python爬取boss直聘数据(selenium+xpath)
文章目录
- 一、主要目标
- 二、开发环境
- 三、selenium安装和驱动下载
- 四、主要思路
- 五、代码展示和说明
- 1、导入相关库
- 2、启动浏览器
- 3、搜索框定位
- 创建csv文件
- 招聘页面数据解析(XPATH)
- 总代码
- 效果展示
- 六、总结
一、主要目标
以boss直聘为目标网站,主要目的是爬取下图中的所有信息,并将爬取到的数据进行持久化存储。(可以存储到数据库中或进行数据可视化分析用web网页进行展示,这里我就以csv形式存在了本地)

二、开发环境
python3.8
pycharm
Firefox
三、selenium安装和驱动下载
环境安装: pip install selenium
版本对照表(火狐的)
https://firefox-source-docs.mozilla.org/testing/geckodriver/Support.html
浏览器驱动下载
https://registry.npmmirror.com/binary.html?path=geckodriver/
火狐浏览器下载
https://ftp.mozilla.org/pub/firefox/releases/
四、主要思路
- 利用selenium打开模拟浏览器,访问boss直聘首页(绕过cookie反爬)
- 定位搜索按钮输入某职位,点击搜索
- 在搜索结果页面,解析出现的职位信息,并保存
- 获取多个页面,可以定位跳转至下一页的按钮(但是这个跳转我一直没成功,于是我就将请求url写成了动态的,直接发送一个新的url来代替跳转)
五、代码展示和说明
1、导入相关库
# 用来将爬取到的数据以csv保存到本地
import csv
from time import sleep
# 使用selenium绕过cookie反爬
from selenium import webdriver
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
# 使用xpath进行页面数据解析
from lxml import etree2、启动浏览器
(有界面)
# 传入浏览器的驱动
ser = Service('./geckodriver.exe')
# 实例化一个浏览器对象
bro = webdriver.Firefox(service=ser)
# 设置隐式等待 超时时间设置为20s
bro.implicitly_wait(20)
# 让浏览器发起一个指定url请求
bro.get(urls[0])
(无界面)
# 1. 初始化配置无可视化界面对象
options = webdriver.FirefoxOptions()
# 2. 无界面模式
options.add_argument('-headless')
options.add_argument('--disable-gpu')# 让selenium规避被检测到的风险
options.add_argument('excludeSwitches')# 传入浏览器的驱动
ser = Service('./geckodriver.exe')# 实例化一个浏览器对象
bro = webdriver.Firefox(service=ser, options=options)# 设置隐式等待 超时时间设置为20s
bro.implicitly_wait(20)# 让浏览器发起一个指定url请求
bro.get(urls[0])
3、搜索框定位
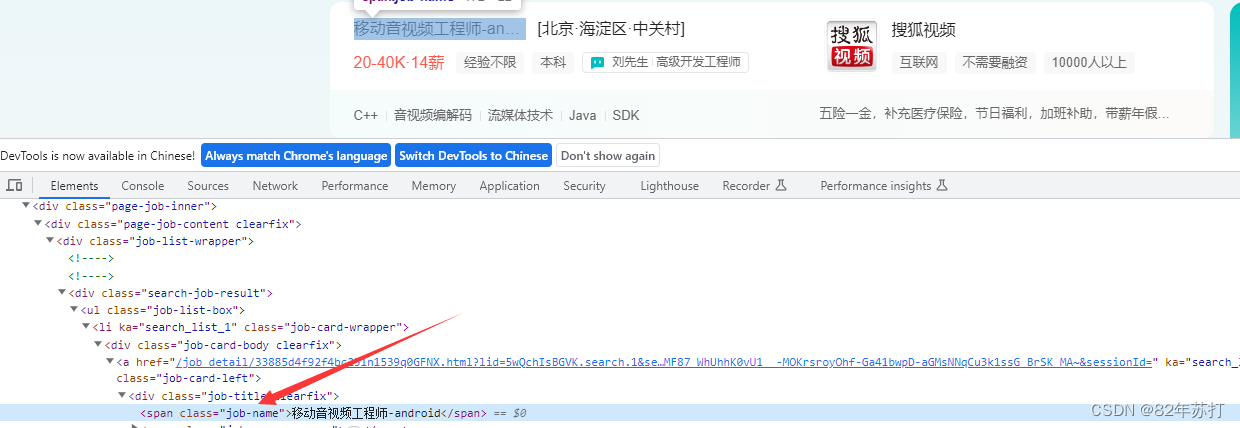
进入浏览器,按F12进入开发者模式
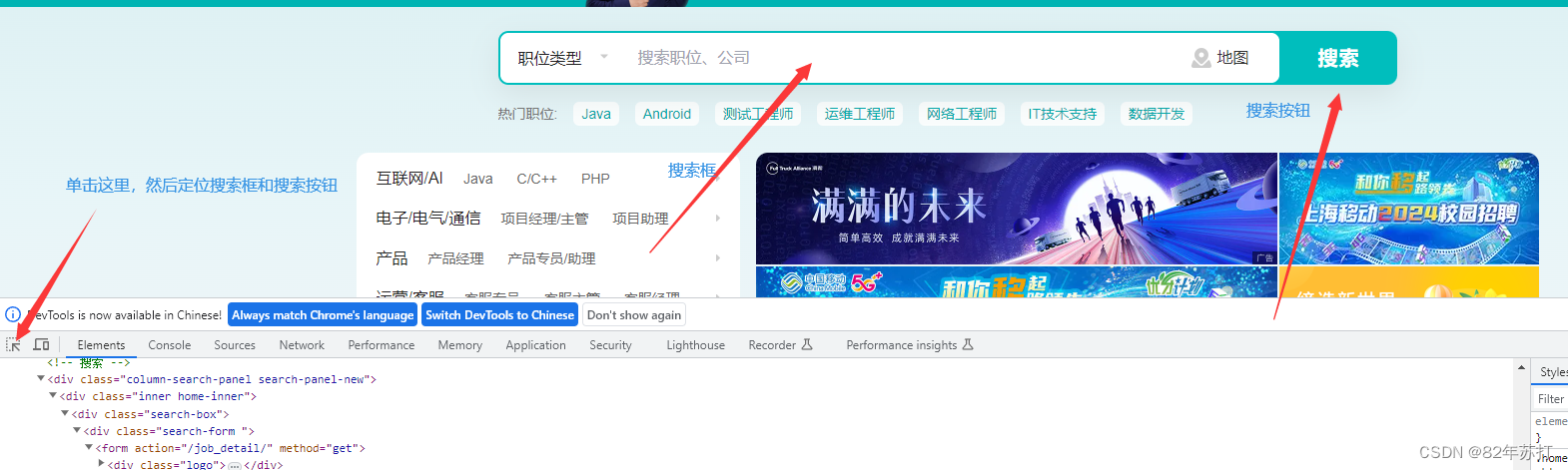
然后分析下图可知,搜索框和搜索按钮都有唯一的class值
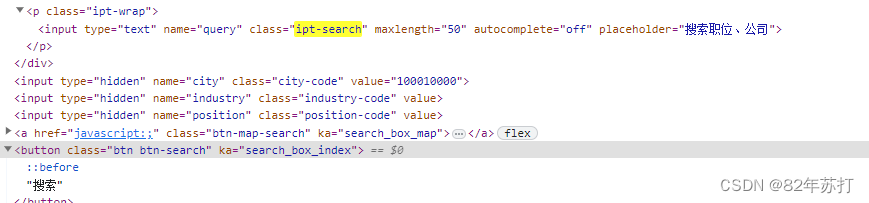
然后输入搜索内容,并跳转,代码如下
# 定位搜索框 .ipt-search
search_tag = bro.find_element(By.CSS_SELECTOR, value='.ipt-search')
# 输入搜索内容
search_tag.send_keys("")# 定位搜索按钮 .代表的是当前标签下的class
btn = bro.find_element(By.CSS_SELECTOR, value='.btn-search')
