ElasticSearch搜索引擎:常用的存储mapping配置项 与 doc_values详细介绍
一、ES的数据存储结构:
ES底层使用 Lucene 存储数据,Lucene 的索引包含以下部分:
A Lucene index is made of several components: an inverted index, a bkd tree, a column store (doc values), a document store (stored fields) and term vectors, and these components can communicate thanks to these doc ids.
其中:
inverted index:倒排索引。
bkd tree: Block k-d tree,用于在高维空间内做索引,如地理坐标的索引。
column store:doc values,列式存储,批量读取连续的数据以提高排序和聚合的效率。
document store:Store Fileds,行式存储文档,用于控制 doc 原始数据的存储,其中占比最大的是 source 字段。
term vectors:用于存储各个词在文档中出现的位置等信息。
二、ES常见配置项说明:
在很多场合下,我们并不需要存储上述全部信息,因此可以通过设置 mappings 里面的属性来控制哪些字段是我们需要存储的、哪些是不需要存储的。而 ES 的 mapping 中有很多设置选项,这些选项如果设置不当,有的可能浪费存储空间,有的可能导致无法使用 Aggregation,有的可能导致不能检索。下面就简单介绍下 ES 中常见的存储与检索的 mapping 配置项:
| 配置项 | 作用 | 注意事项 | 默认值 |
|---|---|---|---|
| _all | 提供跨字段全文检索 | (1)会占用额外空间,把 mapping 中的所有字段通过空格拼接起来做索引,在跨字段全文检索才需要打开; (2)在 v6.0+已被弃用,v7.0会正式移除,可以使用 [copy_to] 来自定义组合字段 | 关闭 |
| _source | 存储 post 提交到ES的原始 json 内容 | (1)会占用很多存储空间。数据压缩存储,读取会有额外解压开销。(2)不需要读取原始字段内容可以考虑关闭,但关闭后无法 reindex | 开启 |
| store | 是否单独存储该字段 | (1)会占用额外存储空间,与 source 独立,同时开启 store 和 source 则会将该字段原始内容保存两份,不同字段单独存储,不同字段的数据在磁盘上不连续,若读取多个字段则需要查询多次,如需读取多个字段,需权衡比较 source 与 store 效率 | 关闭 |
| doc_values | 支持排序、聚合 | 会占用额外存储空间,与 source 独立,同时开启 doc_values 和 _source 则会将该字段原始内容保存两份。doc_values 数据在磁盘上采用列式存储,关闭后无法使用排序和聚合 | 开启 |
| index | 是否加入倒排索引 | 关闭后无法对其进行搜索,但字段仍会存储到 _source 和 doc_values,字段可以被排序和聚合 | 开启 |
| enabled | 是否对该字段进行处理 | 关闭后,只在 _source中存储,类似 index 与 doc_values 的总开关 | 开启 |
在ES的 mapping 设置里,all,source 是 mapping 的元数据字段(Meta-Fields),store、doc_values、enabled、index 是 mapping 参数。
1、_all:
all 字段的作用是提供跨字段查询的支持,把 mapping 中的所有字段通过空格拼接起来做索引。ES在查询的过程中,需要指定在哪一个field里面查询。
{“name”: “smith”,“email”: "John@example.com"
}
用户在查询时,想查询叫做 John 的人,但不知道 John 出现在 name 字段中还是在 email 字段中,由于ES是为每一个字段单独建立索引,所以用户需要以 John 为关键词发起两次查询,分别查询name字段和email字段。
如果开启了 all 字段,则ES会在索引过程中创建一个虚拟的字段 all,其值为文档中各个字段拼接起来所组成的一个很长的字符串(例如上面的例子,all 字段的内容为字符串 “smith John@example.com”)。随后,该字段将被分词打散,与其他字段一样被收入倒排索引中。由于 all 字段包含了所有字段的信息,因此可以实现跨字段的查询,用户不用关心要查询的关键词在哪个字段中。
由于该字段的内容都来自 source 字段,因此默认情况下,该字段的内容并不会被保存,可以通过设置 store 属性来强制保存 all 字段。开启 all 字段,会带来额外的CPU开销和存储,如果没有使用到,可以关闭 all 字段。
2、_source:
source 字段用于存储 post 到 ES 的原始 json 文档。为什么要存储原始文档呢?因为 ES 采用倒排索引对文本进行搜索,而倒排索引无法存储原始输入文本。一段文本交给ES后,首先会被分析器(analyzer)打散成单词,为了保证搜索的准确性,在打散的过程中,会去除文本中的标点符号,统一文本的大小写,甚至对于英文等主流语言,会把发生形式变化的单词恢复成原型或词根,然后再根据统一规整之后的单词建立倒排索引,经过如此一番处理,原文已经面目全非。因此需要有一个地方来存储原始的信息,以便在搜到这个文档时能够把原文返回给查询者。
那么一定要存储原始文档吗?不一定!如果没有取出整个原始 json 结构体的需求,可以在 mapping 中关闭 source 字段或者只在 source 中存储部分字段(使用store)。 但是这样做有些负面影响:
(1)不能获取到原文
(2)无法reindex:如果存储了 source,当 index 发生损坏,或需要改变 mapping 结构时,由于存在原始数据,ES可以通过原始数据自动重建index,如果不存 source 则无法实现
(3)无法在查询中使用script:因为 script 需要访问 source 中的字段
3、store:
store 决定一个字段是否要被单独存储。大家可能会有疑问,source 里面不是已经存储了原始的文档嘛,为什么还需要一个额外的 store 属性呢?原因如下:
(1)如果禁用了 source 保存,可以通过指定 store 属性来单独保存某个或某几个字段,而不是将整个输入文档保存到 source 中。
