竞赛选题 深度学习+python+opencv实现动物识别 - 图像识别
文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
- 3 卷积神经网络
- 3.1卷积层
- 3.2 池化层
- 3.3 激活函数:
- 3.4 全连接层
- 3.5 使用tensorflow中keras模块实现卷积神经网络
- 4 inception_v3网络
- 5 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 **基于深度学习的动物识别算法 **
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate

1 课题背景
利用深度学习对野生动物进行自动识别分类,可以大大提高野生动物监测效率,为野生动物保护策略的制定提供可靠的数据支持。但是目前野生动物的自动识别仍面临着监测图像背景信息复杂、质量低造成的识别准确率低的问题,影响了深度学习技术在野生动物保护领域的应用落地。为了实现高准确率的野生动物自动识别,本项目基于卷积神经网络实现图像动物识别。
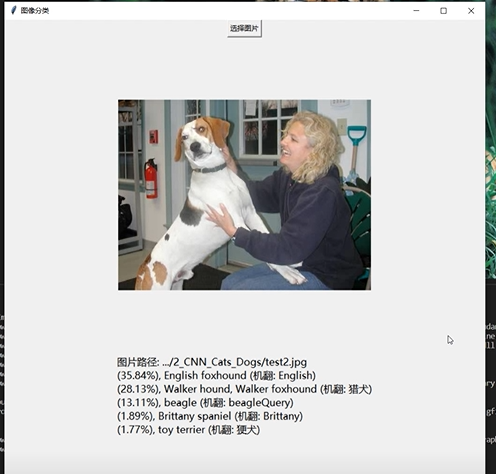
2 实现效果

