【知识蒸馏】知识蒸馏(Knowledge Distillation)技术详解
参考论文:Knowledge Distillation: A Survey
1.前言
近年来,深度学习在学术界和工业界取得了巨大的成功,根本原因在于其可拓展性和编码大规模数据的能力。但是,深度学习的主要挑战在于,受限制于资源容量,深度神经模型很难部署在资源受限制的设备上。如嵌入式设备和移动设备。因此,涌现出了大量的模型压缩和加速技术,知识蒸馏是其中的代表,可以有效的从大型的教师模型中学习到小型的学生模型。本文从知识类别、训练模式、师生架构、蒸馏算法、性能比较和应用等方面对知识蒸馏进行了综述。
提到了近年来深度学习在计算机视觉、强化学习和自然语言处理上的一些进展,指出主要挑战在于大模型在实际应用中的部署。为了开发高效的深度模型,近年来的研究主要集中在深度模型的开发上:(1)深度神经网络高效快的构建;(2)模型压缩和加速技术,主要包含以下:
- 参数剪枝和共享:该方法专注于去除模型中的不必要参数 低秩分解:
- 该方法利用矩阵分解和张量分解来识别深度神经网络的冗余参数;
- 转移紧凑型卷积滤波器:该方法通过转移或压缩卷积滤波器来去除不必要的参数;
- 知识蒸馏(KD):该方法将知识从一个较大的深度神经网络中提取到一个较小的网络中
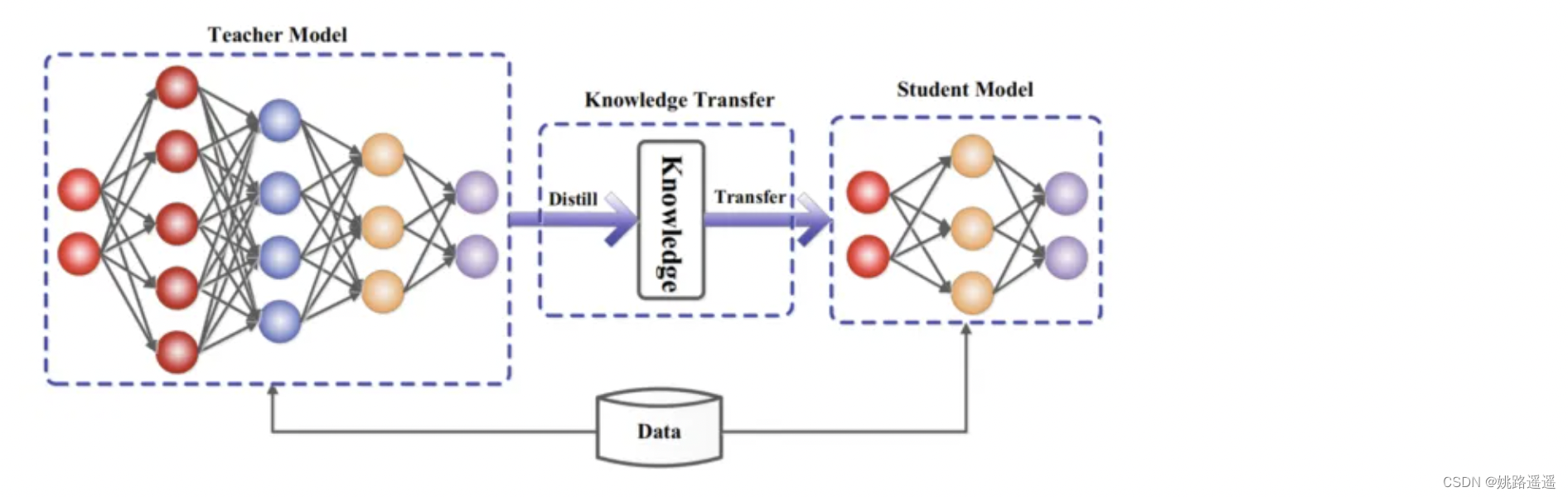
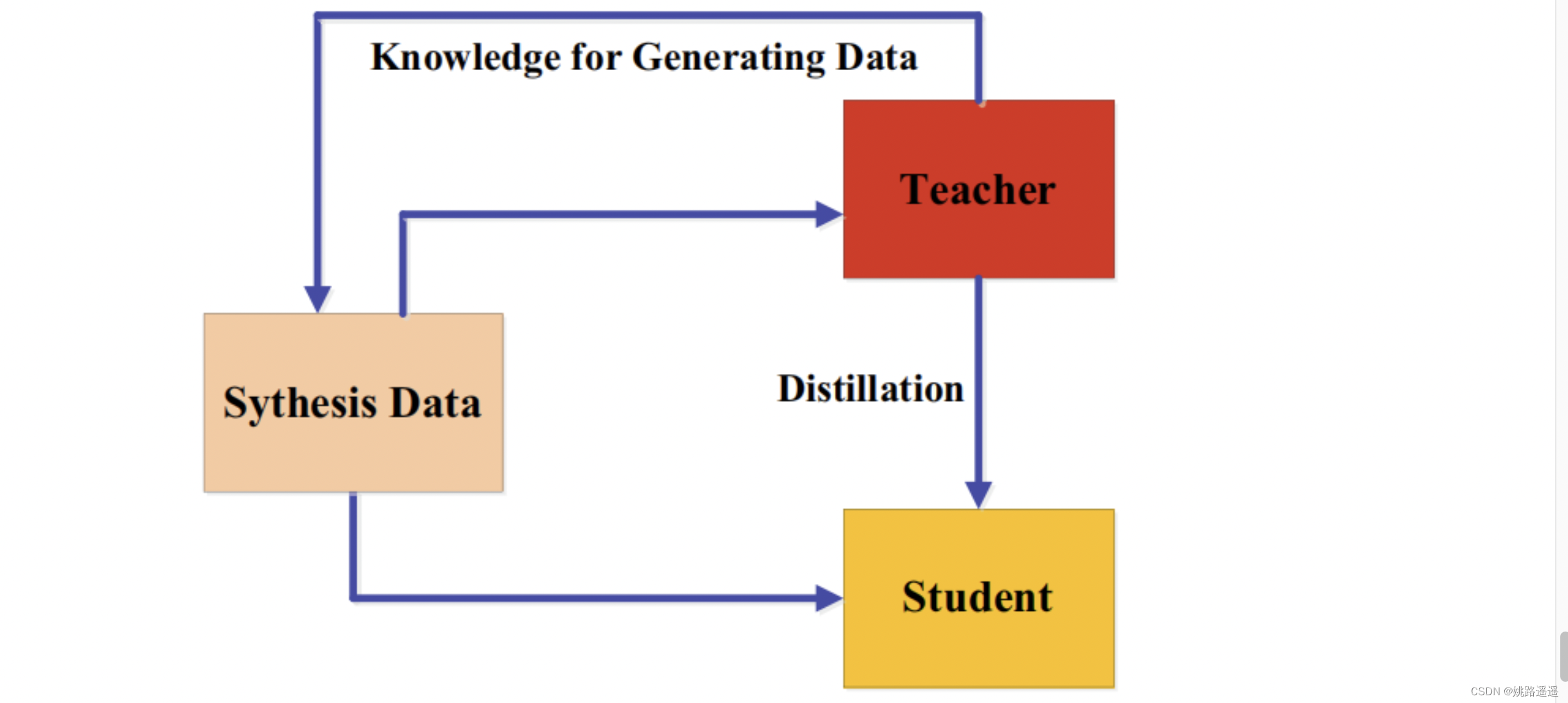
为了解决大模型的线上部署问题,Bucilua et al. (2006)首先提出了模型压缩,在不显著降低精度的情况下,将大模型或模型集合中的信息转换为训练小模型。在半监督学习中,引入了完全监督的教师模型和使用无标记数据的学生模型之间的知识转移。从小模型到大模型的学习后来被正式命名为为知识蒸馏(Hinton )。知识蒸馏主要思想是:学生模型模仿教师模型,二者相互竞争,是的学生模型可以与教师模型持平甚至卓越的表现。关键问题是如何将知识从大的教师模型转移到小的学生模型。知识蒸馏系统由知识、蒸馏算法和师生架构三个关键部分组成。如上图所示。
虽然在实践中取得了巨大的成功,但无论是理论还是经验上对知识蒸馏的理解都不多。关于知识蒸馏的原理,Urner等利用无标记数据证明了从教师模型到学生模型的知识转移是PAC可学习的;Phuong & Lampert通过在深度线性分类器场景下学习蒸馏学生网络的快速收敛获得了知识蒸馏的理证明,这个论证回答了学生学习的内容和速度,并揭示了决定蒸馏成功的因素,成功的蒸馏依赖于数据的分布、蒸馏目标的优化偏差和学生分类器的强单调性;Cheng等人量化了从深度神经网络的中间层中提取视觉概念,以解释知识蒸馏;Ji和Zhu分别从风险界、数据效率和不完善教师三个方面对广义神经网络知识蒸馏进行了理论解释;Cho和Hariharan对知识蒸馏的功效进行了详细的实证分析;Mirzadeh et al.的实证结果表明,由于模型能力差距的存在,模型越大的教师未必就越优秀;Cho and Hariharan (2019)的实验也表明,蒸馏对学生的学习有不利影响。知识蒸馏的不同形式对知识、蒸馏和师生互动的经验评价不包括在内;知识蒸馏也被用于标签平滑、评估教师的准确性和获得最佳输出层参数分布先验。
知识蒸馏与人的学习过程类似,基于此,近年来的一些研究拓展了教师—学生模型,发展为mutual learning、lifelong learning和self-learning。同时受到知识蒸馏在模型压缩中的影响,知识迁移已经被用在了压缩数据上,如dataset distillation。
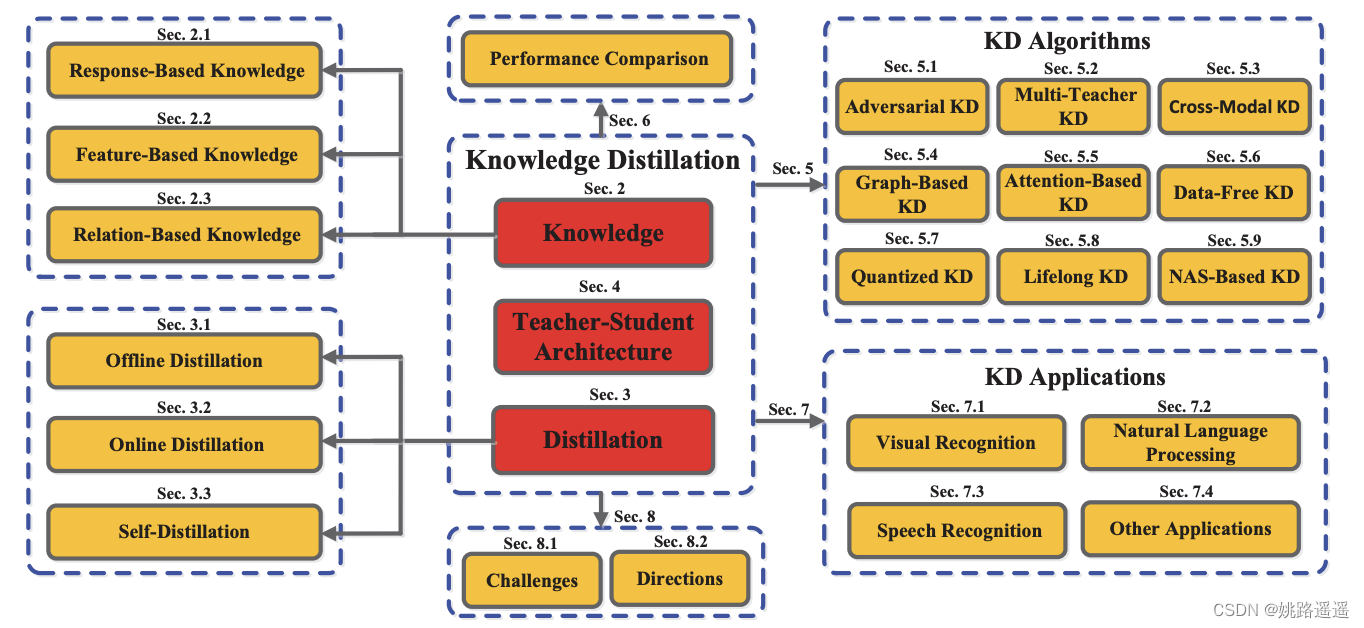
文章结构图
2.知识(Knowledge)
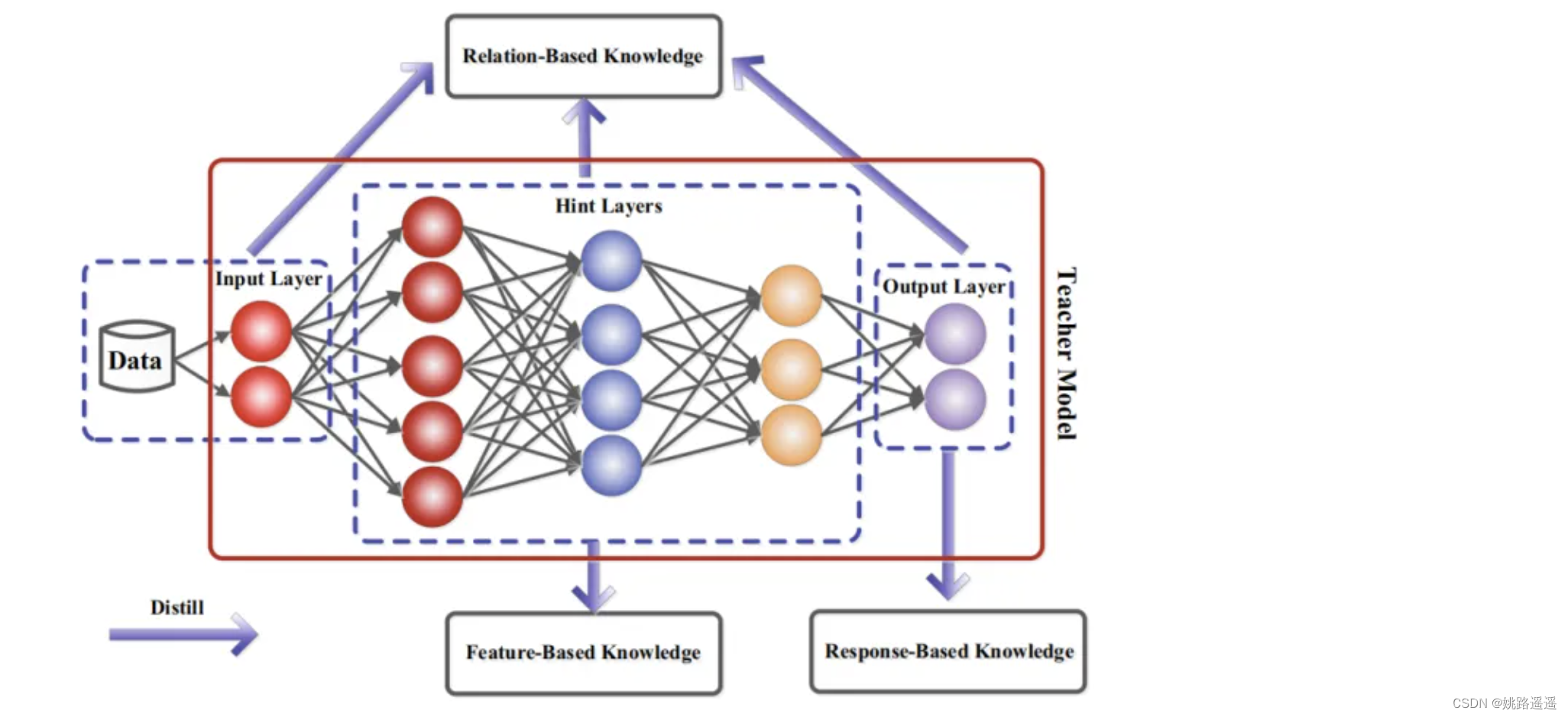
在知识蒸馏中,知识类型、蒸馏策略和师生架构对学生模型的学习起着至关重要的作用。原始知识蒸馏使用大深度模型的对数作为教师知识(Hinton 2015),中间层的激活、神经元或特征也可以作为指导学生模型学习的知识,不同的激活、神经元或成对样本之间的关系包含了教师模型所学习到的丰富信息.此外,教师模型的参数(或层与层之间的联系)也包含了另一种知识,本节主要讨论以下几种类型的知识:基于响应的知识(response-based knowledge),基于特征的知识( feature-based knowledge), 基于关系的知识(relation-based knowledge),下图为教师模型中不同知识类别的直观示例。
2.1. 基于响应的知识(Response-Based Knowledge)
Response-Based Knowledge通常是指教师模型的最后一输出层的神经反应。其主要思想是让学生模型直接模仿教师模式的最终预测(logits),假定对数向量Z为全连接层的最后输出,response-based knowledge蒸馏形式可以被描述为:
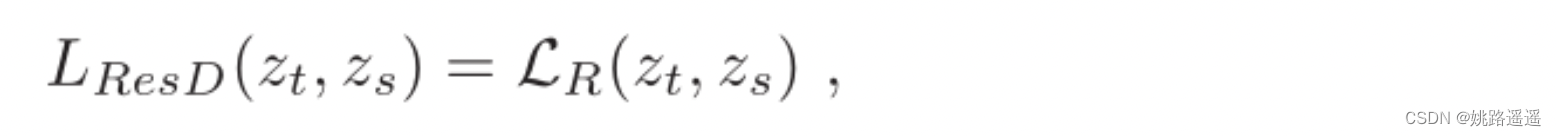
LR(.) 表示散度损失(这里也可以是用交叉熵损失),如下图所示为Response-Based 知识蒸馏模型图。
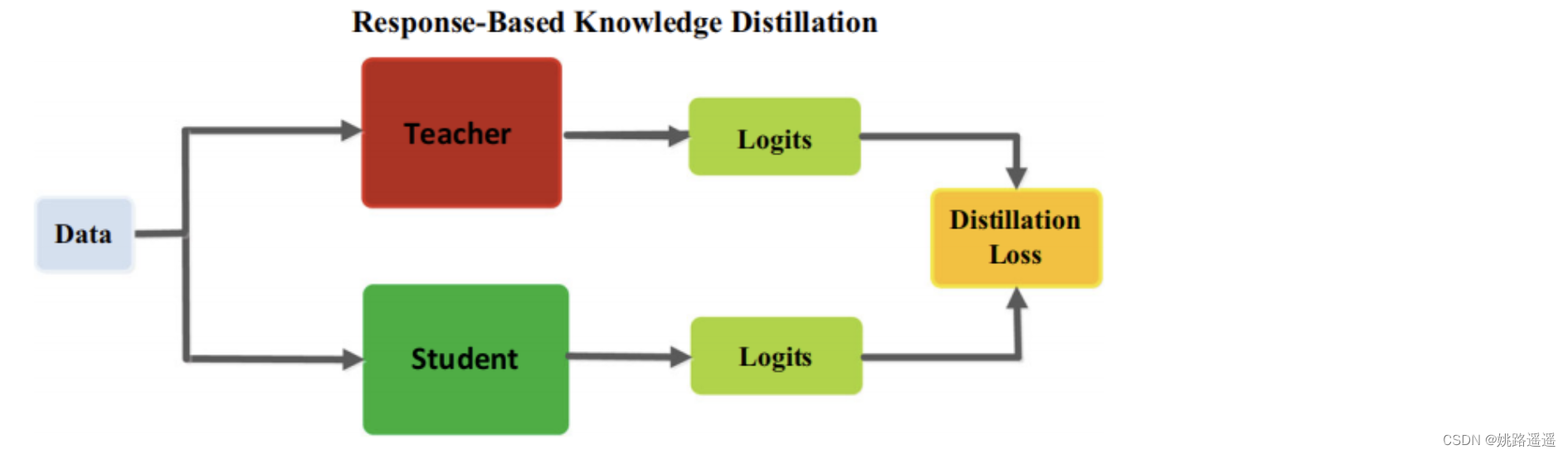
基于响应的知识可以用于不同类型的模型预测。例如,在目标检测任务中的响应可能包含bounding box的偏移量的logits;在人类姿态估计任务中,教师模型的响应可能包括每个地标的热力图。最流行的基于响应的图像分类知识被称为软目标(soft target)。软目标是输入的类别的概率,可以通过softmax函数估计为:

Zi是第i个类别的logit,T是温度因子,控制每个软目标的重要性。软目标包含来自教师模型的暗信息知识(informative dark knowledge)。因此,软logits的蒸馏loss可以重写为:
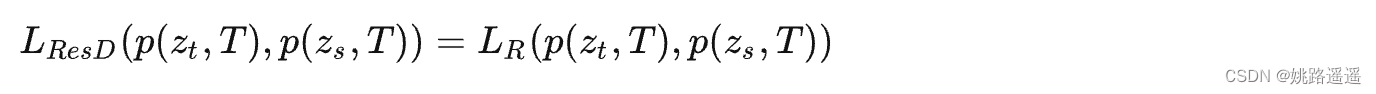
通常,LR(.)使用KL散度loss(Kullback-Leibler divergence,衡量两个概率分布的相似性的度量指标)。优化该等式可以使学习的logits与教师的logits相匹配。下图为基准知识蒸馏的具体架构。

然而,基于响应的知识通常需要依赖最后一层的输出,无法解决来自教师模型的中间层面的监督,而这对于使用非常深的神经网络进行表示学习非常重要。由于logits实际上是类别概率分布,因此基于响应的知识蒸馏限制在监督学习。
2.2. 基于特征的知识(Feature-Based Knowledge)
深度神经网络善于学习到不同层级的表征,因此中间层和输出层的都可以被用作知识来训练学生模型,对于最后一层的输出和中间层的输出(特征图,feature map),都可以作为监督学生模型训练的知识,中间层的Feature-Based Knowledge对于 Response-Based Knowledge是一个很好的补充,其主要思想是将教师和学生的特征激活直接匹配起来。一般情况下,Feature-Based Knowledge知识转移的蒸馏损失可表示为:
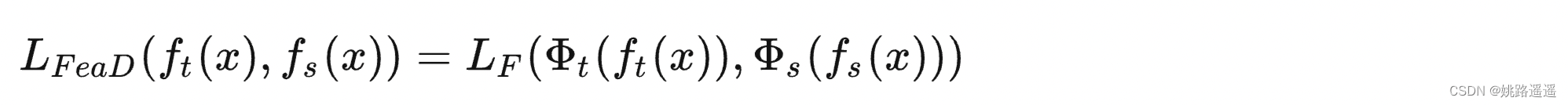
其中ft(x)、fs(x)分别是教师模型和学生模型的中间层的特征图。变换函数当教师和学生模型的特征图大小不同时应用。LF(.)衡量两个特征图的相似性,常用的有L1 norm、L2 norm、交叉熵等。下图为基于特征的知识蒸馏模型的通常架构。
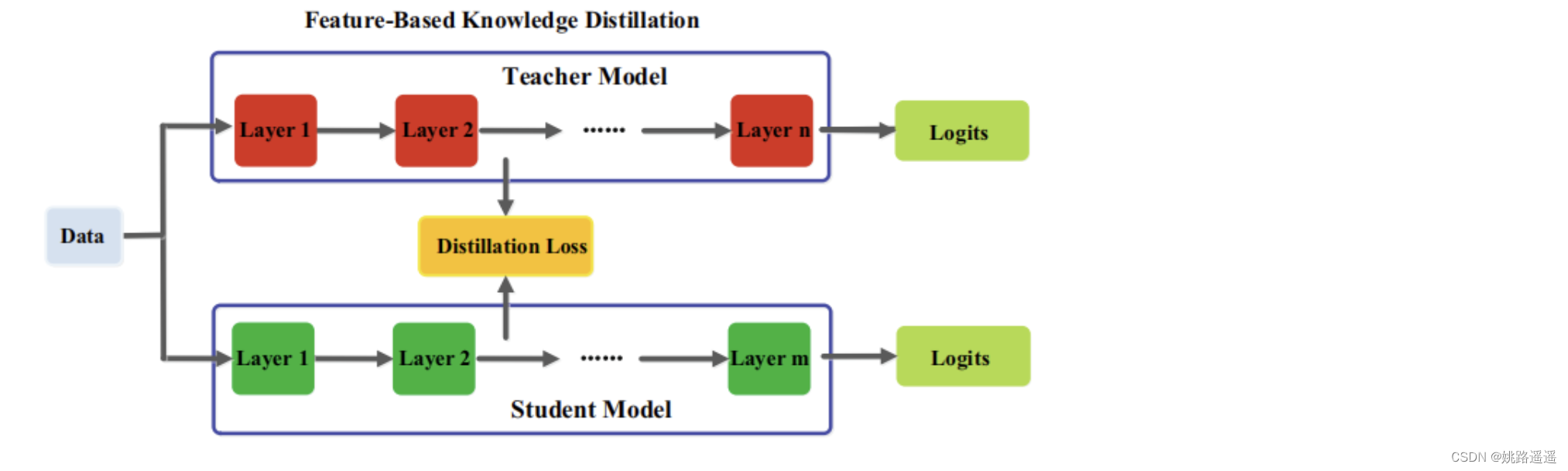
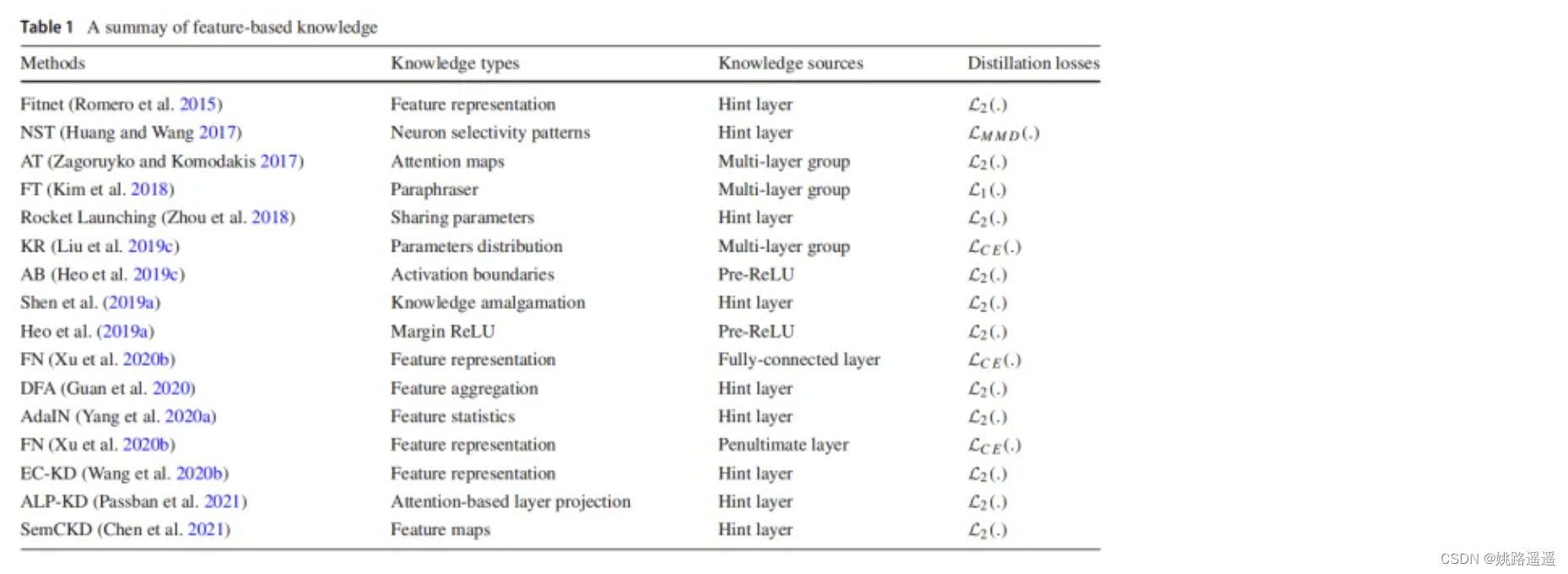
虽然基于特征的知识迁移为学生模型的学习提供了良好的信息,但如何有效地从教师模型中选择提示层,从学生模型中选择引导层,仍有待进一步研究。由于提示层和引导层的大小存在显著差异,如何正确匹配教师和学生的特征表示也需要探讨。
2.3. 基于关系的知识(Response-Based Knowledge)
基于响应和基于特征的知识都使用了教师模型中特定层的输出,基于关系的知识进一步探索了不同层或数据样本的关系。一般,将基于特征图关系的关系知识蒸馏loss表述如下:
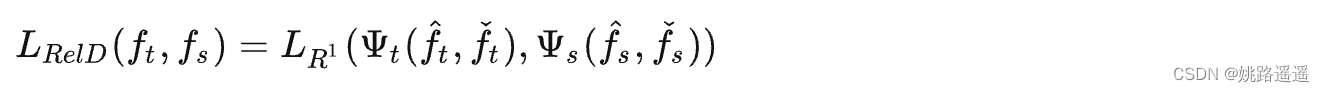
其中,ft和fs分别表示教师模型和学生模型的特征图,ft^、ft 和 fs^、fs~分别是教师模型和学生模型的特征图组(pairs)。函数表示特征组的相似性函数,
传统的知识迁移方法往往涉及到单个知识蒸馏,教师的软目标被直接蒸馏给学生。实际上,蒸馏的知识不仅包含特征信息,还包含数据样本之间的相互关系。这一节的关系涉及许多方面,作者的设计很灵活,建议看原论文更清楚。
3. 蒸馏机制(Distillation Schemes)
根据教师模型是否与学生模型同时更新,知识蒸馏的学习方案可分为离线(offline distillation)蒸馏、在线(online distillation)蒸馏、自蒸馏(self-distillation)。
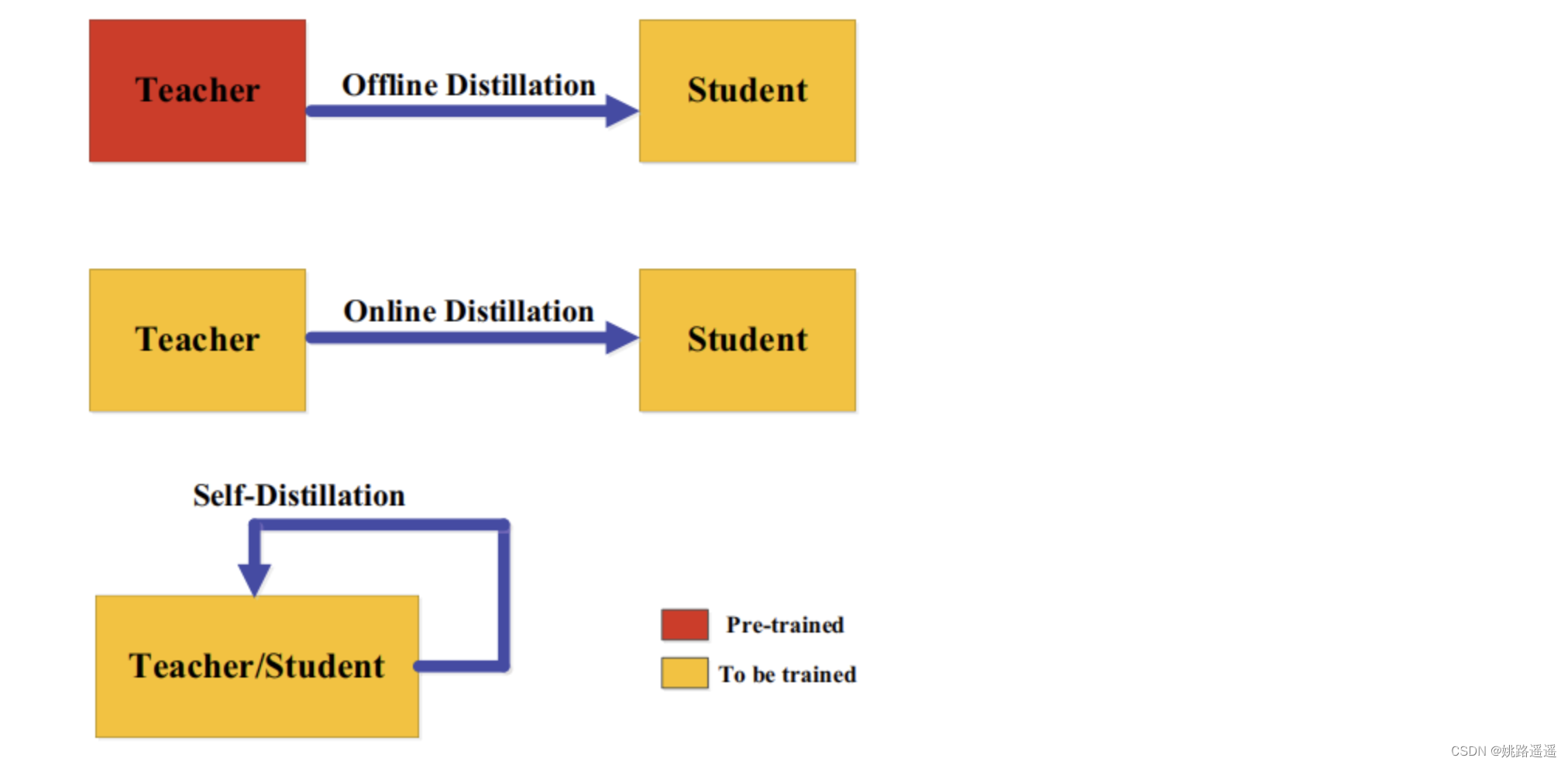
3.1.离线蒸馏(offline distillation)
大多数之前的知识蒸馏方法都是离线的。最初的知识蒸馏中,知识从预训练的教师模型转移到学生模型中,整个训练过程包括两个阶段:1)大型教师模型蒸馏前在训练样本训练;2)教师模型以logits或中间特征的形式提取知识,将其在蒸馏过程中指导学生模型的训练。教师的结构是预定义的,很少关注教师模型的结构及其与学生模型的关系。因此,离线方法主要关注知识迁移的不同部分,包括知识设计、特征匹配或分布匹配的loss函数。离线方法的优点是简单、易于实现。
离线蒸馏方法通常采用单向的知识迁移和两阶段的训练程序。然而,训练时间长的、复杂的、高容量教师模型却无法避免,而在教师模型的指导下,离线蒸馏中的学生模型的训练通常是有效的。此外,教师与学生之间的能力差距始终存在,而且学生往往对教师有极大依赖。
