Apache Lucene 7.0 - 索引文件格式
Apache Lucene 7.0 - 索引文件格式
文章目录
- Apache Lucene 7.0 - 索引文件格式
- 介绍
- 定义
- 反向索引
- 字段类型
- 段
- 文档数量
- 索引结构概述
- 文件命名
- 文件扩展名摘要
- 锁文件
原文地址
介绍
这个文档定义了在这个版本的Lucene中使用的索引文件格式。如果您使用的是不同版本的Lucene,请查询对应版本的文档。
本文档试图提供Apache Lucene文件格式的高级定义。
定义
Lucene的基本概念是索引、文档、字段和术语(分词后的检索词)。
索引包含一系列文档。
文档是一系列字段。
- 字段是一个命名的术语序列。
- 术语是一个字节序列。
- 两个不同字段中的相同字节序列被认为是不同的术语。因此,术语被表示为一对:命名字段的字符串和字段内的字节。
反向索引
索引存储有关术语的统计信息,以便使基于术语的搜索更有效。Lucene的索引属于被称为倒排索引的索引族。这是因为对于一个术语,它可以列出包含它的文档。这与文档列出术语的自然关系相反。
字段类型
在Lucene中,字段可以被存储,在这种情况下,它们的文本以一种非反向的方式逐字存储在索引中。倒置的字段称为索引。一个字段可以被存储和索引。
字段的文本可以被标记成要索引的术语,或者字段的文本可以按字面意思用作要索引的术语。大多数字段都是标记化的,但有时对某些标识符字段进行逐字索引是有用的。
有关Field的更多信息,请参阅Field java文档。
段
Lucene索引可以由多个子索引或段组成。每个段都是一个完全独立的索引,可以单独搜索。指数的演变:
为新添加的文档创建新的段。
- 合并现有段。
- 搜索可能涉及多个段和多个索引,每个索引可能由一组段组成。
文档数量
在内部,Lucene通过一个整数文档号来引用文档。添加到索引中的第一个文档编号为0,随后添加的每个文档的编号都比前一个文档大1。
注意文档的编号可能会改变,所以在Lucene之外存储这些编号时要小心。在以下情况下,数字可能会发生变化:
存储在每个段中的数字仅在该段内是唯一的,并且必须在将其用于更大的上下文中之前进行转换。标准技术是根据每个段中使用的数字范围为每个段分配一个值范围。要将文档号从段转换为外部值,需要添加段的基本文档号。为了将外部值转换回特定于段的值,段由外部值所在的范围标识,并减去段的基值。例如,可以组合两个5个文档段,使第一个段的基值为0,第二个段的基值为5。第二部分的文档3的外部值为8。
当文档被删除时,在编号中会产生空白。随着索引在合并过程中的演变,这些最终会被删除。在合并段时删除已删除的文档。因此,新合并的段在编号上没有间隙。
索引结构概述
每个段索引维护如下内容:
Segment info.它包含关于一个段的元数据,例如文档的数量,它使用的文件。Field names. 它包含索引中使用的字段名称集。Stored Field values. T对于每个文档,这包含一个属性值对列表,其中属性是字段名。它们用于存储关于文档的辅助信息,例如文档的标题、url或访问数据库的标识符。存储的字段集是在搜索时为每个命中返回的内容。这是由文档号输入的。Term dictionary. 包含所有文档的所有索引字段中使用的所有术语的字典。字典还包含包含该术语的文档数量,以及指向该术语的频率和接近度数据的指针。Term Frequency data. 对于字典中的每个术语,包含该术语的所有文档的编号,以及该术语在该文档中出现的频率,除非省略频率(IndexOptions.DOCS_ONLY)Term Proximity data. 对于字典中的每个术语,表示该术语在每个文档中出现的位置。请注意,如果所有文档中的所有字段都省略位置数据,则不存在此方法。Normalization factors. 对于每个文档中的每个字段,存储一个值,该值乘以该字段的命中分数。Term Vectors. 对于每个文档中的每个字段,都可以存储术语向量(有时也称为文档向量)。术语向量由术语文本和术语频率组成。要在索引中添加术语向量,请参见Field构造函数Per-document values.与存储值一样,这些值也是按文档编号键入的,但通常是为了快速访问而加载到主存 储器中。存储值一般用于搜索结果的汇总,而每个文档值则适用于评分因子等。Live documents. 可选文件,说明哪些文件是实时文件。Point values. 可选的一对文件,记录维度索引字段,以实现快速数值范围过滤和大数值,如 BigInteger 和 BigDecimal(1D)以及地理形状交叉(2D、3D)。
文件命名
属于一个段的所有文件具有相同的名称,但扩展名不同。扩展名对应于下面描述的不同文件格式。当使用复合文件格式(小段的默认格式)时,这些文件(段信息文件、锁文件和删除文档文件除外)被折叠成一个.cfs文件(详细信息见下文)。
通常,索引中的所有段都存储在单个目录中,尽管这不是必需的。
文件名永远不会被重用。也就是说,当任何文件保存到目录时,它被赋予一个从未使用过的文件名。这是使用简单的生成方法实现的。例如,第一个片段文件是segments_1,然后是segments_2,等等。生成是一个以字母数字(基数36)形式表示的连续长整数。
文件扩展名摘要
下表总结了 Lucene 中文件的名称和扩展名:
| Name | Extension | Brief Description |
|---|---|---|
Segments File | segments_N | 存储有关提交点的信息,N随着commit的次数增长而增长 |
| Lock File | write.lock | 写入锁文件,可防止多个 IndexWriters 向同一文件写入。 |
Segment Info | .si | 记录对应段的元数据 |
Compound File | .cfs, .cfe | 合并当前段内所有文件生产合并文件,.cfe扩展后缀的合并文件用于记 录合并之前段对应的所有文件的元信息,.cfs扩展后缀的合并文件存储的 是合并前段内所有文件的实际数据 |
Fields | .fnm | 记录index对应所有字段的信息 |
Field Index | .fdx | doc通过docId来标识被存储在.fdt的文件中,方便快速的查询到docid对 应的数据需要对doc数据做相关的索引位置记录 |
Field Data | .fdt | 存储doc数据的文件,只有设置Field.Store.YES的field对应的数据才会 被存储在该文件中 |
Term Dictionary | .tim | 术语词典,记录术语信息 |
Term Index | .tip | term被记录存储在.tim中,当term数据很大时需要对term进行索引方便 快速定位到对应的term |
Frequencies | .doc | 记录包含每个术语的文档列表以及频率 |
Positions | .pos | 记录术语在索引中出现的位置 |
Payloads | .pay | 记录额外的每个位置元数据信息,如字符偏移和用户有效载荷 |
Norms | .nvd, .nvm | nvd保存索引文档字段的加权因子的数据,搜索时计算相关性的一个系数,nvm保存索引文档字段加权因子的元数据 |
Per-Document Values | .dvd, .dvm | dvd保存索引文档的评分因子,也用于存储docValues类型的字段数据,即 列存储(正向索引),dvm保存索引文档的评分因子的元数据 |
Term Vector Index | .tvx | 将偏移量存入文件数据文件 |
Term Vector Data | .tvd | 包含术语向量数据。 |
Live Documents | .liv | 有关实时文件的信息 |
Point values | .dii, .dim | 保存索引点(如果有) |
锁文件
默认存储在索引目录中的写锁名为“write.lock”。如果锁目录与索引目录不同,那么写锁将被命名为“XXXX-write”。其中XXXX是从索引目录的完整路径派生的唯一前缀。当这个文件存在时,写程序当前正在修改索引(添加或删除文档)。这个锁文件确保一次只有一个写入器在修改索引。
相关文章:

Apache Lucene 7.0 - 索引文件格式
Apache Lucene 7.0 - 索引文件格式 文章目录 Apache Lucene 7.0 - 索引文件格式介绍定义反向索引字段类型段文档数量索引结构概述文件命名文件扩展名摘要锁文件 原文地址 介绍 这个文档定义了在这个版本的Lucene中使用的索引文件格式。如果您使用的是不同版本的Lucene…...
GEE:使用中文做变量和函数名写GEE代码
作者:CSDN _养乐多_ 啊?最近在编写GEE代码的时候,无意中发现 JavaScript 已经能够支持中文字符作为变量名和函数名,这个发现让我感到非常兴奋。这意味着以后在编程过程中,我可以更自由地融入中文元素,不再…...
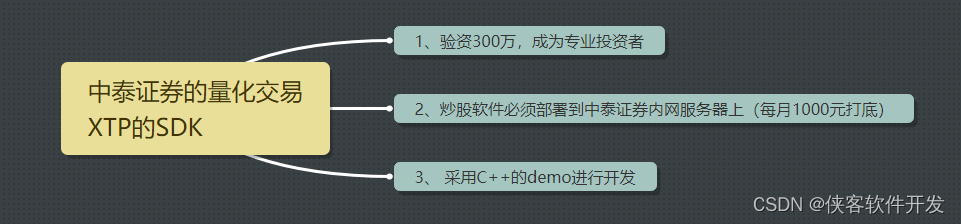
针对量化交易SDK的XTP的初步摸索
这东西只要是调用API实现自动交易股票的,就不可能免费的接口。 并且用这些接口实现自动交易还得 归证券公司监管。比如 xtp出自 中泰证券,那么如果用xtp实现自动交易股票的软件,具体操作实盘的时候 不能跑再自己的电脑上,必须跑在…...
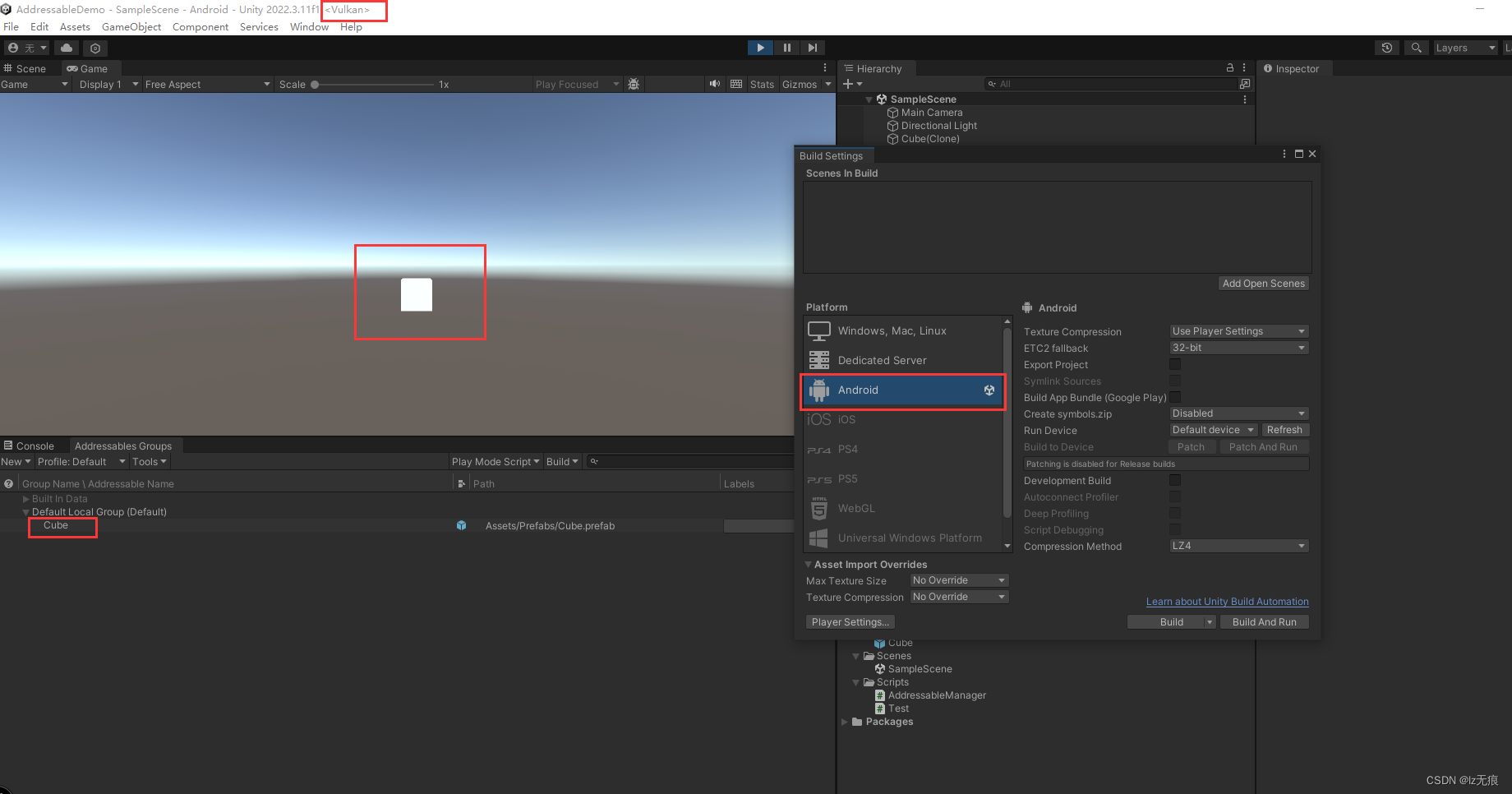
Unity编辑器从PC平台切换到Android平台下 Addressable 加载模型出现粉红色,类似于材质丢失的问题
