NLP项目:维基百科文章爬虫和分类【02】 - 语料库转换管道
一、说明
我的NLP项目在维基百科条目上下载、处理和应用机器学习算法。相关上一篇文章中,展示了项目大纲,并建立了它的基础。首先,一个 Wikipedia 爬网程序对象,它按名称搜索文章,提取标题、类别、内容和相关页面,并将文章存储为纯文本文件。其次,一个语料库对象,它处理完整的文章集,允许方便地访问单个文件,并提供全局数据,如单个令牌的数量。
二、背景介绍
在本文中,我将继续展示如何创建一个NLP项目,以从其机器学习领域对不同的维基百科文章进行分类。你将了解如何创建自定义 SciKit Learn 管道,该管道使用 NLTK 进行标记化、词干提取和矢量化,然后应用贝叶斯模型来应用分类。所有代码也可以在Jupyter Notebook中看到。
本文的技术背景是 Python v3.11 和几个附加库,最重要的是 pandas v2.0.1、scikit-learn v1.2.2 和 nltk v3.8.1。所有示例也应该适用于较新的版本。
2.1 需求和使用的 Python 库
请务必阅读并运行上一篇文章的要求,以便有一个 Jupyter 笔记本来运行所有代码示例。
对于本文,需要以下库:这些步骤中的每一个都将成为管道对象的一部分,管道对象是读取、预处理、矢量化和聚类文本的顺序过程。我们将在此项目中使用以下 Python 库和对象:
pandas
DataFrame用于存储文本、标记和矢量的对象
sk-learn
Pipeline对象实现处理步骤链BaseEstimator并生成表示管道步骤的自定义类TransformerMixin
NLTK
- PlaintextCorpusReader 用于可遍历对象,可访问文档、提供标记化方法并计算有关所有文件的统计信息
- sent_tokenizer 和 word_tokenizer 用于生成令牌
- 减少标记的stopword列表
2.2 SciKit Learn Pipeline
为了便于获得一致的结果和轻松定制,SciKit Learn 提供了 Pipeline 对象。该对象是一系列转换器、实现拟合fit和transform变换方法的对象以及实现拟合fit方法的最终估计器。执行管道对象意味着调用每个转换器来修改数据,然后将最终的估计器(机器学习算法)应用于此数据。管道对象公开其参数,以便可以更改超参数,甚至可以跳过整个管道步骤。
我们将使用此概念来构建一个管道,该管道开始创建语料库对象,然后预处理文本,然后提供矢量化,最后提供聚类或分类算法。为了突出本文的范围,我将在下一篇文章中仅解释转换器步骤,并接近聚类和分类。
三、管道准备
让我们从大局开始。最终的管道对象将按如下方式实现:
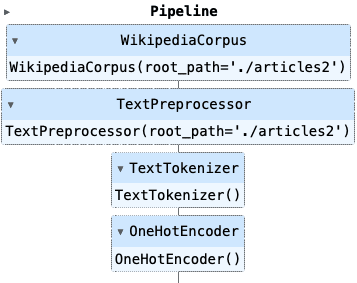
pipeline = Pipeline([('corpus', WikipediaCorpus()),('preprocess', TextPreprocessor()),('tokenizer', Tokenizer()),('encoder', OneHotEncoder())
])然后,此管道从一个空的 Pandas 数据帧对象开始,随后将数据添加到该对象,即我们实现如下所示的数据帧对象:

