「网络编程」网络层协议_ IP协议学习_及深入理解
「前言」文章内容是网络层的IP协议讲解。
「归属专栏」网络编程
「主页链接」个人主页
「笔者」枫叶先生(fy)
目录
- 一、IP协议简介
- 二、IP协议报头
- 三、IP网段划分(子网划分)
- 四、特殊的IP地址
- 五、IP地址的数量限制
- 六、私有IP地址和公网IP地址
- 七、路由
- 八、分片与组装
一、IP协议简介
IP指网际互连协议,
Internet Protocol的缩写,是TCP/IP体系中的网络层协议。
IP协议位于网络层
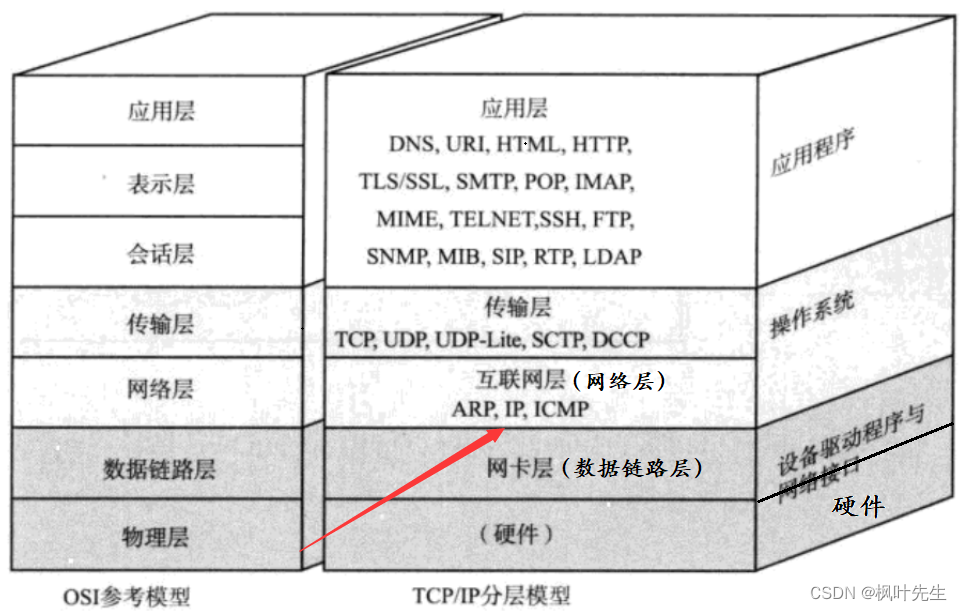
网络层解决的问题
- 传输层: 负责两台主机之间的数据传输。代表协议:TCP协议,确保数据可靠的从源主机发送到目标主机
- 传输层的数据继续向下交付给网络层
- 网络层: 负责地址管理和路由选择。代表协议:IP协议,通过IP地址来标识一台主机,并通过路由表的方式规划出两台主机之间的数据传输的线路(路由)
- TCP作为传输层控制协议,其保证的是数据传输的可靠性,但TCP提供的仅仅是数据传输的策略,而真正负责数据在网络中传输的则传输层之下的网络层和链路层
网络层要解决的问题就是:将数据从一台主机跨网络送到另一台主机,也就是数据的路由(路径选择)
- IP地址的核心作用就是用于定位主机
- IP具有将一个数据数据从A主机跨网络送到B主机的能力(主机到主机)
- 有能力不一定能做到,比如,张三同学数学有考150分的能力,但并不是每次都一定能考150分,有能力代表有非常大的概率去完成这件事
- TCP提供发送数据的策略,IP负责提供行动(发送数据)
- 即网络层不能保证每次都能将数据成功送到对方主机,但在TCP提供的可靠性策略的保证下,最终网络层就一定能够将数据可靠的发送到对方主机
基本概念
- 主机:每台主机都配有IP地址,但是不进行路由控制的设备(现在实际上几乎不存在不进行路由控制的设备)
- 路由器:即配有IP地址,又能进行路由控制(工作在网络层,现在的路由器有些已经具备应用层的功能)
- 节点:主机和路由器的统称
路径选择
数据进行的网络传输一般都是跨网络的,而路由器就是连接多个网络的硬件设备,因此数据在进行跨网络传输时一定需要经过一个或多个路由器
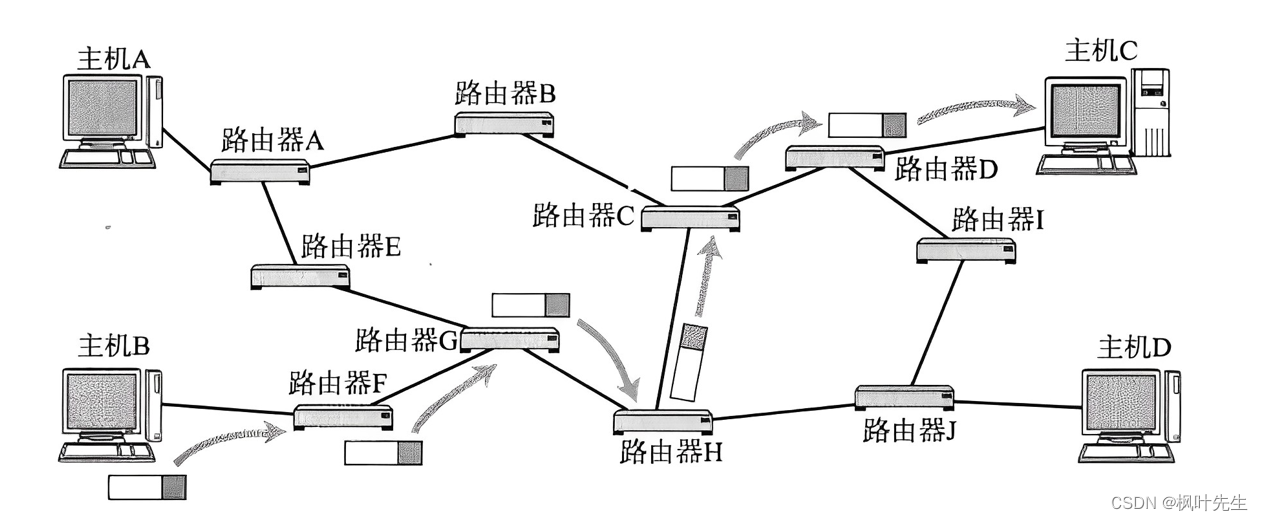
- 比如,B主机发送数据给C主机,确定了C主机的地址后(目的IP),数据就可以进行路由了(目的IP决定了路径怎么走,为什么选择这条路径,而不选择另外一条路径)
- 但数据在路由时无法自行进行路径选择,因为这个数据本身是“不认识路”的
- 而路由器是认得路是怎么走的,它们将自己的“认路经验”都记录到路由表当中
- 因此路由器可以通过查路由表找到去特定节点的最短路径
- 因此数据在路由时,会不断通过路由器来进行路径选择,以此来一步步靠近目标网络或目标主机
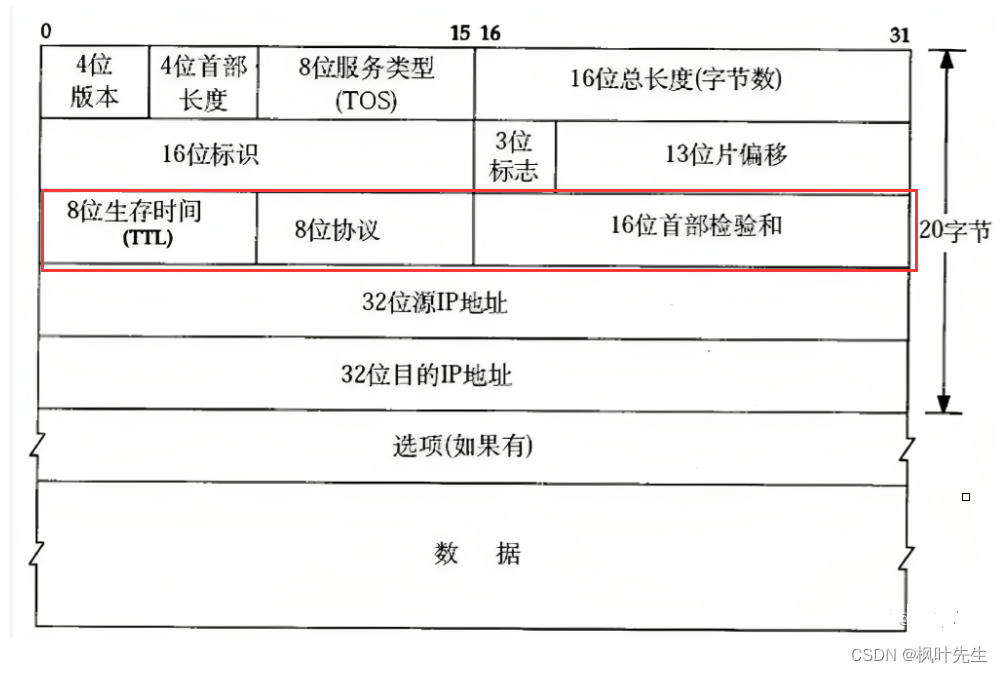
二、IP协议报头
IP协议报头格式如下:
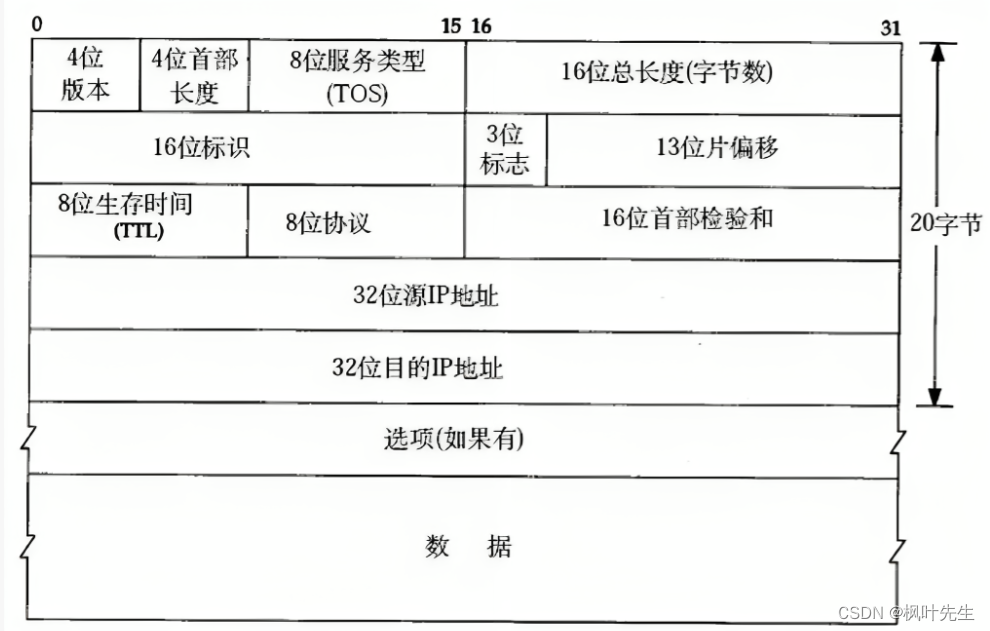
- 4位版本号(
version):指定IP协议的版本,对于IPv4来说,就是4 - 4位首部长度(
header length):表示IP报头的长度,以4字节为单位(IP头部最大长度是60字节,基础报头长度为20字节) - 8位服务类型(
Type Of Service):3位优先权字段(已经弃用),4位TOS字段,和1位保留字段(必须置为0)。4位TOS分别表示:最小延时,最大吞吐量,最高可靠性,最小成本。这四者相互冲突,只能选择一个。比如对于ssh/telnet这样的应用程序,最小延时比较重要,而对于ftp这样的程序,最大吞吐量比较重要。 - 16位总长度(
total length):IP报文(IP报头+有效载荷)的总长度,用于将各个IP报文进行分离 - 16位标识(
