在 Elasticsearch 中实现自动完成功能 3:completion suggester
在这篇博文中,我们将讨论 complete suggester - 一种针对自动完成功能进行优化的 suggester,并且被认为比我们迄今为止讨论的方法更快。
Completion suggester 使用称为有限状态转换器的数据结构,该结构类似于 Trie 数据结构,并且针对更快的查找进行了优化。 这些数据结构存储在节点的内存中,以实现更快的搜索。 与 edge-n-gram 和 search_as_you_type 一样,这也通过使用我们提供的输入更新内存中的 FST 来完成索引时的大部分工作。
Elasticsearch 类型的一种特殊类型 —— complete,用于实现它:
PUT /movies
{"mappings": {"properties": {"title": {"type": "completion"}}}
}映射还支持完成字段的 analyzer、search analyzer、max_input_length 参数。 分析器值默认为 simple analyzer,它将输入小写并对任何非字母字符,例如数字、空格、连字符等进行分词。完成类型上的分析器的行为与其他文本字段上的分析器不同。 经过分析后,分词不能单独使用 - 它们根据输入文本中的顺序放在一起并插入到 FST 中。 此外,我们无法在此方法中使用 _analyze 端点来测试我们的映射。 如果我们尝试这样做,Elasticsearch 会抛出一个错误,指出 “Can't process field [title], Analysis requests are only supported on tokenized fields”。
在索引文档时,我们指定输入和可选的权重参数 -
POST /movies/_doc/1001
{"title": [{"input": "Harry Potter and the Goblet of Fire","weight": 5},{"input": "Goblet of Fire","weight": 10}]
}POST /movies/_doc/1002
{"title": {"input": ["Harry Potter and the Goblet of Fire","Goblet of Fire"],"weight": 2}
}我们可以使用 input 参数为单个文档指定多个匹配项。 weight 参数控制搜索结果中文档的排名。 它可以针对每个 input 进行指定,如上面的第一个文档(1001)中所示,或者可以对所有 input 保持相同,如第二个文档(1002)中所示。
使用 _search 端点的请求正文中的 suggest 子句查询建议字段。 在 ES 5.0 版本之前,有一个单独的端点 - _suggest 用于 suggester。 互联网上的许多示例都使用 _suggest。 从版本 5 开始,_search 端点本身也已更新以支持 suggester。
默认情况下,Elasticsearch 返回整个匹配文档。 如果我们只对建议文本感兴趣,我们可以使用 _source 选项并将其设置为“suggest”。 通过这种方式,我们可以最大限度地减少磁盘获取和传输开销:
GET /movies/_search?filter_path=**.harry_suggest
{"_source": "title.input","suggest": {"harry_suggest": {"prefix": "goblet of f","completion": {"field": "title"}}}
}上面命令返回的结果为:
{"suggest": {"harry_suggest": [{"text": "goblet of f","offset": 0,"length": 11,"options": [{"text": "Goblet of Fire","_index": "movies","_id": "1001","_score": 10,"_source": {"title": [{"input": "Harry Potter and the Goblet of Fire"},{"input": "Goblet of Fire"}]}},{"text": "Goblet of Fire","_index": "movies","_id": "1002","_score": 2,"_source": {"title": {"input": ["Harry Potter and the Goblet of Fire","Goblet of Fire"]}}}]}]}
}"Goblet of Fire" 在建议中返回了两次,因为我们已在两个文档中提供此文本作为输入。 这可以通过使用 skip_duplicates 选项来避免。
GET /movies/_search?filter_path=**.harry_suggest
{"_source": "title.input","suggest": {"harry_suggest": {"prefix": "goblet of f","completion": {"field": "title","skip_duplicates": true}}}
