基于 ACK Fluid 的混合云优化数据访问(五):自动化跨区域中心数据分发
作者:车漾
前文回顾:
本系列将介绍如何基于 ACK Fluid 支持和优化混合云的数据访问场景,相关文章请参考:
-基于 ACK Fluid 的混合云优化数据访问(一):场景与架构
-基于 ACK Fluid 的混合云优化数据访问(二):搭建弹性计算实例与第三方存储的桥梁
-基于 ACK Fluid 的混合云优化数据访问(三):加速第三方存储的读访问,降本增效并行
-基于 ACK Fluid 的混合云优化数据访问(四):将第三方存储目录挂载到 Kubernetes,提升效率和标准化
在之前的文章中,我们讨论了混合云场景下 Kubernetes 与数据相结合的 Day 1:解决数据接入的问题,实现云上计算和线下存储的连接。在此基础上,ACK Fluid 进一步解决了数据访问的成本和性能问题。而进入 Day 2,当用户真的在生产环境使用该方案时,最主要的挑战就是运维側如何处理多区域集群的数据同步。
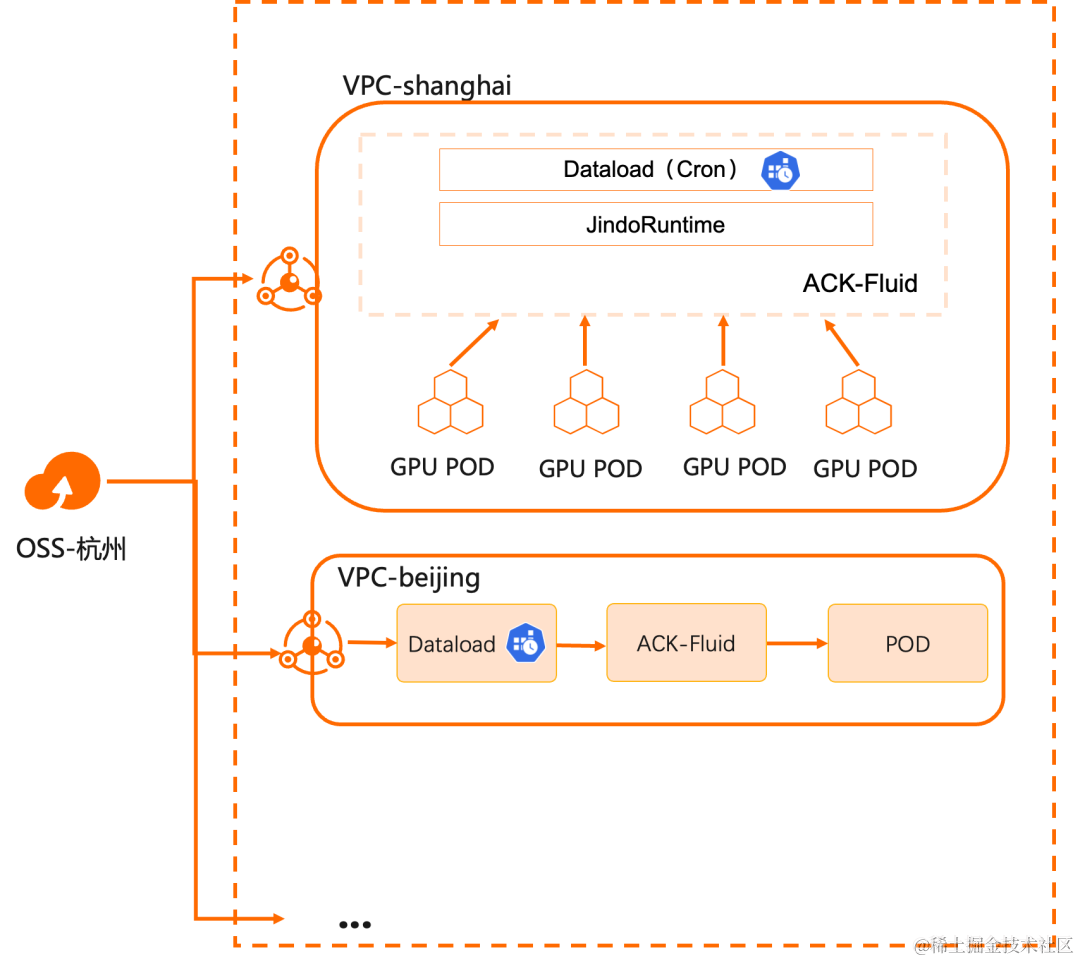
概述
许多企业出于性能、安全、稳定性和资源隔离的目的,会在不同区域建立多个计算集群。而这些计算集群需要远程访问唯一中心化的数据存储。比如随着大语言模型的逐渐成熟,基于其的多区域推理服务也逐渐成为各个企业需要支持的能力,就是这个场景的具体实例,它有不小的挑战:
- 多计算集群跨数据中心手动操作数据同步,非常耗时
- 以大语言模型为例,参数多文件大,数量多,管理复杂:不同业务选择不同的基础模型和业务数据,因此最终模型存在差异。
- 模型数据会根据业务输入不断做更新迭代,模型数据更新频繁
- 模型推理服务启动慢,拉取文件时间长:大型语言模型的参数规模相当巨大,体积通常很大甚至达到几百 GB,导致拉取到 GPU 显存的耗时巨大,启动时间非常慢。
- 模型更新需要所有区域同步更新,而在过载的存储集群上进行复制作业严重影响现有负载的性能。
ACK Fluid 除了提供通用存储客户端的加速能力,还提供了定时和触发式数据迁移和预热能力,简化数据分发的复杂度。
- 节省网络和计算成本: 跨区流量成本大幅降低,计算时间明显缩短,少量增加计算集群成本;并且可以通过弹性进一步优化。
- 应用数据更新大幅加速: 由于计算的数据访问在同一个数据中心或者可用区内完成通信,延时降低,且缓存吞吐并发能力可线性扩展。
- 减少复杂的数据同步操作: 通过自定义策略控制数据同步操作,降低数据访问争抢,同时通过自动化的方式降低运维复杂度。
演示
本演示介绍如何通过 ACK Fluid 的定时预热机制更新用户不同区域的计算集群可以访问的数据。
前提条件
- 已创建 ACK Pro 版集群,且集群版本为 1.18 及以上。具体操作,请参见创建 ACK Pro 版集群 [ 1] 。
- 已安装云原生 AI 套件并部署 ack-fluid 组件。重要:若您已安装开源 Fluid,请卸载后再部署 ack-fluid 组件。
- 未安装云原生 AI 套件:安装时开启 Fluid 数据加速。具体操作,请参见安装云原生 AI 套件 [ 2] 。
- 已安装云原生 AI 套件:在容器服务管理控制台 [ 3] 的云原生 AI 套件页面部署 ack-fluid。
- 已通过 kubectl 连接 Kubernetes 集群。具体操作,请参见通过 kubectl 工具连接集群 [ 4] 。
背景信息
准备好 K8s 和 OSS 环境的条件,您只需要耗费 10 分钟左右即可完成 JindoRuntime 环境的部署。
步骤一:准备 OSS Bucket 的数据
- 执行以下命令,下载一份测试数据。
$ wget https://archive.apache.org/dist/hbase/2.5.2/RELEASENOTES.md
- 将下载的测试数据上传到阿里云 OSS 对应的 Bucket 上,上传方法可以借助 OSS 提供的客户端工具 ossutil。具体操作,请参见安装 ossutil [ 5] 。
$ ossutil cp RELEASENOTES.md oss://<bucket>/<path>/RELEASENOTES.md
步骤二:创建Dataset和JindoRuntime
- 在创建 Dataset 之前,您可以创建一个 mySecret.yaml 文件来保存 OSS 的 accessKeyId 和 accessKeySecret。
创建 mySecret.yaml 文件的 YAML 样例如下:
apiVersion: v1
kind: Secret
metadata:name: mysecret
stringData:fs.oss.accessKeyId: xxxfs.oss.accessKeySecret: xxx
- 执行以下命令,生成 Secret。
$ kubectl create -f mySecret.yaml
- 使用以下 YAML 文件样例创建一个名为 dataset.yaml 的文件,且里面包含两部分:
- 创建一个 Dataset,描述远端存储数据集和 UFS 的信息。
- 创建一个 JindoRuntime,启动一个 JindoFS 的集群来提供缓存服务。
