解密人工智能:KNN | K-均值 | 降维算法 | 梯度Boosting算法 | AdaBoosting算法

文章目录
- 一、机器学习算法简介
- 1.1 机器学习算法包含的两个步骤
- 1.2 机器学习算法的分类
- 二、KNN
- 三、K-均值
- 四、降维算法
- 五、梯度Boosting算法和AdaBoosting算法
- 六、结语
一、机器学习算法简介
机器学习算法是一种基于数据和经验的算法,通过对大量数据的学习和分析,自动发现数据中的模式、规律和关联,并利用这些模式和规律来进行预测、分类或优化等任务。机器学习算法的目标是从数据中提取有用的信息和知识,并将其应用于新的未知数据中。

1.1 机器学习算法包含的两个步骤
机器学习算法通常包括两个主要步骤:训练和预测。在训练阶段,算法使用一部分已知数据(训练数据集)来学习模型或函数的参数,以使其能够对未知数据做出准确的预测或分类。在预测阶段,算法将学习到的模型应用于新的数据,通过模型对数据进行预测、分类或其他任务。
1.2 机器学习算法的分类
机器学习算法可以是基于统计学原理、优化方法、神经网络等等。根据学习的方式不同,机器学习算法可以分为监督学习、无监督学习和强化学习等几种类型。不同的机器学习算法适用于不同的问题和数据类型,选择合适的算法可以提高机器学习的任务效果。
-
监督学习算法:监督学习算法需要训练数据集中包含输入和对应的输出(或标签)信息。常用的监督学习算法包括:线性回归、逻辑回归、决策树、支持向量机、朴素贝叶斯、人工神经网络等。
-
无监督学习算法:无监督学习算法不需要训练数据集中的输出信息,主要用于数据的聚类和降维等问题。常用的无监督学习算法包括:K均值聚类、层次聚类、主成分分析、关联规则挖掘等。
-
强化学习算法:强化学习算法通过与环境进行交互,试图找到最优策略来最大化奖励。常用的强化学习算法包括:Q学习、深度强化学习算法等。
此外,还有一些常用的机器学习算法和技术,如集成学习、降维方法、深度学习、迁移学习、半监督学习等,它们通过不同的方式和建模方法来解决不同的问题。选择合适的机器学习算法需要考虑问题的性质、数据的特点、算法的可解释性和计算效率等因素。
二、KNN
K 最近邻 (KNN) 是一种简单而强大的算法,用于机器学习中的分类和回归任务。它基于这样的想法:相似的数据点往往具有相似的目标值。该算法的工作原理是查找给定输入的 k 个最近数据点,并使用最近数据点的多数类或平均值来进行预测。

构建 KNN 模型的过程从选择 k 值开始,k 是预测时考虑的最近邻居的数量。然后将数据分为训练集和测试集,训练集用于查找最近的邻居。为了对新输入进行预测,该算法计算输入与训练集中每个数据点之间的距离,并选择 k 个最近的数据点。然后使用最近数据点的多数类或平均值作为预测。
优点:KNN 的主要优点之一是其简单性和灵活性。它可用于分类和回归任务,并且不对底层数据分布做出任何假设。此外,它可以处理高维数据,并可用于监督和无监督学习。
缺点:KNN 的主要缺点是其计算复杂性。随着数据集大小的增加,查找最近邻居所需的时间和内存可能会变得非常大。此外,KNN 对 k 的选择很敏感,并且找到 k 的最佳值可能很困难。
总结:K 最近邻(KNN)是一种简单而强大的算法,适用于机器学习中的分类和回归任务。它基于这样的想法:相似的数据点往往具有相似的目标值。KNN的主要优点是简单性和灵活性,它可以处理高维数据,并且可以用于监督和无监督学习。KNN 的主要缺点是其计算复杂性,并且对 k 的选择很敏感。
三、K-均值
K-means 是一种用于聚类的无监督机器学习算法。聚类是将相似的数据点分组在一起的过程。K-means 是一种基于质心的算法或基于距离的算法,我们计算将点分配给簇的距离。