id):唯一的标识主机发送的报文,如果数据在IP层进行了分片,那么每一个分片对应的id都是相同的 - 3位标志字段:第一位保留,保留的意思是现在不用, 但是还没想好说不定以后要用到。第二位表示禁止分片,表示如果报文长度超过
MTU,IP协议就会丢弃该报文。第三位表示“更多分片”,如果报文没有进行分片,则该字段设置为0,如果报文进行了分片,则除了最后一个分片报文设置为0以外,其余分片报文均设置为1(最后一个分片报文该字段为0,类似于结束标志,类似于C语言的字符串以'\0'结尾) - 13位片偏移(
framegament offset):分片相对于原始数据开始处的偏移,表示当前分片在原数据中的偏移位置,实际偏移的字节数是这个值× 8得到的。因此除了最后一个报文之外,其他报文的长度必须是8的整数倍,否则报文就不连续了 - 8位生存时间(
Time To Live,TTL):数据报到达目的地的最大报文跳数,一般是64,每经过一个路由,TTL -= 1,一直减到0还没到达,那么就丢弃了,这个字段主要是用来防止出现路由循环 - 8位协议:表示上层协议的类型
- 16位首部检验和:使用CRC进行校验,来鉴别数据报的首部是否损坏,但不检验数据部分
- 32位源IP地址(
Source IP Address):指示发送该数据报的源主机的IP地址。 - 32位目标IP地址(
Destination IP Address):指示接收该数据报的目标主机的IP地址 - 选项字段:不定长,最多40字节(不谈)
如何进行报头与有效载荷的分离??即如何解包
IP协议的报头与TCP协议的报头类似,当IP从底层获取到一个报文后,虽然IP不知道报头的具体长度,但IP报文的前20个字节是IP的基本报头,并且这20字节当中涵盖4位首部长度
IP解包的过程如下:
- IP从下层获取到一个报文后,首先读取报文的前20个字节,并从中提取出4位的首部长度,此时便获得了IP报头的大小
- 注:IP基本报头的长度是20字节,无脑读取20字节
- IP报头当中的4位首部长度只有4个比特位,即4位首部长度的取值范围是
0000 ~ 1111,即最大长度是15,又因为4位首部长度的基本单位是4字节,所以15*4=60字节 - 即IP报头的最大长度是60字节,基本长度是20字节,即报头的取值范围是
[20 ~ 60] - 报头还有一个字段16位总长度:IP报文(IP报头+有效载荷)的总长度
- 拿到报头长度之后,就可以直接与有效载荷进行分离了
注:不同的协议层对数据包有不同的称谓,在传输层叫做数据段(segment),在网络层叫做数据报 (datagram),在链路层叫做数据帧(frame)
IP如何决定将有效载荷交付给上层的哪一个协议?即如何分用
- 在IP报头当中有一个字段叫做8位协议,该字段(协议的编号)表示的就是上层协议的类型,IP就是根据该字段判定应该将分离出来的有效载荷交付给上层的哪一个协议的
- 注:每个协议都有特定的编号
如何解包与分用已经解决,封装就是逆过来
8位生存时间
- 报文在网络传输过程中,可能因为某些原因导致报文无法到达目标主机,比如报文在路由时出现了环路路由的情况,此时这个报文就成了一个废弃的无用报文
- 为了避免网络当中出现大量的无用报文(无用报文每转发一次就浪费一点路由器资源),于是在IP的报头当中就出现了一个字段,叫做8位生存时。
- 8位生存时间代表的是报文到达目的地的最大报文跳数,每当报文经过一次路由,这里的生存时间就会减一,当生存时间减为0时该报文就会被自动路由器丢弃,此时这个报文就会在网络中消散
32位源IP地址和32位目的IP地址
- 32位源IP地址和32位目的IP地址在路由转发过程中起着重要作用(路径选择)
- 路由器根据这两个地址来决定如何转发数据包。它会查找路由表,找到最佳的路径将数据包从源地址发送到目的地址。这个过程称为路由转发。
- 通过源IP地址和目的IP地址,路由器可以确定数据包的起始点和终点,并选择最佳的路径进行转发,以确保数据包能够快速、准确地到达目的地
16位标识(id)、3位标志字段、13位片偏移最后再谈
三、IP网段划分(子网划分)
