用PolarDB|PostgreSQL提升通用ai机器人在专业领域的精准度
目录
背景
基本步骤讲解
Demo 演示
思考
如果不是用openai?
开源社区能干点啥?
ai应用
收录专栏:PolarDB for PostgreSQL,后续将会发布PolarDB for PostgreSQL教程,大家感兴趣的话可以点个订阅呀!
简介: chatgpt这类通用机器人在专业领域的回答可能不是那么精准, 原因有可能是通用机器人在专业领域的语料库学习有限, 或者是没有经过专业领域的正反馈训练. 为了提升通用机器人在专业领域的回答精准度, 可以输入更多专业领域相似内容作为prompt来提升通用ai机器人在专业领域的精准度. PolarDB | PostgreSQL 开源数据库在与openai结合的过程中起到的核心作用是: 基于向量插件的向量类型、向量索引、向量相似搜索操作符, 加速相似内容的搜索. 通过“问题和正确答案”作为参考输入, 修正openapi在专业领域的回答精准度.
背景
chatgpt这类通用机器人在专业领域的回答可能不是那么精准, 原因有可能是通用机器人在专业领域的语料库学习有限, 或者是没有经过专业领域的正反馈训练.
为了提升通用机器人在专业领域的回答精准度, 可以输入更多专业领域相似内容作为prompt来提升通用ai机器人在专业领域的精准度.
- 参考openai文档. How do I create a good prompt? | OpenAI Help Center
PolarDB | PostgreSQL 开源数据库在与openai结合的过程中起到的核心作用是什么?
基于向量插件的向量类型、向量索引、向量相似搜索操作符, 加速相似内容的搜索. 通过“问题和正确答案”作为参考输入, 修正openapi在专业领域的回答精准度.
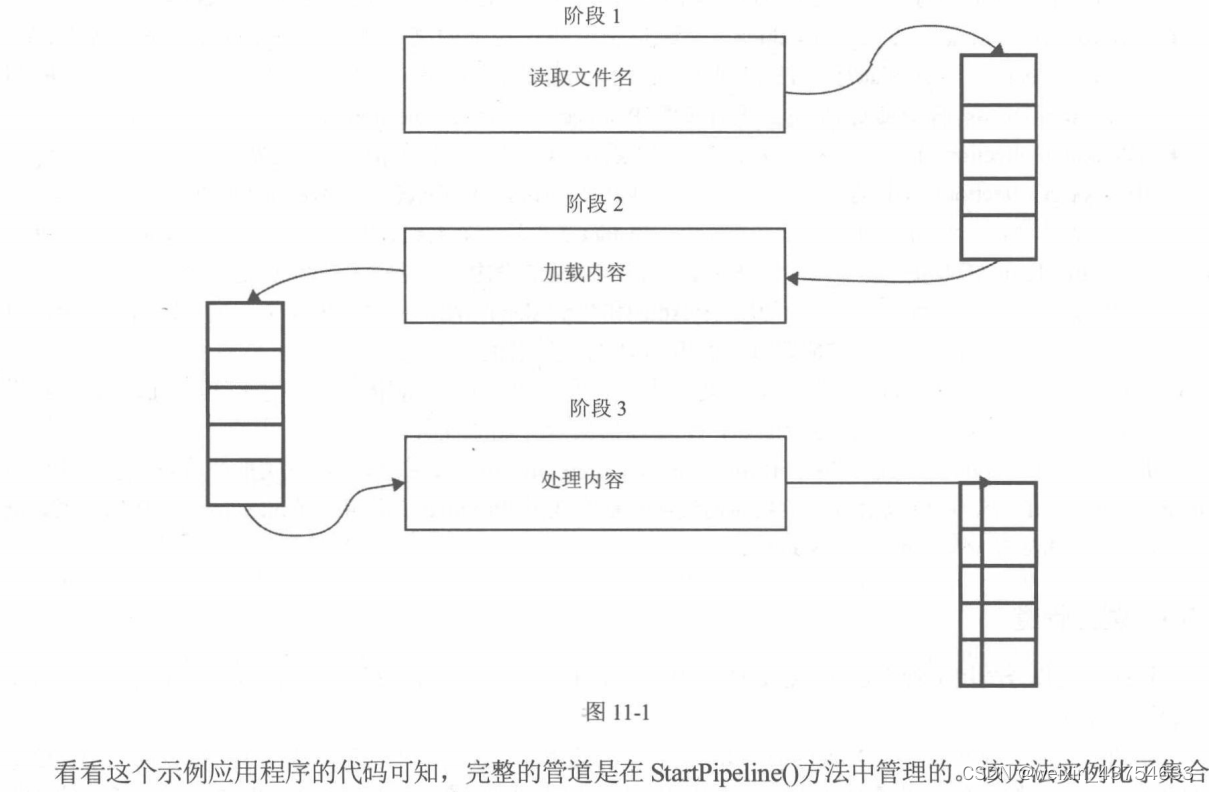
基本步骤讲解
1、准备:
- PolarDB | PostgreSQL 开源数据库
- plpython3u 函数插件 以及 python openai 包
- 向量插件 (pgvector, hnsw, embedding等插件都可以)
- openai 账号
- 参考文档库素材
2、建设专业领域的“参考文档库”, 问题+答案的格式. 这一步可能是人肉工作, 比如从文档提炼成“问题+答案”的格式. 例如:
- 问题: 如何使用PolarDB的eqp功能实现多机并行计算?
- 答案: 以htap模式构建PolarDB集群, 配置xxx相关并行参数, explain sql 观察执行计划, 执行sql; (实际情况你可以写得更详细一些.)
3、创建向量插件
4、创建openai的辅助参考表, 包括“问题文本、问题向量、答案文本”几个字段. 你可以理解为“正确答案”(或者prompt).
5、将"参考文档库"导入数据库, 并调用openai得到辅助参考表“问题文本字段对应的vector值, 1536维度的向量”写入到辅助参考表.
6、创建辅助参考表vector字段的向量索引.
7、在用户向openai问非常专业的问题时,
- 将“用户输入的问题1”抛给openai得到“向量值1”,
-
- 这一步的tiktoken过程介绍:
- 《PostgreSQL 或PolarDB 使用插件pg_tiktoken - 使用 OpenAI tiktoken库文本向量化(tokenization) - 使用分词算法BPE - NLP 自然语言处理》
- 使用“向量值1”搜索辅助参考表, 找到最相似的“向量2”(这一步就是向量检索, 可以用到向量索引), 取出与之相对应的“问题和答案”, (这一步可以设置阈值, 如果没有特别相似的就不要了.)
- 将“用户输入的问题1 + 最相似问题和答案(如果有)”输入, 向openai提问, 从而修正直接向openai问“用户输入的问题1”的结果. 提升openai专业领域回答的准确度.
Demo 演示
1、通过云起实验启动数据库, 这个实验室是永久免费的.
- 快速体验PolarDB开源数据库 - 云起实验室-在线实验-上云实践-阿里云开发者社区-阿里云官方实验平台-阿里云
参考:
- https://github.com/digoal/blog/blob/master/202307/20230710_03.md
创建并启动容器
docker run -d -it --cap-add=SYS_PTRACE --cap-add SYS_ADMIN --privileged=true --name pg registry.cn-hangzhou.aliyuncs.com/digoal/opensource_database:pg14_with_exts进入容器
docker exec -ti pg bash连接数据库
psql这个容器支持如下相似搜索插件, 接下来的例子使用pgvector插件, 如果向量文本特别多, 建议使用hnsw或pg_embedding插件.
- similarity, 近似算法, 类型+索引
- imgsmlr, 图像搜索, 类型+索引
- pgvector, 向量搜索, 类型+索引(ivfflat)
- hnsw, 向量搜索, 类型+索引(hnsw)
- pg_embedding, 向量搜索, 类型+索引(hnsw)
2、创建插件以及 python openai 包
# apt install -y python3-pip
# pip3 install openai root@689ed216de12:/tmp# psql
psql (14.8 (Debian 14.8-1.pgdg110+1))
Type "help" for help. postgres=# create extension plpython3u ;
CREATE EXTENSION
postgres=# create extension vector ;
CREATE EXTENSION3、准备"参考文档库", 你可以理解为“正确答案”.
4、创建openai的辅助参考表, 包括“问题文本、问题向量、答案文本”几个字段.
create table tbl_faq ( id serial8 primary key, f text, -- 问题 q text, -- 标准答案 v vector(1536) -- faq (textcat('title: '||f, ' --- '||q)) 文本向量
);5、将"参考文档库"导入数据库, 并调用openai得到辅助参考表“问题文本字段对应的vector值, 1536维度的向量”写入到辅助参考表.
直接update全表的话容易造成表膨胀, 建议从外面的文件导入的过程中调用openai实时计算vector值并导入.
配置环境变量(启动数据库时的环境变量OPENAI_API_KEY. 用于存储openai key, 当然你也可以使用其他方式获取key, 改写下列function即可.)
