Spark上使用pandas API快速入门
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的动态,一起学习,共同进步。
这是 Spark 上的 pandas API 的简短介绍,主要面向新用户。本笔记本向您展示 pandas 和 Spark 上的 pandas API 之间的一些关键区别。您可以在快速入门页面的“Live Notebook:Spark 上的 pandas API”中自行运行此示例。
习惯上,我们在Spark上导入pandas API如下:
import pandas as pd
import numpy as np
import pyspark.pandas as ps
from pyspark.sql import SparkSession对象创建
通过传递值列表来创建 pandas-on-Spark 系列,让 Spark 上的 pandas API 创建默认整数索引:
s = ps.Series([1, 3, 5, np.nan, 6, 8])
s
0 1.0 1 3.0 2 5.0 3 NaN 4 6.0 5 8.0 dtype: float64
通过传递可转换为类似系列的对象字典来创建 pandas-on-Spark DataFrame。
psdf = ps.DataFrame({'a': [1, 2, 3, 4, 5, 6],'b': [100, 200, 300, 400, 500, 600],'c': ["one", "two", "three", "four", "five", "six"]},index=[10, 20, 30, 40, 50, 60])
psdf| a | b | c | |
|---|---|---|---|
| 10 | 1 | 100 | one |
| 20 | 2 | 200 | two |
| 30 | 3 | 300 | three |
| 40 | 4 | 400 | four |
| 50 | 5 | 500 | five |
| 60 | 6 | 600 | six |
创建pandas DataFrame通过numpyt array, 用datetime 作为索引,label列
dates = pd.date_range('20130101', periods=6)
dates
DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04', '2013-01-05', '2013-01-06'], dtype='datetime64[ns]', freq='D')
pdf = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
pdf
| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-01 | 0.912558 | -0.795645 | -0.289115 | 0.187606 |
| 2013-01-02 | -0.059703 | -1.233897 | 0.316625 | -1.226828 |
| 2013-01-03 | 0.332871 | -1.262010 | -0.434844 | -0.579920 |
| 2013-01-04 | 0.924016 | -1.022019 | -0.405249 | -1.036021 |
| 2013-01-05 | -0.772209 | -1.228099 | 0.068901 | 0.896679 |
| 2013-01-06 | 1.485582 | -0.709306 | -0.202637 | -0.248766 |
现在,dataframe能够转换成pandas 在spark上运行
psdf = ps.from_pandas(pdf)
type(psdf)
pyspark.pandas.frame.DataFrame
看上去和dataframe一样的使用
psdf| A | B | C | D | |
|---|---|---|---|---|
| 2013-01-01 | 0.912558 | -0.795645 | -0.289115 | 0.187606 |
| 2013-01-02 | -0.059703 | -1.233897 | 0.316625 | -1.226828 |
| 2013-01-03 | 0.332871 | -1.262010 | -0.434844 | -0.579920 |
| 2013-01-04 | 0.924016 | -1.022019 | -0.405249 | -1.036021 |
| 2013-01-05 | -0.772209 | -1.228099 | 0.068901 | 0.896679 |
| 2013-01-06 | 1.485582 | -0.709306 | -0.202637 | -0.248766 |
当然通过spark pandas dataframe创建pandas on spark dataframe 非常容易
spark = SparkSession.builder.getOrCreate()
sdf = spark.createDataFrame(pdf)
sdf.show()
+--------------------+-------------------+--------------------+--------------------+ | A| B| C| D| +--------------------+-------------------+--------------------+--------------------+ | 0.91255803205208|-0.7956452608556638|-0.28911463069772175| 0.18760566615081622| |-0.05970271470242...| -1.233896949308984| 0.3166246451758431| -1.2268284000402265| | 0.33287106947536615|-1.2620100816441786| -0.4348444277082644| -0.5799199651437185| | 0.9240158461589916|-1.0220190956326003| -0.4052488880650239| -1.0360212104348547| | -0.7722090016558953|-1.2280986385313222| 0.0689011451939635| 0.8966790729426755| | 1.4855822995785612|-0.7093056426018517| -0.2026366848847041|-0.24876619876451092| +--------------------+-------------------+--------------------+--------------------+
