GRU的 电影评论情感分析 - python 深度学习 情感分类 计算机竞赛
1 前言
🔥学长分享优质竞赛项目,今天要分享的是
🚩 GRU的 电影评论情感分析 - python 深度学习 情感分类
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
这是一个较为新颖的竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 项目介绍
其实,很明显这个项目和微博谣言检测是一样的,也是个二分类的问题,因此,我们可以用到学长之前提到的各种方法,即:
朴素贝叶斯或者逻辑回归以及支持向量机都可以解决这个问题。
另外在深度学习中,我们可以用CNN-Text或者RNN以及LSTM等模型最好。
当然在构建网络中也相对简单,相对而言,LSTM就比较复杂了,为了让不同层次的同学们可以接受,学长就用了相对简单的GRU模型。
如果大家想了解LSTM。以后,学长会给大家详细介绍。
2 情感分类介绍
其实情感分析在自然语言处理中,情感分析一般指判断一段文本所表达的情绪状态,属于文本分类问题。一般而言:情绪类别:正面/负面。当然,这就是为什么本人在前面提到情感分析实际上也是二分类问题的原因。
3 数据集
学长本次使用的是非常典型的IMDB数据集。
该数据集包含来自互联网的50000条严重两极分化的评论,该数据被分为用于训练的25000条评论和用于测试的25000条评论,训练集和测试集都包含50%的正面评价和50%的负面评价。该数据集已经经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词。
查看其数据集的文件夹:这是train和test文件夹。
接下来就是以train文件夹介绍里面的内容
然后就是以neg文件夹介绍里面的内容,里面会有若干的text文件:
4 实现
4.1 数据预处理
#导入必要的包
import zipfile
import os
import io
import random
import json
import matplotlib.pyplot as plt
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear, Embedding
from paddle.fluid.dygraph.base import to_variable
from paddle.fluid.dygraph import GRUUnit
import paddle.dataset.imdb as imdb
#加载字典
def load_vocab():
vocab = imdb.word_dict()
return vocab
#定义数据生成器
class SentaProcessor(object):
def __init__(self):
self.vocab = load_vocab()def data_generator(self, batch_size, phase='train'):if phase == "train":return paddle.batch(paddle.reader.shuffle(imdb.train(self.vocab),25000), batch_size, drop_last=True)elif phase == "eval":return paddle.batch(imdb.test(self.vocab), batch_size,drop_last=True)else:raise ValueError("Unknown phase, which should be in ['train', 'eval']")
步骤
-
首先导入必要的第三方库
-
接下来就是数据预处理,需要注意的是:数据是以数据标签的方式表示一个句子,因此,每个句子都是以一串整数来表示的,每个数字都是对应一个单词。当然,数据集就会有一个数据集字典,这个字典是训练数据中出现单词对应的数字标签。
4.2 构建网络
这次的GRU模型分为以下的几个步骤
- 定义网络
- 定义损失函数
- 定义优化算法
具体实现如下
#定义动态GRUclass DynamicGRU(fluid.dygraph.Layer):def __init__(self,size,param_attr=None,bias_attr=None,is_reverse=False,gate_activation='sigmoid',candidate_activation='relu',h_0=None,origin_mode=False,):super(DynamicGRU, self).__init__()self.gru_unit = GRUUnit(size * 3,param_attr=param_attr,bias_attr=bias_attr,activation=candidate_activation,gate_activation=gate_activation,origin_mode=origin_mode)self.size = sizeself.h_0 = h_0self.is_reverse = is_reversedef forward(self, inputs):hidden = self.h_0res = []for i in range(inputs.shape[1]):if self.is_reverse:i = inputs.shape[1] - 1 - iinput_ = inputs[ :, i:i+1, :]input_ = fluid.layers.reshape(input_, [-1, input_.shape[2]], inplace=False)hidden, reset, gate = self.gru_unit(input_, hidden)hidden_ = fluid.layers.reshape(hidden, [-1, 1, hidden.shape[1]], inplace=False)res.append(hidden_)if self.is_reverse:res = res[::-1]res = fluid.layers.concat(res, axis=1)return res
class GRU(fluid.dygraph.Layer):
def init(self):
super(GRU, self).init()
self.dict_dim = train_parameters[“vocab_size”]
self.emb_dim = 128
self.hid_dim = 128
self.fc_hid_dim = 96
self.class_dim = 2
