HSN:微调预训练ViT用于目标检测和语义分割,华南理工和阿里巴巴联合提出
今天跟大家分享华南理工大学和阿里巴巴联合提出的将ViT模型用于下游任务的高效微调方法HSN,该方法在迁移学习、目标检测、实例分割、语义分割等多个下游任务中表现优秀,性能接近甚至在某些任务上超越全参数微调。

- 论文标题:Hierarchical Side Tuning for Vision Transformers
- 机构:华南理工大学、阿里巴巴
- 论文地址:https://arxiv.org/pdf/2310.05393.pdf
- 代码地址(即将开源):https://github.com/AFeng-x/HST#hierarchical-side-tuning-for-vision-transformers
- 关键词:Vision Transformer、迁移学习、目标检测、实例分割、语义分割
1.动机
近年来,大规模的Vision Transformer(简称ViT)在多个任务中表现优秀,很多研究人员尝试利用ViT中的预训练知识提升下游任务的性能。然而,快速增长的模型规模使得在开发下游任务时直接微调预训练模型变得不切实际。 Parameter-efficient transfer learning(简称PETL)方法通过选择预训练模型的参数子集或在主干中引入有限数量的可学习参数,同时保持大部分原始参数不变,来解决该问题。
尽管PETL方法取得了重大成功,但主要是为识别任务而设计的。当将其用于密集预测任务时(比如目标检测和分割),与完全的微调相比其性能仍有很大的差距,这可能是由于密集预测任务与分类任务有本质上的不同。为了解决这一性能差距,作者提出了一种更通用的PETL方法Hierarchical Side-Tuning(简称HST),作者构建了Hierarchical Side Network(简称HSN),能产生金字塔式的多尺度输出,使得整个模型能适应不同的任务。
2.Hierarchical Side-Tuning(HST)
2.1 HST总体结构
HST的总体结构如下图所示:
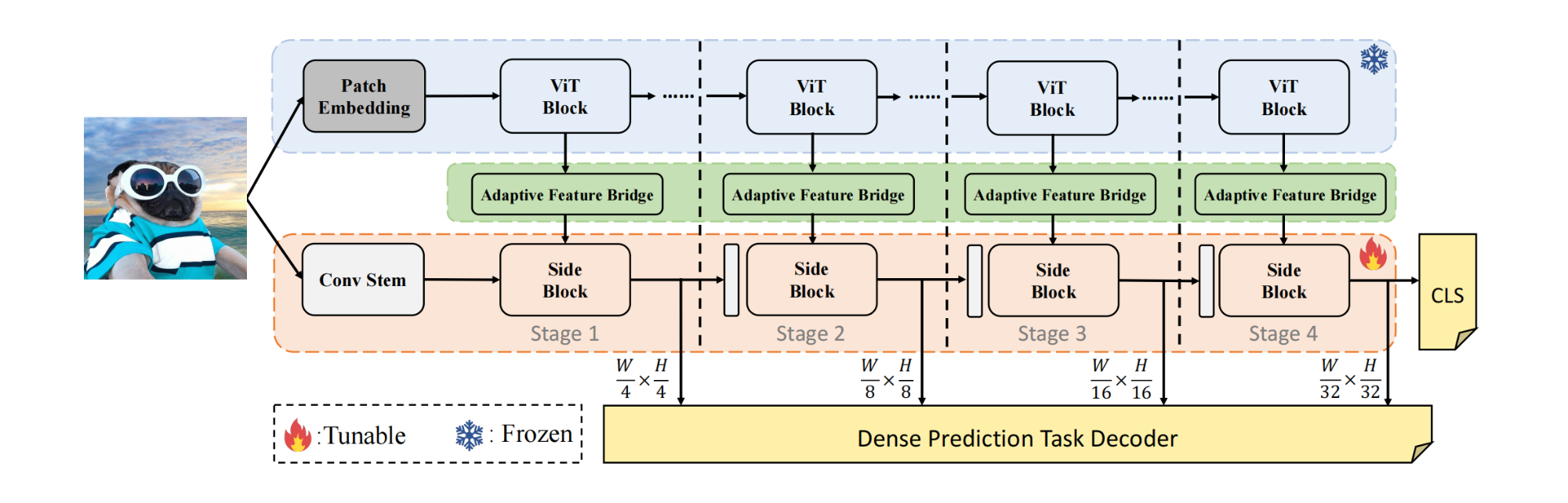
上图中蓝色部分为普通的ViT,其权重被冻结;绿色部分为Adaptive Feature Bridge(简称AFB),用于桥接和预处理中间特征;粉色部分是Hierarchical Side Network(简称HSN),由1个Conv Stem和 L L L个Side Block组成。
对于ViT部分,输入图像首先通过patch embedding,然后进入 L L L个Transformer encoder;对于HSN部分,输入图像通过Conv Stem,从输入图像中引入局部空间上下文信息。HSN由4个stage组成,下采样率分别为 { 4 , 8 , 16 , 32 } \{4,8,16,32\} {4,8,16,32},输出4种不同尺度的特征。每个Transformer encoder都有1个对应的Side Block,信息流从backbone流向Side Block。
2.2 Meta Token
与其他prompt-based的微调方法不同,作者令prompt的数量为1,并将其称作Meta Token(简称MetaT),其结构如下图所示:

作者并没有丢弃prompt对应的输出特征,而是将其与输出的patch token一起作为Adaptive Feature Bridge的输入。由于MetaT的输出特征分布与patch token的分布有差异,这会影响HSN的性能,因此要微调Transformer中的Layer Normalization(简称LN)层,以改变特征的均值和方差(即改变了特征分布),有助于保持同一样本中不同特征之间的相对值。下图展示了MetaT的输出特征与ViT中patch token之间的余弦相似度,显然,通过微调LN层,MetaT的输出与patch token的向量方向能更好地对齐,从而有效地利用MetaT的输出特征。

2.3 Adaptive Feature Bridge(AFB)
由于ViT的输出特征与HSN中的特征形状不同,因此引入了Adaptive Feature Bridge(AFB),AFB包括2个重要部分:双分支分离(Dual-Branch Separation)和权重共享(Linear Weight Sharing),如下图所示:

Dual-Branch Separation
MetaT的输出和patch token先经过线性层进行维度变换,线性层的输出分为2个分支,patch token进行全局平均池化输出1个token,将其称作GlobalT,GlobalT与MetaT拼接得到 F m g i \mathcal{F}_{m g}^i Fmgi。通过双线性差值改变patch token的形状,使其与HSN中对应stage的特征形状一致。整体流程表示如下:
F m g i = [ W j F MetaT i , AvgPooling ( W j F patch i ) ] ; F f g i = T ( W j F v i t i ) \mathcal{F}_{m g}^i=\left[W_j \mathcal{F}_{\text {MetaT }}^i, \operatorname{AvgPooling}\left(W_j \mathcal{F}_{\text {patch }}^i\right)\right] ; \mathcal{F}_{f g}^i=\mathcal{T}\left(W_j \mathcal{F}_{v i t}^i\right) Fmgi=[WjFMetaT i,AvgPooling(WjFpatch i)];Ffgi=T(WjFviti)
上式中 i i i表示第 i i i个Vit block, W j W_j Wj表示第 j j j个stage中线性层的权重矩阵。
Linear Weight Sharing
同一个stage中的多个AFB共享线性层权重,以减少可学习参数;此外,这样能在同一个stage中实现特征间的信息交互,达到与使用多个线性层相当的效果。
2.4 Side Block
Side Block包含1个cross-attention层和1个Feed-Forward Network(简称FFN),其结构如下图所示。

Side Block对ViT的中间特征和多尺度特征进行建模,考虑到这两个输入分支的特点,作者通过不同的方法将它们引入到Side Block中。
Meta-Global Injection
将HSN输出的多尺度特征作为Query(记作 Q Q Q),使用meta-global token作为key(记作 K K K)和value(记作 V V V),cross-attention表示如下:
( ( Q h s n ) ( K m g ) T ) V m g = A V m g \left(\left(Q_{h s n}\right)\left(K_{m g}\right)^T\right) V_{m g}=A V_{m g} ((Qhsn)(Kmg)T)Vmg=AVmg
上式中 Q h s n ∈ R L × d Q_{h s n} \in \mathbb{R}^{L \times d} Qhsn∈RL×d, ( K m g ) T ∈ R d × M \left(K_{m g}\right)^T \in \mathbb{R}^{d \times M} (Kmg)T∈Rd×M, V m g ∈ R M × d V_{m g} \in \mathbb{R}^{M \times d} Vmg∈RM×d, L L L表示多尺度特征输入序列的长度, M M M表示meta-global token的长度, d d d表示特征维度。
将Meta-Global Injection的输出记作 F ^ h s n i \hat{F}_{h s n}^i F^hsni,可表示如下:
F ^ h s n i = F h s n i + CrossAttention ( F h s n i , F m g i ) \hat{\mathcal{F}}_{h s n}^i=\mathcal{F}_{h s n}^i+\operatorname{CrossAttention}\left(\mathcal{F}_{h s n}^i, \mathcal{F}_{m g}^i\right) F^hsni=Fhsni+CrossAttention(Fhsni,Fmgi)
上式中 i i i表示HST和ViT的第 i i i个block。
Fine-Grained Injection
将Meta-Global Injection的输出 F ^ h s n i \hat{F}_{h s n}^i F^hsni与 F f g i F_{f g}^i Ffgi进行元素相加,然后使用FFN进行建模,表示如下:
F h s n i + 1 = F ^ h s n i + F f g i + FFN ( F ^ h s n i + F f g i ) F_{h s n}^{i+1}=\hat{F}_{h s n}^i+F_{f g}^i+\operatorname{FFN}\left(\hat{F}_{h s n}^i+F_{f g}^i\right) Fhsni+1=F^hsni+Ffgi+FFN(F^hsni+Ffgi)
F h s n i + 1 F_{h s n}^{i+1} Fhsni+1作为下一个Side Block的输入。
3.实验
3.1 实验设置