}{"suggest": {"harry_suggest": [{"text": "goblet of f","offset": 0,"length": 11,"options": [{"text": "Goblet of Fire","_index": "movies","_id": "1001","_score": 10,"_source": {"title": [{"input": "Harry Potter and the Goblet of Fire"},{"input": "Goblet of Fire"}]}}]}]}
}警告:当设置为 true 时,此选项会减慢搜索速度,因为需要访问更多建议才能找到前 N 个。
在 completion suggester 的情况下,Elasticsearch 从第一个字符开始一次匹配文档一个字符,在输入新字符时向前移动一个位置。如上所述,它保留 FST 中的输入顺序。 因此,它无法像基于 n-gram 的方法那样在输入中间进行匹配。 即,如果你有一部名为 “Harry Potter and the Goblet of Fire” 的电影,并且你输入 “goblet of fire”,它不会将文档作为匹配项返回。 但是,你可以使用输入选项来提供多个匹配项。 你可以手动对输入字符串进行分词,并将分词传递到输入选项中的 Elasticsearch,就像我们在上面的示例中通过提供 “Goblet of Fire” 作为附加输入所做的那样。
Completion suggester 支持 fuzzy queries,使我们能够在搜索文档时考虑拼写错误。 你还可以指定前缀文本作为正则表达式查询。 下面示例中的两个查询都返回 “Goblet of Fire” 作为建议 -
GET /movies/_search?filter_path=**.harry_suggest
{"_source": "title.input","suggest": {"harry_suggest": {"prefix": "gobet of f","completion": {"field": "title","fuzzy": {"fuzziness": 2}}}}
}GET /movies/_search?filter_path=**.harry_suggest
{"_source": "title.input","suggest": {"harry_suggest": {"regex": "g[aieou]b","completion": {"field": "title"}}}
}添加上下文到搜索
与其他查询不同,completion suggesters 不支持在查询中添加过滤器。 即,你无法根据文档中其他字段的值过滤掉建议。 假设我们有一个存储电影的索引,并且我们正在开发基于标题字段的自动完成功能。 假设我们已将 title 映射为完成类型,还有其他字段,如 genres、ratings、production companies 等。有一个 title 为 “Goblet of Fire” 的文档,其 genre 为 “action”。 现在,如果我们尝试根据 genre = "romance" 过滤掉自动完成建议,我们预计它不应该返回 “Goblet of Fire”:
POST /movies/_doc/1001
{"genre": "action","title": [{"input": "Harry Potter and the Goblet of Fire","weight": 5},{"input": "Goblet of Fire","weight": 10}]
}POST /movies/_doc/1002
{"genre": "fiction","title": {"input": ["Harry Potter and the Goblet of Fire","Goblet of Fire"],"weight": 2}
}GET /movies/_search
{"query": {"bool": {"filter": [{"term": {"genre": "romance"}}]}},"suggest": {"harry_suggest": {"prefix": "goblet","completion": {"field": "title"}}}
}上述搜索将返回和之前一样的结果。仿佛那个过滤器根本就不存在。这并不像我们预期的那样工作 - 它返回 “Goblet of Fire” 作为建议,即使它属于 “action” 类型。 这种限制背后的主要原因是它的设计。 正如已经讨论过的,建议存储在单独的数据结构中 - 内存中 FST,而其他字段存储在磁盘上。 这种设计有助于通过内存中 FST 进行更快的搜索。 像上面这样的查询违背了这种设计。
然而,Elasticsearch 确实提供了上下文建议在一定程度上规避了这个问题。 要使用上下文建议器,我们必须在为索引创建映射时提供上下文:
DELETE moviesPUT /movies
{"mappings": {"properties": {"title": {"type": "completion","contexts": [{"name": "genre","type": "category"}]}}}