IP地址的构成
IP地址由网络号和主机号两部分构成:
网络号:保证相互连接的两个网段具有不同的标识
主机号:同一网段内,主机之间具有相同的网络号,但是不同的主机必须有不同的主机号
P协议有两个版本,IPv4和IPv6。后序凡是提到IP协议,没有特殊说明的,默认都是指IPv4(IPv4与IPv6不兼容)
- 对于IPv4来说,IP地址是一个4字节,32位的正整数(32个比特位)
- 在IP地址的后面加一个
/,并在/后面加上一个数字,这就表示从头数到第几位为止属于网络标识(网络号)
例如,下图中路由器连接了两个网段(子网):
- 对于网络标号来讲,同一网段内主机的网络号是相同的,不同网段内主机的网络标识是不同的
- 对于主机号来说,同一网段内主机的主机号是不同的,不同网段内主机的主机号是可以相同的

- 不同的子网其实就是把网络号相同的主机放到一起
- 如果在子网中新增一台主机,则这台主机的网络号和这个子网的网络号一致,但是主机号必须不能和子网中的其他主机重复
- 一个路由器至少行跨两个子网
为什么要进行IP网段划分??(为什么要进行子网划分?)
- 将数据跨网络从一台主机发送到另一台主机时,并不是进行线性遍历IP地址,而是先将数据发送到目标主机所在的网络,然后再发送到对方的目标网络,然后再将数据发送到目标主机
- 不进行线性遍历IP地址的原因的,因为这样效率极其低下,以IPv4来说就有42亿左右的IP地址
- 找主机的过程本质是排除的过程,如果一开始就以找目标主机为目的,那么在查找的过程中一次只能排除一个主机
- 而如果一开始先以找目标网络为目的,那么在查找过程中就能一次排除大量和目标主机不在同一网段的主机,这样就可以大大提高检索的效率
举个例子:
- 比如,我们的学号,学号是精心设计过的,每个字段都代表不同的含义。
- 每个学校都有许多个学院,假设计算机学院编号001,理学院的编号是002,电子信息学院的编号是003,化工学院的编号是004
- 张三是一名计算机学院的同学,张三见捡到了一个钱包,上面只有学号
0030115,张三不认识这个学号,于是张三就一直问走过来的同学:你的学号是多少… - 假设学校有2w人,运气不好,张三要问完2w人,这效率极其感人
- 张三在这时,脑袋灵光一闪,这上面不是有学院的编号吗,直接把它交给自己学院的管理者,再由自己学院的管理者交给该
0030115学号的学院管理者,再由该学院的管理者交给学号为0030115的同学。这不就大大提高了查找的效率吗
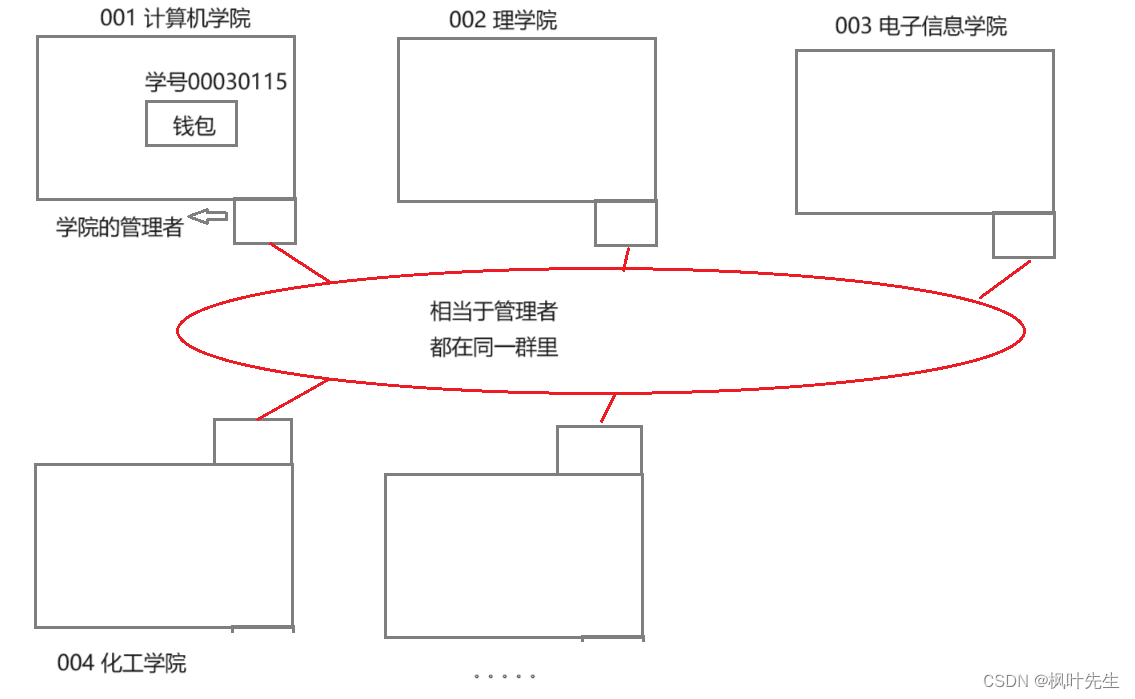
- 虽然张三不认识学号是哪一个学院的
- 但是计算机的管理一看,这不是电子信息学院的吗,直接就扔给了电子信息学院的管理者
- 这样的检索过程实际上就是排除的过程,根据不同的编号(网段),一次就能排除n多群学院(网段),极大提高了查找的效率
- 一个学院的管理者就相当于一个路由器,每个学院就相当于一个子网
因此,为了提高数据路由查找效率,对IP地址进行了IP网段划分(子网划分)
DHCP
通过合理设置主机号和网络号,就可以保证在相互连接的网络中,每台主机的IP地址都不相同
- 以前的IP需要手动进行管理,手动管理IP地址是一个非常麻烦的事情,当子网中新增主机时需要给其分配一个IP地址,当子网当中有主机断开网络时又需要将其IP地址进行回收,便于分配给后续新增的主机使用
- 后面出现了DHCP协议
- DHCP(
Dynamic Host Configuration Protocol,动态主机配置协议)是一个局域网的网络协议,使用UDP协议工作,主要有两个用途:给内部网络或网络服务供应商自动分配IP地址,给用户或者内部网络管理员作为对所有计算机作中央管理的手段 - DHCP是一个基于UDP的应用层协议,一般的路由器都带有DHCP功能,因此路由器也可以看作一个DHCP服务器
当你的设备连接WiFi成功,路由器会自动分配一个IP给你的设备,然后你的设备就有了IP地址,就可以进行上网了(没有联网的设备没有IP地址)
是谁进行子网划分??
