2.9 深入GPU硬件架构及运行机制
五、GPU技术要点
1.SMID和SIMT
SIMD(Single Instruction Multiple Data)是单指令多数据,在GPU的ALU(在Core内)单元内,一条指令可以处理多维向量(一般是4D)的数据。比如,有以下shader指令:
float4 c = a + b; // a,b都是float4类型
对于没有SIMD的处理单元,需要4条指令将4个float数值相加,汇编伪代码如下:
ADD c.x, a.x, b.x
ADD c.y, a.y, b.y
ADD c.z, a.z, b.z
ADD c.w, a.w, b.w
但是有了SIMD技术,只需要一条指令即可处理完:
SIMD_ADD c, a, b
for(i=0; i < n ; ++i) c[i] = a[i] + b[i];
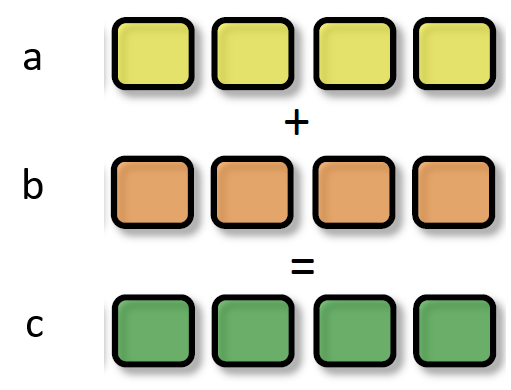
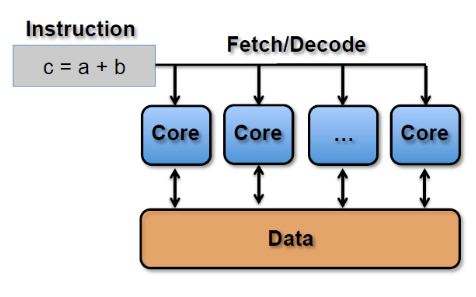
SIMT(Single Instruction Multiple Threads,单指令多线程)是SIMD的升级版,可对GPU中单个SM中的多个Core同时处理一个指令,并且每个Core存取的数据可以是不同的。
SIMT_ADD c,a,b
上述指令会被同时送入在单个SM中被编组的所有Core中,同事执行运算,但a、b、c的值可以不一样:

2.co-issue
co-issue是为了解决SIMD运行单元无法充分利用的问题。例如下图,由于float数量的不同,ALU利用率从100%依次下降为75%、50%、25%。

为了解决着色器在低维向量的利用率低的问题,可以通过合并1D与3D与2D的指令。例如下图,DP3指令用了3D数据,ADD指令只有1D数据,co-issue会自动将他们合并,在同一个ALU只需要一个指令周期即可执行完。

但是对于向量运算(Vector ALU),如果其中一个变量既是操作数又是存储数的情况,无法启用co-issue技术:

