现在您已经对 BERT 有了深入的了解,是时候将您的知识付诸实践了。在本章中,我们将深入研究使用 Hugging Face Transformers 库的实际实现,这是一个用于使用 BERT 和其他基于 Transformer 的模型的强大工具包。
安装Hugging Face Transformers
首先,您需要安装 Hugging Face Transformers 库。打开终端或命令提示符并使用以下命令:
pip install transformers
加载预训练的 BERT 模型
Hugging Face Transformers 可以轻松加载预训练的 BERT 模型。您可以选择各种型号尺寸和配置。让我们加载一个用于文本分类的基本 BERT 模型:
from transformers import BertForSequenceClassification, BertTokenizer
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
文本标记化和编码
BERT 以标记化形式处理文本。您需要使用分词器对文本进行分词并针对模型进行编码:
text = "BERT is amazing!"
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True)
做出预测
对文本进行编码后,您可以使用该模型进行预测。例如,我们进行情感分析:
outputs = model(**inputs)
predicted_class = torch.argmax(outputs.logits).item()
print("Predicted Sentiment Class:", predicted_class)
微调 BERT
针对特定任务微调 BERT 包括加载预训练模型、使其适应您的任务以及在数据集上对其进行训练。这是文本分类的简化示例:
from transformers import BertForSequenceClassification, BertTokenizer, AdamW
import torch
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
text = "Sample text for training."
label = 1 # Assuming positive sentiment
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True)
outputs = model(**inputs, labels=torch.tensor([label]))
loss = outputs.loss
optimizer = AdamW(model.parameters(), lr=1e-5)
loss.backward()
optimizer.step()
探索更多任务和模型
Hugging Face Transformers 库提供了广泛的模型和任务供探索。您可以针对文本分类、命名实体识别、问题回答等微调 BERT。
当您尝试 Hugging Face Transformers 库时,您会发现它是在项目中实现 BERT 和其他基于 Transformer 的模型的宝贵工具。享受将理论转化为实际应用的旅程!
总结
在这篇博文中,我们踏上了 BERT 变革世界的启发之旅——来自 Transformers 的双向编码器表示。从诞生到实际实施,我们已经了解了 BERT 对自然语言处理 (NLP) 及其他领域的影响。
我们深入研究了在现实场景中使用 BERT 所带来的挑战,发现了解决处理长文本和管理计算资源等问题的策略。我们对 Hugging Face Transformers 库的探索为您提供了实用的工具,可以在您自己的项目中利用 BERT 的强大功能。
当我们展望未来时,我们看到了 NLP 的无限可能性——从多语言理解到跨模态学习以及语言模型的不断演变。
我们的旅程并没有结束。 BERT 为语言理解的新时代奠定了基础,弥合了机器与人类交流之间的差距。当您冒险进入人工智能的动态世界时,请记住 BERT 是进一步创新的垫脚石。探索更多、了解更多、创造更多,因为技术的前沿在不断扩展。
感谢您加入我们对 BERT 的探索。当您继续学习之旅时,愿您的好奇心引领您揭开更大的谜团,并为人工智能和自然语言处理的变革做出贡献。
完!
本文由 mdnice 多平台发布
相关文章:
 从初级到高级的综合指南(2))
掌握 BERT:自然语言处理 (NLP) 从初级到高级的综合指南(2)
BERT的先进技术 当您精通 BERT 后,就该探索先进技术以最大限度地发挥其潜力。在本章中,我们将深入研究微调、处理词汇外单词、领域适应,甚至从 BERT 中提取知识的策略。 微调策略:掌握适应 微调 BERT 需要仔细考虑。您不仅可以微调…...
【算法优选】 二分查找专题——贰
文章目录 😎前言🌲[山脉数组的峰顶索引](https://leetcode.cn/problems/peak-index-in-a-mountain-array/)🚩题目描述:🚩算法思路🚩代码实现: 🌴[寻找峰值](https://leetcode.cn/pro…...

SQL 的优化
SQL 优化是指对数据库查询语句进行优化,以提高查询性能和效率。下面列出了一些常见的 SQL 优化技巧: 1、索引优化 (1)使用适当的索引来加速查询操作。在频繁用于查询的列上创建索引,特别是在 WHERE 条件、JOIN 条件和…...

华为云云耀云服务器L实例评测|华为云上的CentOS性能监测与调优指南
目录 引言 编辑1 性能调优的基本要素 2 性能监控功能 2.1 监控数据指标 2.2 数据历史记录 2.3 多种统计指标 3 性能优化策略 3.1 资源分配 3.2 磁盘性能优化 3.3 网络性能优化 3.4 操作系统参数和内核优化 结论 引言 在云计算时代,性能优化和调优对于…...