该算法的工作原理是随机选择 k 个质心,其中 k 是我们想要形成的簇的数量。然后将每个数据点分配给具有最近质心的簇。一旦分配了所有点,质心将被重新计算为簇中所有数据点的平均值。重复此过程,直到质心不再移动或点对簇的分配不再改变。
优点:K-means 的主要优点之一是其简单性和可扩展性。它易于实现并且可以有效地处理大型数据集。此外,它是一种快速且鲁棒的算法,已广泛应用于图像压缩、市场细分和异常检测等许多应用中。
缺点:K 均值的主要缺点是它假设簇是球形且大小相等,但现实世界数据中的情况并非总是如此。此外,它对质心的初始放置和 k 的选择很敏感。它还假设数据是数字的,如果数据不是数字的,则必须在使用算法之前对其进行转换。
总结:总之,K-means 是一种用于聚类的无监督机器学习算法。它基于这样的想法:相似的数据点往往彼此接近。K-means 的主要优点是其简单性、可扩展性,并且广泛应用于许多应用中。K-means 的主要缺点是它假设簇是球形且大小相等,它对质心的初始位置和 k 的选择敏感,并且假设数据是数值的。
四、降维算法
降维是一种用于减少数据集中特征数量同时保留重要信息的技术。它用于提高机器学习算法的性能并使数据可视化更容易。有多种可用的降维算法,包括主成分分析 (PCA)、线性判别分析 (LDA) 和 t 分布随机邻域嵌入 (t-SNE)。

主成分分析 (PCA) 是一种线性降维技术,它使用正交变换将一组相关变量转换为一组称为主成分的线性不相关变量。PCA 对于识别数据模式和降低数据维度而不丢失重要信息非常有用。
线性判别分析(LDA)是一种监督降维技术,用于为分类任务找到最具判别性的特征。LDA 最大化了低维空间中类之间的分离。
t 分布随机邻域嵌入 (t-SNE) 是一种非线性降维技术,对于可视化高维数据特别有用。它使用高维数据点对上的概率分布来查找保留数据结构的低维表示。
优点:降维技术的主要优点之一是它们可以通过降低计算成本和降低过度拟合的风险来提高机器学习算法的性能。此外,它们还可以通过将维度数量减少到更易于管理的数量来使数据可视化变得更容易。
缺点:降维技术的主要缺点是在降维过程中可能会丢失重要信息。此外,降维技术的选择取决于数据的类型和手头的任务,并且可能很难确定要保留的最佳维数。
总结:总之,降维是一种用于减少数据集中特征数量同时保留重要信息的技术。有多种降维算法可用,例如 PCA、LDA 和 t-SNE,它们可用于识别数据模式、提高机器学习算法的性能并使数据可视化更容易。然而,在降维过程中可能会丢失重要信息,并且降维技术的选择取决于数据的类型和手头的任务。
五、梯度Boosting算法和AdaBoosting算法
梯度提升和 AdaBoost 是两种流行的集成机器学习算法,可用于分类和回归任务。这两种算法都通过组合多个弱模型来创建一个强大的最终模型。

梯度Boosting算法:梯度提升是一种迭代算法,它以向前阶段的方式构建模型。它首先将一个简单的模型(例如决策树)拟合到数据中,然后添加其他模型来纠正先前模型所犯的错误。每个新模型都适合损失函数相对于先前模型的预测的负梯度。最终模型是所有单独模型的加权和。
AdaBoosting算法:AdaBoost 是自适应增强 (Adaptive Boosting) 的缩写,是一种类似的算法,也以前向阶段方式构建模型。然而,它的重点是通过调整训练数据的权重来提高弱模型的性能。在每次迭代中,算法都会关注被先前模型错误分类的训练样本,并调整这些样本的权重,以便它们在下一次迭代中被选择的概率更高。最终模型是所有单独模型的加权和。