- 互联网是一个被设计好的世界,同样IP地址也是被设计好的
- 对于我们国家来说,运营商(移动、电信、联通)就是进行子网划分的执行者,底层网络的设计者
如何进行网段划分??(如何进行子网划分)
过去曾经提出一种划分网络号和主机号的方案,就是把所有IP地址分为五类
如下图所示:
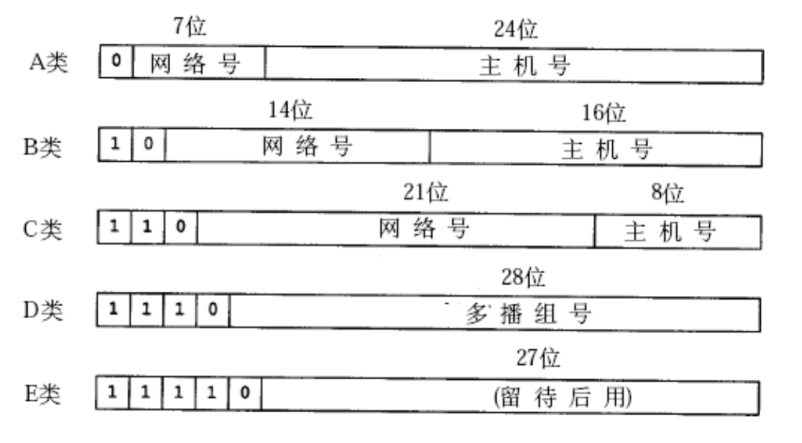
因此,各类IP地址的取值范围如下:
- A类:
0.0.0.0到127.255.255.255 - B类:
128.0.0.0到191.255.255.255 - C类:
192.0.0.0到223.255.255.255 - D类:
224.0.0.0到239.255.255.255 - E类:
240.0.0.0到247.255.255.255
判断一个IP地址属于哪一类网络,可以通过查看IP地址的第一个字节来确定(前8个比特位)
CIDR(无类别域间路由,Classless Interdomain Routing)
但随着网络的飞速发展,这种划分方案的局限性很快就显现出来了
- 例如,申请了一个B类地址,理论上一个子网内能允许6万5千多个主机,对于A类地址的子网内的主机数更多
- 然而实际网络架设中,不会存在一个子网内有这么多的情况。因此大量的IP地址都被浪费掉了
为了避免这种情况,于是又提出了新的划分方案,称为CIDR(Classless Interdomain Routing),CIDR是一种IP地址分配和路由的策略,旨在更有效地利用IPv4地址
- 在原有的五类网络的基础上继续进行子网划分,这也就意味着需要借用主机号当中的若干位来充当网络号,此时为了区分IP地址中的网络号和主机号,于是引入了子网掩码(
subnet mask)的概念 - 每一个子网都有自己的子网掩码,子网掩码实际就是一个32位的正整数,通常用一串“0”来结尾
- 将IP地址与当前网络的子网掩码进行“
按位与”操作,就能够得到当前所在网络的网络号 - 这里的网络号和主机号的划分与这个IP地址是A类、B类还是C类无关
此时一个网络就被更细粒度的划分成了一个个更小的子网,通过不断的子网划分,子网中IP地址对应的主机号就越来越短,因此子网当中可用IP地址的个数也就越来越少,这也就避免了IP地址被大量浪费的情况
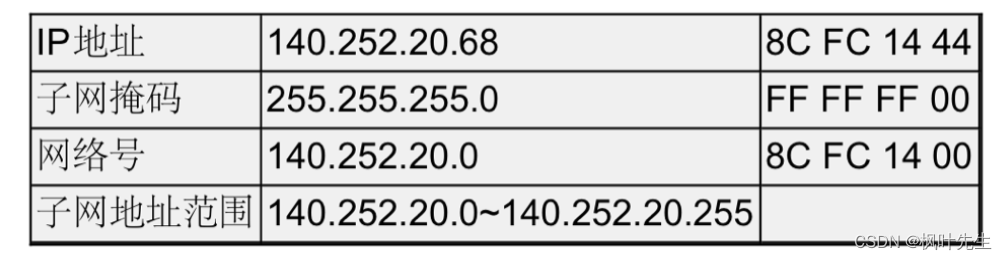
子网划分的例子如下:
- IP地址与子网掩码进行按位与就得到了该网络的网络号
- 主机号从全0到全1就是子网的地址范围

再例如:


需要注意的是,子网划分不是只能进行一次,可以在划分出来的子网的基础上继续进行子网划分
- 一般在一个子网中,管理子网中IP的设备一般是路由器
- 目标网络,子网掩码和子网中的主机,都会被路由器进行管理
- 目标网络和子网掩码都是在路由器上配置的
四、特殊的IP地址
并不是所有的IP地址都能够作为主机的IP地址,有些IP地址本身就是具有特殊用途的。
- 将IP地址中的主机地址全部设为0,就成为了网络号,代表这个局域网。例如上图的
140.252.40.0或140.252.40.64,这个地址代表网络号,不能分配给主机 - 将IP地址中的主机地址全部设为1,就成为了广播地址,用于给同一个链路中相互连接的所有主机发送数据包。例如上图的
140.252.40.255或140.252.40.79,这个地址代表广播地址,也是不能分配给主机 127.*的IP地址用于本机环回(loop back)测试,通常是127.0.0.1
广播地址
- 广播地址用于在同一个链路中相互连接的主机之间发送数据包(广播给同一子网内的所有主机)
- 广播地址是专门用于同时向网络中(通常指同一子网)所有工作站进行发送的一个地址
- 当主机号全为1时,就表示该网络的广播地址
- 例如,上课时班长喊“上课,全体起立!”,班里同学听到后都站起来,这个口令就有广播的含义
本地环回
- 本地环回(loopback)是一个特殊的网络接口,通常用于网络设备的内部通信和管理
- 本地环回接口在IP地址中属于特殊的一类,称为环回地址,通常指定为127.0.0.0/8网段,其中最常见的是127.0.0.1
- 本地环回它不仅可以用于远程管理和故障诊断,还可以用于测试网络服务和内部通信
五、IP地址的数量限制
IP地址(IPv4)是一个4字节32位的正整数,因此一共有2^32个IP地址,也就是将近43亿个IP地址。但TCP/IP协议规定,每个主机都需要有一个IP地址
- 现在全世界人口已经有70多亿了,就算有一半的人没有智能手机,算下来也有30多亿台智能手机需要IP地址
- 随着科技的发展,我们使用的电脑、智能手表、智能冰箱、智能洗衣机等设备如果要入网也是需要IP地址的
- 另外,IP地址并不是按照主机台数来配置的,因此一个主机可能需要多个IP地址,更别谈还有很多组网的路由设备也需要IP地址,以及一些特殊的IP地址不能使用的问题
所以43亿个IP地址其实早就不够用了,因此才提出了CIDR的方案对已经划分好的五类网络继续进行子网划分,其目的就是为了减少IP地址的浪费,根本原因就是IP地址本来就不够了,所以不能够再浪费了。
CIDR虽然在一定程度上缓解了IP地址不够用的问题,因为CIDR提高了IP地址的利用率,减少了浪费,但IP地址的绝对上限并没有增加,依旧是43亿左右
