在 Amazon SageMaker 上使用 ESMFold 语言模型加速蛋白质结构预测

蛋白质驱动着许多生物过程,如酶活性、分子输运和细胞支持。通过蛋白质的三维结构,可以深入了解蛋白质的功能以及蛋白质如何与其他生物分子相互作用。测定蛋白质结构的实验方法(如 X 射线晶体学和核磁共振波谱学)既昂贵又耗时。相比之下,最近开发的几种计算方法能够根据蛋白质的氨基酸序列快速准确地预测蛋白质的结构。这些方法对于难以通过实验研究的蛋白质至关重要,例如膜蛋白,它是许多药物的靶标。
在这些方法中,一个众所周知的例子是 AlphaFold,这是一种基于深度学习的算法,因其预测准确而闻名于世;来自 FAIR 的 ESMFold 是另一种基于深度学习的高精度方法,用于根据氨基酸序列预测蛋白质结构。ESMFold 以大型蛋白质语言模型(pLM)为骨干,进行端到端的操作。与 AlphaFold2 不同,这种方法不需要查找或 多序列比对(MSA)步骤,也不依赖外部数据库来生成预测结果。取而代之的是,FAIR Research 团队根据 UniRef 的数百万个蛋白质序列对模型进行了训练。在训练过程中,该模型开发了注意力模式,这些模式优雅地代表了序列中氨基酸之间的进化相互作用。使用 pLM 代替 MSA 后,可使预测时间比其他先进模型快60倍。这种速度使 FAIR 团队能够创建开源的 ESM 宏基因组图谱,该图谱由超过7.7亿个宏基因组蛋白质结构预测组成。
在本文中,我们使用 Hugging Face Hub 上提供的预训练 ESMFold 模型和 Amazon SageMaker,来预测曲妥珠单抗的重链结构,曲妥珠单抗是一种由 Genentech 首次开发的用于治疗 HER2 阳性乳腺癌的 单克隆抗体。如果研究人员想测试序列修饰的效果,快速预测这种蛋白质的结构可能非常有用。这有可能提高患者的生存率或减少药物副作用。这篇文章提供了一个 Jupyter notebook 示例,相关脚本位于以下 GitHub 存储库中:https://github.com/aws-samples/aws-healthcare-lifescience-ai-ml-sample-notebooks/tree/main/workshops/AI_Driven_Protein_Analysis
先决条件
我们建议在 Amazon SageMaker 工作室笔记本电脑中运行这个示例,该笔记本电脑在 ml.r5.xlarge 实例类型上运行 PyTorch 1.13 Python 3.9 CPU 优化的映像。
以视觉形式呈现
曲妥珠单抗的实验结构
首先,我们使用 biopython 库和辅助脚本从 RCSB 蛋白质数据库下载曲妥珠单抗结构:
from Bio.PDB import PDBList, MMCIFParser
from prothelpers.structure import atoms_to_pdbtarget_id = "1N8Z"
pdbl = PDBList()
filename = pdbl.retrieve_pdb_file(target_id, pdir="data")
parser = MMCIFParser()
structure = parser.get_structure(target_id, filename)
pdb_string = atoms_to_pdb(structure)左滑查看更多
接下来,我们使用 py3Dmol 库将结构可视化为交互式 3D 视觉内容:
view = py3Dmol.view()
view.addModel(pdb_string)
view.setStyle({'chain':'A'},{"cartoon": {'color': 'orange'}})
view.setStyle({'chain':'B'},{"cartoon": {'color': 'blue'}})
view.setStyle({'chain':'C'},{"cartoon": {'color': 'green'}})
view.show()左滑查看更多
下图显示了蛋白质数据库(PDB)中 1N8Z 的 3D 蛋白质结构。在此图中,曲妥珠单抗轻链显示为橙色,重链显示为蓝色(可变区为浅蓝色),HER2 抗原显示为绿色。