从 Spark DataFrame 创建 pandas-on-Spark DataFrame。
psdf = sdf.pandas_api()
psdf
| A | B | C | D | |
|---|---|---|---|---|
| 0 | 0.912558 | -0.795645 | -0.289115 | 0.187606 |
| 1 | -0.059703 | -1.233897 | 0.316625 | -1.226828 |
| 2 | 0.332871 | -1.262010 | -0.434844 | -0.579920 |
| 3 | 0.924016 | -1.022019 | -0.405249 | -1.036021 |
| 4 | -0.772209 | -1.228099 | 0.068901 | 0.896679 |
| 5 | 1.485582 | -0.709306 | -0.202637 | -0.248766 |
具有特定的dtypes。目前支持 Spark 和 pandas 通用的类型。
psdf.dtypes
A float64 B float64 C float64 D float64 dtype: object
以下是如何显示下面框架中的顶行。
请注意,Spark 数据帧中的数据默认不保留自然顺序。可以通过设置compute.ordered_head选项来保留自然顺序,但它会导致内部排序的性能开销。
psdf.head()
| A | B | C | D | |
|---|---|---|---|---|
| 0 | 0.912558 | -0.795645 | -0.289115 | 0.187606 |
| 1 | -0.059703 | -1.233897 | 0.316625 | -1.226828 |
| 2 | 0.332871 | -1.262010 | -0.434844 | -0.579920 |
| 3 | 0.924016 | -1.022019 | -0.405249 | -1.036021 |
| 4 | -0.772209 | -1.228099 | 0.068901 | 0.896679 |
展示index和columns 通过numpy 数据
psdf.index
Int64Index([0, 1, 2, 3, 4, 5], dtype='int64')
psdf.columns
Index(['A', 'B', 'C', 'D'], dtype='object')
psdf.to_numpy()
array([[ 0.91255803, -0.79564526, -0.28911463, 0.18760567],[-0.05970271, -1.23389695, 0.31662465, -1.2268284 ],[ 0.33287107, -1.26201008, -0.43484443, -0.57991997],[ 0.92401585, -1.0220191 , -0.40524889, -1.03602121],[-0.772209 , -1.22809864, 0.06890115, 0.89667907],[ 1.4855823 , -0.70930564, -0.20263668, -0.2487662 ]])
通过简单统计展示你的数据:
psdf.describe()
| A | B | C | D | |
|---|---|---|---|---|
| count | 6.000000 | 6.000000 | 6.000000 | 6.000000 |
| mean | 0.470519 | -1.041829 | -0.157720 | -0.334542 |
| std | 0.809428 | 0.241511 | 0.294520 | 0.793014 |
| min | -0.772209 | -1.262010 | -0.434844 | -1.226828 |
| 25% | -0.059703 | -1.233897 | -0.405249 | -1.036021 |
| 50% | 0.332871 | -1.228099 | -0.289115 | -0.579920 |
| 75% | 0.924016 | -0.795645 | 0.068901 | 0.187606 |
| max | 1.485582 | -0.709306 | 0.316625 | 0.896679 |
转置你的数据:
psdf.T| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| A | 0.912558 | -0.059703 | 0.332871 | 0.924016 | -0.772209 | 1.485582 |
| B | -0.795645 | -1.233897 | -1.262010 | -1.022019 | -1.228099 | -0.709306 |
| C | -0.289115 | 0.316625 | -0.434844 | -0.405249 | 0.068901 | -0.202637 |
| D | 0.187606 | -1.226828 | -0.579920 | -1.036021 | 0.896679 | -0.248766 |
通过index进行排序:
psdf.sort_index(ascending=False)
| A | B | C | D | |
|---|---|---|---|---|
| 5 | 1.485582 | -0.709306 | -0.202637 | -0.248766 |
| 4 | -0.772209 | -1.228099 | 0.068901 | 0.896679 |
| 3 | 0.924016 | -1.022019 | -0.405249 | -1.036021 |
| 2 | 0.332871 | -1.262010 | -0.434844 | -0.579920 |
| 1 | -0.059703 | -1.233897 | 0.316625 | -1.226828 |
| 0 | 0.912558 | -0.795645 | -0.289115 | 0.187606 |
相关文章:

Spark上使用pandas API快速入门
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的…...
WEBRTC/StreamStatisticianImpl持续更新中))
【WebRTC---源码篇】(十:零)WEBRTC/StreamStatisticianImpl持续更新中)
StreamStatisticianImpl是WebRTC的一个内部实现类,用于统计和管理媒体流的各种统计信息。 StreamStatisticianImpl负责记录和计算以下统计数据: 1. 带宽统计:记录媒体流的发送和接收带宽信息,包括发送比特率、接收比特率、发送丢…...
报attempt to call a nil value (global ‘tostring‘)
调用Lua脚本tostring(xxx)报attempt to call a nil value (global ‘tostring‘
在c程序里调用Lua脚本, 脚本中用到了转字符串 tostring(xxx) str "test" function output(a,b,c)d "a:"..tostring(a).."b:"..tostring(b).."c"..tostring(c)return d end 实际运行会报错: attempt to call a nil v…...
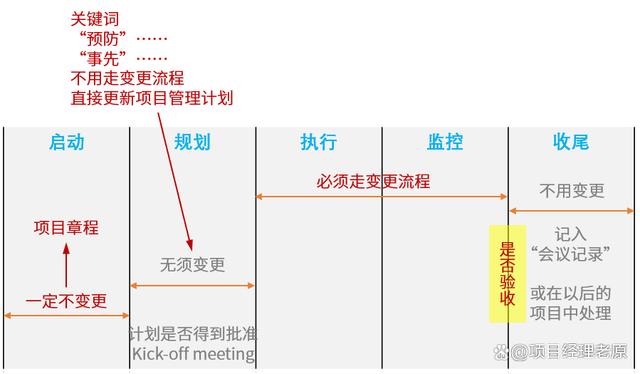
