nnunetv2训练报错 ValueError: mmap length is greater than file size
目录
- 报错
- 解决办法
报错
笔者在使用 nnunetv2 进行 KiTS19肾脏肿瘤分割实验的训练步骤中
使用 2d 和3d_lowres 训练都没有问题
nnUNetv2_train 40 2d 0
nnUNetv2_train 40 3d_lowres 0
但是使用 3d_cascade_fullres 和 3d_fullres 训练
nnUNetv2_train 40 3d_cascade_fullres 0
nnUNetv2_train 40 3d_fullres 0
都会报这个异常 ValueError: mmap length is greater than file size
具体报错内容如下:
root@autodl-container-fdb34f8e52-02177b7e:~# nnUNetv2_train 40 3d_cascade_fullres 0
Using device: cuda:0#######################################################################
Please cite the following paper when using nnU-Net:
Isensee, F., Jaeger, P. F., Kohl, S. A., Petersen, J., & Maier-Hein, K. H. (2021). nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods, 18(2), 203-211.
#######################################################################This is the configuration used by this training:
Configuration name: 3d_cascade_fullres{'data_identifier': 'nnUNetPlans_3d_fullres', 'preprocessor_name': 'DefaultPreprocessor', 'batch_size': 2, 'patch_size': [128, 128, 128], 'median_image_size_in_voxels': [525.5, 512.0, 512.0], 'spacing': [0.78126, 0.78125, 0.78125], 'normalization_schemes': ['CTNormalization'], 'use_mask_for_norm': [False], 'UNet_class_name': 'PlainConvUNet', 'UNet_base_num_features': 32, 'n_conv_per_stage_encoder': [2, 2, 2, 2, 2, 2], 'n_conv_per_stage_decoder': [2, 2, 2, 2, 2], 'num_pool_per_axis': [5, 5, 5], 'pool_op_kernel_sizes': [[1, 1, 1], [2, 2, 2], [2, 2, 2], [2, 2, 2], [2, 2, 2], [2, 2, 2]], 'conv_kernel_sizes': [[3, 3, 3], [3, 3, 3], [3, 3, 3], [3, 3, 3], [3, 3, 3], [3, 3, 3]], 'unet_max_num_features': 320, 'resampling_fn_data': 'resample_data_or_seg_to_shape', 'resampling_fn_seg': 'resample_data_or_seg_to_shape', 'resampling_fn_data_kwargs': {'is_seg': False, 'order': 3, 'order_z': 0, 'force_separate_z': None}, 'resampling_fn_seg_kwargs': {'is_seg': True, 'order': 1, 'order_z': 0, 'force_separate_z': None}, 'resampling_fn_probabilities': 'resample_data_or_seg_to_shape', 'resampling_fn_probabilities_kwargs': {'is_seg': False, 'order': 1, 'order_z': 0, 'force_separate_z': None}, 'batch_dice': True, 'inherits_from': '3d_fullres', 'previous_stage': '3d_lowres'}These are the global plan.json settings:{'dataset_name': 'Dataset040_KiTS', 'plans_name': 'nnUNetPlans', 'original_median_spacing_after_transp': [3.0, 0.78125, 0.78125], 'original_median_shape_after_transp': [108, 512, 512], 'image_reader_writer': 'SimpleITKIO', 'transpose_forward': [2, 0, 1], 'transpose_backward': [1, 2, 0], 'experiment_planner_used': 'ExperimentPlanner', 'label_manager': 'LabelManager', 'foreground_intensity_properties_per_channel': {'0': {'max': 3071.0, 'mean': 102.5714111328125, 'median': 103.0, 'min': -1015.0, 'percentile_00_5': -75.0, 'percentile_99_5': 295.0, 'std': 73.64986419677734}}}2023-10-13 17:22:36.747343: unpacking dataset...