我们将首先使用 ESMFold,根据氨基酸序列预测重链(链 B)的结构。然后,将预测结果与上面显示的实验测定的结构进行对比。
使用 ESMFold
根据曲妥珠单抗重链序列预测其结构
让我们使用 ESMFold 模型来预测重链的结构,并将其与实验结果进行对比。首先,使用 Studio 中预置的 notebook 环境,该环境预装了几个重要的库,如 PyTorch。虽然我们能够使用加速实例类型来提高 notebook 分析的性能,但现在我们改用非加速实例,并在 CPU 上运行 ESMFold 预测。
首先,从 Hugging Face Hub 加载预训练的 ESMFold 模型和标记器:
from transformers import AutoTokenizer, EsmForProteinFoldingtokenizer = AutoTokenizer.from_pretrained("facebook/esmfold_v1")
model = EsmForProteinFolding.from_pretrained("facebook/esmfold_v1", low_cpu_mem_usage=True)左滑查看更多
接下来,将模型复制到我们的设备(本例中为 CPU),并设置一些模型参数:
device = torch.device("cpu")
model.esm = model.esm.float()
model = model.to(device)
model.trunk.set_chunk_size(64)左滑查看更多
为了准备用于分析的蛋白质序列,我们需要对其进行标记化处理。这样可以将氨基酸符号(EVQLV…)转换为 ESMFold 模型可以理解的数字格式(6,19,5,10,19,…):
tokenized_input = tokenizer([experimental_sequence], return_tensors="pt", add_special_tokens=False)["input_ids"]
tokenized_input = tokenized_input.to(device)左滑查看更多
接下来,我们将标记化输入复制到模式中,进行预测,并将结果保存到文件中:
with torch.no_grad():
notebook_prediction = model.infer_pdb(experimental_sequence)
with open("data/prediction.pdb", "w") as f:
f.write(notebook_prediction)左滑查看更多
对于非加速实例类型(如 r5),这大约需要3分钟。
我们可以通过对比实验结构,来检验 ESMFold 预测的准确性。我们使用密歇根大学 Zhang Lab 开发的 US-Align 工具来完成这项工作:
from prothelpers.usalign import tmscoretmscore("data/prediction.pdb", "data/experimental.pdb", pymol="data/superimposed")左滑查看更多

模板建模得分(TM-score)是评测蛋白质结构相似性的指标。得分为 1.0 表示完全匹配。得分高于 0.7 表示两个蛋白质具有相同的骨干结构。得分高于 0.9 表示蛋白质在下游使用中具有功能互换性。在我们的示例中,TM-Score 达到 0.802,表示 ESMFold 预测可能适用于结构评分或配体结合实验等应用,但可能不适用于分子置换等需要极高精度的使用案例。
我们可以通过可视化对齐结构来验证这一结果。这两个结构的重叠程度很高,但并不完全重叠。蛋白质结构预测是一个快速发展的领域,许多研究团队都在开发越来越精确的算法!
将 ESMFold 部署为
SageMaker 推理端点
在 notebook 中运行模型推理可用于实验目的,但如果需要将模型与应用程序集成呢?或者是与 MLOps 管道集成呢?在这种情况下,更好的选择是将模型部署为推理端点。在下面的示例中,我们将 ESMFold 作为 SageMaker 实时推理端点部署在加速实例上。SageMaker 实时端点提供了一种可扩展、经济高效且安全的方式来部署和托管机器学习(ML)模型。通过自动扩缩,您可以调整运行端点的实例数量以满足应用程序的需求,从而优化成本并确保高可用性。
利用预置的 Hugging Face 的 SageMaker 容器,可以轻松地为常见任务部署深度学习模型。然而,对于像蛋白质结构预测这样的新使用案例,我们需要定义一个自定义的 inference.py 脚本,来加载模型、运行预测和格式化输出内容。该脚本包含的代码与我们在 notebook 中使用的代码基本相同。我们还创建了一个 requirements.txt 文件来定义一些 Python 依赖关系,供我们的端点使用。您可以在 GitHub 存储库中看到我们创建的文件:https://github.com/aws-samples/aws-healthcare-lifescience-ai-ml-sample-notebooks/tree/main/workshops/AI_Driven_Protein_Analysis
在下图中,曲妥珠单抗重链的实验(蓝色)和预测(红色)结构非常相似,但并不完全相同。