PBA.客户需求分析 需求管理
一、客户需求分析 1 需求的三个层次: Requirement/Wants/Pains 大部分人认为,产品满足不了客户需要,是因为客户告知的需求是错误的,这听起来有一些道理,却没有任何意义。不同角色对于需求的理解是不一样的。在客户的需求和厂家的…...
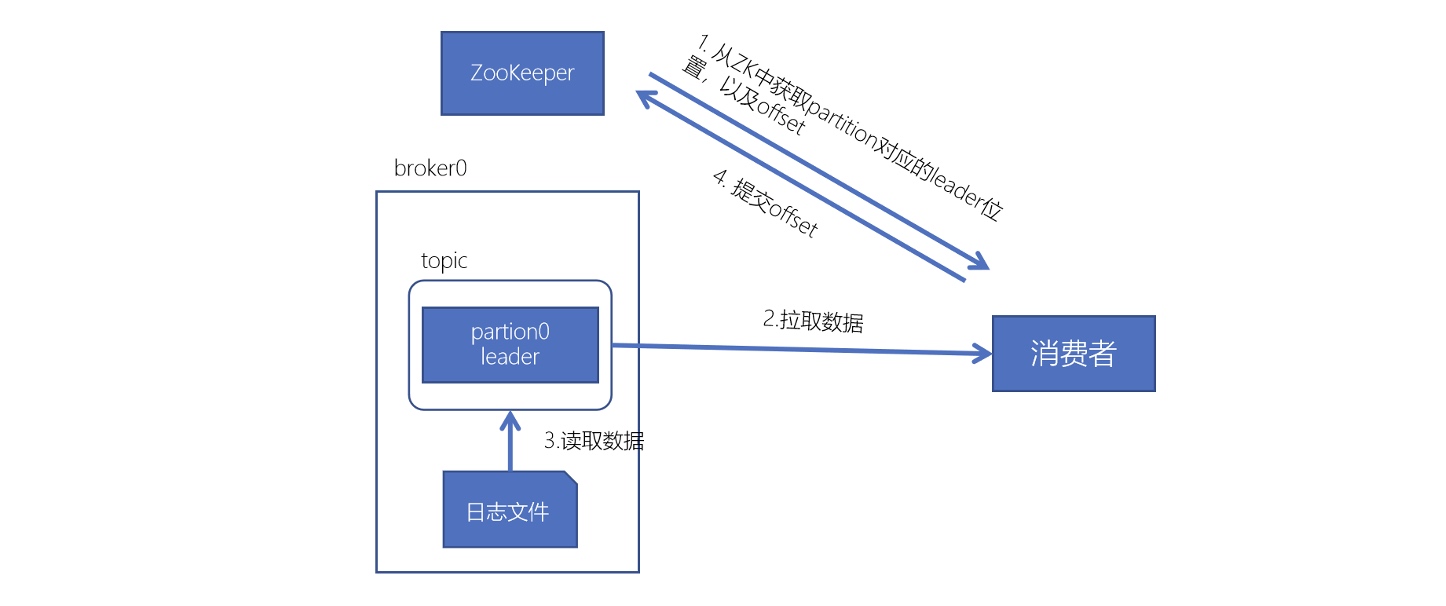
Kafka进阶
Kafka进阶 Kafka事务 kafka的事务机制是指kafka支持跨多个主题和分区的原子性写入,即在一个事务中发送的所有消息要么全部成功,要么全部失败。 kafka的事务机制涉及到以下几个方面: 事务生产者(transactional producer&#x…...
大数计算:e^1000/300!
1.问题:大数计算可能超出数据类型范围 当单独计算 ,因为 ,double的最大取值为1.79769e308,所以 肯定超过了double的表示范围。 同样,对于300!也是如此。 那我们应该怎么去计算和存储结果呢?…...
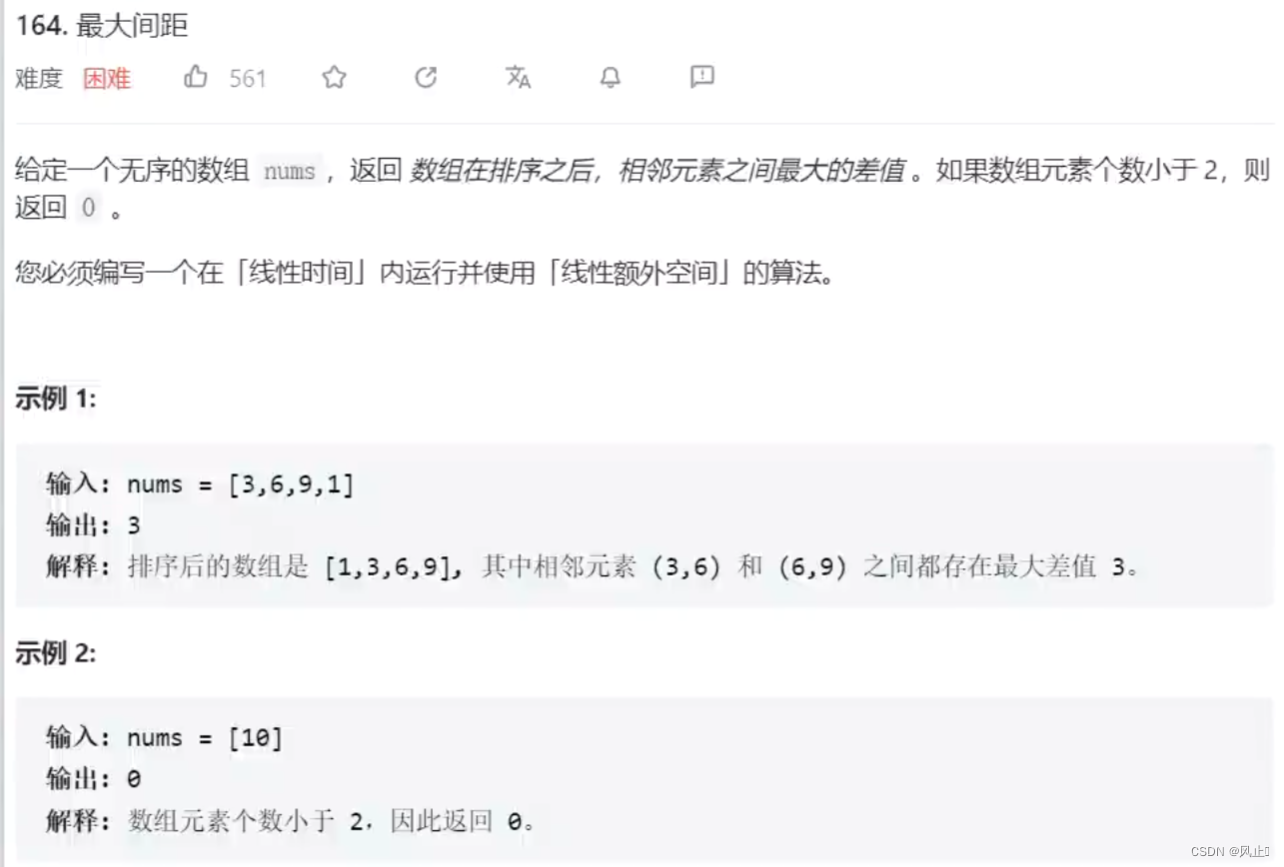
力扣164最大间距
1.前言 因为昨天写了一个基数排序,今天我来写一道用基数排序实现的题解,希望可以帮助你理解基数排序。 这个题本身不难,就是线性时间和线性额外空间(O(n))的算法,有点难实现 基数排序的时间复杂度是O(d*(nradix)),其中…...