self.batch_size = train_parameters[“batch_size”]
self.seq_len = train_parameters[“padding_size”]
self.embedding = Embedding(
size=[self.dict_dim + 1, self.emb_dim],
dtype=‘float32’,
param_attr=fluid.ParamAttr(learning_rate=30),
is_sparse=False)
h_0 = np.zeros((self.batch_size, self.hid_dim), dtype=“float32”)
h_0 = to_variable(h_0)
self._fc1 = Linear(input_dim=self.hid_dim, output_dim=self.hid_dim*3)self._fc2 = Linear(input_dim=self.hid_dim, output_dim=self.fc_hid_dim, act="relu")self._fc_prediction = Linear(input_dim=self.fc_hid_dim,output_dim=self.class_dim,act="softmax")self._gru = DynamicGRU(size=self.hid_dim, h_0=h_0)def forward(self, inputs, label=None):emb = self.embedding(inputs)o_np_mask =to_variable(inputs.numpy().reshape(-1,1) != self.dict_dim).astype('float32')mask_emb = fluid.layers.expand(to_variable(o_np_mask), [1, self.hid_dim])emb = emb * mask_embemb = fluid.layers.reshape(emb, shape=[self.batch_size, -1, self.hid_dim])fc_1 = self._fc1(emb)gru_hidden = self._gru(fc_1)gru_hidden = fluid.layers.reduce_max(gru_hidden, dim=1)tanh_1 = fluid.layers.tanh(gru_hidden)fc_2 = self._fc2(tanh_1)prediction = self._fc_prediction(fc_2)if label is not None:acc = fluid.layers.accuracy(prediction, label=label)return prediction, accelse:return prediction
4.3 训练模型
def train():with fluid.dygraph.guard(place = fluid.CUDAPlace(0)): # # 因为要进行很大规模的训练,因此我们用的是GPU,如果没有安装GPU的可以使用下面一句,把这句代码注释掉即可# with fluid.dygraph.guard(place = fluid.CPUPlace()):
processor = SentaProcessor()
train_data_generator = processor.data_generator(batch_size=train_parameters[“batch_size”], phase=‘train’)
model = GRU()sgd_optimizer = fluid.optimizer.Adagrad(learning_rate=train_parameters["lr"],parameter_list=model.parameters())steps = 0Iters, total_loss, total_acc = [], [], []for eop in range(train_parameters["epoch"]):for batch_id, data in enumerate(train_data_generator()):steps += 1doc = to_variable(np.array([np.pad(x[0][0:train_parameters["padding_size"]], (0, train_parameters["padding_size"] - len(x[0][0:train_parameters["padding_size"]])),'constant',constant_values=(train_parameters["vocab_size"]))for x in data]).astype('int64').reshape(-1))label = to_variable(np.array([x[1] for x in data]).astype('int64').reshape(train_parameters["batch_size"], 1))model.train()prediction, acc = model(doc, label)loss = fluid.layers.cross_entropy(prediction, label)avg_loss = fluid.layers.mean(loss)avg_loss.backward()sgd_optimizer.minimize(avg_loss)model.clear_gradients()if steps % train_parameters["skip_steps"] == 0:Iters.append(steps)total_loss.append(avg_loss.numpy()[0])total_acc.append(acc.numpy()[0])print("step: %d, ave loss: %f, ave acc: %f" %(steps,avg_loss.numpy(),acc.numpy()))if steps % train_parameters["save_steps"] == 0:save_path = train_parameters["checkpoints"]+"/"+"save_dir_" + str(steps)print('save model to: ' + save_path)fluid.dygraph.save_dygraph(model.state_dict(),save_path)draw_train_process(Iters, total_loss, total_acc)

