《动手学深度学习 Pytorch版》 8.5 循环神经网络的从零开始实现
%matplotlib inline
import math
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps) # 仍然使用时间机器数据集
8.5.1 独热编码
采样的小批量数据形状是二维张量:(批量大小,时间步数)。one_hot 函数将这样一个小批量数据转换成形状为(时间步数,批量大小,词表大小)的输出。这将使我们能够更方便地通过最外层的维度, 一步一步地更新小批量数据的隐状态。
F.one_hot(torch.tensor([0, 2]), len(vocab))
tensor([[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0],[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0]])
X = torch.arange(10).reshape((2, 5))
F.one_hot(X.T, 28).shape # 转置一下把时间放前面
torch.Size([5, 2, 28])
8.5.2 初始化模型参数
def get_params(vocab_size, num_hiddens, device):num_inputs = num_outputs = vocab_size # 输入是独热编码所以长度是vocab_size;输出是在vocab里面预测所以长度也是vocab_sizedef normal(shape):return torch.randn(size=shape, device=device) * 0.01# 隐藏层参数W_xh = normal((num_inputs, num_hiddens))W_hh = normal((num_hiddens, num_hiddens))b_h = torch.zeros(num_hiddens, device=device)# 输出层参数W_hq = normal((num_hiddens, num_outputs))b_q = torch.zeros(num_outputs, device=device)# 附加梯度params = [W_xh, W_hh, b_h, W_hq, b_q]for param in params:param.requires_grad_(True)return params
8.5.3 循环神经网络
init_rnn_state 函数在初始化时返回隐状态。这个函数返回的是一个全用 0 填充的张量,张量形状为(批量大小,隐藏单元数)。
def init_rnn_state(batch_size, num_hiddens, device):return (torch.zeros((batch_size, num_hiddens), device=device), )
rnn 函数在一个时间步内计算隐状态和输出。这里使用 tanh 函数作为激活函数。如前节所述,当元素在实数上满足均匀分布时,tanh 函数的平均值为0。
def rnn(inputs, state, params): # inputs的形状:(时间步数量,批量大小,词表大小)W_xh, W_hh, b_h, W_hq, b_q = paramsH, = stateoutputs = []for X in inputs: # X的形状:(批量大小,词表大小) 前面转置是为了这里遍历H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h) # 计算隐状态Y = torch.mm(H, W_hq) + b_q # 计算输出outputs.append(Y)return torch.cat(outputs, dim=0), (H,) # 沿时间步拼接
创建一个类来包装上述函数,并存储从零开始实现的循环神经网络模型的参数。
class RNNModelScratch: #@save"""从零开始实现的循环神经网络模型"""def __init__(self, vocab_size, num_hiddens, device,get_params, init_state, forward_fn):self.vocab_size, self.num_hiddens = vocab_size, num_hiddensself.params = get_params(vocab_size, num_hiddens, device)self.init_state, self.forward_fn = init_state, forward_fndef __call__(self, X, state):X = F.one_hot(X.T, self.vocab_size).type(torch.float32)return self.forward_fn(X, state, self.params)def begin_state(self, batch_size, device):return self.init_state(batch_size, self.num_hiddens, device)
测试输出维度是否不变。
num_hiddens = 512
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn)
state = net.begin_state(X.shape[0], d2l.try_gpu())
Y, new_state = net(X.to(d2l.try_gpu()), state)
Y.shape, len(new_state), new_state[0].shape
(torch.Size([10, 28]), 1, torch.Size([2, 512]))
8.5.4 预测
首先定义预测函数来生成 prefix (用户提供的多字符的字符串)之后的新字符。
在循环遍历 prefix 中的开始字符时,不断地将隐状态传递到下一个时间步,但是不生成任何输出。这被称为 预热期(warm-up),因为在此期间模型会自我更新(例如,更新隐状态),但不会进行预测。预热期结束后,隐状态的值通常比刚开始的初始值更适合预测,从而预测字符并输出它们。
def predict_ch8(prefix, num_preds, net, vocab, device): #@save"""在prefix后面生成新字符"""state = net.begin_state(batch_size=1, device=device)outputs = [vocab[prefix[0]]] # 调用 vocab 类的 __getitem__ 方法get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1)) # 把预测结果(结果的最后一个)作为下一个的输入for y in prefix[1:]: # 预热期 把前缀先载进模型_, state = net(get_input(), state)outputs.append(vocab[y])for _ in range(num_preds): # 预测 num_preds 步y, state = net(get_input(), state)outputs.append(int(y.argmax(dim=1).reshape(1))) # 优雅return ''.join([vocab.idx_to_token[i] for i in outputs])
