MySQL之双主双从读写分离
准备
| 编号 | IP | 预装软件 | 角色 |
| 1 | 192.168.2.3 | MyCat 、 MySQL | MyCat 中间件服务器、M1 |
| 2 | 192.168.2.4 | MySQL | S1 |
| 3 | 192.168.2.5 | MySQL | M2 |
| 4 | 192.168.2.6 | MySQL | S2 |
关闭以上所有服务器的防火墙:systemctl stop firewalldsystemctl disable firewalld
搭建双主从
主库配置
1.Master1(192.168.2.3)
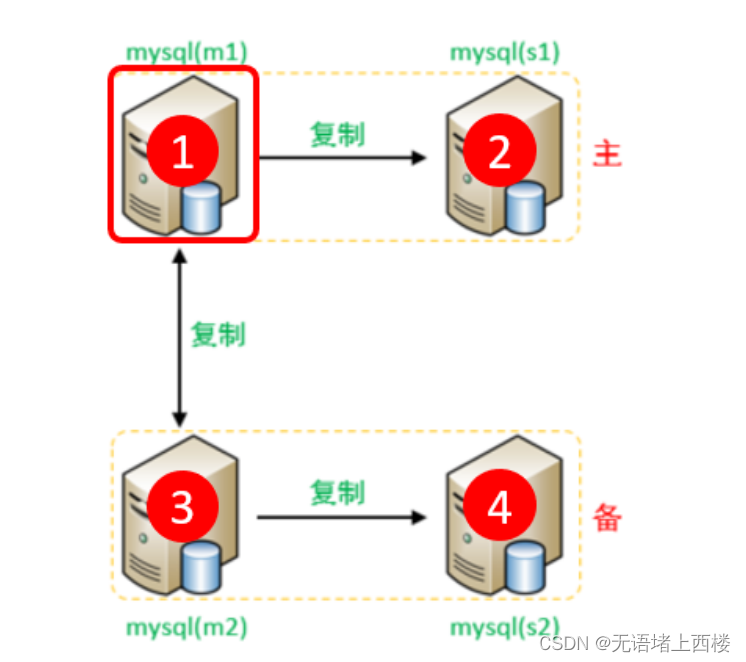
修改配置文件 /etc/my.cnf
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 2^32-1,默认为1
server-id=1
#指定同步的数据库
binlog-do-db=db01
binlog-do-db=db02
binlog-do-db=db03
# 在作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updatessystemctl restart mysqld#创建mytest用户,并设置密码,该用户可在任意主机连接该MySQL服务
CREATE USER 'mytest'@'%' IDENTIFIED WITH mysql_native_password BY 'Root@123456';
#为 'mytest'@'%' 用户分配主从复制权限
GRANT REPLICATION SLAVE ON *.* TO 'mytest'@'%';show master status ;
2.Master2(192.168.2.5)
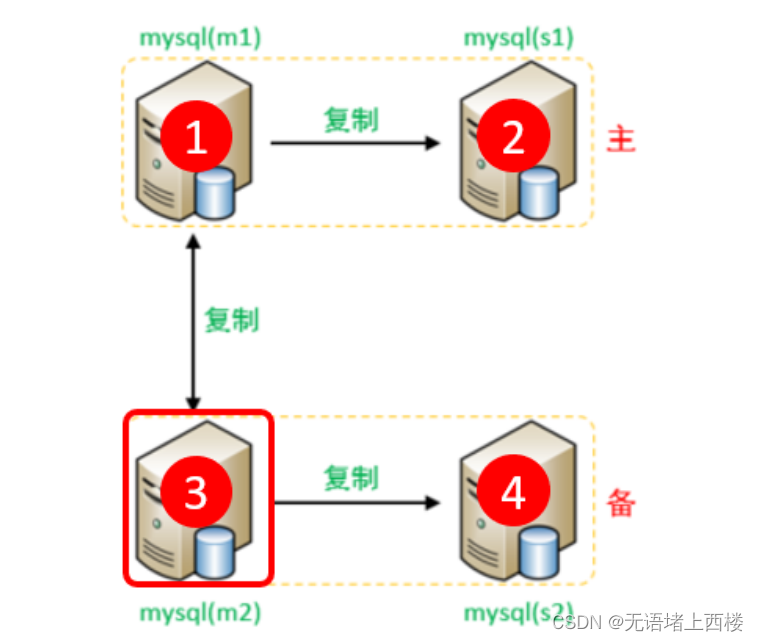
修改配置文件 /etc/my.cnf
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 2^32-1,默认为1
server-id=3
#指定同步的数据库
binlog-do-db=db01
binlog-do-db=db02
binlog-do-db=db03
# 在作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updatessystemctl restart mysqld#创建mytest用户,并设置密码,该用户可在任意主机连接该MySQL服务
CREATE USER 'mytest'@'%' IDENTIFIED WITH mysql_native_password BY 'Root@123456';
#为 'mytest'@'%' 用户分配主从复制权限
GRANT REPLICATION SLAVE ON *.* TO 'mytest'@'%';show master status ;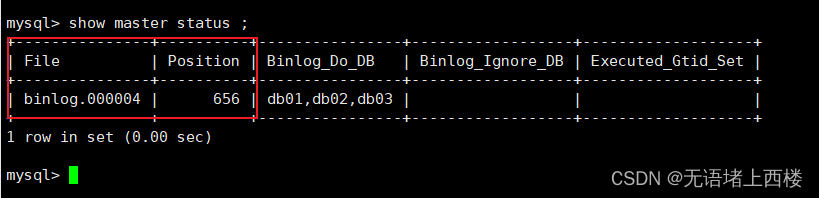
从库配置
1.Slave1(192.168.2.4)
 修改配置文件 /etc/my.cnf
修改配置文件 /etc/my.cnf
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 232-1,默认为1
server-id=2systemctl restart mysqld#创建mytest用户,并设置密码,该用户可在任意主机连接该MySQL服务
CREATE USER 'mytest'@'%' IDENTIFIED WITH mysql_native_password BY 'Root@123456';
#为 'mytest'@'%' 用户分配主从复制权限
GRANT REPLICATION SLAVE ON *.* TO 'mytest'@'%';通过指令,查看两台主库的二进制日志坐标