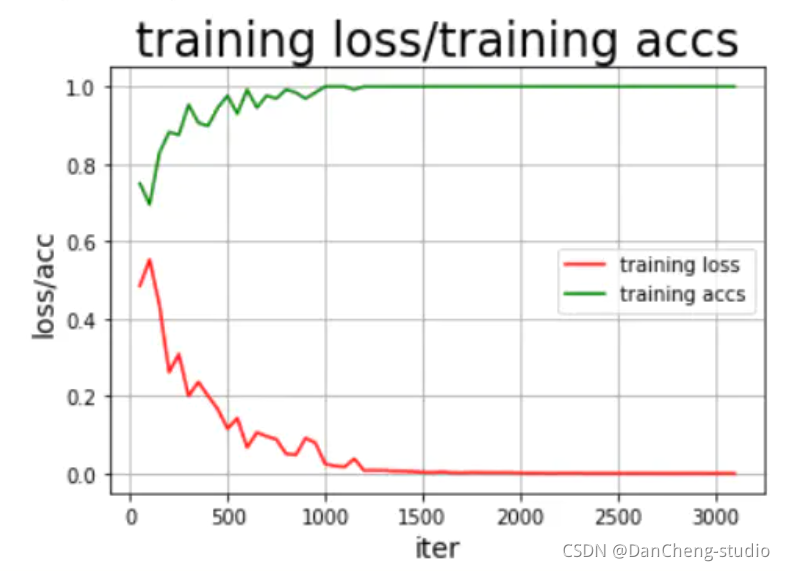
4.4 模型评估

结果还可以,这里说明的是,刚开始的模型训练评估不可能这么好,很明显是过拟合的问题,这就需要我们调整我们的epoch、batchsize、激活函数的选择以及优化器、学习率等各种参数,通过不断的调试、训练最好可以得到不错的结果,但是,如果还要更好的模型效果,其实可以将GRU模型换为更为合适的RNN中的LSTM以及bi-
LSTM模型会好很多。
4.5 模型预测
train_parameters["batch_size"] = 1
with fluid.dygraph.guard(place = fluid.CUDAPlace(0)):sentences = 'this is a great movie'data = load_data(sentences)print(sentences)print(data)data_np = np.array(data)data_np = np.array(np.pad(data_np,(0,150-len(data_np)),"constant",constant_values =train_parameters["vocab_size"])).astype('int64').reshape(-1)infer_np_doc = to_variable(data_np)model_infer = GRU()model, _ = fluid.load_dygraph("data/save_dir_750.pdparams")model_infer.load_dict(model)model_infer.eval()result = model_infer(infer_np_doc)print('预测结果为:正面概率为:%0.5f,负面概率为:%0.5f' % (result.numpy()[0][0],result.numpy()[0][1]))

训练的结果还是挺满意的,到此为止,我们的本次项目实验到此结束。
5 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
GRU的 电影评论情感分析 - python 深度学习 情感分类 计算机竞赛
1 前言 🔥学长分享优质竞赛项目,今天要分享的是 🚩 GRU的 电影评论情感分析 - python 深度学习 情感分类 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:3分创新点:4分 这…...