3.if-else语句
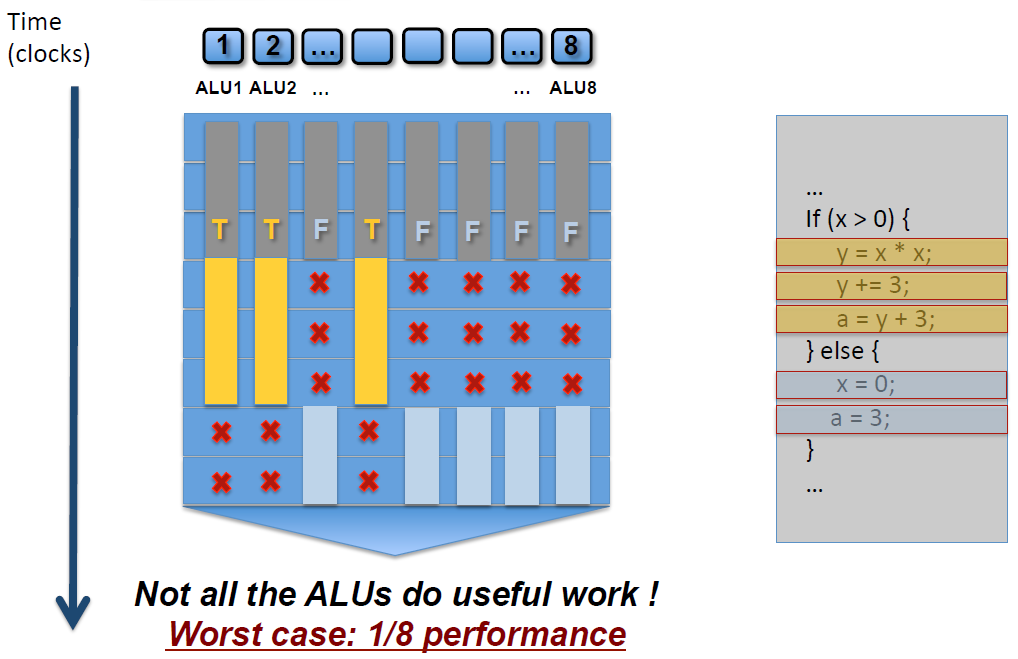
如上图,SM中有8个ALU(Core),由于SIMD的特性,每个ALU的数据都不一样,导致if-else语句在某些ALU中执行的是true分支(黄色),有些ALU执行的是false分支(灰蓝色),这样导致很多ALU的执行周期被浪费掉了(即masked out),拉长了整个执行周期。最坏的情况,同一个SM中只有1/8(8是同一个SM的线程数,不同架构的GPU有所不同)的利用率。
同样,for循环也会导致类似的情况,例如以下shader代码:
void func(int count, int breakNum)
{ for(int i = 0; i < count; ++i) { if (i == breakNum) break; else // do something }
}由于每个ALU的count不一样,加上有break分支,导致最快执行完shader的ALU可能是最慢的N分之一的时间,但由于SIMD的特性,最快的那个ALU依然要等待最慢的ALU执行完毕,才能接下一组指令的活!也就是白白浪费了很多时间周期。
4.Early-Z
早期GPU的渲染管线的深度测试是在像素着色器之后才执行(下图),这样会造成很多本不可见的像素执行了耗性能的像素着色器计算。

后来,为了减少像素着色器的额外消耗,将深度测试提至像素着色器之前(下图),这就是Early-Z技术的由来。

Early-Z技术可以将很多无效的像素提前剔除,避免它们进入耗时严重的像素着色器。Early-Z剔除的最小单位不是1像素,而是像素块(pixel quad,2x2个像素)。
但是,以下情况会导致Early-Z失效:
- 开启Alpha Test:由于Alpha Test需要在像素着色器后面的Alpha Test阶段比较,所以无法在像素着色器之前就决定该像素是否被剔除。
- 开启Alpha Blend:启用了Alpha混合的像素很多需要与frame buffer做混合,无法执行深度测试,也就无法利用Early-Z技术。
- 开启Tex Kill:即在shader代码中有像素摒弃指令(DX的discard,OpenGL的clip)。
- 关闭深度测试。Early-Z是建立在深度测试看开启的条件下,如果关闭了深度测试,也就无法启用Early-Z技术。
- 开启Multi-Sampling:多采样会影响周边像素,而Early-Z阶段无法得知周边像素是否被裁剪,故无法提前剔除。
- 以及其它任何导致需要混合后面颜色的操作。
此外,Early-Z技术会导致一个问题:深度数据冲突(depth data hazard)。

例子要结合上图,假设数值深度值5已经经过Early-Z即将写入Frame Buffer,而深度值10刚好处于Early-Z阶段,读取并对比当前缓存的深度值15,结果就是10通过了Early-Z测试,会覆盖掉比自己小的深度值5,最终frame buffer的深度值是错误的结果。
避免深度数据冲突的方法之一是在写入深度值之前,再次与frame buffer的值进行对比:

