使用PyTorch加载数据集:简单指南
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢迎在文章下方留下你的评论和反馈。我期待着与你分享知识、互相学习和建立一个积极的社区。谢谢你的光临,让我们一起踏上这个知识之旅!

文章目录
- 🥦引言
- 🥦前期的准备
- 🥦基本的步骤说明
- 🥦代码讲解+实现
🥦引言
在机器学习和深度学习中,数据集的加载和处理是一个至关重要的步骤。PyTorch是一种流行的深度学习框架,它提供了强大的工具来加载、转换和管理数据集。在本篇博客中,我们将探讨如何使用PyTorch加载数据集,以便于后续的模型训练和评估。
🥦前期的准备
在实战前,我们需要了解三个名词,Epoch、Batch-Size、Iteration
下面针对上面,我展开进行说明
-
Epoch(周期):
定义:Epoch是指整个训练数据集被完整地前向传播和反向传播通过神经网络的一次循环。在一个Epoch内,模型将看到训练集中的每个样本一次,无论是一次完整的前向传播和反向传播,还是批量的。
作用:一个Epoch代表了一次完整的训练周期。在每个Epoch结束后,模型参数都会被更新一次。Epoch的数量通常是一个超参数,可以控制模型的训练时间和效果。 -
Batch Size(批大小):
定义:Batch Size是指每次迭代时用于训练模型的样本数量。在每个迭代中,模型将根据批大小从训练数据中选择一小批样本来执行前向传播和反向传播,然后更新模型参数。
作用:Batch Size控制了每次参数更新的规模。较大的批大小可以加速训练,但可能需要更多内存。较小的批大小可以增加模型的泛化能力,但训练时间可能更长。 -
Iterations(迭代):
定义:Iteration是指一次完整的前向传播、反向传播和参数更新。一个Iteration中,模型会处理一个Batch Size的样本。
联系:Iterations通常用于描述在一个Epoch内,模型参数更新的次数。一个Epoch内的Iterations数量等于训练数据集的大小除以Batch Size。例如,如果你有1000个训练样本,批大小为100,那么一个Epoch包含10个Iterations(1000 / 100 = 10)。
总结一下: 一个Epoch包含多个Iterations,每个Iteration包含一个Batch Size的样本。
Batch Size决定了每次参数更新的规模,而Epoch表示整个数据集的一个完整训练周期。
训练时通常迭代多个Epochs,其中每个Epoch由多个Iterations组成,以逐渐优化模型的参数。
超参数的选择,如Epoch数量和Batch Size,会影响训练的速度和模型的性能,需要根据具体问题进行调整和优化。
在DataLoader中有一个参数是shuffle,这个参数是一个bool值的参数,如果设置为TRUE的话,表示打乱数据集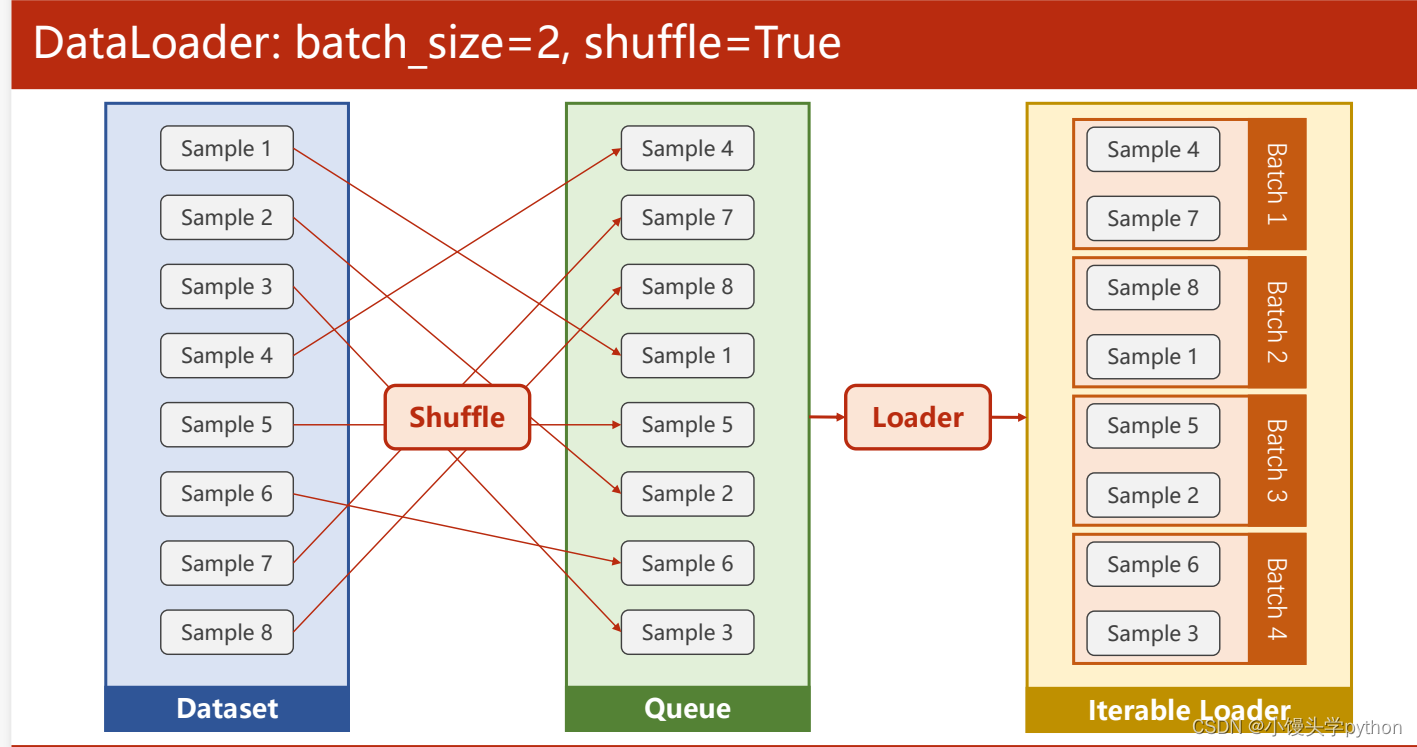
🥦基本的步骤说明
- 导入必要的库
- 定义数据预处理转换
- 下载和准备数据集
- 创建数据加载器
- 数据迭代
这里介绍一下DataLoader的参数
-
dataset:这是你要加载的数据集的实例,通常是继承自torch.utils.data.Dataset的自定义数据集类或内置数据集类(如MNIST)。
-
batch_size:指定每个批次(batch)中包含的样本数。这是一个重要参数,影响了训练和推理过程中的计算效率和模型的性能。通常,你需要根据你的硬件资源和数据集大小来选择适当的批大小。
-
shuffle:布尔值,控制是否在每个Epoch开始时打乱数据集的顺序。通常,设置为True可以帮助模型更好地学习,因为它增加了数据的随机性,避免模型对数据的顺序产生过度依赖。在训练时,通常建议将其设置为True。
-
num_workers:指定用于数据加载的子进程数量。这允许在数据加载过程中并行加载数据,以提高数据加载的效率。通常,设置为大于0的值可以加速数据加载。但要注意,过高的值可能会占用过多系统资源,因此需要权衡。
-
pin_memory:如果为True,则数据加载器会将批次数据置于GPU的锁页内存中,以提高数据传输的效率。通常,在GPU上训练时,建议将其设置为True。
-
drop_last:如果为True,当数据集的大小不能被批大小整除时,将丢弃最后一个批次。通常,将其设置为True以确保每个批次都具有相同大小,这在某些情况下有助于训练的稳定性。
-
timeout:指定数据加载超时的时间(单位秒)。如果数据加载器无法在指定时间内加载数据,它将引发超时异常。这可用于避免数据加载过程中的死锁。
🥦代码讲解+实现