}对于特定的 completion 字段,我们可以定义多个具有唯一名称的上下文。 支持两种类型的上下文:
- Category => 你正在索引的事物的类别,例如 电影/歌曲的类型(genre)
- Geo => 你正在索引的文档的地理点,允许根据经纬度过滤建议。
上述每种上下文类型都支持一些高级参数,例如精度 (precision)、地理上下文的邻居 (neighbours)、查询时的增强 (boost),以便具有特定类别的文档获得更高的分数。 请注意,对于启用上下文的完成字段,在索引文档以及查询文档时,上下文参数是必需的。
让我们在上面创建的索引中索引一些文档:
POST /movies/_doc/2001
{"title": {"input": "Harry Potter and the Chamber of Secrets","contexts": {"genre": "mystery"}}
}POST /movies/_doc/2002
{"title": {"input": "Harry Potter and the Prisoner of Azkaban","contexts": {"genre": "crime"}}
}上面,我们将 "Harry Potter and the Prisoner of Azkaban" 索引为 “crime” 类型的电影,将 "Harry Potter and the Chamber of Secrets" 索引为 “mystery” 类型的电影。 让我们尝试获取前缀 “harry” 的建议:
GET /movies/_search?filter_path=**.harry_suggest
{"_source": "title.input","suggest": {"harry_suggest": {"prefix": "harry","completion": {"field": "title","contexts": {"genre": "crime"}}}}
}上面查询的结果为:
{"suggest": {"harry_suggest": [{"text": "harry","offset": 0,"length": 5,"options": [{"text": "Harry Potter and the Prisoner of Azkaban","_index": "movies","_id": "2002","_score": 1,"_source": {"title": {"input": "Harry Potter and the Prisoner of Azkaban"}},"contexts": {"genre": ["crime"]}}]}]}
}从上面的响应中可以看出,即使传递的前缀与上面索引的两个文档都匹配,也仅返回 “crime” 类型的 “Harry Potter and the Prisoner of Azkaban”。
这就是我们在 Elasticsearch 中实现自动完成的第三种方法。 那么,completion suggester 与迄今为止看到的其他方法相比如何? 它绝对是最快的,因为要搜索的数据在内存中可用,但是如果我们决定使用它实现自动完成,我们需要记住一些事情:
- 必须注意索引的大小,因为建议存储在内存中。
- 中缀 (infix) 匹配,例如 不支持按中间名匹配。
- 不支持对文档中其他字段的建议进行高级过滤。
总结一下,我们可以说在选择在 Elasticsearch 中实现自动完成功能的方法时应考虑以下因素:
- 数据是否已建立索引? 以什么格式? 我们可以重新索引它以使其更适合自动完成功能吗? 如果数据已经被索引为文本字段并且我们无法重新索引它,我们将需要采用查询时间方法 - 即前缀查询 (prefix queries) !
- 该字段可以通过哪些方式查询? 以多种方式存储它有意义吗?
- 是否需要支持中缀 (infix) 匹配? 文本中的单词顺序是固定的吗? 用户是否熟悉该顺序? complete suggesters 不支持中缀匹配,并且不适合具有众所周知的顺序的字段。
- 将作为值提供给我们的字段的文本的最大大小是多少? 如果保存在内存中会产生问题吗? completion suggesters 将数据保存在内存中,基于 n-gram 的方法在基本分词化后创建附加分词以实现更快的匹配。
- 我们需要为这个字段建立一个单独的索引吗? 如果这里提到的所有三种方法都不能满足你的要求,那么你将需要创建另一个索引。 在该索引中,只有 auto-complete 功能所需的字段才会存储为唯一文档,而不是与同一索引中的其他数据一起保存。 这将最大限度地减少节点膨胀的可能性,并且还可以提供更快的建议。 但是,是的,它毕竟是一个单独的索引,你必须保持主索引和新索引之间的数据同步。 管理另一个索引也有开销。
相关文章:
在 Elasticsearch 中实现自动完成功能 3:completion suggester
在这篇博文中,我们将讨论 complete suggester - 一种针对自动完成功能进行优化的 suggester,并且被认为比我们迄今为止讨论的方法更快。 Completion suggester 使用称为有限状态转换器的数据结构,该结构类似于 Trie 数据结构,并且…...