apiVersion: data.fluid.io/v1alpha1
kind: Dataset
metadata:name: demo
spec:mounts:- mountPoint: oss://<bucket-name>/<path>options:fs.oss.endpoint: <oss-endpoint>name: hbasepath: "/"encryptOptions:- name: fs.oss.accessKeyIdvalueFrom:secretKeyRef:name: mysecretkey: fs.oss.accessKeyId- name: fs.oss.accessKeySecretvalueFrom:secretKeyRef:name: mysecretkey: fs.oss.accessKeySecretaccessModes:- ReadOnlyMany
---
apiVersion: data.fluid.io/v1alpha1
kind: JindoRuntime
metadata:name: demo
spec:replicas: 1tieredstore:levels:- mediumtype: MEMpath: /dev/shmquota: 2Gihigh: "0.99"low: "0.8"fuse:args:- -okernel_cache- -oro- -oattr_timeout=60- -oentry_timeout=60- -onegative_timeout=60
相关参数解释如下表所示:
| 参数 | 说明 |
|---|---|
| mountPoint | oss://<oss_bucket>/ |
| fs.oss.endpoint | OSS Bucket的endpoint信息,公网或私网地址皆可。 |
| accessModes | 表示Dataset的访问模式。 |
| replicas | 表示创建JindoFS集群的Worker数量。 |
| mediumtype | 表示缓存类型。定义创建JindoRuntime模板样例时,JindoFS暂时支持HDD/SSD/MEM中的其中一种缓存类型。 |
| path | 表示存储路径,暂时只支持单个路径。当选择MEM做缓存时,需指定一个本地路径来存储Log等文件。 |
| quota | 表示缓存最大容量,单位GB。缓存容量可以根据UFS数据大小自行配置。 |
| high | 表示存储容量上限大小。 |
| low | 表示存储容量下限大小。 |
| fuse.args | 表示可选的fuse客户端挂载参数。通常与Dataset的访问模式搭配使用。当Dataset访问模式为ReadOnlyMany时,我们开启kernel_cache以利用内核缓存优化读性能。此时我们可以设置attr_timeout(文件属性缓存保留时间)、entry_timeout(文件名读取缓存保留时间)超时时间、negative_timeout(文件名读取失败缓存保留时间),默认均为7200s。当Dataset访问模式为ReadWriteMany时,我们建议使用默认配置。此时参数如下:- -oauto_cache- -oattr_timeout=0- -oentry_timeout=0- -onegative_timeout=0使用auto_cache以确保如果文件大小或修改时间发生变化,缓存就会失效。同时将超时时间都设置为0。 |
- 执行以下命令,创建 JindoRuntime 和 Dataset。
$ kubectl create -f dataset.yaml
- 执行以下命令,查看 Dataset 的部署情况。
$ kubectl get dataset
预期输出:
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
demo 588.90KiB 0.00B 10.00GiB 0.0% Bound 2m7s
步骤三:创建支持定时运行的 Dataload
- 使用以下 YAML 文件样例创建一个名为 dataload.yaml 的文件。
apiVersion: data.fluid.io/v1alpha1
kind: DataLoad
metadata:name: cron-dataload
spec:dataset:name: demonamespace: defaultpolicy: Cronschedule: "*/2 * * * *" # Run every 2 min
相关参数解释如下表所示:
| 参数 | 说明 |
|---|---|
| dataset | 表示执行dataload的数据集name和namespace。 |
| policy | 表示执行策略,目前支持Once和Cron。这里创建定时dataload任务。 |
| shcedule | 表示触发dataload的策略。 |
scheule 使用以下 cron 格式:
# ┌───────────── 分钟 (0 - 59)
# │ ┌───────────── 小时 (0 - 23)
# │ │ ┌───────────── 月的某天 (1 - 31)
# │ │ │ ┌───────────── 月份 (1 - 12)
# │ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周一;在某些系统上,7 也是星期日)
# │ │ │ │ │ 或者是 sun,mon,tue,web,thu,fri,sat
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
同时,cron 支持下列运算符:
- 逗号(,)表示列举,例如:1,3,4,7 * * * * 表示在每小时的 1、3、4、7 分时执行Dataload。
- 连词符(-)表示范围,例如:1-6 * * * * 表示每小时的 1 到 6 分钟内,每分钟都执行一次。
- 星号(*)代表任何可能的值。例如:在“小时域”里的星号等于是“每一个小时”。
- 百分号(%) 表示“每"。例如:*%10 * * * * 表示每 10 分钟执行一次。
- 斜杠 (/) 用于描述范围的增量。例如:*/2 * * * *表示每 2 分钟执行一次。
您也可以在这里查看更多信息。
Dataload 相关高级配置请参考如下配置文件:
apiVersion: data.fluid.io/v1alpha1
kind: DataLoad
metadata:name: cron-dataload
spec:dataset:name: demonamespace: defaultpolicy: Cron # including Once, Cronschedule: * * * * * # only set when policy is cronloadMetadata: truetarget:- path: <path1>replicas: 1- path: <path2>replicas: 2
相关参数解释如下表所示:
| 参数 | 说明 |
|---|---|
| policy | 表示dataload执行策略,包括[Once, Cron]。 |
| schedule | 表示cron使用的计划,只有policy为Cron时有效。 |
| loadMetadata | 表示在dataload前是否同步元数据。 |
| target | 表示dataload的目标,支持指定多个目标。 |
| path | 表示执行dataload的路径。 |
| replicas | 表示缓存的副本数。 |
- 执行以下命令创建 Dataload。
$ kubectl apply -f dataload.yaml
- 执行以下命令查看 Dataload 状态。
$ kubectl get dataload
预期输出:
NAME DATASET PHASE AGE DURATION
cron-dataload demo Complete 3m51s 2m12s
- 等待 Dataload 状态为 Complete 后,执行以下命令查看当前 dataset 状态。
$ kubectl get dataset
预期输出:
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
demo 588.90KiB 588.90KiB 10.00GiB 100.0% Bound 5m50s
可以看出 oss 中文件已经全部加载到缓存。
步骤四:创建应用容器访问 OSS 中的数据
本文以创建一个应用容器访问上述文件以查看定时 Dataload 效果。
- 使用以下 YAML 文件样例,创建名为 app.yaml 的文件。
apiVersion: v1
kind: Pod
metadata:name: nginx
spec:containers:- name: nginximage: nginxvolumeMounts:- mountPath: /dataname: demo-volvolumes:- name: demo-volpersistentVolumeClaim:claimName: demo
- 执行以下命令创建应用容器。
$ kubectl create -f app.yaml
- 等待应用容器就绪,执行以下命令查看 OSS 中的数据:
$ kubectl exec -it nginx -- ls -lh /data
预期输出:
total 589K
-rwxrwxr-x 1 root root 589K Jul 31 04:20 RELEASENOTES.md
- 为了验证 dataload 定时更新底层文件效果,我们在定时 dataload 触发前修改 RELEASENOTES.md 内容并重新上传。
$ echo "hello, crondataload." >> RELEASENOTES.md
重新上传该文件到 oss。
$ ossutil cp RELEASENOTES.md oss://<bucket-name>/<path>/RELEASENOTES.md
- 等待 dataload 任务触发。Dataload 任务完成时,执行以下命令查看 Dataload 作业运行情况:
$ kubectl describe dataload cron-dataload
预期输出:
...
Status:Conditions:Last Probe Time: 2023-07-31T04:30:07ZLast Transition Time: 2023-07-31T04:30:07ZStatus: TrueType: CompleteDuration: 5m54sLast Schedule Time: 2023-07-31T04:30:00ZLast Successful Time: 2023-07-31T04:30:07ZPhase: Complete
...
其中,Status 中 Last Schedule Time 为上一次 dataload 作业的调度时间,Last Successful Time 为上一次 dataload 作业的完成时间。
此时,可以执行以下命令查看当前 Dataset 状态:
$ kubectl get dataset
预期输出:
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
demo 588.90KiB 1.15MiB 10.00GiB 100.0% Bound 10m
可以看出更新后的文件也已经加载到了缓存。
- 执行以下命令在应用容器中查看更新后的文件:
$ kubectl exec -it nginx -- tail /data/RELEASENOTES.md
预期输出:
\<name\>hbase.config.read.zookeeper.config\</name\>\<value\>true\</value\>\<description\>Set to true to allow HBaseConfiguration to read thezoo.cfg file for ZooKeeper properties. Switching this to trueis not recommended, since the functionality of reading ZKproperties from a zoo.cfg file has been deprecated.\</description\>
\</property\>
hello, crondataload.
从最后一行可以看出,应用容器已经可以访问更新后的文件。
环境清理
当您不再使用该数据加速功能时,需要清理环境。
执行以下命令,删除 JindoRuntime 和应用容器。
$ kubectl delete -f app.yaml$ kubectl delete -f dataset.yaml
总结
关于基于 ACK Fluid 的混合云优化数据访问的讨论先到这里告一段落,阿里云容器服务团队会和用户在这个场景下持续的迭代和优化,随着实践不断深入,这个系列也会持续更新。
相关链接:
[1] 创建 ACK Pro 版集群
https://help.aliyun.com/document_detail/176833.html#task-skz-qwk-qfb
[2] 安装云原生 AI 套件
https://help.aliyun.com/zh/ack/cloud-native-ai-suite/user-guide/deploy-the-cloud-native-ai-suite#task-2038811
[3] 容器服务管理控制台
https://account.aliyun.com/login/login.htm?oauth_callback=https%3A%2F%2Fcs.console.aliyun.com%2F
[4] 通过 kubectl 工具连接集群
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/obtain-the-kubeconfig-file-of-a-cluster-and-use-kubectl-to-connect-to-the-cluster#task-ubf-lhg-vdb
[5] 安装 ossutil
https://help.aliyun.com/zh/oss/developer-reference/install-ossutil#concept-303829
相关文章:
基于 ACK Fluid 的混合云优化数据访问(五):自动化跨区域中心数据分发
作者:车漾 前文回顾: 本系列将介绍如何基于 ACK Fluid 支持和优化混合云的数据访问场景,相关文章请参考: -基于 ACK Fluid 的混合云优化数据访问(一):场景与架构 -基于 ACK Fluid 的混合云优…...
sentinel的启动与运行
首先我们github下载sentinel Releases alibaba/Sentinel (github.com) 下载好了后输入命令让它运行即可,使用cmd窗口输入一下命令即可 java -Dserver.port8089 -jar sentinel-dashboard-1.8.6.jar 账号密码默认都是sentinel 启动成功后登录进去效果如下...