聚观早报 | “百度世界2023”即将举办;2024款岚图梦想家上市
【聚观365】10月13日消息 “百度世界2023”即将举办 2024款岚图梦想家上市 腾势D9用户超10万 华为发布新一代GigaGreen Radio OpenAI拟进行重大更新 “百度世界2023”即将举办 “百度世界2023”将于10月17日在北京首钢园举办。届时,百度创始人、董事长兼首席执…...

Windows 应用程序监控重启
执行思路 1.定时关闭可执行程序,2.再通过定时监控启动可执行程序 定时启动关闭程序.bat echo off cd "D:\xxxx\" :: 可执行程序目录 Start "" /b xxxx.exe :: 可执行程序 timeout /T 600 /nobreak >nul :: 600秒 taskkill /IM xxxx.exe /…...
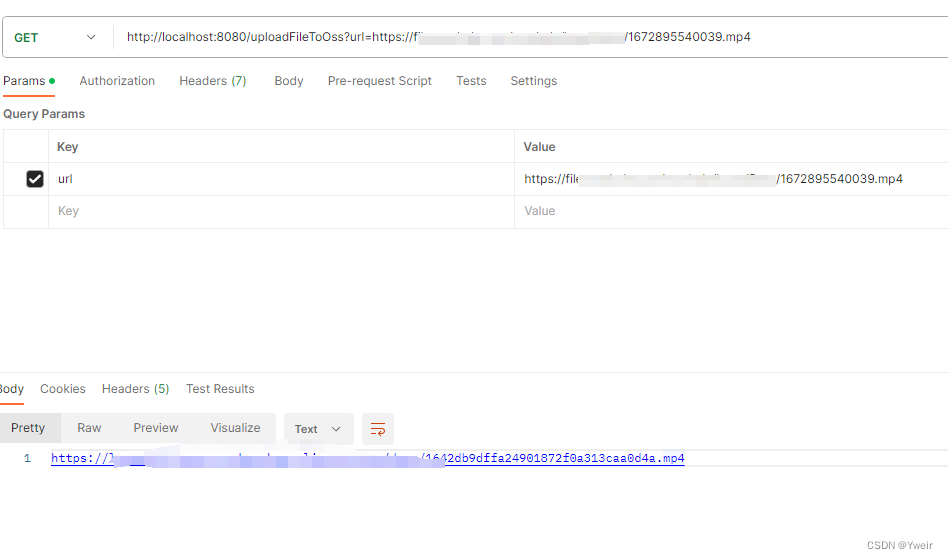
springboot 通过url下载文件并上传到OSS
DEMO流程 传入一个需要下载并上传的url地址下载文件上传文件并返回OSS的url地址 springboot pom文件依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w…...
docker创建elasticsearch、elasticsearch-head部署及简单操作
elasticsearch部署 1 拉取elasticsearch镜像 docker pull elasticsearch:7.7.0 2 创建文件映射路径 mkdir /mydata/elasticsearch/data mkdir /mydata/elasticsearch/plugins mkdir /mydata/elasticsearch/config 3 文件夹授权 chmod 777 /mydata/elastic…...
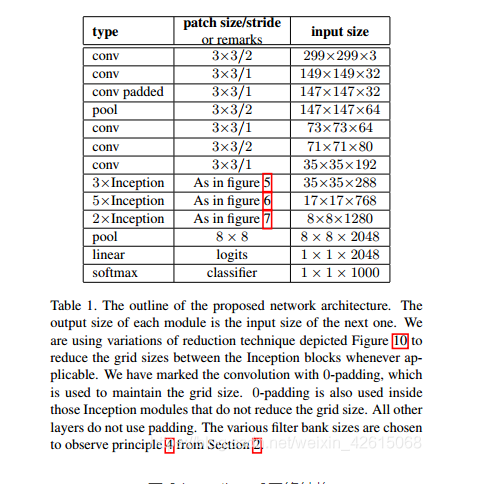
竞赛选题 深度学习+python+opencv实现动物识别 - 图像识别
文章目录 0 前言1 课题背景2 实现效果3 卷积神经网络3.1卷积层3.2 池化层3.3 激活函数:3.4 全连接层3.5 使用tensorflow中keras模块实现卷积神经网络 4 inception_v3网络5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 *…...