人们发现梯度增强和 AdaBoost 在许多实际应用中都可以生成高精度模型。这两种算法的主要优点之一是它们可以处理多种数据类型,包括分类数据和数值数据。此外,这两种算法都可以处理缺失值的数据,并且对异常值具有鲁棒性。
这两种算法的主要缺点之一是它们的计算成本可能很高,特别是当集成中的模型数量很大时。此外,他们可能对基础模型和学习率的选择很敏感。
总之,梯度提升和 AdaBoost 是两种流行的集成机器学习算法,可用于分类和回归任务。这两种算法都通过组合多个弱模型来创建一个强大的最终模型。人们发现,两者都可以在许多实际应用中产生高度准确的模型,但它们的计算成本可能很高,并且对基础模型和学习率的选择很敏感。
六、结语
今天的分享到这里就结束啦!如果觉得文章还不错的话,可以三连支持一下,春人的主页还有很多有趣的文章,欢迎小伙伴们前去点评,您的支持就是春人前进的动力!

相关文章:
解密人工智能:KNN | K-均值 | 降维算法 | 梯度Boosting算法 | AdaBoosting算法
文章目录 一、机器学习算法简介1.1 机器学习算法包含的两个步骤1.2 机器学习算法的分类 二、KNN三、K-均值四、降维算法五、梯度Boosting算法和AdaBoosting算法六、结语 一、机器学习算法简介 机器学习算法是一种基于数据和经验的算法,通过对大量数据的学习和分析&…...
Python深度学习实践
线性模型 课程 import numpy as np import matplotlib.pyplot as plt x_data[1.0,2.0,3.0] y_data[2.0,4.0,6.0] #前馈函数 def forward(x):return x*w #损失函数 def loss(x,y):y_predforward(x)return (y_pred-y)*(y_pred-y) w_list[] mse_list[] for w in np.arange(0.0,4…...
VS2017+QT+PCL环境配置
前言: 最近自己再弄一下小项目中需要用到pcl来开发点云的显示,但是却遇到很多坑,所以记录下来分析给知音人。 避雷:由于vtk和pcl之间有版本以来关系,但是安装过程是不变的。 选择对应的版本参考如下安装: pcl1.8.1依赖vtk版本7.1.1;pcl1.9.1至pcl1.12.0依赖vtk最低版本为…...
207、SpringBoot 整合 RabbitMQ 实现消息的发送 与 接收(监听器)
目录 ★ 发送消息★ 创建队列的两种方式代码演示需求1:发送消息1、ContentUtil 先定义常量2、RabbitMQConfig 创建队列的两种方式之一:配置式:问题: 3、MessageService 编写逻辑PublishController 控制器application.properties 配…...
想要精通算法和SQL的成长之路 - 滑动窗口和大小根堆
想要精通算法和SQL的成长之路 - 滑动窗口和大小根堆 前言一. 大小根堆二. 数据流的中位数1.1 初始化1.2 插入操作1.3 完整代码 三. 滑动窗口中位数3.1 在第一题的基础上改造3.2 栈的remove操作 前言 想要精通算法和SQL的成长之路 - 系列导航 一. 大小根堆 先来说下大小根堆是什…...
Python算法练习 10.15
leetcode 2130 链表的最大孪生和 在一个大小为 n 且 n 为 偶数 的链表中,对于 0 < i < (n / 2) - 1 的 i ,第 i 个节点(下标从 0 开始)的孪生节点为第 (n-1-i) 个节点 。 比方说,n 4 那么节点 0 是节点 3 的孪…...