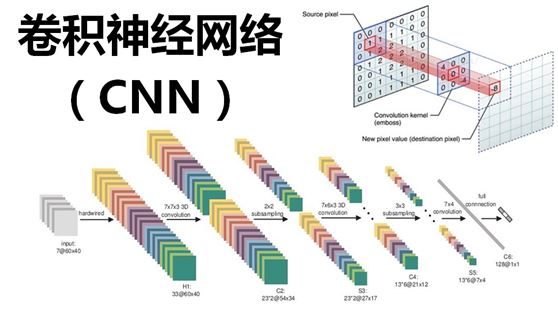
3 卷积神经网络
受到人类大脑神经突触结构相互连接的模式启发,神经网络作为人工智能领域的重要组成部分,通过分布式的方法处理信息,可以解决复杂的非线性问题,从构造方面来看,主要包括输入层、隐藏层、输出层三大组成结构。每一个节点被称为一个神经元,存在着对应的权重参数,部分神经元存在偏置,当输入数据x进入后,对于经过的神经元都会进行类似于:y=w*x+b的线性函数的计算,其中w为该位置神经元的权值,b则为偏置函数。通过每一层神经元的逻辑运算,将结果输入至最后一层的激活函数,最后得到输出output。
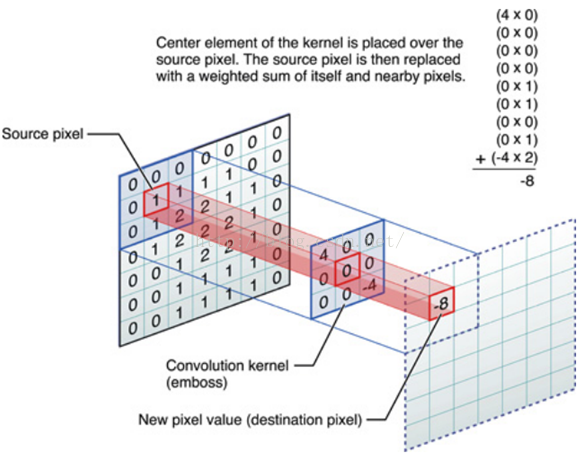
3.1卷积层
卷积核相当于一个滑动窗口,示意图中3x3大小的卷积核依次划过6x6大小的输入数据中的对应区域,并与卷积核滑过区域做矩阵点乘,将所得结果依次填入对应位置即可得到右侧4x4尺寸的卷积特征图,例如划到右上角3x3所圈区域时,将进行0x0+1x1+2x1+1x1+0x0+1x1+1x0+2x0x1x1=6的计算操作,并将得到的数值填充到卷积特征的右上角。
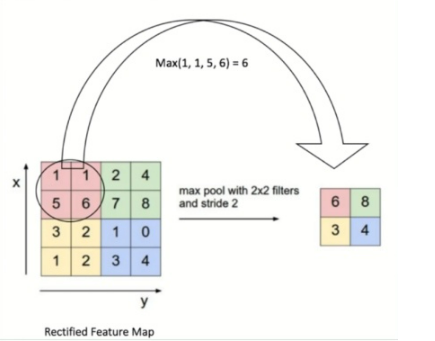
3.2 池化层
池化操作又称为降采样,提取网络主要特征可以在达到空间不变性的效果同时,有效地减少网络参数,因而简化网络计算复杂度,防止过拟合现象的出现。在实际操作中经常使用最大池化或平均池化两种方式,如下图所示。虽然池化操作可以有效的降低参数数量,但过度池化也会导致一些图片细节的丢失,因此在搭建网络时要根据实际情况来调整池化操作。
3.3 激活函数:
激活函数大致分为两种,在卷积神经网络的发展前期,使用较为传统的饱和激活函数,主要包括sigmoid函数、tanh函数等;随着神经网络的发展,研宄者们发现了饱和激活函数的弱点,并针对其存在的潜在问题,研宄了非饱和激活函数,其主要含有ReLU函数及其函数变体
3.4 全连接层
在整个网络结构中起到“分类器”的作用,经过前面卷积层、池化层、激活函数层之后,网络己经对输入图片的原始数据进行特征提取,并将其映射到隐藏特征空间,全连接层将负责将学习到的特征从隐藏特征空间映射到样本标记空间,一般包括提取到的特征在图片上的位置信息以及特征所属类别概率等。将隐藏特征空间的信息具象化,也是图像处理当中的重要一环。
3.5 使用tensorflow中keras模块实现卷积神经网络
class CNN(tf.keras.Model):def __init__(self):super().__init__()self.conv1 = tf.keras.layers.Conv2D(filters=32, # 卷积层神经元(卷积核)数目kernel_size=[5, 5], # 感受野大小padding='same', # padding策略(vaild 或 same)activation=tf.nn.relu # 激活函数)self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)self.conv2 = tf.keras.layers.Conv2D(filters=64,kernel_size=[5, 5],padding='same',activation=tf.nn.relu)self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)self.flatten = tf.keras.layers.Reshape(target_shape=(7 * 7 * 64,))self.dense1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)self.dense2 = tf.keras.layers.Dense(units=10)def call(self, inputs):x = self.conv1(inputs) # [batch_size, 28, 28, 32]x = self.pool1(x) # [batch_size, 14, 14, 32]x = self.conv2(x) # [batch_size, 14, 14, 64]x = self.pool2(x) # [batch_size, 7, 7, 64]x = self.flatten(x) # [batch_size, 7 * 7 * 64]x = self.dense1(x) # [batch_size, 1024]x = self.dense2(x) # [batch_size, 10]output = tf.nn.softmax(x)return output
4 inception_v3网络
简介
如果 ResNet 是为了更深,那么 Inception 家族就是为了更宽。Inception
的作者对训练更大型网络的计算效率尤其感兴趣。换句话说:怎样在不增加计算成本的前提下扩展神经网络?
网路结构图
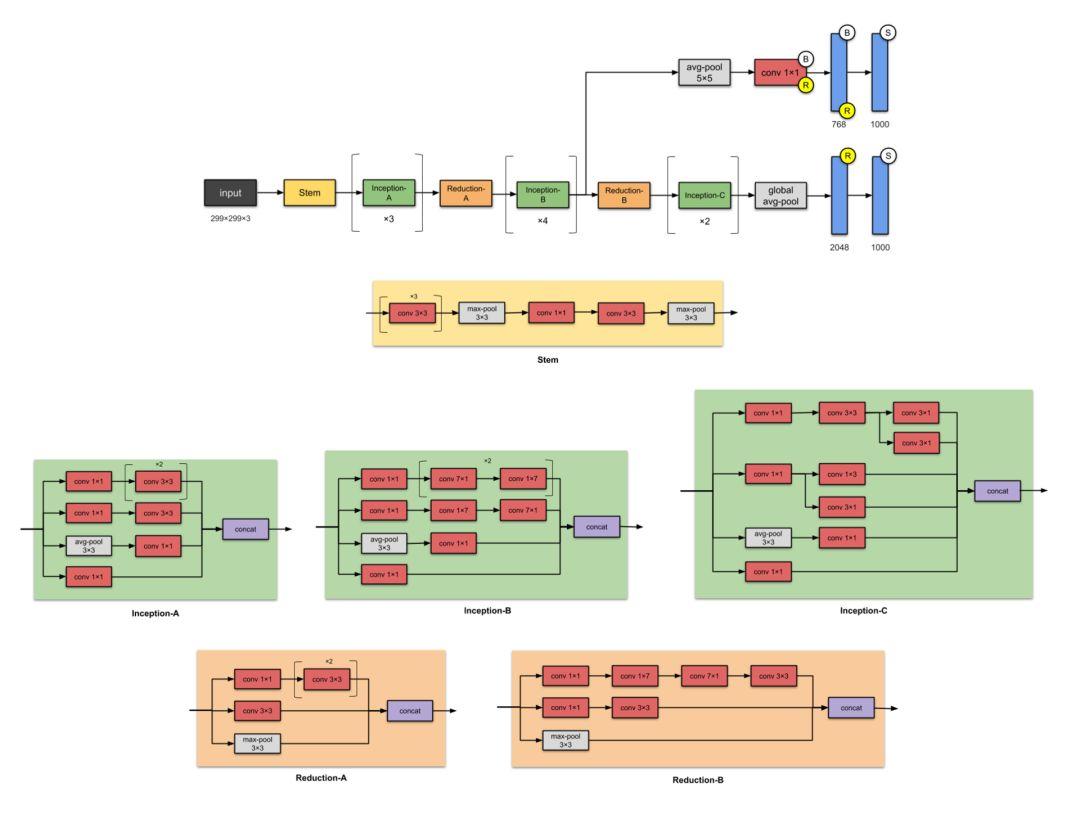
主要改动
- 将7×7卷积分解为3个3×3的卷积。
- 35×35的Inception模块采用图1所示结构,之后采用图5类似结构进行下采样
- 17×17的Inception模块采用图2所示结构,也是采用图5类似结构下采样
- 8×8的Inception模块采用图3所示结构,进行较大维度的提升。
Tensorflow实现代码
import osimport kerasimport numpy as npimport tensorflow as tffrom tensorflow.keras import layersfrom tensorflow.keras.models import Modelconfig = tf.compat.v1.ConfigProto()config.gpu_options.allow_growth = True # TensorFlow按需分配显存config.gpu_options.per_process_gpu_memory_fraction = 0.5 # 指定显存分配比例inceptionV3_One={'1a':[64,48,64,96,96,32],'2a':[64,48,64,96,96,64],'3a':[64,48,64,96,96,64]}inceptionV3_Two={'1b':[192,128,128,192,128,128,128,128,192,192],'2b':[192,160,160,192,160,160,160,160,192,192],'3b':[192,160,160,192,160,160,160,160,192,192],'4b':[192,192,192,192,192,192,192,192,192,192]}keys_two=(list)(inceptionV3_Two.keys())inceptionV3_Three={'1c':[320,384,384,384,448,384,384,384,192],'2c':[320,384,384,384,448,384,384,384,192]}keys_three=(list)(inceptionV3_Three.keys())def InceptionV3(inceptionV3_One,inceptionV3_Two,inceptionV3_Three):keys_one=(list)(inceptionV3_One.keys())keys_two = (list)(inceptionV3_Two.keys())keys_three = (list)(inceptionV3_Three.keys())input=layers.Input(shape=[299,299,3])# 输入部分conv1_one = layers.Conv2D(32, kernel_size=[3, 3], strides=[2, 2], padding='valid')(input)conv1_batch=layers.BatchNormalization()(conv1_one)conv1relu=layers.Activation('relu')(conv1_batch)conv2_one = layers.Conv2D(32, kernel_size=[3, 3], strides=[1,1],padding='valid')(conv1relu)conv2_batch=layers.BatchNormalization()(conv2_one)conv2relu=layers.Activation('relu')(conv2_batch)conv3_padded = layers.Conv2D(64, kernel_size=[3, 3], strides=[1,1],padding='same')(conv2relu)conv3_batch=layers.BatchNormalization()(conv3_padded)con3relu=layers.Activation('relu')(conv3_batch)pool1_one = layers.MaxPool2D(pool_size=[3, 3], strides=[2, 2])(con3relu)conv4_one = layers.Conv2D(80, kernel_size=[3,3], strides=[1,1], padding='valid')(pool1_one)conv4_batch=layers.BatchNormalization()(conv4_one)conv4relu=layers.Activation('relu')(conv4_batch)conv5_one = layers.Conv2D(192, kernel_size=[3, 3], strides=[2,2], padding='valid')(conv4relu)conv5_batch = layers.BatchNormalization()(conv5_one)x=layers.Activation('relu')(conv5_batch)"""filter11:1x1的卷积核个数filter13:3x3卷积之前的1x1卷积核个数filter33:3x3卷积个数filter15:使用3x3卷积代替5x5卷积之前的1x1卷积核个数filter55:使用3x3卷积代替5x5卷积个数filtermax:最大池化之后的1x1卷积核个数"""for i in range(3):conv11 = layers.Conv2D((int)(inceptionV3_One[keys_one[i]][0]), kernel_size=[1, 1], strides=[1, 1], padding='same')(x)batchnormaliztion11 = layers.BatchNormalization()(conv11)conv11relu = layers.Activation('relu')(batchnormaliztion11)conv13 = layers.Conv2D((int)(inceptionV3_One[keys_one[i]][1]), kernel_size=[1, 1], strides=[1, 1], padding='same')(x)batchnormaliztion13 = layers.BatchNormalization()(conv13)conv13relu = layers.Activation('relu')(batchnormaliztion13)conv33 = layers.Conv2D((int)(inceptionV3_One[keys_one[i]][2]), kernel_size=[5, 5], strides=[1, 1], padding='same')(conv13relu)batchnormaliztion33 = layers.BatchNormalization()(conv33)conv33relu = layers.Activation('relu')(batchnormaliztion33)conv1533 = layers.Conv2D((int)(inceptionV3_One[keys_one[i]][3]), kernel_size=[1, 1], strides=[1, 1], padding='same')(x)batchnormaliztion1533 = layers.BatchNormalization()(conv1533)conv1522relu = layers.Activation('relu')(batchnormaliztion1533)conv5533first = layers.Conv2D((int)(inceptionV3_One[keys_one[i]][4]), kernel_size=[3, 3], strides=[1, 1], padding='same')(conv1522relu)batchnormaliztion5533first = layers.BatchNormalization()(conv5533first)conv5533firstrelu = layers.Activation('relu')(batchnormaliztion5533first)conv5533last = layers.Conv2D((int)(inceptionV3_One[keys_one[i]][4]), kernel_size=[3, 3], strides=[1, 1], padding='same')(conv5533firstrelu)batchnormaliztion5533last = layers.BatchNormalization()(conv5533last)conv5533lastrelu = layers.Activation('relu')(batchnormaliztion5533last)maxpool = layers.AveragePooling2D(pool_size=[3, 3], strides=[1, 1], padding='same')(x)maxconv11 = layers.Conv2D((int)(inceptionV3_One[keys_one[i]][5]), kernel_size=[1, 1], strides=[1, 1], padding='same')(maxpool)batchnormaliztionpool = layers.BatchNormalization()(maxconv11)convmaxrelu = layers.Activation('relu')(batchnormaliztionpool)x=tf.concat([conv11relu,conv33relu,conv5533lastrelu,convmaxrelu],axis=3)conv1_two = layers.Conv2D(384, kernel_size=[3, 3], strides=[2, 2], padding='valid')(x)conv1batch=layers.BatchNormalization()(conv1_two)conv1_tworelu=layers.Activation('relu')(conv1batch)conv2_two = layers.Conv2D(64, kernel_size=[1, 1], strides=[1, 1], padding='same')(x)conv2batch=layers.BatchNormalization()(conv2_two)conv2_tworelu=layers.Activation('relu')(conv2batch)conv3_two = layers.Conv2D( 96, kernel_size=[3, 3], strides=[1,1], padding='same')(conv2_tworelu)conv3batch=layers.BatchNormalization()(conv3_two)conv3_tworelu=layers.Activation('relu')(conv3batch)conv4_two = layers.Conv2D( 96, kernel_size=[3, 3], strides=[2, 2], padding='valid')(conv3_tworelu)conv4batch=layers.BatchNormalization()(conv4_two)conv4_tworelu=layers.Activation('relu')(conv4batch)maxpool = layers.MaxPool2D(pool_size=[3, 3], strides=[2, 2])(x)x=tf.concat([conv1_tworelu,conv4_tworelu,maxpool],axis=3)"""filter11:1x1的卷积核个数filter13:使用1x3,3x1卷积代替3x3卷积之前的1x1卷积核个数filter33:使用1x3,3x1卷积代替3x3卷积的个数filter15:使用1x3,3x1,1x3,3x1卷积卷积代替5x5卷积之前的1x1卷积核个数filter55:使用1x3,3x1,1x3,3x1卷积代替5x5卷积个数filtermax:最大池化之后的1x1卷积核个数"""for i in range(4):conv11 = layers.Conv2D((int)(inceptionV3_Two[keys_two[i]][0]), kernel_size=[1, 1], strides=[1, 1], padding='same')(x)batchnormaliztion11 = layers.BatchNormalization()(conv11)conv11relu=layers.Activation('relu')(batchnormaliztion11)conv13 = layers.Conv2D((int)(inceptionV3_Two[keys_two[i]][1]), kernel_size=[1, 1], strides=[1, 1], padding='same')(x)batchnormaliztion13 = layers.BatchNormalization()(conv13)conv13relu=layers.Activation('relu')(batchnormaliztion13)conv3313 = layers.Conv2D((int)(inceptionV3_Two[keys_two[i]][2]), kernel_size=[1, 7], strides=[1, 1], padding='same')(conv13relu)batchnormaliztion3313 = layers.BatchNormalization()(conv3313)conv3313relu=layers.Activation('relu')(batchnormaliztion3313)conv3331 = layers.Conv2D((int)(inceptionV3_Two[keys_two[i]][3]), kernel_size=[7, 1], strides=[1, 1], padding='same')(conv3313relu)batchnormaliztion3331 = layers.BatchNormalization()(conv3331)conv3331relu=layers.Activation('relu')(batchnormaliztion3331)conv15 = layers.Conv2D((int)(inceptionV3_Two[keys_two[i]][4]), kernel_size=[1, 1], strides=[1, 1], padding='same')(x)batchnormaliztion15 = layers.BatchNormalization()(conv15)conv15relu=layers.Activation('relu')(batchnormaliztion15)conv1513first = layers.Conv2D((int)(inceptionV3_Two[keys_two[i]][5]), kernel_size=[1, 7], strides=[1, 1], padding='same')(conv15relu)batchnormaliztion1513first = layers.BatchNormalization()(conv1513first)conv1513firstrelu=layers.Activation('relu')(batchnormaliztion1513first)conv1531second = layers.Conv2D((int)(inceptionV3_Two[keys_two[i]][6]), kernel_size=[7, 1], strides=[1, 1], padding='same')(conv1513firstrelu)batchnormaliztion1531second = layers.BatchNormalization()(conv1531second)conv1531second=layers.Activation('relu')(batchnormaliztion1531second)conv1513third = layers.Conv2D((int)(inceptionV3_Two[keys_two[i]][7]), kernel_size=[1, 7], strides=[1, 1], padding='same')(conv1531second)batchnormaliztion1513third = layers.BatchNormalization()(conv1513third)conv1513thirdrelu=layers.Activation('relu')(batchnormaliztion1513third)conv1531last = layers.Conv2D((int)(inceptionV3_Two[keys_two[i]][8]), kernel_size=[7, 1], strides=[1, 1], padding='same')(conv1513thirdrelu)batchnormaliztion1531last = layers.BatchNormalization()(conv1531last)conv1531lastrelu=layers.Activation('relu')(batchnormaliztion1531last)maxpool = layers.AveragePooling2D(pool_size=[3, 3], strides=[1, 1], padding='same')(x)maxconv11 = layers.Conv2D((int)(inceptionV3_Two[keys_two[i]][9]), kernel_size=[1, 1], strides=[1, 1], padding='same')(maxpool)maxconv11relu = layers.BatchNormalization()(maxconv11)maxconv11relu = layers.Activation('relu')(maxconv11relu)x=tf.concat([conv11relu,conv3331relu,conv1531lastrelu,maxconv11relu],axis=3)conv11_three=layers.Conv2D(192, kernel_size=[1, 1], strides=[1, 1], padding='same')(x)conv11batch=layers.BatchNormalization()(conv11_three)conv11relu=layers.Activation('relu')(conv11batch)conv33_three=layers.Conv2D(320, kernel_size=[3, 3], strides=[2, 2], padding='valid')(conv11relu)conv33batch=layers.BatchNormalization()(conv33_three)conv33relu=layers.Activation('relu')(conv33batch)conv7711_three=layers.Conv2D(192, kernel_size=[1, 1], strides=[1, 1], padding='same')(x)conv77batch=layers.BatchNormalization()(conv7711_three)conv77relu=layers.Activation('relu')(conv77batch)conv7717_three=layers.Conv2D(192, kernel_size=[1, 7], strides=[1, 1], padding='same')(conv77relu)conv7717batch=layers.BatchNormalization()(conv7717_three)conv7717relu=layers.Activation('relu')(conv7717batch)conv7771_three=layers.Conv2D(192, kernel_size=[7, 1], strides=[1, 1], padding='same')(conv7717relu)conv7771batch=layers.BatchNormalization()(conv7771_three)conv7771relu=layers.Activation('relu')(conv7771batch)conv33_three=layers.Conv2D(192, kernel_size=[3, 3], strides=[2, 2], padding='valid')(conv7771relu)conv3377batch=layers.BatchNormalization()(conv33_three)conv3377relu=layers.Activation('relu')(conv3377batch)convmax_three=layers.MaxPool2D(pool_size=[3, 3], strides=[2, 2])(x)x=tf.concat([conv33relu,conv3377relu,convmax_three],axis=3)"""filter11:1x1的卷积核个数filter13:使用1x3,3x1卷积代替3x3卷积之前的1x1卷积核个数filter33:使用1x3,3x1卷积代替3x3卷积的个数filter15:使用3x3卷积代替5x5卷积之前的1x1卷积核个数filter55:使用3x3卷积代替5x5卷积个数filtermax:最大池化之后的1x1卷积核个数"""for i in range(2):conv11 = layers.Conv2D((int)(inceptionV3_Three[keys_three[i]][0]), kernel_size=[1, 1], strides=[1, 1], padding='same')(x)batchnormaliztion11 = layers.BatchNormalization()(conv11)conv11relu=layers.Activation('relu')(batchnormaliztion11)conv13 = layers.Conv2D((int)(inceptionV3_Three[keys_three[i]][1]), kernel_size=[1, 1], strides=[1, 1], padding='same')(x)batchnormaliztion13 = layers.BatchNormalization()(conv13)conv13relu=layers.Activation('relu')(batchnormaliztion13)conv33left = layers.Conv2D((int)(inceptionV3_Three[keys_three[i]][2]), kernel_size=[1, 3], strides=[1, 1], padding='same')(conv13relu)batchnormaliztion33left = layers.BatchNormalization()(conv33left)conv33leftrelu=layers.Activation('relu')(batchnormaliztion33left)conv33right = layers.Conv2D((int)(inceptionV3_Three[keys_three[i]][3]), kernel_size=[3, 1], strides=[1, 1], padding='same')(conv33leftrelu)batchnormaliztion33right = layers.BatchNormalization()(conv33right)conv33rightrelu=layers.Activation('relu')(batchnormaliztion33right)conv33rightleft=tf.concat([conv33leftrelu,conv33rightrelu],axis=3)conv15 = layers.Conv2D((int)(inceptionV3_Three[keys_three[i]][4]), kernel_size=[1, 1], strides=[1, 1], padding='same')(x)batchnormaliztion15 = layers.BatchNormalization()(conv15)conv15relu=layers.Activation('relu')(batchnormaliztion15)conv1533 = layers.Conv2D((int)(inceptionV3_Three[keys_three[i]][5]), kernel_size=[3, 3], strides=[1, 1], padding='same')(conv15relu)batchnormaliztion1533 = layers.BatchNormalization()(conv1533)conv1533relu=layers.Activation('relu')(batchnormaliztion1533)conv1533left = layers.Conv2D((int)(inceptionV3_Three[keys_three[i]][6]), kernel_size=[1, 3], strides=[1, 1], padding='same')(conv1533relu)batchnormaliztion1533left = layers.BatchNormalization()(conv1533left)conv1533leftrelu=layers.Activation('relu')(batchnormaliztion1533left)conv1533right = layers.Conv2D((int)(inceptionV3_Three[keys_three[i]][6]), kernel_size=[3, 1], strides=[1, 1], padding='same')(conv1533leftrelu)batchnormaliztion1533right = layers.BatchNormalization()(conv1533right)conv1533rightrelu=layers.Activation('relu')(batchnormaliztion1533right)conv1533leftright=tf.concat([conv1533right,conv1533rightrelu],axis=3)maxpool = layers.AveragePooling2D(pool_size=[3, 3], strides=[1, 1],padding='same')(x)maxconv11 = layers.Conv2D((int)(inceptionV3_Three[keys_three[i]][8]), kernel_size=[1, 1], strides=[1, 1], padding='same')(maxpool)batchnormaliztionpool = layers.BatchNormalization()(maxconv11)maxrelu = layers.Activation('relu')(batchnormaliztionpool)x=tf.concat([conv11relu,conv33rightleft,conv1533leftright,maxrelu],axis=3)x=layers.GlobalAveragePooling2D()(x)x=layers.Dense(1000)(x)softmax=layers.Activation('softmax')(x)model_inceptionV3=Model(inputs=input,outputs=softmax,name='InceptionV3')return model_inceptionV3model_inceptionV3=InceptionV3(inceptionV3_One,inceptionV3_Two,inceptionV3_Three)model_inceptionV3.summary()
5 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛选题 深度学习+python+opencv实现动物识别 - 图像识别
文章目录 0 前言1 课题背景2 实现效果3 卷积神经网络3.1卷积层3.2 池化层3.3 激活函数:3.4 全连接层3.5 使用tensorflow中keras模块实现卷积神经网络 4 inception_v3网络5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 *…...