create or replace function get_v (faq text) returns vector as $$ import openai import os text = faq openai.api_key = os.getenv("OPENAI_API_KEY") response = openai.Embedding.create( model = "text-embedding-ada-002", input = text.replace("\n", " ") ) embedding = response['data'][0]['embedding'] return embedding
$$ language plpython3u;insert into tbl_faq(f,q,v) select f,q,get_v(textcat('title: '||f, ' --- '||q)) from 外部表;6、创建辅助参考表vector字段的向量索引.
create index on tbl_faq using ivfflat (v vector_cosine_ops);
analyze tbl_faq;7、在用户向openai问非常专业的问题时:
将“用户输入的问题1”抛给openai得到“向量值1”,
select get_v('用户输入的问题1');使用“向量值1”搜索辅助参考表, 找到最相似的“向量2”(这一步就是向量检索, 可以用到向量索引), 取出与之相对应的“问题和答案”, (这一步可以设置阈值, 如果没有特别相似的就不要了.)
create or replace function get_faq( v vector(1536), -- 用户抛出问题向量 th float, -- 相似度阈值 cnt int -- 返回多少条
)
returns table ( id int8, -- 辅助表ID faq text, -- 辅助表问题+答案 similarity float -- 相似度
)
as $$ select tbl_faq.id, textcat('title: '||tbl_faq.f, ' --- '||tbl_faq.q) as faq, 1 - (tbl_faq.v <=> v) as similarity from tbl_faq where 1 - (tbl_faq.v <=> v) > th order by similarity desc limit cnt;
$$ language sql strict stable;select t.id, t.faq, t.similarity
from get_faq( (select get_v('用户输入的问题1')), 0.8, -- 相似度阈值 1 -- 返回最相似的1条
) as t;将“用户输入的问题1 + 最相似问题和答案(如果有)”输入, 向openai提问, 从而修正直接向openai问“用户输入的问题1”的结果. 提升openai专业领域回答的准确度.
create or replace function ask_openai( user_input text, -- 用户输入问题 faq text -- get_faq()得到的参考问题和答案
)
returns text as
$$ import openai import os openai.api_key = os.getenv("OPENAI_API_KEY") search_string = user_input docs_text = faq messages = [{"role": "system", "content": "You concisely answer questions based on text provided to you."}] prompt = """Answer the user's prompt or question: {search_string} by summarising the following text: {docs_text} Keep your answer direct and concise. Provide code snippets where applicable. The question is about a Greenplum/PostgreSQL/PolarDB database. You can enrich the answer with other Greenplum or PostgreSQ-relevant details if applicable.""".format(search_string=search_string, docs_text=docs_text) messages.append({"role": "user", "content": prompt}) response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages) return response.choices[0]["message"]["content"]
$$ language plpython3u;整合成一个函数:
(用户输入, openai返回基于辅助参考表修正后的答案.)
create or replace function good_ai_assistant( user_input text -- 只需要用户输入
)
returns table ( content text
)
language sql stable
as $$ select ask_openai(user_input, (select t.faq from get_faq( (select get_v('用户输入的问题1')), 0.8, 1 ) as t) );
$$;select content from good_ai_assistant('用户输入的问题');思考
如果不是用openai?
由于openai的访问受限, 换一个基于开源自建的大模型或者使用国内大厂的大模型, 也可以使用同样的方法提升其他大模型在专业领域的回答问题精准度.
参考对应模型的api进行相应调整即可.
开源社区能干点啥?
开源社区的优势
- 人多, 每天都有问问题的, 回答问题的
- 问题和答案多, 但是需要提炼
利用大家的力量干什么?
- 一起提炼卡片知识点
如何奖励?
- 钱.
- 从哪里来? 大会(赞助)|流量(广告)|专家(服务)|内容(内容付费) ...
- 荣誉.
1、通过社区提炼卡片式知识点
2、卡片知识点管理方式: github | gitee
3、卡片知识点共享方式: github | gitee - csv - oss - duckdb_fdw - PostgreSQL | PolarDB
4、训练开源领域专业机器人(也许github可以直接对接openai, 将github和openai打通. github+ai, 可以想象=知识库+ai, 代码+ai).
ai应用
- gitee+ai
- 语雀知识库+ai
- 帮助文档+ai
- 钉钉聊天工具+ai
- 图片,音频搜索+ai
- ...
相关文章:

用PolarDB|PostgreSQL提升通用ai机器人在专业领域的精准度
目录 背景 基本步骤讲解 Demo 演示 思考 如果不是用openai? 开源社区能干点啥? ai应用 收录专栏:PolarDB for PostgreSQL,后续将会发布PolarDB for PostgreSQL教程,大家感兴趣的话可以点个订阅呀! 简介: chat…...
idea中maven plugin提示not found
在终端中输入: mvn dependency:resolve 然后 解决了部分问题 Plugin org.apache.maven.plugins:maven-jar-plugin:3.1.0 not found 改为3.3.0了 Plugin maven-source-plugin:3.3.0 not found 改为 2.4 了 版本下降了 感觉后继有坑 待观察...
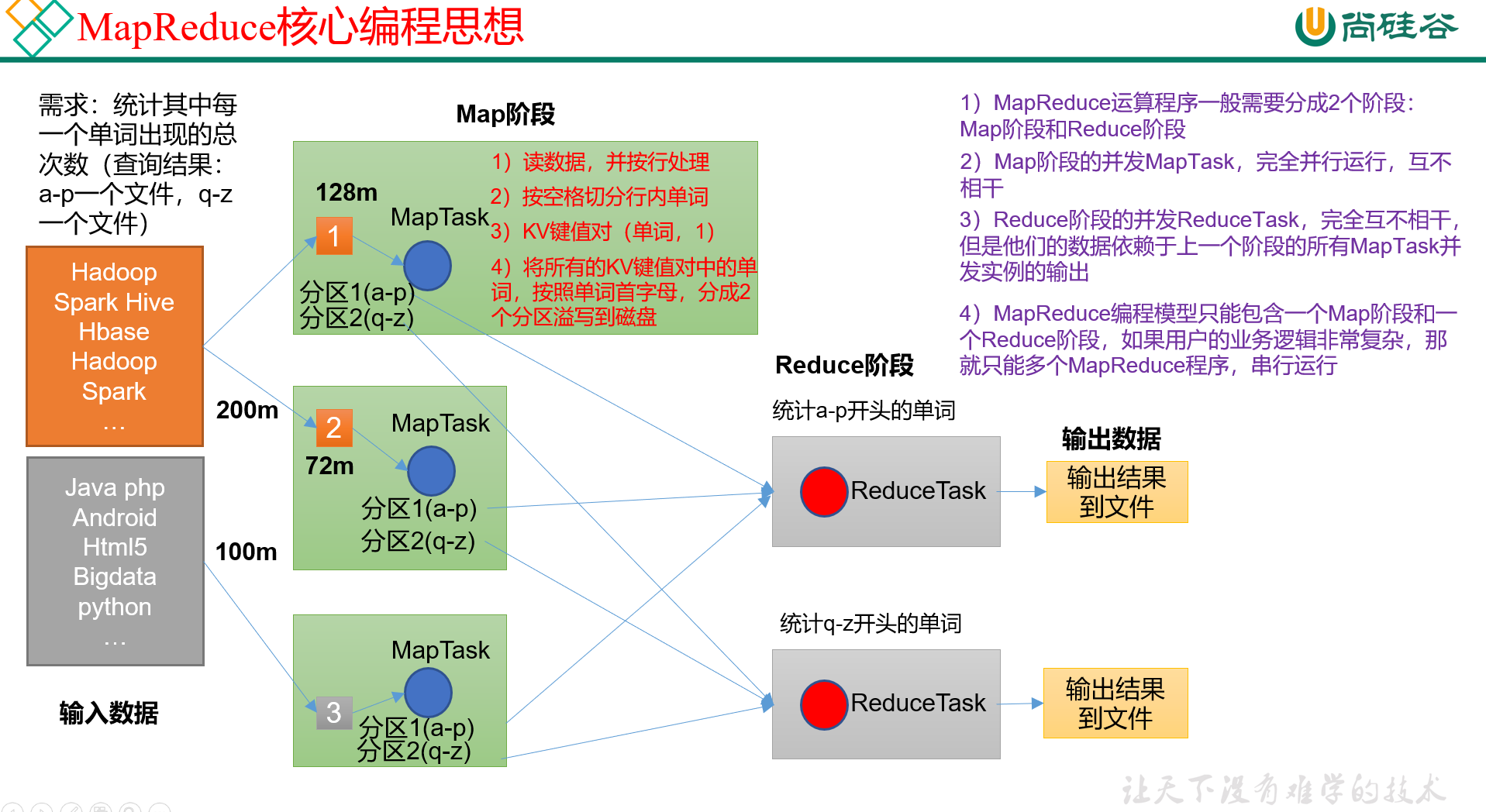
Hadoop3教程(七):MapReduce概述
文章目录 (68) MR的概述&优缺点(69)MR的核心思想MapReduce进程 (70)官方WC源码&序列化类型(71)MR的编程规范MapperReducerDriver (72)WordCount案例需…...