解决IP地址的三种方法
- 动态分配IP地址:只给接入网络的设备分配IP地址,因此同一个MAC地址的设备,每次接入互联网中,得到的IP地址不一定是相同的,避免了IP地址强绑定于某一台设备
- NAT技术:能够让不同局域网当中同时存在两个相同的IP地址,NAT技术不仅能解决IP地址不足的问题,而且还能够有效地避免来自网络外部的攻击,隐藏并保护网络内部的计算机
- IPv6:IPv6用16字节128位来表示一个IP地址,能够大大缓解IP地址不足的问题。但IPv6并不是IPv4的简单升级版,它们是互不相干的两个协议,彼此并不兼容,因此目前IPv6还没有普及
IPv6我国目前搞得比较好,但是由于与IPv4不兼容,导致推广迟迟无法展开。因为IPv4是内嵌在OS里面的,还有底层设施与IPv6不兼容,导致IPv6的推广很困难
由于NAT技术的出现,IP地址不足的问题得到了解决,但是IP地址的绝对上限并没有增加(NAT技术依旧没有彻底解决这个问题)
NAT技术的出现,虽然阻碍了IPv6的发展,但是也帮助了我国IPv6的推广,通过NAT技术,可以把IPv6的地址转化成IPv4的地址,目前我国大部分互联网公司的内网环境都是IPv6
美国虽然也搞IPv6,但是没有动力(我闲着没事干为什么要推翻我的IPv4)
彻底解决IP地址不足的问题还是得靠IPv6
六、私有IP地址和公网IP地址
如果一个组织内部组建局域网,IP地址只用于局域网内的通信,而不直接连到Internet上,理论上使用任意的IP地址都可以,但是RFC 1918规定了用于组建局域网的私有IP地址:
10.,前8位是网络号,共16,777,216个地址172.16.到172.31.,前12位是网络号,共1,048,576个地址192.168.,前16位是网络号,共65,536个地址- 包含在这个范围中的,都称为私网IP(私有IP,内网IP),其余剩下的则称为公网IP(或全局IP)
查看自己主机的IP
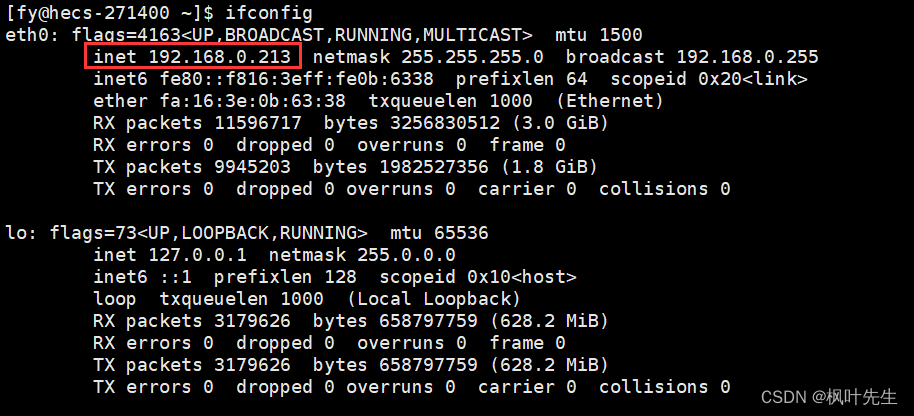
ifconfig:该命令的作用是显示和配置网络接口的信息
比如,购买的Linux服务器,输入该命令
eth0代表的是:通常表示系统的第一个以太网接口。它是物理网络接口,用于连接到局域网或互联网。eth0可以是有线或无线以太网接口,具体取决于你的系统设置和网络硬件lo是本地回环接口(loopback interface),也被称为环回地址。它是一个虚拟网络接口,用于系统内部通信。lo接口的IP地址通常是127.0.0.1,子网掩码为255.0.0.0。它允许系统内部的进程和服务之间进行通信,而不需要通过物理网络接口- 图中
eth0接口中的inet对应的地址192.168.0.213,就是私网IP
用于连接Linux服务器的IP叫做公网IP
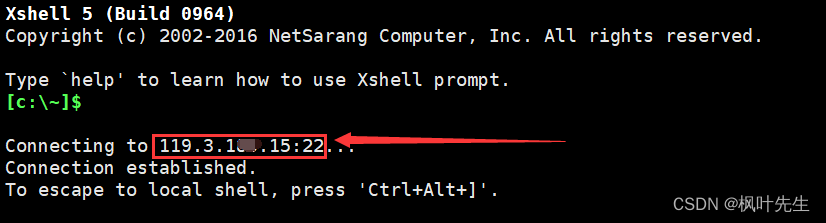
注:在Windows下查看使用命令ipconfig
我们为什么要给运营商交钱??
我们享受的是互联网公司提供服务,比如刷抖音,在淘宝上买东西…,但是我们并没有给互联网公司交钱(上网的费用),而是把钱交给了运营商,为什么把钱交给运营商而不是互联网公司,我们明明享受的是互联网公司提供的各种服务??
- 运营商是网络通信的基础设施的建设者,我们进行上网,各种数据(请求,响应的数据)必须经过运营商
- 也就是说,我们访问服务器的数据请求并不是直接发送到了对应的服务器,而是需要经过运营商建设的各种基站以及各种路由器、集群转发,最终数据才能到达对应的服务器上
- 对应服务器给我们响应的数据也必须经过运行商,经过运营商的转发,最终响应才到达我们的客户端
- 我们给运营商交网费,实际就相当于购买入网许可一样(允许我们进行上网),因为我们必须使用运营商提供了通信的基础设施,不使用就无法上网
比如你的手机号欠费了,你还想进行上网,在经过运行商的时候,运营商就会对你的账号进行认证,发现你欠费了,直接丢掉了你的请求,不转发给相应的服务器
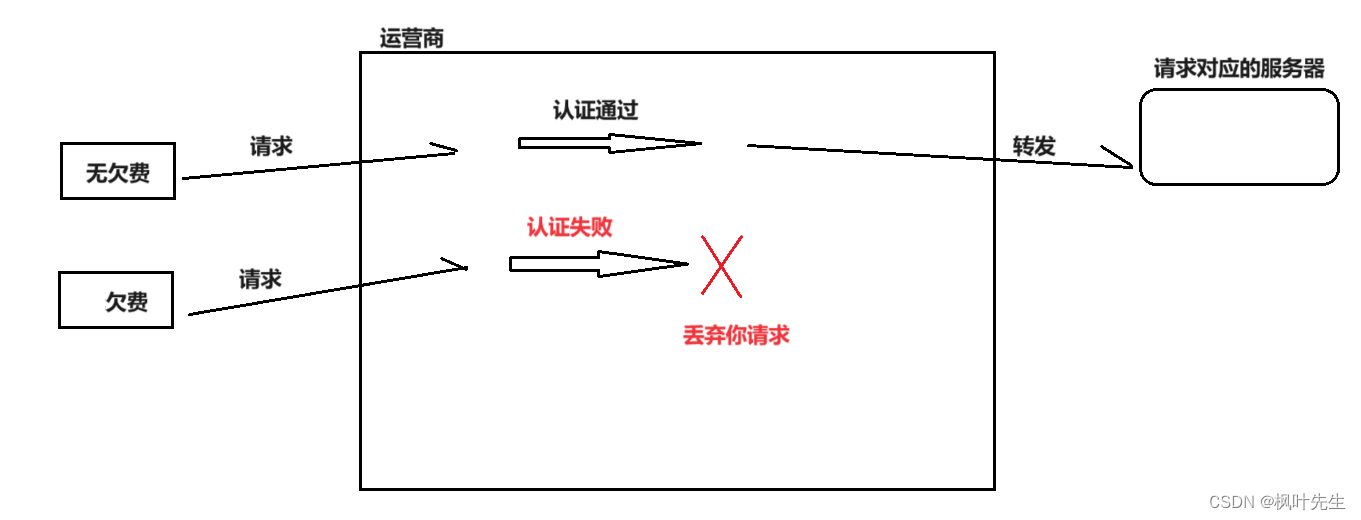
- 相反互联网公司想要上网,也必须向运营商进行交费,否则也上不了网,即服务端的数据发送不到客户端上
- 运营商相当于扮演中间人的角色,两边进行收费
- 所谓的网段划分、子网划分等工作实际都是运营商做的
- 没有运营商提供的这些基础设施,就不会诞生所谓的互联网公司,因为互联网公司是诞生在网络通信基础之上的
- 同理,既然我们的数据报必须经过运营商,运营商就可以对我们的数据包进行检测,如果发现你请求的网址是非法网址或者该数据包访问的是外网,比如Google、推特等,运营商就直接把你的请求叉掉了,不给你的数据包做转发
也就是说,用户上网的数据首先必须经过运营商的相关网络设备,然后才能发送到互联网公司对应的服务器,所以我们想上网必须要给运营商交钱
路由器的功能
- 数据转发
- DHCP 和组建局域网(子网)
- NAT
路由器又分家用版路由器和企业级路由器:
- 组建局域网使用的IP必须是私有IP,不能使用公网IP
- 家用版路由器:功率较低,满足日常使用,搭建局域网使用的私有IP通常是
192.168.的 - 企业级路由器:搭建局域网使用的私有IP通常是
10.或者是172.16.到172.31.