在 code 目录中创建了必要的文件后,我们使用 SageMaker HuggingFaceModel 类部署模型。该类使用一个预置的容器,简化将 Hugging Face 模型部署到 SageMaker 的过程。请注意,创建端点可能需要 10 分钟或更长时间,具体取决于我们区域中 ml.g4dn 实例类型的可用性。
from sagemaker.huggingface import HuggingFaceModel
from datetime import datetimehuggingface_model = HuggingFaceModel(
model_data = model_artifact_s3_uri, # Previously staged in S3
name = f"emsfold-v1-model-" + datetime.now().strftime("%Y%m%d%s"),
transformers_version='4.17',
pytorch_version='1.10',
py_version='py38',
role=role,
source_dir = "code",
entry_point = "inference.py"
)rt_predictor = huggingface_model.deploy(
initial_instance_count = 1,
instance_type="ml.g4dn.2xlarge",
endpoint_name=f"my-esmfold-endpoint",
serializer = sagemaker.serializers.JSONSerializer(),
deserializer = sagemaker.deserializers.JSONDeserializer()
)左滑查看更多
完成端点部署后,我们可以重新提交蛋白质序列,并显示预测的前几行内容:
endpoint_prediction = rt_predictor.predict(experimental_sequence)[0]
print(endpoint_prediction[:900])左滑查看更多
由于我们将端点部署到加速实例中,因此预测应该只需几秒钟。结果中的每一行对应于一个原子,包括氨基酸标识、三个空间坐标和表示该位置预测置信度的 pLDDT 分数。

使用与以前相同的方法,我们可以看到 notebook 和端点的预测结果完全相同。

如下图所示,在 notebook 中生成的 ESMFold 预测结果(红色)与端点生成的预测结果(蓝色)完全一致。

清理
为了避免产生进一步的费用,我们删除了推理端点和测试数据:
rt_predictor.delete_endpoint()
bucket = boto_session.resource("s3").Bucket(bucket)
bucket.objects.filter(Prefix=prefix).delete()
os.system("rm -rf data obsolete code")左滑查看更多
小结
蛋白质结构计算预测是了解蛋白质功能的重要工具。除基础研究外,AlphaFold 和 ESMFold 等算法在医学和生物技术领域也有很多应用。利用这些模型生成的结构洞察,有助于我们更好地了解生物分子是如何相互作用的。这样就能为患者提供更好的诊断工具和疗法。
在这篇文章中,我们将展示如何使用 SageMaker 将 Hugging Face Hub 的 ESMFold 蛋白质语言模型部署为可扩展的推理端点。有关在 SageMaker 上部署 Hugging Face 模型的更多信息,请参阅结合使用 Hugging Face 与 Amazon SageMaker (https://docs.aws.amazon.com/sagemaker/latest/dg/hugging-face.html)。您还可以在 Awesome Protein Analysis on Amazon GitHub 存储库中找到更多蛋白质科学示例。
Original URL:
https://aws.amazon.com/blogs/machine-learning/accelerate-protein-structure-prediction-with-the-esmfold-language-model-on-amazon-sagemaker/
本篇作者

Brian Loyal
Amazon Web Services 全球医疗保健和生命科学团队的高级人工智能/机器学习解决方案架构师。他在生物技术和机器学习领域拥有超过17年的经验,热衷于协助客户解决基因组和蛋白质组学方面的难题。在业余时间,他喜欢烹饪,享受与朋友和家人的就餐时光。

Shamika Ariyawansa
Amazon Web Services 全球医疗保健和生命科学团队的人工智能/机器学习专业解决方案架构师。他热衷于与客户合作,通过提供技术指导,促进客户在亚马逊云科技上进行创新和构建安全的云解决方案,从而加快客户采用人工智能和机器学习的速度。工作之余,他喜欢滑雪和越野运动。

Yanjun Qi
Amazon Machine Learning 解决方案实验室的高级应用科学经理。她通过创新和运用机器学习,协助亚马逊云科技客户加快采用人工智能和云技术的速度。

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!