【Doris实战】Apache-doris-2.0.2部署帮助手册
Apache-doris-2.0.2部署帮助手册 校验时间:2023年10月11日 文章目录 Apache-doris-2.0.2部署帮助手册安装前准备安装包安装要求Linux 操作系统版本需求软件需求句柄需求关闭 Swap网络需求 部署规划用户规划目录规划免密需求 安装步骤配置JDK配置Doris文件 启动与停止…...

如何处理接口调用的频率限制
背景 接口提供方有调用频率限制的场景下,如何合理设计接口请求? 方案 采用Redis队列,利用 lpush 和 rpop 命令来实现 首先,将订单依次lpush写入Redis队列。定时任务通过 rpop 获取队列订单进行接口调用。 额外说明: 若想查看…...

Ubuntu 22.04上安装Anaconda,及 conda 的基础使用
1. 安装软件依赖包: apt install libgl1-mesa-glx libegl1-mesa libxrandr2 libxrandr2 libxss1 libxcursor1 libxcomposite1 libasound2 libxi6 libxtst6 2. 下载Anaconda安装包 使用 wget下载您从Anaconda网站复制的链接。您将把它输出到一个名为anaconda.sh的文…...
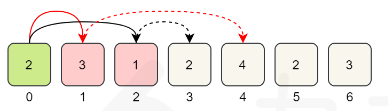
算法练习13——跳跃游戏II
LeetCode 45 跳跃游戏 II 给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处: 0 < j < nums[i] i j < n 返回…...

