【TensorFlow2 之011】TF 如何使用数据增强提高模型性能?

一、说明
亮点:在这篇文章中,我们将展示数据增强技术作为提高模型性能的一种方式的好处。当我们没有足够的数据可供使用时,这种方法将非常有益。
教程概述:
- 无需数据增强的训练
- 什么是数据增强?
- 使用数据增强进行训练
- 可视化
二、没有数据增强的训练
一个熟悉的问题是“我们为什么要使用数据增强?所以,让我们看看答案。
为了证明这一点,我们将在TensorFlow中创建一个卷积神经网络,并在Cats-vs-Dog数据集上对其进行训练。
首先,我们将准备用于训练的数据集。我们将首先从在线存储库下载数据集。完成此操作后,我们将继续解压缩并为训练和验证集创建路径位置。
import os
import wget
import zipfilewget.download("https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip")100% [........................................................................] 68606236 / 68606236Out[2]:
'cats_and_dogs_filtered.zip'
with zipfile.ZipFile("cats_and_dogs_filtered.zip","r") as zip_ref:zip_ref.extractall()base_dir = 'cats_and_dogs_filtered'train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')让我们继续加载本教程所需的必要库。
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.image as mpimgfrom tensorflow.keras import Model
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Dropout, Activation
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.callbacks import TensorBoard
from tensorflow.keras.preprocessing.image import img_to_array, load_img
from tensorflow.keras.preprocessing.image import ImageDataGenerator我们将使用“模型子类化技术”来构建模型。这样,我们应该在__init__中定义我们的层,并在调用中实现模型的前向传递。模型的输入将是大小为 \([150, 150, 3]\) 的图像。在卷积层之后,我们将利用两个完全连接的层来进行预测。这是一个二元分类问题,所以我们在输出层中只有一个神经元。
class Create_model(Model):def __init__(self, chanDim=-1):super(Create_model, self).__init__()self.conv1A = Conv2D(16, 3, input_shape = (150, 150, 3))self.act1A = Activation("relu")self.pool1A = MaxPooling2D(2)self.conv1B = Conv2D(32, 3)self.act1B = Activation("relu")self.pool1B = MaxPooling2D(pool_size=(2, 2))self.conv1C = Conv2D(64, 3)self.act1C = Activation("relu")self.pool1C = MaxPooling2D(2)self.flatten = Flatten()self.dense2A = Dense(512)self.act2A = Activation("relu")self.dense2B = Dense(1)self.sigmoid = Activation("sigmoid")def call(self, inputs):x = self.conv1A(inputs)x = self.act1A(x)x = self.pool1A(x)x = self.conv1B(x)x = self.act1B(x)x = self.pool1B(x)x = self.conv1C(x)x = self.act1C(x)x = self.pool1C(x)x = self.flatten(x)x = self.dense2A(x)x = self.act2A(x)x = self.dense2B(x)x = self.sigmoid(x)return xmodel = Create_model()model.compile(loss='binary_crossentropy',optimizer=RMSprop(lr=0.001),metrics=['accuracy'])我们的图像不在一个文件中,而是在多个文件夹中。为了在这样的数据集上训练网络,我们需要使用图像数据生成器。在创建两个生成器(用于训练和验证)后,我们可以使用 fit 方法训练网络。唯一的区别是,我们不是将输入和输出分别传递给我们的网络,而是将数据生成器传递给网络。
最好规范化像素值,以便每个像素值的值介于 0 和 1 之间,以免中断或减慢学习过程。因此,这将是传递给图像数据生成器的唯一参数。然后,我们将使用这些数据生成器遍历目录、调整图像大小和创建批处理。
train_datagen = ImageDataGenerator(rescale=1./255)
val_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(train_dir,target_size=(150, 150),batch_size=20,class_mode='binary')validation_generator = val_datagen.flow_from_directory(validation_dir,target_size=(150, 150),batch_size=20,class_mode='binary')history = model.fit(train_generator,steps_per_epoch=100,epochs=15,validation_data=validation_generator,validation_steps=50,verbose=0)让我们检查一下模型的分类准确性和损失。
在这里,训练集的准确性和损失都以蓝色显示,而验证集的准确度和损失都以橙色显示。
accuracy = history.history['accuracy']
val_accuracy = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs = range(len(accuracy))plt.plot(epochs, accuracy)
plt.plot(epochs, val_accuracy)
plt.title('Training and validation accuracy')plt.figure()plt.plot(epochs, loss)
plt.plot(epochs, val_loss)
plt.title('Training and validation loss')
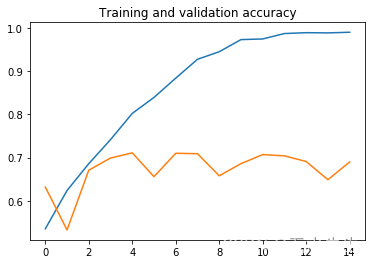