Codeforces Round 903 (Div. 3)ABCDE
Codeforces Round 903 (Div. 3)ABCDE 目录 A. Dont Try to Count题目大意思路核心代码 B. Three Threadlets题目大意思路核心代码 C. Perfect Square题目大意思路核心代码 D. Divide and Equalize题目大意思路核心代码 E. Block Sequence题目大意思路核心代码 A. Don’t Try t…...

C# 与 C/C++ 的交互
什么是平台调用 (P/Invoke) P/Invoke 是可用于从托管代码访问非托管库中的结构、回调和函数的一种技术。 托管代码与非托管的区别 托管代码和非托管代码的主要区别是内存管理方式和对计算机资源的访问方式。托管代码通常运行在托管环境中,如 mono 或 java 虚拟机等…...
新版Android Studio搜索不到Lombok以及无法安装Lombok插件的问题
前言 在最近新版本的Android Studio中,使用插件时,在插件市场无法找到Lombox Plugin,具体表现如下图所示: 1、操作步骤: (1)打开Android Studio->Settings->Plugins,搜索Lom…...

BST二叉搜索树
文章目录 概述实现创建节点查找节点增加节点查找后驱值根据关键词删除找到树中所有小于key的节点的value 概述 二叉搜索树,它具有以下的特性,树节点具有一个key属性,不同节点之间key是不能重复的,对于任意一个节点,它…...