算法|每日一题|只出现一次的数字|位运算
136.只出现一次的数字 力扣每日一题:136.只出现一次的数字 之前整理过本题及其扩展,详细说明了思路和做法,链接如下: 只出现一次的数字I,II,III 给你一个 非空 整数数组 nums ,除了某个元素只出…...
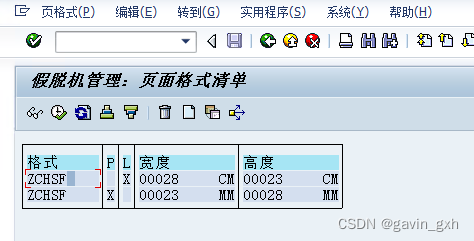
Smartforms 打印出现的问题
上半年ECC做了升级 程序代码从ECC迁移到S4 有用户反馈 打印不能用了 经过调试发现在打印程序中 竟然返回2,但是 smartforms ZRPT_CO_YFLL_DY又是存在的 。 然后去激活 并与 ECC对比发现问题 S4的页大小竟然这么小 找到对应的页格式 对比ECC和S4 果然是这个…...
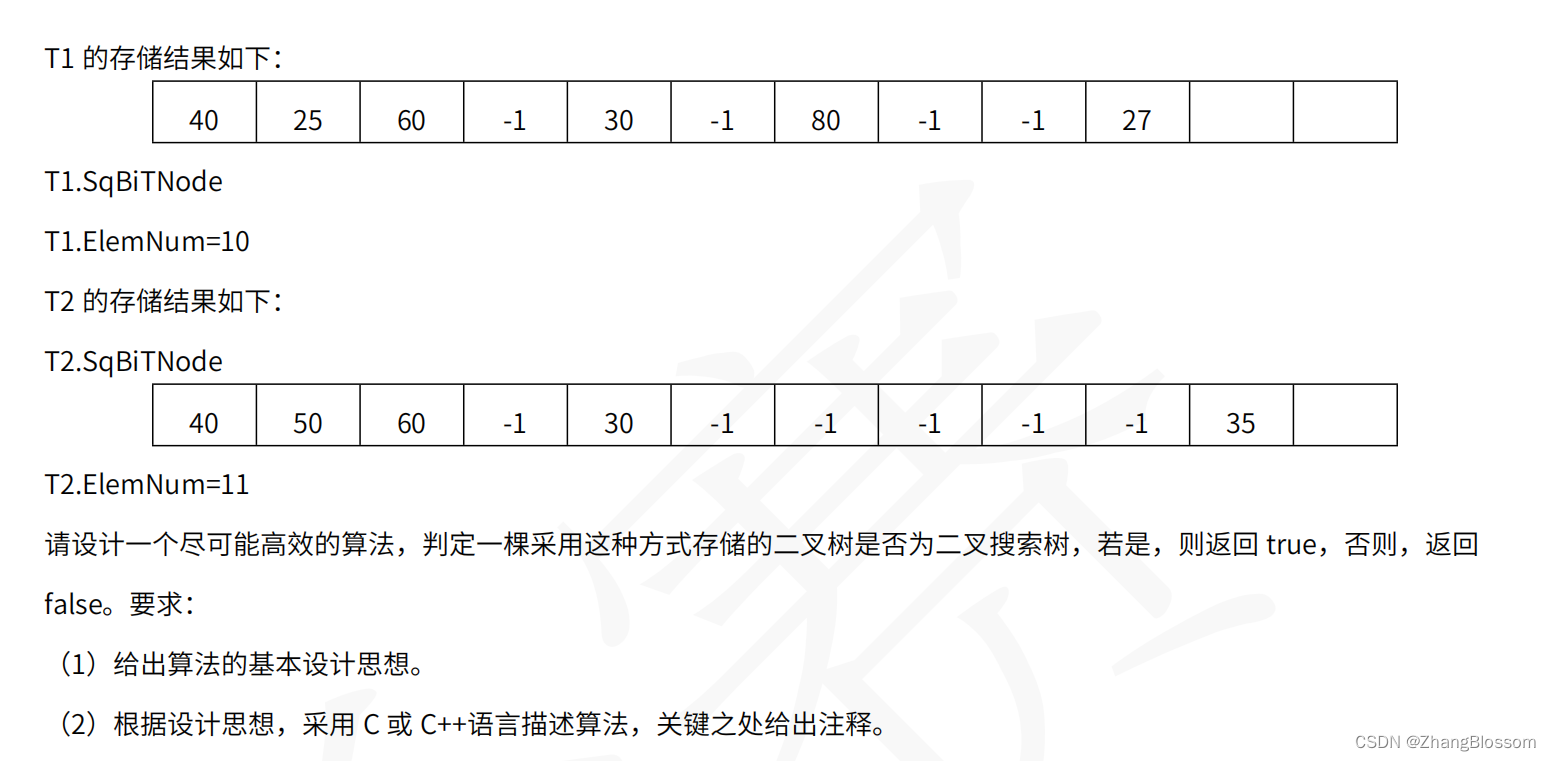
【考研408真题】2022年408数据结构41题---判断当前顺序存储结构树是否是二叉搜索树
文章目录 思路408考研各数据结构C/C代码(Continually updating) 思路 很明显,这是一个顺序存储结构的树的构成方法。其中树的根节点位置从索引0开始,对于该结构,存在有:如果当前根节点的下标为n,…...
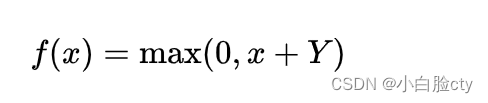
深度学习DAY3:激活函数
激活函数映射——引入非线性性质 h (Σ(W * X)b) yσ(h) 将h的值通过激活函数σ映射到一个特定的输出范围内的一个值,通常是[0, 1]或[-1, 1] 1 Sigmoid激活函数 逻辑回归LR模型的激活函数 Sigmoid函数࿰…...