(2)如果 source 中有长度很长的文本(如一篇文章)和较短的文本(如文章标题),当只需要取出标题时,如果使用 source 字段,ES需要读取整个 source 字段,然后返回其中的 title,由此会引来额外的IO开销,降低效率。此时可以选择将 title 的 store 设置为true,在 source 字段外单独存储一份。读取时不必在读取整 source 字段了。但是需要注意,应该避免使用 store 查询多个字段,因为 store 的存储在磁盘上不连续,ES在读取不同的 store 字段时,每个字段的读取均需要在磁盘上进行查询操作,而使用 source 字段可以一次性连续读取多个字段。
4、doc_values:
倒排索引可以提供全文检索能力,但是无法提供对排序和数据聚合的支持。doc_values 本质上是一个序列化的列式存储结构,适用于聚合(aggregations)、排序(Sorting)、脚本(scripts access to field)等操作。默认情况下,ES几乎会为所有类型的字段存储doc_value,但是 text 或 text_annotated 等可分词字段不支持 doc values 。如果不需要对某个字段进行排序或者聚合,则可以关闭该字段的doc_value存储。
5、index:
控制倒排索引,用于标识指定字段是否需要被索引。默认情况下是开启的,如果关闭了 index,则该字段的内容不会被 analyze 分词,也不会存入倒排索引,即意味着该字段无法被搜索。
6、enabled:
这是一个 index 和 doc_value 的总开关,如果 enabled 设置为false,则这个字段将会仅存在于 source 中,其对应的 index 和 doc_value 都不会被创建。这意味着,该字段将不可以被搜索、排序或者聚合,但可以通过 source 获取其原始值。
7、term_vector:
在对文本进行 analyze 的过程中,可以保留有关分词结果的相关信息,包括单词列表、单词之间的先后顺序、单词在原文中的位置等信息。查询结果返回的高亮信息就可以利用其中的数据来返回。默认情况下,term_vector是关闭的,如有需要(如加速highlight结果)可以开启该字段的存储。
三、doc_values 详细说明:
1、doc_values 的作用:
基于 lucene 的 solr 和 es 都是使用倒排索引实现快速检索的,也就是通过建立 “搜索关键词 ==>文档ID列表” 的关系映射实现快速检索,但是倒排索引也是有缺陷的,比如我们需要字段值做一些排序、分组、聚合操作,lucene 内部会遍历提取所有出现在文档集合的排序字段,然后再次构建一个最终的排好序的文档集合list,这个步骤的过程全部维持在内存中操作,而且如果排序数据量巨大的话,非常容易就造成solr内存溢出和性能缓慢。
doc values 就是在构建倒排索引时,会对开启 doc values 的字段额外构建一个有序的 "document文档 ==> field value“ 的列式存储映射,从而实现对指定字段进行排序和聚合时对内存的依赖,提升该过程的性能。默认情况下每个字段的 doc values 都是开启的,当然 doc values 也会耗费一定的磁盘空间。
另外 doc values 保存在操作系统的磁盘中,当 doc values 大于节点的可用内存,ES 可以从操作系统页缓存中加载或弹出,从而避免发生 JVM 内存溢出的异常,docValues 远小于节点的可用内存,操作系统自然将所有Doc Values存于内存中(堆外内存),有助于快速访问。
2、doc_values 与 source 的区别?使用 docvalue_fields 检索指定的字段?
post 提交到 ES 的原始 Json 文档都存储在 source 字段中,默认情况下,每次搜索的命中结果都包含文档 source,即使仅请求少量字段,也必须加载并解析整个 source 对象,而 source 每次使用时都必须加载和解析,所以使用 source 非常慢。为避免该问题,当我们只需要返回相当少的支持 doc_values 的字段时,可以使用 docvalue_fields 参数获取选定字段的值。
doc values 存储与 _source 相同的值,但在磁盘上基于列的结构中进行了优化,以进行排序和汇总。由于每个字段都是单独存储的,因此 Elasticsearch 仅读取请求的字段值,并且可以避免加载整个文档 _source。通过 docvalue_fields 可以从建好的列式存储结果中直接返回字段值,毕竟 source 是从一大片物理磁盘去,理论上从 doc values 处拿这个字段值会比 source 要快一点,页面抖动少一点。
3、如何在 ES 中使用 doc values?
doc values 通过牺牲一定的磁盘空间带来的好处主要有两个:
节省内存
提升排序,分组等聚合操作的性能
那么我们如何使用 doc values 呢?
(1)我们首先关注如何激活 doc values,只要开启 doc values 后,排序,分组,聚合的时候会自动使用 doc values 提速。在 ElasticSearch 中,doc values 默认是开启的,比较简单暴力,我们也可以酌情关闭一些不需要使用 doc values 的字段,以节省磁盘空间,只需要设置 doc_values 为 false 就可以了,如下:
“session_id”:{“type”:“string”,“index”:“not_analyzed”,“doc_values”:false}
(2)使用 docvalue_fields 的检索指定的字段:
GET my-index-000001/_search
{"query": {"match": {"user.id": "kimchy"}},"docvalue_fields": ["user.id","http.response.*", {"field": "date","format": "epoch_millis" }]
}
ES搜索指定字段的不同方式,详情请见官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.x/search-fields.html#search-fields
————————————————
版权声明:本文为CSDN博主「张维鹏」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/a745233700/article/details/117915118
相关文章:

ElasticSearch搜索引擎:常用的存储mapping配置项 与 doc_values详细介绍
一、ES的数据存储结构: ES底层使用 Lucene 存储数据,Lucene 的索引包含以下部分: A Lucene index is made of several components: an inverted index, a bkd tree, a column store (doc values), a document store (stored fields) and te…...

[Spring]事务的传播机制
一、背景 Mysql在修改完数据后,默认会自动触发事务Commit提交。 而在我们服务的一个方法里,需要多次修改Mysql记录。 为了保证原子性,我们需要将Mysql设为手动提交,多次修改后再commit提交。 二、Spring事务 1、编程式事务管理…...

linux下,如何查看一个文件的哈希值md5以及sha264
在linux终端中,可能存在多个相似的文件,而哈希值可以唯一确定一个文件。文件的哈希值计算可以有以下两种方式,MD5和SHA256,现将两种方式罗列如下: 1、MD5 命令:$ md5sum FileName 一个文件的 MD5 是固定的…...
Java类加载过程
一、前言 我们都知道计算机的底层逻辑都是0和1的编码,当然除了现在所研究的量子计算除外。那么我们在计算机所做的一切操作,底层原理是不是都可以翻译到0和1呢。如果刨根问底的话,可以这么说,当然0和1的表示也属于逻辑门电路电的…...
人脸活体检测技术的应用,有效避免人脸识别容易被攻击的缺陷
随着软件算法和物理终端的进步,人脸识别现在越来越被广泛运用到生活的方方面面,已经成为了重要的身份验证手段,但同时也存在着自身的缺陷,目前常规人脸识别技术可以精准识别目标人像特征,并迅速返回比对结果࿰…...

大数据发展史
一、hadoop发展史 hadoop创始人Doug Cutting,主要为了实现Google类似全文搜索功能,该功能是基于Lucene框架进行优化升级,索引引擎; 2001年底Lucence成为Apache基金会的一个子项目,当时为了解决存储海量数据困难,检索海量速度慢,可以说Google是hadoop的思想之源; GFS…...