从这些图中,我们可以清楚地看到,模型在训练中的表现比在验证集上的表现要好得多。那么我们能做什么呢?使用数据增强。
三、什么是数据增强?
大多数计算机视觉任务需要大量数据,而数据增强是用于提高计算机视觉系统性能的技术之一。计算机视觉是一项相当复杂的任务。对于输入图像,算法必须找到一种模式来理解图片中的内容。
在实践中,拥有更多数据将有助于几乎所有的计算机视觉任务。今天,计算机视觉的状态需要更多的数据来解决大多数计算机视觉问题。对于卷积神经网络的所有应用来说,这可能不是真的,但对于计算机视觉领域来说确实如此。
当我们训练计算机视觉模型时,数据增强通常会有所帮助。无论我们使用迁移学习还是从头开始训练模型,都是如此。
因此,数据增强是一种技术,可以在不收集新数据的情况下显着增加可用于训练的数据的多样性。您可以在此处找到有关数据增强理论方面的更多信息。
四、 使用数据增强进行训练
乍一看,数据增强可能听起来很复杂,但幸运的是,TensorFlow 允许我们有效地实现它。
因此,我们将像以前一样使用图像数据生成器,但我们将添加重新缩放、旋转、移动、缩放、缩放和翻转。再次重要的是要说,此过程仅适用于训练集,而不应用于验证。
在这里,我们不仅要调整大小,还要添加旋转(以度为单位的范围)、高度和宽度偏移(以像素为单位的范围)、剪切范围(以度为单位的逆时针方向的角度)、缩放范围和翻转。
train_datagen = ImageDataGenerator(rescale=1./255,rotation_range=40,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,)val_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(train_dir,target_size=(150, 150),batch_size=20,class_mode='binary')validation_generator = val_datagen.flow_from_directory(validation_dir,target_size=(150, 150),batch_size=20,class_mode='binary')Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
此外,Dropout 层将被添加到我们的神经网络中。我们将丢弃\(50%\)个起始神经元。添加 Dropout 图层将有助于防止过度拟合。
class Create_model(Model):def __init__(self, chanDim=-1):super(Create_model, self).__init__()self.conv1A = Conv2D(16, 3, input_shape = (150, 150, 3))self.act1A = Activation("relu")self.pool1A = MaxPooling2D(2)self.conv1B = Conv2D(32, 3)self.act1B = Activation("relu")self.pool1B = MaxPooling2D(pool_size=(2, 2))self.conv1C = Conv2D(64, 3)self.act1C = Activation("relu")self.pool1C = MaxPooling2D(2)self.flatten = Flatten()self.dense2A = Dense(512)self.act2A = Activation("relu")self.dropout = Dropout(0.5)self.dense2B = Dense(1)self.sigmoid = Activation("sigmoid")def call(self, inputs):x = self.conv1A(inputs)x = self.act1A(x)x = self.pool1A(x)x = self.conv1B(x)x = self.act1B(x)x = self.pool1B(x)x = self.conv1C(x)x = self.act1C(x)x = self.pool1C(x)x = self.flatten(x)x = self.dense2A(x)x = self.act2A(x)x = self.dropout(x)x = self.dense2B(x)x = self.sigmoid(x)return xmodel = Create_model()model.compile(loss='binary_crossentropy',optimizer=RMSprop(lr=0.001),metrics=['accuracy'])现在我们可以训练网络了。
history = model.fit(train_generator,steps_per_epoch=100,epochs=30,validation_data=validation_generator,validation_steps=50,verbose=2)Train for 100 steps, validate for 50 steps
Epoch 1/30
100/100 - 92s - loss: 0.9063 - accuracy: 0.5125 - val_loss: 0.7271 - val_accuracy: 0.5000
Epoch 2/30
100/100 - 56s - loss: 0.7020 - accuracy: 0.5625 - val_loss: 0.6551 - val_accuracy: 0.5480
Epoch 3/30
100/100 - 56s - loss: 0.6815 - accuracy: 0.5950 - val_loss: 0.6253 - val_accuracy: 0.6600
Epoch 4/30
100/100 - 57s - loss: 0.6594 - accuracy: 0.6220 - val_loss: 0.6262 - val_accuracy: 0.6350
Epoch 5/30
100/100 - 56s - loss: 0.6352 - accuracy: 0.6485 - val_loss: 0.5916 - val_accuracy: 0.6890
Epoch 6/30
100/100 - 56s - loss: 0.6336 - accuracy: 0.6675 - val_loss: 0.5774 - val_accuracy: 0.6790
Epoch 7/30
100/100 - 57s - loss: 0.6383 - accuracy: 0.6570 - val_loss: 0.5830 - val_accuracy: 0.6980
让我们看看结果。在这里,训练集的准确性和损失都以蓝色显示,而验证集的准确度和损失都以橙色显示。
accuracy = history.history['accuracy']
val_accuracy = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs = range(len(accuracy))plt.plot(epochs, accuracy)
plt.plot(epochs, val_accuracy)
plt.title('Training and validation accuracy')plt.figure()plt.plot(epochs, loss)
plt.plot(epochs, val_loss)
plt.title('Training and validation loss')Text(0.5, 1.0, 'Training and validation loss')