数据是如何发送到对应的服务器上的
路由器是连接两个或多个子网的硬件设备,在路由器上有两种网络接口,分别是LAN口和WAN口:
LAN口(Local Area Network):表示连接本地网络的端口,主要与家庭网络中的交换机、集线器或PC相连WAN口(Wide Area Network):表可以理解为连接公网网络的接口,一般指互联网
我们将LAN口的IP地址叫做LAN口IP(对内),也叫做子网IP,将WAN口的IP地址叫做WAN口IPO,也叫做外网IP(对外)
我们使用的电脑、家用路由器、运营商路由器、广域网以及我们要访问的服务器之间的关系大致如下:
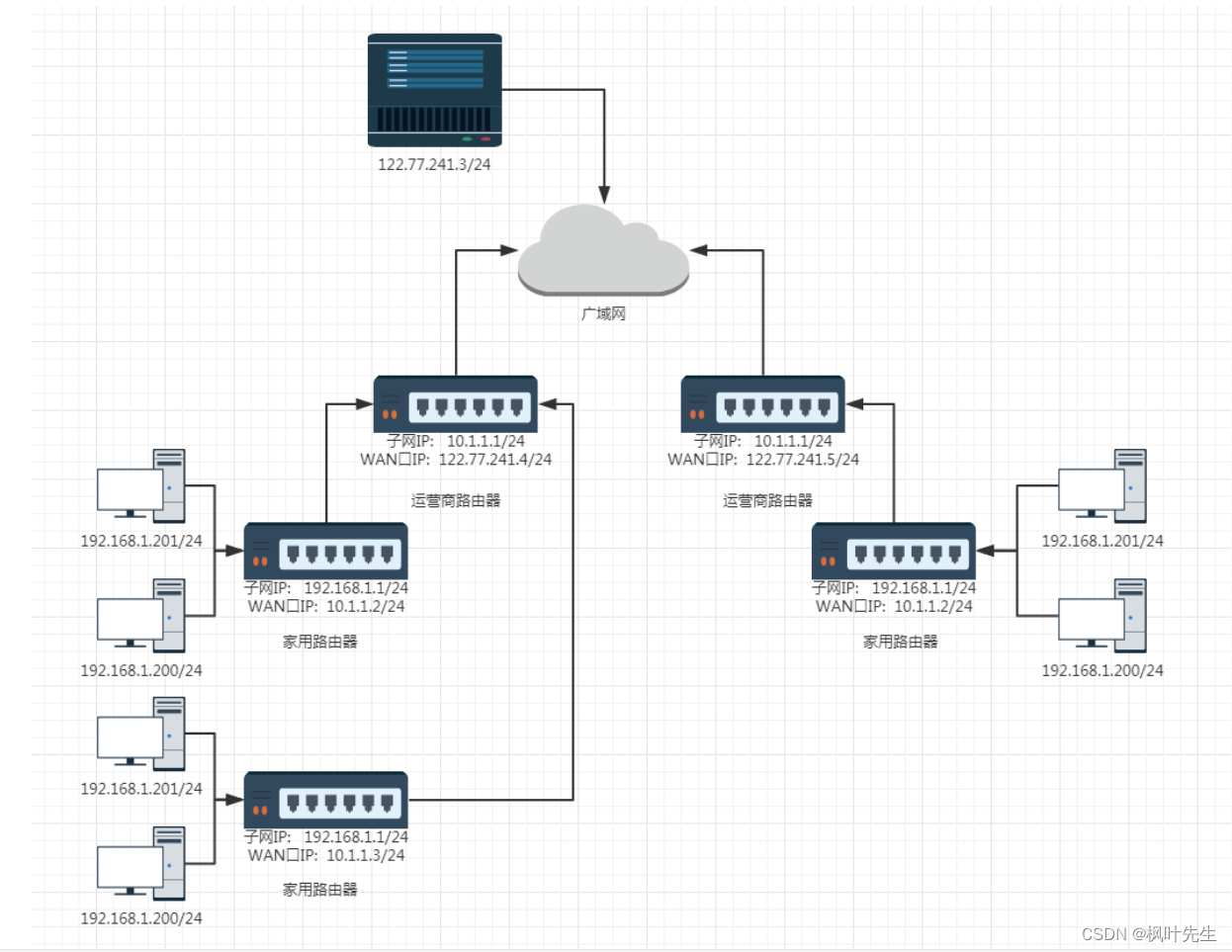
- 不同的路由器,子网IP其实都是一样的(通常都是
192.168.1.1),子网内的主机IP地址不能重复,但是子网之间的IP地址就可以重复了 - 每一个家用路由器,其实又作为运营商路由器的子网中的一个节点,这样的运营商路由器可能会有很多级,最外层的运营商路由器的WAN口IP就是一个公网IP了
- 如果希望我们自己实现的服务器程序,能够在公网上被访问到,就需要把程序部署在一台具有外网IP的服务器上,这样的服务器可以在阿里云/腾讯云上进行购买
注:私网IP不能出现在公网当中
为什么私网IP不能出现在公网当中?
