PyTorch 入门
一、说明
深度学习是机器学习的一个分支,其中编写的算法模仿人脑的功能。深度学习中最常用的库是 Tensorflow 和 PyTorch。由于有各种可用的深度学习框架,人们可能想知道何时使用 PyTorch。以下是人们更喜欢使用 Pytorch 来完成特定任务的原因。
Pytorch 是一个开源深度学习框架,提供 Python 和 C++ 接口。Pytorch 驻留在 torch 模块内。在 PyTorch 中,需要处理的数据以张量的形式输入。
二、安装 PyTorch
如果您的系统中安装了 Anaconda Python 包管理器,则在终端中运行以下命令将安装 PyTorch:
conda install pytorch torchvision cpuonly -c pytorch
此命令将安装最新的稳定版本的 PyTorch。Stable 代表当前经过最多测试和支持的 PyTorch 版本。Pytorch 的最新稳定版本是 1.12.1。如果您想使用 PyTorch 而不将其显式安装到本地计算机中,则可以使用 Google Colab。
三、PyTorch 张量
Pytorch 用于处理张量。张量是多维数组,如 n 维 NumPy 数组。然而,张量也可以在 GPU 中使用,而 NumPy 数组则不然。PyTorch 具有各种内置函数,因此可以加速张量的科学计算。
向量是一维张量,矩阵是二维张量。C、C++ 和 Java 中使用的张量和多维数组之间的一个显着区别是张量在所有维度上应具有相同的列大小。此外,张量只能包含数字数据类型。
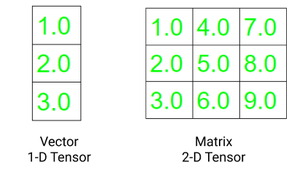
张量的两个基本属性是:
- 形状:指数组或矩阵的维数
- Rank:指张量中存在的维数
代码:
- Python3
# importing torch import torch # creating a tensors t1=torch.tensor([1, 2, 3, 4]) t2=torch.tensor([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]) # printing the tensors: print("Tensor t1: \n", t1) print("\nTensor t2: \n", t2) # rank of tensors print("\nRank of t1: ", len(t1.shape)) print("Rank of t2: ", len(t2.shape)) # shape of tensors print("\nRank of t1: ", t1.shape) print("Rank of t2: ", t2.shape) |
输出:

四、在 PyTorch 中创建张量
在 PyTorch 中创建张量有多种方法。张量可以包含单一数据类型的元素。我们可以使用 python 列表或 NumPy 数组创建张量。Torch 有 10 种适用于 GPU 和 CPU 的张量变体。以下是定义张量的不同方法。
torch.Tensor() :它复制数据并创建其张量。它是 torch.FloatTensor 的别名。
torch.tensor() :它还会复制数据以创建张量;但是,它会自动推断数据类型。
torch.as_tensor() :在这种情况下,在创建数据时共享数据而不是复制数据,并接受任何类型的数组来创建张量。
torch.from_numpy() :它类似于tensor.as_tensor(),但它只接受numpy数组。
代码:
- Python3
# importing torch module
import torch import numpy as np # list of values to be stored as tensor data1 = [1, 2, 3, 4, 5, 6] data2 = np.array([1.5, 3.4, 6.8, 9.3, 7.0, 2.8]) # creating tensors and printing t1 = torch.tensor(data1) t2 = torch.Tensor(data1) t3 = torch.as_tensor(data2) t4 = torch.from_numpy(data2) print("Tensor: ",t1, "Data type: ", t1.dtype,"\n") print("Tensor: ",t2, "Data type: ", t2.dtype,"\n") print("Tensor: ",t3, "Data type: ", t3.dtype,"\n") print("Tensor: ",t4, "Data type: ", t4.dtype,"\n") |
输出:

五、在 Pytorch 中重构张量
我们可以在 PyTorch 中根据需要修改张量的形状和大小。我们还可以创建 and 张量的转置。以下是根据需要更改张量结构的三种常见方法:
.reshape(a, b) :返回大小为 a,b 的新张量
.resize(a, b) :返回大小与 a,b 相同的张量
.transpose(a, b) :返回a和b维度转置的张量
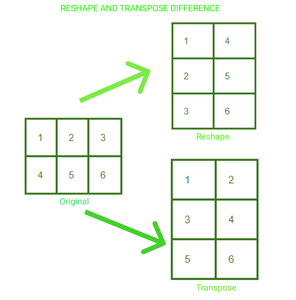
2*3 矩阵已被重新整形并转置为 3*2。我们可以可视化这两种情况下张量中元素排列的变化。
代码:
- Python3
# import torch module import torch # defining tensor t = torch.tensor([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]) # reshaping the tensor print("Reshaping") print(t.reshape(6, 2)) # resizing the tensor print("\nResizing") print(t.resize(2, 6)) # transposing the tensor print("\nTransposing") print(t.transpose(1, 0)) |

六、PyTorch 中张量的数学运算
我们可以使用 Pytorch 对张量执行各种数学运算。执行数学运算的代码与 NumPy 数组的情况相同。下面是在张量中执行四种基本运算的代码。
- Python3
# import torch module import torch # defining two tensors t1 = torch.tensor([1, 2, 3, 4]) t2 = torch.tensor([5, 6, 7, 8]) # adding two tensors print("tensor2 + tensor1") print(torch.add(t2, t1)) # subtracting two tensor print("\ntensor2 - tensor1") print(torch.sub(t2, t1)) # multiplying two tensors print("\ntensor2 * tensor1") print(torch.mul(t2, t1)) # diving two tensors print("\ntensor2 / tensor1") print(torch.div(t2, t1)) |
输出:

要进一步深入了解使用 Pytorch 进行矩阵乘法,请参阅本文。
六、Pytorch 模块
PyTorch 库模块对于创建和训练神经网络至关重要。三个主要的库模块是 Autograd、Optim 和 nn。
# 1. Autograd 模块: autograd 提供了轻松计算梯度的功能,无需明确手动实现所有层的前向和后向传递。
为了训练任何神经网络,我们执行反向传播来计算梯度。通过调用 .backward() 函数,我们可以计算从根到叶子的每个梯度。
代码:
- Python3
# importing torch import torch # creating a tensor t1=torch.tensor(1.0, requires_grad = True) t2=torch.tensor(2.0, requires_grad = True) # creating a variable and gradient z=100 * t1 * t2 z.backward() # printing gradient print("dz/dt1 : ", t1.grad.data) print("dz/dt2 : ", t2.grad.data) |
输出:
![]()
# 2. Optim 模块: PyTorch Optium 模块有助于实现各种优化算法。该软件包包含最常用的算法,例如 Adam、SGD 和 RMS-Prop。要使用 torch.optim,我们首先需要构造一个 Optimizer 对象,它将保留参数并相应地更新它。首先,我们通过提供我们想要使用的优化器算法来定义优化器。我们在反向传播之前将梯度设置为零。然后为了更新参数,调用optimizer.step()。
Optimizer = torch.optim.Adam(model.parameters(), lr=0.01) #定义优化器
Optimizer.zero_grad() #将梯度设置为零
optimizer.step() #参数更新
# 3. nn 模块:这个包有助于构建神经网络。它用于构建层。
为了创建单层模型,我们可以使用 nn.Sequential() 简单地定义它。
模型 = nn.Sequential( nn.Linear(in, out), nn.Sigmoid(), nn.Linear(_in, _out), nn.Sigmoid() )
对于不在单个序列中的模型的实现,我们通过子类化 nn.Module 类来定义模型。
- Python3
class Model (nn.Module) : def __init__(self): super(Model, self).__init__() self.linear = torch.nn.Linear(1, 1) def forward(self, x): y_pred = self.linear(x) return y_pred |
七、PyTorch 数据集和数据加载器
torch.utils.data.Dataset 类包含所有自定义数据集。我们需要实现两个方法,__len__() 和 __get_item__(),来创建我们自己的数据集类。
PyTorch Dataloader 具有一个惊人的功能,可以与自动批处理并行加载数据集。因此,它减少了顺序加载数据集的时间,从而提高了速度。
语法: DataLoader(数据集,shuffle=True,sampler=None,batch_sampler=None,batch_size=32)
PyTorch DataLoader 支持两种类型的数据集:
- 映射式数据集:数据项映射到索引。在这些数据集中, __get_item__() 方法用于检索每个项目的索引。
- 可迭代式数据集:在这些数据集中实现了 __iter__() 协议。数据样本按顺序检索。
请参阅《在 PyTorch 中使用 DataLoader》一文了解更多信息。
八、使用 PyTorch 构建神经网络
我们将在逐步实施中看到这一点:
- 数据集准备:由于PyTorch中的所有内容都以张量的形式表示,因此我们应该首先以张量表示。
- 构建模型:为了构建神经网络,我们首先定义输入层、隐藏层和输出层的数量。我们还需要定义初始权重。权重矩阵的值是使用torch.randn()随机选择的。Torch.randn() 返回一个由标准正态分布的随机数组成的张量。
- 前向传播:将数据输入神经网络,并在权重和输入之间执行矩阵乘法。这可以使用手电筒轻松完成。