模拟量采集无线WiFi网络接口TCP Server, UDP, MQTT
● 4-20mA信号转换成标准Modbus TCP协议 ● 支持TCP Server, UDP, MQTT等通讯协议 ● 内置网页功能,可以通过网页查询数据 ● 宽电源供电范围:8 ~ 32VDC ● 可靠性高,编程方便,易于应用 ● 标准DIN35导轨安装,方便…...
五、OSPF动态路由实验
拓扑图: 基本ip的配置已经配置好了,接下来对两台路由器配置ospf协议,两台PC进行跨网段通讯 R1与R2构成单区域OSPF区域0,首先对R1进行配置 首先进入ospf 默认进程1,router id省略空缺,之后进入area 0区域&…...

系统架构设计:16 论软件开发过程RUP及其应用
目录 一 统一过程RUP 1 典型特点 2 四个阶段 (1)构思阶段(初始阶段/初启阶段)...
Gralloc ION DMABUF in Camera Display
目录 Background knowledge Introduction ia pa va and memory addressing Memory Addressing Page Frame Management Memory area management DMA IOVA and IOMMU Introduce DMABUF What is DMABUF DMABUF 关键概念 DMABUF APIS –The Exporter DMABUF APIS –The…...

【LVS】lvs的四种模式的区别是什么?
LVS中的DR模式、NAT模式、TUN模式和FANT模式是四种不同的负载均衡模式,它们之间的主要区别在于数据包转发方式和网络地址转换。 DR模式(Direct Routing):此模式通过改写请求报文的目标MAC地址,将请求发给真实服务器&a…...
)
Android原生实现控件点击弹起效果方案(API28及以上)
之前在实现控件阴影时有提到过,阴影效果的实现采用的是Android原生的View的属性,拔高Z轴。Z轴会让View产生阴影的效果。 Zelevation translationZ 拔高Z轴可以通过控制elevation和translationZ。 我们之前是通过elevation来单纯的控制Z轴;而…...