智能防眩目前照灯系统控制器ADB
经纬恒润的自适应远光系统—— ADB(Adaptive Driving Beam) 是一种能够根据路况自适应变换远光光型的智能远光控制系统。根据本车行驶状态、环境状态以及道路车辆状态,ADB 系统自动为驾驶员开启或退出远光。同时,根据车辆前方视野…...
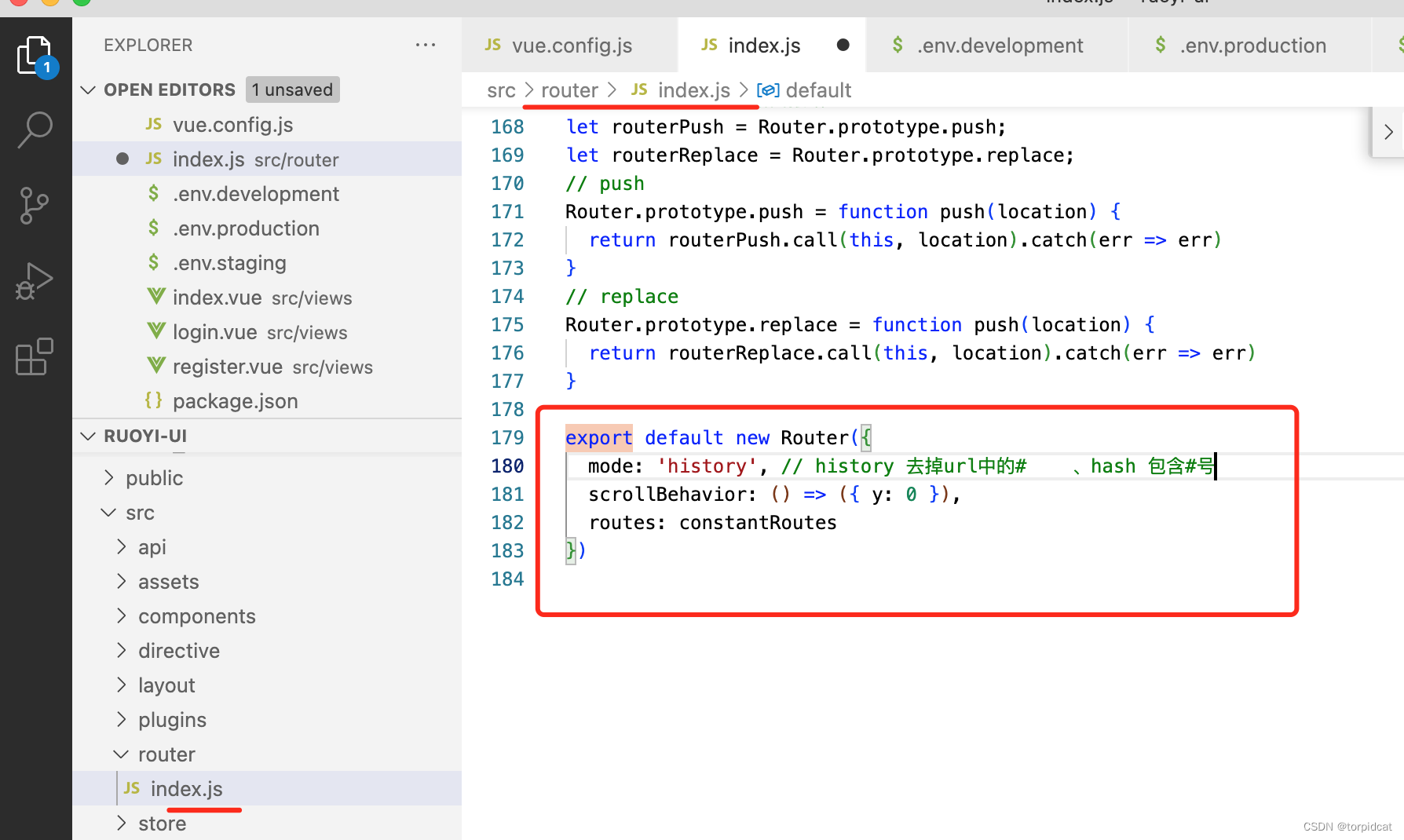
若依 ruoyi 路径 地址 # 井号去除
export default new Router({mode: history, // history 去掉url中的# 、hash 包含#号scrollBehavior: () > ({ y: 0 }),routes: constantRoutes })...
Elasticsearch 和 Arduino:一起变得更好!
作者:Enrico Zimuel 使用 Arduino IoT 设备与 Elasticsearch 和 Elastic Cloud 进行通信的简单方法 在 Elastic,我们不断寻找简化搜索体验的新方法,并开始关注物联网世界。 来自物联网的数据收集可能非常具有挑战性,尤其是当我们…...