Unity编辑器在PC平台下使用Addressable加载打包好的Cube,运行发现能正常显示。 而在切换到Android平台下,使用Addressable时加载AB包,生成Cube对象时,Cube模型呈现粉红色,出现类似材质丢失的问题。如下图所示。 这是…...
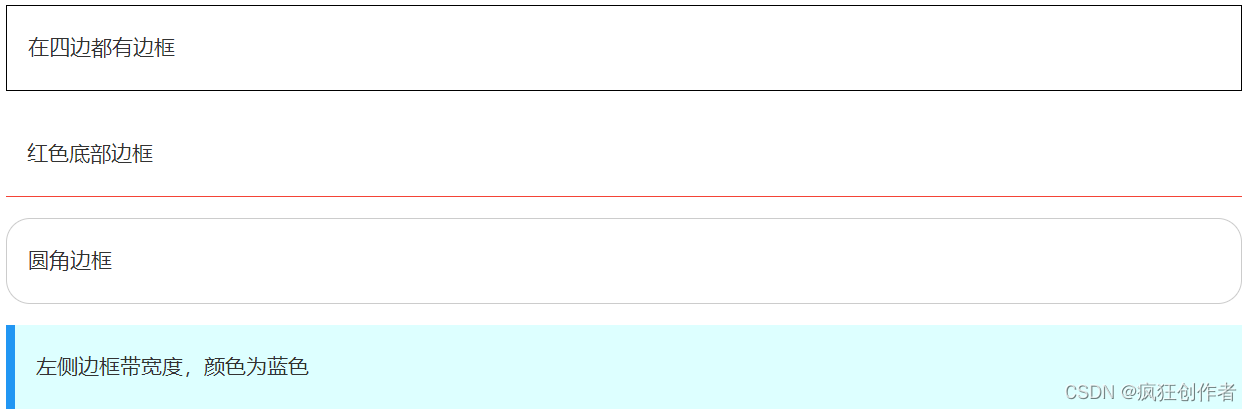
CSS 边框
CSS 边框属性 CSS边框属性允许你指定一个元素边框的样式和颜色。 在四边都有边框 红色底部边框 圆角边框 左侧边框带宽度,颜色为蓝色 边框样式 边框样式属性指定要显示什么样的边界。 border-style属性用来定义边框的样式 border-style 值: none: 默认无边框…...
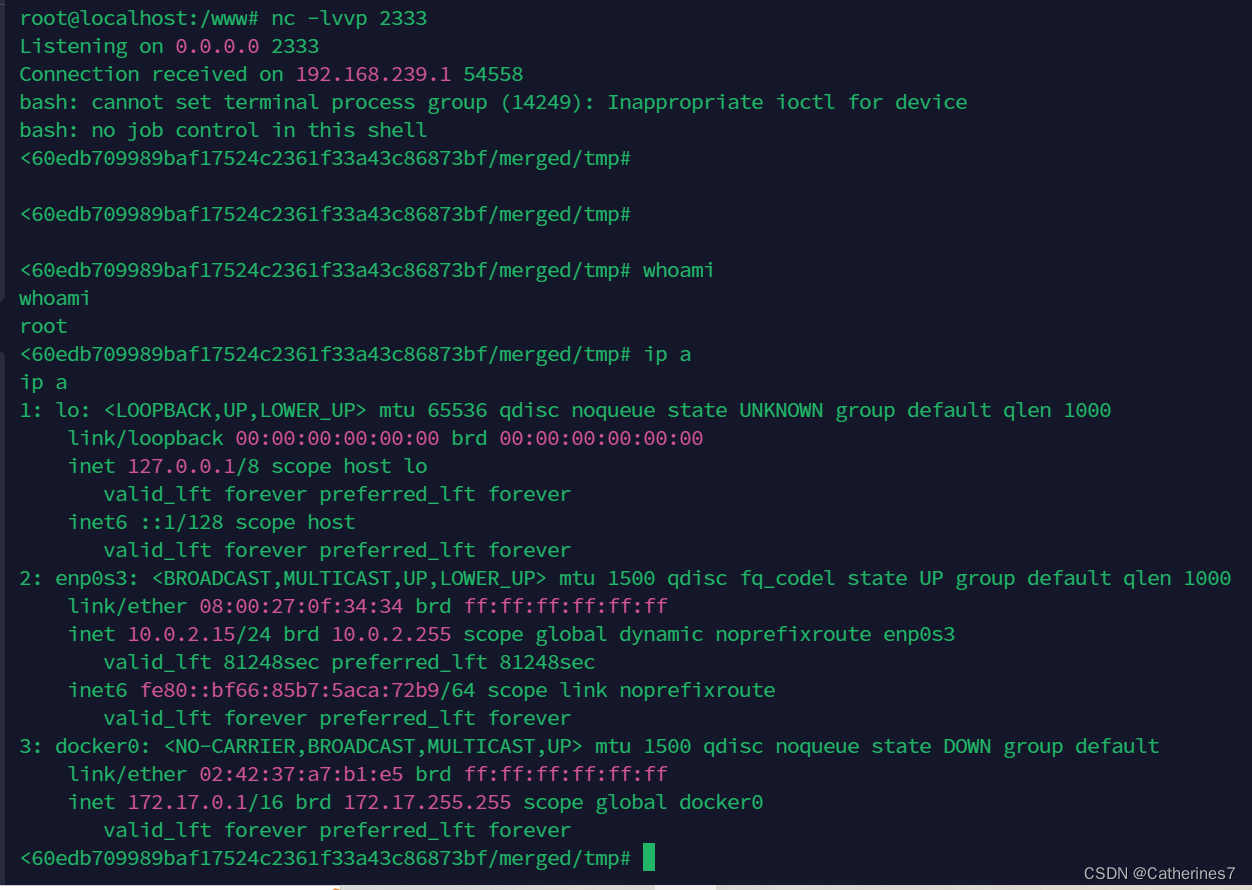
Docker逃逸---CVE-2020-15257浅析
一、产生原因 在版本1.3.9之前和1.4.0~1.4.2的Containerd中,由于在网络模式为host的情况下,容器与宿主机共享一套Network namespace ,此时containerd-shim API暴露给了用户,而且访问控制仅仅验证了连接进程的有效UID为0ÿ…...