# 点击搜索按钮
btn.click()
创建csv文件
一开始编码为utf-8,但在本地打开内容是乱码,然后改成utf-8_sig就ok了
# f = open("boos直聘.csv", "w", encoding="utf-8", newline="")
f = open("boos直聘.csv", "w", encoding="utf-8_sig", newline="")
csv.writer(f).writerow(["职位", "位置", "薪资", "联系人", "经验", "公司名", "类型", "职位技能", "福利", "详情页"])招聘页面数据解析(XPATH)
通过分析可知,招聘数据全在ul标签下的li标签中
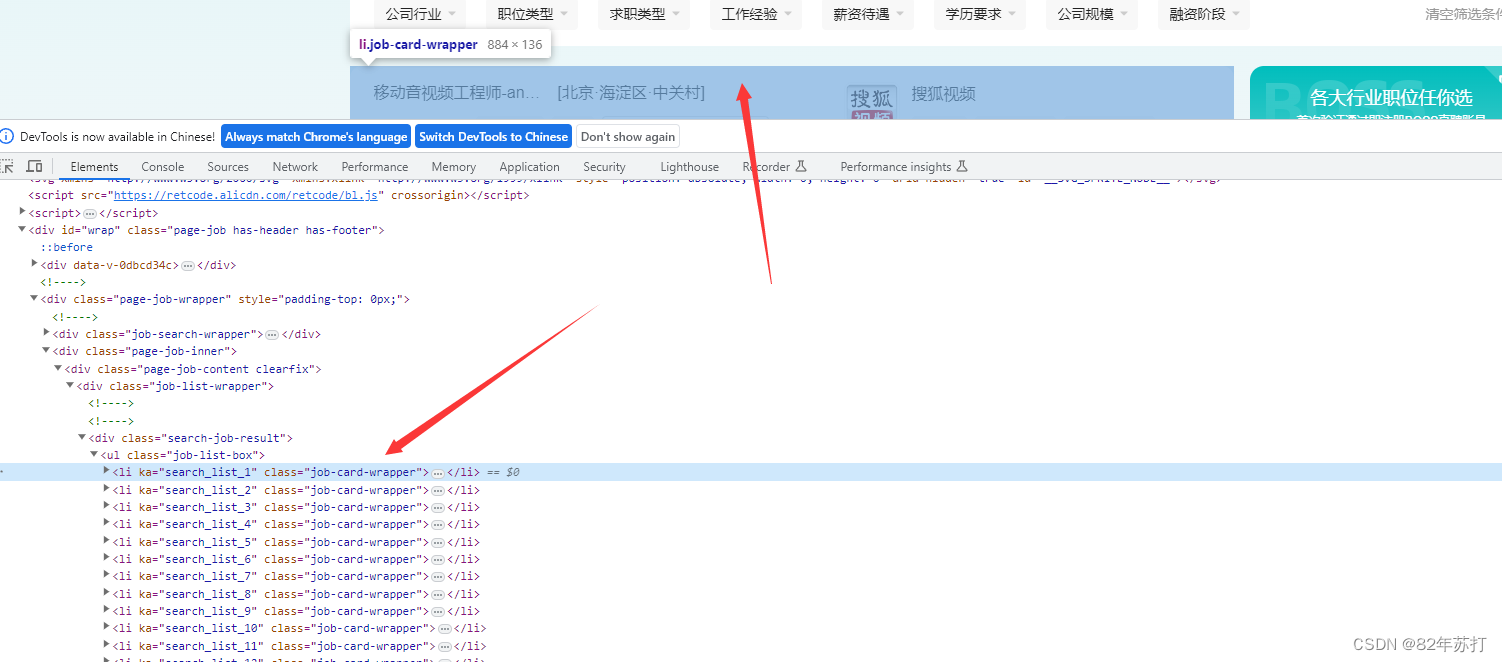
我们要获取的信息有这些,接下来就要进入li标签中,一个一个去分析
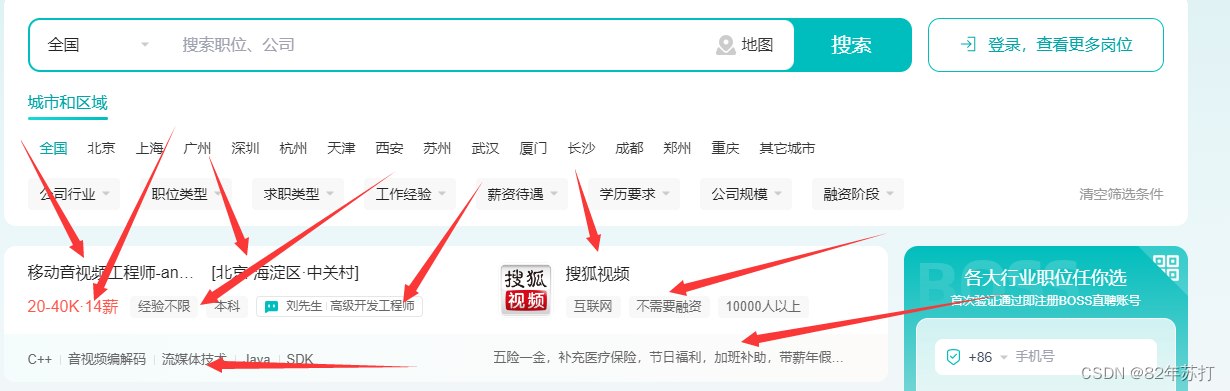
其中职位名称在span标签中,而span标签的class有唯一的值job-name
其它数据分析方式和这个相同
数据解析代码如下
def parse():# 临时存放获取到的信息jobList = []# 提取信息page_text = bro.page_source# 将从互联网上获取的源码数据加载到tree对象中tree = etree.HTML(page_text)job = tree.xpath('//div[@class="search-job-result"]/ul/li')for i in job:# 职位job_name = i.xpath(".//span[@class='job-name']/text()")[0]# 位置jobArea = i.xpath(".//span[@class='job-area']/text()")[0]# 联系人linkman_list = i.xpath(".//div[@class='info-public']//text()")linkman = "·".join(linkman_list)# 详情页urldetail_url = prefix + i.xpath(".//h3[@class='company-name']/a/@href")[0]# print(detail_url)# 薪资salary = i.xpath(".//span[@class='salary']/text()")[0]# 经验job_lable_list = i.xpath(".//ul[@class='tag-list']//text()")job_lables = " ".join(job_lable_list)# 公司名company = i.xpath(".//h3[@class='company-name']/a/text()")[0]# 公司类型和人数等companyScale_list = i.xpath(".//div[@class='company-info']/ul//text()")companyScale = " ".join(companyScale_list)# 职位技能skill_list = i.xpath("./div[2]/ul//text()")skills = " ".join(skill_list)# 福利 如有全勤奖补贴等try:job_desc = i.xpath(".//div[@class='info-desc']/text()")[0]# print(type(info_desc))except:job_desc = ""# print(type(info_desc))# print(job_name, jobArea, salary, linkman, salaryScale, name, componyScale, tags, info_desc)# 将数据写入csvcsv.writer(f).writerow([job_name, jobArea, salary, linkman, job_lables, company, companyScale, skills, job_desc, detail_url])# 将数据存入数组中jobList.append({"jobName": job_name,"jobArea": jobArea,"salary": salary,"linkman": linkman,"jobLables": job_lables,"company": company,"companyScale": companyScale,"skills": skills,"job_desc": job_desc,"detailUrl": detail_url,})return {"jobList": jobList}总代码