show master status ;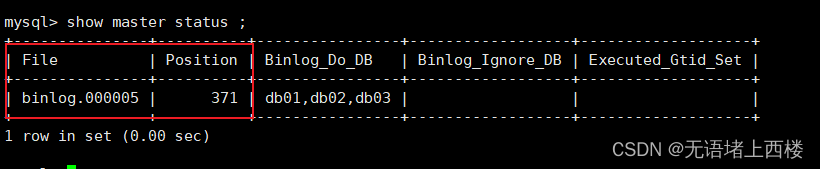
修改配置文件 /etc/my.cnf
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 232-1,默认为1
server-id=4重新启动MySQL服务器
systemctl restart mysqld从库关联主库
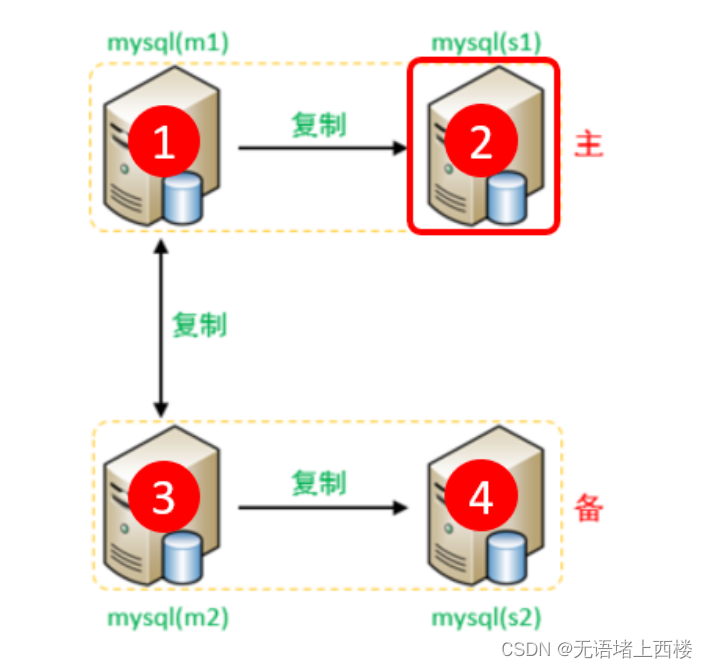
需要注意slave1对应的是master1,slave2对应的是master2。
在 slave1(192.168.2.4)上执行
CHANGE MASTER TO MASTER_HOST='192.168.2.3', MASTER_USER='mytest',
MASTER_PASSWORD='Root@123456', MASTER_LOG_FILE='binlog.000010',
MASTER_LOG_POS=157;CHANGE MASTER TO MASTER_HOST='192.168.2.5', MASTER_USER='mytest',
MASTER_PASSWORD='Root@123456', MASTER_LOG_FILE='binlog.000005',
MASTER_LOG_POS=585;start slave;
show slave status \G;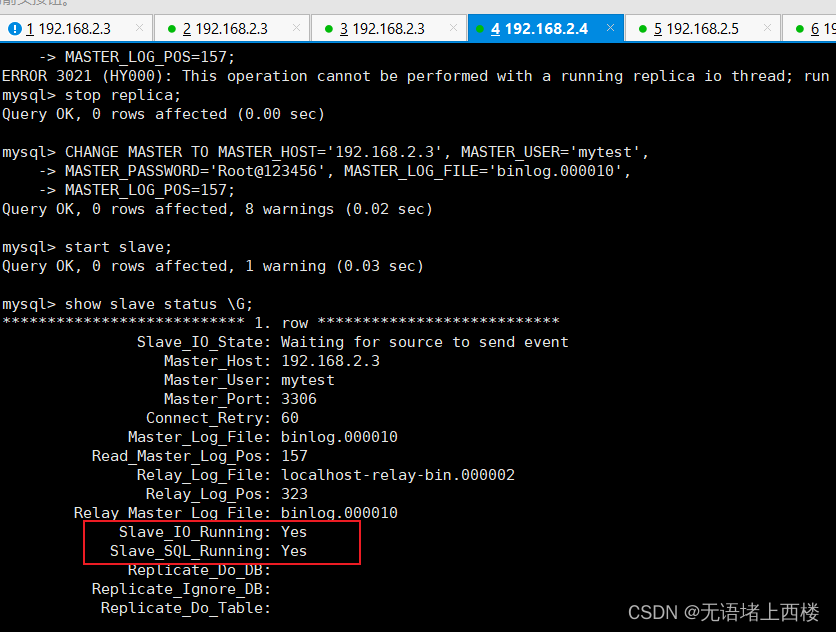
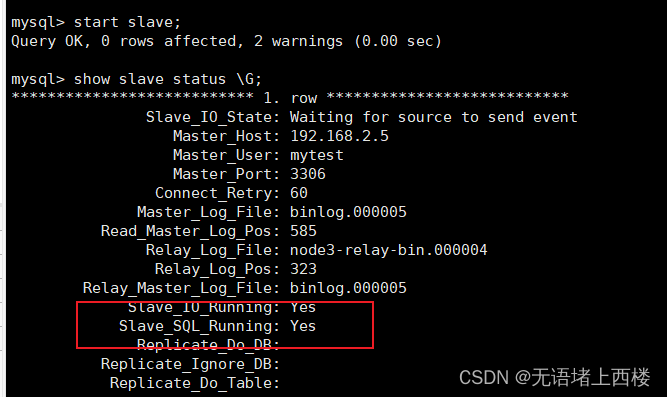
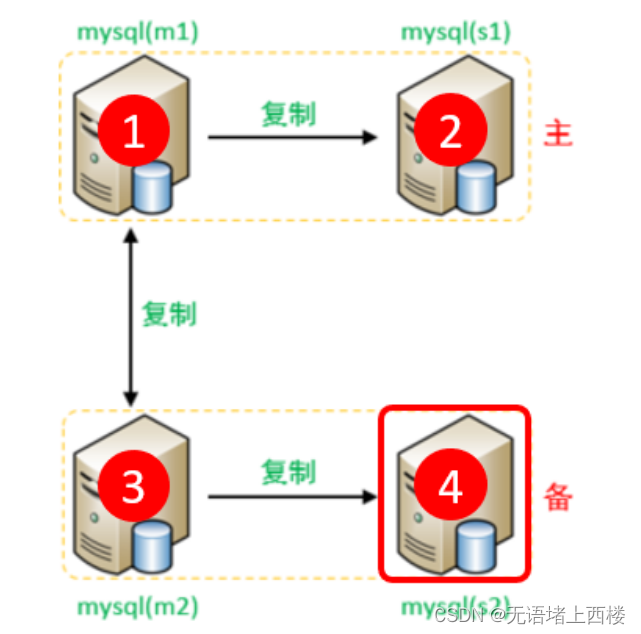
两台主库相互复制
 在 Master1(192.168.2.3)上执行
在 Master1(192.168.2.3)上执行
CHANGE MASTER TO MASTER_HOST='192.168.2.5', MASTER_USER='mytest',
MASTER_PASSWORD='Root@123456', MASTER_LOG_FILE='binlog.000005',
MASTER_LOG_POS=585;CHANGE MASTER TO MASTER_HOST='192.168.2.3', MASTER_USER='mytest',
MASTER_PASSWORD='Root@123456', MASTER_LOG_FILE='binlog.000010',
MASTER_LOG_POS=453;start slave;
show slave status \G;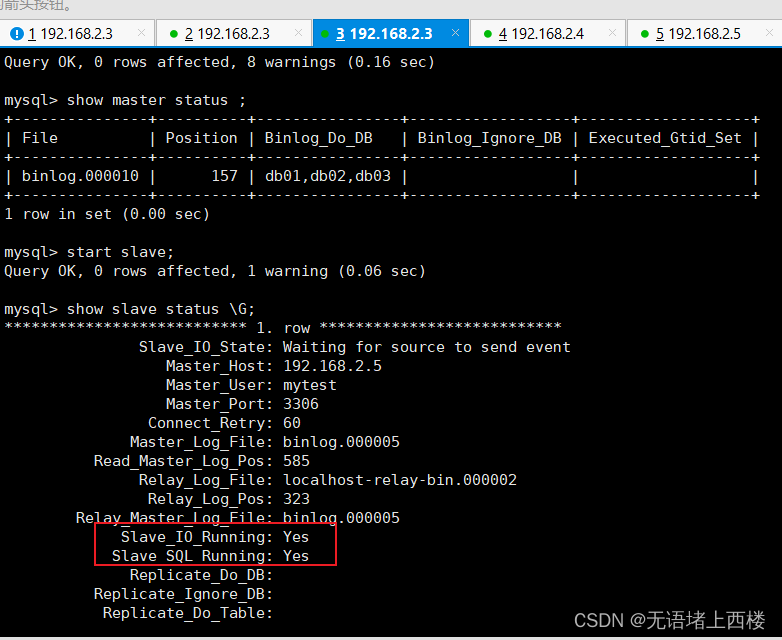
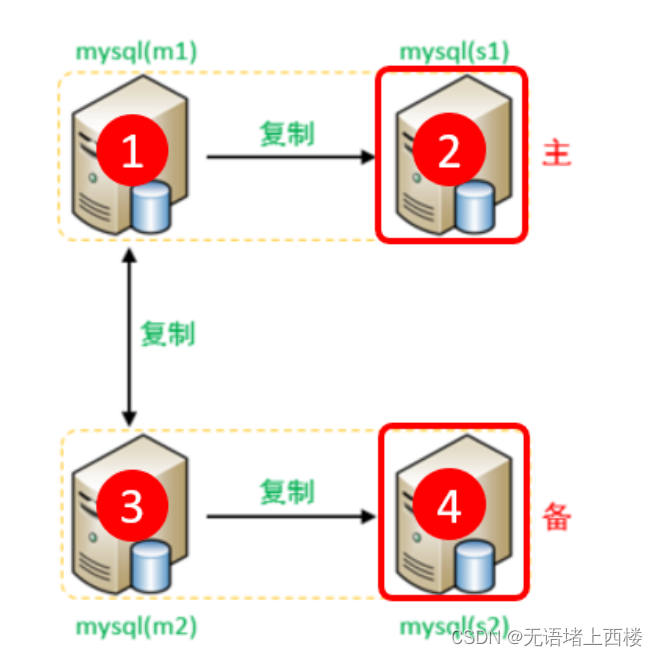
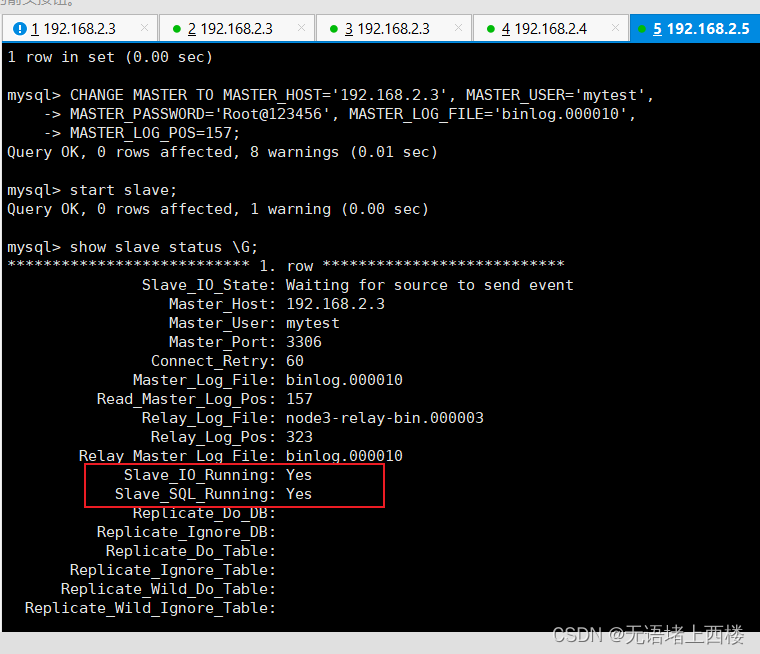 经过上述的配置之后,双主双从的复制结构就已经搭建完成了。 接下来,我们可以来测试验证一下。
经过上述的配置之后,双主双从的复制结构就已经搭建完成了。 接下来,我们可以来测试验证一下。
测试
create database db01;
use db01;
create table tb_user(
id int(11) not null primary key ,
name varchar(50) not null,
sex varchar(1)
)engine=innodb default charset=utf8mb4;insert into tb_user(id,name,sex) values(1,'Tom','1');
insert into tb_user(id,name,sex) values(2,'Trigger','0');
insert into tb_user(id,name,sex) values(3,'Dawn','1');
insert into tb_user(id,name,sex) values(4,'Jack Ma','1');