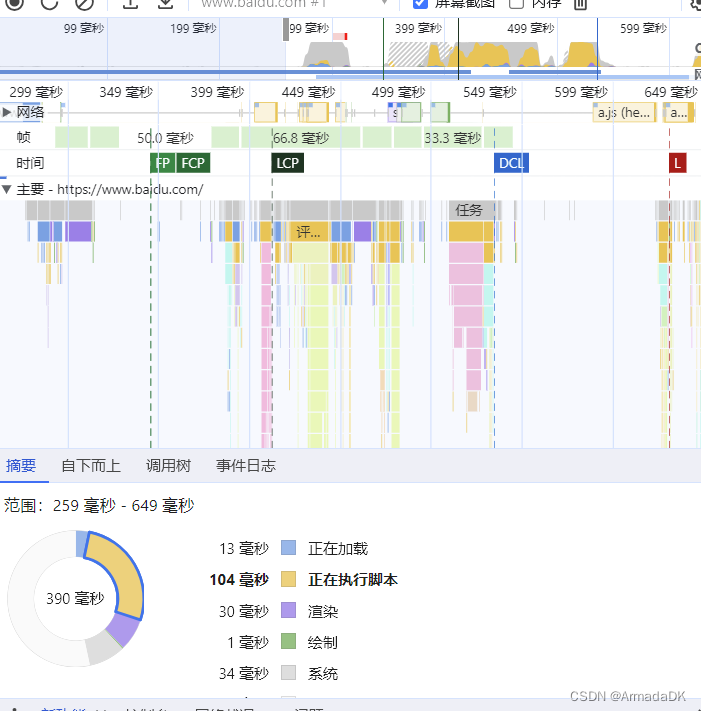
puppeteer
目录 介绍启动方法功能一、爬虫优势如何实现爬虫小demo 功能二、执行脚本百度搜索脚本demo 功能三、获取cookie(这个只能是模拟浏览器当前进入网页的cookie不是平时用的下载的的浏览器的cookie)功能四、监控网页,进行性能分析 介绍 puppetee…...
执行异步HTTP(Ajax)请求的方法($.get、$.post、$getJSON、$ajax))
javascript二维数组(21)执行异步HTTP(Ajax)请求的方法($.get、$.post、$getJSON、$ajax)
执行异步HTTP(Ajax)请求的方法 . g e t 、 .get、 .get、.post、 g e t J S O N 、 getJSON、 getJSON、ajax都是jQuery提供的用于执行异步HTTP(Ajax)请求的方法。每个方法都有其特定的用途和区别。 . g e t :这个方法…...
)
TypeScript React(下)
目录 TypeScript & React TS开发环境的搭建 tsconfig.json webpack.config.js babel.config.js .eslintrc.js TypeScript & React TS开发环境的搭建 软件版本:TypeScript:3.9.5;React:16.13.1 Node:8.17.0环境搭建:正确搭建一…...