- 损失计算: PyTorch.nn 函数有多个损失函数。损失函数用于衡量预测值与目标值之间的误差。
- 反向传播:用于优化权重。改变权重以使损失最小化。
现在让我们从头开始构建一个神经网络:
- Python3
# importing torch import torch # training input(X) and output(y) X = torch.Tensor([[1], [2], [3], [4], [5], [6]]) y = torch.Tensor([[5], [10], [15], [20], [25], [30]]) class Model(torch.nn.Module): # defining layer def __init__(self): super(Model, self).__init__() self.linear = torch.nn.Linear(1, 1) # implementing forward pass def forward(self, x): y_pred = self.linear(x) return y_pred model = torch.nn.Linear(1 , 1) # defining loss function and optimizer loss_fn = torch.nn.L1Loss() optimizer = torch.optim.Adam(model.parameters(), lr = 0.01 ) for epoch in range(1000): # predicting y using initial weights y_pred = model(X.requires_grad_()) # loss calculation loss = loss_fn(y_pred, y) # calculating gradients loss.backward() # updating weights optimizer.step() optimizer.zero_grad() # testing on new data X = torch.Tensor([[7], [8]]) predicted = model(X) print(predicted) |
输出:
![]()
相关文章:
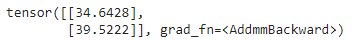
PyTorch 入门
一、说明 深度学习是机器学习的一个分支,其中编写的算法模仿人脑的功能。深度学习中最常用的库是 Tensorflow 和 PyTorch。由于有各种可用的深度学习框架,人们可能想知道何时使用 PyTorch。以下是人们更喜欢使用 Pytorch 来完成特定任务的原因。 Pytorch…...
微信自动批量添加好友的方法
在现在的营销中微信已成为一种重要的沟通方式。微信目前是没有自动批量添加好友的功能,需要运营者一个一个手动去添加,这样太过于浪费时间,并且加频繁了还容易被封号,今天给大家介绍几种手动批量加好友的方式以及怎么借助第三方软…...

[网鼎杯 2018]Comment git泄露 / 恢复 二次注入 .DS_Store bash_history文件查看
首先我们看到账号密码有提示了 我们bp爆破一下 我首先对数字爆破 因为全字符的话太多了 爆出来了哦 所以账号密码也出来了 zhangwei zhangwei666 没有什么用啊 扫一下吧 有git git泄露 那泄露看看 真有 <?php include "mysql.php"; session_start(); if(…...

生态兼容性进一步提升!白鲸开源 WhaleStudio 与火山引擎ByteHouse完成产品互认
数据作为新型生产要素,已快速融入生产、分配、流通、消费和社会服务管理等各环节,深刻改变着生产方式、生活方式和治理方式。越来越多企业也在尝试充分利用数据要素,开辟全新发展路径,进一步实现业务价值提升。 在数字化转型的大…...

iOS 内存管理和优化
对内存管理和拓展有独特的描述 iOS学习-内存管理 比较详细说明内存的关系 iOS 内存管理机制与原理 iOS 内存泄漏排查方法及原因分析 对weak的实现原理描写详细 【iOS】—— weak的基本原理 iOS copy & mutableCopy iOS 深拷贝与浅拷贝 对iOS的浅复制和深复制的深入解释…...