import csv
from time import sleep
from selenium import webdriver
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
from lxml import etree# 指定url
urls = ['https://www.zhipin.com/', 'https://www.zhipin.com/web/geek/job?query={}&page={}']
prefix = 'https://www.zhipin.com'# 1. 初始化配置无可视化界面对象
options = webdriver.FirefoxOptions()
# 2. 无界面模式
options.add_argument('-headless')
options.add_argument('--disable-gpu')# 让selenium规避被检测到的风险
options.add_argument('excludeSwitches')# 传入浏览器的驱动
ser = Service('./geckodriver.exe')# 实例化一个浏览器对象
bro = webdriver.Firefox(service=ser, options=options)
# bro = webdriver.Firefox(service=ser# 设置隐式等待 超时时间设置为20s
# bro.implicitly_wait(20)# 让浏览器发起一个指定url请求
bro.get(urls[0])sleep(6)# 定位搜索框 .ipt-search
search_tag = bro.find_element(By.CSS_SELECTOR, value='.ipt-search')
# 输入搜索内容
search_tag.send_keys("")# 定位搜索按钮 .代表的是当前标签下的class
btn = bro.find_element(By.CSS_SELECTOR, value='.btn-search')
# 点击搜索按钮
btn.click()
sleep(15)# f = open("boos直聘.csv", "w", encoding="utf-8", newline="")
f = open("boos直聘.csv", "w", encoding="utf-8_sig", newline="")
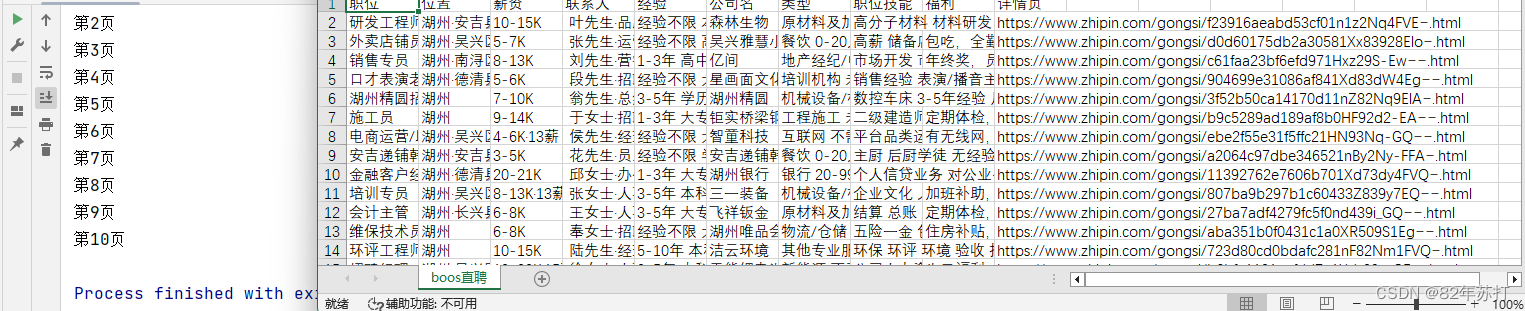
csv.writer(f).writerow(["职位", "位置", "薪资", "联系人", "经验", "公司名", "类型", "职位技能", "福利", "详情页"])def parse():# 临时存放获取到的信息jobList = []# 提取信息page_text = bro.page_source# 将从互联网上获取的源码数据加载到tree对象中tree = etree.HTML(page_text)job = tree.xpath('//div[@class="search-job-result"]/ul/li')for i in job:# 职位job_name = i.xpath(".//span[@class='job-name']/text()")[0]# 位置jobArea = i.xpath(".//span[@class='job-area']/text()")[0]# 联系人linkman_list = i.xpath(".//div[@class='info-public']//text()")linkman = "·".join(linkman_list)# 详情页urldetail_url = prefix + i.xpath(".//h3[@class='company-name']/a/@href")[0]# print(detail_url)# 薪资salary = i.xpath(".//span[@class='salary']/text()")[0]# 经验job_lable_list = i.xpath(".