Python学习 day03(注意事项)
数据容器 列表...

vue中的生命周期有什么,怎么用
Vue.js 的生命周期(lifecycle)是指 Vue 实例从创建到销毁的整个过程。Vue.js 常用的生命周期包括: beforeCreate:在实例被创建之前调用,此时组件的数据观测和事件机制都未被初始化。created:在实例创建完成…...
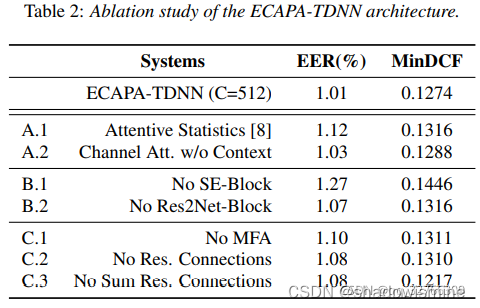
论文阅读:ECAPA-TDNN
1. 提出ECAPA-TDNN架构 TDNN本质上是1维卷积,而且常常是1维膨胀卷积,这样的一种结构非常注重context,也就是上下文信息,具体而言,是在frame-level的变换中,更多地利用相邻frame的信息,甚至跳过…...
【Unity】【VR】详解Oculus Integration输入
【背景】 以下内容适用于Oculus Integration开发VR场景,也就是OVR打头的Scripts,不适用于OpenXR开发场景,也就是XR打头Scripts。 【详解】 OVR的Input相对比较容易获取。重点在于区分不同动作机制的细节效果。 OVR Input的按键存在Button和RawButton两个系列 RawButton…...

vue axios封装
Vue.js 是一款前端框架,而 Axios 是一个基于 Promise 的 HTTP 请求客户端,通常用于发送 Ajax 请求。在Vue.js开发中,经常需要使用 Axios 来进行 HTTP 数据请求,为了更好的维护和使用 Axios,我们可以对其进行封装。下面…...

oracle、mysql、postgresql数据库的几种表关联方法
简介 在数据开发过程中,常常需要判断几个表直接的数据包含关系,便需要使用到一些特定的关键词进行处理。在数据库中常见的几种关联关系,本文以oracle、mysql、postgresql三种做演示 创建测试数据 oracle -- 创建表 p1 CREATE TABLE p1 (tx…...