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
class DiabetesDataset(Dataset):def __init__(self, filepath):xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32) self.len = xy.shape[0]self.x_data = torch.from_numpy(xy[:, :-1])self.y_data = torch.from_numpy(xy[:, [-1]])def __getitem__(self, index):return self.x_data[index], self.y_data[index]def __len__(self): return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2)
class Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self.linear1 = torch.nn.Linear(8, 6) self.linear2 = torch.nn.Linear(6, 4) self.linear3 = torch.nn.Linear(4, 1) self.sigmoid = torch.nn.Sigmoid()def forward(self, x):x = self.sigmoid(self.linear1(x)) x = self.sigmoid(self.linear2(x)) x = self.sigmoid(self.linear3(x)) return x
model = Model()
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(100):for i, data in enumerate(train_loader, 0):# 1. Prepare datainputs, labels = data# 2. Forwardy_pred = model(inputs)loss = criterion(y_pred, labels) print(epoch, i, loss.item())# 3. Backwardoptimizer.zero_grad()loss.backward()# 4. Updateoptimizer.step()
-
首先,导入所需的库,包括NumPy和PyTorch。这些库用于处理数据和创建深度学习模型。
-
创建一个自定义的数据集类DiabetesDataset,用于加载和处理数据。该类继承自torch.utils.data.Dataset类,并包含以下方法:
init:加载数据文件(假定是CSV格式),将数据分为特征(x_data)和标签(y_data),并存储数据集的长度(len)。
getitem:用于获取数据集中特定索引位置的样本。
len:返回数据集的总长度。 -
创建数据集实例dataset,并使用DataLoader创建数据加载器train_loader。数据加载器用于批量加载数据,batch_size参数设置每个批次的样本数,shuffle参数表示是否随机打乱数据集顺序,num_workers参数表示并行加载数据的进程数。
-
定义神经网络模型Model,该模型继承自torch.nn.Module。模型包含三个线性层和Sigmoid激活函数。在__init__方法中,定义了模型的层结构,而forward方法描述了数据在模型中的传递过程。
-
创建模型实例model。
-
定义损失函数criterion和优化器optimizer。在这里,使用了二元交叉熵损失函数(torch.nn.BCELoss)和随机梯度下降优化器(torch.optim.SGD)。
-
进行训练循环,循环次数为100次(由for epoch in range(100)控制)。
在内部循环中,使用enumerate(train_loader, 0)来迭代数据加载器。
准备数据:获取输入数据和标签。
前向传播:将输入数据传递给模型,获得预测值。
计算损失:使用损失函数计算预测值与实际标签之间的损失。
打印损失值:输出当前训练批次的损失值。
反向传播:通过优化器的backward()方法计算梯度。
参数更新:使用优化器的step()方法来更新模型参数。
这段代码演示了一个基本的二分类问题的训练过程,其中神经网络模型用于预测糖尿病患者的标签(0表示非糖尿病,1表示糖尿病)。模型的训练是通过反向传播算法来更新模型参数以减小损失。在训练循环中,你可以观察损失值的变化,以了解模型的训练进展。