2023-10-13 17:22:40.991390: unpacking done...
2023-10-13 17:22:40.992978: do_dummy_2d_data_aug: False
2023-10-13 17:22:40.997410: Using splits from existing split file: /root/autodl-tmp/nnUNet-master/dataset/nnUNet_preprocessed/Dataset040_KiTS/splits_final.json
2023-10-13 17:22:40.998125: The split file contains 5 splits.
2023-10-13 17:22:40.998262: Desired fold for training: 0
2023-10-13 17:22:40.998355: This split has 168 training and 42 validation cases.
/root/miniconda3/lib/python3.10/site-packages/torch/onnx/symbolic_helper.py:1513: UserWarning: ONNX export mode is set to TrainingMode.EVAL, but operator 'instance_norm' is set to train=True. Exporting with train=True.warnings.warn(
2023-10-13 17:22:45.383066:
2023-10-13 17:22:45.383146: Epoch 0
2023-10-13 17:22:45.383244: Current learning rate: 0.01
Exception in background worker 4:mmap length is greater than file size
Traceback (most recent call last):File "/root/miniconda3/lib/python3.10/site-packages/batchgenerators/dataloading/nondet_multi_threaded_augmenter.py", line 53, in produceritem = next(data_loader)File "/root/miniconda3/lib/python3.10/site-packages/batchgenerators/dataloading/data_loader.py", line 126, in __next__return self.generate_train_batch()File "/root/autodl-tmp/nnUNet-master/nnunetv2/training/dataloading/data_loader_3d.py", line 19, in generate_train_batchdata, seg, properties = self._data.load_case(i)File "/root/autodl-tmp/nnUNet-master/nnunetv2/training/dataloading/nnunet_dataset.py", line 86, in load_casedata = np.load(entry['data_file'][:-4] + ".npy", 'r')File "/root/miniconda3/lib/python3.10/site-packages/numpy/lib/npyio.py", line 429, in loadreturn format.open_memmap(file, mode=mmap_mode,File "/root/miniconda3/lib/python3.10/site-packages/numpy/lib/format.py", line 937, in open_memmapmarray = numpy.memmap(filename, dtype=dtype, shape=shape, order=order,File "/root/miniconda3/lib/python3.10/site-packages/numpy/core/memmap.py", line 267, in __new__mm = mmap.mmap(fid.fileno(), bytes, access=acc, offset=start)
ValueError: mmap length is greater than file size
Exception in background worker 2:mmap length is greater than file size
Traceback (most recent call last):File "/root/miniconda3/lib/python3.10/site-packages/batchgenerators/dataloading/nondet_multi_threaded_augmenter.py", line 53, in produceritem = next(data_loader)File "/root/miniconda3/lib/python3.10/site-packages/batchgenerators/dataloading/data_loader.py", line 126, in __next__return self.generate_train_batch()File "/root/autodl-tmp/nnUNet-master/nnunetv2/training/dataloading/data_loader_3d.py", line 19, in generate_train_batchdata, seg, properties = self._data.load_case(i)File "/root/autodl-tmp/nnUNet-master/nnunetv2/training/dataloading/nnunet_dataset.py", line 