走进Flink
什么是Flink Flink是一个分布式的、高性能的、可伸缩的、容错的流处理引擎,它支持批处理和流处理,并提供了丰富的 API 和库,是实时数据处理的理想选择 由Java 和 Scala 实现的,所以所有组件都会运行在Java 虚拟机【单个JVM也可以】…...
Kubernetes核心组件Services
1. Kubernetes Service概念 Service是kubernetes最核心的概念,通过创建Service,可以为一组具有相同功能的POD(容器)应用提供统一的访问入口,并且将请求进行负载分发到后端的各个容器应用上。 在Kubernetes中…...
Win10 系统中用户环境变量和系统环境变量是什么作用和区别?
环境: Win10专业版 问题描述: Win10 系统中用户环境变量和系统环境变量是什么作用和区别? 解答: 在Windows 10系统中,用户环境变量和系统环境变量是两个不同的环境变量,它们具有不同的作用和区别 1.用…...

rust模式
一、模式是什么 模式是Rust中特殊的语法,它用来匹配值 二、模式的使用场景 (一)match match的每个分支箭头左边部分就是模式。 match VALUE {PATTERN > EXPRESSION,PATTERN > EXPRESSION,PATTERN > EXPRESSION, }例子 match x …...
紫光同创FPGA 多路视频处理:图像缩放+视频拼接显示,OV7725采集,提供PDS工程源码和技术支持
目录 1、前言免责声明 2、相关方案推荐FPGA图像缩放方案推荐FPGA视频拼接叠加融合方案推荐紫光同创FPGA图像采集方案推荐紫光同创FPGA图像缩放方案推荐紫光同创FPGA视频拼接方案推荐 3、设计思路框架为什么选择OV7725摄像头?视频源选择OV7725摄像头配置及采集动态彩…...
)
软考 系统架构设计师系列知识点之软件质量属性(4)
接前一篇文章:软考 系统架构设计师系列知识点之软件质量属性(3) 所属章节: 第8章. 系统质量属性与架构评估 第2节. 面向架构评估的质量属性 相关试题 3. 某公司欲开发一个在线交易系统。在架构设计阶段,公司的架构师…...
如何用BI制作图表组合?
BI(Business Intelligence)是一种通过收集、分析和可视化数据来帮助企业做出决策的技术和工具。在BI中,制作图表组合是一种常见的方式,可以将不同的图表类型组合在一起,以更全面地呈现数据。 下面将详细介绍如何使用B…...
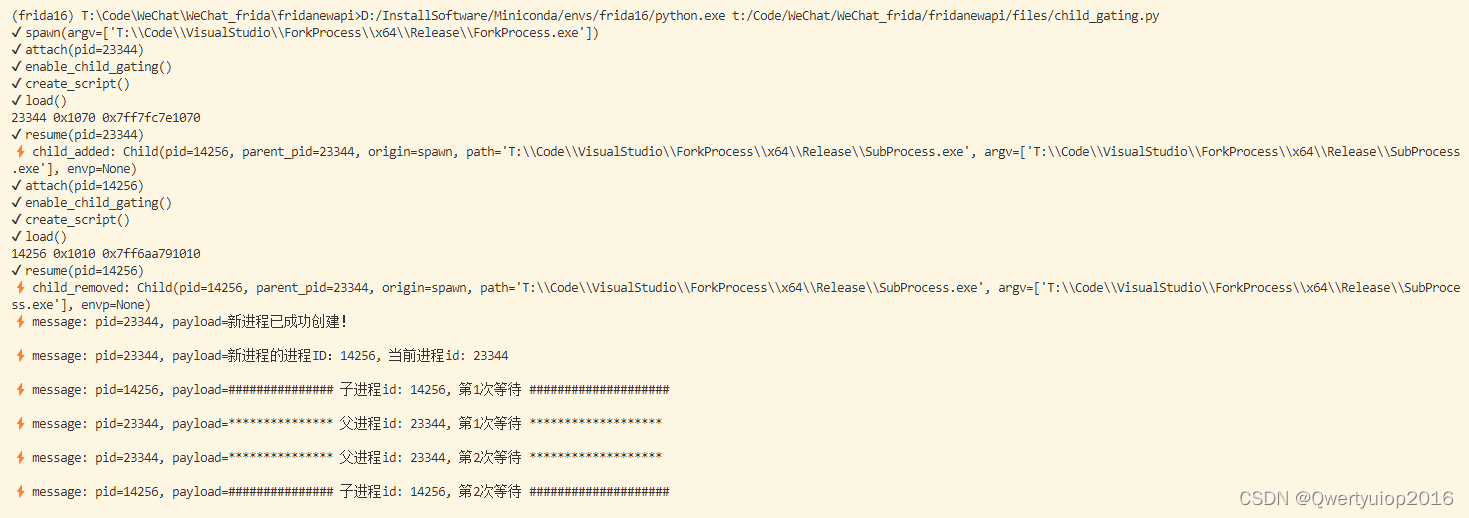
使用frida来spawn Fork 的子进程
索引 需求测试程序父进程代码子进程代码 x64dbg插件功能开始调试 frida运行环境用到的文件和代码 需求 最近在学基础的Windows逆向知识,遇到个小问题。一个进程使用CreateProcessW创建的进程该如何在启动时附加,我想调试这个子进程启动时运行的函数。 …...
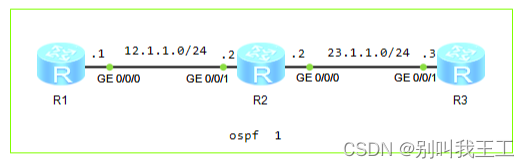
网工笔记整理:策略工具Filter-policy的使用
一、概述 Filter-Policy(过滤-策略)是一个很常用的路由信息过滤工具,能够对接收、发布、引入的路由进行过滤,可应用于IS-IS、OSPF、BGP等协议。 Filter-policy在距离矢量路由协议中的应用 filter-policy import:不发…...