predict_ch8('time traveller ', 10, net, vocab, d2l.try_gpu()) # 没有训练过,会生成荒谬的结果
'time traveller gnwvr gnwv'
8.5.5 梯度裁剪
对于长度为 T T T 的序列,我们在迭代中计算 T T T 这个时间步上的梯度,将会在反向传播过程中产生长度为 O ( T ) O(T) O(T) 的矩阵乘法链。当 T T T 较大时,数值不稳定可能导致梯度爆炸或梯度消失。
一个流行的替代方案是通过将梯度 g g g 投影回给定半径 θ \theta θ 的球来裁剪梯度:
g ← min ( 1 , θ ∣ ∣ g ∣ ∣ ) g g\gets\min\left(1,\frac{\theta}{||g||}\right)g g←min(1,∣∣g∣∣θ)g
def grad_clipping(net, theta): #@save"""裁剪梯度"""if isinstance(net, nn.Module):params = [p for p in net.parameters() if p.requires_grad]else:params = net.paramsnorm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params)) # 计算范数if norm > theta: # 限制梯度范围for param in params:param.grad[:] *= theta / norm
8.5.6 训练
与之前训练模型的方式有三个不同之处:
-
序列数据的不同采样方法将导致隐状态初始化的差异。
-
当使用顺序分区时, 我们只在每个迭代周期的开始位置初始化隐状态。
由于下一个小批量数据中的序列样本 与当前子序列样本相邻,因此当前小批量数据最后一个样本的隐状态将用于初始化下一个小批量数据第一个样本的隐状态。
-
当使用随机抽样时,因为每个样本都是在一个随机位置抽样的,因此需要为每个迭代周期重新初始化隐状态。
-
-
在更新模型参数之前裁剪梯度。即使训练过程中某个点上发生了梯度爆炸,也能保证模型不会发散。
- 在任何一点隐状态的计算,都依赖于同一迭代周期中前面所有的小批量数据,这使得梯度计算变得复杂。为了降低计算量,在处理任何一个小批量数据之前,我们先分离梯度,使得隐状态的梯度计算总是限制在一个小批量数据的时间步内。
-
我们用困惑度来评价模型,确保了不同长度的序列具有可比性。
#@save
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):"""训练网络一个迭代周期(定义见第8章)"""state, timer = None, d2l.Timer()metric = d2l.Accumulator(2) # 训练损失之和,词元数量for X, Y in train_iter:if state is None or use_random_iter:# 在第一次迭代或使用随机抽样时初始化statestate = net.begin_state(batch_size=X.shape[0], device=device)else:if isinstance(net, nn.Module) and not isinstance(state, tuple):# state对于nn.GRU是个张量state.detach_()else:# state对于nn.LSTM或对于我们从零开始实现的模型是个张量for s in state:s.detach_()y = Y.T.reshape(-1) # 经典转置X, y = X.to(device), y.to(device)y_hat, state = net(X, state)l = loss(y_hat, y.long()).mean()if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.backward()grad_clipping(net, 1)updater.step()else:l.backward()grad_clipping(net, 1)# 因为已经调用了mean函数updater(batch_size=1)metric.add(l * y.numel(), y.numel())return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
#@save
def train_ch8(net, train_iter, vocab, lr, num_epochs, device,use_random_iter=False):"""训练模型(定义见第8章)"""loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',legend=['train'], xlim=[10, num_epochs])# 初始化if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(), lr)else:updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)# 训练和预测for epoch in range(num_epochs):ppl, speed = train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter)if (epoch + 1) % 10 == 0:print(predict('time traveller'))animator.add(epoch + 1, [ppl])print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')print(predict('time traveller'))print(predict('traveller'))
num_epochs, lr = 500, 1 # 因为只使用了10000个词元,所以模型需要更多的迭代周期来更好地收敛
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu()) # 先来一波默认的顺序分区
困惑度 1.0, 84837.9 词元/秒 cuda:0
time traveller for so it will be convenient to speak of himwas e
travelleryou can show black is white by argument said filby