- 私网IP可以重复也就意味着我们可以在不同的局域网使用相同的IP地址,缓解了IP的不足
- 即私有IP地址是全球不唯一的,如果直接用在公网上,会造成路由混乱。所以,私有IP地址要想访问外网,会经过路由器并进行地址转换,将私有IP(局域网唯一)转换成公有IP(全球唯一)
由于私网IP不能出现在公网当中:
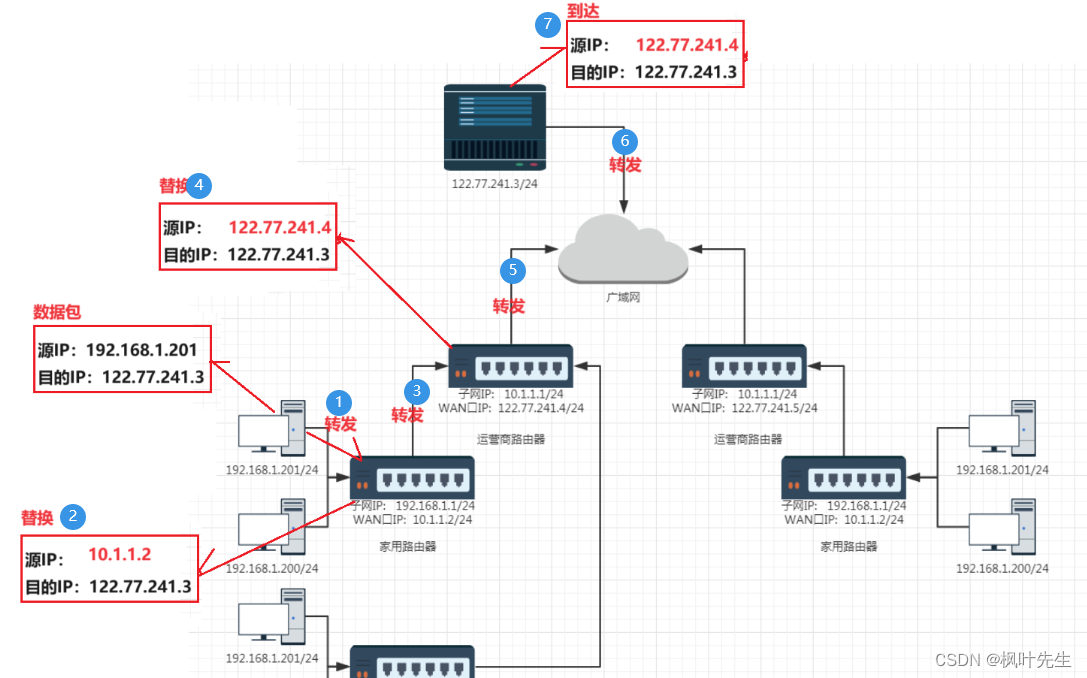
- 因此子网内的主机在和外网进行通信时,路由器会不断将数据包IP首部中的
源IP地址替换成路由器的WAN口IP,这样逐级替换,最终数据包中的源IP地址成为一个公网IP,这种技术成为NAT(Network Address Translation,网络地址转换,把私有地址转换成合法的IP地址)
数据转发的大致流程如下:
- 假设数据包要去往
122.77.241.3/24 - 数据包从自己的主机发送给家用路由器之后,路由器发现要去往的目的IP不再自己的子网内
- 此时就会进行
源IP替换成路由器的WAN口IP,再转发给跟自己直接相连的另一个子网 - 假设转发的数据包到了运营商的路由器,经过多级转发(经过运营商的多个子网),最后发现数据包要去往的目的IP不在自己的子网内
- 此时也进行
源IP替换成路由器的WAN口IP,然后直接把数据包转发到公网上 - 再由公网转发到对应的目的IP
如图:
关于数据包怎么回来的问题,后面再谈
七、路由
数据包路由的过程(类似于问路的过程,一个个接力下去)
- 数据包在路由的过程中,实际就是一跳一跳(Hop by Hop),类似于“问路”的过程
- 所谓“一跳”就是数据链路层中的一个区间,具体在以太网中指从
源MAC地址到目的MAC地址之间的帧传输区间
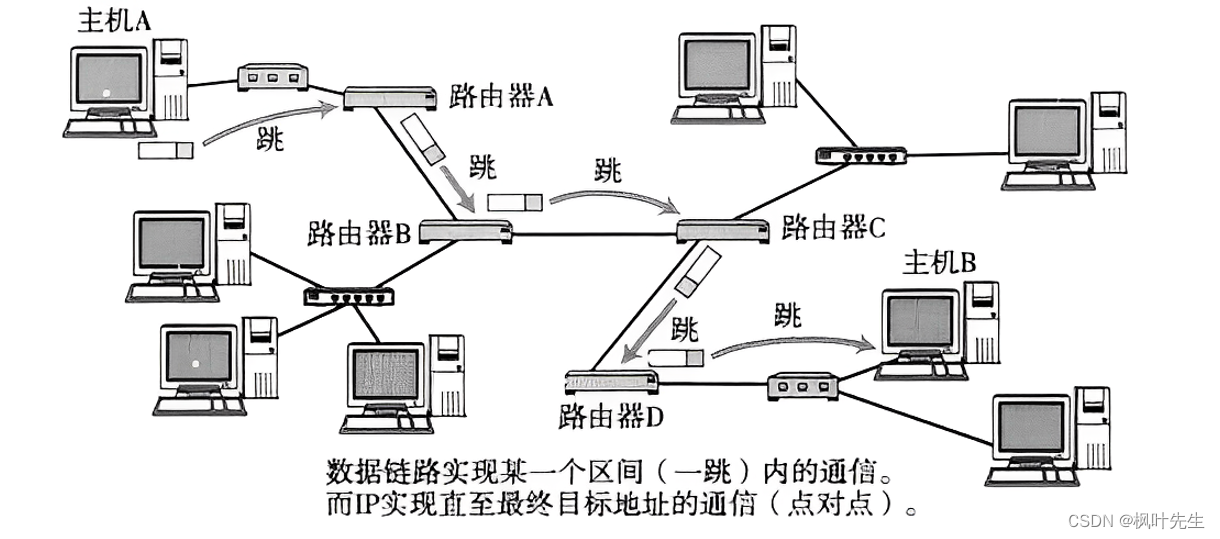
IP数据包的传输过程也和问路一样,IP数据包的传输过程中会遇到很多路由器
这些路由器会帮助数据包进行路由转发,每当数据包遇到一个路由器后,对应路由器都会查看该数据的目的IP地址,并告知该数据下一跳应该往哪跳
- 当IP数据包, 到达路由器时,路由器会先查看目的IP
- 路由器决定这个数据包是能直接发送给目标主机,还是需要发送给下一个路由器(查路由表)
- 依次反复,一直到达目标IP地址
如何判定当前这个数据包该发送到哪里?