对于上述每个步骤,我们将使用自定义类,该类从推荐的 ScitKit Learn 基类继承方法。
from sklearn.base import BaseEstimator, TransformerMixin
from nltk.tokenize import sent_tokenize, word_tokenizeclass SciKitTransformer(BaseEstimator, TransformerMixin):def fit(self, X=None, y=None):return selfdef transform(self, X=None):return self让我们开始实现。
3.1 管道步骤 1:创建语料库
第一步是重用上一篇文章中解释的 Wikipedia 语料库对象,并将其包装在基类中,并提供两个 DataFrame 列 title 和 raw。在标题列中,我们存储除 .txt 扩展名之外的文件名。在原始列中,我们存储文件的完整内容。
此转换使用列表推导式和 NLTK 语料库读取器的内置方法。
class WikipediaCorpus(PlaintextCorpusReader):def __init__(self, root_path):PlaintextCorpusReader.__init__(self, root_path, r'.*')class WikipediaCorpus(SciKitTransformer):def __init__(self, root_path=''):self.root_path = root_pathself.corpus = WikipediaReader(self.root_path)def transform(self, X=None):X = pd.DataFrame().from_dict({'title': [filename.replace('.txt', '') for filename in self.corpus.fileids()],'raw': [self.corpus.raw(doc) for doc in corpus.fileids()]})return X3.2 管道步骤 2:文本预处理
在 NLP 应用程序中,通常会检查原始文本中不需要的符号,或者可以删除的停用词,甚至应用词干提取和词形还原。
对于维基百科的文章,我决定将文本分成句子和标记,而不是标记转换,最后将它们重新组合在一起。转换如下:
- 删除所有停用词
- 删除所有非ASCII字母,非数字标记
- 仅保留 .,以及用于序列分隔
,;. - 使用单个空格删除所有出现的多个空格
这是 TextPreprocessor 的完整实现。 DataFrame 对象使用 Pandas apply 方法预处理的新列进行扩展。
class TextPreprocessor(SciKitTransformer):def __init__(self, root_path=''):self.root_path = root_pathself.corpus = WikipediaReader(self.root_path)self.tokenizer = word_tokenizedef preprocess(self, text):preprocessed = ''for sent in sent_tokenize(text):if not len(sent) <= 3:text = ' '.join([word for word in word_tokenize(sent) if not word in stopwords.words("english")])text = re.sub('[^A-Za-z0-9,;\.]+', ' ', text)text = re.sub(r'\s+', ' ', text)# preserve text tokenstext = re.sub(r'\s\.', '.', text)text = re.sub(r'\s,', ',', text)text = re.sub(r'\s;', ';', text)# remove all non character, non number charspreprocessed += ' '+ text.strip()return preprocesseddef transform(self, X):X['preprocessed'] = X['raw'].apply(lambda text: self.preprocess(text))return X3.3 管道步骤 3-标记化
现在,使用与之前相同的 NLT word_tokenizer 对预处理后的文本进行再次标记化,但可以使用不同的标记化器实现进行交换。
和以前一样,通过在预处理列上使用 apply 来扩展 DataFrame,添加一个新列 tokens。
class TextTokenizer(SciKitTransformer):def preprocess(self, text):return [token.lower() for token in word_tokenize(text)]def transform(self, X):X['tokens'] = X['preprocessed'].apply(lambda text: self.preprocess(text))return X3.4 管道步骤 4:编码器
对标记化文本进行编码是矢量化的先导。为了使本文保持重点,我将提供一种相当简单的编码方法,该方法计算所有文本的完整词汇表,并对特定文章中出现的所有单词进行独热编码。词汇表的基础是错误的:我使用精炼标记列表作为输入,但也可以使用NLTK-CorpusReader对象中的vocab方法。
class OneHotEncoder(SciKitTransformer):def encode(self, token_series, tokens):one_hot = {}for _, token_list in token_series.items():for token in token_list:one_hot[token] = 0for token in tokens:one_hot[token] = 1return one_hotdef transform(self, X):token_list = X['tokens']X['one-hot-encoding'] = X['tokens'].apply(lambda tokens: self.encode(token_list, tokens))return X这种编码非常昂贵,因为每次运行的完整词汇表都是从头开始构建的——这可以在未来的版本中改进。
四、完整的源代码
以下是完整的示例:
import numpy as np
import pandas as pdfrom nltk.tokenize import sent_tokenize, word_tokenize
from nltk.corpus import stopwords
from sklearn.base import TransformerMixin
from sklearn.pipeline import Pipeline
from nltk.corpus.reader.plaintext import CategorizedPlaintextCorpusReader
from nltk.tokenize.stanford import StanfordTokenizerclass WikipediaPlaintextCorpus(PlaintextCorpusReader):def __init__(self, root_path):PlaintextCorpusReader.__init__(self, root_path, r'.*')class SciKitTransformer(BaseEstimator, TransformerMixin):def fit(self, X=None, y=None):return selfdef transform(self, X=None):return selfclass WikipediaCorpus(SciKitTransformer):def __init__(self, root_path=''):self.root_path = root_pathself.wiki_corpus = WikipediaPlaintextCorpus(self.root_path)def transform(self, X=None):X = pd.DataFrame().from_dict({'title': [filename.replace('.txt', '') for filename in self.wiki_corpus.fileids()],'raw': [self.wiki_corpus.raw(doc) for doc in corpus.fileids()]})return Xclass TextPreprocessor(SciKitTransformer):def __init__(self, root_path=''):self.root_path = root_pathself.corpus = WikipediaPlaintextCorpus(self.root_path)def preprocess(self, text):preprocessed = ''for sent in sent_tokenize(text):text = ' '.join([word for word in word_tokenize(sent) if not word in stopwords.words("english")])text = re.sub('[^A-Za-z0-9,;\.]+', ' ', text)text = re.sub(r'\s+', ' ', text)# preserve text tokenstext = re.sub(r'\s\.', '.', text)text = re.sub(r'\s,', ',', text)text = re.sub(r'\s;', ';', text)# remove all non character, non number charspreprocessed += ' '+ text.strip()return preprocesseddef transform(self, X):X['preprocessed'] = X['raw'].apply(lambda text: self.preprocess(text))return Xclass TextTokenizer(SciKitTransformer):def preprocess(self, text):return [token.lower() for token in word_tokenize(text)]def transform(self, X):X['tokens'] = X['preprocessed'].apply(lambda text: self.preprocess(text))return Xclass OneHotEncoder(SciKitTransformer):def encode(self, token_series, tokens):one_hot = {}for _, token_list in token_series.items():for token in token_list:one_hot[token] = 0for token in tokens:one_hot[token] = 1return one_hotdef transform(self, X):token_list = X['tokens']X['one-hot-encoding'] = X['tokens'].apply(lambda tokens: self.encode(token_list, tokens))return Xcorpus = WikipediaPlaintextCorpus('articles2')
pipeline = Pipeline([('corpus', WikipediaCorpus(root_path='./articles2')),('preprocess', TextPreprocessor(root_path='./articles2')),('tokenizer', TextTokenizer()),('encoder', OneHotEncoder())
])管道对象在 Jupyter 笔记本中呈现如下:
五、结论
SciKit Learn Pipeline 对象提供了一种将多个转换和机器学习模型堆叠在一起的便捷方法。所有相关的超参数都可以公开并配置以获得可重复的结果。在本文中,您学习了如何通过四个步骤为 Wikipedia 文章创建文本处理管道:a) WikipediaCorpus 用于访问纯文本文件和全局统计信息(例如单词出现次数),b) TextPreprocessor 用于从文本中删除符号和停用词,c) TextTokenizer从预处理的文本创建标记,d) OneHotEncoder 提供简单的统计,总语料库词汇中的单词出现在特定文章中。下一篇文章将继续如何将标记和编码转换为数值向量表示。
参考资料:塞巴斯蒂安
相关文章:
NLP项目:维基百科文章爬虫和分类【02】 - 语料库转换管道
一、说明 我的NLP项目在维基百科条目上下载、处理和应用机器学习算法。相关上一篇文章中,展示了项目大纲,并建立了它的基础。首先,一个 Wikipedia 爬网程序对象,它按名称搜索文章,提取标题、类别、内容和相关页面&…...
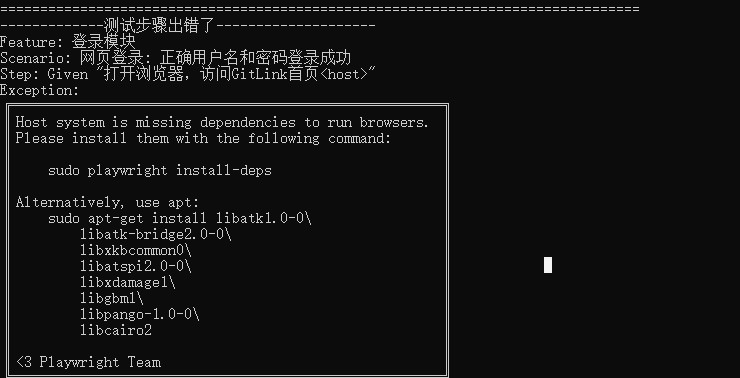
如何在Ubuntu 20.04.6 LTS系统上运行Playwright自动化测试
写在前面 这里以 Ubuntu 20.04.6 LTS为例。示例代码:自动化测试代码。 如果过程中遇到其他非文本中提到的错误,可以使用搜索引擎搜索错误,找出解决方案,再逐步往下进行。 一、 环境准备 1.1 安装python3 1.1.1 使用APT安装Py…...