3.2.在线蒸馏(online distillation)
为了克服离线蒸馏的局限性,提出了在线蒸馏来进一步提高学生模型的性能,特别是在没有大容量高性能教师模型的情况下。在线蒸馏时,教师模型和学生模型同步更新,而整个知识蒸馏框架都是端到端可训练的。
在线蒸馏是一种具有高效并行计算的单阶段端到端训练方案。然而,现有的在线方法(如相互学习)通常无法解决在线环境中的高容量教师,这使进一步探索在线环境中教师和学生模式之间的关系成为一个有趣的话题。
3.3.自蒸馏(self-distillation)
在自蒸馏中,教师和学生模型使用相同的网络,这可以看作是在线蒸馏的一个特例。例如论文(Zhang, L., Song, J., Gao, A., Chen, J., Bao, C. & Ma, K. (2019b).Be your own teacher: Improve the performance of convolutional eural networks via self distillation. In ICCV.)将网络深层的知识蒸馏到浅层部分。
从人类师生学习的角度也可以直观地理解离线、在线和自蒸馏。离线蒸馏是指知识渊博的教师教授学生知识;在线蒸馏是指教师和学生一起学习;自我蒸馏是指学生自己学习知识。而且,就像人类学习的方式一样,这三种蒸馏由于其自身的优点,可以相互补充。
4.教师-学生结构(Teacher-Student Architecture)
在知识蒸馏中,师生架构是形成知识转移的一般载体。换句话说,师生结构决定了学生模型提取教师模型中知识的质量,用人类学习过程来描述,就是我们希望学生获得一个不错的老师来获取知识。因此,在知识的提炼过程中,如何选择或设计合适的师生结构,是一个重要而又困难的问题。最近,在蒸馏过程中,教师和学生的模型设置几乎是固定不变的大小和结构,从而容易造成模型容量缺口。然而,如何特别设计教师和学生的体系结构,以及为什么他们的体系结构由这些模型设置决定,几乎是缺失的。两者之间模型的设置主要有以下关系:
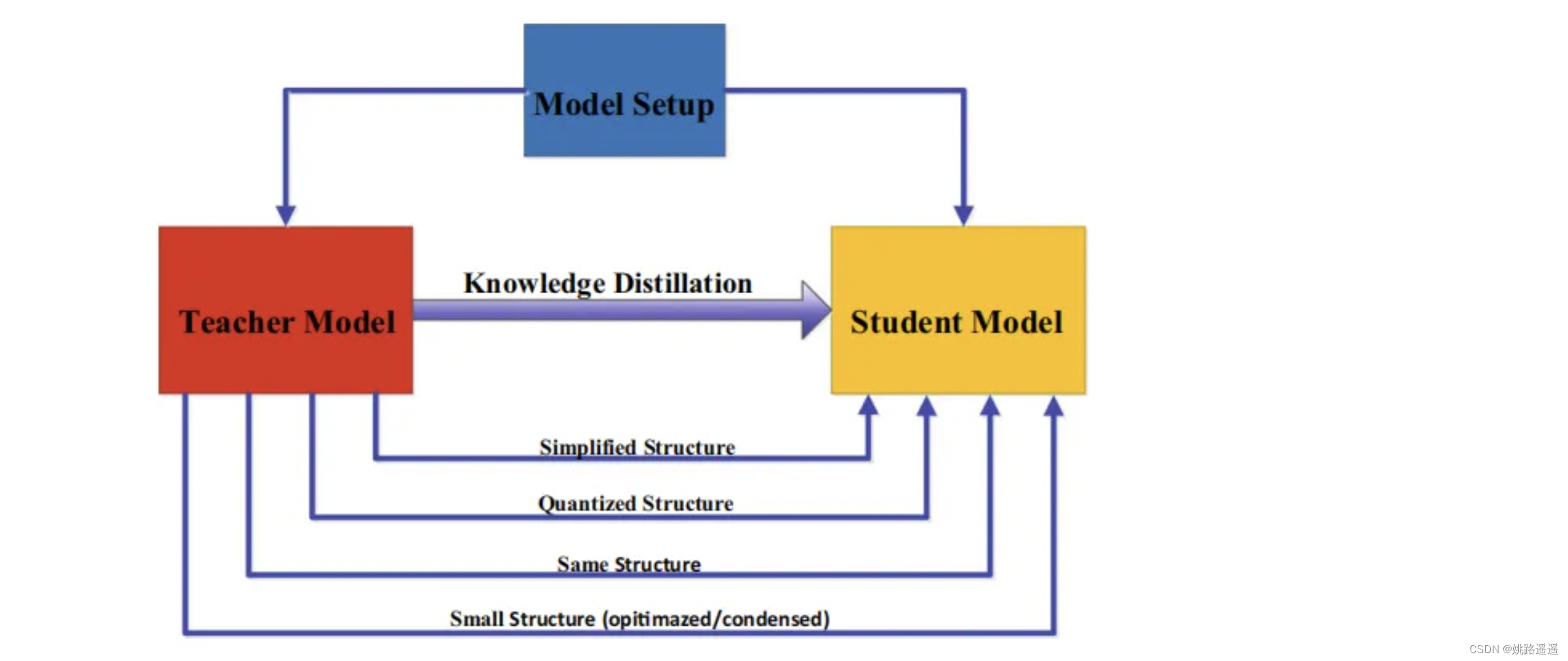
知识蒸馏早期被用来压缩模型,Hinton等人(Hinton, G., Vinyals, O. & Dean, J. (2015). Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531.)曾将知识蒸馏设计为压缩深度神经网络的集合。深度神经网络的复杂性主要来自于深度和宽度这两个维度。通常需要将知识从更深、更宽的神经网络转移到更浅、更窄的神经网络。学生网络的结构通常有以下选择:1)教师网络的简化版本,层数更少,每一层的通道数更少;2)保留教师网络的结构,学生网络为其量化版本;3)具有高效基本运算的小型网络;4)具有优化全局网络结构的小网络;5)与教师网络的结构相同。
大网络和小网络之间容量的差距会阻碍知识的迁移。为了有效地将知识迁移到学生网络中,许多方法被提出来控制降低模型的复杂性。论文(Mirzadeh, S. I., Farajtabar, M., Li, A. & Ghasemzadeh, H. (2020). Improved knowledge distillation via teacher assistant. In AAAI.)引入了一个教师助手,来减少教师模型和学生模型之间的训练差距。另一篇工作通过残差学习进一步缩小差距,利用辅助结构来学习残差。还有其他一些方法关注减小教师模型与学生模型结构上的差异。例如将量化与知识蒸馏相结合,即学生模型是教师模型的量化版本。
以往的研究多侧重于设计师生模型的结构或师生模型之间的知识转移方案。为了使小的学生模型与大的教师模型能够很好地匹配,从而提高知识的蒸馏性能,需要自适应的师生学习结构。近年来,知识蒸馏中的神经结构搜索思想被提出,即在教师模式指导下联合搜索学生结构和知识转移,将成为未来研究的热点。此外,动态搜索知识迁移机制的想法也出现在知识蒸馏中,例如,使用强化学习以数据驱动的方式自动去除冗余层,并寻找给定教师网络的最优学生网络。
5.蒸馏算法
一个简单但有效的知识迁移方法是直接匹配基于响应的、基于特征的或教师模型和学生模型之间的特征空间中的表示分布。许多不同的算法已经被提出,以改善在更复杂的环境中传递知识的过程。
5.1.对抗性蒸馏(Adversarial Distillation)
