SELECT COUNT(*)会不会导致全表扫描引起慢查询
SELECT COUNT(*)会不会导致全表扫描引起慢查询呢?
SELECT COUNT(*) FROM SomeTable
网上有一种说法,针对无 where_clause 的 COUNT(*),MySQL 是有优化的,优化器会选择成本最小的辅助索引查询计数,其实反而性能最高,这种说法对不对呢
针对这个疑问,我首先去生产上找了一个千万级别的表使用 EXPLAIN 来查询了一下执行计划
EXPLAIN SELECT COUNT(*) FROM SomeTable
结果如下

图片
如图所示: 发现确实此条语句在此例中用到的并不是主键索引,而是辅助索引,实际上在此例中我试验了,不管是 COUNT(1),还是 COUNT(*),MySQL 都会用成本最小 的辅助索引查询方式来计数,也就是使用 COUNT(*) 由于 MySQL 的优化已经保证了它的查询性能是最好的!随带提一句,COUNT(*)是 SQL92 定义的标准统计行数的语法,并且效率高,所以请直接使用COUNT(*)查询表的行数!
所以这种说法确实是对的。但有个前提,在 MySQL 5.6 之后的版本中才有这种优化。
那么这个成本最小该怎么定义呢,有时候在 WHERE 中指定了多个条件,为啥最终 MySQL 执行的时候却选择了另一个索引,甚至不选索引?
本文将会给你答案,本文将会从以下两方面来分析
-
SQL 选用索引的执行成本如何计算
-
实例说明
SQL 选用索引的执行成本如何计算
就如前文所述,在有多个索引的情况下, 在查询数据前,MySQL 会选择成本最小原则来选择使用对应的索引,这里的成本主要包含两个方面。
-
IO 成本: 即从磁盘把数据加载到内存的成本,默认情况下,读取数据页的 IO 成本是 1,MySQL 是以页的形式读取数据的,即当用到某个数据时,并不会只读取这个数据,而会把这个数据相邻的数据也一起读到内存中,这就是有名的程序局部性原理,所以 MySQL 每次会读取一整页,一页的成本就是 1。所以 IO 的成本主要和页的大小有关
-
CPU 成本:将数据读入内存后,还要检测数据是否满足条件和排序等 CPU 操作的成本,显然它与行数有关,默认情况下,检测记录的成本是 0.2。
实例说明
为了根据以上两个成本来算出使用索引的最终成本,我们先准备一个表(以下操作基于 MySQL 5.7.18)
CREATE TABLE `person` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`score` int(11) NOT NULL,
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `name_score` (`name`(191),`score`),
KEY `create_time` (`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
这个表除了主键索引之外,还有另外两个索引, name_score 及 create_time。然后我们在此表中插入 10 w 行数据,只要写一个存储过程调用即可,如下:
CREATE PROCEDURE insert_person()
begin
declare c_id integer default 1;
while c_id<=100000 do
insert into person values(c_id, concat('name',c_id), c_id+100, date_sub(NOW(), interval c_id second));
set c_id=c_id+1;
end while;
end
插入之后我们现在使用 EXPLAIN 来计算下统计总行数到底使用的是哪个索引
EXPLAIN SELECT COUNT(*) FROM person

图片
从结果上看它选择了 create_time 辅助索引,显然 MySQL 认为使用此索引进行查询成本最小,这也是符合我们的预期,使用辅助索引来查询确实是性能最高的!
我们再来看以下 SQL 会使用哪个索引
SELECT * FROM person WHERE NAME >'name84059' AND create_time>'2020-05-23 14:39:18'