有关范数的学习笔记
向量的【范数】:模长的推广,柯西不等式_哔哩哔哩_bilibili 模长 范数 这里UP主给了说明 点赞 范数理解(0范数,1范数,2范数)_一阶范数-CSDN博客 出租车/曼哈顿范数 det()行列式 正定矩阵(Posit…...

如何通过MES系统提高生产计划效率?
导 读 ( 文/ 1730 ) 在现代制造业中,通过制造执行系统(MES)系统来提高生产计划效率是至关重要的。本文将介绍如何通过MES系统来优化生产计划,包括实时数据分析、智能排程和协同协作。通过这些关键方法,企业可以提高生产…...

持续提升信息安全运维保障服务能力,天玑科技助力企业快速实现数字化转型
近年来,以互联网、云计算、大数据、物联网为代表的新一代信息技术快速发展。给人们的生产生活方式带来方便的同时,也给信息系统的安全带来了严峻的挑战。我国信息化和信息安全保障工作的不断深入推进,以应急处理、风险评估、灾难恢复、系统测…...
【PostgreSQL启动,停止命令(重启)】
找到 /usr/lib/systemd/system文件夹路径看是否包含 postgresql服务 关闭服务: systemctl stop postgresql-12.service启动服务 systemctl start postgresql-12.service重启服务 systemctl restart postgresql-12查看状态 systemctl status postgresql-12.servi…...
TLS 详解
目录 TLS 定义HTTPS HTTP over TLS.加密记录层分片 (Fragmentation)记录压缩和解压缩 (Record compression and decompression)空或标准流加密 (Null or standard stream cipher)CBC 块加密 (分组加密)记录有效载荷保护 (Record payload protection)密钥计算 (Key calculation…...

【重拾C语言】十、递归程序设计
目录 前言 十、递归程序设计 10.1 计算n!——递归程序设计 10.2 程序设计实例 10.2.1 汉诺塔 10.2.2 齿轮 10.2.3 组合 10.3 计算算术表达式的值——间接递归 10.4 递归程序执行过程 前言 递归程序设计是一种编程技术,其中一个函数通过调用自身…...

SQL日期字段去时分秒
substring( convert(varchar,[申请日期],120),1,10) AS 申请日期 运行结果对比展示 申请日期申请日期2022-12-24 00:00:00.0002022-12-24 说明: substring(...): 这是SQL中用于提取字符串一部分的函数。 convert(varchar, 申请日期, 120): 这部分将日期值&#…...
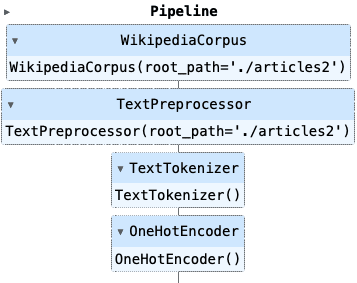
NLP项目:维基百科文章爬虫和分类【02】 - 语料库转换管道
一、说明 我的NLP项目在维基百科条目上下载、处理和应用机器学习算法。相关上一篇文章中,展示了项目大纲,并建立了它的基础。首先,一个 Wikipedia 爬网程序对象,它按名称搜索文章,提取标题、类别、内容和相关页面&…...
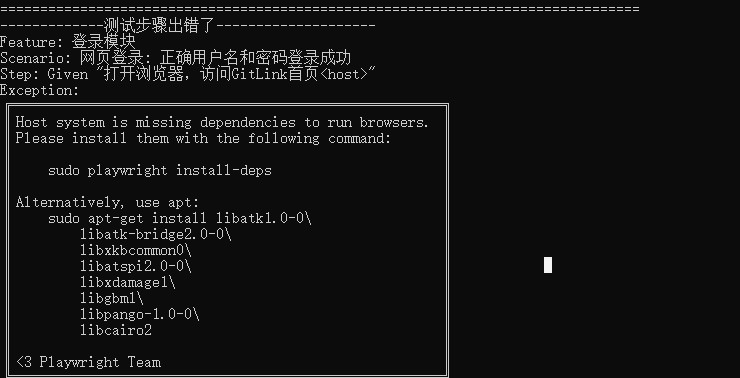
如何在Ubuntu 20.04.6 LTS系统上运行Playwright自动化测试
写在前面 这里以 Ubuntu 20.04.6 LTS为例。示例代码:自动化测试代码。 如果过程中遇到其他非文本中提到的错误,可以使用搜索引擎搜索错误,找出解决方案,再逐步往下进行。 一、 环境准备 1.1 安装python3 1.1.1 使用APT安装Py…...