【数据结构-队列 二】【单调队列】滑动窗口最大值
废话不多说,喊一句号子鼓励自己:程序员永不失业,程序员走向架构!本篇Blog的主题是【单调队列】,使用【队列】这个基本的数据结构来实现,这个高频题的站点是:CodeTop,筛选条件为&…...

如何设置CentOS系统以禁用不必要的网络端口和服务?
要禁用CentOS系统中的不必要的网络端口和服务,可以按照以下步骤进行操作: 1. 查看当前正在运行的服务和端口:使用以下命令可以查看正在运行的服务和对应的端口号。 sudo netstat -tuln 2. 停用不必要的服务:根据netstat命令的输…...

【IDEA项目个别类爆红,但是项目可以正常运行】
打开项目时发现idea个别类爆红,但是项目可以正常运行 问题原因:Idea本身的问题,可能是其缓存问题,导致爆红 解决方案:重置Idea 很多时候排查不出代码问题,就尝试一下此操作。 选择目录:File–>Invalida…...
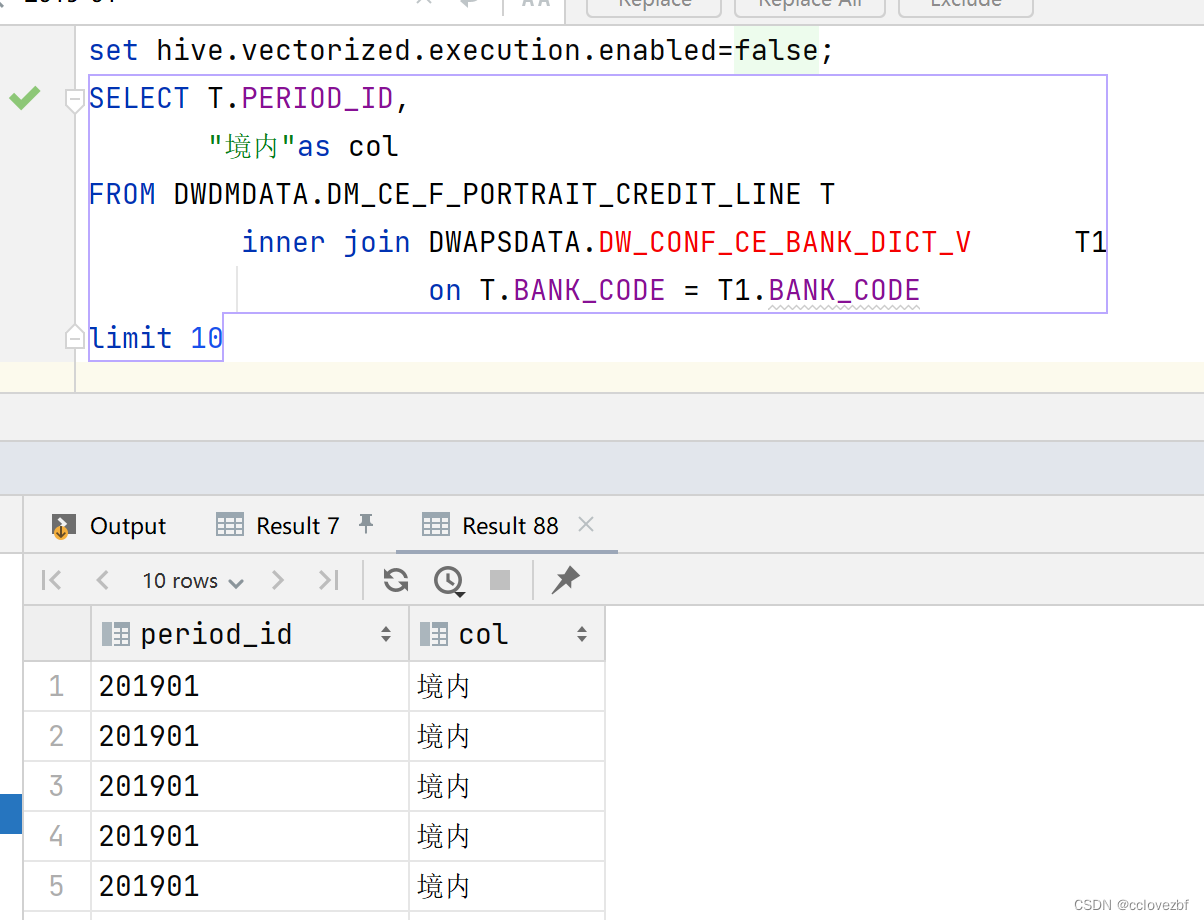
hive 之select 中文乱码
此处的中文乱码和mysql的库表 编码 latin utf 无关。 直接上案例。 有时候我们需要自定义一列,有时是汉字有时是字母,结果遇到这种情况了。 说实话看到这真是糟心。这谁受得了。 单独select 没有任何问题。 这是怎么回事呢? 经过一番检查&…...