相关文章:
在 Amazon SageMaker 上使用 ESMFold 语言模型加速蛋白质结构预测
蛋白质驱动着许多生物过程,如酶活性、分子输运和细胞支持。通过蛋白质的三维结构,可以深入了解蛋白质的功能以及蛋白质如何与其他生物分子相互作用。测定蛋白质结构的实验方法(如 X 射线晶体学和核磁共振波谱学)既昂贵又耗时。相比…...
-每天了解一点)
node.js知识系列(4)-每天了解一点
目录 11. 异步文件操作文件读取文件写入 12. 包管理器(npm)13. 子进程14. 事件发射器(EventEmitter)15. 异步编程和回调16. Node.js 集成测试工具和框架17. Express.js 中间件的 HTTP 请求流程18. 文件上传和验证19. Express.js 中…...
can not remove .unionfs
文件夹下出现unionfs 套娃,无法删除。 处理方式: 需要管理员权限umount之后删除使用fusermount -zu .unionfs ,然后再删除。...
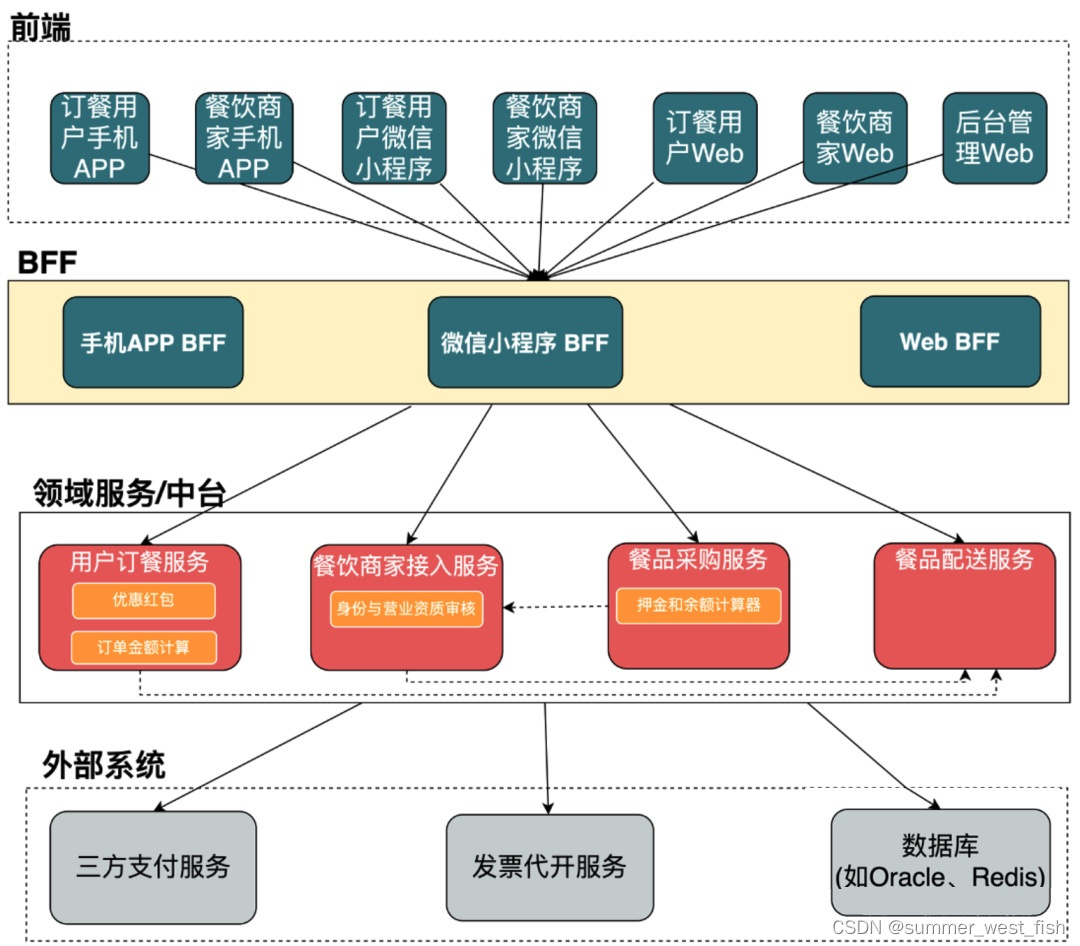
微服务 BFF 架构设计
在现代软件开发中,由于程序、团队、数据规模太大,需要把企业的业务能力进行复用,将领域服务剥离,提供通用能力,避免重复建设和代码;另外服务功能的弹性能力不一样,比如定时任务、数据同步明确的…...

零基础学python之元组
文章目录 元组1、元组的应用场景2、定义元组3、元组的常见操作4、总结 元组 目标 元组的应用场景定义元组元组常见操作 1、元组的应用场景 思考:如果想要存储多个数据,但是这些数据是不能修改的数据,怎么做? 答:列…...