挑战与创造都是很痛苦的,但是很充实。
相关文章:
使用PyTorch加载数据集:简单指南
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢…...
)
【考研数学】线性代数第六章 —— 二次型(2,基本定理及二次型标准化方法)
文章目录 引言一、二次型的基本概念及其标准型1.2 基本定理1.3 二次型标准化方法1. 配方法2. 正交变换法 写在最后 引言 了解了关于二次型的基本概念以及梳理了矩阵三大关系后,我们继续往后学习二次型的内容。 一、二次型的基本概念及其标准型 1.2 基本定理 定理…...
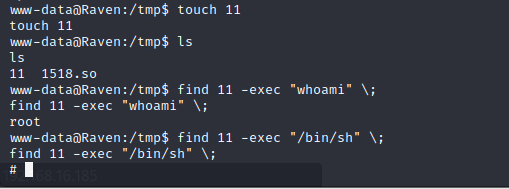
Raven2靶机渗透
1. 信息收集 1.1 主机探测 sudo arp-scan -l1.2 端口扫描 nmap -p- -A 192.168.16.185开放了80端口,尝试登录网址查看信息,通过浏览器插件找出指纹 1.3 目录扫描 访问登录界面,发现remember Me怀疑是shiro界面 登录/vendor/界面࿰…...

UE5中双pass解决半透明材质乱序问题
透明度材质乱序问题一直是半透明效果时遇到的比较多的问题,用多pass方案只能说一定程度上解决,当遇到多半透明物体穿插等情况时,仍然不能完美解决。 双pass方案Unity用的比较多,因为Unity支持多个pass绘制。在UE中我们可以以复制多…...
Cisdem Video Player for mac(高清视频播放器) v5.6.0中文版
Cisdem Video Player mac是一款功能强大的视频播放器,适用于 macOS 平台。它可用于播放不同格式的视频文件,并具有一些实用的特性和功能。 Cisdem Video Player mac 中文版软件特点 多格式支持:Cisdem Video Player 支持几乎所有常见的视频格…...