3.2 实验结果
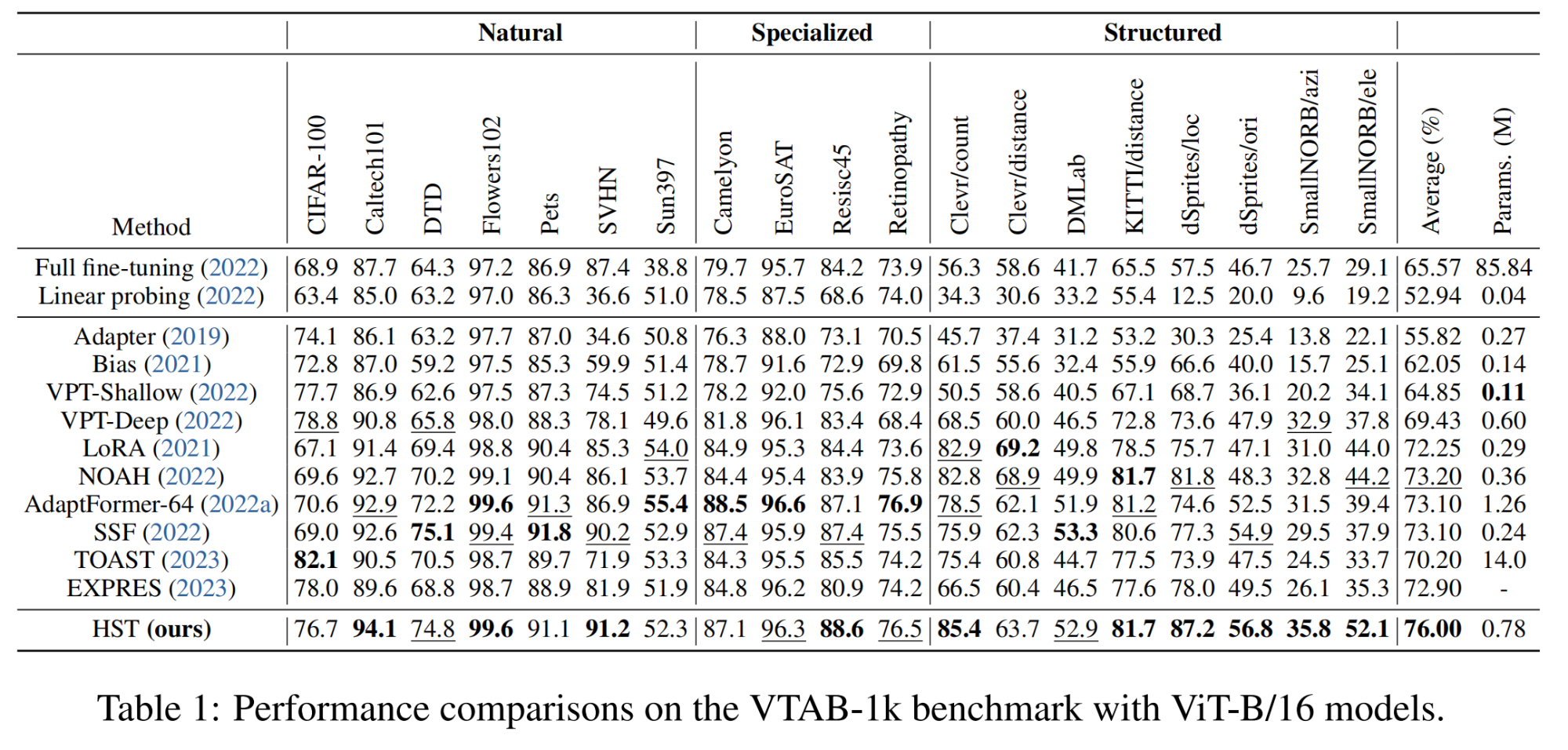
(1)图像分类
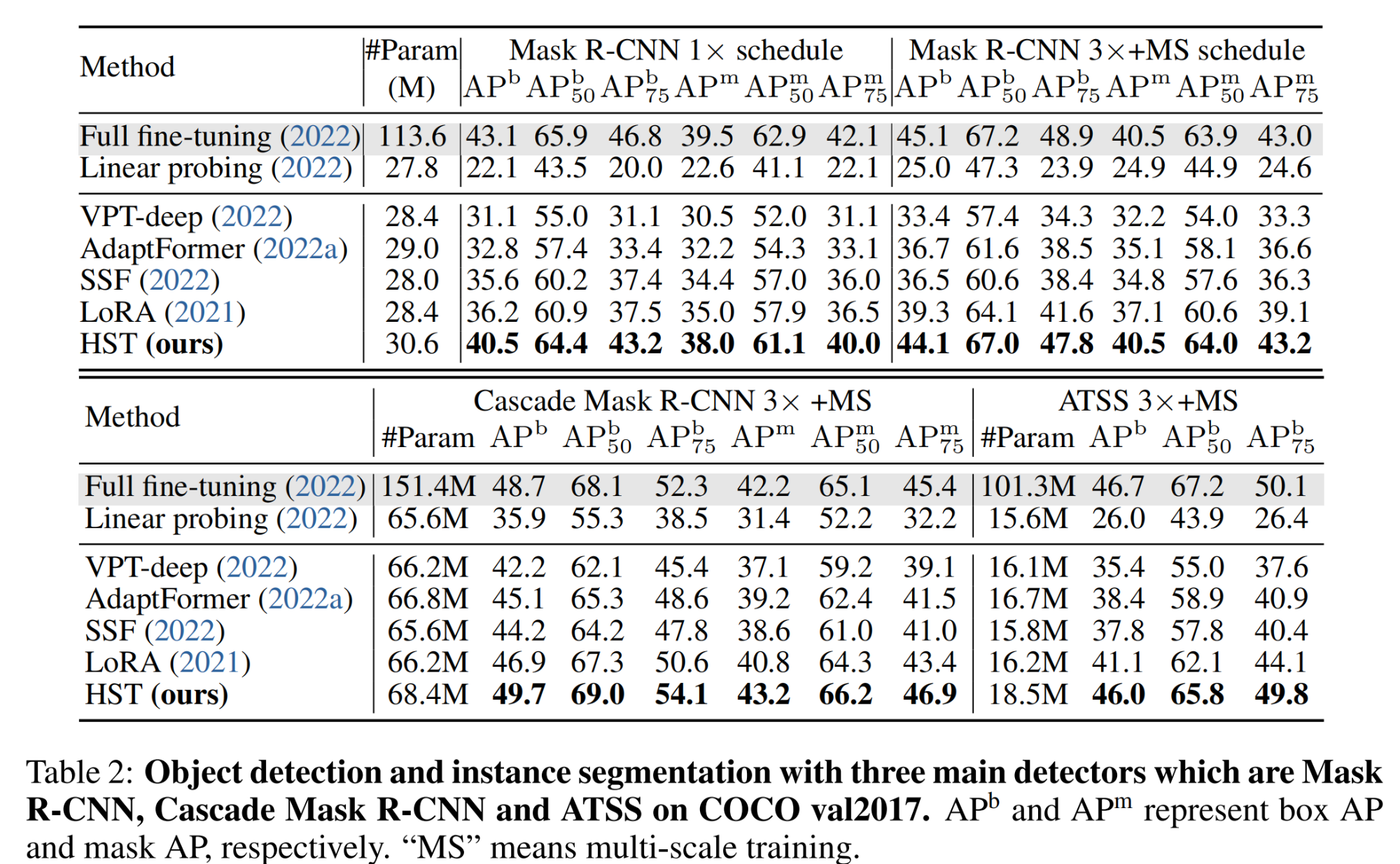
(2)目标检测和实例分割
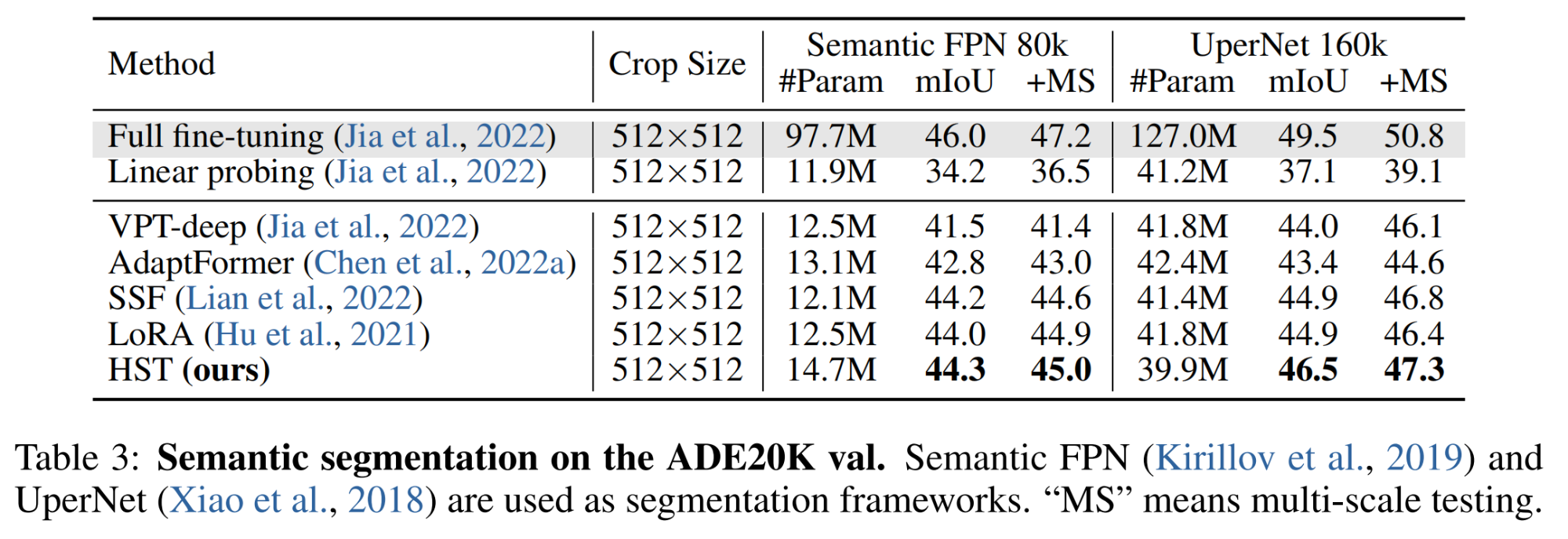
(3)语义分割
更多消融实验及分析请查看原文。
4.总结
作者提出了一种新的参数高效的迁移学习方法Hierarchical Side-Tuning(HST),可训练的side network利用了backbone的中间特征,并生成了用于进行预测的多尺度特性。通过实验表明,HST在不同的数据集和任务中表现优异,显著地减少了在密集预测任务中PETL与完全微调的性能差距。
相关文章:
HSN:微调预训练ViT用于目标检测和语义分割,华南理工和阿里巴巴联合提出
今天跟大家分享华南理工大学和阿里巴巴联合提出的将ViT模型用于下游任务的高效微调方法HSN,该方法在迁移学习、目标检测、实例分割、语义分割等多个下游任务中表现优秀,性能接近甚至在某些任务上超越全参数微调。 论文标题:Hierarchical Side…...
机器学习的原理是什么?
训过小狗没? 没训过的话总见过吧? 你要能理解怎么训狗,就能非常轻易的理解机器学习的原理. 比如你想教小狗学习动作“坐下”一开始小狗根本不知道你在说什么。但是如果你每次都说坐下”然后帮助它坐下,并给它一块小零食作为奖励,经过多次…...