Go If流程控制与快乐路径原则
Go if流程控制与快乐路径原则 文章目录 Go if流程控制与快乐路径原则一、流程控制基本介绍二、if 语句2.1 if 语句介绍2.2 单分支结构的 if 语句形式2.3 Go 的 if 语句的特点2.3.1 分支代码块左大括号与if同行2.3.2 条件表达式不需要括号 三、操作符3.1 逻辑操作符3.2 操作符的…...

yolov8 strongSORT多目标跟踪工具箱BOXMOT
1 引言 多目标跟踪MOT项目在Github中比较完整有:BOXMOT , 由mikel brostrom提供。在以前的版本中,有yolov5deepsort(版本v3-v5), yolov8strongsort(版本v6-v9),直至演变…...

如何开发一款跑酷游戏?
跑酷游戏(Parkour Game)是一种流行的视频游戏类型,玩家需要在游戏中控制角色进行极限动作、跳跃、爬墙和各种动作,以完成各种挑战和任务。如果你有兴趣开发一款跑酷游戏,以下是一些关键步骤和考虑事项: 游…...
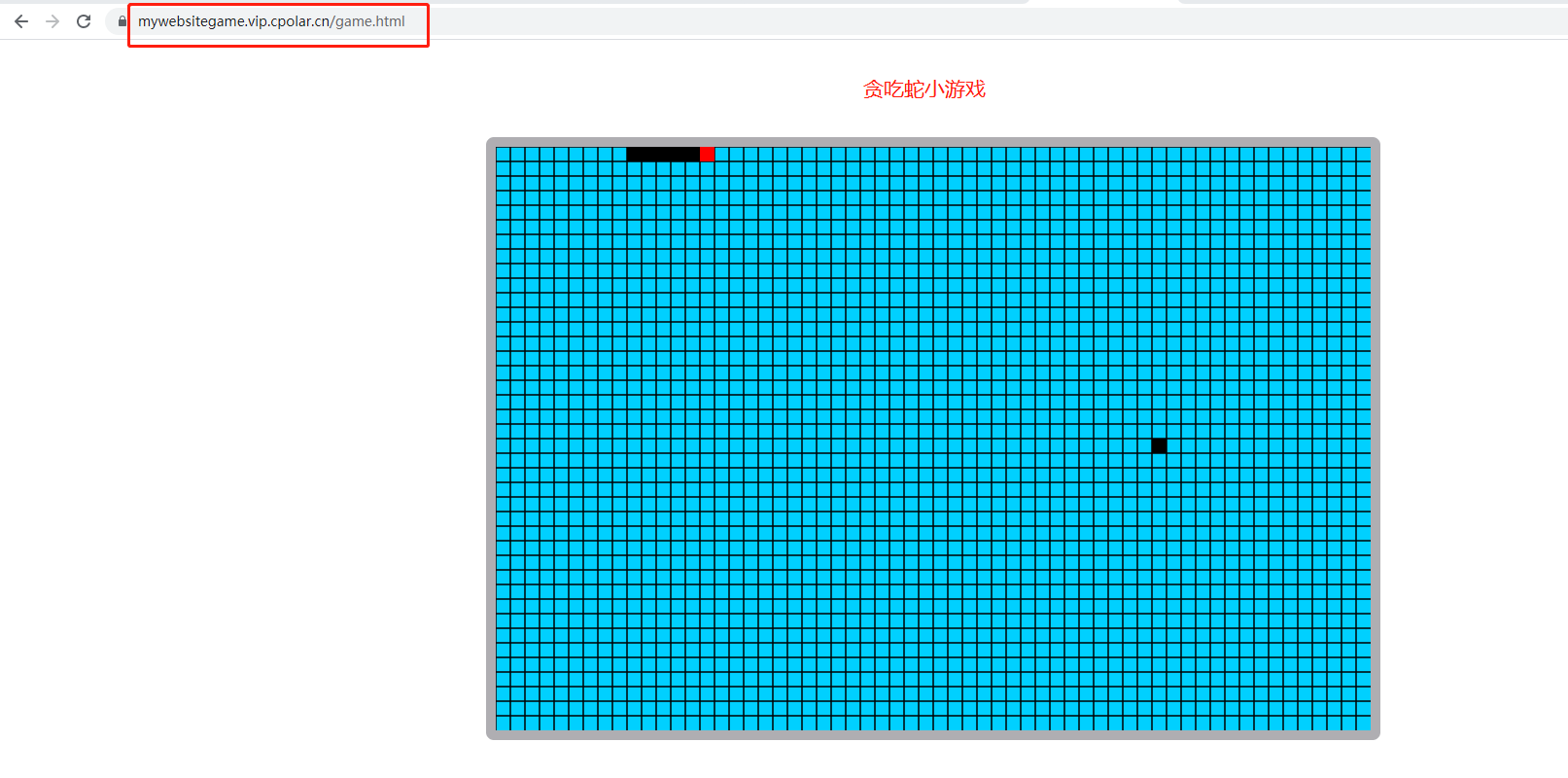
使用宝塔面板在Linux上搭建网站,并通过内网穿透实现公网访问
文章目录 前言1. 环境安装2. 安装cpolar内网穿透3. 内网穿透4. 固定http地址5. 配置二级子域名6. 创建一个测试页面 前言 宝塔面板作为简单好用的服务器运维管理面板,它支持Linux/Windows系统,我们可用它来一键配置LAMP/LNMP环境、网站、数据库、FTP等&…...