『Linux小程序』进度条
文章目录 缓冲区问题回车与换行的区别进度条小程序 缓冲区问题 假设有一段代码为: #include<iostream> #include<unistd.h> int main() …...
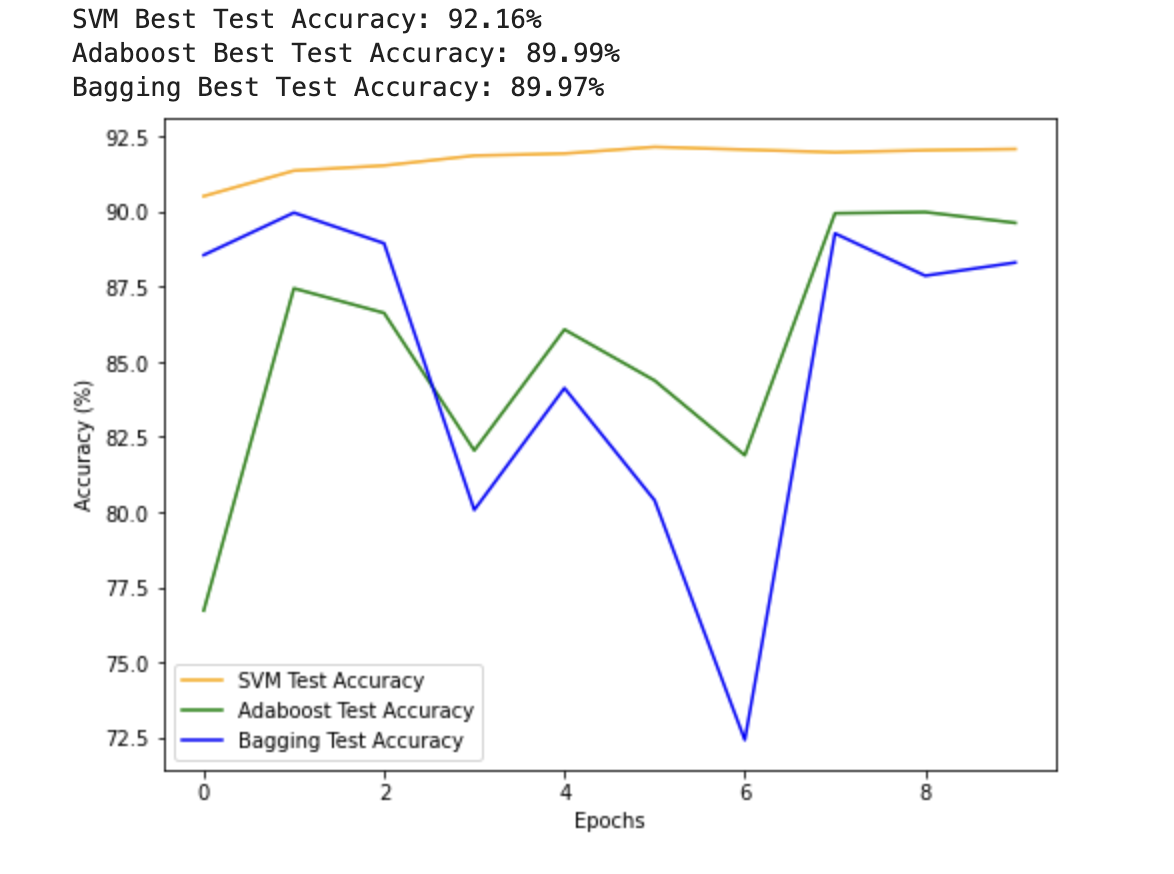
【手写数字识别】GPU训练版本
SVM Adaboost Bagging 完整代码 I import torch import torch.nn.functional as F from torch.utils.data import DataLoader, TensorDataset from torchvision import transforms, datasets import matplotlib.pyplot as plt# 超参数 batch_size 64 num_epochs 10# 数据…...
c#-特殊的集合
位数组 可观察的集合 private ObservableCollection<string> strList new ObservableCollection<string>();// Start is called before the first frame updatevoid Start(){strList.CollectionChanged Change;strList.Add("ssss");strList.Add("…...

Android 使用 eChart 设置标线
echart使用标线 Android部分: import android.webkit.WebView; import com.jianqu.plasmasterilizer.R; import com.jianqu.plasmasterilizer.utils.DisplayUtils; import com.jianqu.plasmasterilizer.utils.TimerUtil; import java.util.ArrayList; import java.…...