c++ sort函数cmp比较参数传入
开始 假定有一个结构体 struct node{int p,r,val; };第一种 定义cmp函数,sort直接传入cmp bool cmp(node a,node b){return a.p<b.p;} sort(vec.begin(),vec.end(),cmp);第二种 lamada表达式??这个中括号里面可以不为空,但是…...
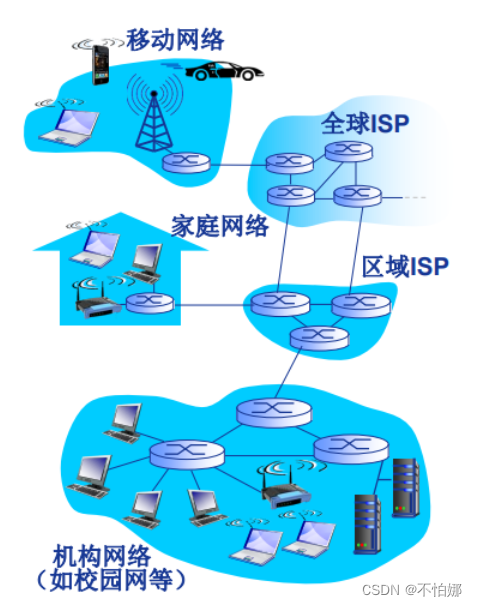
【计算机网络笔记】什么是计算机网络?
前言计算机网络的定义交换网络什么是Internet从组成细节角度看从服务角度看 最后感谢 💖 本篇文章总字数:1342字 预计阅读时间:5~10min 建议收藏之后慢慢阅读 前言 计算机网络通信技术计算机技术。 计算机网络是通信技术与计算机技术紧密结…...