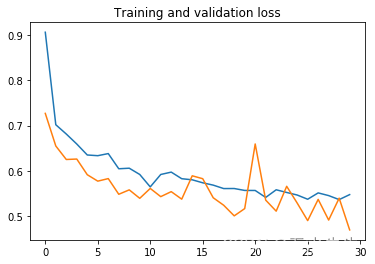
现在的结果好多了。但是,我们模型的准确性还不完美。
我们将在下一篇文章中使用迁移学习来解决这个问题。
五、 可视化
到目前为止,我们只是在讨论如何创建增强图像,但让我们看看它们的外观。
为此,我们需要使用来自生成器的一个图像并“循环它”。这将遍历生成器并执行增强。下面我们展示了这些图像样本的可视化。
augmented_images = [train_generator[0][0][0] for i in range(12)]
plt.figure(figsize=(8,6))for i in range(12):plt.subplot(3, 4, i+1)image = augmented_images[i]image = image.reshape(150, 150, 3)plt.imshow(image)
pyplot.show()
六、总结
总而言之,我们已经学会了如何使用数据增强技术来提高模型的性能。在数据稀缺或数据收集成本高昂的情况下,我们可以使用这种方法。但是,请注意,我们不能将数据集扩充到非常大的比例。此方法有其局限性。在下一篇文章中,我们将展示如何应用迁移学习的过程。
有关该主题的更多资源:
相关文章:
【TensorFlow2 之011】TF 如何使用数据增强提高模型性能?
一、说明 亮点:在这篇文章中,我们将展示数据增强技术作为提高模型性能的一种方式的好处。当我们没有足够的数据可供使用时,这种方法将非常有益。 教程概述: 无需数据增强的训练什么是数据增强?使用数据增强进行训练可视…...
Hadoop 安装教程 (Mac m1/m2版)
安装JDK1.8 这里最好是安装1.8版本的jdk 1. 进入官网Java Downloads | Oracle Hong Kong SAR, PRC,下滑到中间区域找到JDK8 2.选择mac os,下载ARM64 DMG Installer对应版本 注:这里下载需要注册oracle账号,不过很简单,只需要提供邮箱即可&…...

Docker - 网络模式与容器网络互连
前言 简单记录一下在Docker学习过程中,关于网络模式和容器网络互连的基本概念。 一、Docker的网络模式 (1)桥接模式:Docker会为每个容器创建一个虚拟网卡,并将这些虚拟网卡连接到一个虚拟交换机上,从而实…...
【基础篇】三、Flink集群角色、系统架构以及作业提交流程
文章目录 1、集群角色2、部署模式3、Flink系统架构3.1 作业管理器(JobManager)3.2 任务管理器(TaskManager) 4、独立部署会话模式下的作业提交流程5、Yarn部署的应用模式下作业提交流程 1、集群角色 Flink提交作业和执行任务&…...
第一个2DGodot游戏-从零开始-逐步解析
视频教程地址:https://www.bilibili.com/video/BV1Hw411v78Y/ 前言 大家好,这一集我将要带领大家完成官方文档里的第一个2DGodot游戏,从零开始,逐步解析,演示游戏的制作全过程,尽量让,就算是新…...
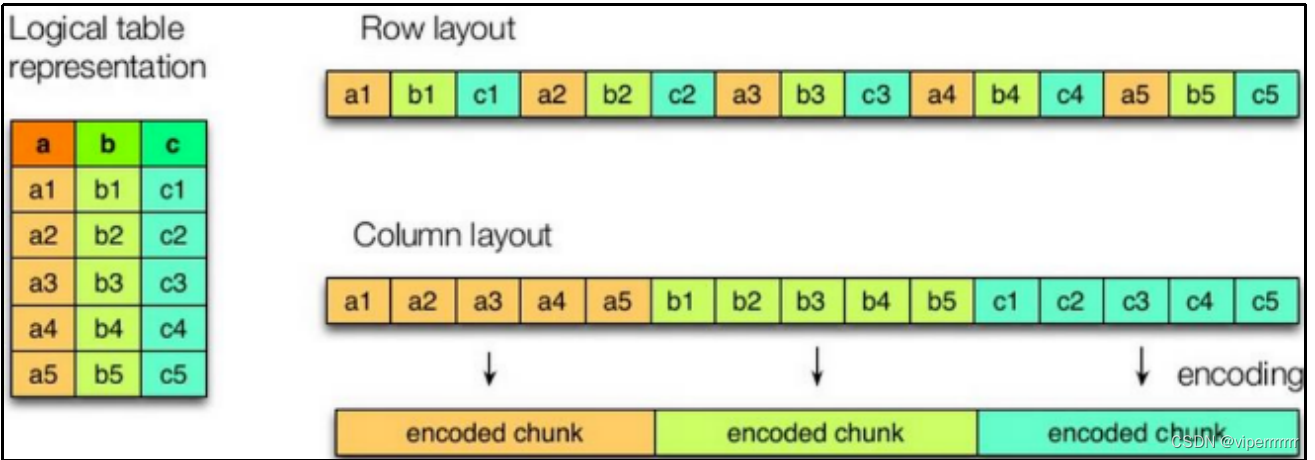
大数据学习(7)-hive文件格式总结
&&大数据学习&& 🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博>主哦&#x…...