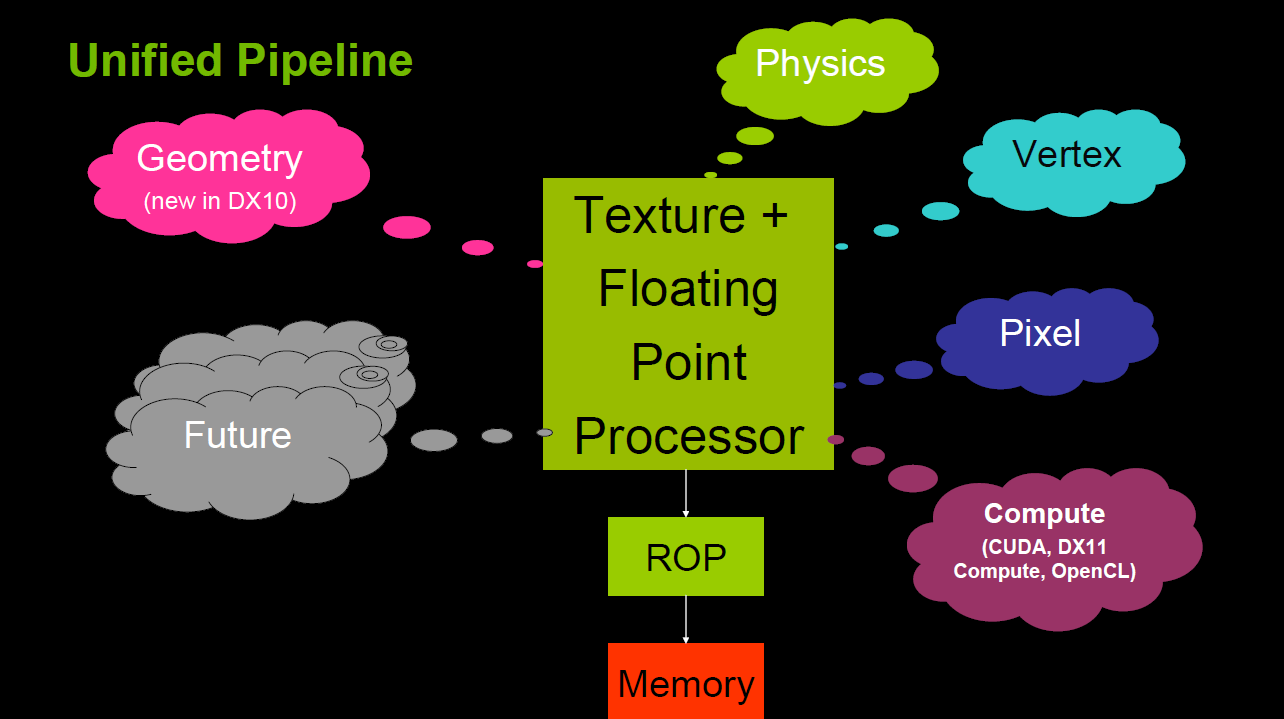
5.统一着色器架构(Unitfied shader Architecture)
在早期的GPU,顶点着色器和像素着色器的硬件结构是独立的,它们各有各的寄存器、运算单元等部件。这样很多时候,会造成顶点着色器与像素着色器之间任务的不平衡。对于顶点数量多的任务,像素着色器空闲状态多;对于像素多的任务,顶点着色器的空闲状态多(下图)。

于是,为了解决VS和PS之间的不平衡,引入了统一着色器架构(Unified shader Architecture)。用了此架构的GPU,VS和PS用的都是相同的Core。也就是,同一个Core既可以是VS又可以是PS。
6.像素块
5.4中提到的:
32个像素线程将被分成一组,或者说8个2x2的像素块,这是在像素着色器上面的最小工作单元,在这个像素线程内,如果没有被三角形覆盖就会被遮掩,SM中的warp调度器会管理像素着色器的任务。
也就是说,在像素着色器中,会将相邻的四个像素作为不可分隔的一组,送入同一个SM内4个不同的Core。
为什么像素着色器处理的最小单元是2x2的像素块?
推测有以下原因:
1、简化和加速像素分派的工作。
2、精简SM的架构,减少硬件单元数量和尺寸。
3、降低功耗,提高效能比。
4、无效像素虽然不会被存储结果,但可辅助有效像素求导函数。
这种设计虽然有其优势,但同时,也会激化过绘制(Over Draw)的情况,损耗额外的性能。比如下图中,白色的三角形只占用了3个像素(绿色),按我们普通的思维,只需要3个Core绘制3次就可以了。
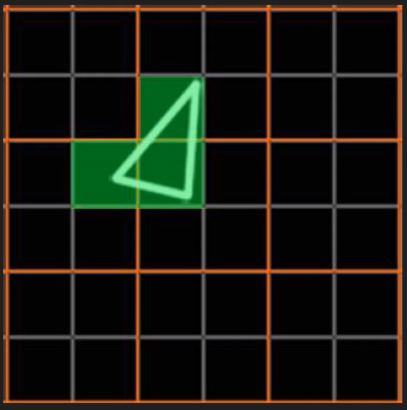
但是,由于上面的3个像素分别占据了不同的像素块(橙色分隔),实际上需要占用12个Core绘制12次(下图)。
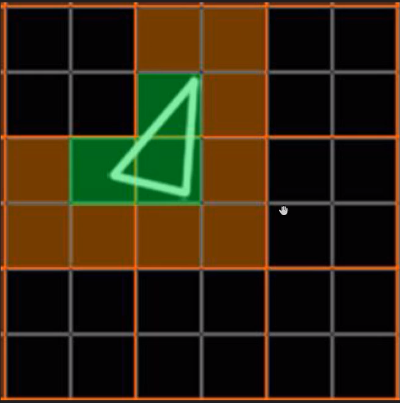
这就会额外消耗300%的硬件性能,导致了更加严重的过绘制情况。
更多详情可以观看虚幻官方的视频教学:实时渲染深入探究。
相关文章:
2.9 深入GPU硬件架构及运行机制
五、GPU技术要点 1.SMID和SIMT SIMD(Single Instruction Multiple Data)是单指令多数据,在GPU的ALU(在Core内)单元内,一条指令可以处理多维向量(一般是4D)的数据。比如,…...