红队专题-Cobalt strike 4.x - Beacon重构
红队专题 招募六边形战士队员重构后 Beacon 适配的功能windows平台linux和mac平台C2profile 重构思路跨平台功能免杀代码部分sysinfo包packet包config.go命令的执行shell、run、executepowershell powerpick命令powershell-importexecute-assembly 堆内存加密字符集 招募六边形…...

一文掌握 Go 文件的写入操作
前言 通过案例展示如何读取文件里的内容。本文接着上篇文章的内容,介绍文件的写入操作。 File.Write、File.WriteString、File.WriteAt File.Write(b []byte) (n int, err error) 直接操作磁盘往文件里写入数据,写入单位为字节。 b 参数:…...

3步构建智能文献管理系统:Zotero GPT插件从配置到精通指南
3步构建智能文献管理系统:Zotero GPT插件从配置到精通指南 【免费下载链接】zotero-gpt GPT Meet Zotero. 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-gpt 在信息爆炸的学术环境中,研究人员平均每天需要处理超过20篇文献,传…...
手把手教你用Transceiver Wizard搞定UltraScale FPGA的GTY时钟网络规划
手把手教你用Transceiver Wizard搞定UltraScale FPGA的GTY时钟网络规划 在FPGA高速收发器设计中,时钟网络的合理规划往往是决定系统稳定性的关键因素。对于刚接触Xilinx UltraScale架构的开发者来说,GTY收发器的时钟分配规则就像一座迷宫——相邻Bank共享…...

XXL-SSO与Active Directory集成:企业级身份管理终极方案
XXL-SSO与Active Directory集成:企业级身份管理终极方案 XXL-SSO是一款分布式单点登录框架,能够帮助企业实现多系统统一身份认证与授权。本文将详细介绍如何将XXL-SSO与Active Directory集成,打造企业级身份管理解决方案,让用户认…...
批量生成)
Pixel Aurora Engine实战应用:像素游戏道具图标(武器/药水/装备)批量生成
Pixel Aurora Engine实战应用:像素游戏道具图标(武器/药水/装备)批量生成 1. 像素游戏道具生成的痛点与解决方案 独立游戏开发者经常面临一个共同挑战:如何高效制作大量风格统一的像素艺术道具图标。传统手工绘制方式存在三个主…...

Phi-3-mini-4k-instruct-gguf效果展示:温度0.0下100%一致性的制度类文本生成
Phi-3-mini-4k-instruct-gguf效果展示:温度0.0下100%一致性的制度类文本生成 1. 模型介绍与特点 Phi-3-mini-4k-instruct-gguf是微软推出的轻量级文本生成模型,属于Phi-3系列中的GGUF版本。这个模型特别适合需要稳定、一致输出的场景,尤其是…...

OneDrive导致桌面图标变白的解决方案
OneDrive导致桌面图标变白的原因主要是由于OneDrive的同步功能或图标缓存损坏。当使用OneDrive的“释放空间”功能时,可能会导致图标变为空白页或默认图标。此外,图标缓存损坏也可能导致图标变白。解决方法:1. 调整OneDrive设置:在…...

别再只建网站了!宝塔面板的‘Node项目’功能,让你的Express/Koa后端服务上线更简单
解锁宝塔面板的隐藏技能:Node.js后端服务一键部署实战指南 你是否还在为Node.js项目的繁琐部署流程而头疼?手动配置PM2、Nginx反向代理、环境变量设置...这些操作不仅耗时耗力,还容易出错。其实,你每天都在使用的宝塔面板早已内置…...

告别传统方法:LogAnomaly如何用NLP技术提升日志异常检测准确率?
告别传统方法:LogAnomaly如何用NLP技术重构日志异常检测范式? 日志数据如同数字世界的神经系统,记录着系统运行的每一次"心跳"与"呼吸"。传统检测方法就像拿着放大镜寻找心电图异常,而LogAnomaly则带来了全新…...

循环冷却水流量示意图设计 建筑水流量示意图绘制教程
一、引言 在建筑给排水、暖通空调及工业循环水系统设计中,循环冷却水流量示意图与建筑水流量示意图是核心技术图纸之一,其作用是直观呈现水流路径、管径规格、流量分配、设备连接关系及压力节点参数,为系统施工、调试、运维及故障排查提供可…...

从STFT到ISTFT:窗函数、填充与流式处理的实战指南
1. 窗函数一致性:信号重建的隐形守护者 第一次用STFT处理语音信号时,我踩过一个典型坑:用汉宁窗做分析,却忘了在重建时指定相同窗函数。结果重建后的语音像被掐着脖子说话,高频部分全是毛刺。这个教训让我明白…...