极简C++(2) 类与对象
类与对象的基本概念 CLASS类将数据以及数据上的操作封装在一起 OBJECT对象是有具体类类型的变量 打个比方,类就像一个制作月饼的摸具,那么我们可以通过这个摸具来放入面粉和馅料编程一个月饼,那么摸具就是类,而各种各样的月饼便是…...

【Java 进阶篇】JavaScript流程控制语句详解
JavaScript是一门高级编程语言,具备丰富的流程控制语句,用于控制程序的执行流程。在本篇博客中,我们将深入探讨JavaScript的流程控制语句,包括条件语句、循环语句、以及其他一些控制语句。这篇博客将逐步介绍这些概念,…...
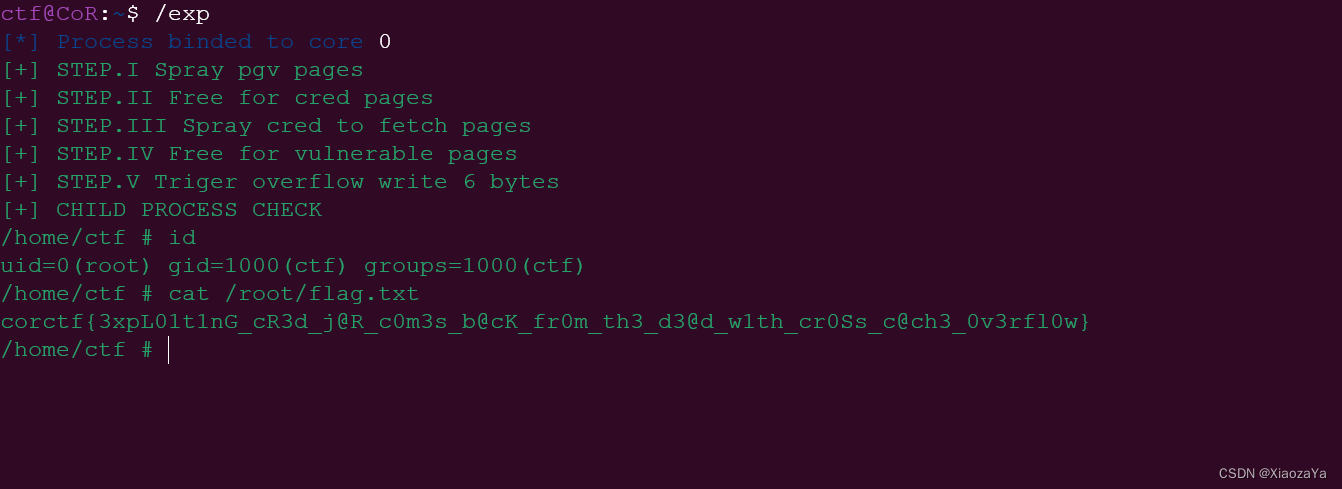
【Page-level Heap Fengshui -- Cross-Cache Overflow】corCTF2022-cache-of-castaways
前言 什么叫 Cross Cache 呢?其实就是字面意思,我们知道内核中的大部分结构体都有自己的专属 slab 内存池。那现在我们可以想象一下这个场景,我们拥有一个特定 kmem-cache 的溢出漏洞,那么我们该如何利用呢? 程序分析…...
vue-mixin
1.vue中,混入(mixin)是一种特殊的使用方式。一个混入对象可以包含任意的组件配置选项(data, props, components, watch,computed…)可以根据需求"封装"一些可复用的单元,并在使用时根据一定的策略合并到组件的选项中,使用时和组件自…...