//ul[@class='tag-list']//text()")job_lables = " ".join(job_lable_list)# 公司名company = i.xpath(".//h3[@class='company-name']/a/text()")[0]# 公司类型和人数等companyScale_list = i.xpath(".//div[@class='company-info']/ul//text()")companyScale = " ".join(companyScale_list)# 职位技能skill_list = i.xpath("./div[2]/ul//text()")skills = " ".join(skill_list)# 福利 如有全勤奖补贴等try:job_desc = i.xpath(".//div[@class='info-desc']/text()")[0]# print(type(info_desc))except:job_desc = ""# print(type(info_desc))# print(job_name, jobArea, salary, linkman, salaryScale, name, componyScale, tags, info_desc)# 将数据写入csvcsv.writer(f).writerow([job_name, jobArea, salary, linkman, job_lables, company, companyScale, skills, job_desc, detail_url])# 将数据存入数组中jobList.append({"jobName": job_name,"jobArea": jobArea,"salary": salary,"linkman": linkman,"jobLables": job_lables,"company": company,"companyScale": companyScale,"skills": skills,"job_desc": job_desc,"detailUrl": detail_url,})return {"jobList": jobList}if __name__ == '__main__':# 访问第一页jobList = parse()query = ""# 访问剩下的九页for i in range(2, 11):print(f"第{i}页")url = urls[1].format(query, i)bro.get(url)sleep(15)jobList = parse()# 关闭浏览器bro.quit()效果展示
六、总结
不知道是boss反爬做的太好,还是我个人太菜(哭~)
我个人倾向于第二种
这个爬虫还有很多很多的不足之处,比如在页面加载的时候,boss的页面会多次加载(这里我很是不理解,我明明只访问了一次,但是他能加载好多次),这就导致是不是ip就会被封…
再比如,那个下一页的点击按钮,一直点不了,不知有没有路过的大佬指点一二(呜呜呜~)
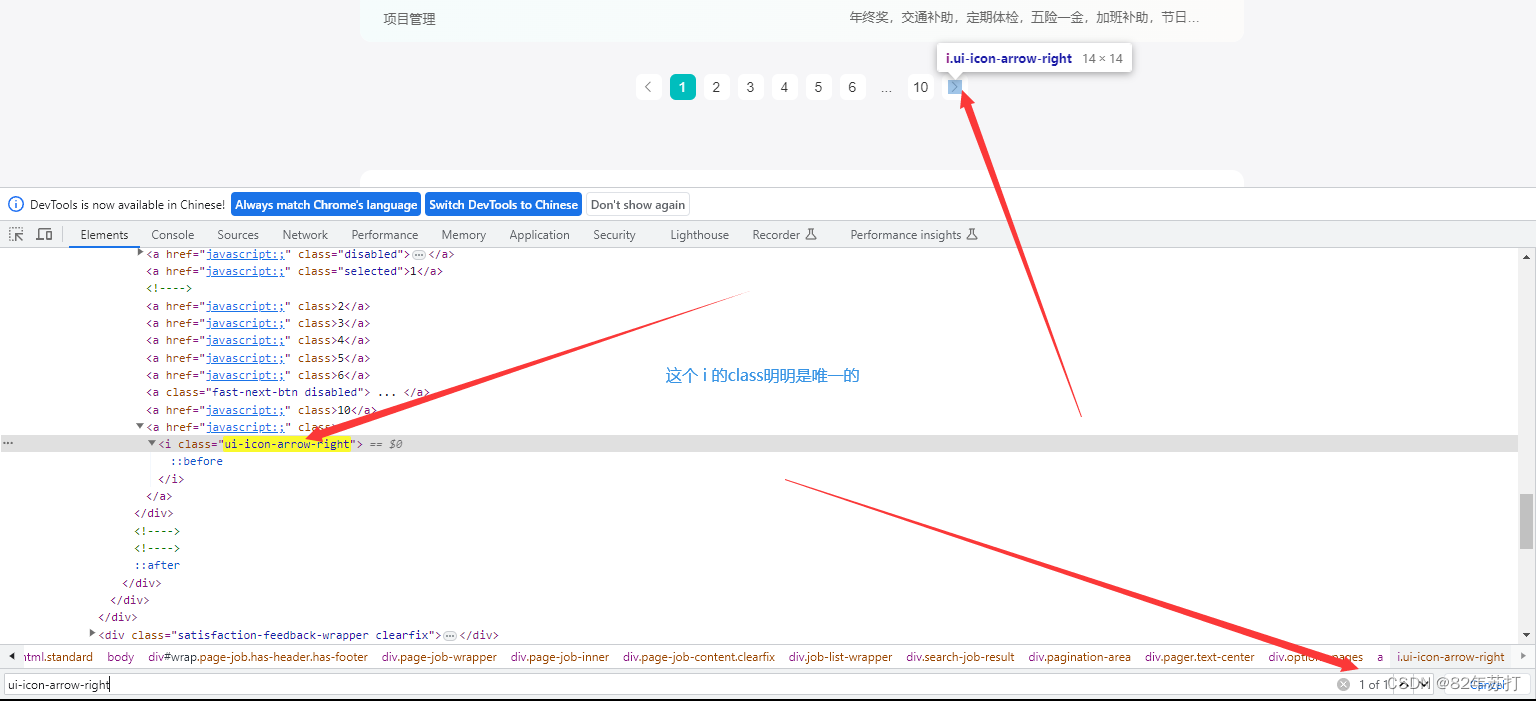
# 下一页标签定位 ui-icon-arrow-right
next_tag = bro.find_element(By.CSS_SELECTOR, value='.ui-icon-arrow-right')
# action = ActionChains(bro)
# # 点击指定的标签
# action.click(next_tag).perform()
# sleep(0.1)
# # 释放动作链
# action.release().perform()
总之boss的信息爬取,我还是无法做到完全自动化😭
相关文章:
python爬取boss直聘数据(selenium+xpath)
文章目录 一、主要目标二、开发环境三、selenium安装和驱动下载四、主要思路五、代码展示和说明1、导入相关库2、启动浏览器3、搜索框定位创建csv文件招聘页面数据解析(XPATH)总代码效果展示 六、总结 一、主要目标 以boss直聘为目标网站,主要目的是爬取下图中的所…...
GEO生信数据挖掘(六)实践案例——四分类结核病基因数据预处理分析
前面五节,我们使用阿尔兹海默症数据做了一个数据预处理案例,包括如下内容: GEO生信数据挖掘(一)数据集下载和初步观察 GEO生信数据挖掘(二)下载基因芯片平台文件及注释 GEO生信数据挖掘&…...