数据库管理-第109期 19c OCM考后感(20231015)
数据库管理-第109期 19c OCM考后感(202301015) 距离上一篇又过了两周多,为啥又卡了这么久,主要是后面几个问题:1. 9月1日的19c OCM upgrade考试木有过,因为有一次免费补考机会就又预约了10月8日的考试&…...
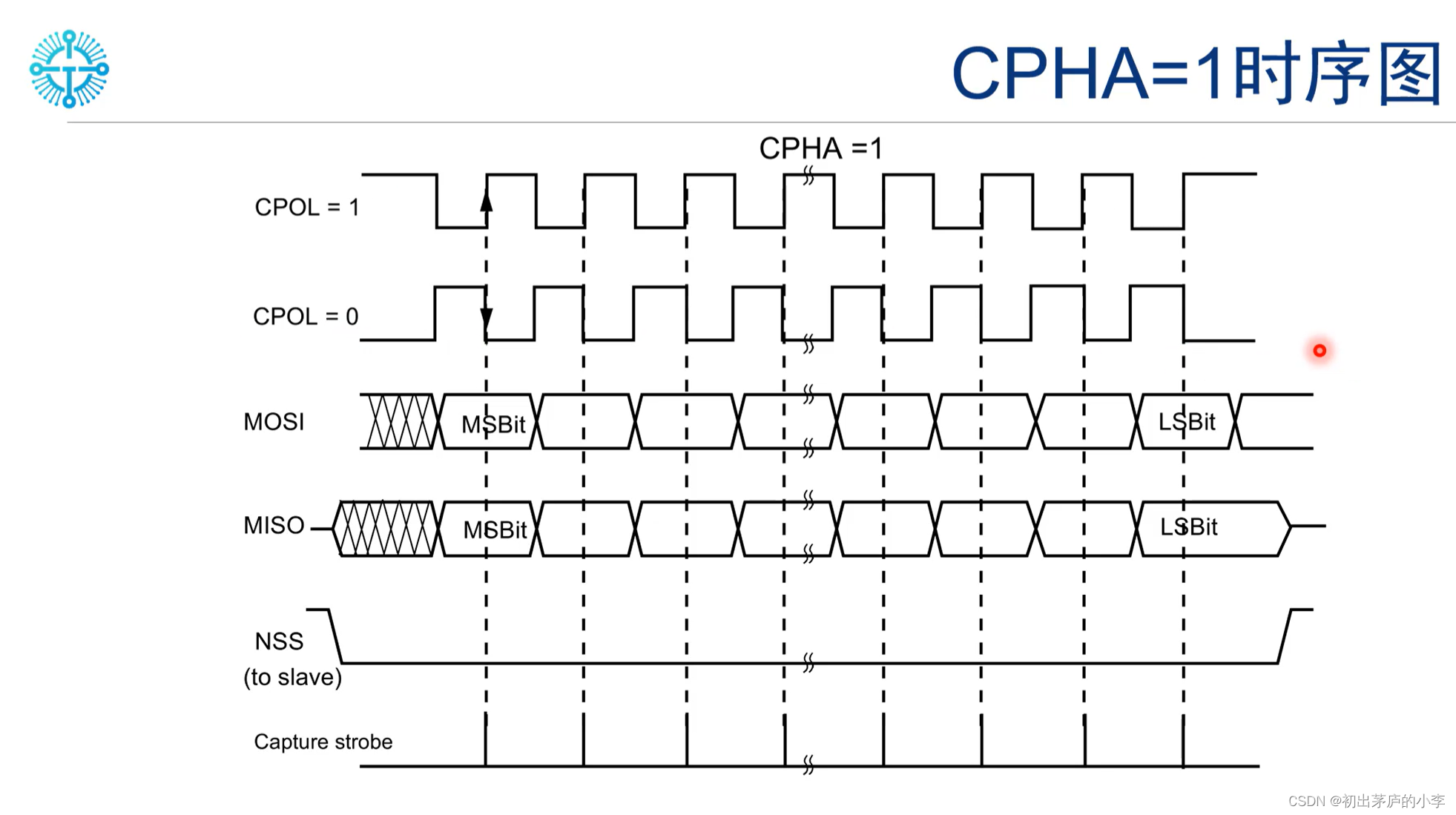
初出茅庐的小李博客之SPI工作模式
SPI的工作模式 SPI(Serial Peripheral Interface)是一种同步串行通信协议,常用于连接微控制器和外围设备。SPI有四种模式,分别是0、1、2、3模式。 0模式:时钟空闲时为低电平,数据在时钟的下降沿采样&#…...