Codeforces Round 903 (Div. 3)ABCDE
Codeforces Round 903 (Div. 3)ABCDE 目录 A. Dont Try to Count题目大意思路核心代码 B. Three Threadlets题目大意思路核心代码 C. Perfect Square题目大意思路核心代码 D. Divide and Equalize题目大意思路核心代码 E. Block Sequence题目大意思路核心代码 A. Don’t Try t…...

C# 与 C/C++ 的交互
什么是平台调用 (P/Invoke) P/Invoke 是可用于从托管代码访问非托管库中的结构、回调和函数的一种技术。 托管代码与非托管的区别 托管代码和非托管代码的主要区别是内存管理方式和对计算机资源的访问方式。托管代码通常运行在托管环境中,如 mono 或 java 虚拟机等…...
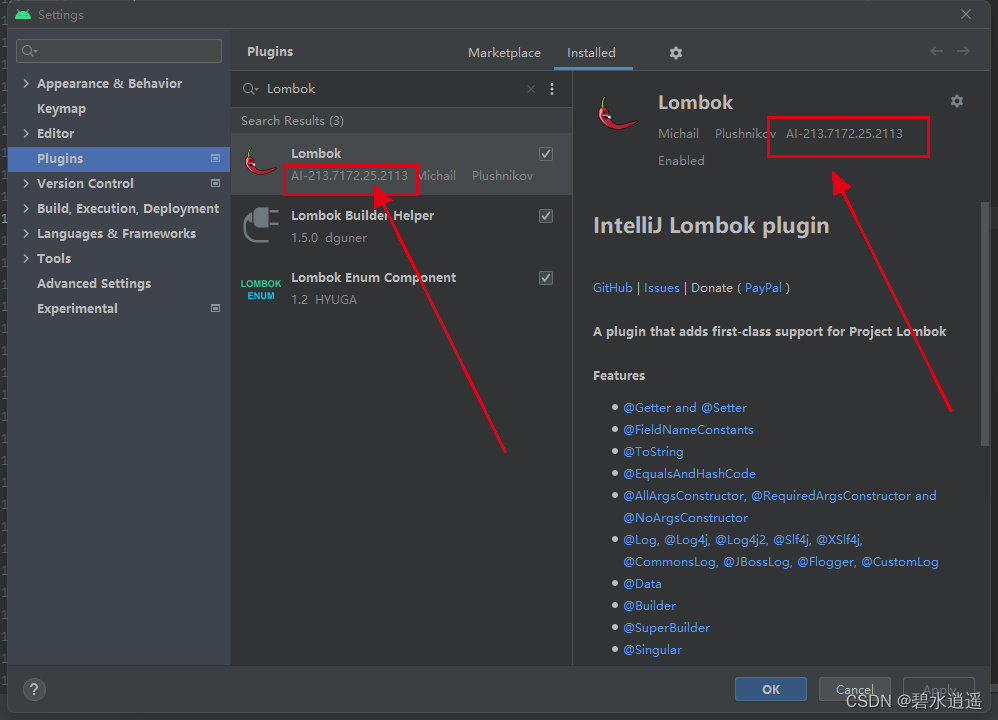
新版Android Studio搜索不到Lombok以及无法安装Lombok插件的问题
前言 在最近新版本的Android Studio中,使用插件时,在插件市场无法找到Lombox Plugin,具体表现如下图所示: 1、操作步骤: (1)打开Android Studio->Settings->Plugins,搜索Lom…...