GRU的 电影评论情感分析 - python 深度学习 情感分类 计算机竞赛
1 前言 🔥学长分享优质竞赛项目,今天要分享的是 🚩 GRU的 电影评论情感分析 - python 深度学习 情感分类 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:3分创新点:4分 这…...

kafka简述
前言 在大数据高并发场景下,当系统中出现“生产“和“消费“的速度或稳定性等因素不一致的时候,就需要消息队列,作为抽象层,弥合双方的差异。一般选型是Kafka、RocketMQ,这源于这些中间件的高吞吐、可扩展以及可靠…...
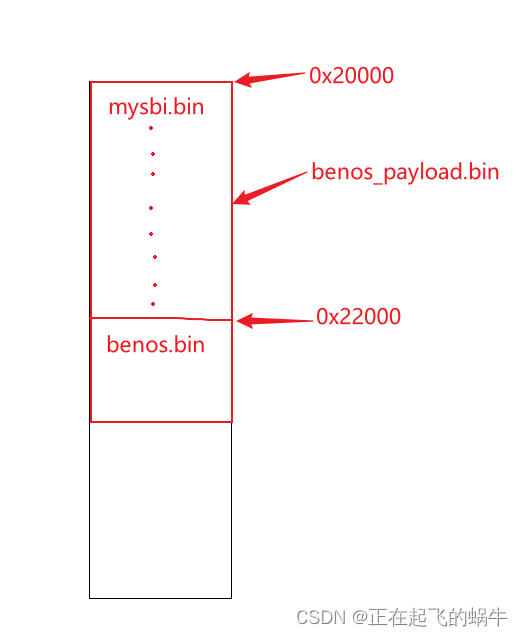
《RISC-V体系结构编程与实践》的benos_payload程序——mysbi跳转到benos分析
1、benos_payload.bin结构分析 韦东山老师提供的开发文档里已经对程序的结构做了分析,这里不再赘述,下面是讨论mysbi跳转到benos的问题; 2、mysbi跳转到benos的代码 3、跳转产生的疑问 我认为mysbi.bin最后跳转到0x22000地址处执行࿰…...
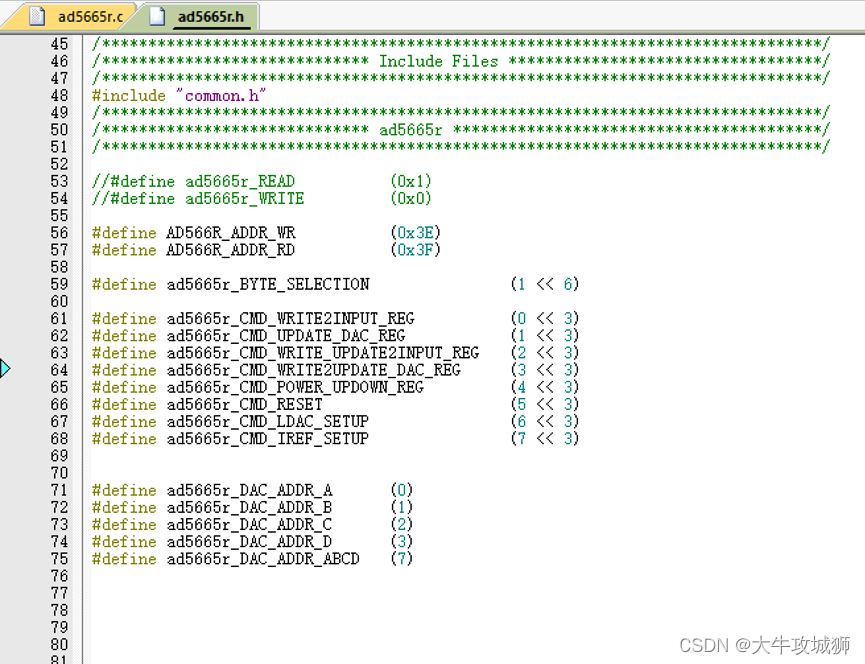
ad5665r STM32 GD32 IIC驱动设计
本文涉及文档工程代码,下载地址如下 ad5665rSTM32GD32IIC驱动设计,驱动程序在AD公司提供例程上修改得到,IO模拟的方式进行IIC通信资源-CSDN文库 硬件设计 MCU采用STM32或者GD32,GD32基本上和STM32一样,针对ad566r的IIC时序操作是完全相同的. 原理图设计如下 与MC…...