kafka简述
前言 在大数据高并发场景下,当系统中出现“生产“和“消费“的速度或稳定性等因素不一致的时候,就需要消息队列,作为抽象层,弥合双方的差异。一般选型是Kafka、RocketMQ,这源于这些中间件的高吞吐、可扩展以及可靠…...
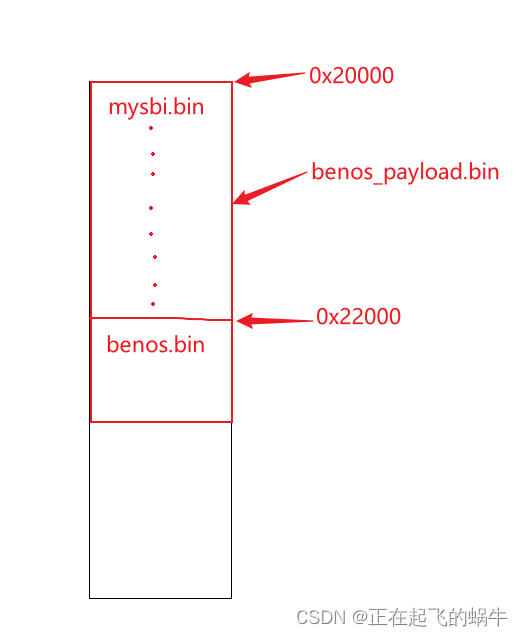
《RISC-V体系结构编程与实践》的benos_payload程序——mysbi跳转到benos分析
1、benos_payload.bin结构分析 韦东山老师提供的开发文档里已经对程序的结构做了分析,这里不再赘述,下面是讨论mysbi跳转到benos的问题; 2、mysbi跳转到benos的代码 3、跳转产生的疑问 我认为mysbi.bin最后跳转到0x22000地址处执行࿰…...
ad5665r STM32 GD32 IIC驱动设计
本文涉及文档工程代码,下载地址如下 ad5665rSTM32GD32IIC驱动设计,驱动程序在AD公司提供例程上修改得到,IO模拟的方式进行IIC通信资源-CSDN文库 硬件设计 MCU采用STM32或者GD32,GD32基本上和STM32一样,针对ad566r的IIC时序操作是完全相同的. 原理图设计如下 与MC…...
TensorFlow入门(十六、识别模糊手写图片)