11. SpringBoot项目中参数获取与响应
SpringBoot项目中参数获取与响应 1. 程序结构&通信方式 程序结构: C/S : 客户端/服务器端 -Main方法。 -效果炫目、数据相对安全。 -公司成本高,因为要分别开发客户端和服务器端。 B/S: 浏览器端/服务器端 -效果依赖于浏览…...
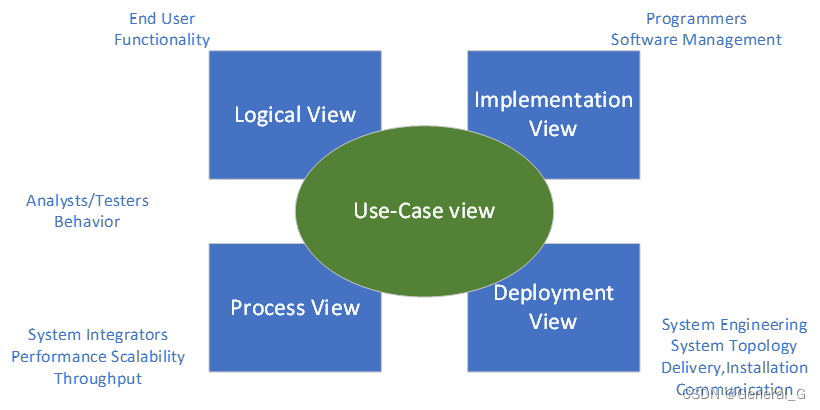
4+1视图与UML
目录 逻辑视图过程视图开发视图物理视图(部署视图)用例视图 41视图,即逻辑视图,过程视图,实现视图,部署视图,用例视图。 为什么不用一个视图? 针对多个用户,即终端用户&a…...

没用的知识增加了,尝试用文心实现褒义词贬义词快速分类
尝试用文心实现褒义词贬义词快速分类 一、我的需求二、项目环境搭建千帆SDK安装及使用流程 三、项目实现过程创建应用获取签名调用接口计算向量积总结 百度世界大会将于10月17日在北京首钢园举办,今天进入倒计时五天了。通过官方渠道的信息了解到,这次是…...
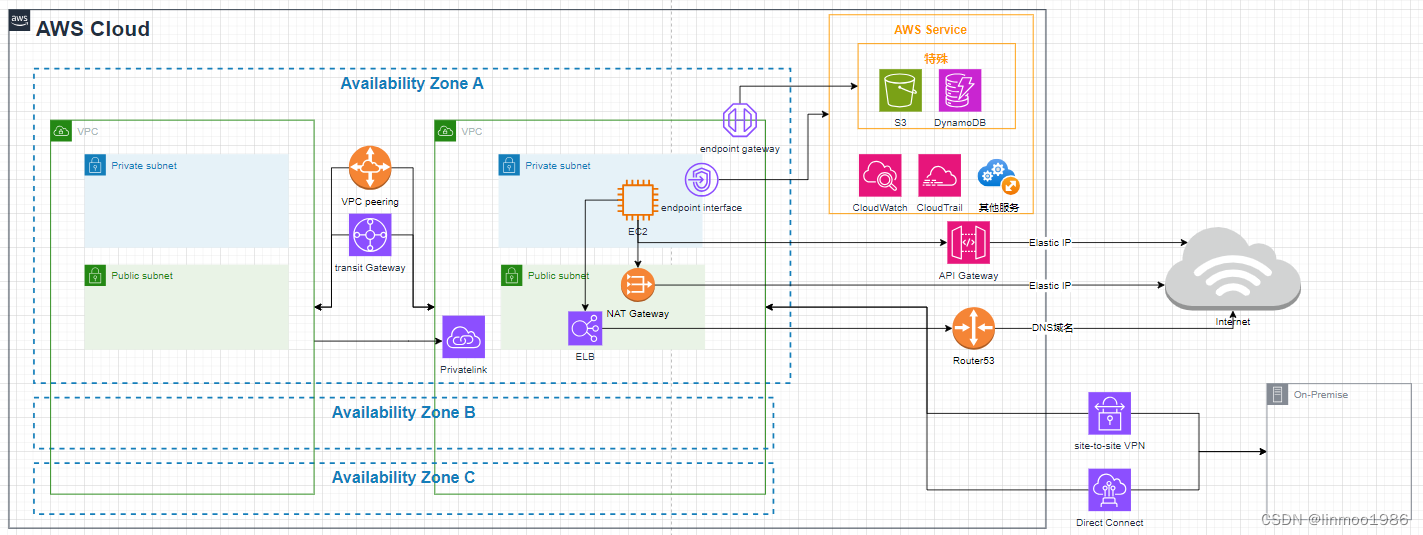
AWS SAP-C02教程3--网络资源
架构设计中网络也是少不了的一个环节,而AWS有自身的网络结构和网络产品。本章中将带你看看AWS中不同网络产品,以及计算资源、存储资源等产品在网络架构中处于哪个位置,如何才能让它们与互联网互通、与其它产品互通。下图视图将SAP涉及到网络相关组件在一张图表示出来,图中可…...

