MyBatis-Plus为简化开发而生
简介
MyBatis-Plus 简称 MP是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。

他们的愿景是成为 MyBatis 最好的搭档,就像魂斗罗中的 1P、2P,基友搭配,效率翻倍。
特性
-
无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
-
损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
-
强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
-
支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
-
支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
-
内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
-
内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
-
分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
支持数据库
任何能使用
MyBatis进行 CRUD, 并且支持标准 SQL 的数据库,具体支持情况如下,如果不在下列表查看分页部分教程 PR 您的支持。
-
MySQL,Oracle,DB2,H2,HSQL,SQLite,PostgreSQL,SQLServer,Phoenix,Gauss ,ClickHouse,Sybase,OceanBase,Firebird,Cubrid,Goldilocks,csiidb,informix,TDengine,redshift
-
达梦数据库,虚谷数据库,人大金仓数据库,南大通用(华库)数据库,南大通用数据库,神通数据库,瀚高数据库,优炫数据库。
框架结构
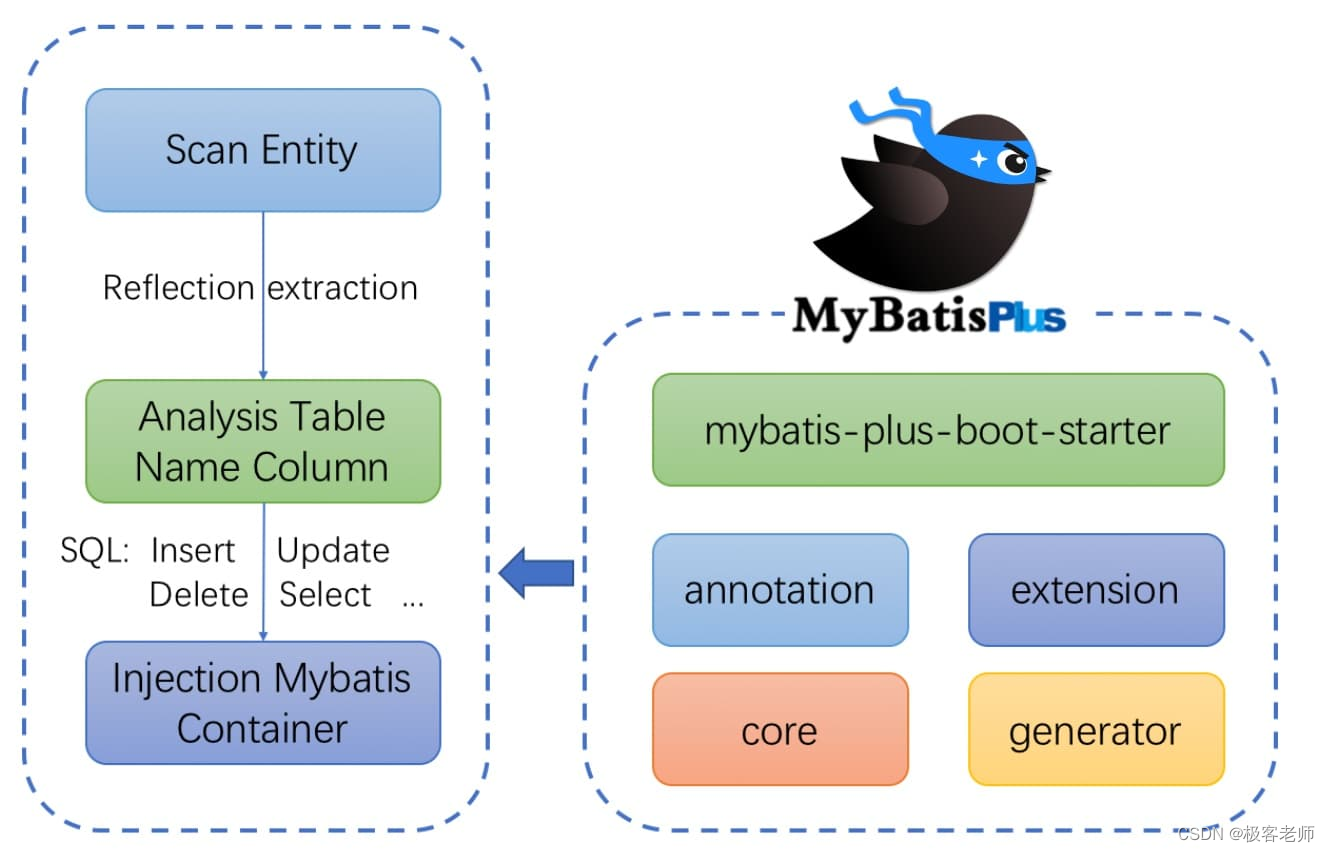
SSM传统编程模式
快速开始
现有一张User表
-- 用户表:user
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (`id` BIGINT(20) PRIMARY KEY AUTO_INCREMENT COMMENT '主键',`name` VARCHAR(30) DEFAULT NULL COMMENT '姓名',`age` INT(11) DEFAULT NULL COMMENT '年龄',`email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱',`manager_id` BIGINT(20) DEFAULT NULL COMMENT '直属上级id',`create_time` DATETIME(0) DEFAULT NULL COMMENT '创建时间',`update_time` DATETIME DEFAULT NULL COMMENT '修改时间',`version` INT(11) DEFAULT '1' COMMENT '版本',`deleted` INT(1) DEFAULT '0' COMMENT '逻辑删除标识(0.未删除,1.已删除)'
) ENGINE=INNODB CHARSET=UTF8;
INSERT INTO `user`(`id`,`name`,`age`,`email`,`manager_id`,`create_time`) VALUES
(1087982257332887553, '徐源', 28, 'boss@baomidou.com', NULL, '2023-06-28 09:20:20'),
(1088248166370832385, 'Tony', 25, 'wtf@baomidou.com', 1087982257332887553, '2023-06-28 11:12:22'),
(1088250446457389058, 'Jack', 28, 'lyw@baomidou.com', 1088248166370832385, '2023-06-28 08:31:16'),
(1094590409767661570, 'Rose', 31, 'zjq@baomidou.com', 1088248166370832385, '2023-06-27 09:15:15'),
(1094592041087729666, 'Lemon', 32, 'lhm@baomidou.com', 1088248166370832385, '2023-06-28 09:48:16');
项目添加依赖
<properties><java.version>1.8</java.version><mybatis-plus.version>3.3.2</mybatis-plus.version>
</properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>${mybatis-plus.version}</version></dependency>
</dependencies>
配置
在 application.yml 配置文件中添加数据库的相关配置:
# 配置数据源
spring:datasource:url: jdbc:mysql://121.89.226.84:3306/mybatis-plus?useUnicode=true&characterEncoding=utf8&serverTimezone=UTCdriver-class-name: com.mysql.cj.jdbc.Driverusername: rootpassword: root# 配置日志
logging:level:root: warncom.xkw.mp.crud.mapper: tracepattern:console: '%p%m%n'mybatis-plus:mapper-locations: ['classpath:/mapper/*Mapper.xml']
在 Spring Boot 启动类中添加 @MapperScan 注解,扫描 Mapper 文件夹:
@SpringBootApplication
@MapperScan("com.xkw.mp.crud.mapper")
public class CrudApp {public static void main(String[] args) {SpringApplication.run(ServiceApp.class, args);}
}
编码
编写实体类 User.java(此处使用了 Lombok简化代码)
@Data
public class User {private Long id;private String name;private Integer age;private String email;private Long managerId;private LocalDateTime createTime;private LocalDateTime updateTime;// 乐观锁注解@Versionprivate Integer version = 1;// 逻辑删除标识(0.未删除,1.已删除)@TableLogic@TableField(select = false)private Integer deleted = 0;
}
编写 Mapper 包下的 UserMapper接口
public interface UserMapper extends BaseMapper<User> {}
编写 Service 包下的 IUserService接口(非必须)
public interface IUserService extends IService<User> {}
@Service
public class UserService extends ServiceImpl<UserMapper, User> implements IUserService {}
测试
@RunWith(SpringRunner.class)
@SpringBootTest(classes = CrudApp.class)
@Slf4j