86, in load_casedata = np.load(entry['data_file'][:-4] + ".npy", 'r')File "/root/miniconda3/lib/python3.10/site-packages/numpy/lib/npyio.py", line 429, in loadreturn format.open_memmap(file, mode=mmap_mode,File "/root/miniconda3/lib/python3.10/site-packages/numpy/lib/format.py", line 937, in open_memmapmarray = numpy.memmap(filename, dtype=dtype, shape=shape, order=order,File "/root/miniconda3/lib/python3.10/site-packages/numpy/core/memmap.py", line 267, in __new__mm = mmap.mmap(fid.fileno(), bytes, access=acc, offset=start)
ValueError: mmap length is greater than file size
using pin_memory on device 0
Traceback (most recent call last):File "/root/miniconda3/bin/nnUNetv2_train", line 8, in <module>sys.exit(run_training_entry())File "/root/autodl-tmp/nnUNet-master/nnunetv2/run/run_training.py", line 268, in run_training_entryrun_training(args.dataset_name_or_id, args.configuration, args.fold, args.tr, args.p, args.pretrained_weights,File "/root/autodl-tmp/nnUNet-master/nnunetv2/run/run_training.py", line 204, in run_trainingnnunet_trainer.run_training()File "/root/autodl-tmp/nnUNet-master/nnunetv2/training/nnUNetTrainer/nnUNetTrainer.py", line 1237, in run_trainingtrain_outputs.append(self.train_step(next(self.dataloader_train)))File "/root/miniconda3/lib/python3.10/site-packages/batchgenerators/dataloading/nondet_multi_threaded_augmenter.py", line 196, in __next__item = self.__get_next_item()File "/root/miniconda3/lib/python3.10/site-packages/batchgenerators/dataloading/nondet_multi_threaded_augmenter.py", line 181, in __get_next_itemraise RuntimeError("One or more background workers are no longer alive. Exiting. Please check the "
RuntimeError: One or more background workers are no longer alive. Exiting. Please check the print statements above for the actual error message
解决办法
nnunet 作者给出的解决办法,详情请戳
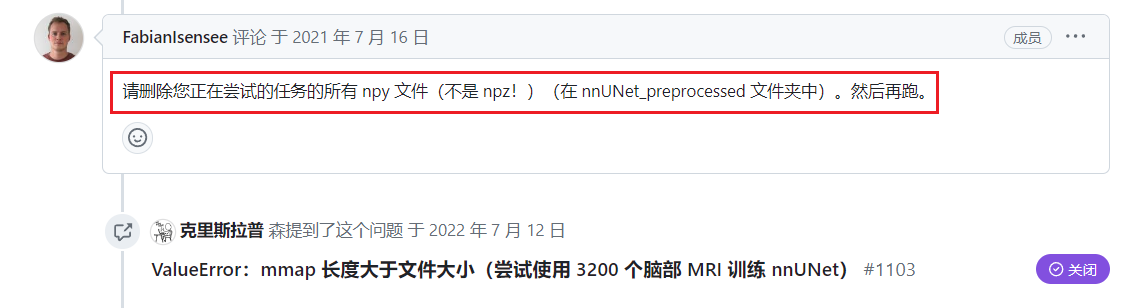
进入指定文件夹中,执行
rm *.npy
相关文章:
nnunetv2训练报错 ValueError: mmap length is greater than file size
目录 报错解决办法 报错 笔者在使用 nnunetv2 进行 KiTS19肾脏肿瘤分割实验的训练步骤中 使用 2d 和3d_lowres 训练都没有问题 nnUNetv2_train 40 2d 0nnUNetv2_train 40 3d_lowres 0但是使用 3d_cascade_fullres 和 3d_fullres 训练 nnUNetv2_train 40 3d_cascade_fullres …...
-每天10个小知识)
React知识点系列(2)-每天10个小知识
目录 1. 如何优化 React 应用的性能?你用过哪些性能分析工具?2. 在 React 中,什么是 Context API?你在什么场景下会使用它?3. 你能解释一下什么是 React Fiber 吗?4. 在项目中,你是否使用过 Rea…...
AutoGPT:让 AI 帮你完成任务事情 | 开源日报 No.54
Significant-Gravitas/AutoGPT Stars: 150.4k License: MIT AutoGPT 是开源 AI 代理生态系统的核心工具包。它采用模块化和可扩展的框架,使您能够专注于以下方面: 构建 - 为惊人之作打下基础。测试 - 将您的代理调整到完美状态。查看 - 观察进展成果呈…...
USB 转串口芯片 CH340
目录 1、概述 2、特点 3、封装 4、引脚 6、参数 6.1 绝对最大值(临界或者超过绝对最大值将可能导致芯片工作不正常甚至损坏) 6.2 电气参数(测试条件:TA25℃,VCC5V,不包括连接 USB 总线的引脚&…...
Day 05 python学习笔记
循环 应用:循环轮播图 最基础、最核心 循环:周而复始,谓之循环 (为了代码尽量不要重复) while循环 while的格式 索引定义 while 表达式(只要结果为布尔值即可): 循环体 通过条件的不断变化,从…...