困惑度 1.0,属于是把书背下来了。
net1 = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn)
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu(),use_random_iter=True) # 使用随机抽样方法
困惑度 1.5, 79291.4 词元/秒 cuda:0
time traveller held in his hand was a glitteringmetallic framewo
travellerit would be remarkably convenient for the historia

练习
(1)尝试说明独热编码等价于为每个对象选择不同的嵌入表示。
不会,略
(2)通过调整超参数(如轮数、隐藏单元数、小批量数据的时间步数、学习率等)来改善困惑度。
a. 困惑度可以降到多少?
b. 用可学习的嵌入表示替换独热编码,是否会带来更好的表现?
c. 如果用H.G.Wells的其他书作为数据集时效果如何, 例如世界大战?
能降,b c太麻烦了,略。
batch_size, num_steps2 = 32, 64
train_iter2, vocab = d2l.load_data_time_machine(batch_size, num_steps2)num_hiddens2 = 1024
net2 = RNNModelScratch(len(vocab), num_hiddens2, d2l.try_gpu(), get_params,init_rnn_state, rnn)num_epochs2, lr2 = 1000, 0.5
train_ch8(net2, train_iter2, vocab, lr2, num_epochs2, d2l.try_gpu(),use_random_iter=True) # 使用随机抽样方法,顺序分区已经降无可降了
困惑度 1.2, 58441.2 词元/秒 cuda:0
time traveller for so it will be convenient to speak of himwas e
traveller with a slight accession ofcheerfulness really thi

(3)修改预测函数,例如使用抽样,而不是选择最有可能的下一个字符。
a. 会发生什么?
b. 调整模型使之偏向更可能的输出,例如,当 α > 1 \alpha >1 α>1,从 q ( x t ∣ x t − 1 , … , x 1 ) ∝ P ( x t ∣ x t − 1 , … , x 1 ) α q(x_t|x_{t-1},\dots,x_1)\propto P(x_t|x_{t-1},\dots,x_1)^\alpha q(xt∣xt−1,…,x1)∝P(xt∣xt−1,…,x1)α 中采样。
不会,略。
(4)在不裁剪梯度的情况下运行本节中的代码会发生什么?
略。
def train_epoch_ch8_4(net, train_iter, loss, updater, device, use_random_iter):state, timer = None, d2l.Timer()metric = d2l.Accumulator(2)for X, Y in train_iter:if state is None or use_random_iter:state = net.begin_state(batch_size=X.shape[0], device=device)else:if isinstance(net, nn.Module) and not isinstance(state, tuple):state.detach_()else:for s in state:s.detach_()y = Y.T.reshape(-1)X, y = X.to(device), y.to(device)y_hat, state = net(X, state)l = loss(y_hat, y.long()).mean()if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.backward()# grad_clipping(net, 1) # 去掉梯度裁剪updater.step()else:l.backward()# grad_clipping(net, 1) # 去掉梯度裁剪updater(batch_size=1)metric.add(l * y.numel(), y.numel())return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()def train_ch8_4(net, train_iter, vocab, lr, num_epochs, device,use_random_iter=False):loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',legend=['train'], xlim=[10, num_epochs])if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(), lr)else:updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device)for epoch in range(num_epochs):ppl, speed = train_epoch_ch8_4(net, train_iter, loss, updater, device, use_random_iter)if (epoch + 1) % 10 == 0:print(predict('time traveller'))animator.add(epoch + 1, [ppl])print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')print(predict('time traveller'))print(predict('traveller'))
net3 = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn)
num_epochs, lr = 500, 1
train_ch8_4(net3, train_iter, vocab, lr, num_epochs, d2l.try_gpu()) # 去掉梯度裁剪直接爆炸
困惑度 195745164855533848843693558201405885920387170281738976926429980299285757160792307487577948624519168.0, 92924.4 词元/秒 cuda:0
time travellertttttttttttttttttttttttttttttttttttttttttttttttttt
travellertttttttttttttttttttttttttttttttttttttttttttttttttt