insert into tb_user(id,name,sex) values(5,'Coco','0');
insert into tb_user(id,name,sex) values(6,'Jerry','1');- 在Master1中执行DML、DDL操作,看看数据是否可以同步到另外的三台数据库中。
- 在Master2中执行DML、DDL操作,看看数据是否可以同步到另外的三台数据库中。
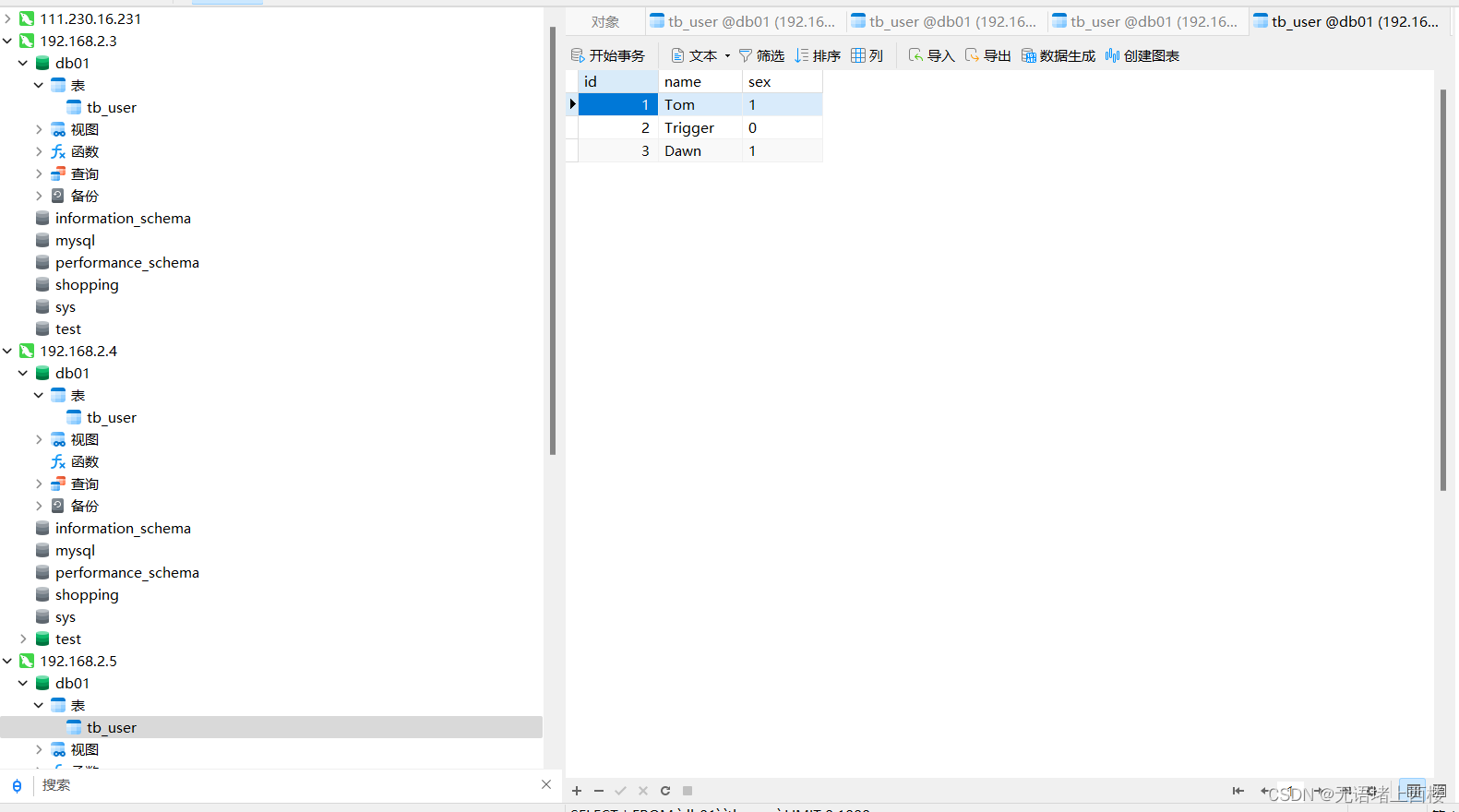
双主双从读写分离
配置
schema.xml
<schema name="TEST_RW2" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn7">
</schema><dataNode name="dn7" dataHost="dhost7" database="db01" /><dataHost name="dhost7" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="master1" url="jdbc:mysql://192.168.2.3:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="newPwd520@" ><readHost host="slave1" url="jdbc:mysql://192.168.2.4:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="newPwd520@" /></writeHost><writeHost host="master2" url="jdbc:mysql://192.168.2.5:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="newPwd520@" ><readHost host="slave2" url="jdbc:mysql://192.168.2.6:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="newPwd520@" /></writeHost></dataHost>| balance="1" | 代表全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1 , M2->S2 ,并且 M1 与 M2 互为主备 ) ,正常情况下,M2,S1,S2 都参与 select 语句的负载均衡 ; |
| writeType | 0 : 写操作都转发到第 1 台 writeHost, writeHost1 挂了 , 会切换到 writeHost2 上 ; 1 : 所有的写操作都随机地发送到配置的 writeHost 上 ; |
| switchType | -1 : 不自动切换 1 : 自动切换 |
user.xml
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TEST_RW2</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="true">
<schema name="DB01" dml="0110" >
<table name="TB_ORDER" dml="1110"></table>
</schema>
</privileges>
-->
</user>重启MyCat
bin/mycat restart测试
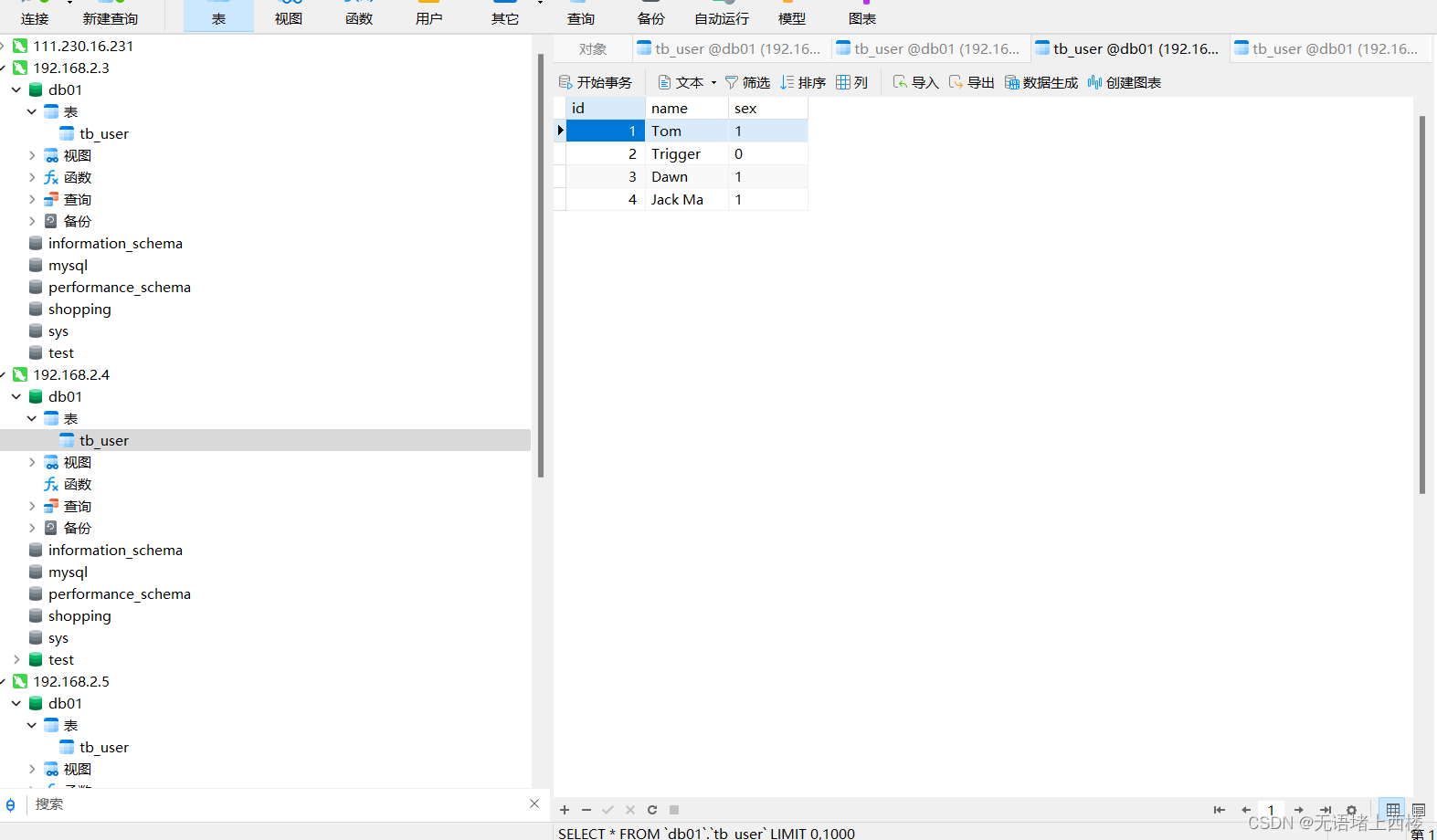
insert into tb_user(id,name,sex) values(4,'Jack Ma','1');插入数据成功
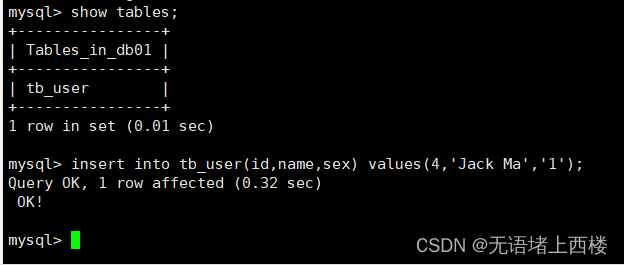
在全部mysql也插入数据成功