c++ sort函数cmp比较参数传入
开始 假定有一个结构体 struct node{int p,r,val; };第一种 定义cmp函数,sort直接传入cmp bool cmp(node a,node b){return a.p<b.p;} sort(vec.begin(),vec.end(),cmp);第二种 lamada表达式??这个中括号里面可以不为空,但是…...
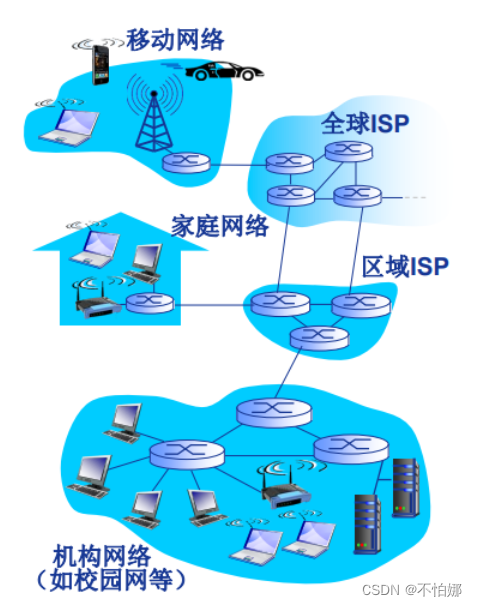
【计算机网络笔记】什么是计算机网络?
前言计算机网络的定义交换网络什么是Internet从组成细节角度看从服务角度看 最后感谢 💖 本篇文章总字数:1342字 预计阅读时间:5~10min 建议收藏之后慢慢阅读 前言 计算机网络通信技术计算机技术。 计算机网络是通信技术与计算机技术紧密结…...

极简C++(2) 类与对象
类与对象的基本概念 CLASS类将数据以及数据上的操作封装在一起 OBJECT对象是有具体类类型的变量 打个比方,类就像一个制作月饼的摸具,那么我们可以通过这个摸具来放入面粉和馅料编程一个月饼,那么摸具就是类,而各种各样的月饼便是…...

【Java 进阶篇】JavaScript流程控制语句详解
JavaScript是一门高级编程语言,具备丰富的流程控制语句,用于控制程序的执行流程。在本篇博客中,我们将深入探讨JavaScript的流程控制语句,包括条件语句、循环语句、以及其他一些控制语句。这篇博客将逐步介绍这些概念,…...
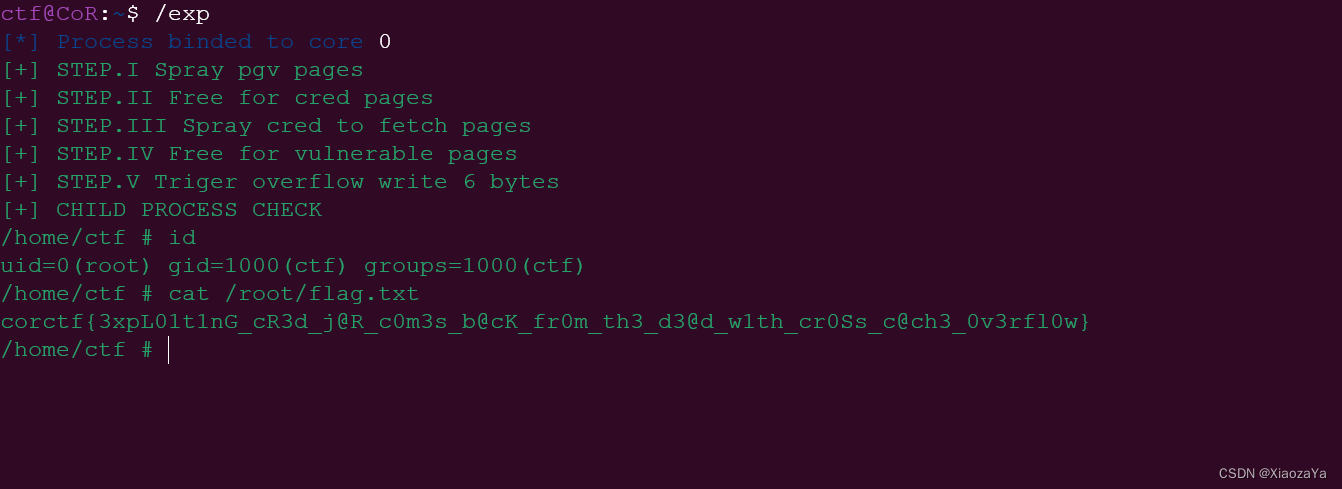
【Page-level Heap Fengshui -- Cross-Cache Overflow】corCTF2022-cache-of-castaways
前言 什么叫 Cross Cache 呢?其实就是字面意思,我们知道内核中的大部分结构体都有自己的专属 slab 内存池。那现在我们可以想象一下这个场景,我们拥有一个特定 kmem-cache 的溢出漏洞,那么我们该如何利用呢? 程序分析…...