(5)更改顺序划分,使其不会从计算图中分离隐状态。运行时间会有变化吗?困惑度呢?
略。
(6)用 ReLU 替换本节中使用的激活函数,并重复本节中的实验。我们还需要梯度裁剪吗?为什么?
def rnn_6(inputs, state, params):W_xh, W_hh, b_h, W_hq, b_q = paramsH, = stateoutputs = []for X in inputs:H = torch.relu(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)Y = torch.mm(H, W_hq) + b_qoutputs.append(Y)return torch.cat(outputs, dim=0), (H,)
net4 = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn_6)
num_epochs, lr = 500, 1
train_ch8_4(net4, train_iter, vocab, lr, num_epochs, d2l.try_gpu()) # 用 Relu 好像不用裁剪也行哇,收敛更快了
困惑度 1.0, 83541.7 词元/秒 cuda:0
time traveller for so it will be convenient to speak of himwas e
traveller with a slight accession ofcheerfulness really thi

net5 = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn_6)
num_epochs, lr = 500, 1
train_ch8(net5, train_iter, vocab, lr, num_epochs, d2l.try_gpu()) # 换了 Relu 好像用不用裁剪没差
困惑度 1.0, 88798.8 词元/秒 cuda:0
time traveller with a slight accession ofcheerfulness really thi
traveller with a slight accession ofcheerfulness really thi

相关文章:
《动手学深度学习 Pytorch版》 8.5 循环神经网络的从零开始实现
%matplotlib inline import math import torch from torch import nn from torch.nn import functional as F from d2l import torch as d2lbatch_size, num_steps 32, 35 train_iter, vocab d2l.load_data_time_machine(batch_size, num_steps) # 仍然使用时间机器数据集8.…...