在知识蒸馏中,教师模型很难学习到真实数据分布,同时,学生模型容量小,不能准确模仿教师模型。近年来,对抗训练在生成网络中取得了成功,生成对抗网络(GAN)中的鉴别器估计样本来自训练数据分布的概率,而生成器试图使用生成的数据样本欺骗鉴别器的概率预测。受此启发,许多对抗知识蒸馏方法被提出,以使教师和学生网络更好地了解真实的数据分布,如下图所示,对抗训练在知识蒸馏中的应用可以刚被分为三类。
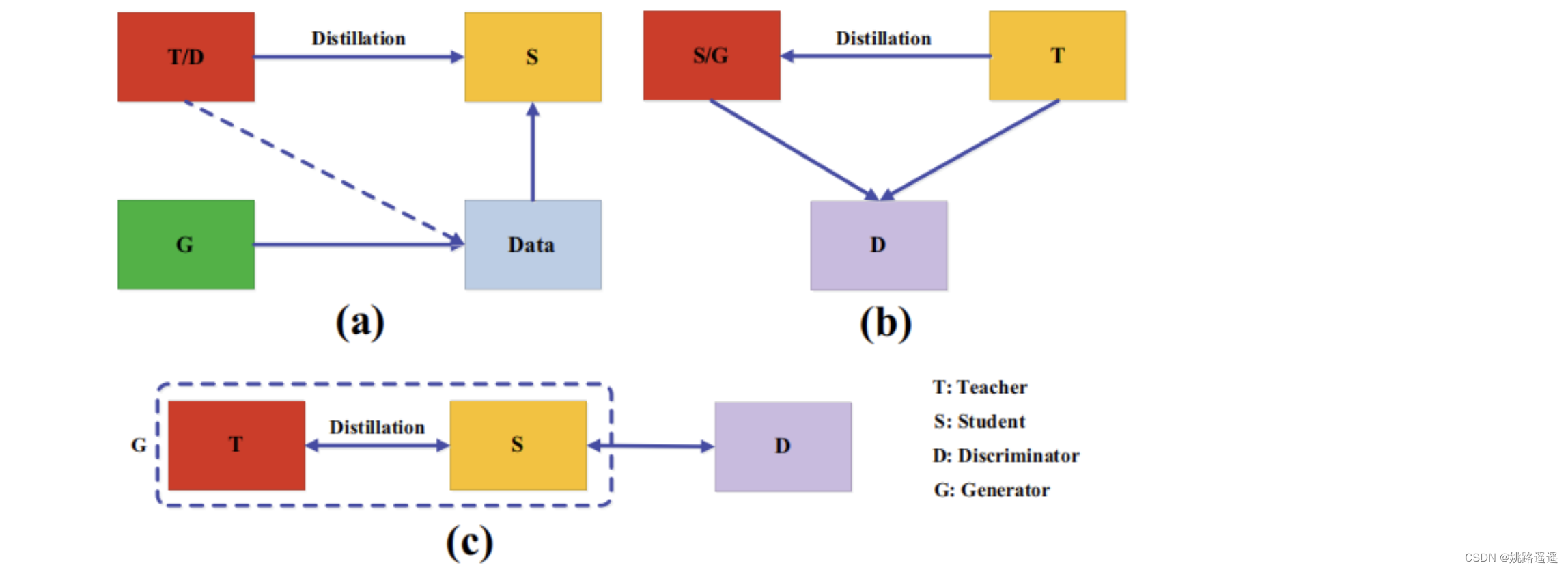
a)训练一个对抗性生成器生成合成的数据,将其直接作为训练集或用于增强训练集。
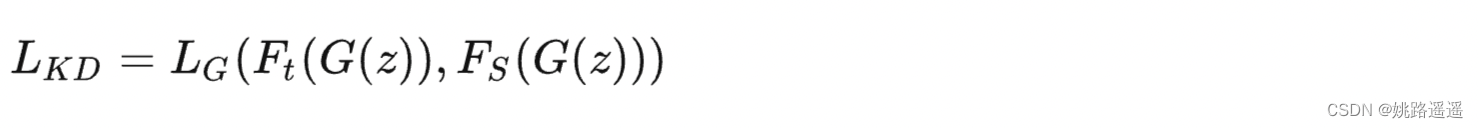
其中,Ft(.)和Fs(.)分别是教师模型和学生模型的输出;G(z)表示给定随机输入向量z的生成器G生成的训练样本;LG是蒸馏损失,以迫使预测的概率分布与真实概率分布之间匹配,蒸馏损失函数通常采用交叉熵或KL散度。
b)使用鉴别器,利用logits或特征来分辨样本来自教师或是学生模型。
代表性方法如论文(Wang, Y., Xu, C., Xu, C. & Tao, D. (2018f). Adversarial learning of portable student networks. In AAAI.),其loss可以表示为:
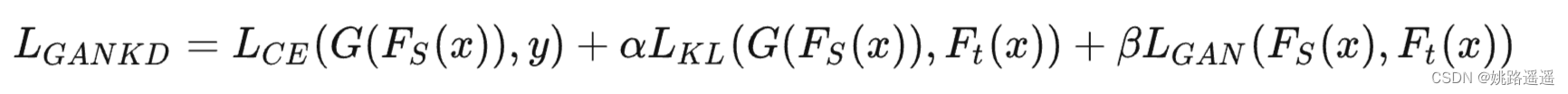
其中,G是一个学生网络,LGAN是生成对抗网络使用的损失函数,使学生和教师之间的输出尽可能相似。
c)在线方式进行,在每次迭代中,教师和学生共同进行优化。
利用知识蒸馏压缩GAN,小GAN学生网络通过知识迁移模仿大GAN教师网络。从上述对抗性蒸馏方法中,可以得出三个主要结论:1)GAN是通过教师知识迁移来提高学生学习能力的有效工具;2)联合GAN和知识蒸馏可以为知识蒸馏的性能生成有价值的数据,克服了不可用和不可访问的数据的限制;3)知识蒸馏可以用来压缩GAN。
5.2.多教师蒸馏(Multi-teacher Distillation)
不同的教师架构可以为学生网络提供他们自己有用的知识。在训练一个教师网络期间,多个教师网络可以单独或整体地用于蒸馏。在一个典型的师生框架中,教师通常是一个大的模型或一个大的模型的集合。要迁移来自多个教师的知识,最简单的方法是使用来自所有教师的平均响应作为监督信息。多教师蒸馏的一般框架如下图所示。
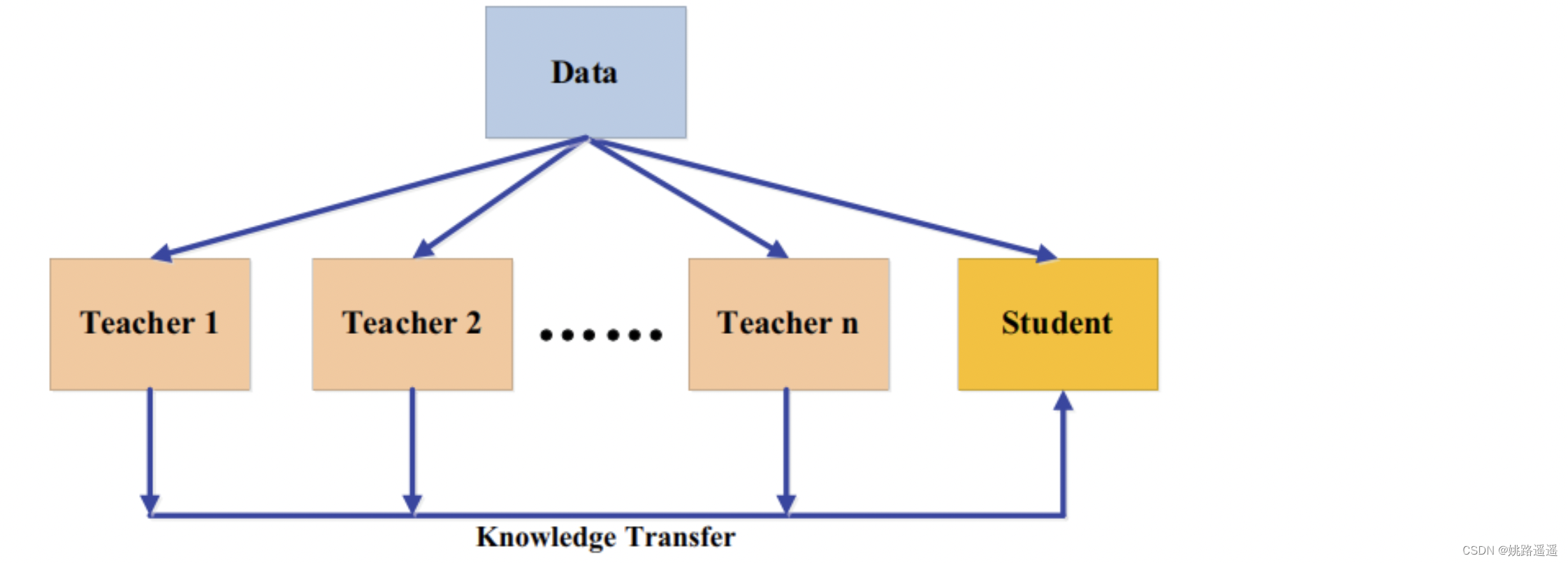
多个教师网络通常使用logits和特征表示作为知识。除了来自所有教师的平均logits,还有其他的变体。文献(Chen, X., Su, J., & Zhang, J. (2019b). A two-teacher tramework for knowledge distillation. In ISNN.)使用了两个教师网络,其中一名教师将基于响应的知识迁移给学生,另一名将基于特征的知识迁移给学生。文献(Fukuda, T., Suzuki, M., Kurata, G., Thomas, S., Cui, J. & Ramabhadran,B. (2017). Effificient knowledge distillation from an ensemble of teachers. In Interspeech.))在每次迭代中从教师网络池中随机选择一名教师。一般来说,多教师知识蒸馏可以提供丰富的知识,并能针对不同教师知识的多样性量身定制一个全方位的学生模型。然而,如何有效地整合来自多名教师的不同类型的知识,还需要进一步研究。
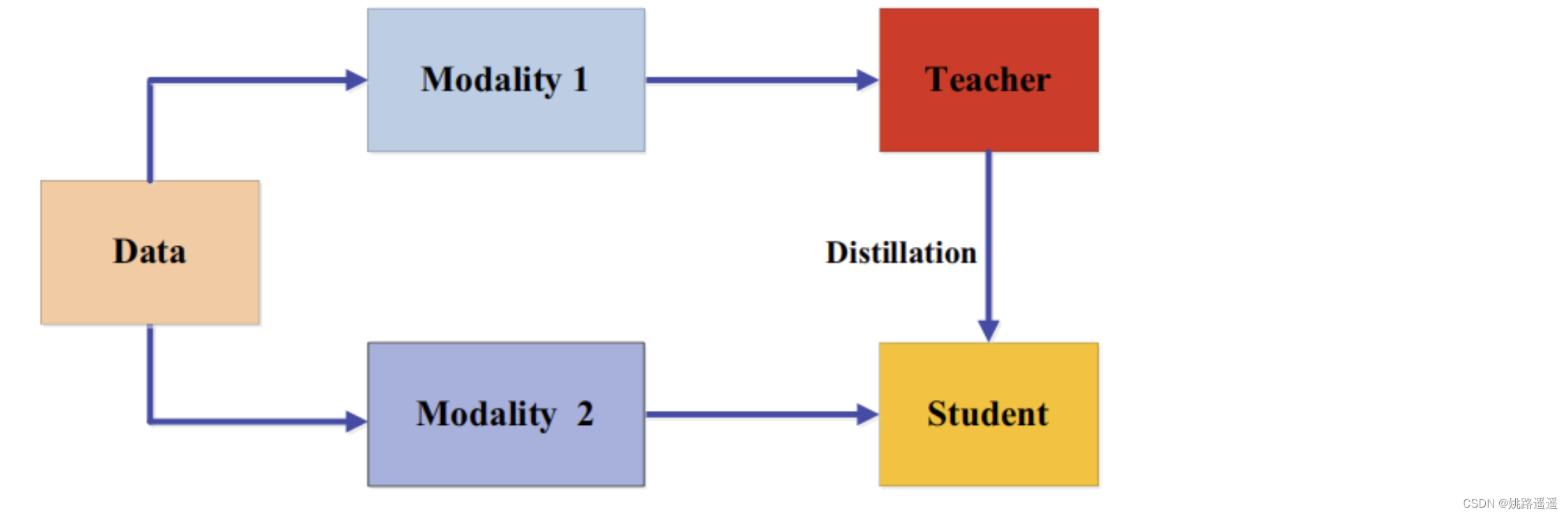
5.3.跨模态蒸馏(Cross-Modal Distillation)
在训练或测试时一些模态的数据或标签可能不可用,因此需要在不同模态间知识迁移。在教师模型预先训练的一种模态(如RGB图像)上,有大量注释良好的数据样本,(Gupta, S., Hoffman, J. & Malik, J. (2016). Cross modal distillation for supervision transfer. In CVPR.)将知识从教师模型迁移到学生模型,使用新的未标记输入模态,如深度图像(depth image)和光流(optical flow)。具体来说,所提出的方法依赖于涉及两种模态的未标记成对样本,即RGB和深度图像。然后将教师从RGB图像中获得的特征用于对学生的监督训练。成对样本背后的思想是通过成对样本迁移标注(annotation)或标签信息,并已广泛应用于跨模态应用。成对样本的示例还有1)在人类动作识别模型中,RGB视频和骨骼序列;2)在视觉问题回答方法中,将图像-问题-回答作为输入的三线性交互教师模型中的知识迁移到将图像-问题作为输入的双线性输入学生模型中。跨模态蒸馏的框架如下:
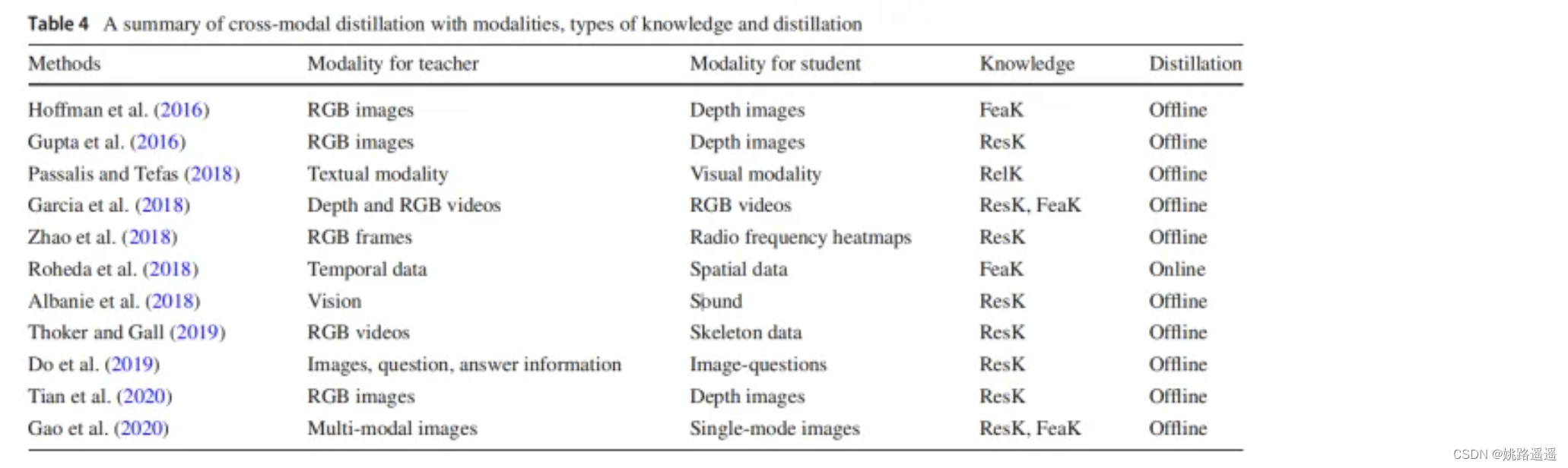
跨模态总结如下。其中ResK表示基于响应的知识,FeaK表示基于特征的知识,RelK表示基于关系的知识。
5.4.基于图的蒸馏(Graph-Based Distillation)
大多数知识蒸馏算法侧重于将个体实例知识从教师传递给学生,而最近提出了一些方法使用图来探索数据内关系。这些基于图的蒸馏方法的主要思想是1)使用图作为教师知识的载体;2)使用图来控制教师知识的传递。基于图的知识可以归类为基于关系的知识。基于图的知识蒸馏如下图所示:
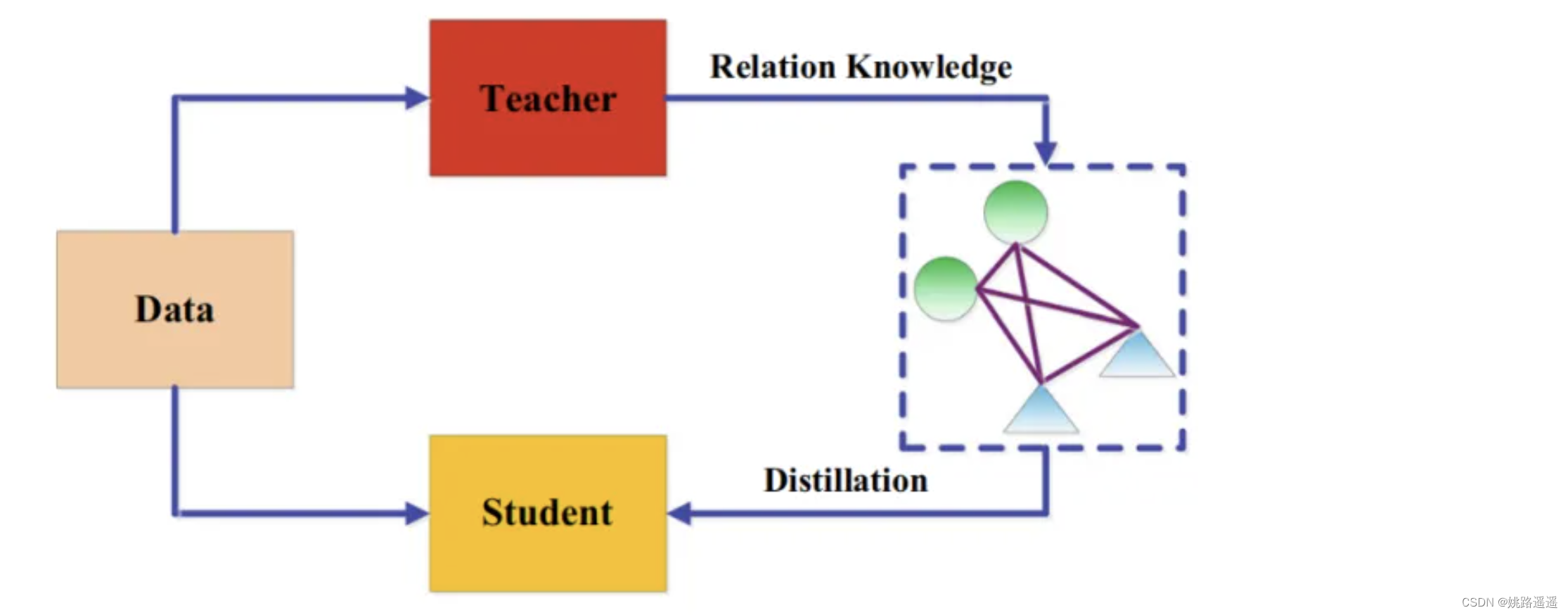
1)使用图作为教师知识的载体
文献(Zhang, C. & Peng, Y. (2018). Better and faster: knowledge transfer from multiple self-supervised learning tasks via graph distillation for video classifification. In IJCAI)中,每个顶点表示一个自监督的教师,利用logits和中间特征构造两个图,将多个自监督的教师的知识转移给学校。
2)使用图来控制知识迁移
文献(Luo, Z., Hsieh, J. T., Jiang, L., Carlos Niebles, J.& Fei-Fei, L. (2018).Graph distillation for action detection with privileged http://modalities.In ECCV.)将模态差异纳入来自源领域的特权信息,特权信息。引入了一种有向图来探讨不同模态之间的关系。每个顶点表示一个模态,边表示一个模态和另一个模态之间的连接强度。
5.5. 基于注意力的蒸馏(Attention-Based Distillation)
注意力机制能够很好地反映神经网络中神经元的激活情况,因此在知识蒸馏中引入了注意力机制,提高了学生模型的性能。基于注意力机制的知识迁移的核心是定义注意力图,将特征嵌入神经网络的各个层次。也就是说,利用注意力图函数转移特征嵌入知识。
5.6.无数据的蒸馏(Data-Free Distillation)
无数据蒸馏的方法提出的背景是克服由于隐私性、合法性、安全性和保密问题导致的数据缺失。“data free”表明并没有训练数据,数据是新生成或综合产生的。新生的数据可以利用GAN来产生。合成数据通常由预先训练过的教师模型的特征表示生成。
尽管无数据蒸馏在数据不可用的情况下显示出了巨大的潜力,但如何生成高质量的多样化训练数据来提高模型的泛化能力仍然是一个非常具有挑战性的任务。
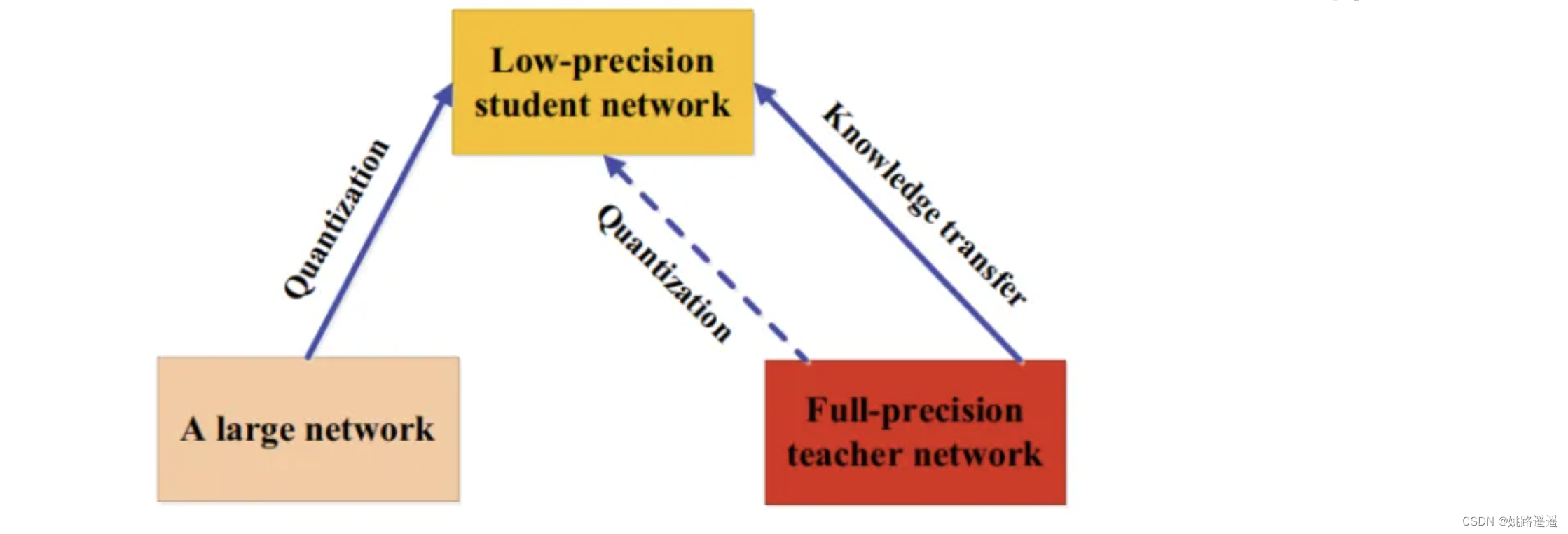
5.7. 量化蒸馏(Quantized Distillation)
网络量化通过将高精度网络(如32位浮点)转换为低精度网络(如2位和8位),降低了神经网络的计算复杂度。同时,知识蒸馏的目标是训练小模型,使其具有与复杂模型相当的性能。在师生框架下,利用量化过程提出了一些KD方法,如下图所示;
5.8.终身蒸馏(Lifelong Distillation)
终身学习包括持续学习、持续学习和元学习,旨在以与人相似的方式学习。它积累了以前学到的知识,并将所学到的知识转化为未来的学习,知识蒸馏提供了一种有效的方法来保存和转移学习到的知识,而不会造成灾难性的遗忘。最近,越来越多的KD变体被开发出来,它们是基于终身学习的。
5.9.基于神经架构搜索的蒸馏(NAS-Based Distillation)
神经架构搜索(NAS),它是最流行的自动机器学习(或AutoML)之一,旨在自动识别深度神经模型和自适应学习合适的深度神经结构。在知识蒸馏中,知识转移的成功不仅取决于教师的知识,还取决于学生的架构。然而,大教师模式和小学生模式之间可能存在能力差距,使得学生很难从老师那里学得好。为了解决这一问题,采用神经结构搜索寻找合适的学生结构。