什么是UML UML入门到放弃系列
1.定义 UML-Unified Modeling Language 统一建模语言,又称标准建模语言。是用来对软件密集系统进行可视化建模的一种语言。 2.UML的三个级别 《UML精粹》一书中把这三个级别称为概念级、规格说明级和实现级。 2.1 概念级 概念级的图示和源代码之间没有很强的关联。…...
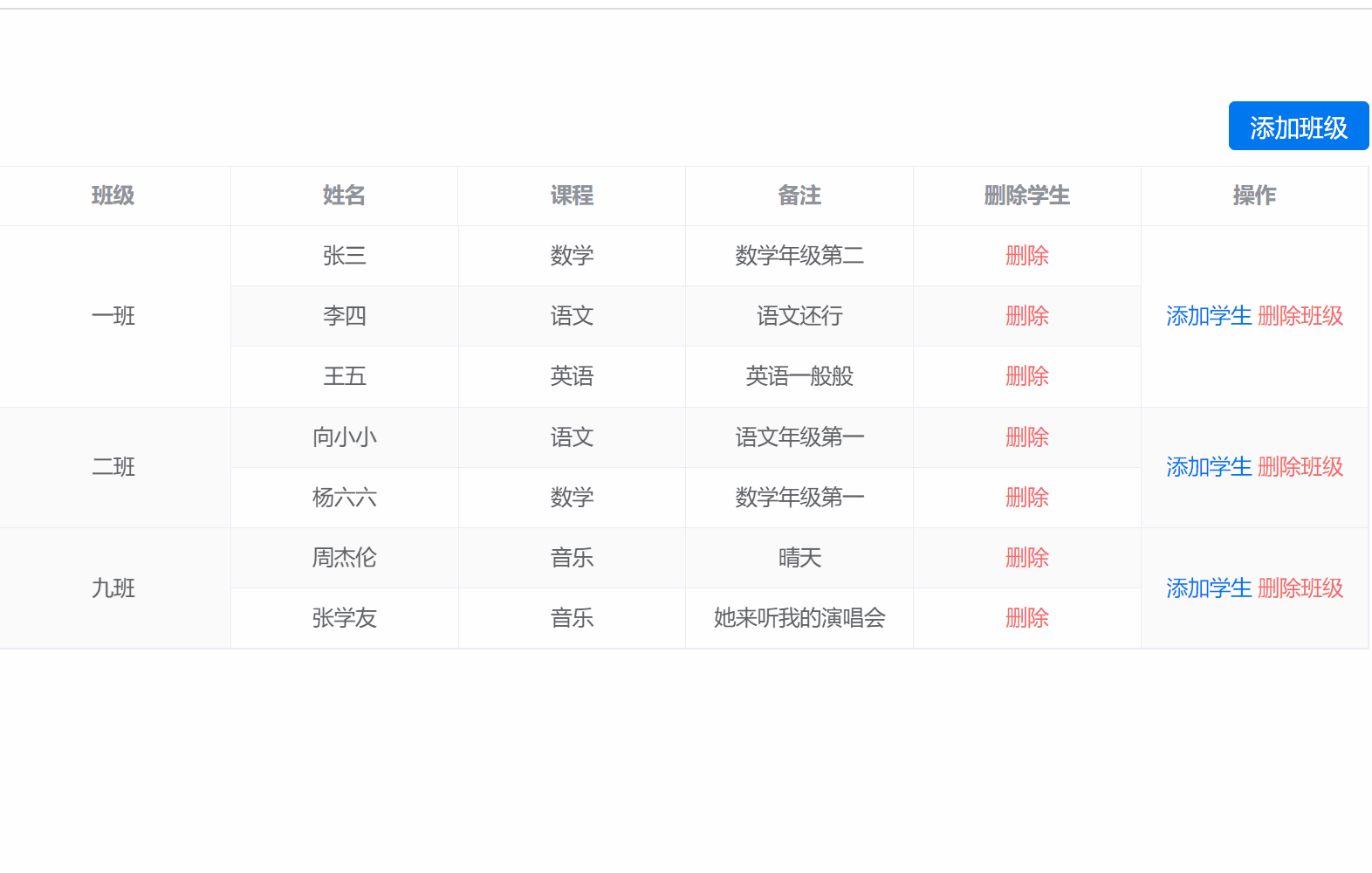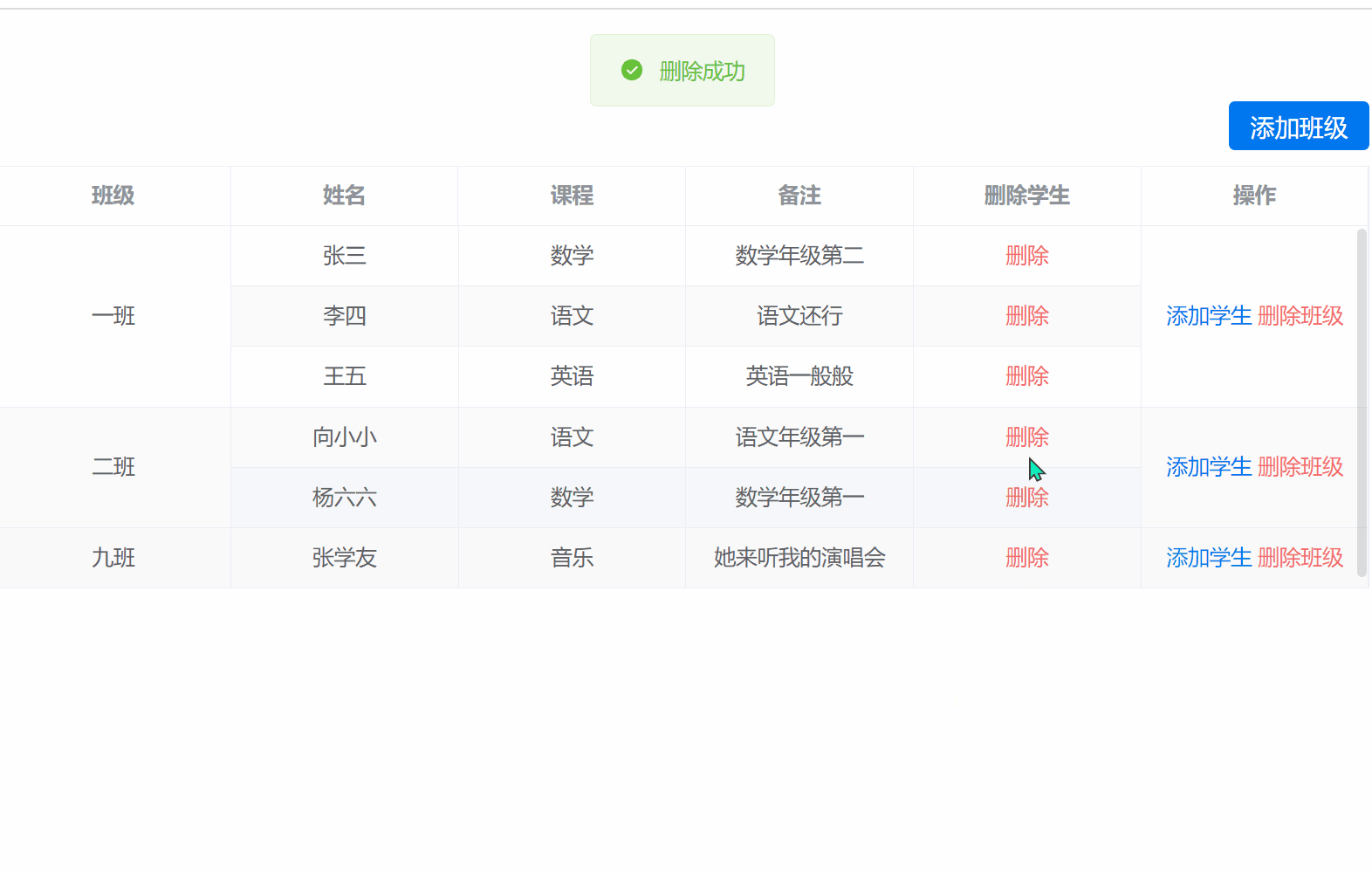