基于Ubuntu环境Git 服务器搭建及使用
多人合作开发的时候 常常会需要使用代码管理平台,保持代码一致和解决冲突。在工作中我使用过SVN和TFS,本文说明另外一种平台,Git,下面是基于Ubuntu环境安装并简单使用Git服务器。 确认安装git apt install git levilevi-ThinkPa…...
【quartus13.1/Verilog】swjtu西南交大:计组课程设计
实验目的: 通过学习简单的指令系统及其各指令的操作流程,用 Verilog HDL 语言实 现简单的处理器模块,并通过调用存储器模块,将处理器模块和存储器模块连接形成简 化的计算机核心部件组成的系统。 二. 实验内容 1. 底层用 Verilog…...

基于springboot的网上点餐系统论文开题报告
一、选题背景 随着互联网和移动互联网技术的快速发展,网上点餐成为了人们越来越喜欢的一种点餐方式。一些具有创新意识的餐厅也开始逐渐尝试利用互联网技术来提升用户的点餐体验。因此,开发一个基于Spring Boot的网上点餐系统就显得非常必要和重要。 二…...
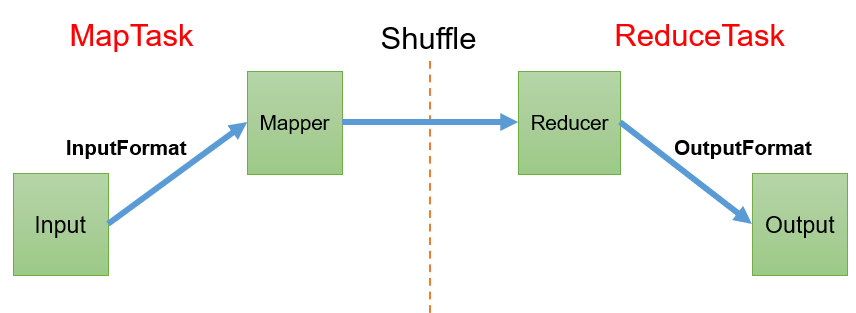
Hadoop3教程(九):MapReduce框架原理概述
文章目录 简介参考文献 简介 这属于整个MR中最核心的一块,后续小节会展开描述。 整个MR处理流程,是分为Map阶段和Reduce阶段。 一般,我们称Map阶段的进程是MapTask,称Reduce阶段是ReduceTask。 其完整的工作流程如图ÿ…...

使用PyTorch加载数据集:简单指南
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢…...
)
【考研数学】线性代数第六章 —— 二次型(2,基本定理及二次型标准化方法)
文章目录 引言一、二次型的基本概念及其标准型1.2 基本定理1.3 二次型标准化方法1. 配方法2. 正交变换法 写在最后 引言 了解了关于二次型的基本概念以及梳理了矩阵三大关系后,我们继续往后学习二次型的内容。 一、二次型的基本概念及其标准型 1.2 基本定理 定理…...
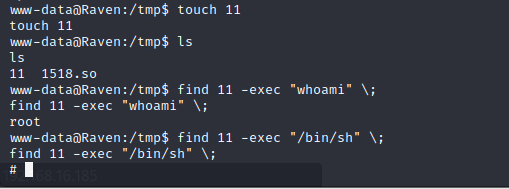
Raven2靶机渗透
1. 信息收集 1.1 主机探测 sudo arp-scan -l1.2 端口扫描 nmap -p- -A 192.168.16.185开放了80端口,尝试登录网址查看信息,通过浏览器插件找出指纹 1.3 目录扫描 访问登录界面,发现remember Me怀疑是shiro界面 登录/vendor/界面࿰…...

UE5中双pass解决半透明材质乱序问题
透明度材质乱序问题一直是半透明效果时遇到的比较多的问题,用多pass方案只能说一定程度上解决,当遇到多半透明物体穿插等情况时,仍然不能完美解决。 双pass方案Unity用的比较多,因为Unity支持多个pass绘制。在UE中我们可以以复制多…...
Cisdem Video Player for mac(高清视频播放器) v5.6.0中文版
Cisdem Video Player mac是一款功能强大的视频播放器,适用于 macOS 平台。它可用于播放不同格式的视频文件,并具有一些实用的特性和功能。 Cisdem Video Player mac 中文版软件特点 多格式支持:Cisdem Video Player 支持几乎所有常见的视频格…...