public class SampleTest {@AutowiredUserMapper userMapper;@AutowiredIUserService userService;@Testpublic void testSelect() {List<User> users01 = userMapper.selectList(null);Assert.assertEquals(8, users01.size());users01.forEach(user -> log.info(user.getName()));List<User> users02 = userService.list();Assert.assertEquals(8, users02.size());users02.forEach(user -> log.info(user.getName()));}
}
以上代码可以通过代码生成器快速生成,并且可以定制化生成:
AutoGenerator 是 MyBatis-Plus 的代码生成器,通过 AutoGenerator 可以快速生成 Entity、Mapper、Mapper XML、Service、Controller 等各个模块的代码,极大的提升了开发效率。
CRUD
通用Mapper
通用 CRUD 封装BaseMapper 接口,为 Mybatis-Plus 启动时自动解析实体表关系映射转换为 Mybatis 内部对象注入容器;
泛型 T 为任意实体对象;
参数 Serializable 为任意类型主键 Mybatis-Plus 不推荐使用复合主键约定每一张表都有自己的唯一 id 主键;
对象 Wrapper 为 条件构造器。
/*** Mapper 继承该接口后,无需编写 mapper.xml 文件,即可获得CRUD功能* <p>这个 Mapper 支持 id 泛型</p>** @author hubin* @since 2016-01-23*/
public interface BaseMapper<T> extends Mapper<T> {/*** 插入一条记录** @param entity 实体对象*/int insert(T entity);/*** 根据 ID 删除** @param id 主键ID*/int deleteById(Serializable id);/*** 根据 columnMap 条件,删除记录** @param columnMap 表字段 map 对象*/int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);/*** 根据 entity 条件,删除记录** @param wrapper 实体对象封装操作类(可以为 null)*/int delete(@Param(Constants.WRAPPER) Wrapper<T> wrapper);/*** 删除(根据ID 批量删除)** @param idList 主键ID列表(不能为 null 以及 empty)*/int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);/*** 根据 ID 修改** @param entity 实体对象*/int updateById(@Param(Constants.ENTITY) T entity);/*** 根据 whereEntity 条件,更新记录** @param entity 实体对象 (set 条件值,可以为 null)* @param updateWrapper 实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句)*/int update(@Param(Constants.ENTITY) T entity, @Param(Constants.WRAPPER) Wrapper<T> updateWrapper);/*** 根据 ID 查询** @param id 主键ID*/T selectById(Serializable id);/*** 查询(根据ID 批量查询)** @param idList 主键ID列表(不能为 null 以及 empty)*/List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);/*** 查询(根据 columnMap 条件)** @param columnMap 表字段 map 对象*/List<T> selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);/*** 根据 entity 条件,查询一条记录** @param queryWrapper 实体对象封装操作类(可以为 null)*/T selectOne(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);/*** 根据 Wrapper 条件,查询总记录数** @param queryWrapper 实体对象封装操作类(可以为 null)*/Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);/*** 根据 entity 条件,查询全部记录** @param queryWrapper 实体对象封装操作类(可以为 null)*/List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);/*** 根据 Wrapper 条件,查询全部记录** @param queryWrapper 实体对象封装操作类(可以为 null)*/List<Map<String, Object>> selectMaps(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);/*** 根据 Wrapper 条件,查询全部记录* <p>注意: 只返回第一个字段的值</p>** @param queryWrapper 实体对象封装操作类(可以为 null)*/List<Object> selectObjs(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);/*** 根据 entity 条件,查询全部记录(并翻页)** @param page 分页查询条件(可以为 RowBounds.DEFAULT)* @param queryWrapper 实体对象封装操作类(可以为 null)*/<E extends IPage<T>> E selectPage(E page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);/*** 根据 Wrapper 条件,查询全部记录(并翻页)** @param page 分页查询条件* @param queryWrapper 实体对象封装操作类*/<E extends IPage<Map<String, Object>>> E selectMapsPage(E page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
}
通用Service
通用 Service CRUD 封装IService接口,进一步封装 CRUD 采用 get 查询单行 remove 删除 list 查询集合 page 分页 前缀命名方式区分 Mapper 层避免混淆;
泛型 T 为任意实体对象;
建议如果存在自定义通用 Service 方法的可能,请创建自己的 IBaseService 继承 Mybatis-Plus 提供的基类;
对象 Wrapper 为 条件构造器。
Save
// 插入一条记录(选择字段,策略插入)
boolean save(T entity);
// 插入(批量)
boolean saveBatch(Collection<T> entityList);
// 插入(批量)
boolean saveBatch(Collection<T> entityList, int batchSize);
通用 insertBatch 为什么放在 service 层处理
-
SQL 长度有限制海量数据量单条 SQL 无法执行,就算可执行也容易引起内存泄露 JDBC 连接超时等
-
不同数据库对于单条 SQL 批量语法不一样不利于通用
-
目前的解决方案:循环预处理批量提交,虽然性能比单 SQL 慢但是可以解决以上问题。
SaveOrUpdate
// TableId 注解存在更新记录,否插入一条记录