力扣刷题 day43:10-13
1.完全平方数 给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。 完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 …...

3、在docker 容器中安装tomcat
1、在服务器上查找tomcat镜像,查看前5条 docker search tomcat --limit 5 2、拉取镜像到本地 拉取官方的tomcat到本地 docker pull tomcat:9.0.34-jdk8 3、查看本地镜像 docker images |grep tomcat 4、启动tomcat 服务 使用默认配置 docker ru…...

工业互联网系列1 - 智能制造中有哪些数据在传输
工业互联网以网络为基础,需要传输的数据种类多种多样,这些数据对于实时监控、生产优化、设备维护和决策支持等方面都至关重要。 以下是一些常见智能制造业中需要传输的数据类型: 传感器数据:制造设备上安装的传感器(如…...
centos7部署Nginx和RabbitMQ
文章目录 Nginx安装部署【简单】简介安装 RabbitMQ安装部署【简单】简介安装 Nginx安装部署【简单】 简介 Nginx (engine x) 是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。Nginx可以托管用户编写的WEB应用程序成为可访问的网页服务&am…...
Nacos集群搭建
Nacos集群搭建 1.集群结构图 Nacos集群图: 其中包含3个nacos节点,然后一个负载均衡器代理3个Nacos。这里负载均衡器可以使用nginx。 三个nacos节点的地址: 节点ipportnacos1192.168.150.18845nacos2192.168.150.18846nacos3192.168.150…...
运维小工具分享
1.windwos时间同步工具 通过NetTime软件同步 通过一个免费的同步时间软件来进行对时操作 软件官网链接:http://timesynctool.com/ 修改Windows主机时间,修改时间,时间差为10年、3年、4月份、24小时、2小时、1分钟;都可以及时与“…...
Eclipse插件安装版本不兼容问题解决方案——Papyrus插件为例
项目场景: Eclipse Papyrus安装后,没有新建Papyrus工程选项,也没有新建Papyrus Model的选项。 打开Papyrus Model会报错 问题描述 同样的,安装其他插件也是。可能某个插件之前安装是好用的,结果Eclipse的版本更新了,就再也安装不好用了 原因分析: 根本原因是因为包之…...

【Qt之QTimer】使用及技巧
简介 QTimer是Qt中的定时器类,用于执行定时操作,如在一段时间间隔后触发某个槽函数或执行特定的代码。它提供了灵活的定时功能,可以用于处理各种时间相关的任务。它是基于Qt的事件循环机制工作的。 主要函数说明 构造函数: QTim…...
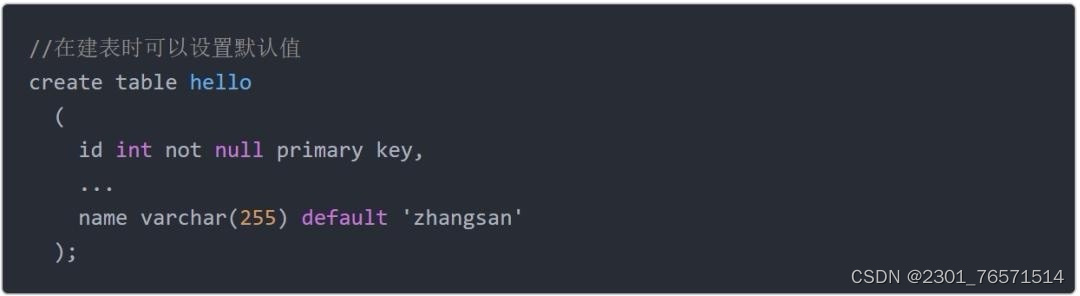
零基础快速自学SQL,2天足矣。
此文是《10周入门数据分析》系列的第6篇。 想了解学习路线,可以先行阅读“ 学习计划 | 10周入门数据分析 ” 上一篇分享了数据库的基础知识,以及如何安装数据库,今天这篇分享数据库操作和SQL。 SQL全称是 Structured Query Language&#x…...