然后停掉master1
systemctl stop mysqld再次在mycat插入数据
insert into tb_user(id,name,sex) values(5,'Coco','0');还是成功
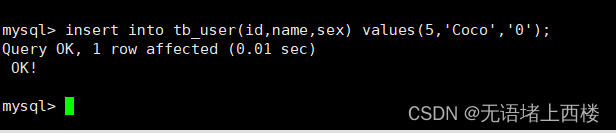
除了master,其他mysql也插入数据成功
相关文章:
MySQL之双主双从读写分离
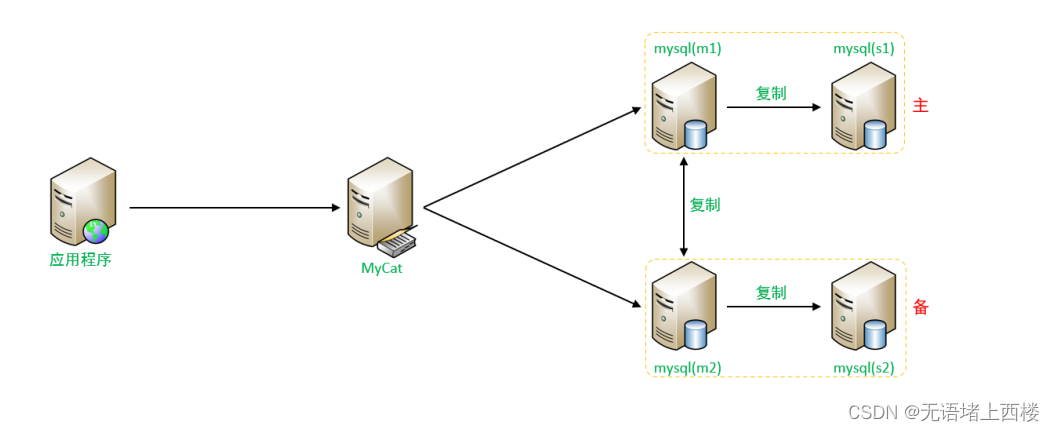
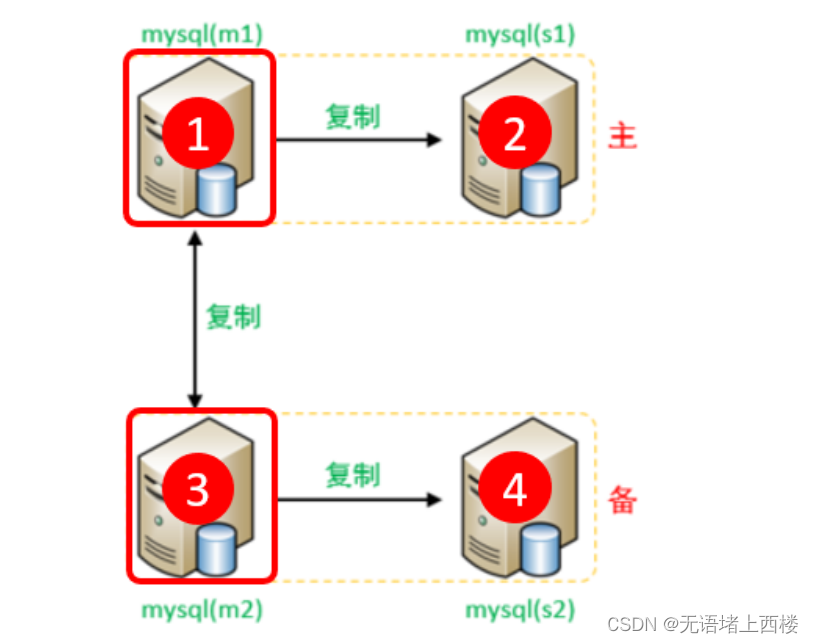
一个主机 Master1 用于处理所有写请求,它的从机 Slave1 和另一台主机 Master2 还有它的从 机 Slave2 负责所有读请求。当 Master1 主机宕机后, Master2 主机负责写请求, Master1 、 Master2 互为备机。架构图如下 : 准备 我们…...
使用eBPF加速阿里云服务网格ASM
背景 随着云原生应用架构的快速发展,微服务架构已经成为了构建现代应用的主要方式之一。而在微服务架构中,服务间的通信变得至关重要。为了实现弹性和可伸缩性,许多组织开始采用服务网格技术来管理服务之间的通信。 Istio作为目前最受欢迎的…...