TensorFlow入门(十六、识别模糊手写图片)
TensorFlow在图像识别方面,提供了多个开源的训练数据集,比如CIFAR-10数据集、FASHION MNIST数据集、MNIST数据集。 CIFAR-10数据集有10个种类,由6万个32x32像素的彩色图像组成,每个类有6千个图像。6万个图像包含5万个训练图像和1万个测试图像。 FASHION MNIST数据集由衣服、鞋子…...
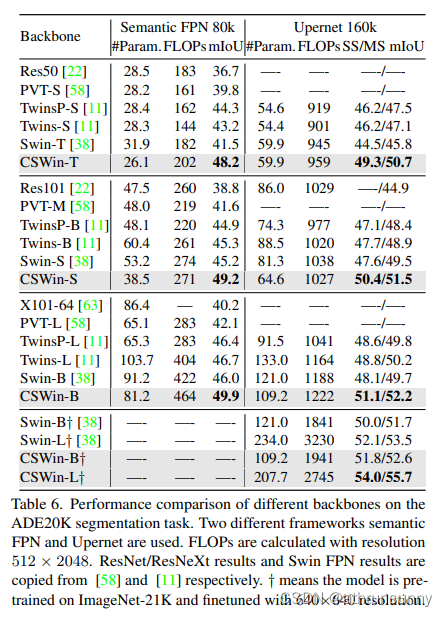
CSwin Transformer 学习笔记
Cswin提出了上图中使用交叉形状局部attention,为了解决VIT模型中局部自注意力感受野进一步增长受限的问题,同时提出了局部增强位置编码模块,超越了Swin等模型,在多个任务上效果SOTA(当时的SOTA,已经被SG Fo…...
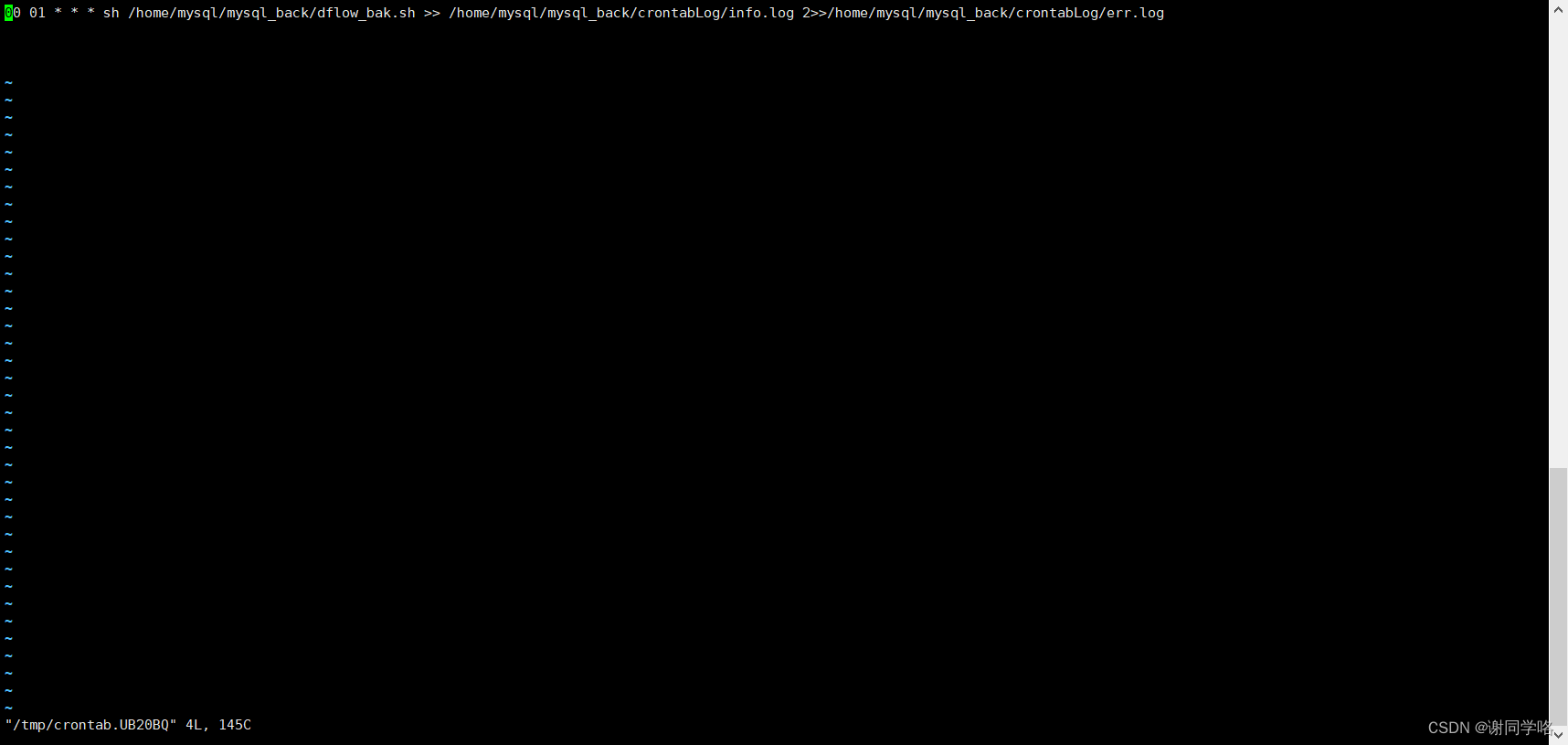
Linux上通过mysqldump命令实现自动备份
Linux上通过mysqldump命令实现自动备份 直接上代码 #!/bin/bash mysql_user"root" mysql_host"localhost" mysql_port"3306" mysql_charset"utf8mb4"backup_location/home/mysql/mysql_back/sql # 是否开始自动删除过期文件,过期时间…...