Meta开源数字水印Stable Signature,极大增强生成式AI安全
全球社交、科技巨头Meta(Facebook、Instagram等母公司)在官网宣布,开源数字水印产品Stable Signature,并公开论文。 据悉,Stable Signature是由Meta和INRIA(法国国家信息与自动化研究所)联合开…...

python实现分词器
在Python中实现分词有很多方法,具体取决于你的应用场景和数据。下面我会介绍一种常用的分词库——jieba。如果你的数据是英文,你也可以使用nltk库。 中文分词 使用jieba进行中文分词: 首先,你需要安装jieba库。如果还未安装&am…...
第五十二章 学习常用技能 - Global 映射
文章目录 第五十二章 学习常用技能定义数据库定义命名空间Global映射 第五十二章 学习常用技能 定义数据库 创建本地数据库: 登录管理门户。选择系统管理 > 配置 > 系统配置 > 本地数据库。选择创建新数据库以打开数据库向导。输入新数据库的以下信息&a…...

【2026年5月16日最新】别再用Cursor了!这5款AI编程神器让我效率暴涨300%
2026年5月,AI编程工具迎来了史诗级更新潮。OpenAI发布GPT-5.5后,代码理解和工程重构能力达到历史最强;字节跳动Trae凭借全链路AI原生IDE和免费无限制政策迅速崛起;DeepSeek V4更是用极致算法效率撕开了算力铁幕 。作为一名每天和代…...

顶伯知识竞赛系统 · 核心功能列表
🚀 顶伯知识竞赛系统 核心功能列表专业 高效 让知识竞赛组织更简单🎯 核心优势速览⏱️ 高效:传统方式2-3天的准备工作,2-3小时完成🎯 精准:系统自动计分、自动判定抢答,零误差🎨…...

VMware Unlocker 3.0技术深度解析:如何在非苹果硬件上运行macOS虚拟机的实现原理与实战指南
VMware Unlocker 3.0技术深度解析:如何在非苹果硬件上运行macOS虚拟机的实现原理与实战指南 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker VMware Unlocker 3.0是一个专门为VMware Worksta…...

C#面向对象封装详解:从字段到属性,为什么要用属性?
封装详解:从字段到属性1. 什么是封装封装是指隐藏类的内部实现细节,仅对外提供安全的访问接口,通过控制数据的读写操作来确保数据安全性。其核心目的是保护类中重要的内部数据。2. 字段直接暴露的问题当直接使用字段而不定义属性时࿰…...

OpenVort开源文本嵌入引擎:本地化部署与语义搜索实战指南
1. 项目概述与核心价值最近在折腾一些需要处理大量文本数据的项目,比如日志分析、文档摘要生成,或者是想给自己的应用加个智能问答功能,总是绕不开一个核心环节:如何高效、准确地将非结构化的文本转换成机器能理解的向量。这个“向…...

企业内如何通过Taotoken实现大模型API的统一管理与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内如何通过Taotoken实现大模型API的统一管理与审计 对于需要将大模型能力集成到内部系统的企业而言,直接让各个团队…...

【困难】字符串匹配问题-Java:递归解法
分享一个大牛的人工智能教程。零基础!通俗易懂!风趣幽默!希望你也加入到人工智能的队伍中来!请轻击人工智能教程大家好!欢迎来到我的网站! 人工智能被认为是一种拯救世界、终结世界的技术。毋庸置疑&#x…...

zen-rails-security-checklist测试策略:安全测试用例与自动化扫描
zen-rails-security-checklist测试策略:安全测试用例与自动化扫描 【免费下载链接】zen-rails-security-checklist Checklist of security precautions for Ruby on Rails applications. 项目地址: https://gitcode.com/gh_mirrors/ze/zen-rails-security-checkli…...

SoC与SoM:硬件开发的效率革命与双刃剑效应
1. 项目概述:当“系统”成为商品从业十几年,从画第一块51单片机的板子,到参与设计复杂的通信基站,我亲眼见证了硬件开发模式的剧变。如果说早些年我们还在为如何把CPU、内存、Flash、各种接口控制器塞进一块PCB而绞尽脑汁…...

DirectX12画三角形时,GPU命令队列、围栏和资源屏障到底在干嘛?
DirectX12画三角形时,GPU命令队列、围栏和资源屏障到底在干嘛? 当你在DirectX12中成功绘制出第一个三角形时,可能已经注意到代码中充斥着命令队列、围栏和资源屏障这些概念。它们不像顶点着色器那样直观,却构成了D3D12异步渲染架构…...