8.Mobilenetv2网络代码实现
代码如下: import math import os import numpy as npimport torch import torch.nn as nn import torch.utils.model_zoo as model_zoo#1.建立带有bn的卷积网络 def conv_bn(inp, oup, stride):return nn.Sequential(nn.Conv2d(inp,oup,3,stride,biasFalse),nn.Bat…...

Spring Boot Controller
刚入门小白,详细请看这篇SpringBoot各种Controller写法_springboot controller-CSDN博客 Spring Boot 提供了Controller和RestController两种注解。 Controller 返回一个string,其内容就是指向的html文件名称。 Controller public class HelloControll…...

在网络安全、爬虫和HTTP协议中的重要性和应用
1. Socks5代理:保障多协议安全传输 Socks5代理是一种功能强大的代理协议,支持多种网络协议,包括HTTP、HTTPS和FTP。相比之下,Socks5代理提供了更高的安全性和功能性,包括: 多协议支持: Socks5代…...
Web测试框架SeleniumBase
首先,SeleniumBase支持 pip安装: > pip install seleniumbase它依赖的库比较多,包括pytest、nose这些第三方单元测试框架,是为更方便的运行测试用例,因为这两个测试框架是支持unittest测试用例的执行的。 Seleniu…...

jvm打破砂锅问到底- 为什么要标记或记录跨代引用
为什么要标记或记录跨代引用. ygc时, 直接把老年代引用的新生代对象(可能是对象区域)记录下来当做根, 这其实就是依据第二假说和第三假说, 强者恒强, 跨代引用少(存在互相引用关系的两个对象,是应该倾 向于同时生存或者同时消亡的). 拿ygc老年代跨代引用对象当做根…...