优化|优化处理可再生希尔伯特核空间的非参数回归中的协变量偏移
原文:Optimally tackling covariate shift in RKHS-based nonparametric regression. The Annals of Statistics, 51(2), pp.738-761, 2023. 原文作者:Cong Ma, Reese Pathak, Martin J. Wainwright 论文解读者:赵进 编者按: …...

Netty深入浅出Java网络编程学习笔记(一) Netty入门篇
目录 一、概述 1、什么是Netty 2、Netty的优势 二、入门案例 1、服务器端代码 2、客户端代码 3、运行流程 组件解释 三、组件 1、EventLoop 处理普通与定时任务 关闭 EventLoopGroup 处理IO任务 服务器代码 客户端代码 分工细化 划分Boss 和Work 增加自定义EventLoopGroup 切换…...
自动化产线集控系统(西门子CNC 840D/840DSL远程控制)
1.1项目背景 RQQ/VF120机组目前为1人操作3台机床,需在机台旁监控。为了改善人员在班中劳动强度非常大的现状,调整好每台机床的节奏,以保证机床的最少的等待时间。本项目旨在通过远程监视设备运行过程关键参数,操作人员人员可远程监…...
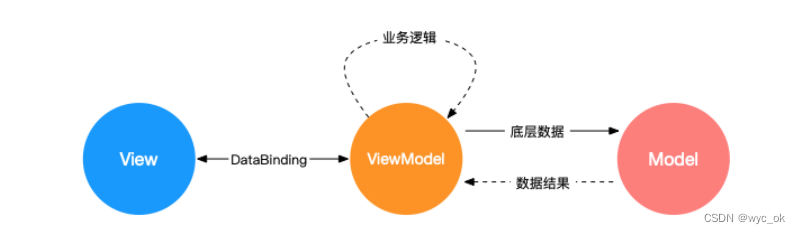
MVVM 与 MVC区别和应用场景?
MVVM 和 MVC 1. MVC2. MVVM 1. MVC MVC 是 Model View Controller 的缩写 Model:模型层,是应用程序中用于处理应用程序数据逻辑的部分。通常模型对象负责在数据库中存取数据。View:视图层,用户界面渲染逻辑,通常视图…...

Linux开发-Ubuntu软件源工具
开发&验证环境: 操作系统:ubuntu 20.04 软件源:http://archive.ubuntu.com/ubuntu 开发工具 sudo apt install vim sudo apt install git# gnu工具链 sudo apt install gcc sudo apt install g sudo apt install gdb# llvm工具链 sudo …...
环境下载地址
1. DOTNET环境下载 适用于 Visual Studio 的 .NET SDK 下载 (microsoft.com)https://dotnet.microsoft.com/zh-cn/download/visual-studio-sdks...
)
E. Block Sequence-Codeforces Round 903 (Div. 3)
E. Block Sequence dp题,设dp[i]表示i~n之间的数,需要最小删除数量 那么每一位数有两种情况,设数a[i]: 1.被删除:dp[i]dp[i1]1,这一位等于上一位的加一。 2.被保留:dp[i]min(dp[i],dp[ia[i]1]); #include<iostream…...
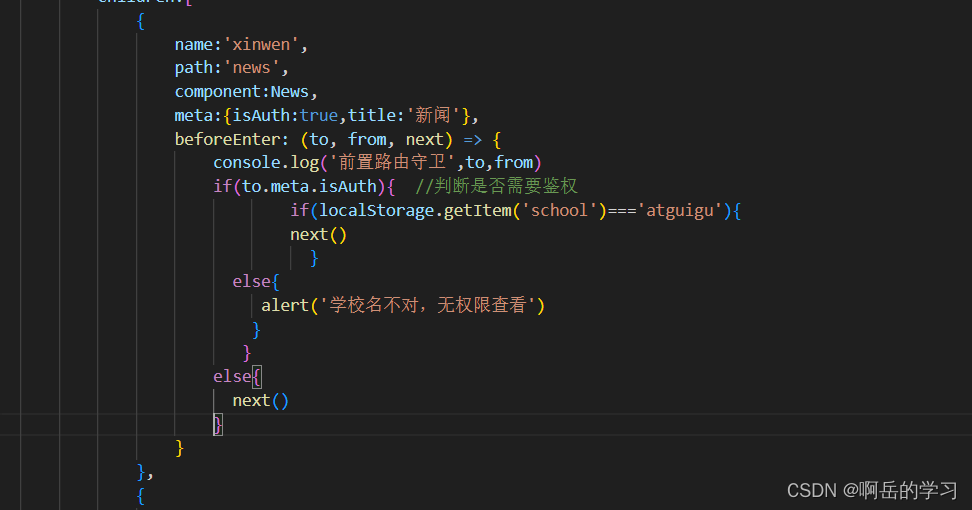
路由router
什么是路由? 一个路由就是一组映射关系(key - value)key 为路径,value 可能是 function 或 component 2、安装\引入\基础使用 只有vue-router3,才能应用于vue2;vue-router4可以应用于vue3中 这里我们安装vue-router3…...