BST二叉搜索树
文章目录 概述实现创建节点查找节点增加节点查找后驱值根据关键词删除找到树中所有小于key的节点的value 概述 二叉搜索树,它具有以下的特性,树节点具有一个key属性,不同节点之间key是不能重复的,对于任意一个节点,它…...

【Leetcode】211. 添加与搜索单词 - 数据结构设计
一、题目 1、题目描述 请你设计一个数据结构,支持 添加新单词 和 查找字符串是否与任何先前添加的字符串匹配 。 实现词典类 WordDictionary : WordDictionary() 初始化词典对象void addWord(word) 将 word 添加到数据结构中,之后可以对它…...
Discuz户外旅游|旅行游记模板/Discuz!旅行社、旅游行业门户网站模板
价值328的discuz户外旅游|旅行游记模板,本模板需要配套【仁天际-PC模板管理】插件使用。 模板说明 1、模板页面宽度1200px,简洁大气,较适合户外旅行、骑行、游记、摩旅、旅游、活动等类型的论坛、频道网站; 2、所优化的页面有&…...

【重拾C语言】十一、外部数据组织——文件
目录 前言 十一、外部数据组织——文件 11.1 重新考虑户籍管理问题——文件 11.2 文件概述 11.2.1 文件分类 11.2.2 文件指针、标记及文件操作 11.3 打开、关闭文件 11.4 I/O操作 11.4.1 字符读写 11.4.2 字符串读写 11.4.3 格式化读写 11.4.4 数据块读写 11.4.5 …...
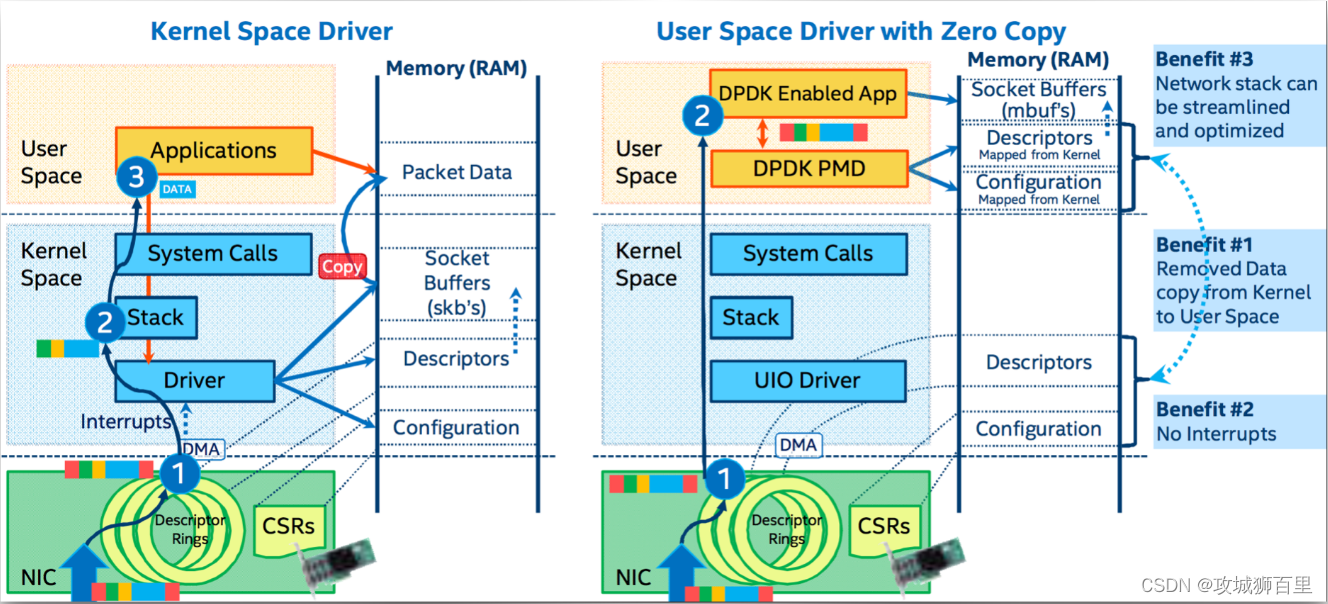
dpdk/spdk/网络协议栈/存储/网关开发/网络安全/虚拟化/ 0vS/TRex/dpvs技术专家成长体系教程
课程围绕安全,网络,存储,云原生4个维度去讲解核心技术点。 6个专栏组成:dpdk网络专栏、存储技术专栏、安全与网关开发专栏、虚拟化与云原生专栏、测试工具专栏、性能测试专栏 一、dpdk网络 dpdk基础知识 多队列网卡࿰…...