6.性能比较(Performance Comparison)
为了更好地证明知识蒸馏的有效性,总结了一些典型的KD方法在两种流行的图像分类数据集上的分类性能。这两个数据集分别是CIFAR10和CIFAR100。两者都有50000张训练图像和10000张测试图像,每一类都有相同数量的训练和测试图像。为了进行公平的比较,实验分类精度结果(%)的KD是直接从相应的原始论文中获取,本文报告了在使用不同类型的知识、蒸馏方案和教师/学生模型结构时,不同方法的性能。括号中的准确率是教师模型和学生模型分别训练后的分类结果。
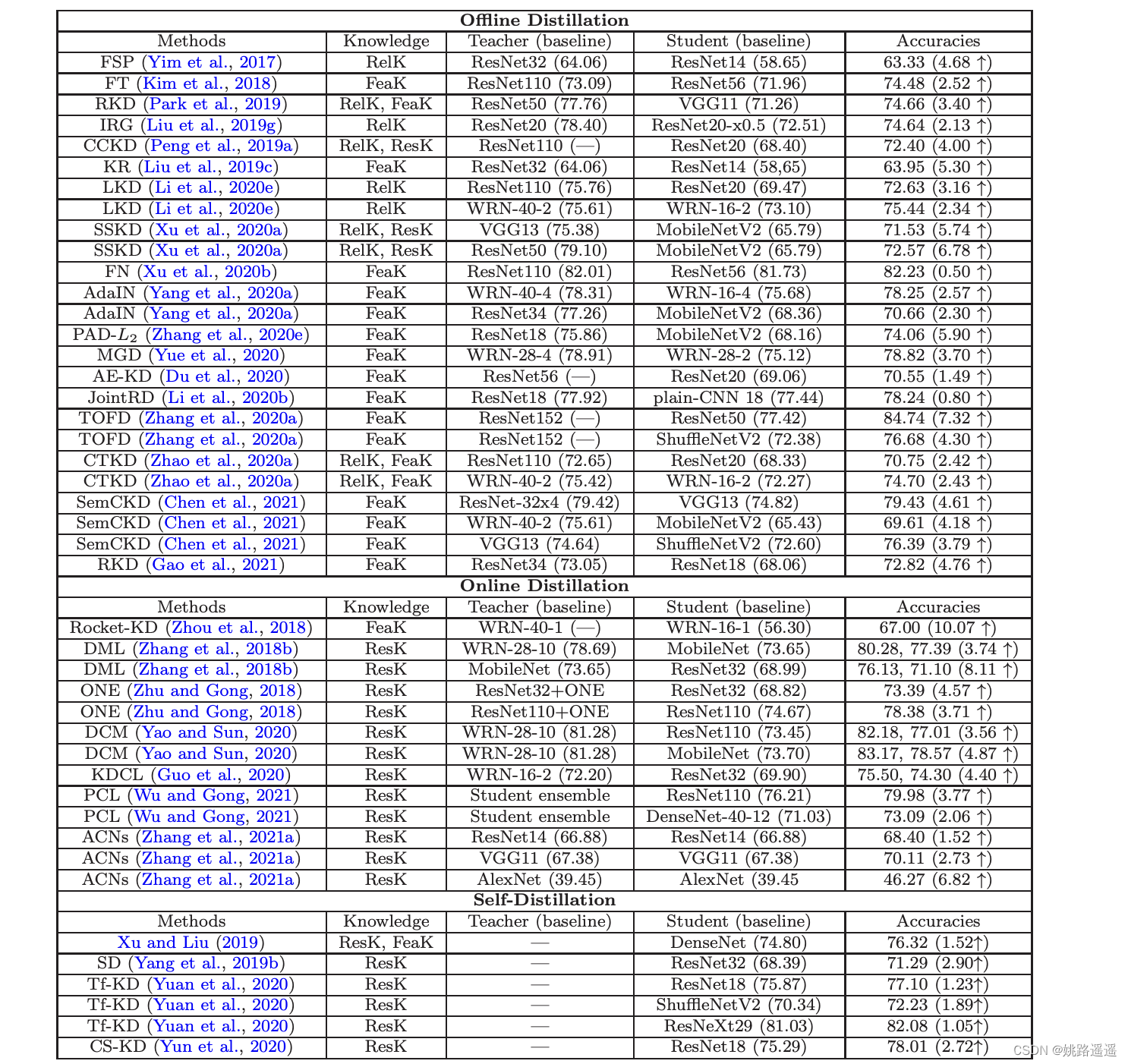
从上表性能比较中,可以总结出以下几点:
- 知识蒸馏可以在不同的深度模型上实现;
- 通过知识蒸馏可以实现不同深度模型的模型压缩 ;
- 基于协作学习的在线知识蒸馏可以显著提高深度模型的性能;
- 自蒸馏可以很好地提高深度模型的性能 ;
- 离线和在线蒸馏方法通常分别传递基于特征的知识和基于响应的知识;
- 通过对高容量教师模型的知识转移,可以提高轻量级深度模型(学生)的性能。
通过对不同知识蒸馏方法的性能比较,可以得出知识蒸馏是一种有效、高效的深度模型压缩技术。
7.应用(Applications)
知识蒸馏作为一种有效的深度神经网络压缩和加速技术,已广泛应用于人工智能的各个领域,包括视觉识别、语音识别、自然语言处理(NLP)和推荐系统。此外,知识蒸馏还可以用于其他目的,如数据隐私和作为对抗攻击的防御。本节简要回顾了知识蒸馏的应用。
KD in NLP
传统的语言模型(如BERT)结构复杂,耗费大量的时间和资源。知识蒸馏是自然语言处理领域中广泛研究的一种方法,其目的是获得轻量级、高效、有效的语言模型。越来越多的KD方法被提出来解决大量的NLP任务。在这些基于KD的NLP方法中,大多数都属于自然语言理解(NLU),其中许多基于自然语言理解的KD方法都被设计成任务特定蒸馏和多任务蒸馏。
以下是自然语言处理中知识蒸馏的一些总结。
- 知识蒸馏提供了高效、有效的轻量级语言深度模型。大容量教师模型可以将大量不同种类的语言数据中丰富的知识转化为小容量学生模型,使学生能够快速有效地完成许多语言任务。
- 考虑到多语言模型中的知识可以相互传递和共享,师生知识转移可以轻松有效地解决多个多语言任务。
- 在深度语言模型中,序列知识可以有效地从大型网络转移到小型网络中
8.总结和讨论(Conclusion and Discussion)
本文从知识、蒸馏方案、师生体系结构、蒸馏算法、性能比较和应用等方面对知识蒸馏进行了综述,下面,主要讨论了知识蒸馏面临的挑战,并对知识蒸馏的未来研究提出了一些见解。
8.1.挑战(Challenges)
- 不同知识来源的重要性,以及他们的整合方式,如何在一个统一的、互补的框架内对不同类型的知识进行建模仍然是一个挑战;
- 为了提高知识转移的有效性,需要进一步研究模型复杂度与现有蒸馏方案或其他新型蒸馏方案之间的关系。
- 如何设计一个有效的学生模型,或者构建一个合适的教师模型,仍然是知识提炼中具有挑战性的问题。 知识蒸馏的可解释性。
尽管知识蒸馏的方法和应用有大量的存在,但对知识蒸馏的理解,包括理论解释和经验评价,仍然不足。教师和学生模型线性化的假设,使得通过蒸馏研究学生学习特征的理论解释成为可能。然而,要深刻理解知识蒸馏的概括性,特别是如何衡量知识的质量或师生建筑的质量,仍然是非常困难的。
8.2.未来方向(Future Directions)
为了提高知识蒸馏的性能,最重要的因素包括:什么样的师生网络架构,从教师网络中学习到什么样的知识,在哪里提炼到学生网络中。
- 在现有的知识蒸馏方法中,讨论知识蒸馏与其他各种压缩方法相结合的相关著作很少;
- 知识蒸馏除了用于深度神经网络加速的模型压缩外,由于师生结构中知识传递的自然特性,知识蒸馏也可用于其他问题。比如,数据隐私、数据扩充、对抗训练和多模态。
相关文章:
【知识蒸馏】知识蒸馏(Knowledge Distillation)技术详解
参考论文:Knowledge Distillation: A Survey 1.前言 近年来,深度学习在学术界和工业界取得了巨大的成功,根本原因在于其可拓展性和编码大规模数据的能力。但是,深度学习的主要挑战在于,受限制于资源容量࿰…...