Python如何17行代码画一个爱心
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...

生产环境中常用Linux命令
太简单的我就不讲解啦,浪费时间,直接将生产中常用的 文章目录 1.总纲2.整机 top3.CPU vmstat3. 内存 free4. 硬盘: df5. 磁盘IO iostat6. 网络IO ifstat7: 内存过高的情景排查 1.总纲 整机:topcpu:vmstat内存:free硬盘:df磁盘io: iostat网络io:ifstat 2.整机 top 首先们要查…...
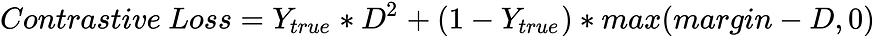
【使用 TensorFlow 2】03/3 创建自定义损失函数
一、说明 TensorFlow 2发布已经接近5年时间,不仅继承了Keras快速上手和易于使用的特性,同时还扩展了原有Keras所不支持的分布式训练的特性。3大设计原则:简化概念,海纳百川,构建生态.这是本系列的第三部分,…...

Vue3中使用v-model高级用法参数绑定传值
Vue3中使用v-model高级用法参数绑定传值 单个输入框传值多个输入框传值,一个组件接受多个v-model值 单个输入框传值 App.vue <template><p>{{firstName}}</p><hello-world v-model"firstName"></hello-world> </template><…...

你的工作中,chatGPT可以帮你做什么?
如何在工作中使用 ChatGPT 的 10 种实用方法 现在您已经知道如何开始使用 ChatGPT 并了解其基本功能(提示 -> 响应),让我们探讨如何使用它来大幅提高工作效率。 1. 总结报告、会议记录等 ChatGPT可以快速分析大文本并识别关键点。例如&a…...