boolean saveOrUpdate(T entity);
// 根据updateWrapper尝试更新,否继续执行saveOrUpdate(T)方法
boolean saveOrUpdate(T entity, Wrapper<T> updateWrapper);
// 批量修改插入
boolean saveOrUpdateBatch(Collection<T> entityList);
// 批量修改插入
boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize);
Remove
// 根据 queryWrapper 设置的条件,删除记录
boolean remove(Wrapper<T> queryWrapper);
// 根据 ID 删除
boolean removeById(Serializable id);
// 根据 columnMap 条件,删除记录
boolean removeByMap(Map<String, Object> columnMap);
// 删除(根据ID 批量删除)
boolean removeByIds(Collection<? extends Serializable> idList);
Update
// 根据 UpdateWrapper 条件,更新记录 需要设置sqlset
boolean update(Wrapper<T> updateWrapper);
// 根据 whereWrapper 条件,更新记录
boolean update(T updateEntity, Wrapper<T> whereWrapper);
// 根据 ID 选择修改
boolean updateById(T entity);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList, int batchSize);
Get
// 根据 ID 查询
T getById(Serializable id);
// 根据 Wrapper,查询一条记录。结果集,如果是多个会抛出异常,随机取一条加上限制条件 wrapper.last("LIMIT 1")
T getOne(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
T getOne(Wrapper<T> queryWrapper, boolean throwEx);
// 根据 Wrapper,查询一条记录
Map<String, Object> getMap(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
<V> V getObj(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
List
// 查询所有
List<T> list();
// 查询列表
List<T> list(Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
Collection<T> listByIds(Collection<? extends Serializable> idList);
// 查询(根据 columnMap 条件)
Collection<T> listByMap(Map<String, Object> columnMap);
// 查询所有列表
List<Map<String, Object>> listMaps();
// 查询列表
List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper);
// 查询全部记录
List<Object> listObjs();
// 查询全部记录
<V> List<V> listObjs(Function<? super Object, V> mapper);
// 根据 Wrapper 条件,查询全部记录
List<Object> listObjs(Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录
<V> List<V> listObjs(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
Page
// 无条件分页查询
IPage<T> page(IPage<T> page);
// 条件分页查询
IPage<T> page(IPage<T> page, Wrapper<T> queryWrapper);
// 无条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page);
// 条件分页查询
IPage<Map<String, Object>> pageMaps(IPage<T> page, Wrapper<T> queryWrapper);
Chain
query
// 链式查询 普通
QueryChainWrapper<T> query();
// 链式查询 lambda 式。注意:不支持 Kotlin
LambdaQueryChainWrapper<T> lambdaQuery();// 示例:
query().eq("column", value).one();
lambdaQuery().eq(Entity::getId, value).list();
update
/ 链式更改 普通
UpdateChainWrapper<T> update();
// 链式更改 lambda 式。注意:不支持 Kotlin
LambdaUpdateChainWrapper<T> lambdaUpdate();// 示例:
update().eq("column", value).remove();
lambdaUpdate().eq(Entity::getId, value).update(entity);
条件构造器
MyBatis-Plus条件构造器(MyBatis-Plus Condition Wrapper)是 MyBatis-Plus 框架提供的一个强大的查询条件构建工具,用于在 SQL 查询中添加多个动态条件;
通过使用条件构造器,您可以方便地根据不同的情况动态构建查询条件,并且避免了手动编写复杂的 SQL 语句。它提供了一套简单直观的 API,使得构建和管理查询条件变得更加灵活和高效。
使用条件构造器,您可以轻松实现以下常见操作:
等值判断 eq(column, value) 示例:
QueryWrapper<User> query = new QueryWrapper<>();
query.eq("name", "Tony");
不等值判断 ne(column, value) 示例:
QueryWrapper<User> query = new QueryWrapper<>();
query.ne("age", 28);
大于判断 gt(column, value)示例:gt(“salary”, 5000)
小于判断 lt(column, value)示例:lt(“create_time”, LocalDateTime.now())
范围判断 between(column, value1, value2)示例:between(“price”, 100, 200)
模糊查询 like(column, value)示例:like(“title”, “%keyword%”)
除此之外,条件构造器还支持排序、分页、子查询等功能,以及各种逻辑运算符(与、或、非)、函数计算等高级操作。
Lambda条件构造器
在 MyBatis-Plus 中,除了常规的条件构造器外,还提供了一种更为简洁、方便的 Lambda 条件构造器(Lambda Query Wrapper);
使用 Lambda 条件构造器,您可以通过 Java 8 中引入的 Lambda 表达式来编写查询条件;
使用 Lambda 条件构造器,能够让代码更加精炼,并且具有语法高亮和类型安全性,防误写;
下面是几个示例:
等值判断 eq(column, value) 示例:
LambdaQueryWrapper<User> lambdaQuery = Wrappers.lambdaQuery();
lambdaQuery.eq(User::getName, "Tony");
不等值判断 ne(column, value) 示例:
LambdaQueryWrapper<User> lambdaQuery = Wrappers.lambdaQuery();
lambdaQuery.ne(User::getAge, 28);
大于判断:wrapper.gt(User::getSalary, 5000)
小于判断:wrapper.lt(User::getCreateTime, LocalDateTime.now())
范围判断:wrapper.between(User::getPrice, 100, 200)
模糊查询:wrapper.like(User::getTitle, "%keyword%")
Lambda 条件构造器还支持排序、分页、子查询等功能,以及各种逻辑运算符(与、或、非)、函数计算等高级操作,使得条件拼接变得更加灵活和简单。
通过使用 MyBatis-Plus 的 Lambda 条件构造器,您可以轻松实现复杂查询,减少手动编写 SQL 的工作量,并且更容易维护和理解代码。它大大简化了查询条件的构建过程,提升了开发效率和代码质量。
Case
查询,徐姓或者年龄大于等于25,按照年龄降序排列,年龄相同则按照id升序排列
SQL:name like ‘徐%’ or age>=25 order by age desc,id asc
QueryWrapper<User> query = new QueryWrapper<>();
query.likeRight("name", "徐").or().ge("age", 25).orderByDesc("age").orderByAsc("id");
List<User> list = userMapper.selectList(query);
list.forEach(System.out::println);LambdaQueryWrapper<User> lambdaQuery = Wrappers.lambdaQuery();
lambdaQuery.likeRight(User::getName, "徐").or().ge(User::getAge, 25).orderByDesc(User::getAge).orderByAsc(User::getId);
List<User> list02 = userMapper.selectList(lambdaQuery);
list02.forEach(System.out::println);List<User> list03 = userService.lambdaQuery().likeRight(User::getName, "涂").or().ge(User::getAge, 25).orderByDesc(User::getAge).orderByAsc(User::getId).list();
list03.forEach(System.out::println);/**
* DEBUG==> Preparing: SELECT id,name,age,email,manager_id,create_time FROM user WHERE (name LIKE ? OR age >= ?) ORDER BY age DESC,id ASC
* DEBUG==> Parameters: 徐%(String), 20(Integer)
*/
查询,徐姓或者(龄小于40并且年龄大于28并且邮箱不为空)
SQL:name like ‘徐%’ or (age < 40 and age > 28 and email is not null)
QueryWrapper<User> query = new QueryWrapper<>();
query.likeRight("name", "徐").or(q -> q.between("age", 28, 40).isNotNull("email"));
List<User> list01 = userMapper.selectList(query);
list01.forEach(System.out::println);LambdaQueryWrapper<User> lambdaQuery = Wrappers.lambdaQuery();
lambdaQuery.likeRight(User::getName, "徐").or(q -> q.between(User::getAge, 28, 40).isNotNull(User::getName));
List<User> list02 = userMapper.selectList(lambdaQuery);
list02.forEach(System.out::println);/**
* DEBUG==> Preparing: SELECT id,name,age,email,manager_id,create_time FROM user WHERE (name LIKE ? OR (age BETWEEN ? AND ? AND name IS NOT NULL))
* DEBUG==> Parameters: 徐%(String), 28(Integer), 40(Integer)
*/
查询指定字段,名字中包含雨并且年龄小于40
QueryWrapper<User> query = new QueryWrapper<>();
query.select("name", "age").like("name", "雨").lt("age", 40);
List<User> list01 = userMapper.selectList(query);
list01.forEach(System.out::println);LambdaQueryWrapper<User> lambdaQuery = Wrappers.lambdaQuery();
lambdaQuery.select(User::getName, User::getAge).like(User::getName, "雨").lt(User::getAge, 40);
List<User> list02 = userMapper.selectList(lambdaQuery);
list02.forEach(System.out::println);/**
* DEBUG==> Preparing: SELECT name,age FROM user WHERE (name LIKE ? AND age < ?)
* DEBUG==> Parameters: %雨%(String), 40(Integer)
*/
查询,创建日期为2023年06月28日并且直属上级为徐姓
SQL:date_format(create_time, ‘%Y-%m-%d’)=‘2023-06-28’ and manager_id in (select id from user where name like ‘徐%’)
QueryWrapper<User> query = new QueryWrapper<>();
query.apply("DATE_FORMAT(create_time,'%Y-%m-%d')={0}", "2023-06-28").inSql("manager_id", "SELECT id FROM `user` WHERE `name` LIKE '徐%'");
List<User> list01 = userMapper.selectList(query);
list01.forEach(System.out::println);LambdaQueryWrapper<User> lambdaQuery = Wrappers.lambdaQuery();
lambdaQuery.apply("DATE_FORMAT(create_time,'%Y-%m-%d')={0}", "2023-06-28").inSql(User::getManagerId, "SELECT id FROM `user` WHERE `name` LIKE '徐%'");
List<User> list02 = userMapper.selectList(lambdaQuery);
list02.forEach(System.out::println);/**
* DEBUG==> Preparing: SELECT id,name,age,email,manager_id,create_time FROM user WHERE (DATE_FORMAT(create_time,'%Y-%m-%d')=? AND manager_id IN (SELECT id FROM `user` WHERE `name` LIKE '徐%'))