【苍穹外卖 | 项目日记】第四天
前言: 今天状态还可以,既有自己实战独立写接口,又听了课,学习了新的知识 目录 前言: 今日完结任务: 今日收获: 实现店铺状态接口 杂项知识点: 总结: 今日完结任务…...
零代码编程:用ChatGPT批量采集bookroo网页上的英文书目列表
bookroo网页上有很多不错的英文图书书目。比如这个关于儿童花样滑冰的书单: https://bookroo.com/explore/books/topics/ice-skating 怎么批量下载下来呢? 这个网页是动态网页,要爬取下来比较麻烦,可以先查看源代码,…...
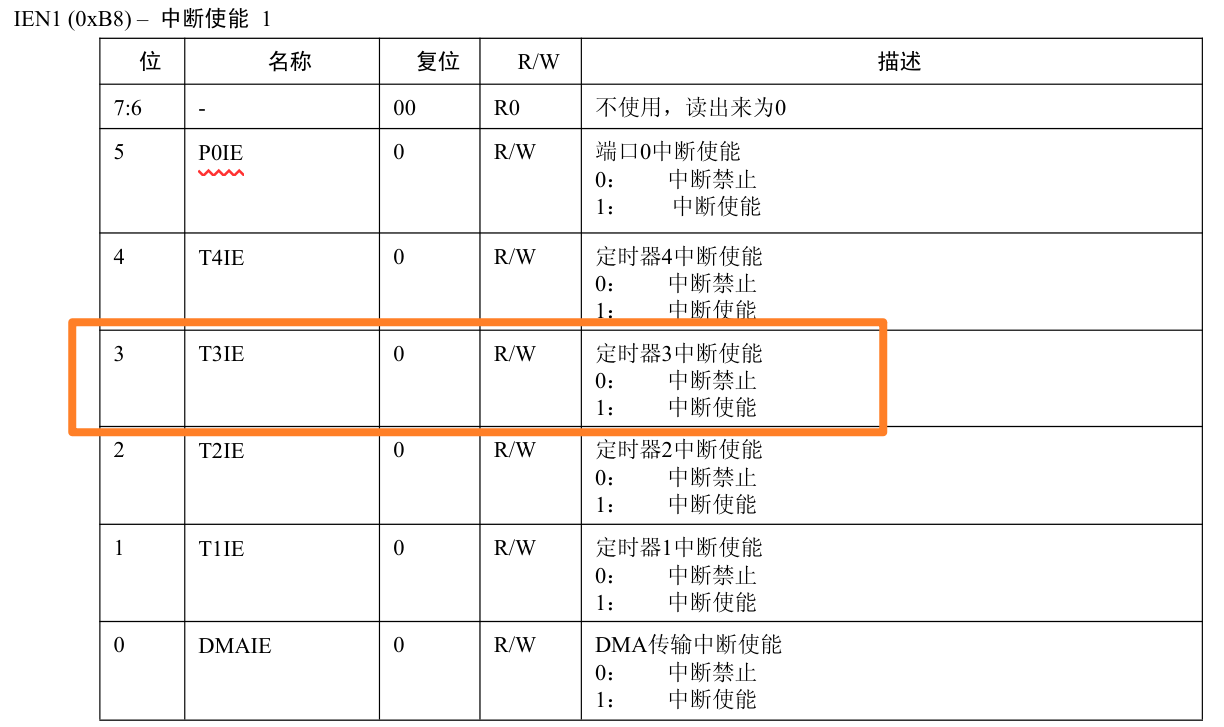
7.定时器
定时器资源 CC2530有四个定时器TIM1~TIM4和休眠定时器 TIM1 定时器1 是一个独立的16 位定时器,支持典型的定时/计数功能,比如输入捕获,输出比较和PWM 功能。定时器有五个独立的捕获/比较通道。每个通道定时器使用一个I/O 引脚。定时器用于…...
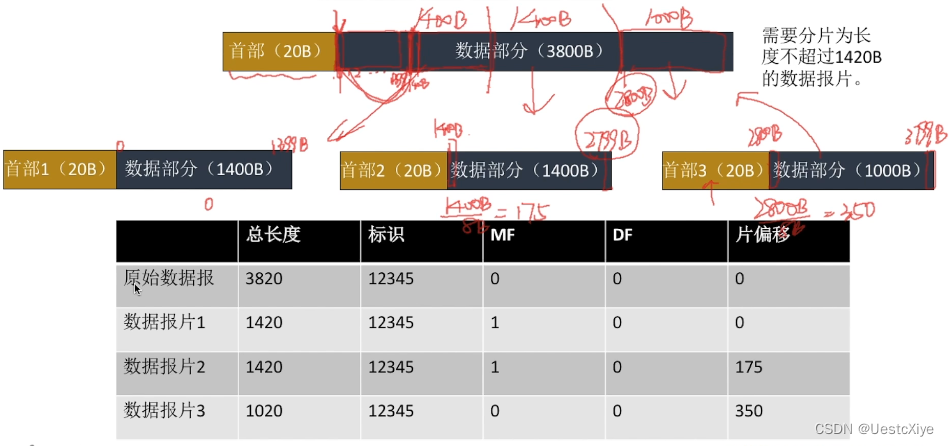
计算机网络 | 网络层
计算机网络 | 网络层 计算机网络 | 网络层功能概述SDN(Software-Defined Networking)路由算法与路由协议IPv4IPv4 分组IPv4 分组的格式IPv4 数据报分片 参考视频:王道计算机考研 计算机网络 参考书:《2022年计算机网络考研复习指…...
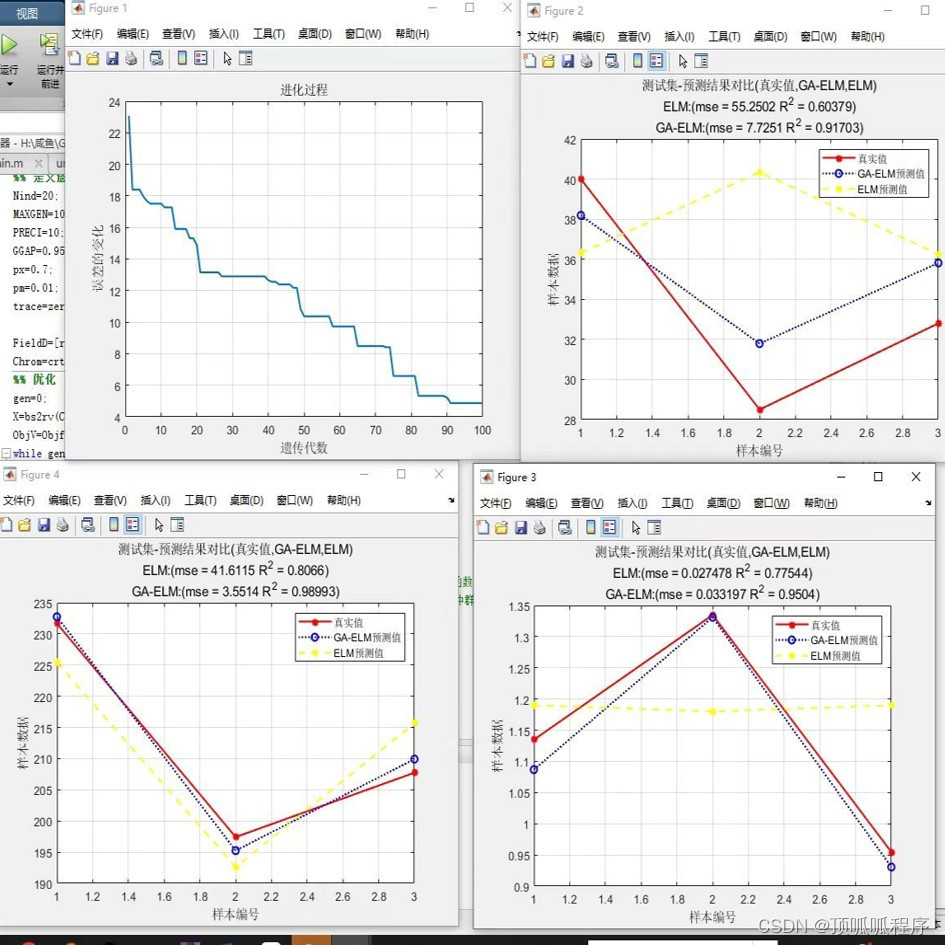
21GA-ELM,遗传算法优化ELM预测,并和优化前后以及真实数值进行对比,确定结果,基于MATLAB平台,程序已经调通,可以直接运行,需要直接拍下。