公司新招了个腾讯5年经验的测试员,让我见识到什么才是真正的测试天花板····
5年测试,应该是能达到资深测试的水准,即不仅能熟练地开发业务,而且还能熟悉项目开发,测试,调试和发布的流程,而且还应该能全面掌握数据库等方面的技能,如果技能再高些的话,甚至熟悉分…...

(一维、二维)数组传参,(一级、二级)指针传参【含样例分析,新手易懂】
目录数组传参一维数组传参二维数组传参指针传参一级指针传参二级指针传参我们在写代码的时候难免要把数组或者指针传给函数,那函数的参数该如何设计呢? 数组传参 一维数组传参 我们首先来看下面代码的几个例子: #include <stdio.h>…...

for循环中的setTimeout以及var let作用域
看了很多解释,感觉都不好理解。这个文章是我自己的理解,可以做个参考,如果我理解的不对,欢迎在评论区指正: var:使用var声明的变量具有全局作用域 (循环中每次声明的是同一个变量) l…...
有限差分法求解不可压NS方程
网上关于有限差分法解NS方程的程序实现不尽完备,这里是一些补充注解 现有的优秀资料 理论向 【1】如何从物理意义上理解NS方程? - 知乎 【2】NS方程数值解法:投影法的简单应用 - 知乎 【3】[计算流体力学] NS 方程的速度压力法差分格式_…...
Android入门第66天-使用AOP
开篇这篇恐怕又是一篇补足网上超9成关于这个领域实际都是错的、用不起来的一个知识点了。网上太多太多教程和案例用的是一个叫hujiang的AOP组件-com.hujiang.aspectjx:gradle-android-plugin-aspectjx。首先这些错的文章我不知道是怎么来的,其次那些案例真的运行成功…...