* DEBUG==> Parameters: 2023-06-28(String)
*/
主键策略
MyBatis-Plus 提供了一种灵活且开发友好的主键策略,可以方便地生成和管理实体类的主键。以下是 MyBatis-Plus 主要支持的几种主键策略:
-
自增主键(AUTO_INCREMENT):这是最常见的主键策略之一,数据库会自动为每条记录分配一个唯一的递增值作为主键;
-
UUID 主键:使用 Universally Unique Identifier (UUID) 作为唯一标识符,在插入数据时会自动生成一个长度为 32 的唯一字符串,并将其作为主键;
-
分布式 ID:提供了多种分布式 ID 策略,如雪花算法 Snowflake、Leaf、Ulid 等。这些策略通过在不同节点之间进行协调来产生全局唯一的 ID;
-
自定义主键生成器:允许开发者根据具体业务需求自定义主键生成逻辑,只需要实现 KeyGenerator 接口并配置到相应的实体上即可。
对于自增主键,MyBatis-Plus 在默认情况下会假设数据库会返回自动生成的主键,并自动将其设置回实体对象中。
若您使用的数据库无法自动生成主键或想手动控制主键生成过程,可以设置 @TableId注解的 type 属性为 IdType.INPUT,然后通过编码方式设置主键值。
对于 UUID 主键或分布式 ID,只需使用 @TableId注解指定主键生成策略为IdType.UUID 或 IdType.ID_WORKER 等即可。MyBatis-Plus 将会在插入数据时自动生成相应的主键。
若想自定义主键生成逻辑,可以实现 KeyGenerator 接口,并将该自定义主键生成器注入到 IOC 容器中。然后在实体类的 @TableId 注解中设置 generator 属性为自定义主键生成器的名字。
总而言之,MyBatis-Plus 提供了多种灵活且易用的主键策略,能够满足不同项目和业务场景下的需求。开发者可以根据具体情况选择合适的主键生成方式,并通过简单的配置即可轻松管理实体对象的主键。
插件
分页插件
分页插件(PaginationInterceptor):分页是在大部分应用中都需要处理的需求之一;MyBatis-Plus 的分页插件可以帮助我们方便地进行数据库查询结果的分页操作。通过使用该插件,我们可以很容易地实现分页查询并获取分页结果。
@Bean
@ConditionalOnMissingBean
public PaginationInterceptor paginationInterceptor() {PaginationInterceptor paginationInterceptor = new PaginationInterceptor();// 单页限制 500 条,小于 0 如 -1 不受限制paginationInterceptor.setLimit(-1);// 溢出总页数后是否进行处理(默认不处理)paginationInterceptor.setOverflow(true);return paginationInterceptor;
}
LambdaQueryWrapper<User> query = new LambdaQueryWrapper<>();
query.ge(User::getAge, 26).orderByDesc(User::getCreateTime);
Page<User> page = new Page<>(1, 2);
IPage<Map<String, Object>> iPage = userMapper.selectMapsPage(page, query);
System.out.println("总页数:" + page.getPages());
System.out.println("总记录数:" + iPage.getTotal());
List<Map<String, Object>> list = iPage.getRecords();
list.forEach(System.out::println);
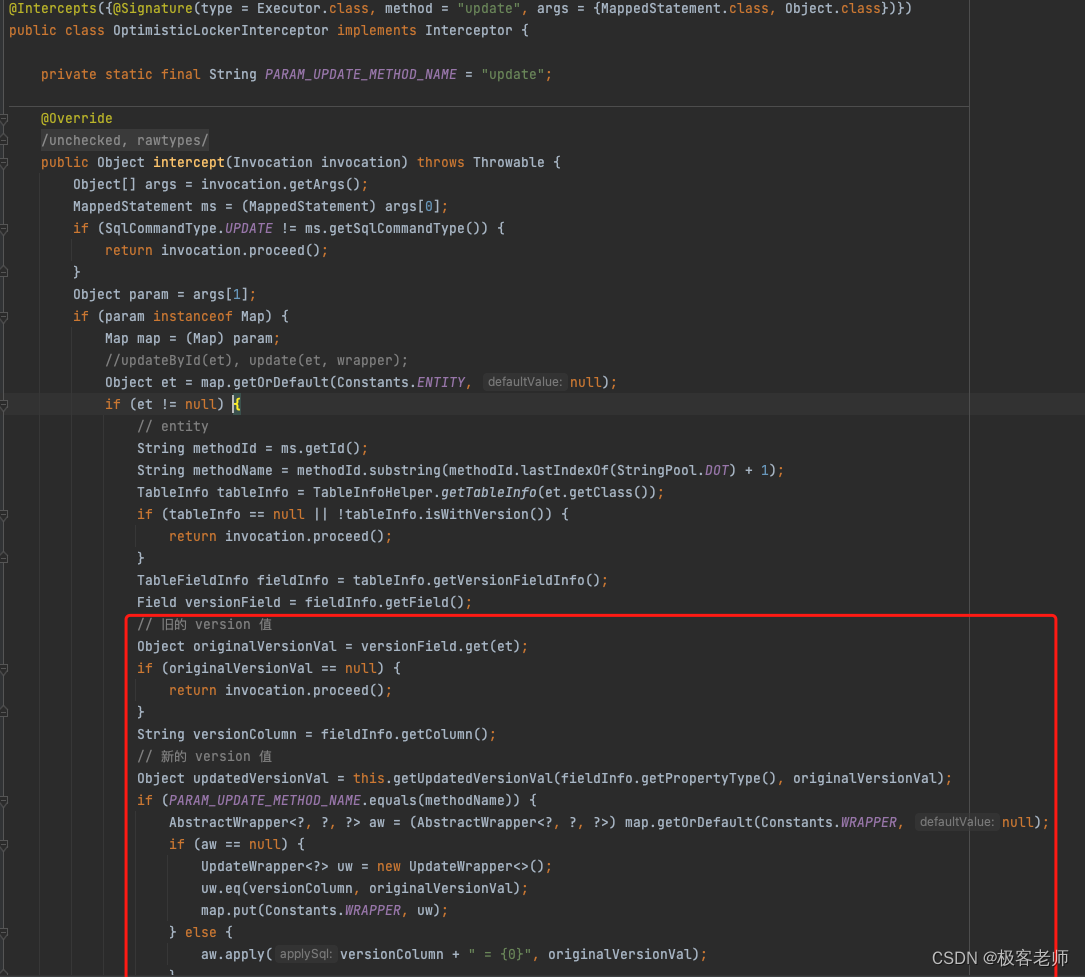
乐观锁插件
数据库乐观锁插件(OptimisticLockerInterceptor):乐观锁是一种并发控制机制,通过在数据表中添加一个版本号字段实现。MyBatis-Plus 的乐观锁插件可以自动处理带有乐观锁的更新操作,确保并发情况下不会出现数据被覆盖或丢失的问题。
/*** 引入乐观锁插件*/
@Bean
@ConditionalOnMissingBean
public OptimisticLockerInterceptor optimisticLockerInterceptor(){return new OptimisticLockerInterceptor();
}
@Data
public class User {/*** 乐观锁注解*/@Versionprivate Integer version;
}
User user = userMapper.selectById(1673973063479255042L);
user.setAge(30);System.out.println("开始休息,在修改的过程中,有其他用户对数据进行了更新...");
Thread.sleep(10000);
System.out.println("去数据库修改该条数据,并将version增加一个版本");int rows = userMapper.updateById(user);
System.out.println("影响行数:"+rows);/**
* DEBUG==> Preparing: SELECT id,name,age,email,manager_id,create_time,update_time,version,deleted FROM user WHERE id=?
* DEBUG==> Parameters: 1673973063479255042(Long)
* TRACE<== Columns: id, name, age, email, manager_id, create_time, update_time, version, deleted
* TRACE<== Row: 1673973063479255042, 王二狗, 30, null, 1088248166370832385, 2023-06-28 00:34:14, null, 5, 0
* DEBUG<== Total: 1
* 开始休息,在修改的过程中,有其他用户对数据进行了更新...
* 去数据库修改该条数据,并将version增加一个版本
* DEBUG==> Preparing: UPDATE user SET name=?, age=?, manager_id=?, create_time=?, version=?, deleted=? WHERE id=? AND version=?
* DEBUG==> Parameters: 王二狗(String), 30(Integer), 1088248166370832385(Long), 2023-06-28T00:34:14(LocalDateTime), 6(Integer), 0(Integer), 1673973063479255042(Long), 5(Integer)
* DEBUG<== Updates: 0
* 影响行数:0
*/
相关文章:
MyBatis-Plus为简化开发而生
简介 MyBatis-Plus 简称 MP是一个 MyBatis 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。 他们的愿景是成为 MyBatis 最好的搭档,就像魂斗罗中的 1P、2P,基友搭配,效率翻倍。 特性 无…...
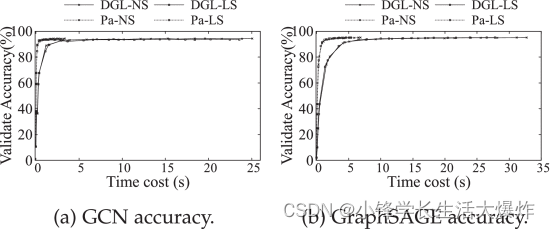
【翻译】Efficient Data Loader for Fast Sampling-Based GNN Training on Large Graphs
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 此内容为机器翻译的结果,若有异议的地方,建议查看原文。 机器翻译的一些注意点,比如: 纪元、时代 > epoch工人 > worker火车、培训、训练师 > train Effic…...