GA-ELM,遗传算法优化ELM预测,并和优化前后以及真实数值进行对比,确定结果,基于MATLAB平台,程序已经调通,可以直接运行,需要直接拍下。 21matlab时间序列预测极限学习遗传优化算 (xiaohongshu.co…...
)
287_C++_TaskQueue管理任务队列和定时器(头文件.h)
#ifndef TASKQUEUE_H #define TASKQUEUE_H#include <sys/types.h> #include <stdlib.h> #include <pthread.h>...
)
Hadoop+Zookeeper+HA错题总结(一)
题目3: 下列哪项通常是hadoop集群运行时的最主要瓶颈?() [单选题] A、CPU B、网络 C、磁盘 IO D、内存 【参考答案】: C 【您的答案】: D 这道题的答案取决于集群的性能,一般来说运行时的主要瓶颈是网络。但是如果集群的磁盘IO性能较差&am…...
React高级特性之context
例1: createContext // 跨组件通信Context引入createContext import React, { createContext } from react// App传数据给组件C App -- A -- C// 1. 创建Context对象 const { Provider, Consumer } createContext()function SonA () {return (<div>我是…...
【OS】操作系统课程笔记 第五章 并发性——互斥、同步和通信
并发性:并发执行的各个进程之间,既有独立性,又有制约性; 独立性:各进程可独立地向前推进; 制约性:一个进程会受到其他进程的影响,这种影响关系可能有3种形式: 互斥&am…...