树莓派玩转openwrt软路由:5.OpenWrt防火墙配置及SSH连接
1、SSH配置 打开System -> Administration,打开SSH Access将Interface配置成unspecified。 如果选中其他的接口表示仅在给定接口上侦听,如果未指定,则在所有接口上侦听。在未指定下,所有的接口均可通过SSH访问认证。 2、防火…...

Gin:获取本机IP,获取访问IP
获取本机IP func GetLocalIP() []string {var ipStr []stringnetInterfaces, err : net.Interfaces()if err ! nil {fmt.Println("net.Interfaces error:", err.Error())return ipStr}for i : 0; i < len(netInterfaces); i {if (netInterfaces[i].Flags & ne…...

缓存降级代码结构设计
缓存降级设计思想 接前文缺陷点 本地探针应该增加计数器,多次异常再设置,避免网络波动造成误判。耦合度过高,远端缓存和本地缓存应该平行关系被设计为上下游关系了。公用的远端缓存的操作方法应该私有化,避免集成方代码误操作&…...

一文深入理解高并发服务器性能优化
我们现在已经搞定了 C10K并发连接问题 ,升级一下,如何支持千万级的并发连接?你可能说,这不可能。你说错了,现在的系统可以支持千万级的并发连接,只不过所使用的那些激进的技术,并不为人所熟悉。…...

pytorch中的归一化函数
在 PyTorch 的 nn 模块中,有一些常见的归一化函数,用于在深度学习模型中进行数据的标准化和归一化。以下是一些常见的归一化函数: nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d: 这些函数用于批量归一化 (Batch Normalization…...

【管理运筹学】第 10 章 | 排队论(1,排队论的基本概念)
文章目录 引言一、基本概念1.1 排队过程1.2 排队系统的组成和特征1.3 排队模型的分类1.4 系统指标1.5 系统状态 引言 开一点排队论的内容吧,方便做题。 排队论(Queuing Theory)也称随机服务系统理论,是为解决一系列排队问题&…...

【Express】服务端渲染(模板引擎 EJS)
EJS(Embedded JavaScript)是一款流行的模板引擎,可以用于在Express中创建动态的HTML页面。它允许在HTML模板中嵌入JavaScript代码,并且能够生成基于数据的动态内容。 下面是一个详细的讲解和示例,演示如何在Express中…...

Linux CentOS8安装gitlab_ce步骤
1 下载安装包 wget --content-disposition https://packages.gitlab.com/gitlab/gitlab-ce/packages/el/8/gitlab-ce-15.0.2-ce.0.el8.x86_64.rpm/download.rpm2 安装gitlab yum install policycoreutils-python-utilsrpm -Uvh gitlab-ce-15.0.2-ce.0.el8.x86_64.rpm3 更新配…...
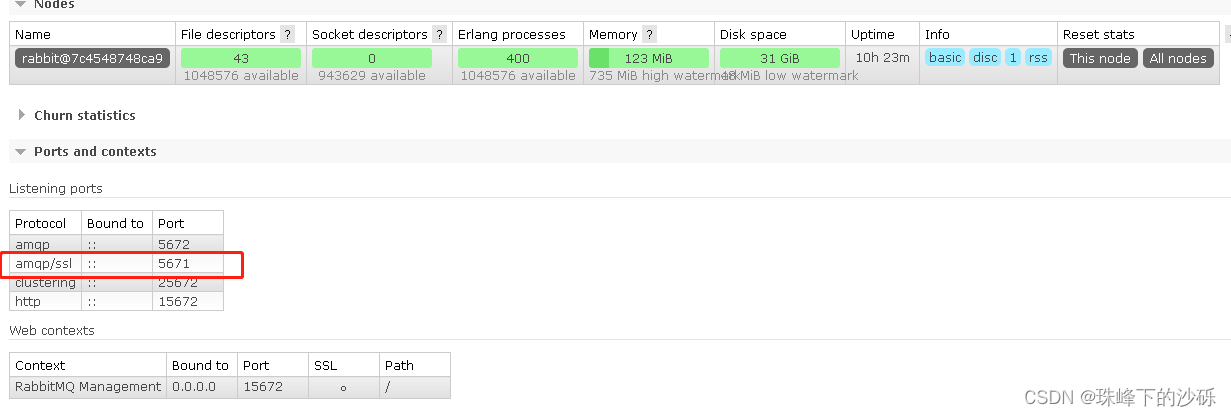
RabbitMq启用TLS
Windows环境 查看配置文件的位置 选择使用的节点 查看当前节点配置文件的配置 配置TLS 将证书放到同配置相同目录中 编辑配置文件添加TLS相关配置 [{ssl, [{versions, [tlsv1.2]}]},{rabbit, [{ssl_listeners, [5671]},{ssl_options, [{cacertfile,"C:/Users/17126…...
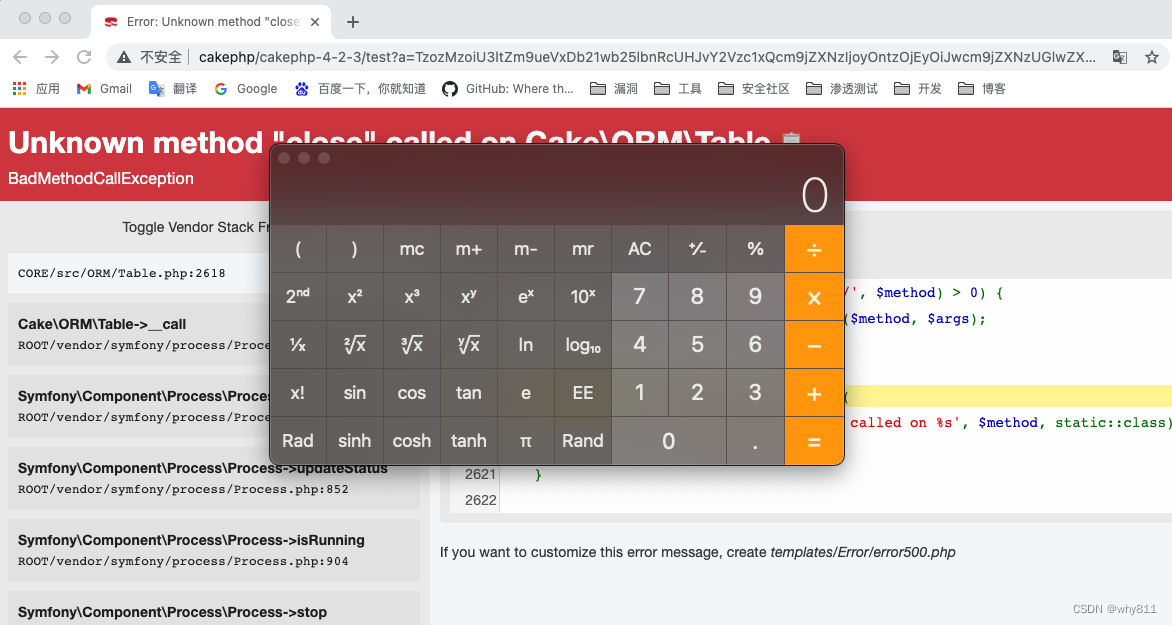
CakePHP 3.x/4.x反序列化RCE链
最近网上公开了cakephp一些反序列化链的细节,但是没有公开poc,并且网上关于cakephp的反序列化链比较少,于是自己跟一下 ,构造pop链。 CakePHP简介 CakePHP是一个运用了诸如ActiveRecord、Association Data Mapping、Front Contr…...