常见工具指令【Vim | GIT | ZIP | UNZIP | IDEA】
VIM 快捷键说明Ctrl U (up)向上翻动半页Ctrl B (back)向上翻动一页Ctrl D (down)向下翻页半页Ctrl F (forward)向下翻动一页 GIT 指令解释git init 使用指定目录作为Git仓库git add filename向资源库添加文件filenamegit rm file从资源库中删除文件git branch 分支名称创…...

中国人民大学与加拿大女王大学金融硕士——顺势而为,掌握人生的方向盘
在这个快速发展的时代,每个人在不断面临全新挑战的同时, 也在时刻接收着各种机会。有人抓住时代红利,实现更新迭代;有人却只能作为旁观者,眼看时代发展,而自己被逐渐淘汰。时代从不会抛下任何一个人&#x…...
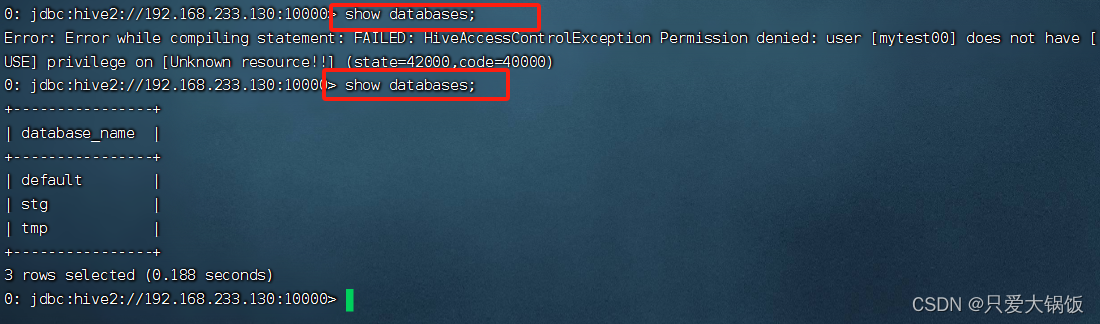
Apache Ranger:(二)对Hive集成简单使用
1.Ranger Hive-plugin安装 进入 Ranger 编译生成的目录下 找到 ranger-2.0.0-hive-plugin.tar.gz 进行解压 tar -zxvf ranger-2.0.0-hive-plugin.tar.gz -C /opt/module/ 2.修改配置文件 vim install.properties #策略管理器的url地址 POLICY_MGR_URLhttp://[ip]:6080#组件…...
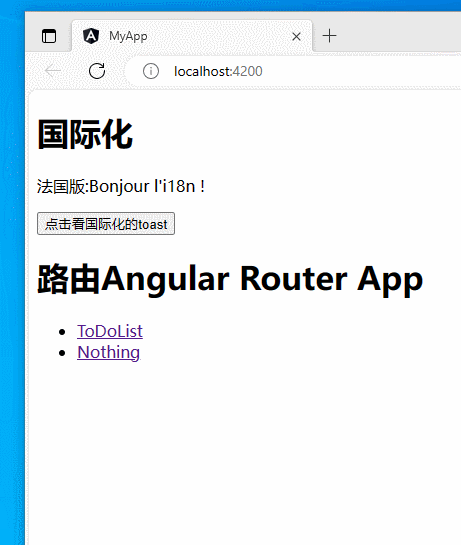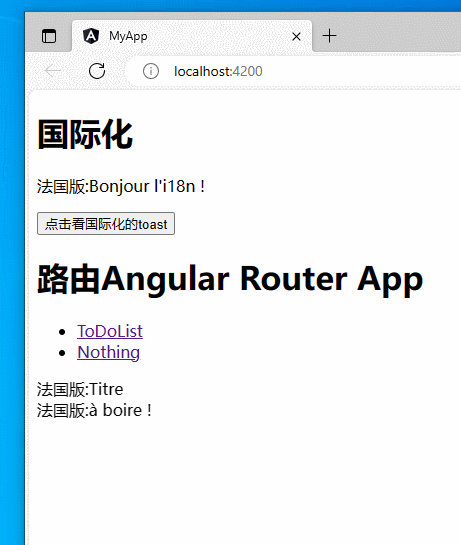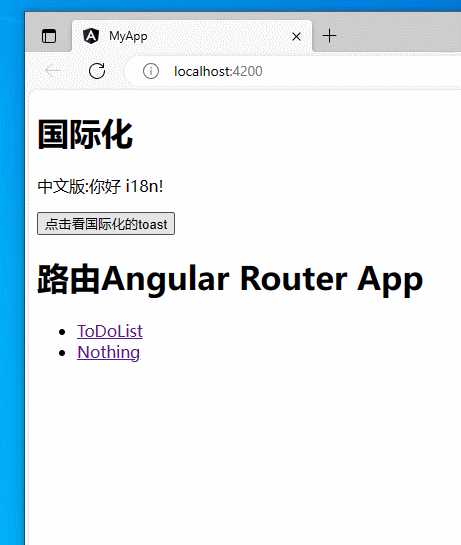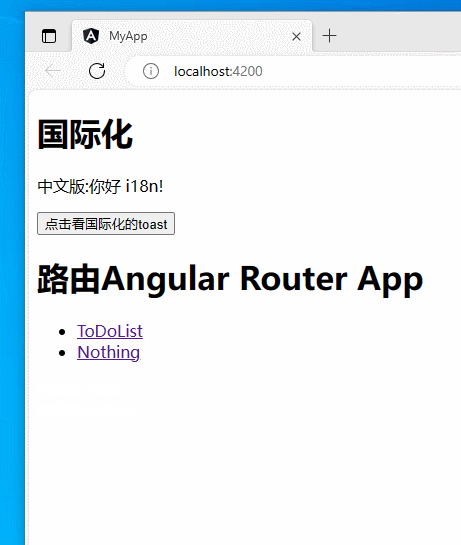
【angular】实现简单的angular国际化(i18n)
文章目录 目标过程运行在TS中国际化参考 目标 实现简单的angular国际化。本博客实现中文版和法语版。 将Hello i18n!变为中文版:你好 i18n!或法语版:Bonjour l’i18n !。 过程 创建一个项目: ng new i18nDemo在集成终端中打开。 添加本地化包&#…...