k8s简单部署nginx
文章目录 1. 前言2. 部署nginx2.1. **创建一个nginx的Deployment**2.2. **创建一个nginx的service** 3. 总结 1. 前言 前文提要: kubeadm简单搭建k8s集群第三方面板部署k8s 上篇文章我们简单部署了k8s的集群环境,相比一定迫不及待的想部署一个实际应用了…...
小黑子—MyBatis:第四章
MyBatis入门4.0 十 小黑子进行MyBatis参数处理10.1 单个简单类型参数10.1.1 单个参数Long类型10.1.2 单个参数Date类型 10.2 Map参数10.3 实体类参数(POJO参数)10.4 多参数10.5 Param注解(命名参数)10.6 Param注解源码分析 十一 小…...
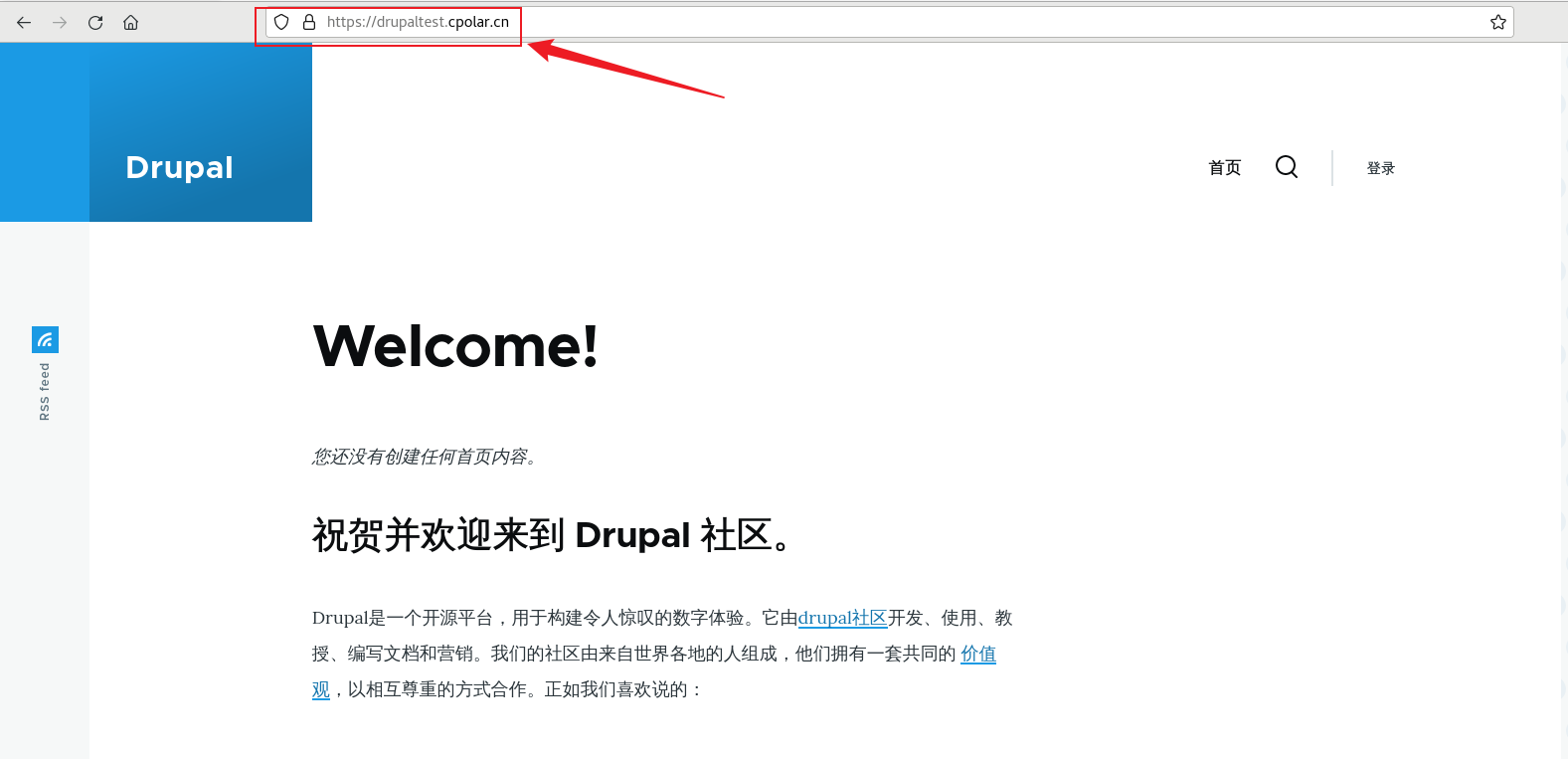
Docker快速上手:使用Docker部署Drupal并实现公网访问
文章目录 前言1. Docker安装Drupal2. 本地局域网访问3 . Linux 安装cpolar4. 配置Drupal公网访问地址5. 公网远程访问Drupal6. 固定Drupal 公网地址 前言 Dupal是一个强大的CMS,适用于各种不同的网站项目,从小型个人博客到大型企业级门户网站。它的学习…...
-每天10个小知识)
React知识点系列(1)-每天10个小知识
目录 1.什么是 React,以及它在前端开发中的优势是什么?2.你是如何组织和管理 React 组件的?3.你能解释一下 React 的生命周期方法吗?你通常在哪个生命周期方法中发起网络请求?4.什么是 React Hooks?你常用哪…...

substring 和 substr 的区别
1、结论 两个方法都用于截取字符串,其用法不同: 1)相同点: ① 都用于截取字符串; ② 第一个参数都是表示提取字符的开始索引位置; 2)不同点: ① 第一个参数的取值范围不同&…...

产品经理的工作职责是什么?
产品经理的工作职责主要包括以下几个方面: 1. 产品策划与定义:产品经理负责制定产品的整体策略和规划,包括产品定位、目标用户、市场需求分析等。他们需要与团队合作,定义产品的功能和特性,明确产品的核心竞争力和差异…...

智能井盖传感器:提升城市安全与便利的利器
在智能化城市建设的浪潮中,WITBEE万宾智能井盖传感器,正以其卓越的性能和创新的科技,吸引着越来越多的关注。本文小编将为大家详细介绍这款产品的独特优势和广阔应用前景。 在我们生活的城市中,井盖可能是一个最不起眼的存在。然而…...
给你一个项目,你将如何开展性能测试工作?
一、性能三连问 1、何时进行性能测试? 性能测试的工作是基于系统功能已经完备或者已经趋于完备之上的,在功能还不够完备的情况下没有多大的意义。因为后期功能完善上会对系统的性能有影响,过早进入性能测试会出现测试结果不准确、浪费测试资…...