写一个宏,可以将一个整数的二进制位的奇数位和偶数位交换
我们这里是利用按位与来计算的 我们可以想想怎么保留偶数上的位?我们可以利用0x55555555按位与上这个数就保留了偶数 我们知道,16进制0x55555555转换为二进制就是0x01010101010101010101010101010101 我们知道,二进制每一位,如…...
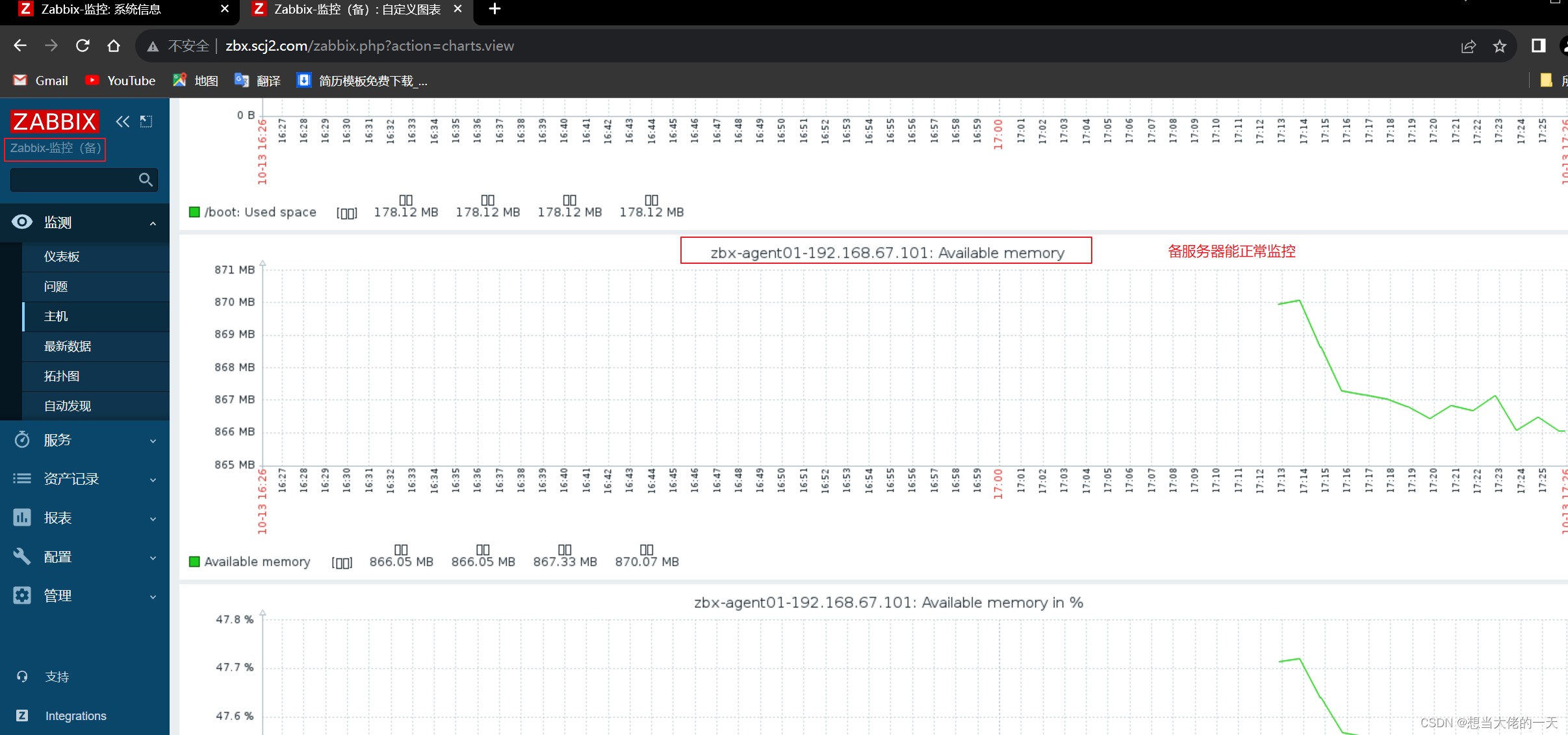
Zabbix监控系统详解2:基于Proxy分布式实现Web应用监控及Zabbix 高可用集群的搭建
文章目录 1. zabbix-proxy的分布式监控的概述1.1 分布式监控的主要作用1.2 监控数据流向1.3 构成组件1.3.1 zabbix-server1.3.2 Database1.3.3 zabbix-proxy1.3.4 zabbix-agent1.3.5 web 界面 2. 部署zabbix代理服务器2.1 前置准备2.2 配置 zabbix 的下载源,安装 za…...
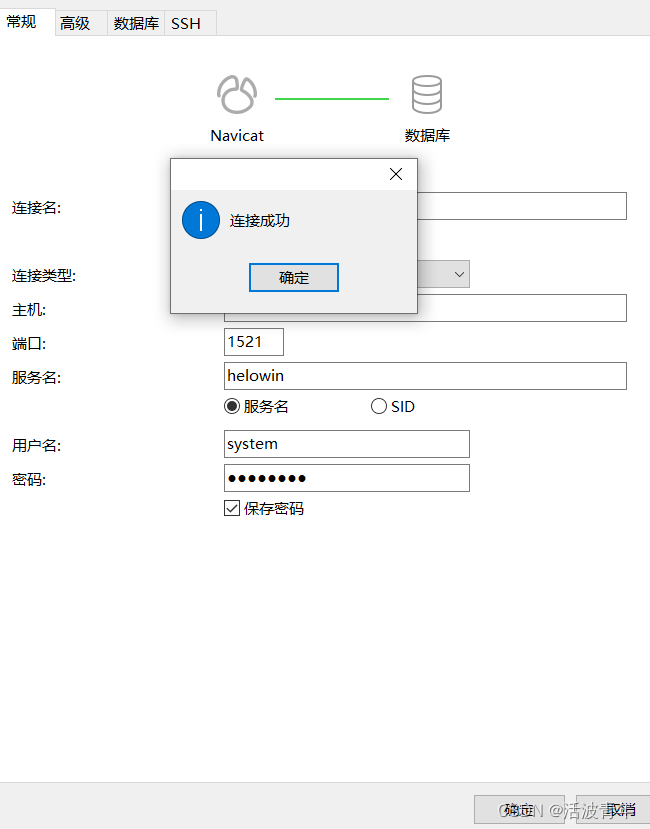
docker 安装oracle
拉取镜像 拉取oracle_11g镜像 拉取oracle镜像(oracle 11.0.2 64bit 企业版 实例名: helowin) Oracle主要在Docker基础上安装,安装环境注意空间和内存,Oracle是一个非常庞大的一个软件, 建议使用网易镜像或阿里镜像网站这里以oracle 11.0.2…...
)
C++ vector 自定义排序规则(vector<vector<int>>、vector<pair<int,int>>)
vector< int > vector<int> vec{1,2,3,4};//默认从小到大排序 1234 sort(vec.begin(),vec.end()); //从大到小排序 4321 sort(vec.begin(),vec.end(),greater<int>());二维向量vector<vector< int >> vector<vector<int>> vec{{0…...

机器学习 Q-Learning
对马尔可夫奖励的理解 看的这个教程 公式:V(s) R(s) γ * V(s’) V(s) 代表当前状态 s 的价值。 R(s) 代表从状态 s 到下一个状态 s’ 执行某个动作后所获得的即时奖励。 γ 是折扣因子,它表示未来奖励的重要性,通常取值在 0 到 1 之间。…...