RabbitMQ概述原理
RabbitMQ是一种消息队列中间件,其主要作用是在应用程序之间传输数据。它基于AMQP(高级消息队列协议)实现,可以用于不同语言和不同操作系统之间的通信。 RabbitMQ的工作原理是生产者将消息发送到队列中,消费者从队列中接…...

8.Covector Transformation Rules
上一节已知,任意的协向量都可以写成对偶基向量的线性组合,以及如何通过计算基向量穿过的协向量线来获得协向量分量,且看到 协向量分量 以 与向量分量 相反的方式进行变换。 现要在数学上确认协向量变换规则是什么。 第一件事:…...

RustDay04------Exercise[21-30]
21.使用()对变量进行解包 // primitive_types5.rs // Destructure the cat tuple so that the println will work. // Execute rustlings hint primitive_types5 or use the hint watch subcommand for a hint.fn main() {let cat ("Furry McFurson", 3.5);// 这里…...

OpenAI科学家谈GPT-4的潜力与挑战
OpenAI Research Scientist Hyung Won Chung 在首尔国立大学发表的一场演讲。 模型足够大,某些能力才会显现,GPT-4 即将超越拐点并在其能力上实现显着跳跃。GPT-3 和 GPT-4 之间的能力仍然存在显着差距,并且尝试弥合与当前模型的差距可能是无…...
Java电子病历编辑器项目源码 采用B/S(Browser/Server)架构
电子病历(EMR,Electronic Medical Record)是用电子技术保存、管理、传输和重现的数字化的病人的医疗记录,取代手写纸张病历,将医务人员在医疗活动过程中,使用医疗机构管理系统生成的文字、符号、图表、图形、数据、影像等数字化内…...