TensorFlow在图像识别方面,提供了多个开源的训练数据集,比如CIFAR-10数据集、FASHION MNIST数据集、MNIST数据集。 CIFAR-10数据集有10个种类,由6万个32x32像素的彩色图像组成,每个类有6千个图像。6万个图像包含5万个训练图像和1万个测试图像。 FASHION MNIST数据集由衣服、鞋子…...
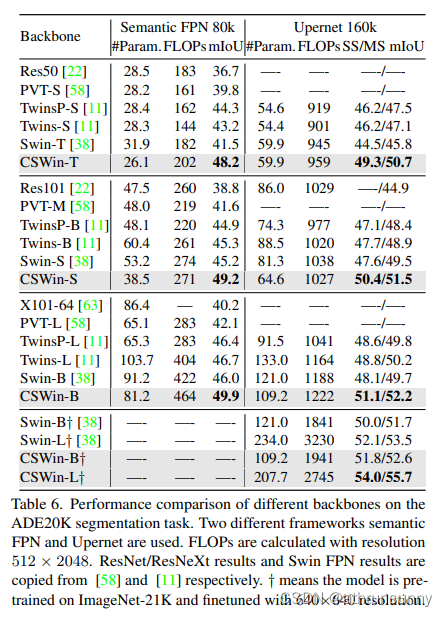
CSwin Transformer 学习笔记
Cswin提出了上图中使用交叉形状局部attention,为了解决VIT模型中局部自注意力感受野进一步增长受限的问题,同时提出了局部增强位置编码模块,超越了Swin等模型,在多个任务上效果SOTA(当时的SOTA,已经被SG Fo…...
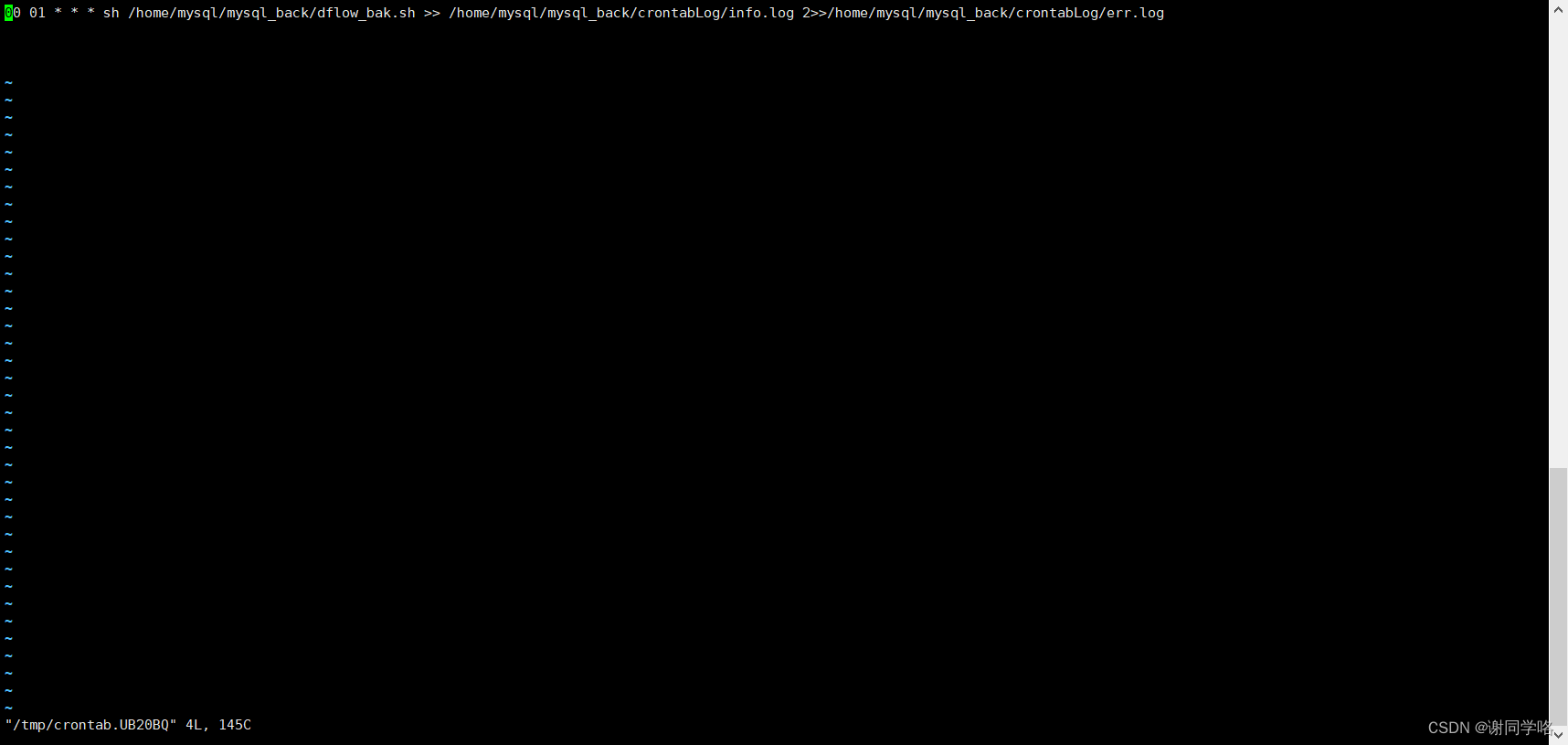
Linux上通过mysqldump命令实现自动备份
Linux上通过mysqldump命令实现自动备份 直接上代码 #!/bin/bash mysql_user"root" mysql_host"localhost" mysql_port"3306" mysql_charset"utf8mb4"backup_location/home/mysql/mysql_back/sql # 是否开始自动删除过期文件,过期时间…...