产品设计心得体会 优漫动游
产品设计需要综合考虑用户需求、市场需求和技术可行性,从而设计出能够满足用户需求并具有市场竞争力的产品。以下是我在产品设计方面的心得体会: 产品设计心得体会 1.深入了解用户需求:在产品设计之前,需要进行充分的用户调研…...

前端--CSS
文章目录 CSS的介绍 引入方式 代码风格 选择器 复合选择器 (选学) 常用元素属性 背景属性 圆角矩形 Chrome 调试工具 -- 查看 CSS 属性 元素的显示模式 盒模型 弹性布局 一、CSS的介绍 层叠样式表 (Cascading Style Sheets). CSS 能够对网页中元素位置的排版进行像素级精…...
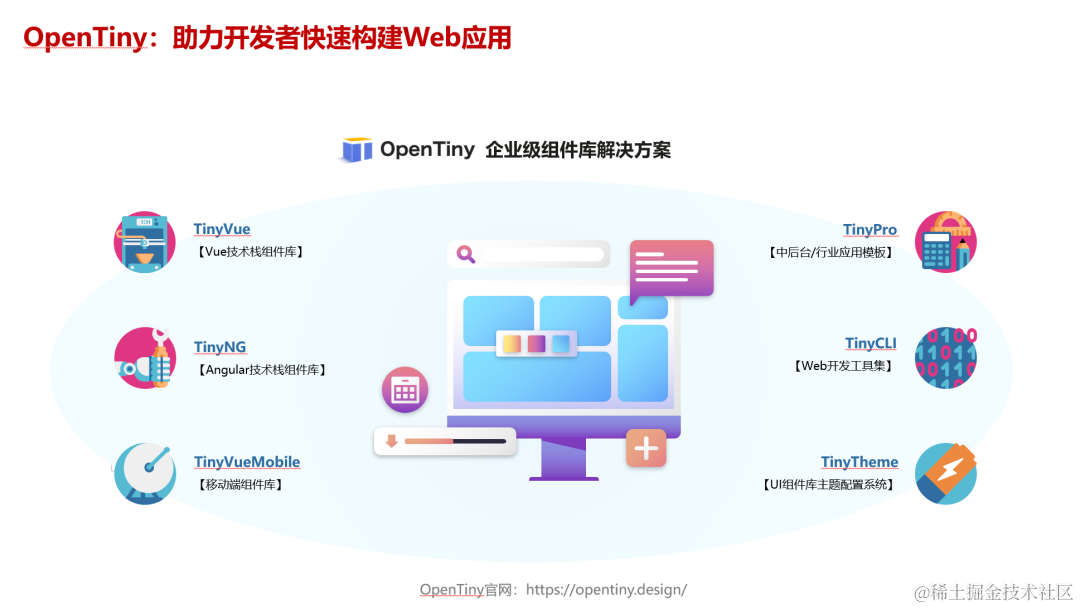
实操指南|如何用 OpenTiny Vue 组件库从 Vue 2 升级到 Vue 3
前言 根据 Vue 官网文档的说明,Vue2 的终止支持时间是 2023 年 12 月 31 日,这意味着从明年开始: Vue2 将不再更新和升级新版本,不再增加新特性,不再修复缺陷 虽然 Vue3 正式版本已经发布快3年了,但据我了…...

系统架构设计:15 论软件架构的生命周期
目录 一 软件架构的生命周期 1 需求分析阶段 2 设计阶段 3 实现阶段 4 构件组装阶段...

金山wps golang面试题总结
简单自我介绍如果多个协程并发写map 会导致什么问题如何解决(sync.map,互斥锁,信号量)chan 什么时候会发生阻塞如果 chan 缓冲区满了是阻塞还是丢弃还是panicchan 什么时候会 panic描述一下 goroutine 的调度机制goroutine 什么时…...

计算机视觉实战--直方图均衡化和自适应直方图均衡化
计算机视觉 文章目录 计算机视觉前言一、直方图均衡化1.得到灰度图2. 直方图统计3. 绘制直方图4. 直方图均衡化 二、自适应直方图均衡化1.自适应直方图均衡化(AHE)2.限制对比度自适应直方图均衡化(CRHE)3.读取图片4.自适应直方图均…...