使用 AWS DataSync 进行跨区域 AWS EFS 数据传输
如何跨区域EFS到EFS数据传输 部署 DataSync 代理 在可以访问源 EFS 和目标 EFS 的源区域中部署代理。转至AWS 代理 AMI 列表并按 AWS 区域选择您的 AMI。对于 us-west-1,单击 us-west-1 前面的启动实例。 启动实例 2. 选择您的实例类型。AWS 建议使用以下实例类型之…...
-19)
设计模式~解释器模式(Interpreter)-19
解释器模式(Interpreter Pattern)提供了评估语言的语法或表达式的方式,它属于行为型模式。这种模式实现了一个表达式接口,该接口解释一个特定的上下文。这种模式被用在 SQL 解析、符号处理引擎等。 【俺有一个《泡MM真经》&#x…...

对象混入的实现方式
对象混入(Object mixins)是一种在面向对象编程中用于组合和重用代码的技术。它允许你将一个对象的属性和方法混合(或合并)到另一个对象中,从而创建一个具有多个来源的对象,这些来源可以是不同的类、原型或其…...
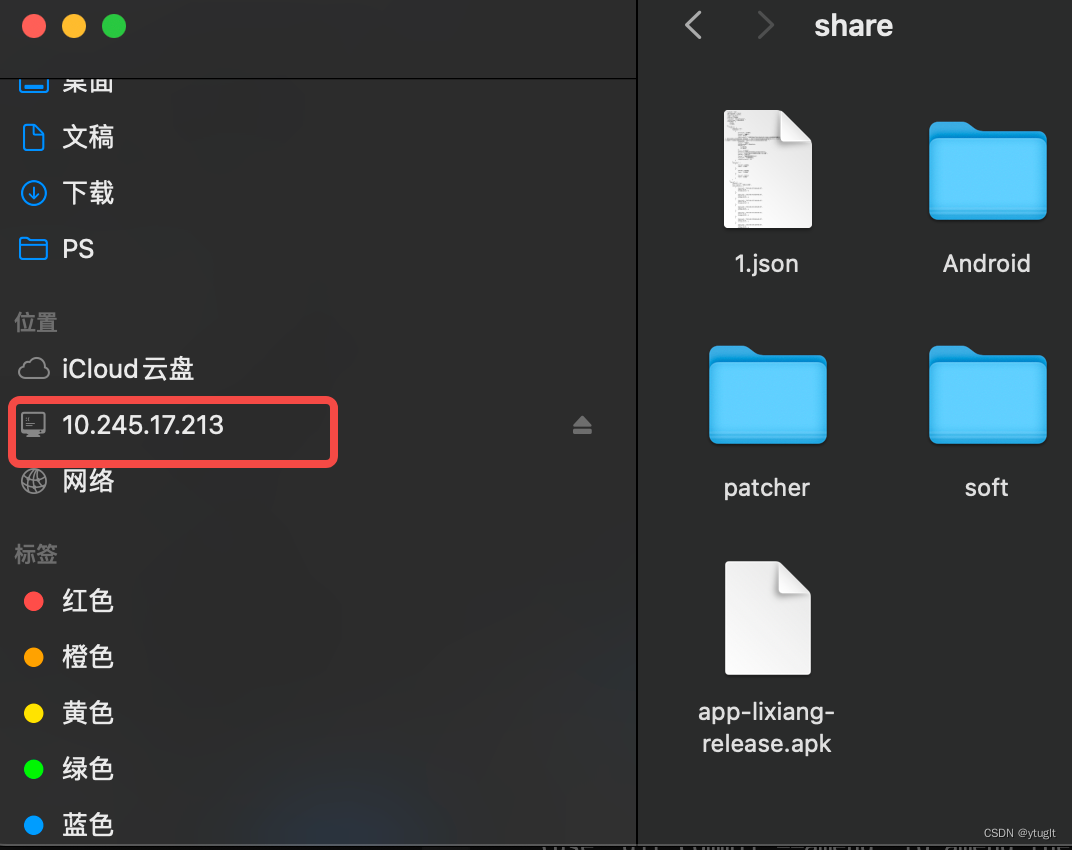
Mac 远程 Ubuntu
1. Iterm2 添加ssh 参考:https://www.javatang.com/archives/2021/11/29/13063392.html 2. Finder 添加远程文件管理 2.1 ubuntu 配置 安装samba sudo apt-get install samba配置 [share]path /home/USER_NAME/shared_directoryavailable yesbrowseable ye…...