大型数据集处理之道:深入了解Hadoop及MapReduce原理
在大数据时代,处理海量数据是一项巨大挑战。而Hadoop作为一个开源的分布式计算框架,以其强大的处理能力和可靠性而备受推崇。本文将介绍Hadoop及MapReduce原理,帮助您全面了解大型数据集处理的核心技术。 Hadoop简介 Hadoop是一个基于Google…...
LCR 095. 最长公共子序列(C语言+动态规划)
1. 题目 给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。 一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(…...

程序员不写注释:探讨与反思
一、为什么程序员不写注释 当程序员选择不写注释时,通常有一系列常见原因,这些原因可以影响他们的决策和行为。同时,这个决策可能会带来多方面的影响和后果。以下是详细阐述为什么程序员不写注释的常见原因以及这种决策可能导致的影响和后果…...
《论文阅读:Dataset Condensation with Distribution Matching》
点进去这篇文章的开源地址,才发现这篇文章和DC DSA居然是一个作者,数据浓缩写了三篇论文,第一篇梯度匹配,第二篇数据增强后梯度匹配,第三篇匹配数据分布。DC是匹配浓缩数据和原始数据训练一次后的梯度差,DS…...
免费chatGPT工具
发现很多人还是找不到好用的chatGPT工具,这里分享一个邮箱注册即可免费试用。 PromptsZone - 一体化人工智能平台使用 PromptsZone 与 ChatGPT、Claude、AI21 Labs、Google Bard 聊天,并使用 DALL-E、Stable Diffusion 和 Google Imagegen 创建图像&…...