Unity可视化Shader工具ASE介绍——6、通过例子说明ASE节点的连接方式
大家好,我是阿赵。继续介绍Unity可视化Shader编辑插件ASE的用法。上一篇已经介绍了很多ASE常用的节点。这一篇通过几个小例子,来看看这些节点是怎样连接使用的。 这篇的内容可能会比较长,最终是做了一个遮挡X光的效果,不过把这…...
VUE3基础知识梳理
VUE3基础知识梳理 一、vue了解和环境搭建1.vue是什么:cn.vuejs.org/vuejs.org2.渐进式框架3.vue的版本4.vueAPI的风格5.准备环境5.1.创建vue项目5.2.vue的目录结构 二、vue3语法1.干净的vue项目2.模板语法2.1 文本插值2.2属性绑定2.3条件渲染2.4列表渲染2.5通过key管…...

Java架构师缓存通用设计方案
目录 1 采用多级缓存2 缓存数据尽量前移3 静态化4 数据平衡策略5 jvm缓存的问题6 redis存放数据解决7 redis垂直拆分8 总结1 采用多级缓存 在实际应用中需要考虑的实际问题。首先,前端页面可以做缓存,虽然图上没有显示,但在现实应用中这是提高性能的一个重要方面。前端页面缓…...
2023年【危险化学品生产单位安全生产管理人员】及危险化学品生产单位安全生产管理人员模拟考试题
题库来源:安全生产模拟考试一点通公众号小程序 危险化学品生产单位安全生产管理人员考前必练!安全生产模拟考试一点通每个月更新危险化学品生产单位安全生产管理人员模拟考试题题目及答案!多做几遍,其实通过危险化学品生产单位安…...
微信小程序 在bindscroll事件中监听scroll-view滚动到底
scroll-view其实提供了一个 bindscrolltolower 事件 这个事件的作用是直接监听scroll-view滚动到底部 但是 总有不太一样的情况 公司的项目 scroll-view 内部 最下面有一个 类名叫 bottombj 的元素 我希望 滚动到这个 bottombj 上面的时候就开始加载滚动分页 简单说 bottombj这…...
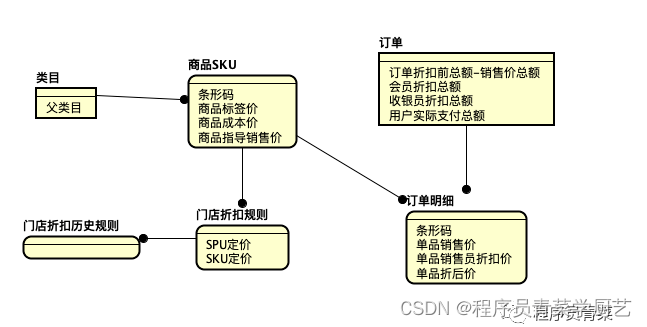
收银系统商品定价设计思考
一、背景 因为门店系统里商品总共也就几万款,一直以来都是根据条码由总部统一定价销售,现在有加盟店,各门店也有进行各自促销活动的需求,这就需要放开门店自主定价权,所以近段时间系统在商品定价上做了扩展。 二、商…...
Kotlin函数作为参数指向不同逻辑
Kotlin函数作为参数指向不同逻辑 fun sum(): (Int, Int) -> Int {return { a, b -> (a b) } }fun multiplication(): (Int, Int) -> Int {return { a, b -> (a * b) } }fun main(args: Array<String>) {var math: (Int, Int) -> Intmath sum()println(m…...