【TensorFlow2 之012】TF2.0 中的 TF 迁移学习
#012 TensorFlow 2.0 中的 TF 迁移学习 一、说明 在这篇文章中,我们将展示如何在不从头开始构建计算机视觉模型的情况下构建它。迁移学习背后的想法是,在大型数据集上训练的神经网络可以将其知识应用于以前从未见过的数据集。也就是说,为什么…...

mysql面试题46:MySQL中datetime和timestamp的区别
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:MySQL中DATETIME和TIMESTAMP的区别 在MySQL中,DATETIME和TIMESTAMP是两种用于存储日期和时间的数据类型。虽然它们都可以用于存储日期和时间信息…...

【Spring Boot】RabbitMQ消息队列 — RabbitMQ入门
💠一名热衷于分享知识的程序员 💠乐于在CSDN上与广大开发者交流学习。 💠希望通过每一次学习,让更多读者了解我 💠也希望能结识更多志同道合的朋友。 💠将继续努力,不断提升自己的专业技能,创造更多价值。🌿欢迎来到@"衍生星球"的CSDN博文🌿 🍁本…...
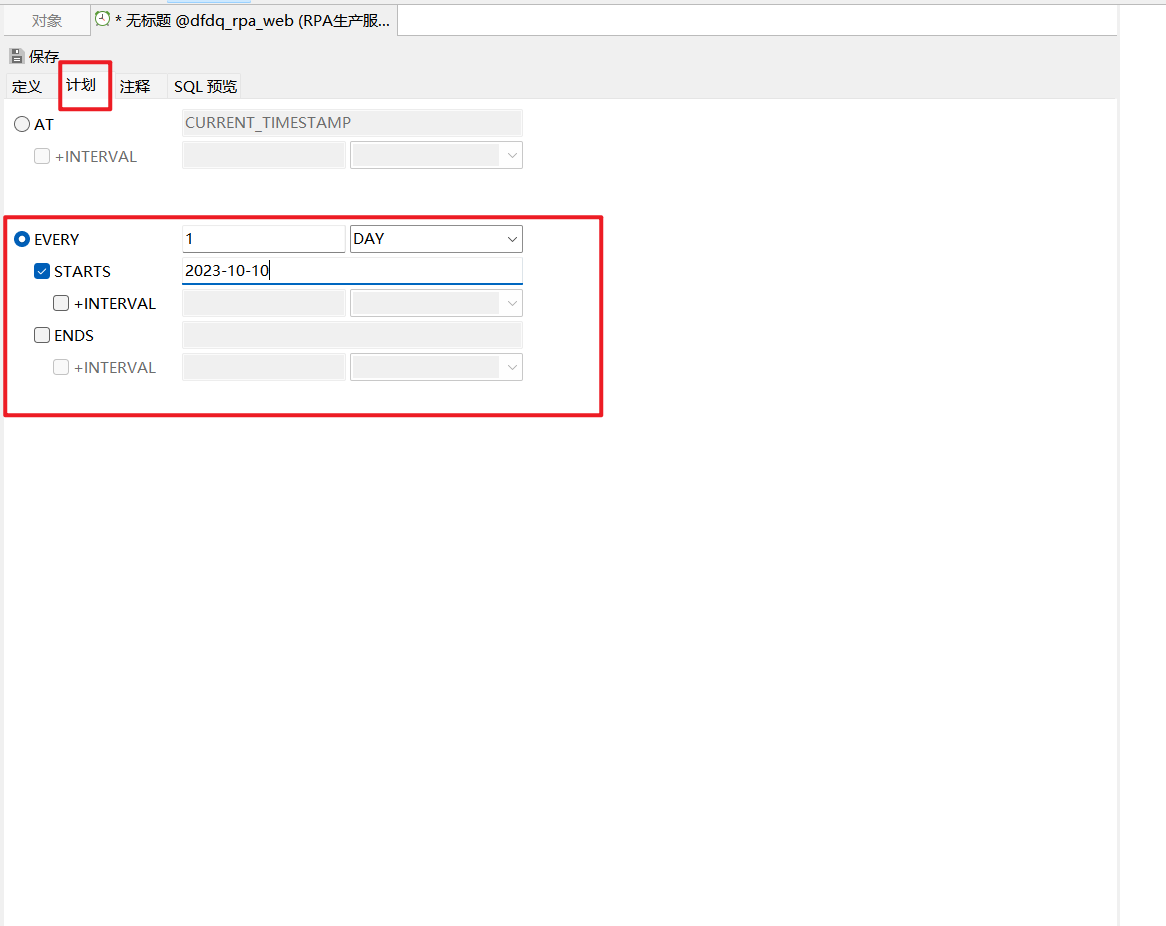
Navicat定时任务
Navicat定时任务 1、启动Navicat for MySQL工具,连接数据库。 2、查询定时任务选项是否开启 查询命令:SHOW VARIABLES LIKE ‘%event_scheduler%’; ON表示打开,OFF表示关闭。 打开定时任务命令 SET GLOBAL event_scheduler 0; 或者 SET G…...
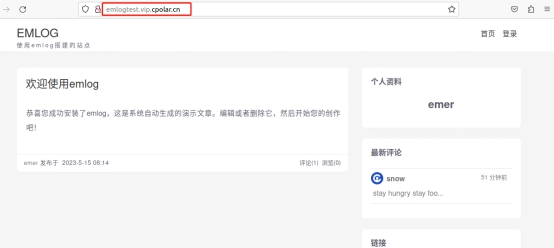
小白必备:简单几步, 使用Cpolar+Emlog在Ubuntu上搭建个人博客网站
文章目录 前言1. 网站搭建1.1 Emolog网页下载和安装1.2 网页测试1.3 cpolar的安装和注册 2. 本地网页发布2.1 Cpolar临时数据隧道2.2.Cpolar稳定隧道(云端设置)2.3.Cpolar稳定隧道(本地设置) 3. 公网访问测试总结 前言 博客作为使…...