图片
用了全表扫描!理论上应该用 name_score 或者 create_time 索引才对,从 WHERE 的查询条件来看确实都能命中索引,那是否是使用 SELECT * 造成的回表代价太大所致呢,我们改成覆盖索引的形式试一下
SELECT create_time FROM person WHERE NAME >'name84059' AND create_time > '2020-05-23 14:39:18'
结果 MySQL 依然选择了全表扫描!这就比较有意思了,理论上采用了覆盖索引的方式进行查找性能肯定是比全表扫描更好的,为啥 MySQL 选择了全表扫描呢,既然它认为全表扫描比使用覆盖索引的形式性能更好,那我们分别用这两者执行来比较下查询时间吧
-- 全表扫描执行时间: 4.0 ms
SELECT create_time FROM person WHERE NAME >'name84059' AND create_time>'2020-05-23 14:39:18'
-- 使用覆盖索引执行时间: 2.0 ms
SELECT create_time FROM person force index(create_time) WHERE NAME >'name84059' AND create_time>'2020-05-23 14:39:18'
从实际执行的效果看使用覆盖索引查询比使用全表扫描执行的时间快了一倍!说明 MySQL 在查询前做的成本估算不准!我们先来看看 MySQL 做全表扫描的成本有多少。
前面我们说了成本主要 IO 成本和 CPU 成本有关,对于全表扫描来说也就是分别和聚簇索引占用的页面数和表中的记录数。执行以下命令
SHOW TABLE STATUS LIKE 'person'

图片
可以发现
-
行数是 100264,我们不是插入了 10 w 行的数据了吗,怎么算出的数据反而多了,其实这里的计算是估算 ,也有可能这里的行数统计出来比 10 w 少了,估算方式有兴趣大家去网上查找,这里不是本文重点,就不展开了。得知行数,那我们知道 CPU 成本是
100264 * 0.2 = 20052.8。 -
数据长度是 5783552,InnoDB 每个页面的大小是 16 KB,可以算出页面数量是 353。
也就是说全表扫描的成本是 20052.8 + 353 = 20406。
这个结果对不对呢,我们可以用一个工具验证一下。在 MySQL 5.6 及之后的版本中,我们可以用 optimizer trace 功能来查看优化器生成计划的整个过程 ,它列出了选择每个索引的执行计划成本以及最终的选择结果,我们可以依赖这些信息来进一步优化我们的 SQL。
optimizer_trace 功能使用如下
SET optimizer_trace="enabled=on";
SELECT create_time FROM person WHERE NAME >'name84059' AND create_time > '2020-05-23 14:39:18';
SELECT * FROM information_schema.OPTIMIZER_TRACE;
SET optimizer_trace="enabled=off";
执行之后我们主要观察使用 name_score,create_time 索引及全表扫描的成本。
先来看下使用 name_score 索引执行的的预估执行成本:
{
"index": "name_score",
"ranges": [
"name84059 <= name"
],
"index_dives_for_eq_ranges": true,
"rows": 25372,
"cost": 30447
}
可以看到执行成本为 30447,高于我们之前算出来的全表扫描成本:20406。所以没选择此索引执行
注意:这里的 30447 是查询二级索引的 IO 成本和 CPU 成本之和,再加上回表查询聚簇索引的 IO 成本和 CPU 成本之和。
再来看下使用 create_time 索引执行的的预估执行成本:
{
"index": "create_time",
"ranges": [
"0x5ec8c516 < create_time"
],
"index_dives_for_eq_ranges": true,
"rows": 50132,
"cost": 60159,
"cause": "cost"
}
可以看到成本是 60159,远大于全表扫描成本 20406,自然也没选择此索引。
再来看计算出的全表扫描成本:
{
"considered_execution_plans": [
{
"plan_prefix": [
],
"table": "`person`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 100264,
"access_type": "scan",
"resulting_rows": 100264,
"cost": 20406,
"chosen": true
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 100264,
"cost_for_plan": 20406,
"chosen": true
}
]
}注意看 cost:20406,与我们之前算出来的完全一样!这个值在以上三者算出的执行成本中最小,所以最终 MySQL 选择了用全表扫描的方式来执行此 SQL。
实际上 optimizer trace 详细列出了覆盖索引,回表的成本统计情况,有兴趣的可以去研究一下。
相关文章:
SELECT COUNT(*)会不会导致全表扫描引起慢查询
SELECT COUNT(*)会不会导致全表扫描引起慢查询呢? SELECT COUNT(*) FROM SomeTable 网上有一种说法,针对无 where_clause 的 COUNT(*),MySQL 是有优化的,优化器会选择成本最小的辅助索引查询计数,其实反而性能最高&…...