小程序长期订阅
准备工作 ::: tip 管理后台配置 小程序类目:住建(硬性要求) 功能-》订阅消息-》我的模版 申请模版:1、预约进度通知 2、申请结果通知 3、业务办理进度提醒 ::: 用户订阅一次后,可长期下发多条消息。目前长期性订阅…...

Studio One6.5中文版本版下载及功能介绍
Studio One是一款专业的音乐制作软件,由美国PreSonus公司开发。该软件提供了全面的音频编辑和混音功能,包括录制、编曲、合成、采样等多种工具,可用于制作各种类型的音乐,如流行音乐、电子音乐、摇滚乐等。 Studio One的主要特点…...

07-Zookeeper分布式一致性协议ZAB源码剖析
上一篇:06-Zookeeper选举Leader源码剖析 整个Zookeeper就是一个多节点分布式一致性算法的实现,底层采用的实现协议是ZAB。 1. ZAB协议介绍 ZAB 协议全称:Zookeeper Atomic Broadcast(Zookeeper 原子广播协议)。 Zook…...

云原生安全应用场景有哪些?
当今数字化时代,数据已经成为企业最宝贵的资产之一,而云计算作为企业数字化转型的关键技术,其安全性也日益受到重视。随着云计算技术的快速发展,云原生安全应用场景也越来越广泛,下面本文将从云原生安全应用场景出发&a…...

Step 1 搭建一个简单的渲染框架
Step 1 搭建一个简单的渲染框架 万事开头难。从萌生到自己到处看源码手抄一个mini engine出来的想法,到真正敲键盘去抄,转眼过去了很久的时间。这次大概的确是抱着认真的想法,打开VS从零开始抄代码。不知道能坚持多久呢。。。 本次的主题是搭…...
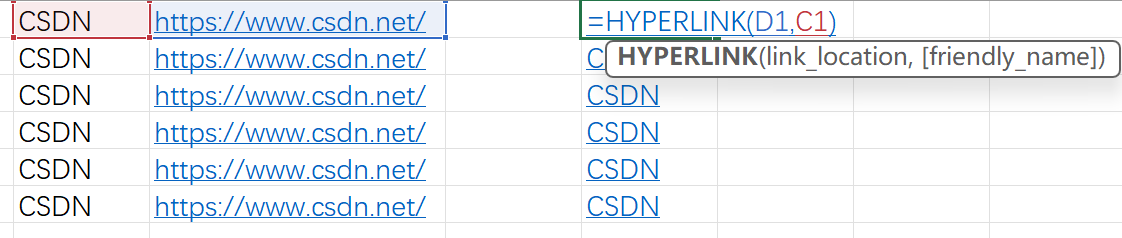
Excel 插入和提取超链接
构造超链接 HYPERLINK(D1,C1)提取超链接 Sheet页→右键→查看代码Sub link()Dim hl As HyperlinkFor Each hl In ActiveSheet.Hyperlinkshl.Range.Offset(0, 1).Value hl.AddressNext End Sub工具栏→运行→运行子过程→提取所有超链接地址参考: https://blog.cs…...

基础架构开发-操作系统、编译器、云原生、嵌入式、ic
基础架构开发-操作系统、编译器、云原生、嵌入式、ic 操作系统编译器词法分析AST语法树生成语法优化生成机器码 云原生容器开发一般遇到的岗位描述RDMA、DPDK是什么东西NFV和VNF是什么RisingWave云原生存储引擎开发实践 单片机、嵌入式雷达路线规划 ic开发 操作系统 以C和Rust…...
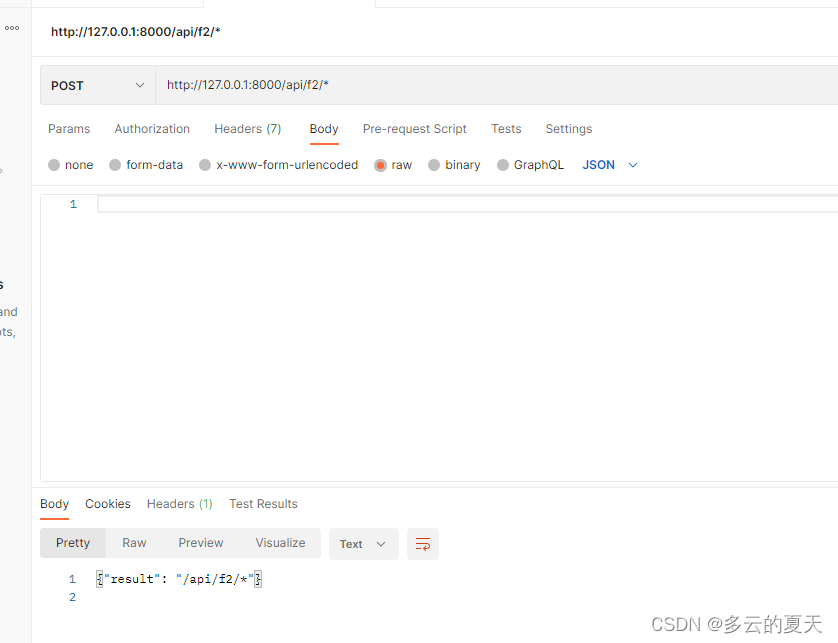
C++-Mongoose(3)-http-server-https-restful
1.url 结构 2.http和 http-restful区别在于对于mg_tls_opts的赋值 2.1 http和https 区分 a) port地址 static const char *s_http_addr "http://0.0.0.0:8000"; // HTTP port static const char *s_https_addr "https://0.0.0.0:8443"; // HTTP…...
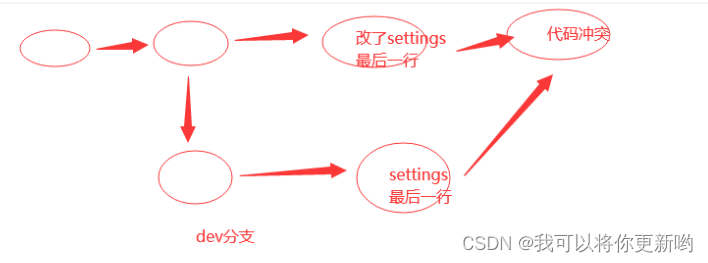
git多分支、git远程仓库、ssh方式连接远程仓库、协同开发(避免冲突)、解决协同冲突(多人在同一分支开发、 合并分支)
1 git多分支 2 git远程仓库 2.1 普通开发者,使用流程 3 ssh方式连接远程仓库 4 协同开发 4.1 避免冲突 4.2 协同开发 5 解决协同冲突 5.1 多人在同一分支开发 5.2 合并分支 1 git多分支 ## 命令操作分支-1 创建分支git branch dev-2 查看分支git branch-3 分支合…...