SpringCloud-Bus
一、介绍 (1)bus搭配config可以实现客户端配置自动刷新 (2)bus支持两种消息代理,rabbitmq和kafka (3)使用topic模式分发消息 二、项目搭建(广播) (1&#…...
Adobe2024 全家桶更新了,PS、Ai、AE、PR应用尽有
Adobe2024 全家桶更新了,包含的PS、Ai、AE、PR......个人学习,专业领域都是必不可少的软件都有,需要的不要错过了。 如果你不知道从哪里安装这些工具,小编为大家带来了破J版资源,附上详细的安装包及安装教程。 Mac软件…...

【斗破年番】彩鳞换装美翻,雁落天惨死,萧炎暗杀慕兰三老遇险,彩鳞霸气护夫
Hello,小伙伴们,我是小郑继续为大家深度解析斗破苍穹年番资讯。 斗破苍穹动画已经更新了,小医仙与萧炎相认,三国联军撤退,随后彩鳞与萧炎以及小医仙夜晚相会,一起制定了刺杀行动。从官方公布的第68集预告,彩…...

华为端到端战略管理体系(DSTE开发战略到执行)的运作日历图/逻辑图及DSTE三大子流程介绍
华为端到端战略管理体系(DSTE开发战略到执行)的运作日历图/逻辑图及DSTE三大子流程介绍 本文作者 | 谢宁,《华为战略管理法:DSTE实战体系》、《智慧研发管理》作者 添加图片注释,不超过 140 字(可选&#…...
Linux友人帐之调试器--gdb的使用
一、debug和realease版本的区别 区别 debug是给程序员用的版本,添加了调试信息,用于解决软件或程序中出现的问题,realease是发行给客户使用的版本,并未添加调试信息,只需要给客户提供优越的产品使用环境即可ÿ…...
antd pro form 数组套数组 form数组动态赋值 shouldUpdate 使用
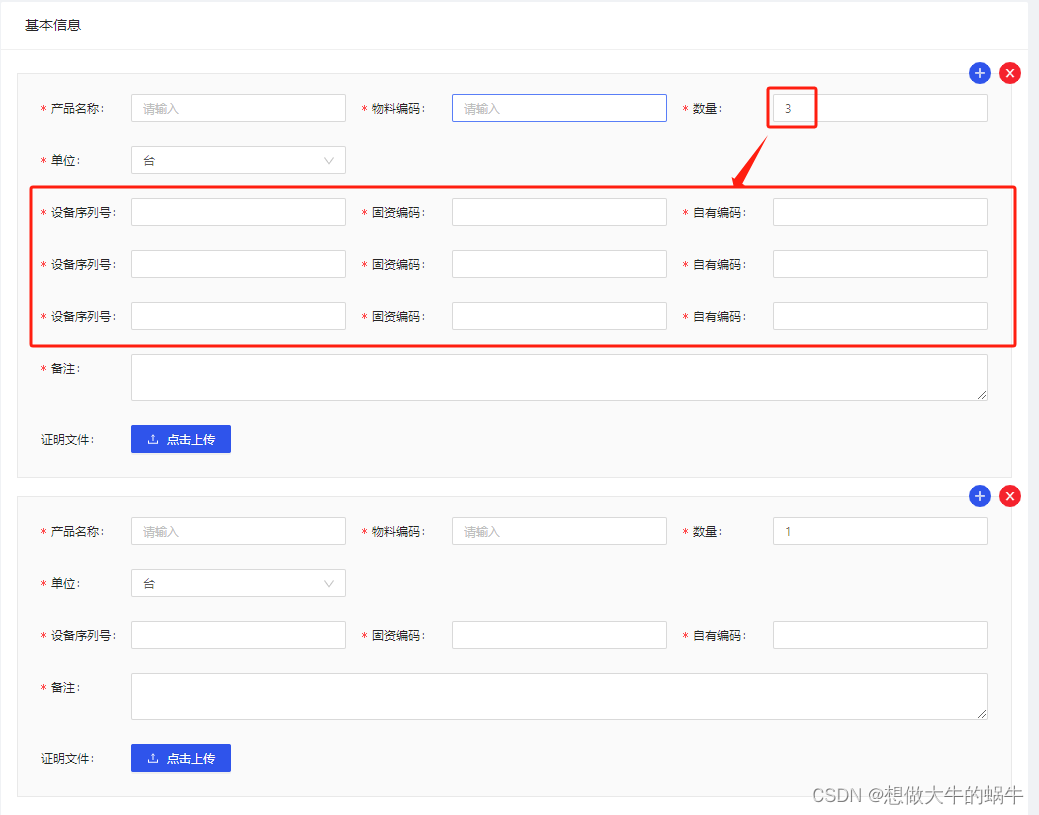
antd form中数组套数组 form数组动态变化 动态赋值 需求如上,同时添加多个产品,同时每个产品可以增加多台设备,根据设备增加相应编号,所以存在数组套数组,根据数组值动态变化 使用的知识点 form.list form中的数组…...