Redis之主从复制,哨兵模式,集群
Redis之主从复制,哨兵模式,集群 1、主从复制1.1主从复制概述1.2Redis主从复制作用1.3Redis主从复制流程1.4部署Redis 主从复制 2、哨兵模式2.1哨兵模式原理2.2哨兵模式的作用2.3哨兵模式的结构2.4故障转移机制2.5搭建Redis 哨兵模式 3、Redis集群模式3.1…...

掌动智能浅析Web自动化测试的重要性
在现代Web开发中,确保Web应用程序的质量和稳定性至关重要。Web自动化测试工具成为了开发团队的关键资源,帮助他们自动化测试流程、减少手动劳动,提高测试覆盖率和效率。本文将介绍Web自动化测试的重要性是什么! Web自动化测试的重要性&#x…...

JTS: 12 Descriptions 图形覆盖
这里写目录标题 版本代码Intersection 交集Union 并集Difference 差集SymDifference 补集 版本 org.locationtech.jts:jts-core:1.19.0 链接: github 代码 /*** 图形覆盖操作* author LiHan* 2023年10月12日 19:34:09*/ public class GeometryDescriptions {private final Ge…...
业务安全五重价值:防攻击、保稳定、助增收、促合规、提升满意度
目录 防范各类威胁攻击 保障业务的连续性和稳定性 保障业务的合规性 提升企业营收和发展 提升企业满意度和品牌知名度 2023年暑假被“票贩子”和“黄牛”攻陷。他们利用各种手段抢先预约名额,然后加价出售给游客,导致了门票供不应求的局面ÿ…...
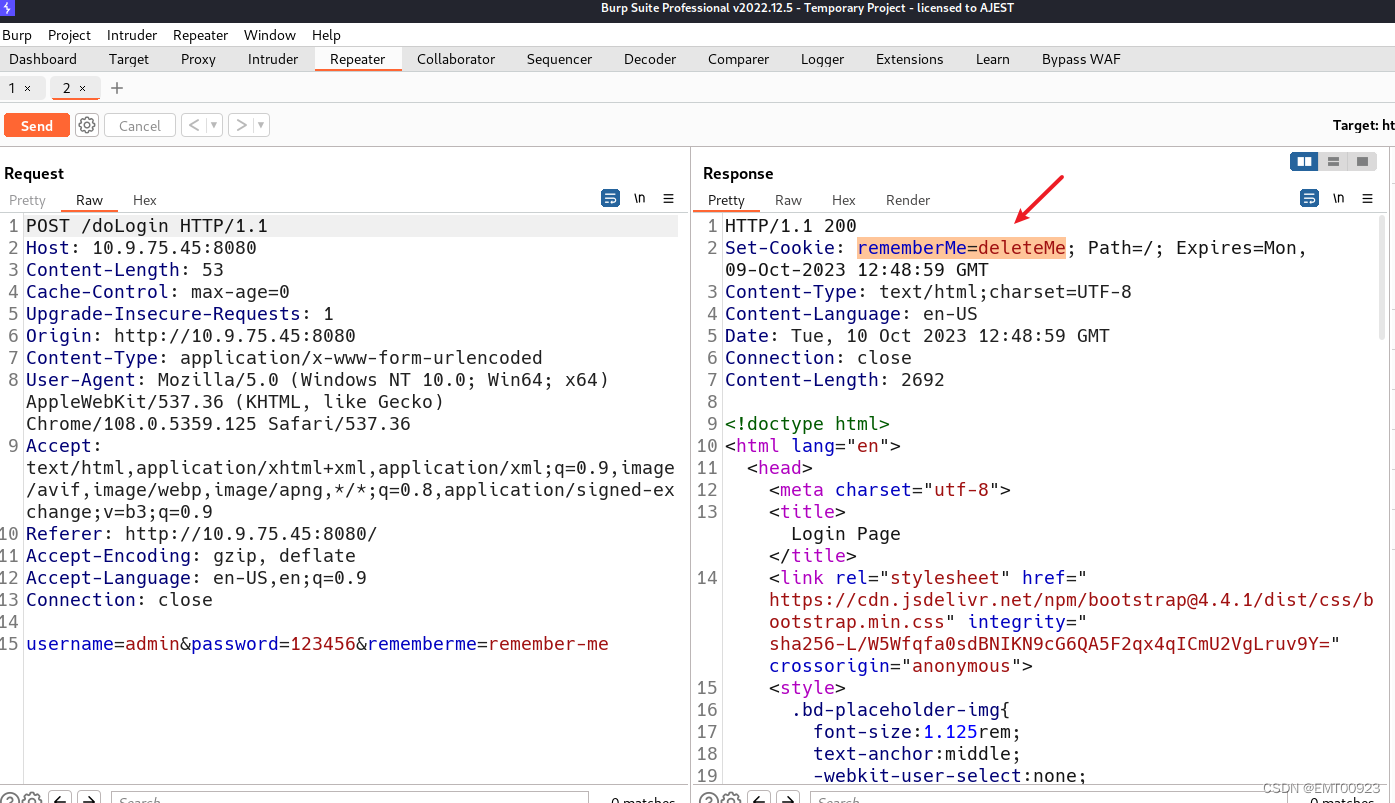
shiro反序列化和log4j
文章目录 安装环境shiro漏洞验证log4j 安装环境 进入vulhb目录下的weblogic,复现CVE-2018-2894漏洞: cd /vulhub/shiro/CVE-2010-3863查看docker-compose的配置文件: cat docker-compose.yml如图,里面有一个镜像文件的信息和服…...

『Linux项目自动化构建工具』make/Makefile
前言 如题可知,make/Makefile为在Linux下的项目自动化构建工具; 在上一篇文章『Linux - gcc / g』c程序翻译过程 中讲解了C/C程序的翻译过程; 而make/Makefile即可以看成,是Makefile在使用gcc/g使在Linux环境下能够更好的高效率的进行项目构建; 在此之前首先要对make/Makefile…...
,如何才能解决)
github提示Permission denied (publickey),如何才能解决
当GitHub提示“Permission denied (publickey)”错误,这通常意味着您的SSH密钥没有被正确地配置。以下是一些常见的解决步骤,帮助您诊断和解决该问题: 检查是否已设置SSH密钥: 运行以下命令检查是否存在SSH密钥: bash…...
金x软件有限公司安全测试岗位面试
目录 一、自我介绍 二、你是网络空间安全专业的,那你介绍下网络空间安全这块主要学习的东西? 三、本科专业是网络工程,在嘉兴海视嘉安智城科技有限公司实习过,你能说下干的工作吗?(没想到问的是本科实习…...