GBFR Logs:游戏数据采集与实时分析引擎的架构深度解析
GBFR Logs:游戏数据采集与实时分析引擎的架构深度解析 【免费下载链接】gbfr-logs GBFR Logs lets you track damage statistics with a nice overlay DPS meter for Granblue Fantasy: Relink. 项目地址: https://gitcode.com/gh_mirrors/gb/gbfr-logs 在游…...

Windows 环境 OpenClaw 部署详解|从安装到使用全流程
OpenClaw(小龙虾)Windows 一键部署教程|10 分钟搭建自动化数字员工 前言 OpenClaw(俗称小龙虾)是 2026 年热门的开源 AI 智能体,GitHub 星标突破 28 万,主打本地运行、低门槛、自动化执行。本…...

ESP32 Arduino核心开发终极指南:构建专业级物联网控制系统
ESP32 Arduino核心开发终极指南:构建专业级物联网控制系统 【免费下载链接】arduino-esp32 Arduino core for the ESP32 family of SoCs 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 还在为物联网项目开发中的硬件兼容性、开发环境复杂…...

NCM解密终极指南:3步解锁网易云音乐加密文件
NCM解密终极指南:3步解锁网易云音乐加密文件 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经在网易云音乐下载了心爱的歌曲,却发现只能在官方客户端播放,无法在其他设备或播放器上欣赏&…...

CSL编辑器技术深度解析:基于HTML5的学术引用样式编辑全栈指南
CSL编辑器技术深度解析:基于HTML5的学术引用样式编辑全栈指南 【免费下载链接】csl-editor cslEditorLib - A HTML 5 library for searching and editing CSL styles 项目地址: https://gitcode.com/gh_mirrors/csl/csl-editor CSL编辑器是一个基于HTML5技术…...

Windows MSI文件提取终极指南:lessmsi替代方案轻松提取安装包内容
Windows MSI文件提取终极指南:lessmsi替代方案轻松提取安装包内容 【免费下载链接】lessmsi A tool to view and extract the contents of an Windows Installer (.msi) file. 项目地址: https://gitcode.com/gh_mirrors/le/lessmsi 你是否曾经为了从MSI安装…...

如何快速获取网易云和QQ音乐的精准LRC歌词?这款免费工具帮你一键搞定!
如何快速获取网易云和QQ音乐的精准LRC歌词?这款免费工具帮你一键搞定! 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为音乐播放器缺少歌词而…...

【亲测免费】【免费下载】 探索视觉新边界:RexVision视觉框架深度解析
探索视觉新边界:RexVision视觉框架深度解析 【下载地址】RexVision视觉框架下载仓库 本仓库提供了一个名为“RexVision视觉框架”的资源文件下载。该框架是一个视觉处理相关的工具或库,用户只需将文件放置在D盘的根目录下即可进行编译和使用 项目地址:…...

长期使用Taotoken聚合API在服务稳定性方面的体验分享
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合API在服务稳定性方面的体验分享 作为一家长期依赖大模型能力进行产品开发的团队,我们在过去数月里…...

词达人自动化助手:终极指南让英语词汇学习效率提升10倍
词达人自动化助手:终极指南让英语词汇学习效率提升10倍 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 厌倦了在词达人平台上花费数小时完成重复的词汇…...