数据库管理-第109期 19c OCM考后感(20231015)
数据库管理-第109期 19c OCM考后感(202301015) 距离上一篇又过了两周多,为啥又卡了这么久,主要是后面几个问题:1. 9月1日的19c OCM upgrade考试木有过,因为有一次免费补考机会就又预约了10月8日的考试&…...
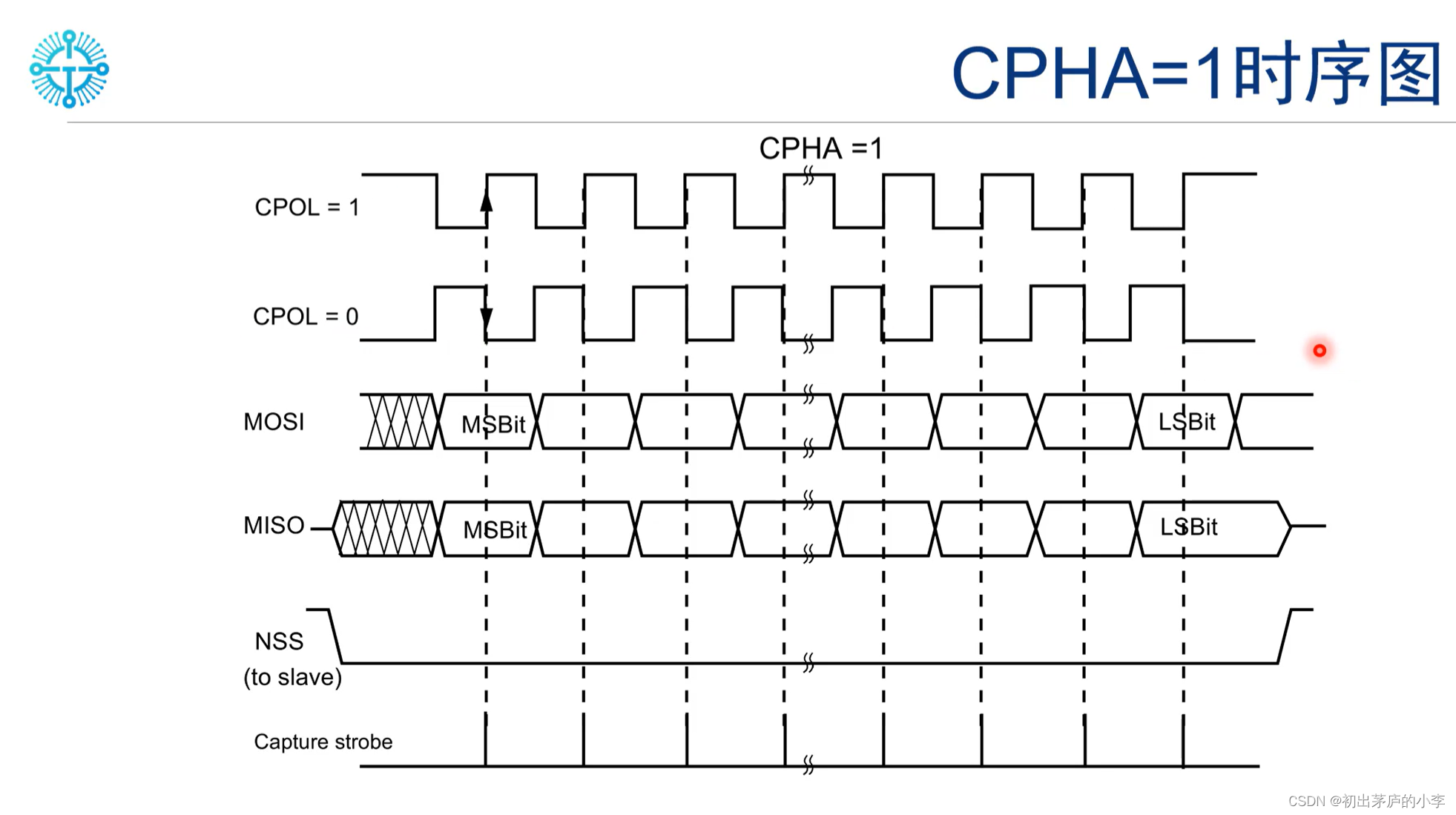
初出茅庐的小李博客之SPI工作模式
SPI的工作模式 SPI(Serial Peripheral Interface)是一种同步串行通信协议,常用于连接微控制器和外围设备。SPI有四种模式,分别是0、1、2、3模式。 0模式:时钟空闲时为低电平,数据在时钟的下降沿采样&#…...