Java集合框架之ArrayList源码分析
文章目录 简介ArrayList底层数据结构初始化集合操作追加元素插入数据删除数据修改数据查找 扩容操作总结 简介 ArrayList是Java提供的线性集合,本篇笔记将从源码(java SE 17)的角度学习ArrayList: 什么是ArrayList?ArrayList底层数据结构是…...
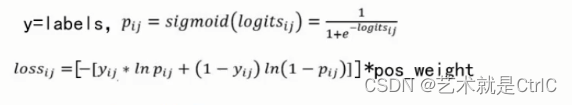
TensorFlow入门(二十、损失函数)
损失函数 损失函数用真实值与预测值的距离指导模型的收敛方向,是网络学习质量的关键。不管是什么样的网络结构,如果使用的损失函数不正确,最终训练出的模型一定是不正确的。常见的两类损失函数为:①均值平方差②交叉熵 均值平方差 均值平方差(Mean Squared Error,MSE),也称&qu…...

MySQL中死锁
数据库的死锁是指不同的事务在获取资源时相互等待,导致无法继续执行的一种情况。当发生死锁时,数据库会自动中断其中一个事务,以解除死锁。在数据库中,事务可以分为读事务和写事务。读事务只需要获取读锁,而写事务需要…...

【LeetCode刷题(数据结构)】:给定一个链表 每个节点包含一个额外增加的随机指针 该指针可以指向链表中的任何节点或空节点 要求返回这个链表的深度拷贝
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点 构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next…...

uniapp封装loading 的动画动态加载
实现效果 html代码 <view class"loadBox" v-if"loading"><img :src"logo" class"logo"> </view> css代码 .loadBox {width: 180rpx;min-height: 180rpx;border-radius: 50%;display: flex;align-items: center;j…...
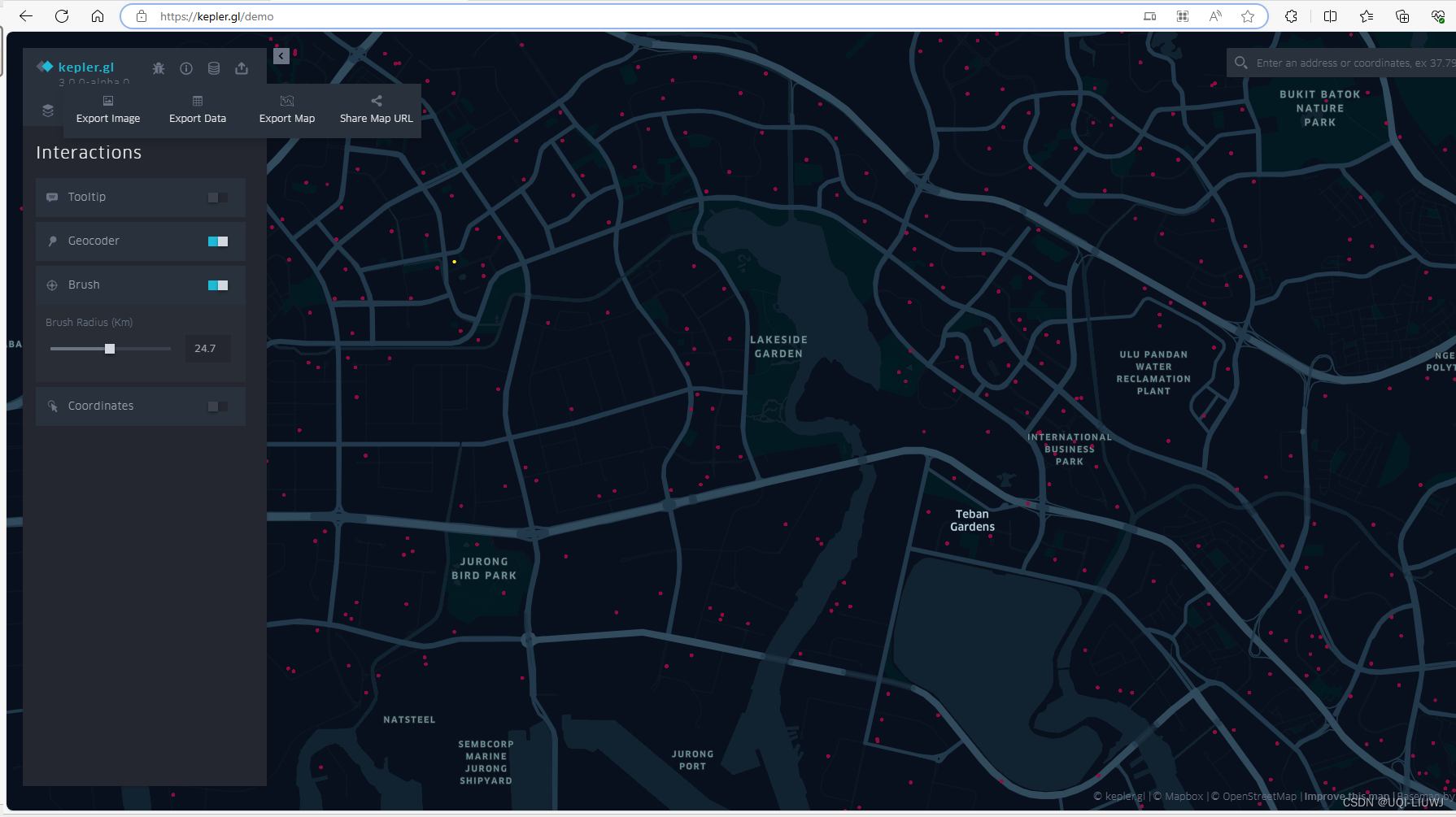
Kopler.gl笔记:可视化功能总览
1 添加数据 2 添加图层 打开“数据层”菜单,开始可视化。 层(Layers)简单来说就是可以相互叠加的数据可视化。 3 添加过滤器 在地图上添加过滤器以限制显示的数据。过滤器必须基于数据集中的列。要创建新的过滤器,打开“过滤器…...