数据分析基础:数据可视化+数据分析报告
数据分析是指通过对大量数据进行收集、整理、处理和分析,以发现其中的模式、趋势和关联,并从中提取有价值的信息和知识。 数据可视化和数据分析报告是数据分析过程中非常重要的两个环节,它们帮助将数据转化为易于理解和传达的形式࿰…...

settings.xml的文件配置大全
settings.xml 文件中最常配置的还是这几个标签 localRepository和mirrors settings.xml文件官方文档地址 <settings xmlns"http://maven.apache.org/SETTINGS/1.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"ht…...
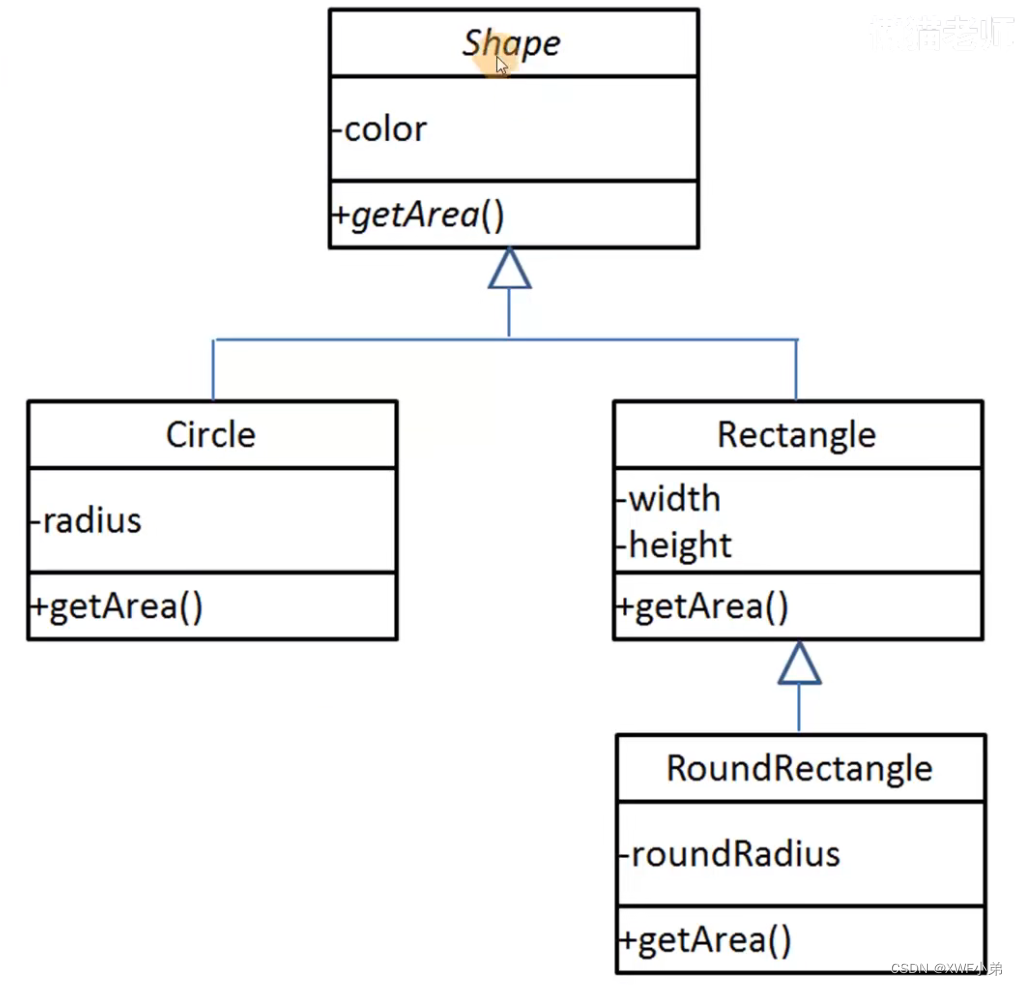
极简c++(7)类的继承
为什么要用继承 子类不必复制父类的任何属性,已经继承下来了;易于维护与编写; 类的继承与派生 访问控制规则 一般只使用Public! 构造函数的继承与析构函数的继承 构造函数不被继承! 在创建子类对象的时候&…...
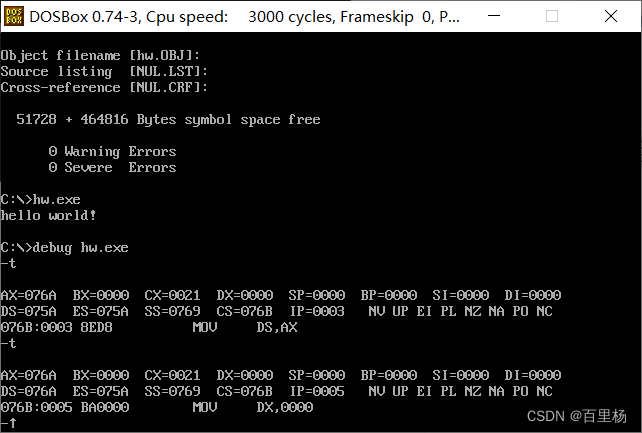
DOSBox和MASM汇编开发环境搭建
DOSBox和MASM汇编开发环境搭建 1 安装DOSBox2 安装MASM3 编译测试代码4 运行测试代码5 调试测试代码 本文属于《 X86指令基础系列教程》之一,欢迎查看其它文章。 1 安装DOSBox 下载DOSBox和MASM:https://download.csdn.net/download/u011832525/884180…...
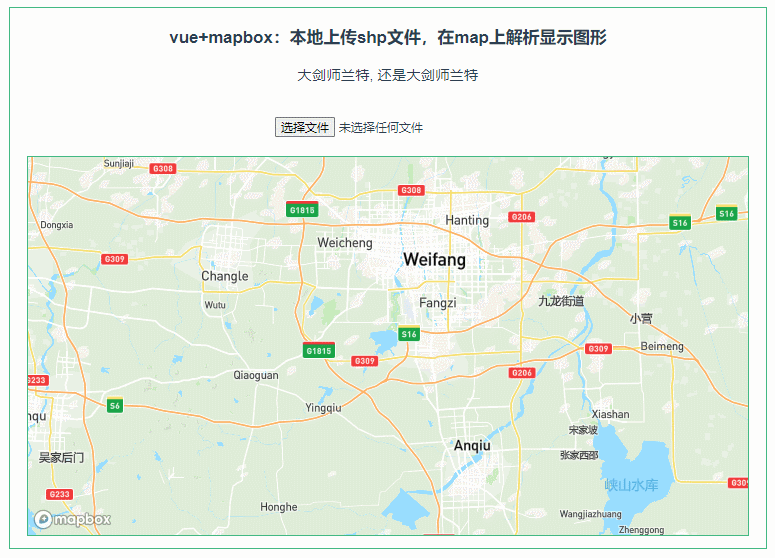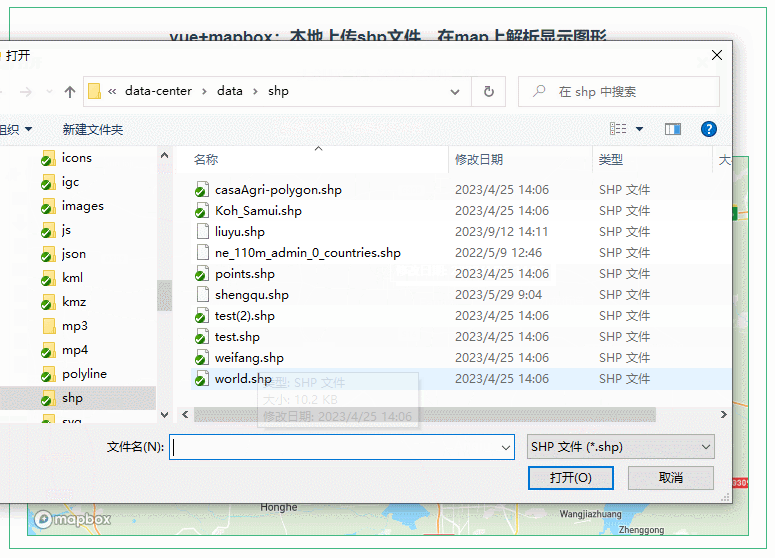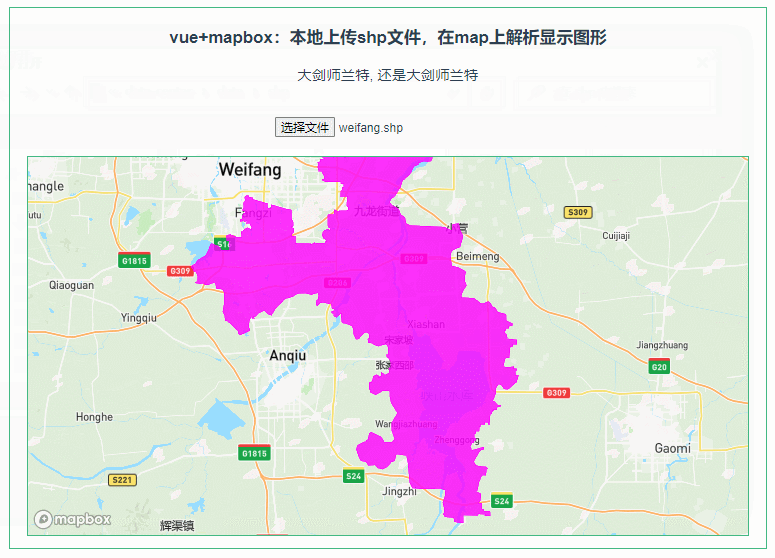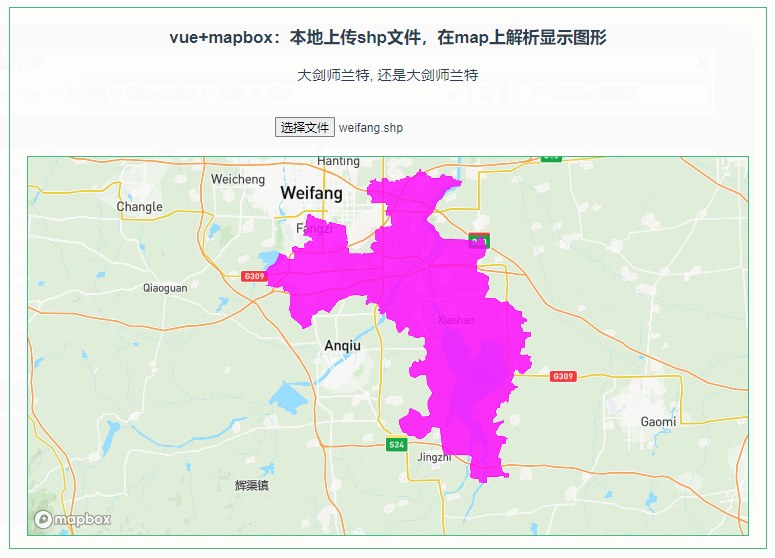
047:mapboxGL本地上传shp文件,在map上解析显示图形
第047个 点击查看专栏目录 本示例的目的是介绍演示如何在vue+mapbox中本地上传shp文件,利用shapefile读取shp数据,并在地图上显示图形。 直接复制下面的 vue+mapbox源代码,操作2分钟即可运行实现效果 文章目录 示例效果配置方式示例源代码(共117行)加载shapefile.js方式…...
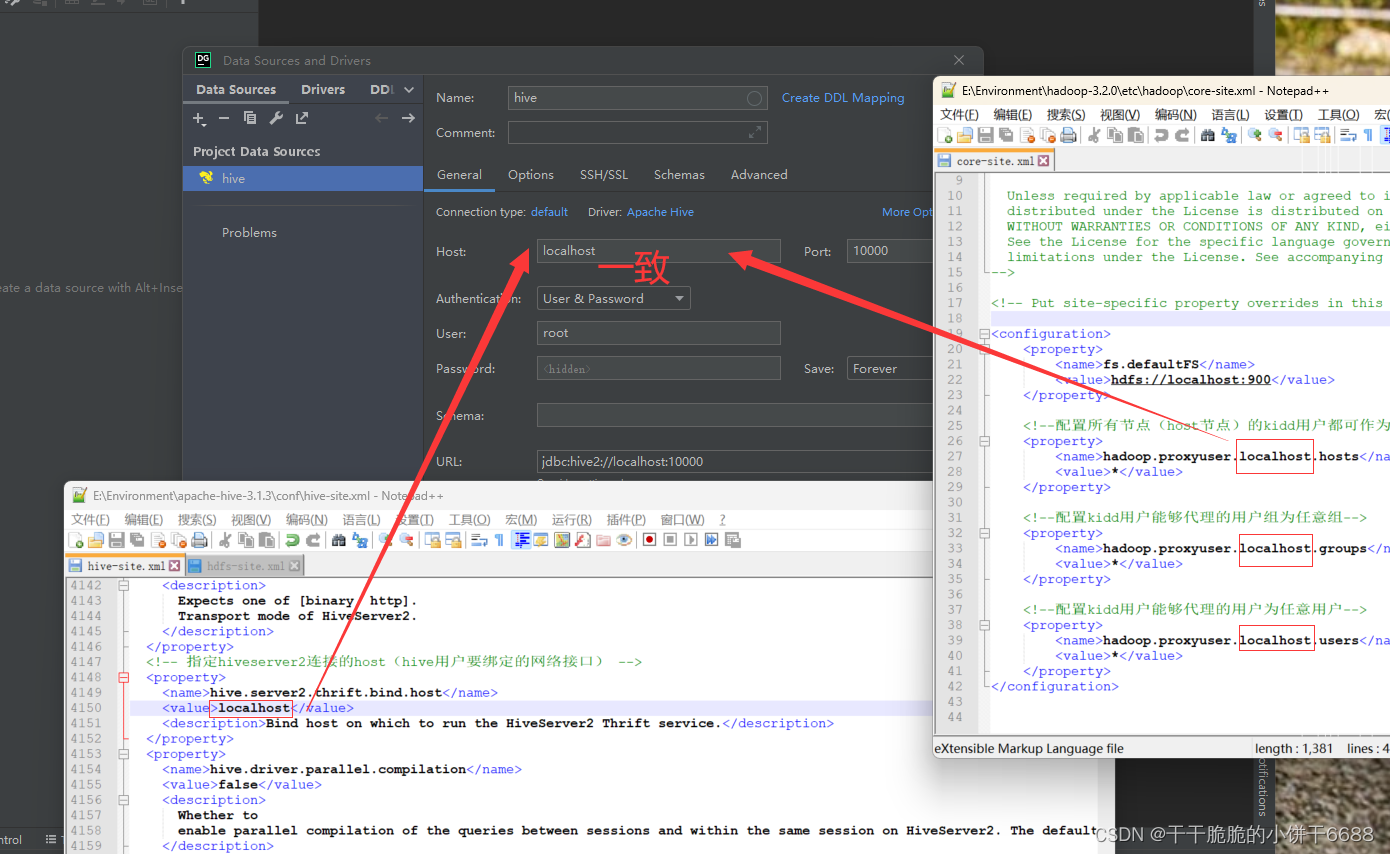
Windows下DataGrip连接Hive
DataGrip连接Hive 1. 启动Hadoop2. 启动hiveserver2服务3. 启动元数据服务4. 启动DG 1. 启动Hadoop 在控制台中输入start-all.cmd后,弹出下图4个终端(注意终端的名字)2. 启动hiveserver2服务 单独开一个窗口启动hiveserver2服务,…...
Xshell7和Xftp7超详细下载教程(包括安装及连接服务器附安装包)
1.下载 1.官网地址: XSHELL - NetSarang Website 选择学校免费版下载 2.将XSHELL和XFTP全都下载下来 2.安装 安装过程就是选择默认选项,然后无脑下一步 3.连接服务器 1.打开Xshell7,然后新建会话 2.填写相关信息 出现Connection establi…...