OPUS解码器PLC
OPUS解码器支持PLC(Packet Loss Concealment)技术。 在音频通信中,网络丢包是常见的情况。当网络丢失一些音频数据包时,接收端可能无法正常解码并播放这些丢失的音频信号,导致声音中断或质量下降。为了改善这种情况&a…...
Rancher 使用指南
Rancher 使用指南 Rancher 是什么?Rancher 与 OpenShift / Kubesphere 主要区别对比RancherOpenShiftKubesphere 对比 Rancher 和 OpenShift Rancher 安装 Rancher 是什么? 企业级Kubernetes管理平台 Rancher 是供采用容器的团队使用的完整软件堆栈。它解决了管理多个Kuber…...

百度SEO优化全攻略(提高网站排名的5个方面)
百度SEO入门介绍: 随着互联网的不断发展,SEO已经成为网站优化的重要一环。而百度作为中国最大的搜索引擎,其SEO优化更是至关重要。SEO不仅能够提高网站排名,还能够提高网站流量、用户体验以及品牌知名度。因此,掌握百…...

华为云云耀云服务器L实例评测|华为云耀云服务器L实例私有库搭建verdaccio(八)
九、华为云耀云服务器L实例私有库搭建verdaccio: Verdaccio 是一个简单的、零配置本地私有 npm 软件包代理注册表。Verdaccio 开箱即用,拥有自己的小型数据库,能够代理其它注册表(例如 npmjs.org),缓存下载…...
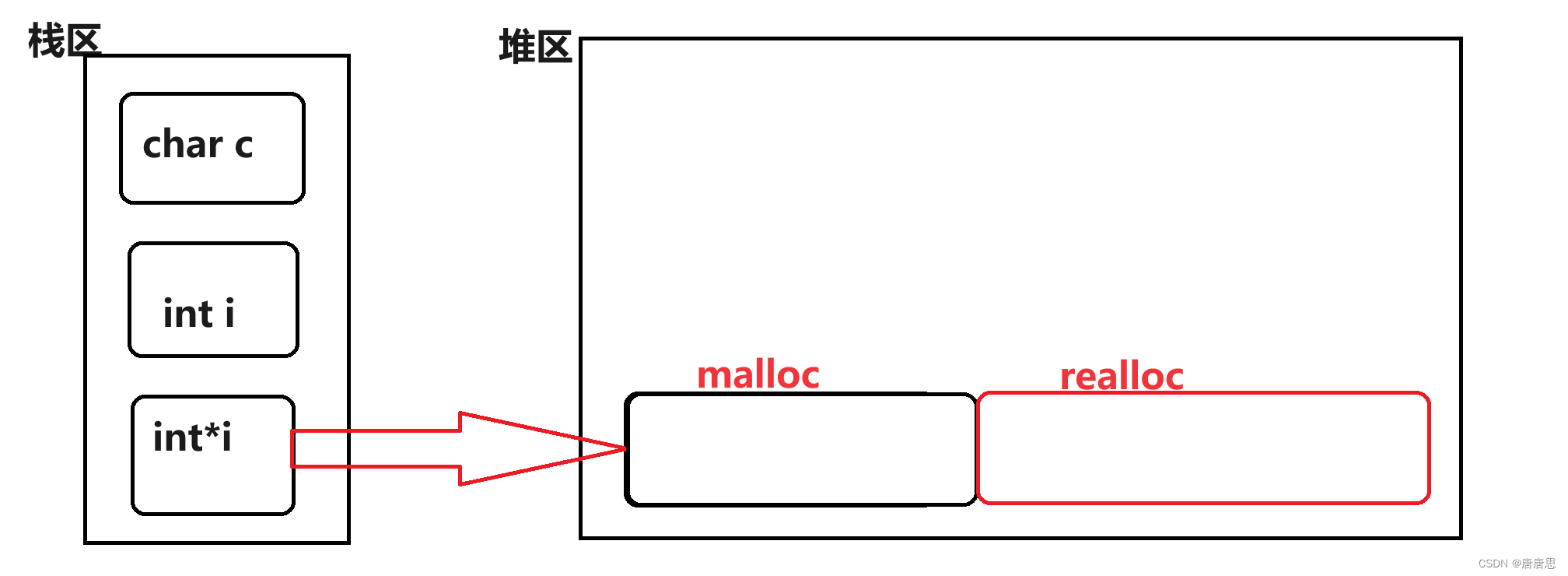
C语言之动态内存管理_柔性数组篇(2)
目录 柔性数组的特点 柔性数组的使用 动态内存函数增容柔性数组模拟实现 柔性数组的优势 今天接着来讲解一下柔性数组知识。 柔性数组的特点 C99中,结构中的最后一个元素允许是未知大小的数组,这就叫做【柔性数组】成员。 结构体中最后一个成员未…...