rust学习Cell、RefCell、OnceCell
背景 Rust 内存安全基于以下规则:给定一个对象 T,它只能具有以下之一: 对对象有多个不可变引用 (&T)(也称为别名 aliasing)对对象有一个可变引用 (&mut T)(也称为可变性 mutability)这是由 Rust 编译器强制执行的。然而,在某些情况下,该规则不够灵活(this r…...
基于SSM的摄影约拍系统
基于SSM的摄影约拍系统的设计与实现 开发语言:Java数据库:MySQL技术:SpringSpringMVCMyBatisJSP工具:IDEA/Ecilpse、Navicat、Maven 【主要功能】 前台系统:首页拍摄作品展示、摄影师展示、模特展示、文章信息、交流论…...
分析智能平台VMware Greenplum 7 正式发布!
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...
动态规划算法(3)--0-1背包、石子合并、数字三角形
目录 一、0-1背包 1、概述 2、暴力枚举法 3、动态规划 二、石子合并问题 1、概述 2、动态规划 3、环形石子怎么办? 三、数字三角形问题 1、概述 2、递归 3、线性规划 四、租用游艇问题 一、0-1背包 1、概述 0-1背包:给定多种物品和一个固定…...
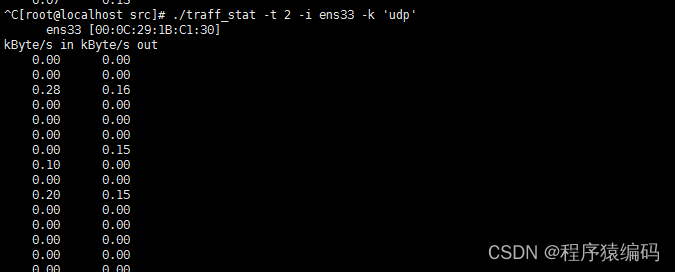
Linux C/C++ 嗅探数据包并显示流量统计信息
嗅探数据包并显示流量统计信息是网络分析中的一种重要技术,常用于网络故障诊断、网络安全监控等方面。具体来说,嗅探器是一种可以捕获网络上传输的数据包,并将其展示给分析人员的软件工具。在嗅探器中,使用pcap库是一种常见的方法…...

Vitis导入自制IP导致无法构建Platform
怎么还有这种问题( 解决Vitis导入自制IP导致无法构建Platform – TaterLi 个人博客 Vitis报错:fatal error: xxx.h: No such file or directory._ly2lj的博客-CSDN博客 在指定位置黏入以上代码即可: INCLUDEFILES$(wildcard *.h) LIBSOUR…...

SQLAlchemy 使用封装实例
类封装 database.py #! /usr/bin/env python # -*- coding: utf-8 -*-import sys import json import logging from datetime import datetimefrom core.utils import classlock, parse_bool from core.config import (MYSQL_HOST,MYSQL_PORT,MYSQL_USER,MYSQL_PASS,MYSQL_DA…...

Android Framework通信:Binder
文章目录 前言一、Linux传统跨进程通信原理二、Android Binder跨进程通信原理1、动态内核可加载模块2、内存映射3、Binder IPC 实现原理 三、Android Binder IPC 通信模型1、Client/Server/ServiceManager/驱动Binder与路由器之间的角色关系 2、Binder通信过程3、Binder通信中的…...

如何用精准测试来搞垮团队?
测试行业每年会冒出来一些新鲜词:混沌工程、精准测试、AI测试…… 这些新概念、新技术让我们感到很焦虑,逼着自己去学习和了解这些新玩意,担心哪一天被淘汰掉。 以至于给我这样的错觉,当「回归测试」、「精准测试」这两个词摆在一…...
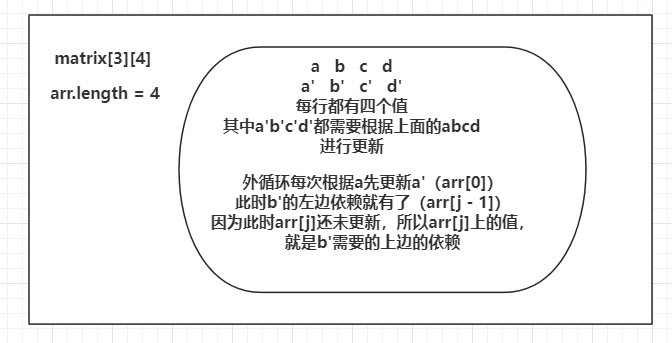
暴力递归转动态规划(十)
题目 给定一个二维数组matrix[][],一个人必须从左上角出发,最终到达右下角,沿途只可以向下或者向右走,沿途的数字都累加就是距离累加和。返回最小距离累加和。 这道题中会采用压缩数组的算法来进行优化 暴力递归 暴力递归方法的整…...