练习之C++[3]
文章目录 1.模板类2.模板声明3.string类 1.模板类 模板可以具有非类型参数,用于指定大小,可以根据指定的大小创建动态结构所以可用来创建动态增长和减小的数据结构模板运行时不检查数据类型,也不保证类型安全,相当于类型的宏替换…...

在自动化工作流中集成Taotoken多模型聚合API
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化工作流中集成Taotoken多模型聚合API 当开发者构建自动化脚本或智能体工作流时,一个常见的需求是能够灵活调用不…...

别再为MATLAB+Amesim联合仿真装环境发愁了!保姆级VS2019+2022a+2021.1安装避坑指南
MATLABAmesim联合仿真环境搭建全攻略:从零避坑到一次成功 当第一次接触MATLAB与Amesim联合仿真时,许多工程师和研究生都会在环境搭建阶段遭遇各种"玄学问题"——明明按照教程操作,却总是卡在某个环节无法继续。本文将分享一套经过…...

GAD7980 ADC在振动数据采集中的实战应用与设计要点
1. 项目概述:为什么我们需要“快、精、高”的振动数据采集?在工业设备状态监测、精密仪器分析乃至消费电子性能评估领域,振动数据就像设备的“心电图”。它直接反映了机械结构的健康状况、运动部件的平衡性以及系统运行的稳定性。过去&#x…...

你的Mac数字管家:Pearcleaner如何让macOS保持“梨子般“的清新体验?
你的Mac数字管家:Pearcleaner如何让macOS保持"梨子般"的清新体验? 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾…...

为什么你的ElevenLabs广告完播率低于行业均值37%?——专业声学工程师用频谱图还原真相
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs广告配音的核心声学失效诊断 当ElevenLabs生成的广告语音出现“机械感过强”“情感断层”或“语调塌陷”等现象时,问题往往并非源于模型随机性,而是底层声学特征在合…...

半导体测试数据可视化终极指南:STDF-Viewer从入门到精通
半导体测试数据可视化终极指南:STDF-Viewer从入门到精通 【免费下载链接】STDF-Viewer A free GUI tool to visualize STDF (semiconductor Standard Test Data Format) data files. 项目地址: https://gitcode.com/gh_mirrors/st/STDF-Viewer STDF-Viewer是…...

原神帧率解锁终极指南:免费突破60FPS限制的完整教程
原神帧率解锁终极指南:免费突破60FPS限制的完整教程 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 原神帧率解锁工具(genshin-fps-unlock)是一款开源…...

如何免费快速解锁电脑隐藏性能:UXTU硬件调优终极指南
如何免费快速解锁电脑隐藏性能:UXTU硬件调优终极指南 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility 还在为电脑性…...

告别网络瓶颈:手把手教你用K8s RDMA Device Plugin和SR-IOV CNI搭建超低延迟通信栈
云原生时代的超高速通信:基于K8s RDMA与SR-IOV的实战架构设计 当分布式AI训练任务因为网络延迟导致GPU利用率不足50%,当金融高频交易系统因TCP协议栈开销错过最佳套利窗口,传统网络架构已成为性能瓶颈的罪魁祸首。本文将揭示如何通过RDMA&…...

后端架构师转型AI智能体落地:收藏这份3个月进阶指南,轻松玩转不确定性系统
本文为后端/全栈/架构师提供了一条从零到一掌握AI智能体落地的技术路径。文章首先分析了架构师在AI智能体落地中的核心优势,如分布式系统设计、数据库设计、API封装等;接着,提出了一个分四阶段的三个月进阶计划,包括掌握核心范式、…...