英国物联网初创公司【FourJaw】完成180万英镑融资
来源:猛兽财经 作者:猛兽财经 猛兽财经获悉,总部位于英国谢菲尔德的物联网初创公司【FourJaw】今日宣布已完成180万英镑融资。 本轮融资完成后,FourJaw的总融资金额已达400万英镑,本轮融资的投资机构包括:…...

许战海战略文库|无增长则衰亡:中小型制造企业增长困境
竞争环境不是匀速变化,而是加速变化。企业的衰退与进化、兴衰更迭在不断发生,这成为一种不可避免的现实。事实上,在产业链竞争中增长困境不分企业大小,而是一种普遍存在的问题,许多收入在1亿至10亿美元间的制造企业也同…...

广州华锐互动:候车室智能数字孪生系统实现交通信息可视化
随着科技的不断发展,数字化技术在各个领域得到了广泛的应用。智慧车站作为一种新型的交通服务模式,通过运用先进的数字化技术,为乘客提供了更加便捷、舒适的出行体验。 将智慧车站与数字孪生大屏结合,可以将实际现实世界的实体车站…...
智慧工地:助力数字建造、智慧建造、安全建造、绿色建造
智慧工地管理系统融合计算机技术、物联网、视频处理、大数据、云计算等,为工程项目管理提供先进的技术手段,构建施工现场智能监控系统,有效弥补传统监理中的缺陷,对人、机、料、法、环境的管理由原来的被动监督变成全方位的主动管…...
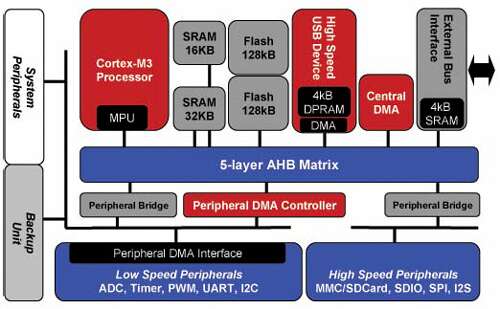
增强基于Cortex-M3的MCU以处理480 Mbps高速USB
通用串行总线(USB)完全取代了PC上的UART,PS2和IEEE-1284并行接口,现在已在嵌入式开发应用程序中得到广泛认可。嵌入式开发系统使用的大多数I / O设备(键盘,扫描仪,鼠标)都是基于USB的…...
山海鲸汽车需求调研系统:智慧决策的关键一步
随着社会的发展和科技的进步,汽车行业也迎来了新的挑战和机遇。如何更好地满足用户需求、提高产品竞争力成为了汽车制造商们关注的焦点。在这个背景下,山海鲸汽车需求调研互动系统应运而生,为汽车行业赋予了智慧决策的力量。 智慧决策的核心&…...