黑豹程序员-h5前端录音、播放
H5支持页面中调用录音机进行录音 H5加入录音组件,录音后可以进行播放,并形成录音文件,其采样率固化48000,传言是google浏览器的BUG,它无法改动采样率。 大BUG,目前主流的支持16000hz的采样率。 录音组件 …...
)
保姆级教程:在RK3588开发板上编译并加载Xilinx XDMA PCIe驱动(含完整Makefile解析)
RK3588与FPGA的PCIe通信实战:XDMA驱动编译与深度优化指南 当RK3588遇上FPGA,PCIe通信便成为两者之间高速数据交互的核心桥梁。作为一款广泛应用于边缘计算和嵌入式AI场景的ARM处理器,RK3588的PCIe 3.0 x4接口能够提供接近4GB/s的理论带宽&am…...
)
从移动平均到IIR滤波:用Matlab filter函数实现数据降噪的完整指南(附对比实验)
从移动平均到IIR滤波:用Matlab filter函数实现数据降噪的完整指南(附对比实验) 在数据分析与信号处理领域,噪声污染是影响结果准确性的常见挑战。无论是来自传感器的物理干扰,还是数据传输过程中的随机波动,…...

Phi-4-mini-reasoning开源镜像实操:无需conda/pip,开箱即用推理环境
Phi-4-mini-reasoning开源镜像实操:无需conda/pip,开箱即用推理环境 1. 模型简介 Phi-4-mini-reasoning 是一个基于合成数据构建的轻量级开源模型,专注于高质量、密集推理的数据处理能力。作为Phi-4模型家族的一员,它经过专门微…...

Wan2.2-I2V-A14B私有部署实战教程:RTX 4090D一键生成1080P视频
Wan2.2-I2V-A14B私有部署实战教程:RTX 4090D一键生成1080P视频 1. 开篇:为什么选择私有部署 当你需要频繁生成高质量视频内容时,公有云服务往往面临三个痛点:生成排队时间长、隐私数据风险、调用成本高。Wan2.2-I2V-A14B私有部署…...

uniapp学习9,同时兼容h5和微信小程序的百度地图组件
H5端微信小程序端:manifest.json配置 "mp-weixin" : {"appid" : "你的微信小程序appid","setting" : {"urlCheck" : false},"usingComponents" : true,"permission": {"scope.userLoca…...

【05-log-+-diff:看懂你改了什么、历史是什么】
第五篇:log diff:看懂你改了什么、历史是什么会提交只是第一步,会"读"历史才是真的用上了 Git。这篇教你把 log 和 diff 玩出花来。git log:查看提交历史 git log默认输出太详细,通常用这些参数来精简&…...

NaViL-9B多场景应用:医疗报告图解、工业缺陷识别、文档智能审阅
NaViL-9B多场景应用:医疗报告图解、工业缺陷识别、文档智能审阅 1. 平台简介 NaViL-9B是上海人工智能实验室研发的原生多模态大语言模型,具备强大的文本理解和图像分析能力。不同于传统单一模态模型,NaViL-9B能够同时处理纯文本问答和图片理…...

网站关键词排名变化规律是什么_网站关键词排名优化对SEO的重要性是什么
网站关键词排名变化规律是什么_网站关键词排名优化对SEO的重要性是什么 在当今数字化时代,网站的SEO优化是一个至关重要的领域。其中,关键词排名的变化规律和关键词排名优化对SEO的重要性尤为关键。本文将详细探讨这两方面的内容,帮助你更好…...

OpenClaw调试进阶:百川2-13B-4bits量化模型响应日志分析
OpenClaw调试进阶:百川2-13B-4bits量化模型响应日志分析 1. 为什么需要关注模型响应日志 上周我在用OpenClaw对接百川2-13B-4bits量化模型时,遇到了一个奇怪的现象:自动化任务执行到一半突然中断,控制台只显示"模型响应异常…...

ROS2开发环境搭建避坑指南:Win11 + WSL2 + Ubuntu 22.04 从安装到测试的完整记录
ROS2开发环境搭建实战:Win11与WSL2深度适配指南 环境准备与系统调优 在Windows 11上搭建ROS2开发环境,选择WSL2作为Linux子系统是最佳实践方案。不同于传统虚拟机方案,WSL2提供了接近原生Linux的性能表现,同时完美集成Windows桌…...