数据结构和算法——查找算法
目录 线性查找法 二分查找法 插值查找法 斐波那契查找法 线性查找法 可以是有序的,也可以是无序的。 public class SeqSearch {public static void main(String[] args) {int[] arr new int[]{1, 9, 11, -1, 34, 89};int res seqSearch(arr, 34);}public st…...

Blender:对模型着色
Blender:使用立方体制作动漫头像-CSDN博客 上一步已经做了一个头像模型,我做的太丑了,就以这个外星人头像为例 首先切换到着色器编辑器 依次搜索:纹理坐标、映射、分离xyz和颜色渐变 这里的功能也是非常丰富和强大,…...

加密市场波动:地缘政治与美股走弱引发不确定性!
伴随着国庆假期的结束,多日波动率维持低位的加密市场也似乎开始苏醒。近期多次突破28000美元未果的比特币,于9日15:00开始从27800美元附近下跌,最低跌至27260美元,同期以太坊也至1550美元左右,创近半个月来新低。 Coin…...
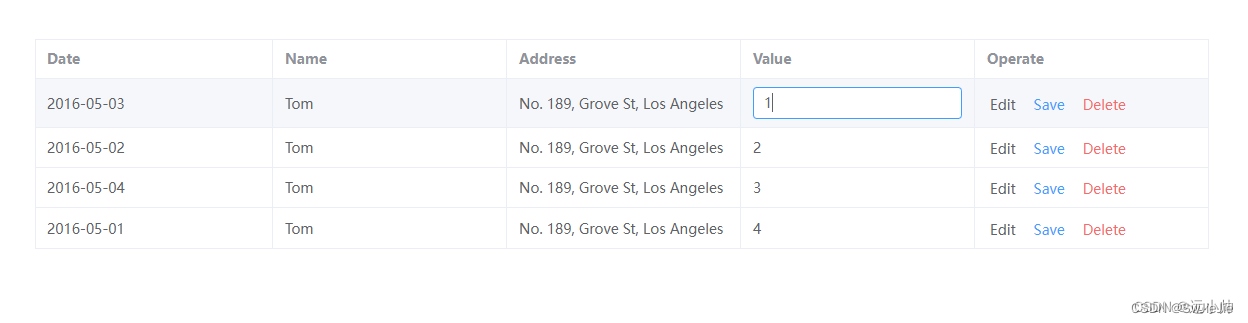
ElementUI编辑表格单元格与查看模式切换的应用
需求:有时候在填写表单的时候,想要在输入的时候是input输入框的状态,但是当鼠标移出输入框失去焦点时,希望是查看的状态,这种场景可以通过 v-if实现 vue2ElementUi里面使用如下: 1.el-table标签注册 cell-…...