读书笔记—《如何阅读一本书》
读书笔记—《如何阅读一本书》 一、阅读的层次1、主动阅读的基础一个阅读者要提出的四个基本问题 2、基础阅读(第一层)3、检视阅读(第二层)4、分析阅读(第三层) 二、阅读不同读物的方法三、阅读的最终目标1…...

Kafka数据同步原理详解
Kafka数据同步原理详解 Kafka是一种分布式的消息队列系统,它具有高吞吐量、可扩展性和分布式特性等优势。在Kafka中,数据按照主题进行分区,每个主题都有一组分区。每个分区都有自己的生产者和消费者,生产者负责向分区中写入消息&…...

C++课程总复习
一、c的第一条程序 1.cout cout >输出类对象,用来输出的,可以自动识别类型,所以不需要加格式符号 << 插入符(输出符号) endl 换行>\n #include <iostream> //#预处理 //include 包含 相应的头…...

数据结构—顺序表
目录 1.线性表 2.顺序表概念 3.实现顺序表 (1)声明结构体 (2)初始化 (3)打印数据 (4) 销毁 (5)尾插&头插 尾插 判断是否扩容 头插 (6)尾删&头删 尾删 头删 (7)指定位置插入元素 (8)删除指定位置元素 (9)查找指定元素位置 (10)修改指定位置元素 完整版…...

企业服务器租用对性能有什么要求呢?
企业租用服务器租用首要的是稳定,其次是安全,稳定是为了让企业的工作能够顺利进行,只有性能稳定的服务器才能保证网站之类的正常工作,就让小编带大家看一看有什么要求吧! 服务器简单介绍。服务器是在网络上为其它客户机…...

Node.js性能预测工具nodestradamus:从监控到预警的实践指南
1. 项目概述与核心价值最近在折腾一些服务器监控和性能预测的活儿,偶然间在GitHub上发现了一个叫nodestradamus的项目,作者是ChristosGrigoras。这个名字挺有意思,结合了“Node.js”和“诺查丹玛斯”(那位著名的预言家)…...

CFETR重载机械臂精确运动控制验证【附仿真】
✨ 长期致力于中国聚变工程实验堆、遥操作、多功能重载机械臂、路径规划、精确控制、数据融合控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)刚柔…...

树莓派5本地大模型实时分析SEN6x环境传感器数据实战
1. 项目概述:当环境传感器遇上本地大模型在物联网和边缘计算领域,我们早已习惯了这样的工作流:传感器采集数据,微控制器或单板计算机(比如树莓派)负责收集和上传,最终的数据分析和洞察则交给云端…...

Windows11下DOSBox从零到精通的完整配置与实战指南
1. 为什么要在Windows11上使用DOSBox? 很多年轻朋友可能都没见过DOS系统长什么样。作为上世纪80年代到90年代的主流操作系统,DOS虽然界面简陋,但它孕育了无数经典软件和游戏。直到今天,学习汇编语言、运行老式工业控制程序、怀旧经…...

告别命令行!用Python脚本批量管理Docker容器和镜像的实战技巧
告别命令行!用Python脚本批量管理Docker容器和镜像的实战技巧 在DevOps和云原生技术快速发展的今天,Docker已经成为现代应用部署的标准工具。然而,随着容器数量的增加和部署频率的提高,手动通过命令行管理Docker容器和镜像变得越来…...

MAA明日方舟小助手:让游戏回归乐趣的智能伙伴
MAA明日方舟小助手:让游戏回归乐趣的智能伙伴 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitcode.com…...


Steam库存管理革命:5分钟掌握批量操作终极指南
Steam库存管理革命:5分钟掌握批量操作终极指南 【免费下载链接】Steam-Economy-Enhancer 中文版:Enhances the Steam Inventory and Steam Market. 项目地址: https://gitcode.com/gh_mirrors/ste/Steam-Economy-Enhancer Steam Economy Enhancer…...

Horos:免费开源医学影像软件,3D医疗图像处理的终极指南
Horos:免费开源医学影像软件,3D医疗图像处理的终极指南 【免费下载链接】horos Horos™ is a free, open source medical image viewer. The goal of the Horos Project is to develop a fully functional, 64-bit medical image viewer for OS X. Horos…...

CellProfiler:生物图像分析的瑞士军刀,让科研更智能更高效
CellProfiler:生物图像分析的瑞士军刀,让科研更智能更高效 【免费下载链接】CellProfiler An open-source application for biological image analysis 项目地址: https://gitcode.com/gh_mirrors/ce/CellProfiler 你是否曾经面对成百上千张细胞图…...