动态规划:918. 环形子数组的最大和
个人主页 : 个人主页 个人专栏 : 《数据结构》 《C语言》《C》《算法》 文章目录 前言一、题目解析二、解题思路解题思路状态表示状态转移方程初始化填表顺序返回值 三、代码实现总结 前言 本篇文章仅是作为小白的我的一些理解,,…...

毅速丨模具3D打印材料有哪些选择
当前1.2709和CX是市面上最常用的3D打印模具钢材料,模具3D打印有没有更多的材料选择呢? 据了解,上海毅速推出的几款3D打印新材料正在被越来越多的行业所采用。如毅速的EM191S高性能高抛光不锈钢粉末,这款材料的抗开裂和耐腐蚀性能是…...
Springcloud笔记(1)-微服务和springcloud介绍
微服务简介 就是将一个大的应用,拆分成多个小的模块,每个模块都有自己的功能和职责,每个模块可以 进行交互,这就是微服务对于微服务,业界没有严格统一的定义,但是作为“微服务”这名词的发明人,…...
十六、代码校验(4)
本章概要 调试 使用 JDB 调试图形化调试器 调试 尽管聪明地使用 System.out 或日志信息能给我们带来对程序行为的有效见解,但对于困难问题来说,这种方式就显得笨拙且耗时了。 你也可能需要更加深入地理解程序,仅依靠打印日志做不到。此时…...

【已解决】No Python at ‘D:\Python\python.exe‘
起因,我把我的python解释器,重新移了个位置,导致我在Pycharm中的爬虫项目启动,结果出现这个问题。 然后,从网上查到了这篇博客: 【已解决】No Python at ‘D:\Python\python.exe‘-CSDN博客 但是,按照上述…...

蓝桥杯双周赛算法心得——数树数(dfs)
大家好,我是晴天学长,一个简单的dfs思想,需要的小伙伴可以关注支持一下哦!后续会继续更新的。 1) .数树数 2) .算法思路 代码的主要逻辑是: 1.使用Scanner读取输入的整数n和q,其中n表示测试用例的数量&am…...
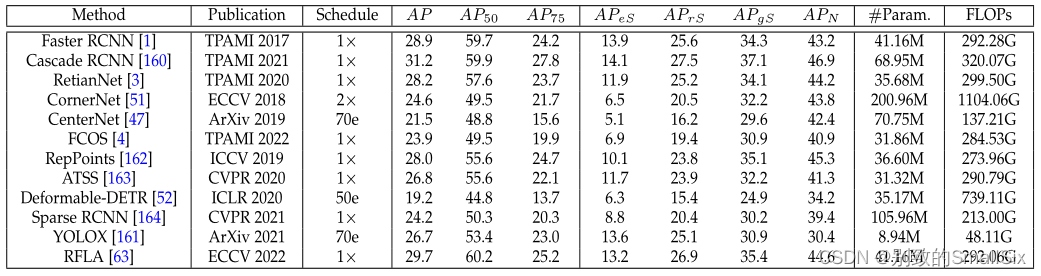
综述:大规模小目标检测
论文地址: Towards Large-Scale Small Object Detection: Survey and Benchmarksarxiv.org/abs/2207.14096 目录 摘要 1.Introduction 1.1 与之前综述的比较 1.2 总结 2.小目标检测回顾 2.1 问题定义 2.2 主要挑战 2.3 小目标检测算法回顾 3.小目标检测的数据集 …...