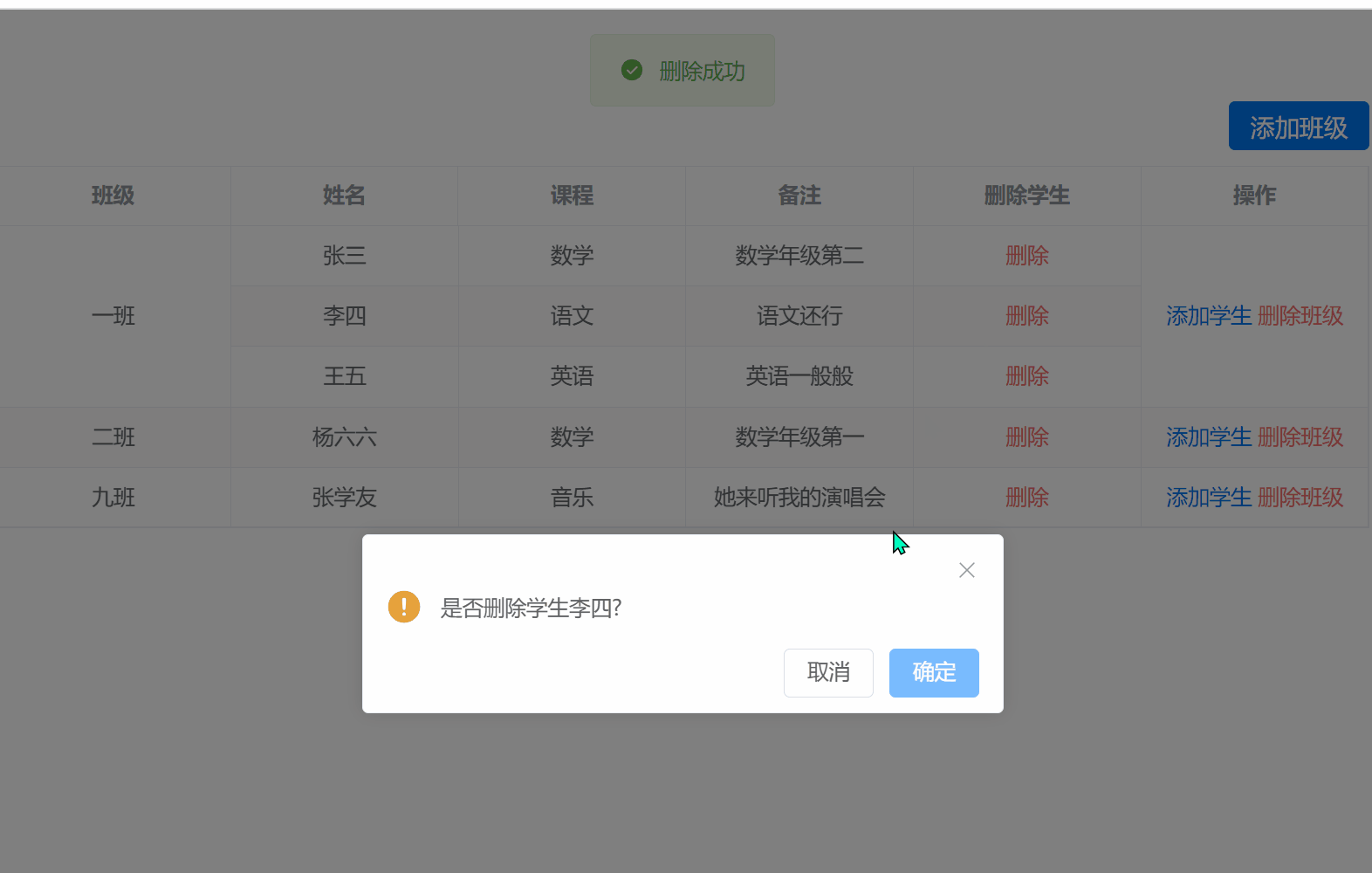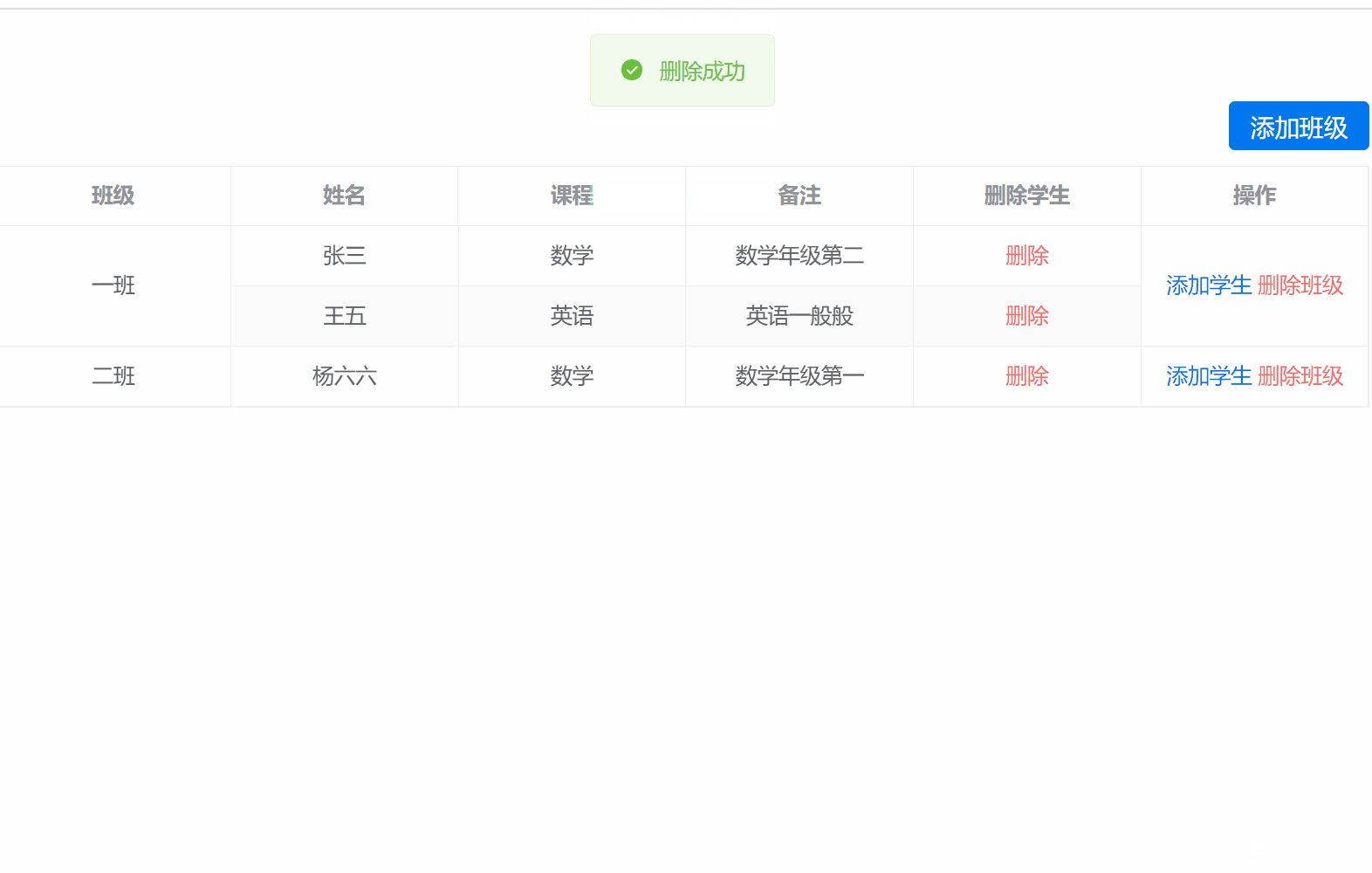
vue3 + element Plus实现表格根据关键字合并行,并实现行的增删改操作
根据关键字合并表格 1.实现初始化表格2.实现添加班级与学生的功能3.添加的弹窗4.删除班级5.删除学生 首先看最终实现的效果 1.实现初始化表格 这里主要用到的是表格的span-method这个方法 <template><div class"main-page"><div class"flex-en…...