vue基础
引入vue文件 <div id"app"><!--{{}}插值表达式,绑定vue中的data数据-->{{message}} </div><script src"vue.min.js"></script> <script>new Vue({el:#app,data:{message:Hello Vue}}) </script>单项…...
访问量突破1W,纪念一下~
Mr.kanglong, 继续加油!...
)
C# 处理TCP数据的类(服务端)
using System; using System.Collections.Generic; using System.Net; using System.Net.Sockets; using System.Threading;namespace TestDemo {/// <summary>/// 处理TCP数据的类(服务端)/// </summary>public class TcpService{/// <s…...
【Jenkins】调用API构建并钉钉通知
文章目录 Jenkins API介绍提交作业带参数的作业API 令牌 Shell调用代码 Jenkins API介绍 Jenkins 提供了远程访问 API。目前它有三种格式: XML JSON Python 远程访问 API 形式为"…/api/" 例如, Jenkins 安装位于https://ci.jenkins.io&a…...

Java NIO三大核心组件
文章目录 一、Buffer1、重要属性2、重要方法1)allocate()创建缓冲区2)put()写入到缓冲区3)flip()翻转4)get()从缓冲区读取5)rewind()倒带6)mark()和reset()7)clear()清空缓冲区8)使用…...
?)
js数据排序方法(sort)?
在JavaScript中,可以使用Array的sort()方法对数据进行排序。下面是一个基本的例子,它展示了如何对一个数组进行升序和降序排序: // 创建一个数字数组 let numbers [2, 9, 1, 5, 8, 6];// 升序排序 let ascending numbers.sort(function(a,…...

若依框架学习笔记_mybatis
一、 在框架中引用的先后顺序 在ruoyi-system的resources下的xml中定义方法在java下的mapper包中引用方法在java下的service包中再引用mapper的方法 二、xml中的写法 标签: resultMap 返回数据sql 查询语句 可包含在其他操作中select 查询insert 插入update 更新…...