告别手动点鼠标!用Python脚本批量跑Simulink仿真,效率提升10倍
告别手动点鼠标!用Python脚本批量跑Simulink仿真,效率提升10倍 在工程仿真领域,Simulink无疑是建模与分析的利器。但当面对参数扫描、蒙特卡洛分析或设计迭代等需要大量重复仿真的场景时,手动操作不仅效率低下,还容易…...

手把手教你用Claude Desktop的MCP协议,5分钟搞定本地SQLite数据库查询
5分钟实现自然语言查询SQLite:Claude Desktop MCP协议实战指南 想象一下这样的场景:你手头有一个存储着上万条商品信息的SQLite数据库,现在需要快速统计某个品类的库存数量。传统方式可能需要打开数据库工具、编写SQL查询语句,或者…...

DanKoe 视频笔记:人生经验课:给18岁自己的信
在本节课中,我们将学习一位28岁人士回顾过去,总结出的核心人生经验。这些经验旨在帮助年轻人,特别是那些感到迷茫、渴望超越平凡生活的人,建立自主性、明确目标并采取有效行动。我们将把这些经验整理成一套清晰的教程,…...

Wan2.2-I2V-A14B效果对比:LSTM时序预测辅助下的动态剧情生成
Wan2.2-I2V-A14B效果对比:LSTM时序预测辅助下的动态剧情生成 1. 引言 想象一下,当你输入一段文字描述,AI不仅能生成对应的视频,还能像专业导演一样把控剧情节奏和情感起伏。这正是Wan2.2-I2V-A14B结合LSTM时序预测技术带来的突破…...

DeepSeek-V3 vs V3-Base:开发者如何根据项目需求选择最适合的模型?
DeepSeek-V3 vs V3-Base:开发者如何根据项目需求选择最适合的模型? 当你在GitHub上搜索代码补全工具,或是在Kaggle上寻找数学竞赛的解题思路时,可能会被各种AI模型的选择搞得眼花缭乱。作为开发者,我们需要的不是"…...

从拒稿到录用:我的TOMM投稿实战复盘与经验分享
1. 从TMM拒稿到TOMM录用的心路历程 第一次收到TMM的拒稿邮件时,我正在实验室熬夜改代码。邮件弹出来的那一刻,整个人就像被泼了一盆冷水。那篇论文已经经历了三轮大修,每次都是几十条审稿意见,我们团队前前后后修改了上百个细节。…...

巧用Google Maps与ScreenToGif:零行程数据也能轻松生成动态路线图
1. 从零开始制作动态路线图的必备工具 最近有个朋友问我:"想给客户展示项目选址的交通路线,但实地考察还没开始,怎么做出专业的动态路线图?"这让我想起自己两年前第一次做商业提案时的窘境——当时为了展示物流配送路线…...

深度解析Windows设备指纹伪装技术:EASY-HWID-SPOOFER内核级硬件隐私保护实现
深度解析Windows设备指纹伪装技术:EASY-HWID-SPOOFER内核级硬件隐私保护实现 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 在数字化时代,硬件隐私保护已成…...
)
别再死记硬背GAT公式了!用Python+PyTorch手把手图解注意力机制(附代码)
图解GAT:用PythonPyTorch拆解图注意力机制的实现奥秘 当你第一次听说图注意力网络(GAT)时,是否被那些复杂的数学公式和抽象概念吓退?本文将以全新的可视化方式,带你从零实现一个完整的GAT层,用代…...

Thorium浏览器:重新定义Chromium性能的颠覆性优化方案
Thorium浏览器:重新定义Chromium性能的颠覆性优化方案 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Windows and MacOS/Raspi/Android/Special builds are in different repositories, links are towards the top of the READM…...