Kook Zimage 真实幻想 Typora文档集成方案
Kook Zimage 真实幻想 Typora文档集成方案 1. 引言 技术文档写作最头疼的是什么?文字描述得再生动,也不如一张直观的图片来得有说服力。传统的文档创作流程中,我们需要先在专门的AI绘图工具中生成图片,然后下载保存,…...

【技术解析】SimpleNet:用极简网络架构革新工业图像异常检测
1. 工业图像异常检测的现状与挑战 工业生产线上的质检环节一直是个让人头疼的问题。想象一下,你站在一条每分钟生产上百件产品的流水线旁,需要肉眼检查每个产品表面是否有划痕、凹陷或污渍——这几乎是不可能完成的任务。传统计算机视觉方法在这个领域已…...

车载Java OTA升级崩溃率从18.7%降至0.3%:基于Delta Patch + 类隔离热修复的4步标准化流程
第一章:车载Java OTA升级崩溃率从18.7%降至0.3%:基于Delta Patch 类隔离热修复的4步标准化流程在车载嵌入式Java环境(JVM 11,ART兼容层)中,OTA升级引发的ClassCastException与NoClassDefFoundError曾导致高…...

从make clean到build.prop:揭秘Android系统属性生成的完整链条
从make clean到build.prop:揭秘Android系统属性生成的完整链条 当你通过adb shell getprop ro.build.display.id查看设备版本号时,是否好奇过这个字符串背后的生成逻辑?在Android编译系统中,从Makefile执行到最终生成build.prop文…...

企微API集成指南——从回调到主动发送,全流程代码解析
企业微信提供了丰富的API,用于接收用户添加事件、发送消息、管理标签等。今天从实战角度,给出API集成的最佳实践,附带伪代码。一、核心API清单API用途频率限制获取access_token调用其他API的前提2000次/分钟添加外部联系人通过好友每个号300人…...
的协同诊断逻辑)
解码汽车ECU的“健康档案”:剖析吉利Basetech五大运行周期计数器(OCC)的协同诊断逻辑
1. 汽车ECU的“健康档案”是什么? 当你去医院体检时,医生会查看你的病历记录、化验报告和近期症状,综合判断你的健康状况。汽车ECU(电子控制单元)也有类似的"健康档案",它就是吉利Basetech技术中…...

foobox-cn个性化定制:打造你的专属foobar2000音乐界面
foobox-cn个性化定制:打造你的专属foobar2000音乐界面 【免费下载链接】foobox-cn DUI 配置 for foobar2000 项目地址: https://gitcode.com/GitHub_Trending/fo/foobox-cn 当你每天打开foobar2000时,是否希望看到的不只是一个播放器,…...

ShardingSphere-Proxy 5.2 容器化部署与开发调试实战指南
1. 为什么选择ShardingSphere-Proxy 5.2作为开发调试工具 在分库分表场景下开发应用时,最让人头疼的就是数据查询和调试问题。想象一下,你的订单数据被分散在4个库的8张表中,每次测试时想确认数据是否正确写入,都得手动连接不同数…...

高数值孔径物镜焦斑分析
背景介绍在显微成像、激光加工、光存储与单分子探测等应用中,高数值孔径物镜承担着“把光压缩到极小空间”的关键任务。物镜聚焦后的焦斑尺寸、形状、能量分布以及偏振特性,直接决定系统的分辨率、加工精度和探测灵敏度。因此,如何准确分析高…...

isaac lab5.0与ROS2通信
问题:isaac lab 5.0是基于python3.11 ros2是基于python3.10,因此不能在isaac sim的代码中直接写ros2的代码 在isaac sim中加import socketdef send_to_ros2(v, w):try:sock socket.socket(socket.AF_INET, socket.SOCK_STREAM)sock.connect((127.0.0.1…...