ASP.net数据从Controller传递到视图
最常见的方式是使用模型或 ViewBag。 使用模型传递数据: 在控制器中,创建一个模型对象,并将数据赋值给模型的属性。然后将模型传递给 View 方法。 public class HomeController : Controller {public IActionResult Index(){// 创建模型对…...

c++ 友元函数 友元类
1. 友元函数 1.1 简介 友元函数是在类的声明中声明的非成员函数,它被授予访问类的私有成员的权限。这意味着友元函数可以访问类的私有成员变量和私有成员函数,即使它们不是类的成员。 一个类中,可以将其他类或者函数声明为该类的友元&#…...

Spring推断构造器源码分析
Spring中bean虽然可以通过多种方式(Supplier接口、FactoryMethod、构造器)创建bean的实例对象,但是使用最多的还是通过构造器创建对象实例,也是我们最熟悉的创建对象的方式。如果有多个构造器时,那Spring是如何推断使用…...
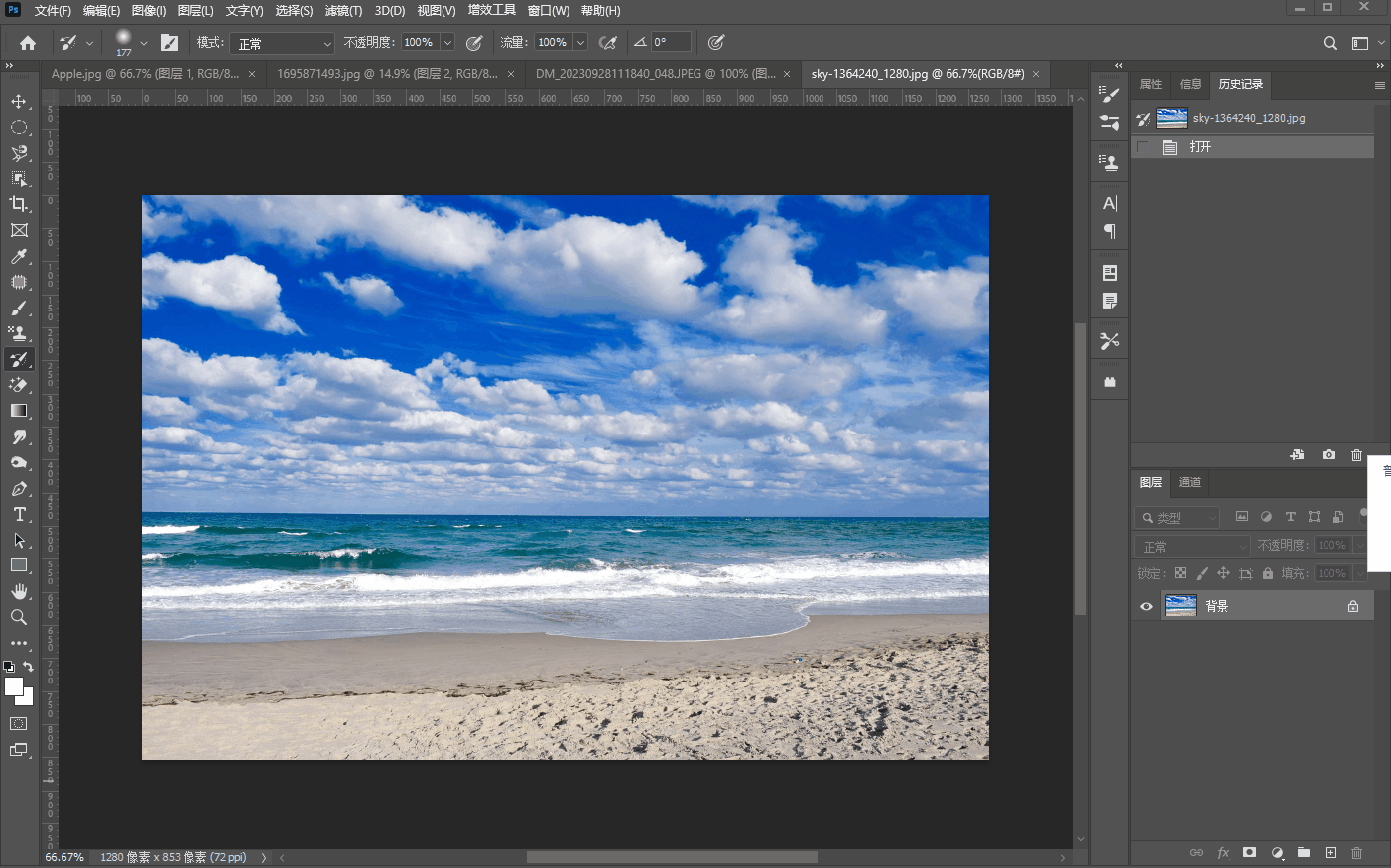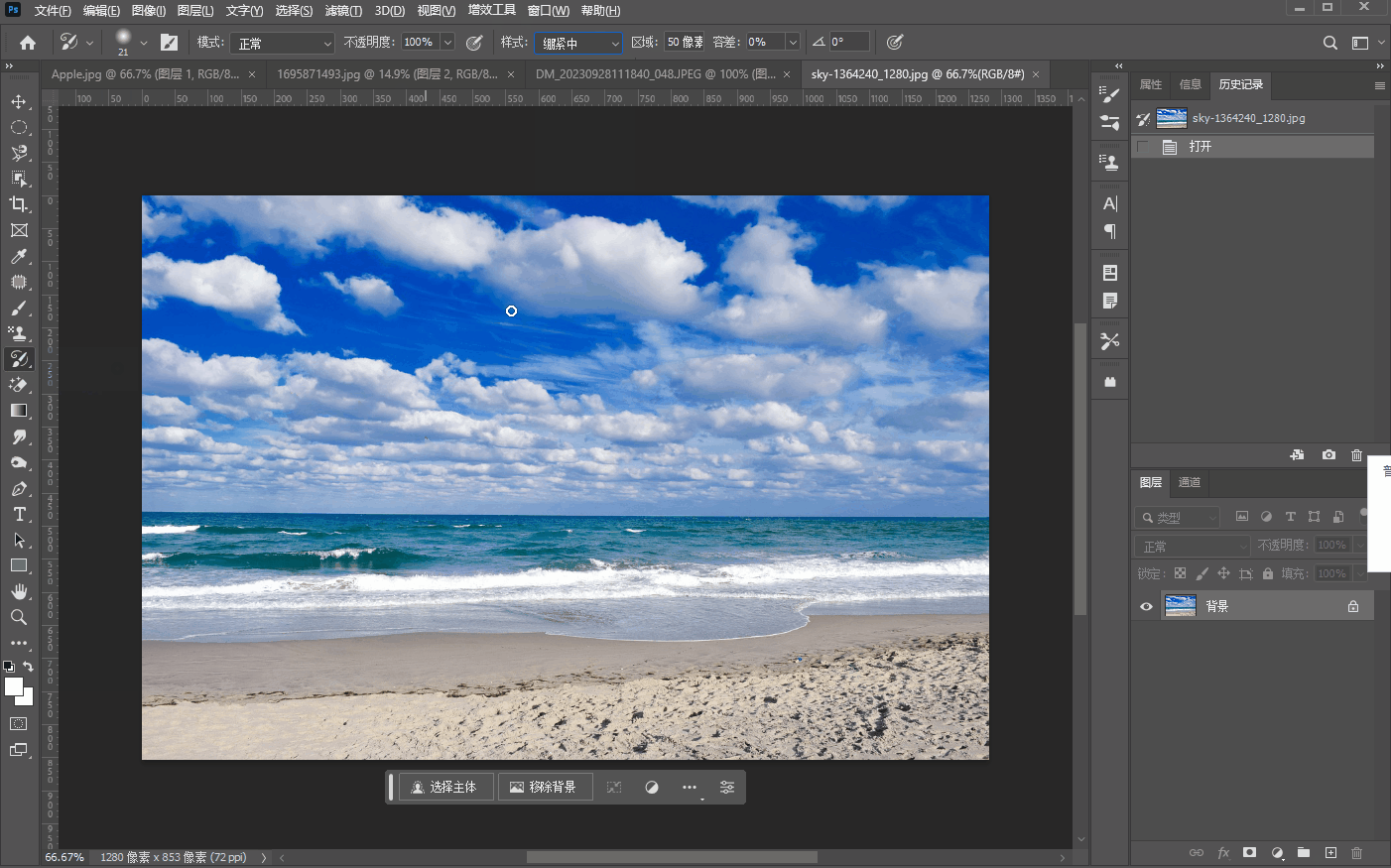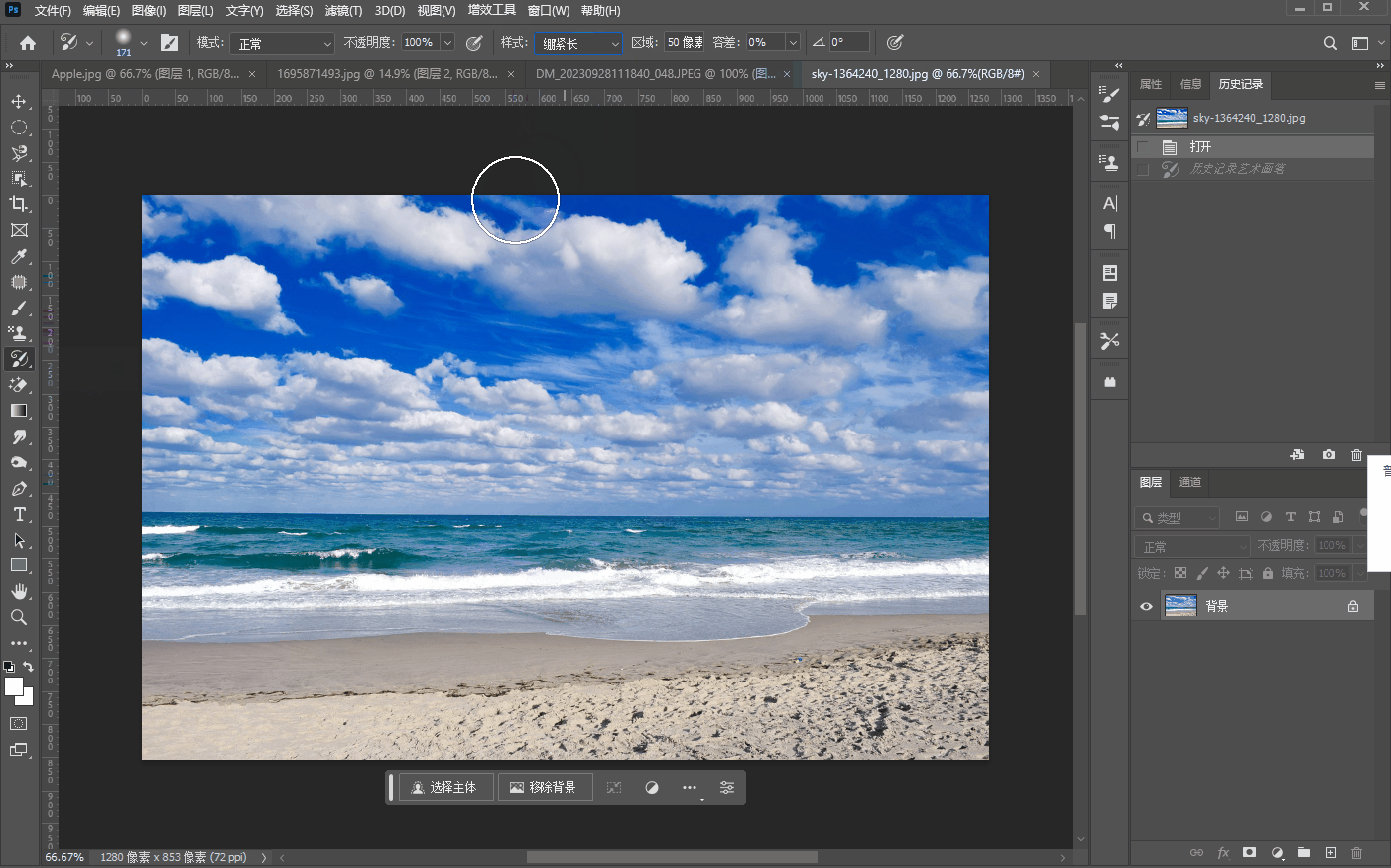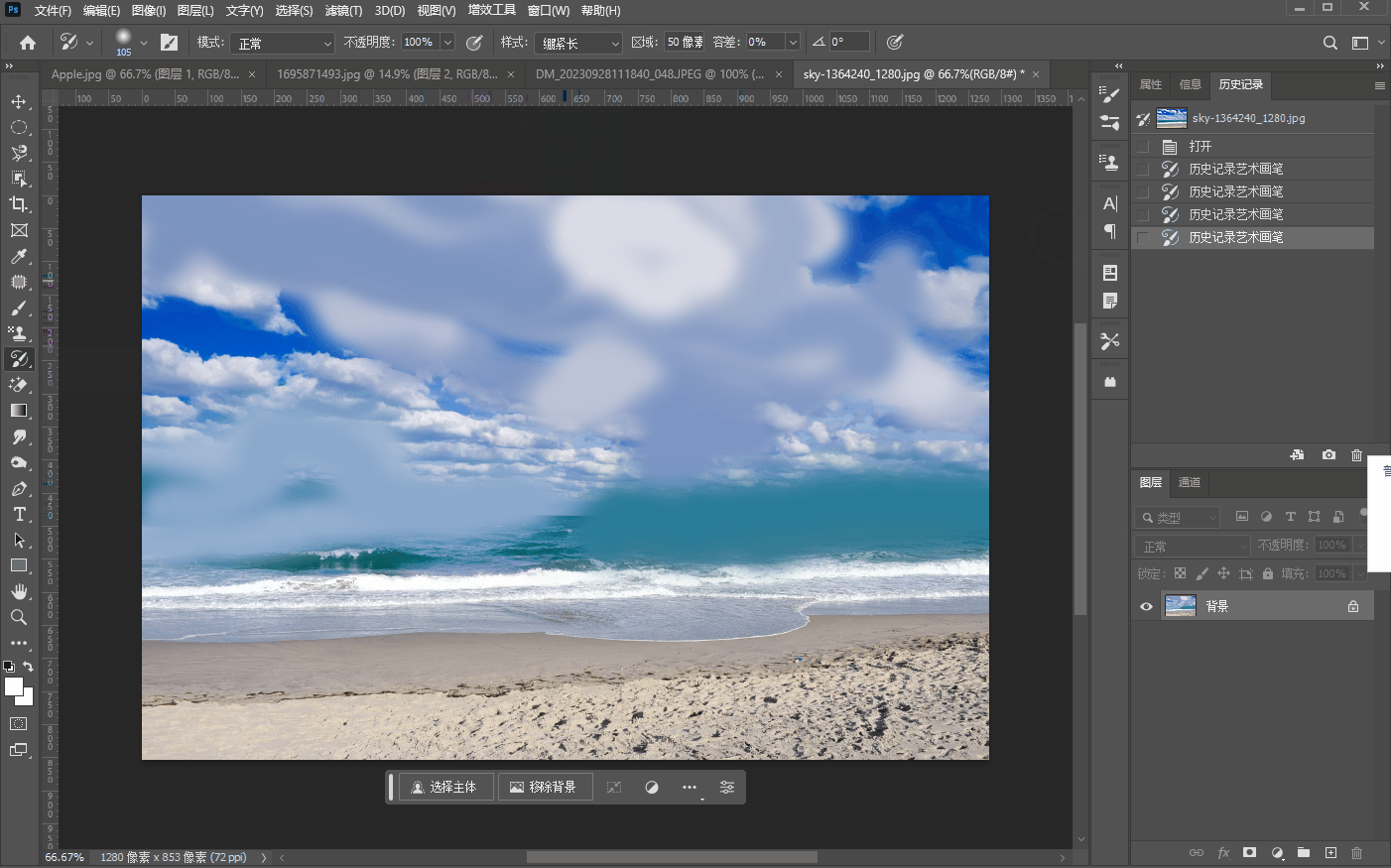
十五、【历史记录画笔工具组】
文章目录 历史记录画笔工具历史记录艺术画笔工具 历史记录画笔工具 历史记录画笔工具很简单,就是将画笔工具嗯,涂抹过的修改过的地方,然后用历史记录画笔工具重新修改回来,比如我们将三叠美元中的一叠用画笔工具先涂抹掉…...