501. 二叉搜索树中的众数
501. 二叉搜索树中的众数 # Definition for a binary tree node. # class TreeNode: # def __init__(self, val0, leftNone, rightNone): # self.val val # self.left left # self.right right class Solution:def findMode(self, root: Option…...

【Linux】常用命令
目录 文件解压缩服务器文件互传scprsync 进程资源网络curl发送简单get请求发送 POST 请求发送 JSON 数据保存响应到文件 文件 ls,打印当前目录下所有文件和目录; ls -l,打印每个文件的基本信息 pwd,查看当前目录的路径 查看文件 catless:可以左右滚动阅读more :翻…...
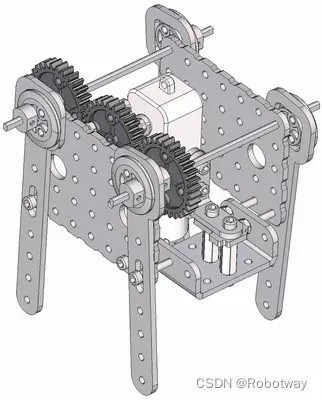
机器人制作开源方案 | 齿轮传动轴偏心轮摇杆简易四足
1. 功能描述 齿轮传动轴偏心轮摇杆简易四足机器人是一种基于齿轮传动和偏心轮摇杆原理的简易四足机器人。它的设计原理通常如下: ① 齿轮传动:通过不同大小的齿轮传动,实现机器人四条腿的运动。通常采用轮式齿轮传动或者行星齿轮传动…...
Windows中将tomcat以服务的形式安装,然后在服务进行启动管理
Windows中将tomcat以服务的形式安装,然后在服务进行启动管理 第一步: 在已经安装好的tomcat的bin目录下: 输入cmd,进入命令窗口 安装服务: 输入如下命令,最后是你的服务名,避免中文和特殊字符 service.…...
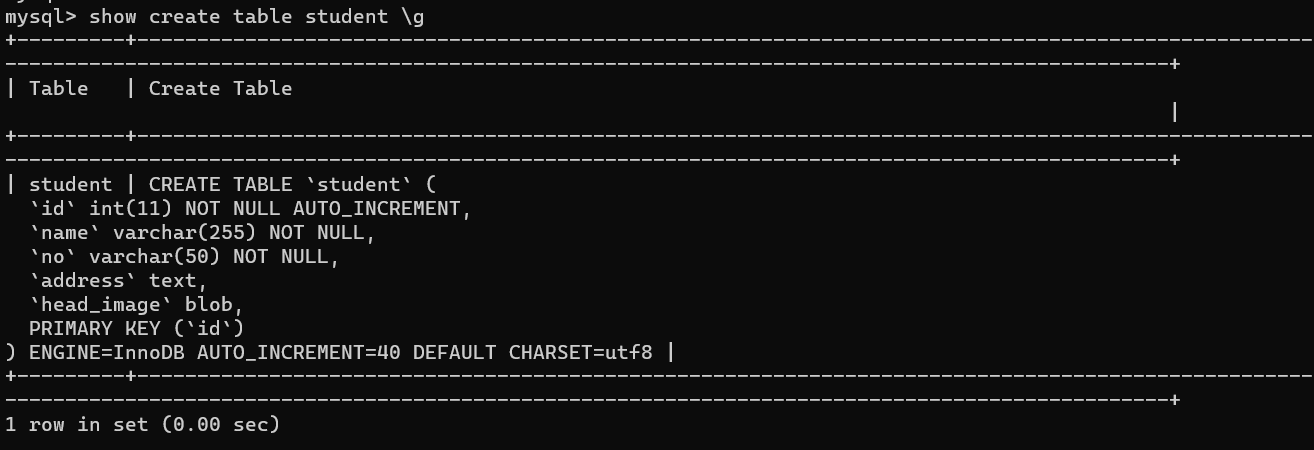
解决ERROR: No query specified的错误以及\G 和 \g 的区别
文章目录 1. 复现错误2. 分析错误3. 解决问题4. \G和\g的区别 1. 复现错误 今天使用powershell连接数据库后,执行如下SQL语句: mysql> select * from student where id 39 \G;虽然成功查询除了数据,但报出如下错误的信息: my…...

mysql中SUBSTRING_INDEX函数用法详解
MySQL中的SUBSTRING_INDEX函数用于从字符串中提取子字符串,其用法如下: SUBSTRING_INDEX(str, delim, count)参数说明: str:要提取子字符串的原始字符串。delim:分隔符,用于确定子字符串的位置。count&am…...