c++视觉处理---直方图均衡化
直方图均衡化 直方图均衡化是一种用于增强图像对比度的图像处理技术。它通过重新分布图像的像素值,以使图像的直方图变得更均匀,从而提高图像的视觉质量。在OpenCV中,您可以使用 cv::equalizeHist 函数来执行直方图均衡化。以下是 cv::equal…...
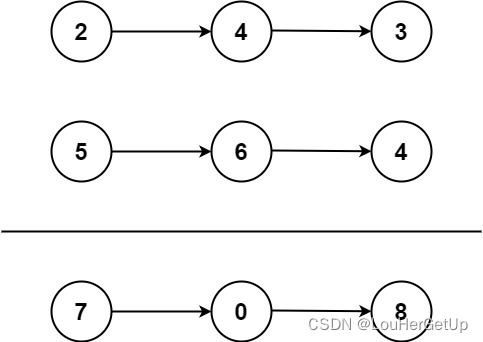
【LeetCode】2.两数相加
目录 1 题目2 答案2.1 我写的(不对)2.2 更正 3 问题 1 题目 给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。 请你将两个数相加,并以相同形式返…...

蜘蛛飞机大战
欢迎来到程序小院 蜘蛛飞机大战 玩法: 点击开始游戏,鼠标移动控制方向,可自由移动飞机打剁掉方飞机下落的子弹并打掉敌方飞机,三次生命,不同关卡不同奖励,快去闯关吧^^。开始游戏https://www.ormcc.com/pl…...
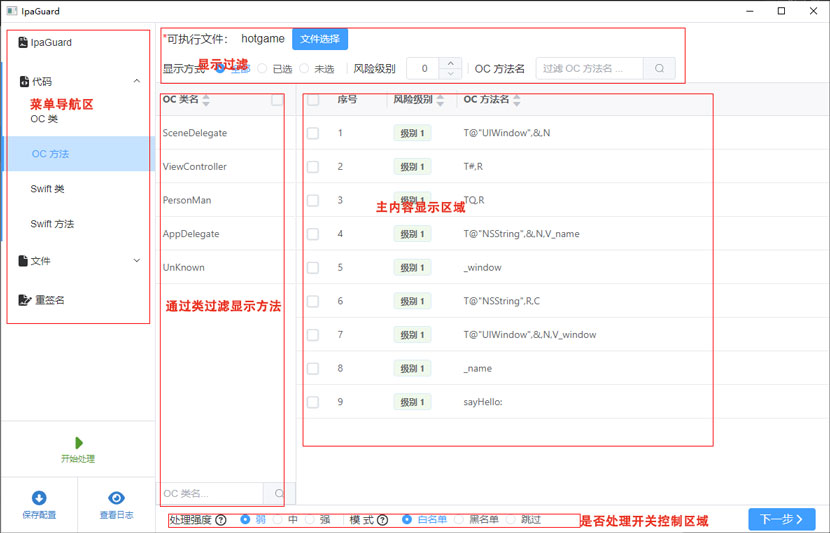
代码混淆界面介绍
代码混淆界面介绍 代码混淆功能包括oc,swift,类和函数设置区域。其他flutter,混合开发的最终都会转未oc活着swift的的二进制,所以没有其他语言的设置。 代码混淆功能分顶部的显示控制区域:显示方式,风险等…...