Spark上使用pandas API快速入门
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的…...
WEBRTC/StreamStatisticianImpl持续更新中))
【WebRTC---源码篇】(十:零)WEBRTC/StreamStatisticianImpl持续更新中)
StreamStatisticianImpl是WebRTC的一个内部实现类,用于统计和管理媒体流的各种统计信息。 StreamStatisticianImpl负责记录和计算以下统计数据: 1. 带宽统计:记录媒体流的发送和接收带宽信息,包括发送比特率、接收比特率、发送丢…...

RK3588核心板赋能无人机智能飞控:异构计算与AI视觉实践
1. 项目概述:当高性能核心板遇上无人机最近在折腾一个挺有意思的项目,核心是把一块高性能的核心板——迅为的RK3588,塞进无人机里,让它成为飞控大脑。这听起来可能有点“大材小用”,毕竟RK3588这玩意儿算力不低&#x…...

Qt程序图标设置全攻略:从.ico文件到任务栏显示,一个坑都不踩
Qt程序图标设置全攻略:从资源文件到系统缓存的完整解决方案 第一次用Qt打包发布程序时,我盯着任务栏上那个丑陋的默认图标发呆了十分钟——明明在代码里设置了图标,为什么还是显示不出来?相信很多Qt开发者都遇到过类似问题。图标…...

安全聚合技术:原理、实现与多场景应用
1. 安全聚合技术概述安全聚合(Secure Aggregation)是一种多方安全计算技术,它允许多个互不信任的参与方在不泄露各自私有数据的前提下,共同计算出一个聚合结果。这项技术的核心价值在于解决了数据隐私与数据共享之间的矛盾&#x…...

5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南
5步实现AutoHotkey脚本独立运行:Ahk2Exe编译实战指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否遇到过这样的困扰?精心编写的A…...

Helm-Intellisense:VS Code智能补全插件,提升values.yaml编写效率
1. 项目概述:为什么我们需要一个Helm智能补全工具?如果你和我一样,日常工作中大量使用Helm来管理Kubernetes应用,那你一定对编写values.yaml文件时那种“盲人摸象”的感觉深有体会。面对一个动辄几十上百行配置的Helm Chart&#…...

Nixtla时间序列预测库实战:从统计模型到深度学习的一站式解决方案
1. 项目概述:时间序列预测的“瑞士军刀”如果你正在处理销售预测、服务器负载监控或者任何与时间相关的数据预测问题,并且厌倦了在复杂的模型库和繁琐的预处理步骤之间反复横跳,那么 Nixtla 这个开源项目很可能就是你一直在找的“瑞士军刀”。…...

Otter多模态大模型实战:从Flamingo架构到指令调优与部署优化
1. 项目概述:一个能“看懂”世界的多模态大模型最近在折腾多模态大模型(Multimodal Large Language Models, MLLMs)的朋友,应该对 Otter 这个名字不陌生。它不是一个独立的产品,而是一个开源的研究项目,全称…...

FeFET时间域内存计算宏:突破AI边缘计算能效瓶颈
1. 项目概述:FeFET时间域内存计算宏的创新实现在人工智能和边缘计算蓬勃发展的当下,传统冯诺依曼架构面临着一个根本性挑战:数据在处理器和存储器之间的频繁搬运导致的高能耗和延迟瓶颈。这个问题在需要大量并行乘累加(MAC)运算的神经网络应用…...

Midjourney玩具相机风格从翻车到封神:1个--v 6.1专属参数组合+2个隐藏式胶片颗粒注入指令+1套曝光补偿校准表
更多请点击: https://intelliparadigm.com 第一章:Midjourney玩具相机风格的视觉本质与审美悖论 失真即真实:玩具相机的光学哲学 玩具相机(Toy Camera)风格在 Midjourney 中并非简单模拟 Lomography 或 Holga 的物理…...
)
别再只会`cmatrix`了!解锁Linux终端屏保的10种炫酷玩法(含快捷键大全)
终端美学革命:10种cmatrix高阶玩法与快捷键全解析 当绿色代码雨第一次在终端流淌而下时,那种黑客帝国般的视觉冲击令人难忘。但你是否知道,这个看似简单的cmatrix命令背后隐藏着一个可编程的视觉艺术工具箱?本文将带你突破基础用法…...