v-model与.sync的区别
我们在日常开发的过程中,v-model指令可谓是随处可见,一般来说 v-model 指令在表单及元素上创建双向数据绑定,但 v-model 本质是语法糖。但提到语法糖,这里就不得不提另一个与v-model有相似功能的双向绑定语法糖了,这就是 .sync修饰符。在这里就两者的使用进行一下比较和总结: …...

Linux---进程(1)
操作系统 传统的计算机系统资源分为硬件资源和软件资源。硬件资源包括中央处理器,存储器,输入设备,输出设备等物理设备;软件资源是以文件形式保存在存储器上的成熟和数据等信息。 操作系统就是计算机系统资源的管理者。 如果你的计…...
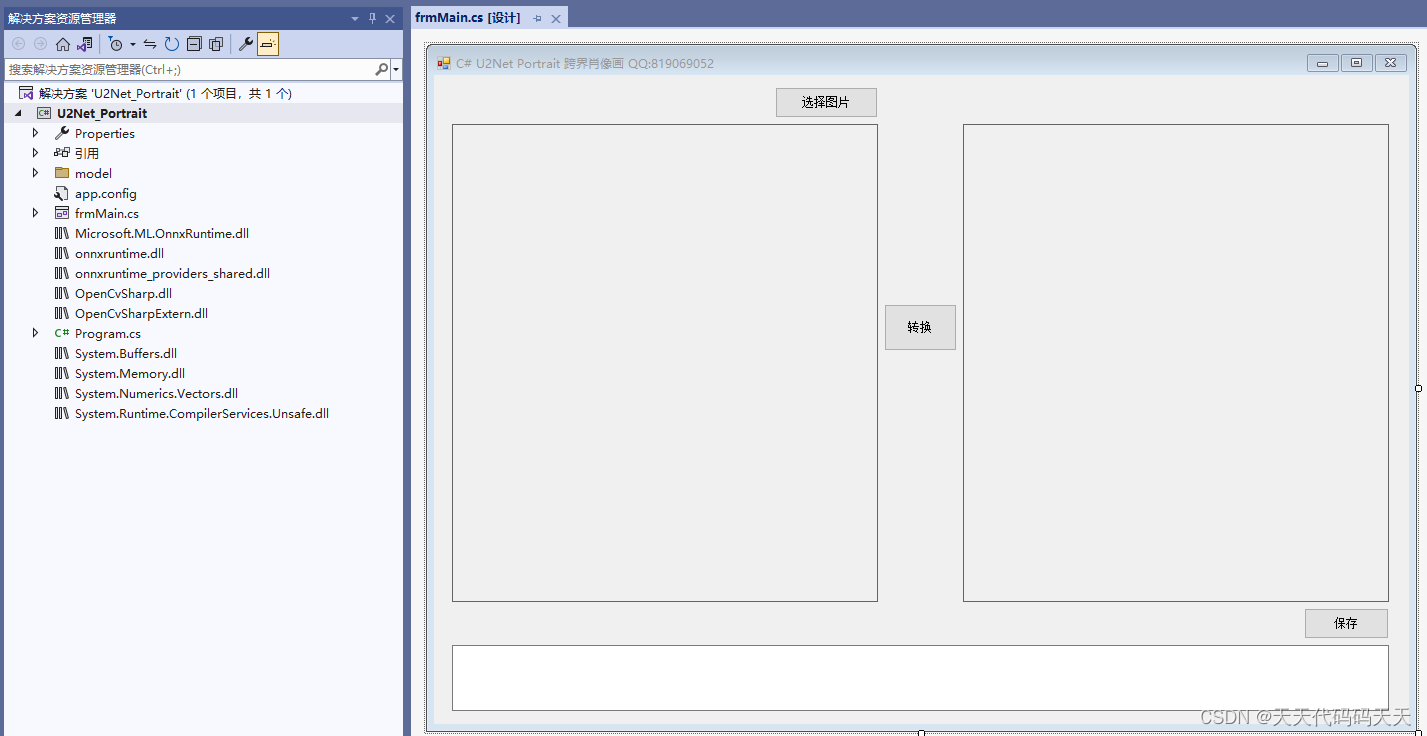
C# U2Net Portrait 跨界肖像画
效果 项目 下载 可执行文件exe下载 源码下载...
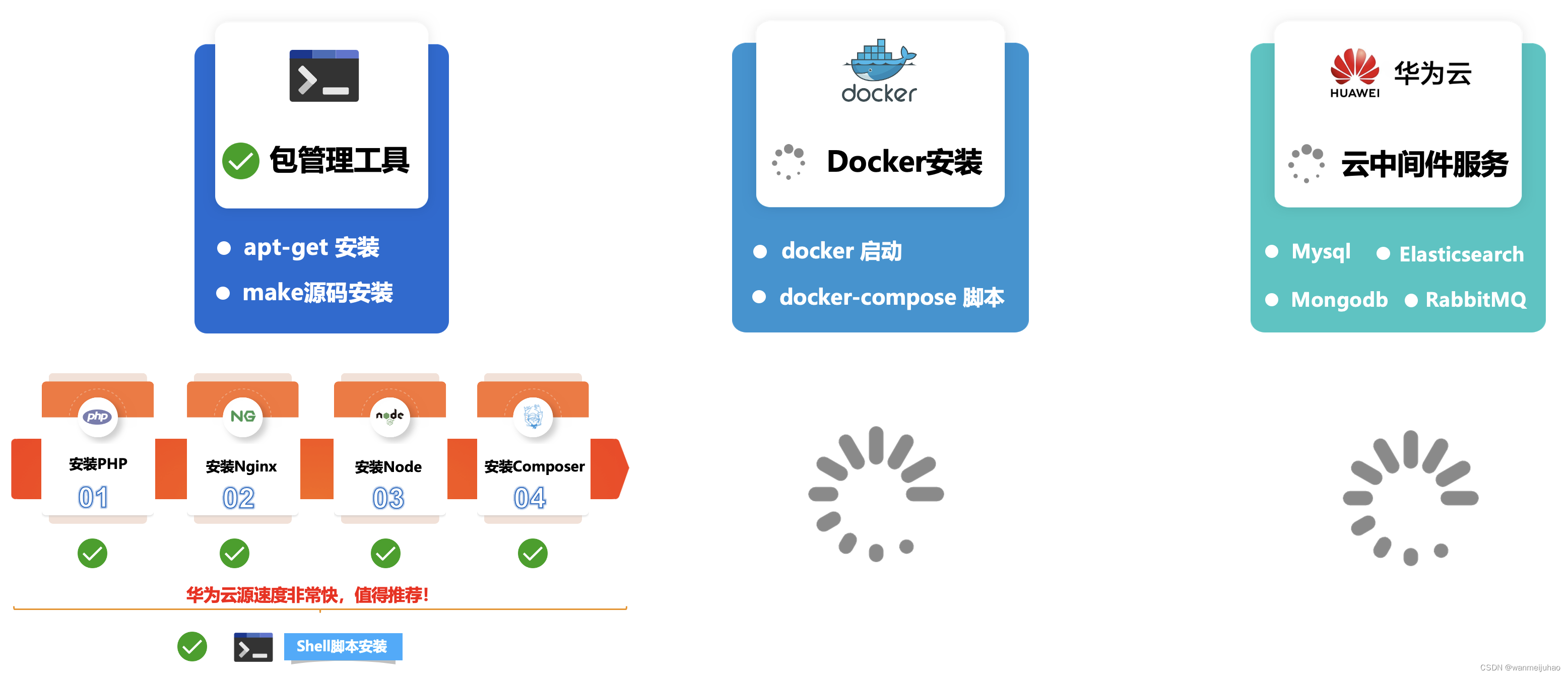
华为云云耀云服务器L实例评测|华为云耀云服务器L实例评测包管理工具安装软件(六)
七、华为云耀云服务器L实例评测包管理工具安装软件: 根据企业级项目架构图所示,本章主要是安装公司企业项目的基本环境LNMP,相关的包管理器Composer、Node、Npm、Yarn安装,评测一下包管理工具安装软件是否存在问题,如果…...