点燃市场热情,让产品风靡全球——实用推广策略大揭秘!
文章目录 一、实用推广策略的重要性1. 提高产品知名度和认可度2. 拓展产品市场和用户群体3. 增强企业品牌形象和市场竞争力 二、实用推广策略的种类1. 社交媒体推广2. 定向推广3. 口碑营销4. 内容推广 三、实用推广策略的实施步骤1. 研究目标用户和市场需求,明确产品…...

Python操作Hive数据仓库
Python连接Hive 1、Python如何连接Hive?2、Python连接Hive数据仓库 1、Python如何连接Hive? Python连接Hive需要使用Impala查询引擎 由于Hadoop集群节点间使用RPC通信,所以需要配置Thrift依赖环境 Thrift是一个轻量级、跨语言的RPC框架&…...

Taotoken多模型API助力MATLAB用户解决复杂建模问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken多模型API助力MATLAB用户解决复杂建模问题 对于在MATLAB环境中进行算法开发与系统仿真的研究人员而言,日常工作…...

2026年热门抠图软件怎么选?好用的抠图工具实测对比与推荐指南
抠图的需求无处不在——做小红书封面、制作电商商品图、处理证件照、视频背景分离——但市面上的抠图工具繁杂多样,究竟哪个才是真正好用的?我们在2026年对市场上主流的抠图软件进行了全面实测,从操作体验、AI识别精度、输出质量、使用成本等…...

如何在MATLAB中调用Taotoken聚合大模型API进行智能分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何在MATLAB中调用Taotoken聚合大模型API进行智能分析 对于使用MATLAB进行科学计算、数据分析或算法开发的工程师和研究人员而言&…...

Perplexity法律文献搜索实战指南:7步构建精准检索式,避开90%的无效结果
更多请点击: https://codechina.net 第一章:Perplexity法律文献搜索实战指南:7步构建精准检索式,避开90%的无效结果 Perplexity 作为面向专业研究者的AI搜索工具,在法律文献检索中展现出远超通用搜索引擎的语义理解与…...

5个步骤掌握微信聊天记录永久保存:WeChatMsg完全掌控指南
5个步骤掌握微信聊天记录永久保存:WeChatMsg完全掌控指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/We…...

智能车视觉巡线:从图像处理到PID控制的嵌入式实战解析
1. 项目概述:一场关于速度与精度的极限挑战十多年前,当飞思卡尔(Freescale)智能车竞赛还是校园里最硬核的科技赛事之一时,摄像头组的较量无疑是皇冠上的明珠。它不像光电组依赖地面反射,也不像电磁组追寻导…...

AI+STEAM教育方案:基于边缘计算的智能硬件与算法部署实践
1. 项目概述:当AI遇见STEAM,教育如何被重新定义作为一名在教育和科技交叉领域摸爬滚打了十来年的从业者,我亲眼见证了从多媒体教室到在线教育平台,再到如今AI深度介入的整个变迁过程。最近几年,一个词被反复提及&#…...

网易云QQ音乐歌词获取终极指南:163MusicLyrics让你轻松拥有完美歌词
网易云QQ音乐歌词获取终极指南:163MusicLyrics让你轻松拥有完美歌词 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为音乐播放器缺少歌词而烦恼…...

基于RP2040与CircuitPython的复古电话点歌系统:从矩阵键盘到音频播放
1. 项目概述:当复古电话遇见现代微控制器几年前,我在一个旧货市场淘到了一台成色还不错的Western Electric 2500DM电话机。这种经典的按键式电话,拿在手里沉甸甸的,听筒里仿佛还残留着上个世纪的通话声。当时我就在想,…...

从硬件电路深入理解计算机中断机制:8088到现代中断控制器
1. 项目概述:从硬件视角重新认识中断在计算机的世界里,中断(Interrupt)是一个既基础又至关重要的概念。它就像是程序世界里的“紧急呼叫”系统,允许CPU这个“大管家”在埋头处理日常事务(执行主程序&#x…...