c语言之strlen函数使用和实现
文章目录 前言一、strlen函数使用二、实现方法 前言 c语言之strlen函数使用和实现 一、strlen函数使用 strlen函数返回的是在字符串中的个数,但不包含字符串结束符’\0’ #include<stdio.h> #include<string.h> int main() {char str1[] "abcd…...
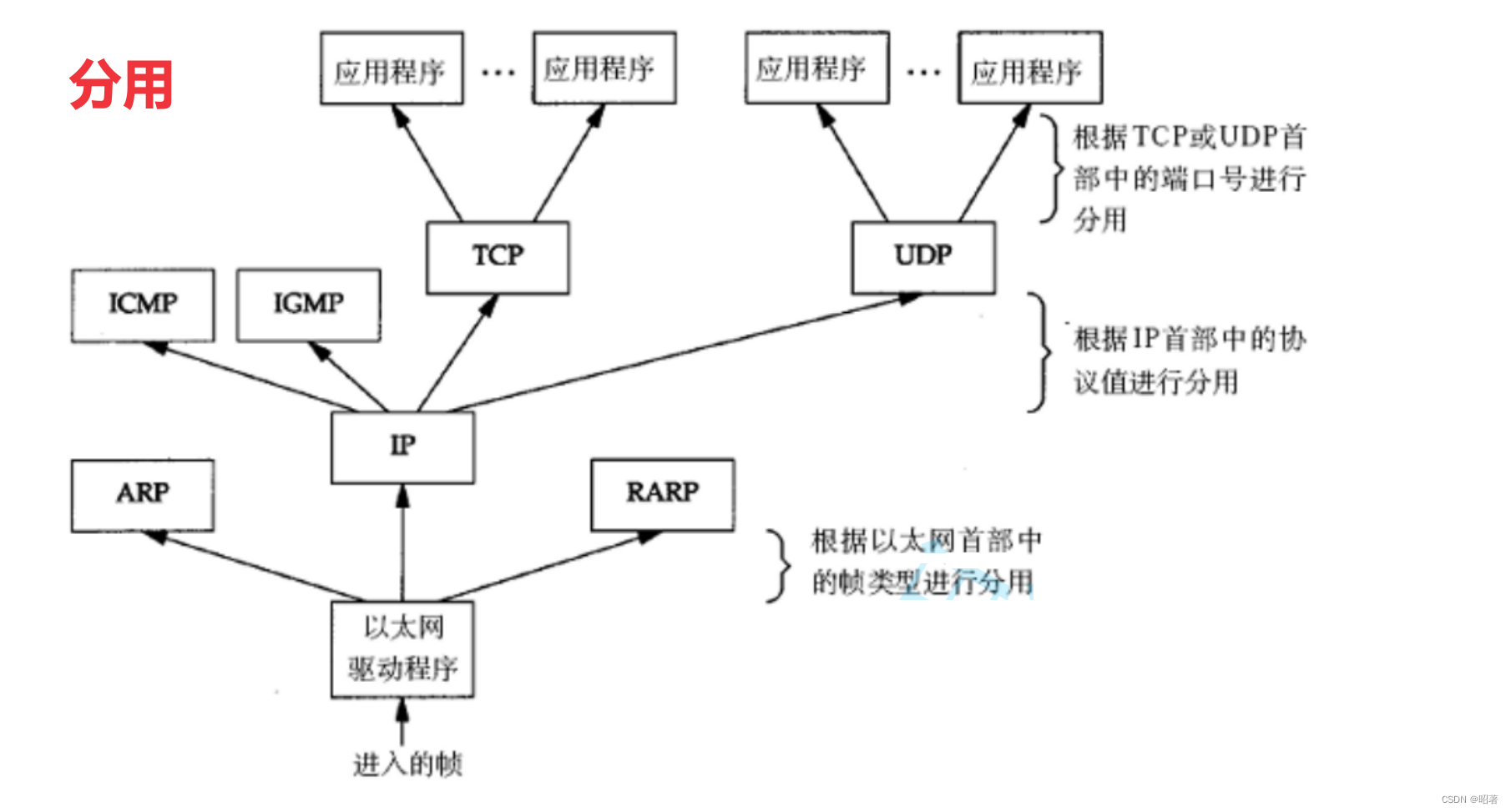
网络初识(JAVA EE)
文章目录 一、网络发展史二、网络通信基础三、协议分层四、封装和分用 一、网络发展史 独立模式:计算机之间相互独立,每个终端都各自持有客户数据,且当处理一个业务时,按照业务流程进行 网络互连:将多台计算机连接在一…...