spring-创建Webservice服务
Web service是一个平台独立的,松耦合的,自包含的、基于可编程的web的应用程序,可使用开放的XML标准来描述、发布、发现、协调和配置这些应用程序,用于开发分布式的互操作的应用程序。webservice用的是soap协议。 客户通过发送请求…...
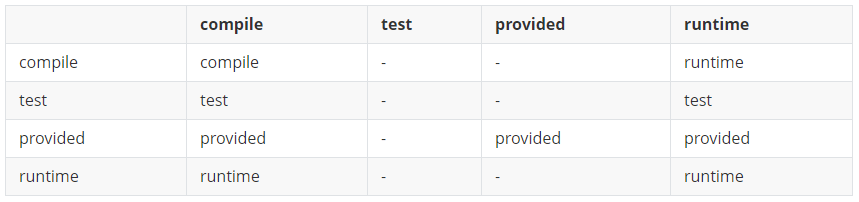
Maven系列第3篇:详解maven解决依赖问题
maven系列目标:从入门开始开始掌握一个高级开发所需要的maven技能。 这是maven系列第3篇。 我们先来回顾一下什么是maven? maven是apache软件基金会组织维护的一款自动化构件工具,专注服务于java平台的项目构件和依赖管理。 本文主要内容…...

读书笔记:多Transformer的双向编码器表示法(Bert)-4
多Transformer的双向编码器表示法 Bidirectional Encoder Representations from Transformers,即Bert; 第二部分 探索BERT变体 从本章开始的诸多内容,以理解为目标,着重关注对音频相关的支持(如果有的话)…...

Stable Diffusion XL搭建
本文参考:Stable Diffusion XL1.0正式发布了,赶紧来尝鲜吧-云海天教程 Stable Diffision最新模型SDXL 1.0使用全教程 - 知乎 1、SDXL与SD的区别 (1)分辨率得到了提升 原先使用SD生成图片,一般都是生成512*512&…...
:性能优化之PureComponent和memo)
面试题-React(十一):性能优化之PureComponent和memo
一、React性能优化的重要性 随着应用的复杂性增加,React组件的渲染可能成为性能瓶颈。频繁的渲染可能导致不必要的性能开销和卡顿。为了确保应用的高性能和流畅用户体验,我们需要采取一些措施来优化组件的渲染。 二、PureComponent-自动浅比较 PureCo…...
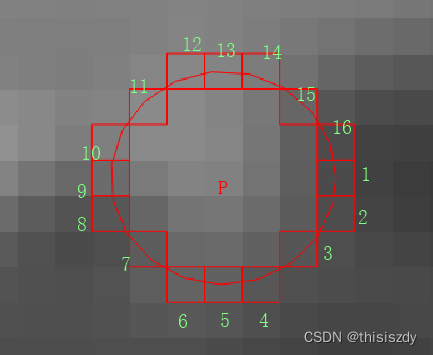
<图像处理> Fast角点检测
Fast角点检测 基本原理是使用圆周长为N个像素的圆来判定其圆心像素P是否为角点,如下图所示为圆周长为16个像素的圆(半径为3);OpenCV还提供圆周长为12和8个像素的圆来检测角点。 相对中心像素的位置信息 //圆周长为16 static c…...