虚拟机的发展史:从分时系统到容器化
一、前世 早期计算机的价格非常昂贵,一台计算机可能需要花费几十万甚至上百万美元。例如,ENIAC计算机,作为世界上第一台通用电子数字计算机,当时的造价约为48万美元。科学家或者工程师们需要计算机的能力,但是买不起整…...

季涨约3~8%,DRAM合约价大幅回升 | 百能云芯
据TrendForce的研究显示,第4季DRAM与NAND Flash均价将开始全面上涨。特别是DRAM,预计第4季的合约价将季涨幅约在3%到8%之间。然而,这波上涨是否能持续,取决于供应商是否坚守减产策略以及实际需求的回升程度,尤其值得关…...

LocalDate的用法
日期时间转换 2023-03-30 14:25:00.000 DateTimeFormat(pattern "yyyy-MM-dd HH:mm:ss:sss")private LocalDateTime requestTimeStamp; 2021-06-18T10:46:19.67378508:00 new SimpleDateFormat("yyyy-MM-ddTHH:mm:ss:sssXXX");yyyy-mm-dd hh:mm:ss.sss 05…...

React通过ref获取子组件的数据和方法
父组件 1) ref必须传值, 否则childRef拿不到子组件的数据和方法 注意: 不一定使用app组件, 其他的任何父组件都可以 import "./App.css"; import React, { useEffect, useRef } from "react"; import RefToGetChild from "./components/RefToGetCh…...

Enhancing Self-Consistency and Performance of Pre-Trained Language Model
本文是LLM系列文章,针对《Enhancing Self-Consistency and Performance of Pre-Trained Language Models through Natural Language Inference》的翻译。 通过自然语言推理增强预训练语言模型的自一致性和性能 摘要1 引言2 相关工作3 通过关系检测进行一致性校正4 …...
安防监控视频汇聚平台EasyCVR视频广场搜索异常,报错“通道未开启”的问题排查与解决
安防视频监控系统EasyCVR视频汇聚平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等,能对外分发RTSP、RTMP、FLV、…...

2025小红书跳转卡片技术揭秘:从逆向分析到服务器端自动化部署
1. 小红书跳转卡片技术现状解析 小红书跳转卡片功能原本是平台提供给商家的官方营销工具,但近期所有公开接口都已关闭。现在市面上能正常使用的方案,基本都是通过逆向工程实现的Hook技术方案。我花了两个月时间逆向分析了小红书安卓端7.8版本到8.5版本的…...

拦截器与 JWT 联合使用详解
1. 核心概念1.1 什么是 JWT?JWT 是一个开放标准(RFC 7519),用于在各方之间以 JSON 对象的形式安全地传输信息。该信息可以被验证和信任,因为它是数字签名的。JWT 结构:Header(头部)&…...

DeepSeek-Coder-V2本地化部署指南:构建你的专属AI编程助手
DeepSeek-Coder-V2本地化部署指南:构建你的专属AI编程助手 【免费下载链接】DeepSeek-Coder-V2 DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence 项目地址: https://gitcode.com/GitHub_Trending/de/DeepSeek-Coder-V2 …...

如何高效保存B站视频?BiliTools全能下载解决方案让你无忧离线观看
如何高效保存B站视频?BiliTools全能下载解决方案让你无忧离线观看 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliT…...

Phi-4-mini-reasoning企业落地:金融风控规则推理+合规性自动校验
Phi-4-mini-reasoning企业落地:金融风控规则推理合规性自动校验 1. 模型概述与金融场景价值 Phi-4-mini-reasoning是微软推出的3.8B参数轻量级开源模型,专为数学推理、逻辑推导和多步解题等强逻辑任务设计。在金融领域,这个"小参数、强…...

为什么选择Drawflow:5大优势让你爱上这个流程图库
为什么选择Drawflow:5大优势让你爱上这个流程图库 【免费下载链接】Drawflow Simple flow library 🖥️🖱️ 项目地址: https://gitcode.com/gh_mirrors/dr/Drawflow Drawflow是一个简单而强大的JavaScript流程图库,专为创…...

Nano Banana进阶指南:从动漫角色到真人手办场景的AI创意融合
1. Nano Banana创意工作流全解析 第一次接触Nano Banana时,我就被它强大的图像生成能力震撼了。但真正让我着迷的,是它能够将动漫角色、真人cosplay和手办场景这三个看似独立的元素完美融合的能力。这种"三位一体"的创作方式,不仅打…...
)
用51单片机+Proteus仿真,从零到一复刻一个数码管电子钟(附完整代码和电路图)
从零构建51单片机数码管电子钟:Proteus仿真与实战全解析 数码管电子钟作为单片机入门经典项目,能系统训练定时器、中断、数码管驱动等核心技能。但很多初学者在独立实现时,常遇到仿真效果不稳定、显示闪烁或计时不准等问题。本文将用保姆级教…...

告别Putty和串口助手:这款LVGL开发的LCOM,如何成为我的嵌入式开发调试新宠?
告别Putty和串口助手:这款LVGL开发的LCOM,如何成为我的嵌入式开发调试新宠? 作为一名嵌入式开发者,每天与各种开发板、单片机打交道是家常便饭。调试过程中,串口通信工具就像我们的"第三只手",从…...
)
别再只用ZF和MMSE了!手把手教你用MATLAB实现ML信号检测(附完整代码与性能对比)
突破传统线性检测:MATLAB实战ML信号检测全解析 在无线通信系统的接收端设计领域,信号检测算法的选择直接影响着系统性能与实现复杂度之间的平衡。许多初学者往往止步于迫零(ZF)和最小均方误差(MMSE)这两种线性检测方法,却忽视了最大似然(ML)检…...