ChatGPT或将引发现代知识体系转变
作为当下大语言模型的典型代表,ChatGPT对人类学习方式和教育发展所产生的变革效应已然引起了广泛关注。技术的快速发展在某种程度上正在“倒逼”教育领域开启更深层次的变革。在此背景下,教育从业者势必要学会准确识变、科学应变、主动求变、以变应变&am…...
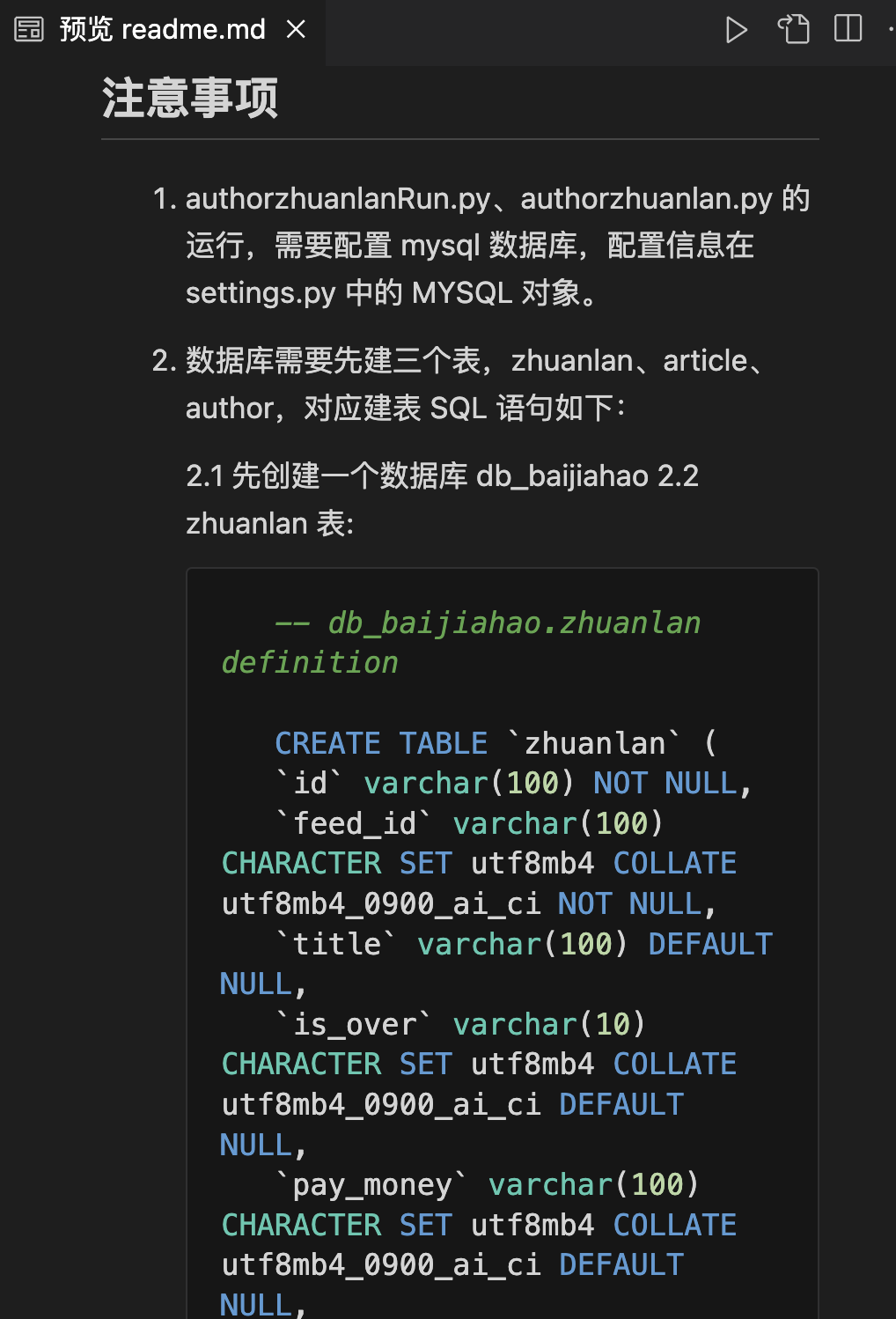
【爬虫实战】用pyhon爬百度故事会专栏
一.爬虫需求 获取对应所有专栏数据;自动实现分页;多线程爬取;批量多账号爬取;保存到mysql、csv(本案例以mysql为例);保存数据时已存在就更新,无数据就添加; 二.最终效果…...