v-model与.sync的区别
我们在日常开发的过程中,v-model指令可谓是随处可见,一般来说 v-model 指令在表单及元素上创建双向数据绑定,但 v-model 本质是语法糖。但提到语法糖,这里就不得不提另一个与v-model有相似功能的双向绑定语法糖了,这就是 .sync修饰符。在这里就两者的使用进行一下比较和总结: …...

Linux---进程(1)
操作系统 传统的计算机系统资源分为硬件资源和软件资源。硬件资源包括中央处理器,存储器,输入设备,输出设备等物理设备;软件资源是以文件形式保存在存储器上的成熟和数据等信息。 操作系统就是计算机系统资源的管理者。 如果你的计…...
C# U2Net Portrait 跨界肖像画
效果 项目 下载 可执行文件exe下载 源码下载...
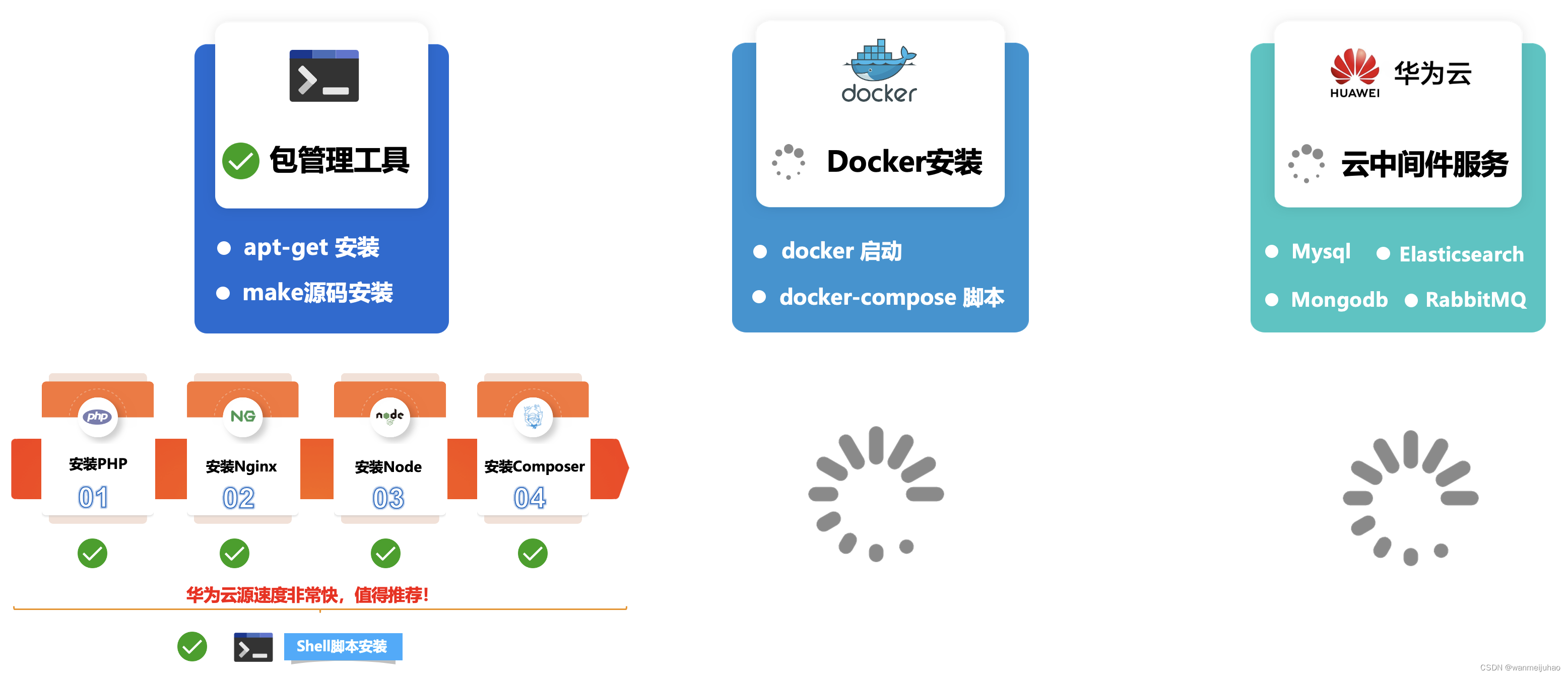
华为云云耀云服务器L实例评测|华为云耀云服务器L实例评测包管理工具安装软件(六)
七、华为云耀云服务器L实例评测包管理工具安装软件: 根据企业级项目架构图所示,本章主要是安装公司企业项目的基本环境LNMP,相关的包管理器Composer、Node、Npm、Yarn安装,评测一下包管理工具安装软件是否存在问题,如果…...

在PYTHON中用zlib模块对文本进行压缩,写入图片的EXIF中,后在C#中读取EXIF并用SharpZipLib进行解压获取压缩前文本
在PYTHON中用zlib模块对文本进行压缩长度,写入图片的EXIF中,并在C#中读取EXIF后用SharpZipLib进行解压缩获取压缩前文本。 PS:当压缩后的字节数组长度为单数时,无法写入EXIF的XPComment中,需要在后面增加一个以utf-8编码的空格&a…...
centos / oracle Linux 常用运维命令讲解
目录 1.shell linux常用目录: 2.命令格式 3.man 帮助 4.提示符 5.echo输出字符串或变量值 6.date显示及设置系统的时间或日期 7.重启系统 8.关闭系统 9.登录注销 10.wget 下载文件 11.ps 查看系统的进程 12.top动态监视进程信息和系统负载等信息 13.l…...
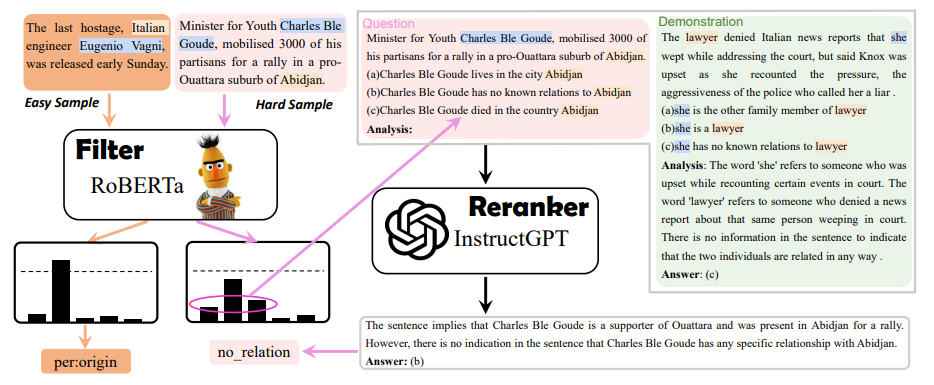
EMNLP 2023 录用论文公布,速看NLP各领域最新SOTA方案
EMNLP 2023 近日公布了录用论文。 开始前以防有同学不了解这个会议,先简单介绍介绍:EMNLP 是NLP 四大顶会之一,ACL大家应该都很熟吧,EMNLP就是由 ACL 下属的SIGDAT小组主办的NLP领域顶级国际会议,一年举办一次。相较于…...