【Leetcode】211. 添加与搜索单词 - 数据结构设计
一、题目 1、题目描述 请你设计一个数据结构,支持 添加新单词 和 查找字符串是否与任何先前添加的字符串匹配 。 实现词典类 WordDictionary : WordDictionary() 初始化词典对象void addWord(word) 将 word 添加到数据结构中,之后可以对它…...
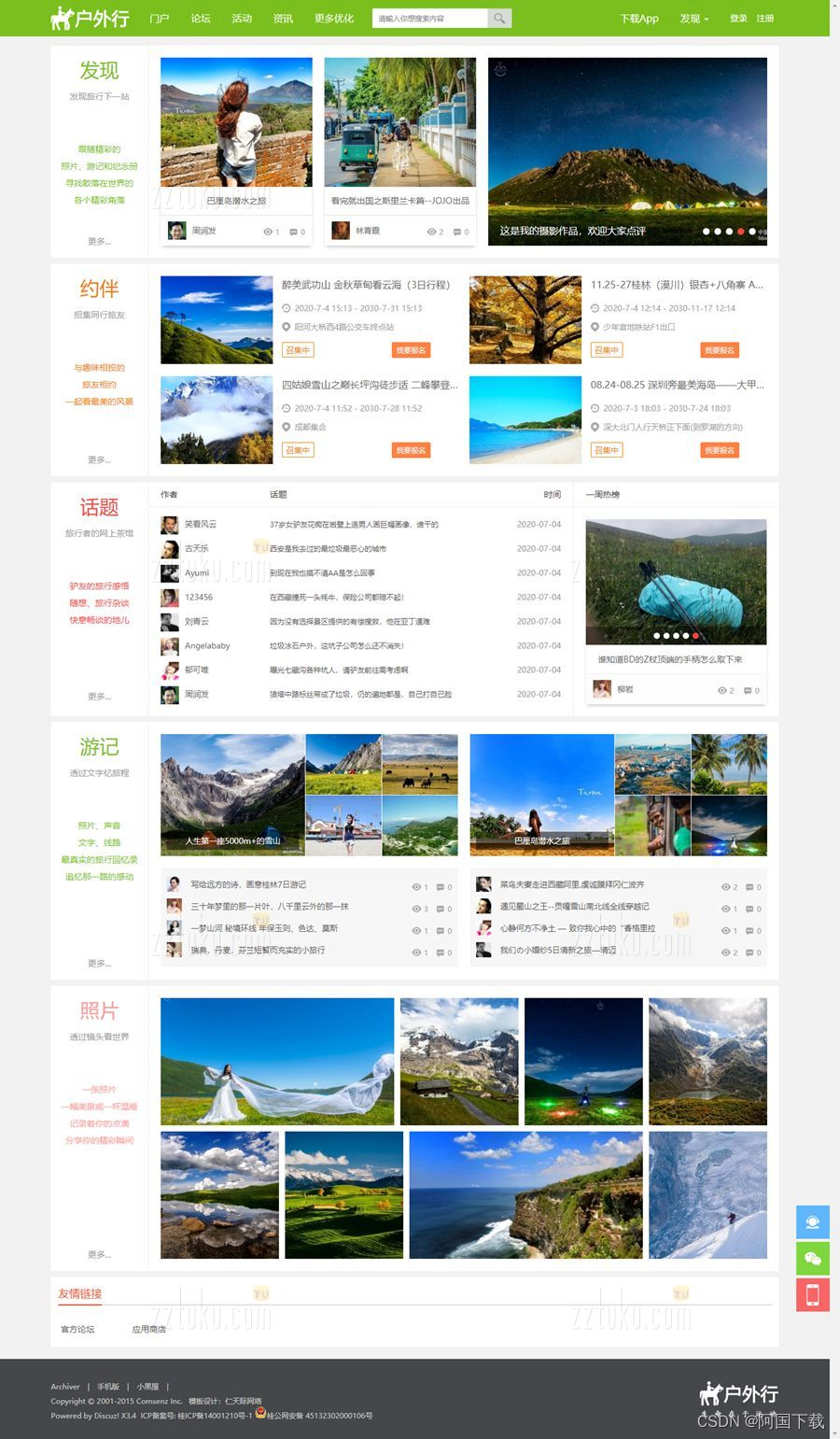
Discuz户外旅游|旅行游记模板/Discuz!旅行社、旅游行业门户网站模板
价值328的discuz户外旅游|旅行游记模板,本模板需要配套【仁天际-PC模板管理】插件使用。 模板说明 1、模板页面宽度1200px,简洁大气,较适合户外旅行、骑行、游记、摩旅、旅游、活动等类型的论坛、频道网站; 2、所优化的页面有&…...