焦炭反应性及反应后强度试验方法
声明 本文是学习GB-T 4000-2017 焦炭反应性及反应后强度试验方法. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 7— 进气口; 8— 测温热电偶。 图 A.1 单点测温加热炉体结构示意图 A.3 温度控制装置 控制精度:(11003)℃。…...
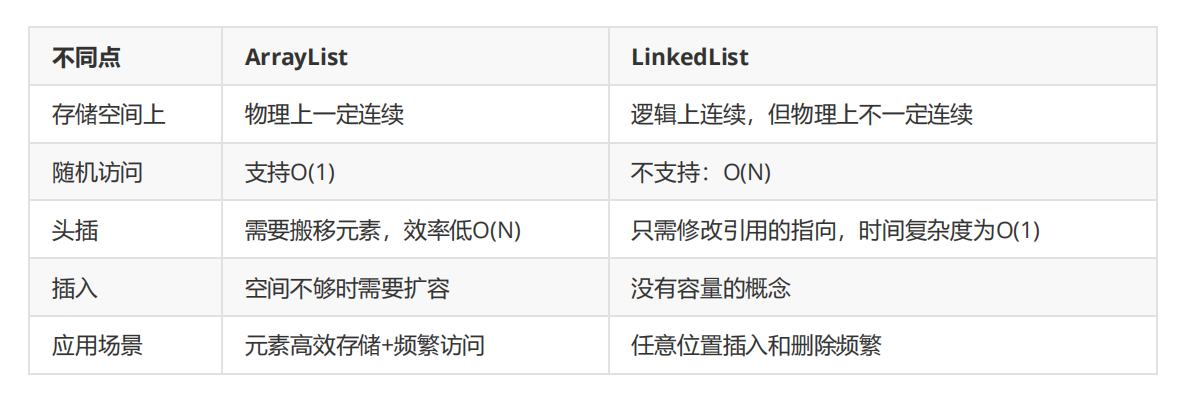
链表(3):双链表
引入 我们之前学的单向链表有什么缺点呢? 缺点:后一个节点无法看到前一个节点的内容 那我们就多设置一个格子prev用来存放前面一个节点的地址,第一个节点的prev存最后一个节点的地址(一般是null) 这样一个无头双向…...

别再只用人体红外了!聊聊24.125GHz微波模块在智能家居中的另类玩法与局限
24.125GHz微波传感模块的智能家居创新应用与工程实践 在智能家居领域,人体感应技术早已从简单的红外探测走向多传感器融合时代。当大多数开发者还在依赖传统PIR红外传感器时,一种成本仅20元左右的24.125GHz微波模块正在小众硬件圈引发讨论。这种原本用于…...

Android项目集成CH340串口驱动:从官方Demo到体温检测模块的完整配置流程
Android项目集成CH340串口驱动:从官方Demo到体温检测模块的完整配置流程 在医疗设备、工业控制等物联网场景中,Android设备与外围硬件通过串口通信的需求日益增长。CH340作为一款高性价比的USB转串口芯片,因其稳定性和广泛兼容性成为许多硬件…...

基板式PCB与嵌入式芯片:下一代电子系统集成的核心技术解析
1. 项目概述:从一块“板子”看透一个产业干了十几年硬件,从画第一块51单片机的板子,到如今参与定义复杂的系统级封装,我越来越觉得,PCB(印制电路板)和芯片的关系,早已不是简单的“承…...
)
QT ToolButton的5个隐藏技巧与3个常见坑,新手避雷指南(基于Qt 6.5)
QT ToolButton的5个隐藏技巧与3个常见坑,新手避雷指南(基于Qt 6.5) 在模仿现代软件工具栏设计时,QT的ToolButton组件往往是实现专业级交互的关键。但许多开发者第一次使用时会发现,这个看似简单的按钮藏着不少"陷…...

永强数据恢复硬盘设备加密数据专业解锁恢复服务
在当今数字化时代,数据的重要性不言而喻。无论是个人用户存储的珍贵照片、视频,还是企业存储的关键商业数据,一旦丢失,都可能带来巨大的损失。而硬盘设备加密数据的丢失或无法解锁,更是让人头疼不已。北京永强数据恢复…...

命令行媒体管理工具amem:本地化素材归档与自动化实践
1. 项目概述:一个被低估的本地化媒体管理工具最近在整理个人数字资产时,我遇到了一个老生常谈但又无比棘手的问题:如何高效、优雅地管理那些散落在硬盘各个角落的短视频、图片和音频文件?无论是手机拍摄的生活片段,还是…...

基于BLE MIDI的智能木琴:用Arduino与电磁铁桥接物理乐器与数字音频工作站
1. 项目概述:当传统木琴遇见现代数字音乐如果你和我一样,既着迷于传统打击乐器那清脆、富有共鸣的物理音色,又离不开现代数字音频工作站(DAW)那强大的创作和编辑能力,那么“如何将两者无缝桥接”可能一直是…...

WeChatExporter:将你的数字记忆转化为永恒的数字档案
WeChatExporter:将你的数字记忆转化为永恒的数字档案 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾有过这样的经历?深夜翻看旧手机&…...

SISSO 终极指南:数据驱动建模的强大工具
SISSO 终极指南:数据驱动建模的强大工具 【免费下载链接】SISSO A data-driven method combining symbolic regression and compressed sensing for accurate & interpretable models. 项目地址: https://gitcode.com/gh_mirrors/si/SISSO SISSO…...

靠谱的openai claudecode AI中转站
各位大神开发都用那些模型?最近用Trae的模型一下就降智,切换到apikeyfun.com 用了ops4.7和gpt5.5简直是降维打击,速度快,还不错!...