互联网Java工程师面试题·Java 并发编程篇·第三弹
目录 26、什么是线程组,为什么在 Java 中不推荐使用? 27、为什么使用 Executor 框架比使用应用创建和管理线程好? 27.1 为什么要使用 Executor 线程池框架 27.2 使用 Executor 线程池框架的优点 28、java 中有几种方法可以实现一个线程…...

mac jdk的环境变量路径,到底在哪里?
在mac 电脑中,直接执行 java -version 显示Jdk的版本为1.8 然后打印Java环境变量 在终端中执行 echo $JAVA_HOME 1、情况一:发现环境变量是空的 我草,没配置环境变量怎么能使用Java ,和查看jdk版本 2、情况二:环…...
PyQt5 PyQt6 Designer 的安装
pip国内的一些镜像 阿里云 http://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/ 豆瓣(douban) http://pypi.douban.com/simple/ 清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/ 中国科学技术大学 http://pypi.mirrors.ustc.…...
)
数据库:Hive转Presto(四)
这次补充了好几个函数,并且新加了date_sub函数,代码写的比较随意,有的地方比较繁琐,还待改进,而且这种文本处理的东西,经常需要补充先前没考虑到的情况,要经常修改。估计下一篇就可以补充完所有…...
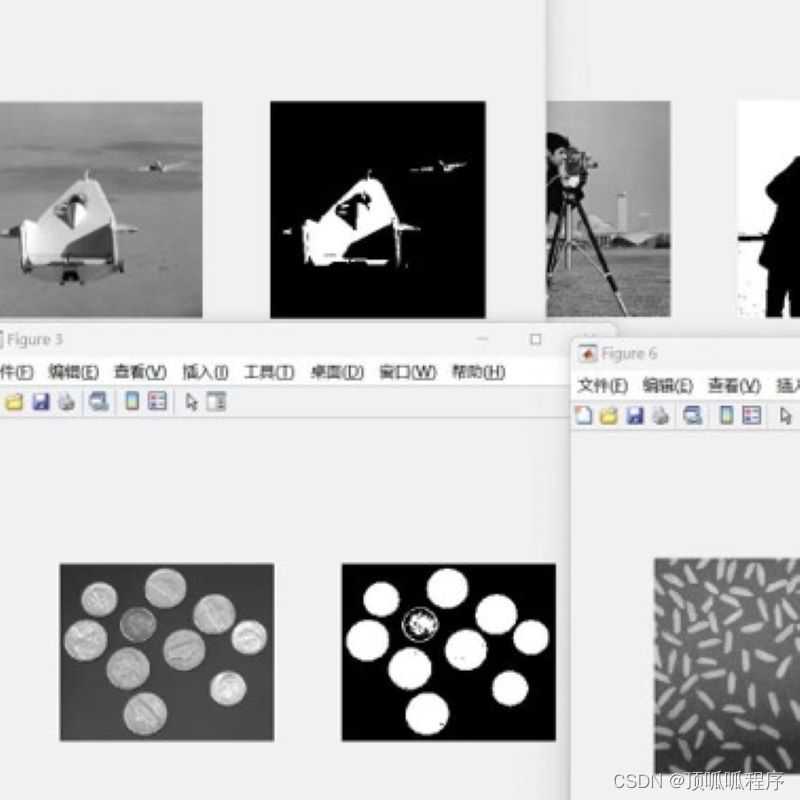
16基于otsuf方法的图像分割,程序已调通,可更换自己的图片进行分割,程序具有详细的代码注释,可轻松掌握。基于MATLAB平台,需要直接拍下。
基于otsuf方法的图像分割,程序已调通,可更换自己的图片进行分割,程序具有详细的代码注释,可轻松掌握。基于MATLAB平台,需要直接拍下。 16matlab图像处理图像分割 (xiaohongshu.com)...