封装 Token
什么是token? 作为计算机术语,是“令牌”的意思 。 Token 是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需带上这个Token前来请…...
——点云添加均匀分布的随机噪声)
CloudCompare 二次开发(17)——点云添加均匀分布的随机噪声
目录 一、概述二、代码集成三、结果展示一、概述 不依赖任何第三方点云相关库,使用CloudCompare编程实现点云添加随机噪声。添加随机噪声的算法原理见:PCL 点云添加均匀分布的随机噪声。 二、代码集成 1、mainwindow.h文件public中添加: void doActionAddRandomNoise(); …...

研发必会-异步编程利器之CompletableFuture(含源码 中)
近期热推文章: 1、springBoot对接kafka,批量、并发、异步获取消息,并动态、批量插入库表; 2、SpringBoot用线程池ThreadPoolTaskExecutor异步处理百万级数据; 3、基于Redis的Geo实现附近商铺搜索(含源码) 4、基于Redis实现关注、取关、共同关注及消息推送(含源码) 5…...
上海亚商投顾:沪指高开高走 锂电等新能源赛道大反攻
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 沪指昨日高开后强势震荡,创业板指盘中一度翻绿,随后探底回升再度走高。碳酸锂期货合约…...
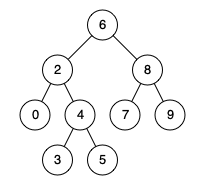
力扣第235题 二又搜索树的最近公共祖先 c++
题目 235. 二叉搜索树的最近公共祖先 中等 (简单) 相关标签 树 深度优先搜索 二叉搜索树 二叉树 给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。 百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q&…...