手把手教你用85033E校准套件搞定E5071C网分的TDR和S参数测量
手把手教你用85033E校准套件搞定E5071C网分的TDR和S参数测量 在射频和微波测试领域,网络分析仪是工程师不可或缺的工具,而E5071C作为一款经典的中端矢量网络分析仪,广泛应用于通信、雷达、天线等领域的研发和测试。对于刚接触这款设备的新手工…...

SteamAutoCrack完整指南:一键移除游戏DRM保护
SteamAutoCrack完整指南:一键移除游戏DRM保护 【免费下载链接】Steam-auto-crack Steam Game Automatic Cracker 项目地址: https://gitcode.com/gh_mirrors/st/Steam-auto-crack SteamAutoCrack是一款专业的开源游戏DRM移除工具,能够自动解除Ste…...

AIGC 检测算法 1.0 到 4.0 升级了什么?嘎嘎降 AI 实测 80% AI 率降到 6% 答辩稳过
AIGC 检测算法 1.0 到 4.0 升级了什么?嘎嘎降 AI 实测 80% AI 率降到 6% 答辩稳过 很多同学不理解——为什么 2024 年用换同义词就能降下 AI 率、2025 年开始这招就半失效了、2026 年完全没用了?真相是——AIGC 检测算法从 1.0 升级到 4.0 经历了 4 次大…...

Vivado 2022.1里Floating-point IP核的隐藏技巧:如何优化开方运算的延迟与资源消耗
Vivado 2022.1浮点开方IP核深度调优:从参数配置到硬件实现的黄金法则 在FPGA信号处理系统中,浮点运算单元往往是性能瓶颈所在。当设计一个实时性要求极高的雷达信号处理链路时,我曾在某型号的Xilinx UltraScale器件上遭遇过这样的困境&#x…...

如何高效下载B站视频:3分钟掌握智能下载工具完整指南
如何高效下载B站视频:3分钟掌握智能下载工具完整指南 【免费下载链接】BiliDownloader BiliDownloader是一款界面精简,操作简单且高速下载的b站下载器 项目地址: https://gitcode.com/gh_mirrors/bi/BiliDownloader 你是否曾经遇到过这样的情况&a…...

如何高效掌握LAMMPS:分子动力学模拟的完整实战指南
如何高效掌握LAMMPS:分子动力学模拟的完整实战指南 【免费下载链接】lammps Public development project of the LAMMPS MD software package 项目地址: https://gitcode.com/gh_mirrors/la/lammps 想要快速掌握强大的分子动力学模拟工具吗?LAMM…...

专业级LaTeX排版:深度解析中国科学技术大学学位论文模板括号使用的最佳实践
专业级LaTeX排版:深度解析中国科学技术大学学位论文模板括号使用的最佳实践 【免费下载链接】ustcthesis LaTeX template for USTC thesis 项目地址: https://gitcode.com/gh_mirrors/us/ustcthesis 在学术论文写作中,细节决定专业水准。中国科学…...

5个步骤掌握微信聊天记录永久保存:WeChatMsg完全掌控指南
5个步骤掌握微信聊天记录永久保存:WeChatMsg完全掌控指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/We…...

CH348芯片全平台驱动实战:从Windows Server到树莓派Linux,一次搞定8串口配置
CH348芯片全平台驱动实战:从Windows Server到树莓派Linux,一次搞定8串口配置 工业自动化、物联网网关、多设备调试等场景中,工程师常面临一个核心痛点:如何在各类操作系统环境下高效管理多串口设备。南京沁恒微电子的CH348芯片以其…...

1951-2025年中国1km月平均气温逐年年内季节波动幅度数据集
中国1000米分辨率月平均气温数据集(1951-2025)提供了长时间序列、规则网格的气象背景信息,为开展气候变化分析和区域比较研究提供了基础数据支撑。针对原始月尺度序列直接使用不够便捷的问题,需要进一步形成具有明确主题和统一格式…...