【重拾C语言】十一、外部数据组织——文件
目录 前言 十一、外部数据组织——文件 11.1 重新考虑户籍管理问题——文件 11.2 文件概述 11.2.1 文件分类 11.2.2 文件指针、标记及文件操作 11.3 打开、关闭文件 11.4 I/O操作 11.4.1 字符读写 11.4.2 字符串读写 11.4.3 格式化读写 11.4.4 数据块读写 11.4.5 …...
dpdk/spdk/网络协议栈/存储/网关开发/网络安全/虚拟化/ 0vS/TRex/dpvs技术专家成长体系教程
课程围绕安全,网络,存储,云原生4个维度去讲解核心技术点。 6个专栏组成:dpdk网络专栏、存储技术专栏、安全与网关开发专栏、虚拟化与云原生专栏、测试工具专栏、性能测试专栏 一、dpdk网络 dpdk基础知识 多队列网卡࿰…...

FlicFlac终极指南:Windows平台最轻量音频转换工具深度解析
FlicFlac终极指南:Windows平台最轻量音频转换工具深度解析 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 在数字音频处理领域,开…...

轻量级推荐系统MiniOneRec:从协同过滤到服务部署的实践指南
1. 项目概述:一个轻量级、高可用的推荐系统引擎在数据驱动的今天,推荐系统早已不是大型互联网公司的专属。无论是电商平台、内容社区,还是企业内部的知识库、工具集,个性化推荐都已成为提升用户体验和业务效率的核心能力。然而&am…...

Godot引擎集成Lua脚本:实现原理、技术价值与实战应用
1. 项目概述:当Godot遇上Lua,一场引擎与脚本的“双向奔赴”如果你是一位游戏开发者,尤其是对Godot引擎有所涉猎的朋友,最近可能在一些社区或开源平台上瞥见过一个名为“godot_luaAPI”的项目。乍一看,这个名字似乎有些…...

3步解锁鸣潮120帧:你的终极游戏体验优化指南
3步解锁鸣潮120帧:你的终极游戏体验优化指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 还在为《鸣潮》游戏中的60帧限制而烦恼吗?明明拥有强大的硬件配置,却无法充…...

深度解析Scarab:空洞骑士模组管理器的专业实现与架构设计
深度解析Scarab:空洞骑士模组管理器的专业实现与架构设计 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 空洞骑士模组管理器Scarab为玩家提供了高效、专业的模组…...

纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书
纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书副标题:摒弃井下繁杂传感布设,依靠暗光三维实景重构、深部空间无感感知、盲区跨镜无痕跟踪、身体指纹生物核验,实现井下 24 小时无人值守、全域透明运维前言矿山井下…...

Qdrant Python客户端全解析:从向量数据库连接到AI应用开发实战
1. 项目概述:从向量数据库到客户端,现代AI应用落地的关键拼图如果你最近在折腾大语言模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率已经听过“向量数据库”这个词了。简单来说,它就像一个专门为AI模型设…...

从分布式到可分发:大规模软件制品分发架构设计与实践
1. 项目概述:从“分布式”到“可分发”的思维跃迁最近在梳理团队内部的基础设施时,又翻出了distr-sh/distr这个项目。说实话,第一次看到这个仓库名,我下意识地把它归类为又一个“分布式系统”框架。但当我真正点进去,花…...

激光切割外壳设计全流程:从创客工具到产品级制造的实战指南
1. 项目概述:为什么选择激光切割来做外壳?如果你和我一样,捣鼓过不少电子项目,从简单的Arduino温湿度计到复杂的树莓派家庭服务器,那你一定为“给它们找个家”这件事头疼过。3D打印太慢,开模注塑成本又高得…...

如何免费高效优化电脑性能:UXTU终极调优指南
如何免费高效优化电脑性能:UXTU终极调优指南 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility Universal x86 Tuning…...