时代风口中的Web3.0基建平台,重新定义Web3.0!
近年来,Web3.0概念的广泛兴起,给加密行业带来了崭新的叙事方式,同时也为加密行业提供了更加具有想象力的应用场景与商业空间,并让越来越多的行业从业者们意识到只有更大众化的市场共性需求才能推动加密市场的持续繁荣。当前围绕这…...
角色为何在创业公司成为最稀缺的竞争力?)
产品工程师(Product Engineer)角色为何在创业公司成为最稀缺的竞争力?
在科技招聘市场,一位能力顶尖的工程师投递了上百份简历,却始终卡在“技术面试过关、产品讨论却露怯”的阶段。团队明明需要能快速交付价值的人,可最终录用的往往是那些“既懂代码又能自己做产品决策”的少数派。大多数候选人把精力全放在刷 L…...

解析日本工程塑料厂家代理新日铁住金产品的核心价值与
在众多日本工程塑料供应商中,新日铁住金凭借其在特种工程塑料领域的技术积累和稳定品质,成为众多制造企业的优选合作伙伴。对于寻求高性价比、稳定供应的塑胶制品厂、精密注塑厂及汽车零部件厂商而言,选择专业代理商是平衡品质与成本的关键。…...

Python OAuth终极指南:requests-oauthlib快速入门与实战
Python OAuth终极指南:requests-oauthlib快速入门与实战 【免费下载链接】requests-oauthlib OAuthlib support for Python-Requests! 项目地址: https://gitcode.com/gh_mirrors/re/requests-oauthlib 🔐 Python OAuth认证是现代Web开发中不可或…...
)
OpenISP 模块拆解 · 第7讲:去马赛克 (CFA)
OpenISP 模块拆解 第7讲:去马赛克 (CFA) 模块作用 CFA 插值也叫 demosaic,是把单通道 Bayer RAW 转成三通道 RGB 的关键模块。每个传感器像素只采集 R/G/B 之一,CFA 要为每个位置估计缺失的两个颜色通道。 openISP 实现 源码类名为 CFA(img,…...

BGA底部填充胶:嵌入式主控板可靠性设计与工艺全解析
1. 项目概述:为什么BGA底部填充胶是嵌入式主控板的“定海神针”?在嵌入式计算机主控板的设计与生产领域,尤其是那些采用高密度、细间距BGA(球栅阵列)封装芯片的板卡上,有一个工艺环节常常被新手工程师忽略&…...

智能手表核心升级:三星OLED与4nm处理器如何重塑用户体验
1. 项目概述:一次旗舰智能手表核心元件的深度迭代最近看到一条关于谷歌Pixel Watch 2的消息,核心信息点很明确:屏幕将由三星供应OLED面板,同时处理器将升级到4纳米制程。这看起来只是两个硬件参数的简单罗列,但对于我们…...

别再死记硬背了!用NestJS + TypeORM实战‘用户-标签’系统,搞懂OneToMany和ManyToOne
NestJS TypeORM实战:构建高可维护的用户标签系统 在开发内容管理平台时,用户与标签的关联关系是典型的多对一建模场景。本文将带你从零实现一个基于NestJS和TypeORM的生产级用户标签系统,重点解析OneToMany和ManyToOne在实际项目中的最佳实践…...
避坑指南:你的Harmony和Seurat SCTransform连用顺序对了吗?一个参数引发的聚类差异
Harmony与Seurat SCTransform联用避坑指南:参数细节如何影响聚类结果 在单细胞RNA测序数据分析中,数据预处理和批次校正对最终结果的可靠性至关重要。许多研究者已经熟悉了Seurat流程中的SCTransform标准化方法和Harmony批次校正工具的基本使用ÿ…...

CANN/asc-devkit核间同步API文档
CrossCoreWaitFlag(ISASI) 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https…...

嵌入式AI转型实战:从传统MCU开发到端侧智能部署
1. 项目概述:当嵌入式遇上AI,一场静默的变革最近和几个在芯片原厂、消费电子和工业控制领域干了十多年的老伙计聊天,话题总绕不开一个词:AI。不是那种高谈阔论的未来畅想,而是实实在在的焦虑和困惑。一个做电机驱动的兄…...