kantts docker化
kan-tts docker本地化 环境安装 下载docker镜像(python3.8的) registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.8.0-py38-torch2.0.1-tf2.13.0-1.9.2 安装基础模型 pip install modelscope 安装语音模型 pip install "modelscope…...

从零到一:vue-print-nb插件在Vue项目中的实战打印方案
1. 为什么选择vue-print-nb插件 在Vue项目中实现打印功能,开发者通常会面临多种选择。传统的window.print()方法虽然简单,但存在明显的局限性:无法精确控制打印区域、难以自定义打印样式、对移动端支持不佳等。这时候,一个专门为V…...

Cat-Catch:浏览器资源嗅探的终极解决方案与实用指南
Cat-Catch:浏览器资源嗅探的终极解决方案与实用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在当今数字内容爆炸的时代…...

AArch64虚拟内存系统架构与地址转换详解
1. AArch64虚拟内存系统架构概述虚拟内存是现代计算机系统的核心机制,它通过地址转换技术将程序使用的虚拟地址(VA)映射到实际的物理地址(PA)。AArch64作为ARMv8-A和ARMv9-A架构的64位执行状态,其虚拟内存系统在设计上兼顾了灵活性和性能需求。在AArch64…...
C166架构_testclear_函数原理与应用解析
1. C166开发中的_testclear_函数使用解析在嵌入式C166架构开发过程中,开发人员经常会遇到一些编译器特有的内置函数(intrinsic functions)使用问题。其中_testclear_函数就是一个典型的例子,它用于原子性地测试并清除某个内存位置的值。最近我在调试一个…...

保姆级教程:解决PyTorchViz安装报错,手把手教你用AlexNet模型可视化
PyTorch模型可视化实战:从安装报错到AlexNet结构解析全指南 在深度学习模型开发过程中,可视化工具如同开发者的"第二双眼睛"。PyTorchViz作为PyTorch生态中轻量级但功能强大的可视化工具,能直观展示模型的计算图结构,帮…...

2026届必备的五大降AI率神器推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 人工智能技术不断深入发展着,学术领域对于原创性以及学术诚信的要求愈发严格起来…...

别再只用箱线图了!用R语言ggplot2绘制高颜值小提琴图,让你的SCI图表更专业
科研数据可视化进阶:用R语言打造专业级小提琴图 在生物医学领域的科研论文中,数据可视化是展示研究成果的关键环节。许多研究者习惯性地使用箱线图来呈现数据分布,却忽略了这种传统方法可能掩盖的重要信息细节。当面对复杂的数据分布模式时&…...

【每日一题】排序
📌 写在前面:排序是算法竞赛中最基础也最核心的技能之一。它不仅是快速查找、去重、贪心等算法的前置步骤,更是自定义比较策略、多关键字排序、排序后贪心等高级技巧的基石。本文基于蓝桥杯官方课程与真题,从基础排序到竞赛实战&a…...

对比直接购买与通过Taotoken聚合使用大模型API的体验差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接购买与通过Taotoken聚合使用大模型API的体验差异 在开发和集成大模型能力的过程中,开发者或团队通常面临两种主…...

2026年便利店成交金额究竟要达到多少,才能摆脱亏损困境?
在便利店行业竞争日益激烈的当下,众多便利店品牌都在为实现盈利而努力。美喜福作为便利店行业的一员,在这一背景下有着独特的发展路径和潜力。那么,2026年便利店成交金额究竟要达到多少才能摆脱亏损困境呢?让我们结合美喜福的实际…...