2、使用阿里云镜像加速器提升Docker的资源下载速度
1、注册阿里云账号并登录 https://www.aliyun.com/ 2、进入个人控制台,找到“容器镜像服务” 3、在“容器镜像服务”中找到“镜像加速器” 4、在右侧列表中会显示你的加速器地址,复制地址 5、进入/etc/docker目录,编辑daemon.json࿰…...

BesTV_R3300-L S905L芯片刷机实战:从驱动识别到固件烧录的完整避坑指南
1. 认识你的BesTV_R3300-L盒子 我手头这台BesTV_R3300-L盒子已经吃灰大半年了,原厂系统用起来卡顿不说,还经常弹出各种广告。拆开外壳看到S905L芯片的那一刻,我就知道这玩意儿有救——毕竟这是刷机圈里的"老熟人"了。先给新手朋友科…...

5步掌握碧蓝航线Live2D资源提取完整教程
5步掌握碧蓝航线Live2D资源提取完整教程 【免费下载链接】AzurLaneLive2DExtract OBSOLETE - see readme / 碧蓝航线Live2D提取 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneLive2DExtract 你是否曾经被碧蓝航线中精美的Live2D角色动画所吸引,却苦…...

CLI工具集claw:模块化设计与插件化架构深度解析
1. 项目概述:一个面向开发者的现代化CLI工具集最近在GitHub上看到一个名为opsyhq/claw的项目,第一眼就被它简洁的名字吸引了。claw,中文意思是“爪子”,听起来就很有力量感和抓取感。点进去一看,果然,这是一…...

树莓派NOOBS安装指南:从SD卡准备到系统配置全流程详解
1. 项目概述:为什么选择NOOBS作为树莓派入门首选如果你刚拿到一块树莓派,看着这块小小的电路板,第一反应可能是兴奋,紧接着就是困惑:我该怎么让它“活”过来?对于嵌入式开发、物联网原型搭建,甚…...

NotebookLM权限审计日志难追溯?手把手教你启用VPC Service Controls + Cloud Logging Query Builder构建实时越权预警看板
更多请点击: https://intelliparadigm.com 第一章:NotebookLM权限控制设置 NotebookLM 是 Google 推出的基于用户上传文档进行 AI 辅助理解与生成的实验性工具,其权限模型默认采用 Google 账户体系集成,但需主动配置以满足团队协…...

【Gin】中间件练习题
路由组中间件题目描述 创建一个 /admin 路由组,给它单独加一个鉴权中间件,其他接口不受影响。规则:请求头带 token: admin123 才允许访问否则返回 401 无权限输出示例无 token:{"code":401,"msg":"无权限…...

TPS5430玩点不一样的:15V输入如何生成一个干净的-12V电源?电路设计与极性电容防炸指南
TPS5430负压生成实战:从15V到-12V的电路设计精要 在模拟电路设计中,双电源供电系统(如12V)是音频设备、运算放大器和高精度ADC的常见需求。然而,当系统仅提供单路正电压输入时,如何高效生成稳定的负电压轨成…...

441GB香港OSGB数据实战:从ContextCapture目录到Smart3D加载的完整指南
1. 441GB香港OSGB数据背景解析 第一次拿到441GB的香港OSGB数据时,我的硬盘指示灯疯狂闪烁了整整一晚上。这种规模的倾斜摄影数据在业内确实罕见,特别是覆盖香港565平方公里区域的完整数据集。实测发现,这套数据采用ContextCapture标准目录结构…...

避坑指南:从ADS导入DXF到Altium Designer时,如何解决封装丢失和铺铜失败的常见问题
从ADS到Altium Designer的工程迁移:封装与铺铜问题的深度解决方案 在射频与微波电路设计领域,工程师常常面临一个典型困境:如何在ADS(Advanced Design System)中完成高频仿真后,将设计无缝迁移到Altium Des…...

【免费下载】 最靠谱的Cadence Allegro PCB SI 板级仿真教程
最靠谱的Cadence Allegro PCB SI 板级仿真教程 【下载地址】最靠谱的CadenceAllegroPCBSI板级仿真教程 最靠谱的Cadence Allegro PCB SI 板级仿真教程欢迎来到“最靠谱的Cadence Allegro PCB SI 板级仿真教程”资源页面 项目地址: https://gitcode.com/open-source-toolkit/e…...