嵌入式 - shell 常用语法简单总结
初步使用#!bin/bashecho "Hello world!"echo# shellvim helloworld.shchmod ux helloworld.sh# 在当前bash运行. helloworld.shsource helloworld.sh# 在子bash中运行,无法修改当前shell的变量./helloworld.shLinux中工具链的配置 ~/.bashrc用于定义当前…...

Qwen3.5-9B-AWQ-4bit参数调优实战:温度=0.7时中文回答质量与响应速度平衡点
Qwen3.5-9B-AWQ-4bit参数调优实战:温度0.7时中文回答质量与响应速度平衡点 1. 模型概述与参数调优背景 Qwen3.5-9B-AWQ-4bit是一个支持图像理解的多模态模型,能够结合上传图片与文字提示词输出中文分析结果。在实际应用中,我们发现温度参数…...

4个维度解析Steam Achievement Manager:开源工具如何重塑游戏成就管理体验
4个维度解析Steam Achievement Manager:开源工具如何重塑游戏成就管理体验 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager 一、困境诊断&#…...

降低AI检测率哪个工具好?10款免费工具2026亲测,亲测有用
很多同学在写论文时都会遇到同一个难题:用AI辅助写完的内容,一查AIGC率高到离谱,被导师打回要求整改。后台最近也收到不少私信问:怎么才能有效降低AI检测率?有没有靠谱的免费降AI率工具推荐? 我自己当初也踩…...

Python内存监控体系搭建:Prometheus+Custom Metrics+内存火焰图,实现OOM前15分钟精准预警
第一章:Python智能体内存管理策略 Python智能体(如基于LLM的Agent、ReAct架构或Tool-Calling Agent)在运行过程中频繁创建临时对象、缓存推理上下文、序列化工具调用结果,导致内存压力显著高于常规脚本。其内存管理需兼顾GC效率、…...

造相Z-Image文生图模型v2:3步搭建你的专属AI画师
造相Z-Image文生图模型v2:3步搭建你的专属AI画师 1. 为什么选择Z-Image v2作为你的AI画师 在众多文生图模型中,造相Z-Image v2以其独特的优势脱颖而出。作为阿里通义万相团队开源的高性能模型,它原生支持768768及以上分辨率的高清图像生成&…...

Element Plus访问优化指南:从卡顿到流畅的开发体验提升方案
Element Plus访问优化指南:从卡顿到流畅的开发体验提升方案 【免费下载链接】element-plus 🎉 A Vue.js 3 UI Library made by Element team 项目地址: https://gitcode.com/GitHub_Trending/el/element-plus 在前端开发过程中,你是否…...

STM32开发方式对比与HAL库实战指南
1. STM32开发方式概述作为一名嵌入式开发者,我亲历了STM32开发方式的变迁。从早期的寄存器操作到标准库,再到如今主流的HAL库,每种方式都有其独特的优势和适用场景。对于刚接触STM32的新手来说,选择合适的开发方式往往是个令人困惑…...

文明降级指南:回归纸笔躲避AI监控
AI监控时代的测试者困境在软件测试领域,人工智能的渗透已从效率工具演变为一种全景式的监控架构。AI驱动的测试套件能够以前所未有的速度执行用例、预测缺陷并生成报告,将测试周期与人力成本压缩至惊人水平。然而,这一技术乌托邦的背后&#…...

从三角函数到雷达滤波:三角窗的DSP实现与性能测试全记录
从三角函数到雷达滤波:三角窗的DSP实现与性能测试全记录 1. 三角窗的数学本质与信号处理价值 在数字信号处理领域,窗函数就像是一位精密的调音师,能够对原始信号进行细致的修饰和调整。三角窗作为其中最基础却又最富特色的成员之一࿰…...