视频缩放的概念整理-步长数组
最近在读ffmpeg的代码时候,这个接口不是很能看懂int sws_scale(struct SwsContext *c, const uint8_t *const srcSlice[], const int srcStride[], int srcSliceY, int srcSliceH, uint8_t *const dst[], const int dstStride[]); 多方请教后,记录结果如…...
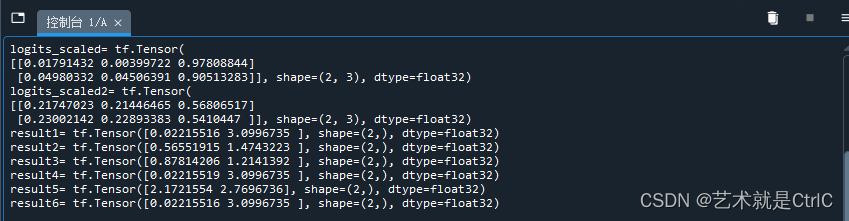
TensorFlow入门(二十一、softmax算法与损失函数)
在实际使用softmax计算loss时,有一些关键地方与具体用法需要注意: 交叉熵是十分常用的,且在TensorFlow中被封装成了多个版本。多版本中,有的公式里直接带了交叉熵,有的需要自己单独手写公式求出。如果区分不清楚,在构建模型时,一旦出现问题将很难分析是模型的问题还是交叉熵的使…...

UDP通信:快速入门
UDP协议通信模型演示 UDP API DatagramPacket:数据包对象(韭菜盘子) public DatagramPacket(byte[] buf, int length, InetAddress address, int port)创建发送端数据包对象 buf:要发送的内容,字节数组 length&…...

修炼k8s+flink+hdfs+dlink(四:k8s(一)概念)
一:概念 1. 概述 1.1 kubernetes对象. k8s对象包含俩个嵌套对象字段。 spec(规约):期望状态 status(状态):当前状态 当创建对象的时候,会按照spec的状态进行创建,如果…...

redis与 缓存击穿、缓存穿透、缓存雪崩
什么是缓存击穿、缓存穿透、缓存雪崩 缓存击穿、缓存穿透和缓存雪崩是与缓存相关的三种常见问题,它们可以在高并发的应用中导致性能问题。以下是它们的解释: 缓存击穿(Cache Miss) 缓存击穿指的是在高并发情况下,有大…...

印度网络安全:威胁与应对
随着今年过半,我们需要评估并了解不断崛起的网络威胁复杂性,这些威胁正在改变我们的数字景观。 从破坏性的网络钓鱼攻击到利用人工智能的威胁,印度的网络犯罪正在升级。然而,在高调的数据泄露事件风暴中,我们看到了政…...

AR动态贴纸SDK,让创作更加生动有趣
在当今的社交媒体时代,视频已经成为了人们表达自我、分享生活的重要方式。然而,如何让你的视频在众多的信息中脱颖而出,吸引更多的关注和点赞呢?答案可能就在你的手中——美摄AR动态贴纸SDK。 美摄AR动态贴纸SDK是一款专为视频编辑…...

MySQL常用命令01
今天开始,每天总结一点MySQL相关的命令,方便大家后期熟悉。 1.命令行登录数据库 mysql -H IP地址 -P 端口号 -u 用户名 -p 密码 数据库名称 -h 主机IP地址 登录本机 localhost或127.0.0.1 -P 数据库端口号 Mysql默认是3306 -u 用户名 -p 密码 …...

Java synchronized 关键字
synchronized 是什么? synchronized 是 Java 中的一个关键字,翻译成中文就是 同步 的意思,主要解决的是多个线程之间访问资源的同步性,可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。 如何使用 synchronized?…...

滑动窗口算法(C语言描述)
第一种类型:不固定长窗口 问题1:*** C代码1: #include<stdio.h> #include<string.h> #define N 5int min_len(int len1,int len2) {return (len1 < len2 ? len1:len2); }int main() {int target 0;int num[N];scanf("…...

【已修复】vcruntime140.dll有什么用,vcruntime140.dll缺失如何修复
我是网友,今天非常荣幸能够在这里和大家分享关于电脑找不到vcruntime140.dll无法继续执行代码的解决方法。我相信,在座的许多朋友都曾遇到过这个问题,而今天我将为大家介绍五种有效的解决方法。 首先,让我们来了解一下vcruntime1…...