深度学习-房价预测案例
1. 实现几个函数方便下载数据 import hashlib import os import tarfile import zipfile import requests#save DATA_HUB dict() DATA_URL http://d2l-data.s3-accelerate.amazonaws.com/def download(name, cache_diros.path.join(.., data)): #save"""下载…...

【26】c++设计模式——>命令模式
c命令模式 C的命令模式是一种行为模式,通过将请求封装成对象,以实现请求发送者和接受者的解耦。 在命令模式中,命令被封装成一个包含特定操作的对象,这个对象包含的执行该操作的方法,以及一些必要的参数。命令对象可以…...
Transformer不只是NLP的宠儿:看CMX如何用交叉注意力玩转多模态语义分割
Transformer跨界多模态语义分割:CMX如何用交叉注意力重塑RGB-X融合范式 当视觉Transformer在ImageNet分类任务中首次超越CNN时,很少有人预见到这项源自自然语言处理的技术会在计算机视觉的各个领域引发如此深刻的变革。特别是在需要密集预测的语义分割任…...
)
手把手教你用Gemini 3和MediaPipe,为你的网页添加“隔空操控”魔法(附完整代码)
从零构建手势操控3D粒子系统:MediaPipe与Three.js深度整合指南 当我们在科幻电影中看到主角挥挥手就能操控全息界面时,总会心生向往。如今,借助MediaPipe的手势识别能力和Three.js的3D渲染技术,开发者完全可以在网页中实现这种&qu…...

小程序毕业设计springboot基于微信小程序的校园综合服务
前言 在现代校园生活节奏日益加快、师生需求愈发多元化的当下,Spring Boot 校园综合服务系统宛如一位万能助手,全方位覆盖校园学习、生活、社交等各个领域,依托 Spring Boot 强大的开发框架,将繁杂事务化繁为简,为校园…...

Go的interface空值与类型断言的最佳实践
Go语言中的interface空值与类型断言是开发者经常遇到的核心概念,掌握其最佳实践能显著提升代码的健壮性和可维护性。interface的灵活性使其成为Go多态的重要工具,但空值处理和类型断言的不当使用可能导致运行时错误或逻辑漏洞。本文将深入探讨如何高效处…...

3分钟掌握MicroPython WebREPL:浏览器直接控制嵌入式设备
3分钟掌握MicroPython WebREPL:浏览器直接控制嵌入式设备 【免费下载链接】webrepl WebREPL client and related tools for MicroPython 项目地址: https://gitcode.com/gh_mirrors/we/webrepl 想要用浏览器直接控制你的MicroPython开发板吗?WebR…...

YOLO12工业质检场景应用:快速部署检测模型,助力产品缺陷识别
YOLO12工业质检场景应用:快速部署检测模型,助力产品缺陷识别 1. 工业质检的痛点与YOLO12解决方案 在制造业生产线上,产品缺陷检测一直是个老大难问题。传统的人工质检方式存在几个明显短板: 效率低下:工人需要肉眼检…...

手把手玩转Workbench单向流固耦合——从离心泵到风电叶片的实战指南
Workbench单向流固耦合---自己录制 01-离心泵流固耦合分析(3节) 包括01-水泵网格划分、02-CFX中流场设置 03-WB中单向耦合设置、04-后处理等 02-叶片耦合应力分析(3节) 包括01-BladeGen轴流叶片设置技巧、 02-Turbogrid旋转机械网…...
)
LaTeX表格排版救星:用tabularx和 esizebox搞定超宽表格(Overleaf实测)
LaTeX表格排版救星:用tabularx和resizebox搞定超宽表格(Overleaf实测) 在学术写作中,数据表格是展示研究成果的重要方式,但处理多列宽表时常常让人头疼——要么表格溢出页面边界,要么缩放后字体小到难以辨认…...

2026 国内源码网站 TOP10:高速稳定 + 中文友好,开发者收藏版
对于国内开发者、站长、学生与创业团队来说,稳定高速、全中文、资源靠谱、无冗余广告的源码平台,能大幅降低开发成本、提升项目落地效率。2026 年实测筛选出国内综合体验 TOP10 源码站点,兼顾免费学习、商用部署、快速建站等场景,…...

OpenClaw团队协作版:ollama-QwQ-32B支持多人任务队列的改造
OpenClaw团队协作版:ollama-QwQ-32B支持多人任务队列的改造 1. 为什么我们需要团队协作版的OpenClaw 上周我们小组遇到了一个典型问题:三个人同时使用同一台机器上的OpenClaw实例时,任务开始互相干扰。最严重的一次,A同事的自动…...