蓝桥杯每日一题2023.10.9
题目描述 成绩统计 - 蓝桥云课 (lanqiao.cn) 题目分析 学会使用四舍五入函数round #include<bits/stdc.h> using namespace std; int s1, s2; int main() {int n, x;cin >> n;for(int i 1; i < n; i ){cin >> x; if(x > 60)s1 ;if(x > 85)s2 ;…...

HTML5的新增表单元素
HTML5 有以下新的表单元素: <datalist> <keygen> <output> datalist datalist 元素规定输入域的选项列表。 datalist属性规定 form 或 input 域应该拥有自动完成功能。当用户在自动完成域中开始输入时,浏览器应该在该域中显示填写的选项&…...
)
手把手教你用YOLACT训练自己的数据集:从COCO格式准备到模型推理全流程(附Python源码)
YOLACT实战指南:从数据标注到工业级实例分割模型部署 1. 实例分割技术演进与YOLACT核心优势 在计算机视觉领域,实例分割一直被视为目标检测与语义分割的结合体。不同于简单的边界框检测或像素级分类,实例分割要求算法能够区分同一类别的不同个…...

AI迈向“自动驾驶”,零售回归“人间清醒”:2026商业底层逻辑正在重组
导读:2026年的初夏,商业世界正处在一个奇妙的交汇点。一边是AI编程正式宣告进入“无人驾驶”时代,生产力工具迎来质变;另一边,零售巨头们在狂热中开始自省,重新审视效率与人性的边界。从阿里、腾讯的智能体…...

基于HPM5E00的EtherCAT从站开发板全流程实战:从硬件设计到软件配置
1. 项目概述:为什么我们要自己动手做一块EtherCAT开发板?如果你是一名从事工业自动化、运动控制或者机器人开发的工程师,最近几年一定没少听到EtherCAT的大名。它号称“以太网控制自动化技术”,本质上是一种基于标准以太网的实时工…...

数字孪生+高斯泼溅+CIMPro孪大师,打造申报“硬通货”
当前,2026年全国智能工厂梯度培育申报窗口期正在密集推进中。从四川、江苏到福建、安徽,各地工信部门纷纷下发《关于做好2026年度智能工厂梯度培育有关工作的通知》,2025年至2027年是基础级、卓越级、领航级智能工厂建设的三年关键窗口期。你…...

【免费下载】 树莓派4B原理图资源下载
树莓派4B原理图资源下载 【下载地址】树莓派4B原理图资源下载分享 树莓派4B原理图资源下载本仓库提供了一个方便的途径,供大家下载树莓派4B的原理图资源文件 项目地址: https://gitcode.com/open-source-toolkit/ae590 本仓库提供了一个方便的途径࿰…...

前端开发自救指南:不用写测试代码,5分钟用Playwright录制生成E2E测试脚本
前端开发自救指南:5分钟零代码生成E2E测试脚本的Playwright实战 最近在重构公司后台管理系统时,我遇到了一个典型的前端开发困境:每次修改表单验证逻辑后,都需要手动点击十几个字段组合来验证是否会影响其他功能。直到团队里的测…...

CNC木质树莓派外壳制作:从设计到加工的全流程实践
1. 项目概述:当数字制造遇上经典木艺 给树莓派找个“家”,这事儿我干过不少。从3D打印的塑料壳到亚克力板拼的“鱼缸”,总觉得差点意思。塑料感太强,亚克力又显得冰冷。直到有一次在工作室里看到一块边角料的硬枫木,纹…...

猫抓插件完全指南:浏览器资源嗅探与下载的终极解决方案
猫抓插件完全指南:浏览器资源嗅探与下载的终极解决方案 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾在浏览网页时发现心仪的…...

产业园区如何构建智能化科技服务体系?
观点作者:科易网-国家科技成果转化(厦门)示范基地 一、现状概述(成效与短板) 近年来,我国产业园区在推动科技成果转化、促进科技创新方面发挥了显著作用。然而,随着数智化浪潮的兴起,…...

【SysBench】从零到一:在Linux上部署sysbench-1.20进行数据库压测
1. 为什么你需要sysbench? 如果你正在使用MySQL或PostgreSQL这类数据库,迟早会遇到一个灵魂拷问:我的数据库到底能扛住多少并发请求?这时候sysbench就该登场了。这个工具就像数据库的"体能测试仪",能模拟真实…...