AndroidStudio报错:android.support.v4.app.Fragment
解决办法一 android.support.v4.app.Fragment替换为android.app.Fragment 解决办法二 有时太多,先类型过去再说。 找到gradle.properties,修改: android.useAndroidXfalse android.enableJetifierfalse...
今年这情况,还能不能选计算机了?
在知乎上看到一个有意思的问题,是劝退计算机的。 主要观点: 计算机从业人员众多加班,甚至需要99635岁危机秃头 综上所属,计算机不仅卷,而且还是一个高危职业呀,可别来干了。 关于卷 近两年确实能明显感觉…...
)
ElevenLabs语音合成效果翻倍的秘密(行业未公开的声学参数调优矩阵)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs英文语音合成效果翻倍的核心洞察 关键瓶颈在于语音上下文建模粒度 ElevenLabs 的高质量语音合成并非单纯依赖更大模型参数量,而是通过细粒度的语义-韵律联合编码实现自然度跃升。…...

颠覆性创新:为什么Upkie开源轮式双足机器人正在重新定义机器人开发范式
颠覆性创新:为什么Upkie开源轮式双足机器人正在重新定义机器人开发范式 【免费下载链接】upkie Open-source wheeled biped robots 项目地址: https://gitcode.com/gh_mirrors/up/upkie 在传统机器人设计面临轮式与足式两难选择的今天,一个革命性…...
)
告别内置ADC的烦恼:用ADS1119搞定STM32/DSP的高精度电压采样(附完整代码)
告别内置ADC的烦恼:用ADS1119搞定STM32/DSP的高精度电压采样(附完整代码) 在嵌入式系统开发中,电压采样是基础却至关重要的环节。许多工程师在使用STM32或DSP内置ADC时,常会遇到精度不足、抗干扰能力差、无法测量差分信…...

高效浏览器视频嗅探工具:猫抓扩展完整使用指南
高效浏览器视频嗅探工具:猫抓扩展完整使用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)…...

Nestia:基于TypeScript编译时分析的NestJS端到端类型安全实践
1. 项目概述:当NestJS遇上TypeScript的极致类型安全如果你正在用NestJS开发后端API,并且对TypeScript的类型安全有近乎偏执的追求,那么你很可能已经听说过,或者正在寻找一个能让你“写一次,安全两次”的工具。我说的“…...

可穿戴电子模块化连接方案:5mm微型按扣实现电路板与织物的可插拔连接
1. 项目概述与核心思路在折腾可穿戴电子项目时,最让人头疼的问题之一,就是如何让电路板与衣物既可靠连接,又能方便地拆下来。传统的做法要么是用导电胶带粘(不牢靠、易氧化),要么是直接把线焊死在板子上然后…...

AI驱动的Web可访问性审查:LLM如何成为你的自动化无障碍专家
1. 项目概述:一个为AI智能体而生,却意外照亮了所有人的可访问性审查工具 最近在折腾AI智能体(AI Agent)的开发,一个老问题又浮上水面:怎么确保我造出来的这个“数字员工”,能真正服务好所有人&…...

Apache Burr:用状态机模式构建Python流式应用
1. 项目概述:一个用于构建流式应用的Python框架最近在折腾一些实时数据处理和模型推理的项目,从简单的日志分析到复杂的在线推荐,总感觉现有的工具链要么太重,要么太散。想要一个既能处理流式数据,又能轻松集成机器学习…...

基于LLM的游戏AI智能体:从感知到决策的框架构建与实践
1. 项目概述:一个能“玩”游戏的AI智能体最近在GitHub上看到一个挺有意思的项目,叫ChattyPlay-Agent。光看名字,你可能会觉得这又是一个基于大语言模型的聊天机器人。但点进去仔细研究后,我发现它的定位非常独特:这是一…...

AI驱动全栈开发:Cursor集成模板与高效协作实践
1. 项目概述:当AI代码助手遇上全栈开发最近在GitHub上看到一个挺有意思的项目,叫“Cursor-FullStack-AI-App”。光看名字,你大概能猜到它和Cursor这个AI编程工具,以及全栈应用开发有关。作为一个在前后端都摸爬滚打过多年的开发者…...