10月12日,每日信息差
今天是2023年10月12日,以下是为您准备的13条信息差 第一、欧盟投资4.5亿欧元在法国建设电池超级工厂。欧洲投资银行是欧盟的贷款机构,也是世界上最大的跨国银行之一 第二、北京银行推出数字人民币智能合约平台 数字人民币预付资金管理产品在商超场景首…...

网络安全技术(黑客学习)——自学方法
如果你想自学网络安全,首先你必须了解什么是网络安全!,什么是黑客!! 1.无论网络、Web、移动、桌面、云等哪个领域,都有攻与防两面性,例如 Web 安全技术,既有 Web 渗透2.也有 Web 防…...

Zynq-7000 Linux系统构建全流程:从Vivado硬件配置到内核启动调试
1. 项目概述:为什么要在Zynq上折腾Linux?如果你手头有一块Xilinx Zynq-7000系列(比如我用的黑金Zynq7020)开发板,并且想把它从一个单纯的FPGA逻辑验证平台,变成一个能跑完整操作系统、可以灵活编程、还能用…...
)
EEGLab新手避坑:手把手教你搞定EEG数据的Marker、分段与Epoch提取(附完整代码)
EEGLab新手避坑指南:Marker设置、数据分段与Epoch提取全流程解析 在脑电信号处理领域,EEGLab作为MATLAB环境下最常用的开源工具包,其强大的功能和灵活的扩展性深受研究者青睐。但对于刚接触EEGLab的研究生和初级用户来说,从原始EE…...

YOLOv5-6.1单通道图像训练实战:从代码修改到ONNX模型转换全解析
1. 为什么需要单通道图像训练? 在工业视觉和医学影像领域,我们经常会遇到单通道图像数据。比如X光片、红外热成像图、工业CT扫描结果等,这些图像通常都是灰度图,只包含亮度信息而没有颜色信息。传统的YOLOv5默认处理的是三通道RGB…...

华硕笔记本性能优化神器:3步掌握G-Helper轻量级控制中心
华硕笔记本性能优化神器:3步掌握G-Helper轻量级控制中心 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, …...
大模型面试100问:从Transformer到RAG,互联网大厂AI岗位必备!
本文主要针对想要或者正在从事大语言模型、知识库、搜索增强生成(RAG)的研发、产品和测试同学,在面试中会遇到什么样的问题? 以下主要来自于各位从事大模型研发、产品和测试的伙伴、朋友在面试互联网大厂、AI科技公司的相关AI岗位…...
)
保姆级教程:用PHPStudy+Nginx一键部署新麦同城V3开源版(附数据库配置避坑点)
零基础30分钟部署新麦同城V3:PHPStudyNginx全流程避坑指南 第一次接触本地部署开源系统时,最怕的不是代码复杂,而是明明按教程操作却卡在某个配置环节。本文将以真实踩坑记录为核心,手把手带你在Windows环境下用PHPStudy快速搭建…...

Cursor Pro免费激活终极指南:简单快速解锁AI编程高级功能
Cursor Pro免费激活终极指南:简单快速解锁AI编程高级功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your …...

3行代码实现语音检索:用FunASR从10万段音频中精准定位关键信息
3行代码实现语音检索:用FunASR从10万段音频中精准定位关键信息 【免费下载链接】FunASR A Fundamental End-to-End Speech Recognition Toolkit and Open Source SOTA Pretrained Models, Supporting Speech Recognition, Voice Activity Detection, Text Post-proc…...

Avidemux:开源视频剪辑神器,5分钟学会专业级视频处理
Avidemux:开源视频剪辑神器,5分钟学会专业级视频处理 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 你知道吗?在开源视频编辑领域,有一款轻量级但功…...
XUnity Auto Translator:Unity游戏玩家的终极翻译解决方案
XUnity Auto Translator:Unity游戏玩家的终极翻译解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为外语游戏中的生涩文本而烦恼吗?XUnity Auto Translator为你提供了…...