pl/sql篇之触发器
简述本文將具体简述触发器的语法,触发条件及其适用场景,希望对读者理解,使用触发器能起到作用。触发器的定位触发器是数据库独立编译,存储的对象,是数据库重要的技术。和函数不同,触发器的执行是主动的&…...

黑马《数据结构与算法2023版》正式发布
有人的地方就有江湖。 在“程序开发”的江湖之中,各种技术流派风起云涌,变幻莫测,每一位IT侠客,对“技术秘籍”的追求和探索也从未停止过。 要论开发技术哪家强,可谓众说纷纭。但长久以来,确有一技&#…...
Spring的创建和使用
目录 创建Spring项目 步骤 1)使用Maven的方式创建Spring项目 2)添加Spring依赖 3)创建启动类 存Bean对象 1.创建Bean对象 2.将Bean注册到Spring中 取Bean对象并使用 步骤 1.先得到Spring上下文对象 2.从Spring中获取Bean对象 3.使用Bean ApplicationContext VS Bea…...
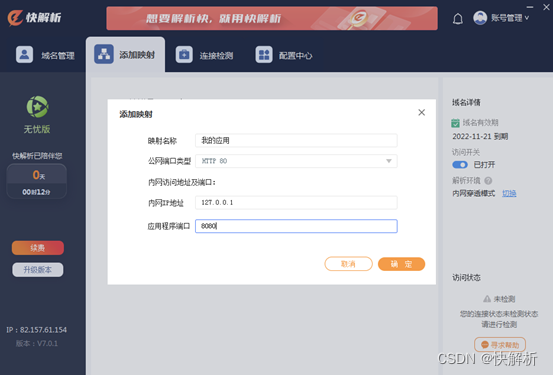
如何实现外网跨网远程控制内网计算机?快解析来解决
远程控制,是指管理人员在异地通过计算机网络异地拨号或双方都接入Internet等手段,连通需被控制的计算机,将被控计算机的桌面环境显示到自己的计算机上,通过本地计算机对远方计算机进行配置、软件安装程序、修改等工作。通俗来讲&a…...

【跟着ChatGPT学深度学习】ChatGPT教我文本分类
【跟着ChatGPT学深度学习】ChatGPT教我文本分类 ChatGPT既然无所不能,我为啥不干脆拜他为师,直接向他学习,岂不是妙哉。说干就干,我马上就让ChatGPT给我生成了一段文本分类的代码,不看不知道,一看吓一跳&am…...

IM即时通讯架构技术:可靠性、有序性、弱网优化等
消息的可靠性是IM系统的典型技术指标,对于用户来说,消息能不能被可靠送达(不丢消息),是使用这套IM的信任前提。 换句话说,如果这套IM系统不能保证不丢消息,那相当于发送的每一条消息都有被丢失的…...

【算法】三道算法题两道难度中等一道困难
算法目录只出现一次的数字(中等难度)java解答参考二叉树的层序遍历(难度中等)java 解答参考给表达式添加运算符(比较困难)java解答参考大家好,我是小冷。 上一篇是算法题目 接下来继续看下算法题…...
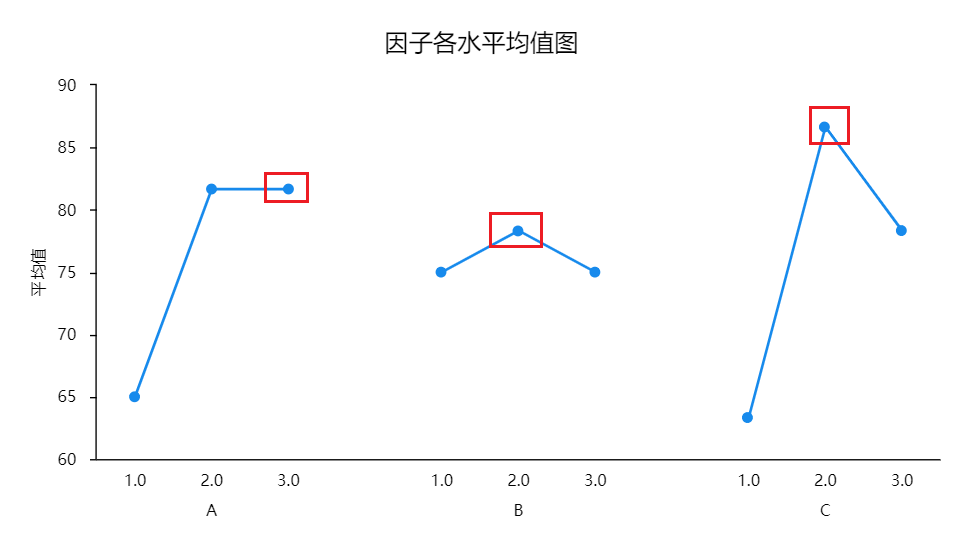
正交实验与极差分析
正交试验极差分析流程如下图: 正交试验说明 正交试验是研究多因素试验的设计方法。对于多因素、多水平的实验要求,如果每个因素的每个水平都要进行试验,这样就会耗费大量的人力和时间,正交试验可以选择出具有代表性的少数试验进行…...
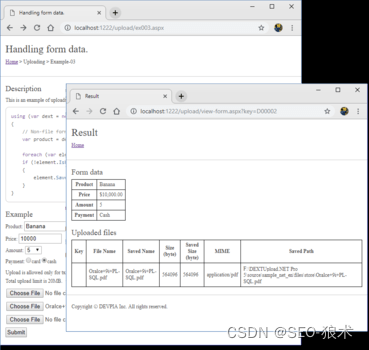
DEXTUpload .NET增强的上传速度和可靠性
DEXTUpload .NET增强的上传速度和可靠性 DEXTUpload.NET Pro托管在Windows操作系统上的Internet Information Server(IIS)上,服务器端组件基于HTTP协议,支持从web浏览器到web服务器的文件上载。它也可以在ASP.NET服务器应用程序平台开发的任何网站上使用…...
)
SkyWalking 将方法加入追踪链路(@Trace)
SkyWalking8 自定义链路追踪@Trace 自定义链路,需要依赖skywalking官方提供的apm-toolkit-trace包.在pom.xml的dependencies中添加如下依赖: <dependency><groupId>org.apache.skywalking</groupId><artifactId>apm-toolkit-trace</artifactId>&…...
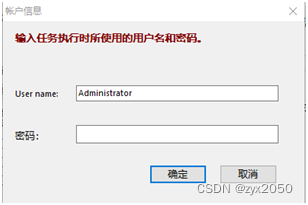
MySQL Administrator定时备份MySQL数据库
1、下载并安装软件mysql-gui-tools-5.0-r17-win32.exe 2、将汉化包zh_CN文件夹拷贝到软件安装目录 3、菜单中打开MySql Adminstrator,见下图,初次打开无服务实例。 点击已存储连接右侧按钮①,打开下图对话框。点击“新连接”按钮ÿ…...

Kubernetes入门教程 --- 使用二进制安装
Kubernetes入门教程 --- 使用二进制安装1. Introduction1.1 架构图1.2 关键字介绍1.3 简述2. 使用Kubeadm Install2.1 申请三个虚拟环境2.2 准备安装环境2.3 配置yum源2.4 安装Docker2.4.1 配置docker加速器并修改成k8s驱动2.5 时间同步2.6 安装组件3. 基础知识3.1 Pod3.2 控制…...

深度学习模型压缩方法概述
一,模型压缩技术概述 1.1,模型压缩问题定义 因为嵌入式设备的算力和内存有限,因此深度学习模型需要经过模型压缩后,方才能部署到嵌入式设备上。 模型压缩问题的定义可以从 3 角度出发: 模型压缩的收益: 计算: 减少浮点运算量(FLOPs),降低延迟(Latency)存储: 减少内…...

《NFL橄榄球》:坦帕湾海盗·橄榄1号位
坦帕湾海盗(英语:Tampa Bay Buccaneers)是一支位于佛罗里达州的坦帕湾职业美式橄榄球球队。他们是全国橄榄球联盟的南区其中一支球队。在1976年,与西雅图海鹰成为NFL的球队。球队在最初的两个球季连败26场,在二十世纪七…...

终结拟合式智能:记忆博弈心智架构重塑硅基生命进化逻辑
当前全球AGI研发赛道,正陷入一场难以破局的同质化内卷。无论是头部科技企业的超大参数模型,还是轻量化垂直AI产品,核心底层始终沿用Transformer概率拟合逻辑。这套技术体系虽然实现了人工智能的规模化落地,却从根源上锁死了AI的智…...

GitHub资源精准下载:3分钟掌握DownGit的完整使用指南
GitHub资源精准下载:3分钟掌握DownGit的完整使用指南 【免费下载链接】DownGit github 资源打包下载工具 项目地址: https://gitcode.com/gh_mirrors/dow/DownGit 还在为下载GitHub上单个文件而烦恼吗?DownGit是你的终极解决方案!这个…...

手机提取OTA镜像文件:无需电脑的Android系统镜像提取终极指南
手机提取OTA镜像文件:无需电脑的Android系统镜像提取终极指南 【免费下载链接】Payload-Dumper-Android Payload Dumper App for Android. Extract boot.img or any other partitions (images) from OTA.zip or payload.bin without PC 项目地址: https://gitcode…...

K8s集群健康监控、Pod调度与配置存储卷
33.Kubernets对集群Pod和健康容器状态如何进行监控和检测的。 K8s通过kubelet节点监控,使用三种探针来监控和管理容器监控状态,每种探针在容器生命周期种的不同阶段发挥不同的作用。 34.解释LivenessProbes探针的作用及其适用场景。 LivenessProbes存活探…...

后端开发必知的数据库优化技巧:这5个方法让你的系统性能提升10倍
对于软件测试从业者来说,理解数据库优化逻辑不仅能帮我们更快定位性能瓶颈,还能让我们在测试阶段就提前发现潜在的数据库设计问题,避免上线后出现大规模性能故障。很多测试同学往往把注意力放在接口逻辑、功能正确性上,却忽略了数…...

Go Web中间件机制深度剖析与实战
Go Web中间件机制深度剖析与实战 引言 中间件(Middleware)是Web开发中的核心概念,它在请求处理链路中扮演着至关重要的角色。本文将深入探讨Go语言中中间件的实现机制,并通过实战案例展示如何构建可复用的中间件系统。 一、中间件…...

iOS自动化测试真机连接失败的五大根因与工程化解决方案
1. 为什么iOS自动化测试总卡在“连不上真机”这一步? Appium做iOS自动化,标题里写“全网最详细”,不是吹牛,是踩过太多坑之后的实话。我带过三支测试团队,从2018年用Xcode 9配Appium 1.8开始,到今天Xcode 1…...
/打印1-100直接3倍数的数字/两个数最大公约数(最小公倍数))
C语言学习笔记20260522—交换两个整数的值(地址传递)/打印1-100直接3倍数的数字/两个数最大公约数(最小公倍数)
一.知识点 函数需要改变实参时,必要要用地址传递,不能用值传递。当一个数%比自己大的数是,%的值就是自己本身。数辗转相除法(欧几里得算法)求两个数的最大公约数。两个数的最小公倍数为两个数的乘积除以最大公约数。 二…...

trae 提示 测到模型循环,请求已被中断。请重试或新建任务。怎么处理?
这个提示是 Trae 的防死循环保护机制,核心原因是:模型陷入了「重复执行无效操作 → 无法推进任务 → 又重复执行」的循环,系统主动中断请求,避免资源浪费和任务卡死。下面给你拆解常见原因和对应的解决办法,按从高到低…...

数据缺失处理实战指南:从原理到应用,掌握KNN与MICE填补技术
1. 项目概述:数据缺失,一个绕不开的“坑”做数据分析、机器学习或者任何和数据打交道的工作,你大概率都遇到过这种情况:打开数据集,满怀期待地准备大干一场,结果发现好几列数据里都夹杂着刺眼的“NaN”、“…...