在PYTHON中用zlib模块对文本进行压缩,写入图片的EXIF中,后在C#中读取EXIF并用SharpZipLib进行解压获取压缩前文本
在PYTHON中用zlib模块对文本进行压缩长度,写入图片的EXIF中,并在C#中读取EXIF后用SharpZipLib进行解压缩获取压缩前文本。 PS:当压缩后的字节数组长度为单数时,无法写入EXIF的XPComment中,需要在后面增加一个以utf-8编码的空格&a…...
centos / oracle Linux 常用运维命令讲解
目录 1.shell linux常用目录: 2.命令格式 3.man 帮助 4.提示符 5.echo输出字符串或变量值 6.date显示及设置系统的时间或日期 7.重启系统 8.关闭系统 9.登录注销 10.wget 下载文件 11.ps 查看系统的进程 12.top动态监视进程信息和系统负载等信息 13.l…...
EMNLP 2023 录用论文公布,速看NLP各领域最新SOTA方案
EMNLP 2023 近日公布了录用论文。 开始前以防有同学不了解这个会议,先简单介绍介绍:EMNLP 是NLP 四大顶会之一,ACL大家应该都很熟吧,EMNLP就是由 ACL 下属的SIGDAT小组主办的NLP领域顶级国际会议,一年举办一次。相较于…...
)
用Python手把手复现灰狼算法GWO:从狩猎行为到代码实现(附完整源码)
用Python手把手复现灰狼算法GWO:从狩猎行为到代码实现(附完整源码) 灰狼优化算法(Grey Wolf Optimizer, GWO)作为一种新兴的群体智能算法,正逐渐在工程优化、机器学习参数调优等领域崭露头角。与传统的遗传…...

从特征稀缺到精准定位:基于HS-FPN与可变形注意力的白细胞检测新范式
1. 白细胞检测的现状与挑战 在医学影像分析领域,白细胞检测一直是个让人头疼的问题。想象一下,医生需要从密密麻麻的血细胞图像中找出白细胞,就像在沙滩上找特定形状的贝壳一样困难。传统方法主要依赖医生手动操作显微镜,不仅效率…...

告别龟速传输:在AutoDL上利用AutoPanel高效迁移大容量数据集的实战技巧
1. 为什么大容量数据集传输总是慢如蜗牛? 每次在AutoDL上处理大容量数据集时,最让人抓狂的就是漫长的传输等待。我清楚地记得第一次尝试上传15GB图像数据集时的绝望——整整6个小时的等待,期间还因为网络波动失败了两次。后来才发现ÿ…...

零基础玩转Linux:CentOS安装、Xshell连接与文件权限全攻略
零基础玩转Linux:CentOS安装、Xshell连接与文件权限全攻略 目录 1、Linux系统简介 2、安装Linux 3、Linux相关配制 3.1 配制静态IP 3.2 安装Linux终端 3.3 安装ftp 3.4、Linux目录结构 4、Linux基本命令 4.1、关机与重启 4.2、文件与目录 4.3、日期与日历 4.4、帮助指令 4.5、…...

白盒测试覆盖题
先贴完整逻辑代码java运行if (温度 < 高温值 && 温度 > 低温值) {显示正常温度; // 分支1 } else {if (温度 > 高温值) {高温报警; // 分支2} else {低温报警; // 分支3}蜂鸣警报; // 分支4 }先定义 3 个条件A:温度<高温值B&am…...

WorkshopDL:打破平台壁垒,免费获取Steam创意工坊模组的终极方案
WorkshopDL:打破平台壁垒,免费获取Steam创意工坊模组的终极方案 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic、GOG等平台购买的游戏无法使…...

Display Driver Uninstaller:显卡驱动清理的终极解决方案
Display Driver Uninstaller:显卡驱动清理的终极解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uninstall…...

我给 Codex 加上 Superpowers 和 OpenSpec 后,才开始真正理解 AI Coding 工作流
上一篇我写了 Codex 怎么参与 Good Plan 的开发过程。 那篇文章里,我真正想说的不是“Codex 帮我写了多少代码”,而是另一个感受:AI coding 真的进入项目以后,最考验人的地方,往往不是写代码本身,而是问题…...

OpenWebUI智能管道:连接本地AI模型与高性能推理后端
1. 项目概述:一个连接OpenWebUI与本地AI模型的智能管道最近在折腾本地大语言模型(LLM)的朋友,估计都绕不开OpenWebUI(原名Ollama WebUI)这个项目。它提供了一个极其美观、功能强大的Web界面,让我…...

终极Fansly下载指南:5步快速掌握高效内容保存技巧
终极Fansly下载指南:5步快速掌握高效内容保存技巧 【免费下载链接】fansly-downloader Easy to use fansly.com content downloading tool. Written in python, but ships as a standalone Executable App for Windows too. Enjoy your Fansly content offline anyt…...