- 这个就依靠每个节点(路由器)内部维护一个路由表
- 通过查路由表就可以知道应该把数据表发送给谁
IP数据包中的
目的IP,在路由器的路由表查找结果可能有以下三种:
- 路由器经过路由表查询后,得知该数据下一跳应该跳到哪一个子网
- 路由器经过路由表查询后,没有发现匹配的子网,此时路由器会将该数据转发给默认路由(默认网关)
- 路由器经过路由表查询后,得知该数据的目标网络就是当前所在的网络,此时路由器就会将该数据转给当前网络中对应的主机
查看路由表
路由表可以使用route命令查看,该命令可以显示当前系统的路由表
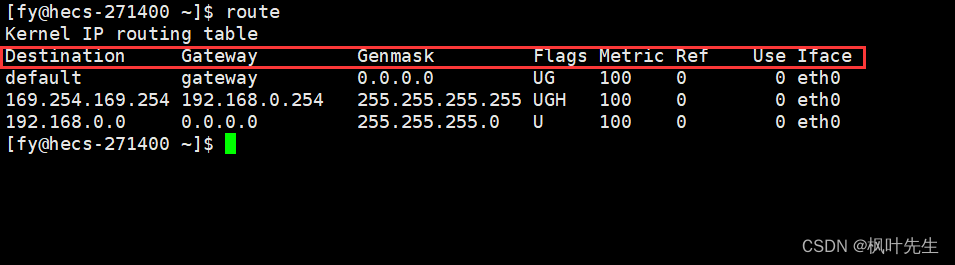
条目部分解释:
Destination:目标网络或主机的IP地址Gateway:下一跳网关的IP地址,即发送数据包到目标网络或主机的下一跳路由器Genmask:目标网络或主机的网络掩码Flags:标志位,用于表示路由表项的状态和属性。常见的标志位包括U(路由表项是可用的),G(路由表项是由网关指定的,表示此条目的下一跳地址是某个路由器的地址),H(路由表项是一个主机路由)Iface:接口,表示数据包将通过哪个网络接口发送
其中一些字段的意思:
default:表示这是默认路由(网关),即当系统找不到匹配的目标网络或主机时,将使用这个路由表项0.0.0.0:表示目标网络或主机为任意网络或主机UG:表示这是一个默认路由表项,并且网关字段是有效的,没有G标志的条目表示目的网络地址是与本机接口直接相连的网络,不必经路由器转发
查路由表的过程
-
当IP数据包到达路由器时,路由器就会查该数据包的目的IP地址,依次与路由表中的子网掩码
Genmask进行“按位与”操作(遍历路由表),然后将结果与子网掩码对应的目的网络地址Destination进行比对,如果匹配则说明该数据包下一跳就应该跳去这个子网,此时就会将该数据包通过对应的发送接口Iface发出 -
如果将该数据包的目的IP地址与子网掩码进行“按位与”后,没有找到匹配的目的网络地址,此时路由器就会将这个数据包发送到默认路由,也就是路由表中目标网络地址中的
default。可以看到默认路由对应的Flags是UG,实际就是将该数据转给了另一台路由器,让该数据在另一台路由器继续进行路由 -
数据包不断经过路由器路由后,最终就能到达目标主机所在的目标网络,此时就不再根据该数据包目的IP地址当中的网络号进行路由了,而是根据目的IP地址当中的主机号进行路由,最终根据该数据包对应的主机号就能将数据发送给目标主机
路由表可以由网络管理员手动维护(静态路由),也可以通过一些算法自动生成(动态路由)
路由表生成算法:距离向量算法, LS算法, Dijkstra算法等
注意:>网络层的IP协议是为数据的路由提供决策,而真正的对数据进行转发路由的是数据链路层(正真做事的)
最后补充上面没有谈到的16位标识(id)、3位标志字段、13位片偏移
八、分片与组装
下面进行解释16位标识(id)、3位标志字段、13位片偏移
这里会涉及到数据链路层的问题
- IP能够将数据包跨网络从一台主机送到另一台主机,而数据包在进行跨网络传送时,需要经过一个个的路由器进行路由转发,最终才能到达目标主机
- 因此IP进行数据包跨网络传送的前提是,需要先将数据包从一个节点传送到和自己相连的下一个节点,这个问题实际就是由IP之下的数据链路层解决的,其中数据链路层代表协议就是MAC帧协议
- 即数据链路层负责在相邻节点之间进行通信,将数据包封装成帧,并通过物理介质进行传输
- 而两个节点直接相连也就意味着这两个节点是在同一个局域网当中的,因此要讨论两个相邻节点的数据传送时,实际讨论的就是局域网通信的问题
最大传输单元 MTU
- MAC帧作为数据链路层的协议,它会将IP传下来的数据封装成数据帧,然后发送到网络当中(跑在网线上的是数据帧),但是MAC帧协议传输数据是有限制大小的,传输数据帧的时候不能超过这个值,这个值被称为MTU,最大传输单元
- 最大传输单元(
Maximum Transmission Unit,MTU)是指在网络通信中,数据链路层能够传输的最大数据帧的大小。MTU的大小通常由网络设备或网络协议规定,它限制了一次可传输的数据量 - MTU默认的大小一般是1500字节
在Linux下使用ifconfig命令可以查看对应的MTU
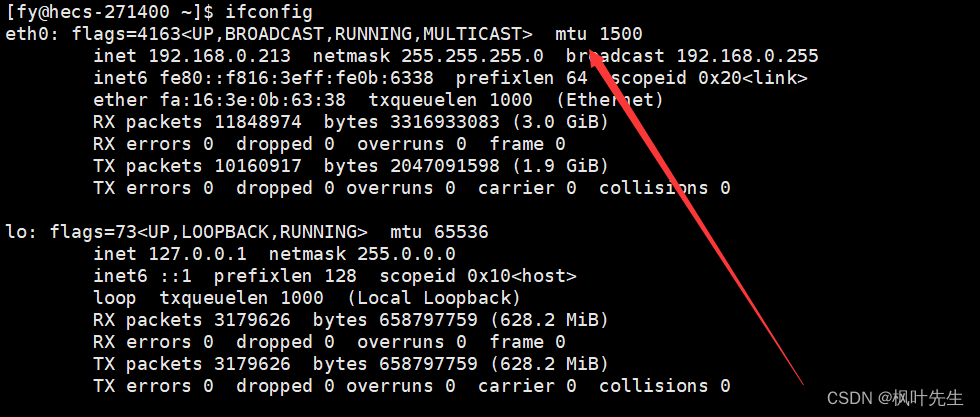
- MAC帧协议无法发送大于1500字节的数据
- 因此IP层向下交付的数据包的长度不能超过1500字节,而且
IP报头+有效载荷 <= 1500字节 - 如果大于1500字节,MAC帧协议就无法发送该数据
- 如果IP层要发送的数据超过了1500字节,那么就需要先在IP层对该数据进行分片,然后再将分片后的数据交给下层MAC帧进行发送
- 因为IP协议控制不了发送一个报文的大小,控制发送一个报文大小是传输层协议控制的(TCP或UDP)
既然有分片,就也要有组装,分片与组装是在IP层完成的,分片与组装单纯是IP协议的行为,与上一层传输层和下一层数据链路层没有任何关系
注意:IP的分片与组装不是主流情况,IP的分片与组装是特殊情况,主流的情况下一篇文章数据链路层再谈
如何分片和组装??
靠这三个字段即可完成分片与组装:
- 16位标识(
id):唯一的标识主机发送的报文,如果数据在IP层进行了分片,那么每一个分片对应的id都是相同的 - 3位标志字段:第一位保留,保留的意思是现在不用,但是还没想好说不定以后要用到。第二位表示禁止分片,表示如果报文长度超过
MTU,IP协议就会丢弃该报文。第三位表示“更多分片”,如果报文没有进行分片,则该字段设置为0,如果报文进行了分片,则除了最后一个分片报文设置为0以外,其余分片报文均设置为1(最后一个分片报文该字段为0,类似于结束标志,类似于C语言的字符串以'\0'结尾) - 13位片偏移(
framegament offset):分片相对于原始数据开始处的偏移,表示当前分片在原数据中的偏移位置,实际偏移的字节数是这个值× 8得到的。因此除了最后一个报文之外,其他报文的长度必须是8的整数倍,否则报文就不连续了
注意:被分片的报文都要重新封装IP报头
怎么知道一个IP报文是否被分片了?
- 3位标志字段中的第三位标志位,表示“更多分片”,如果报文没有进行分片,则该字段设置为0,如果报文进行了分片,则除了最后一个分片报文设置为0以外,其余分片报文均设置为1
同一个报文的分片如何都能被识别出来?
- 通过16位标识,被分片的报文16位表示ID都是相同的
如何判断分片的报文哪一个是第一个,哪一个是最后一个?
- 最后一个分片的报文可以通过第三位标志位更多分和片偏移得知,即更
多分片标志位为0 && 片偏移>0即代表最后一个分片报文 - 第一个分片报文通过
多分片标志位为1 && 片偏移 == 0进行判断,如果满足则是第一个分片报文
如何得知被分片的报文有没有被收全?如何进行组装,哪个分片报文在前,哪个平分报文在后?
- 分片的报文是否收全通过13位片偏移判断(当前的起始位置+自身长度 == 下一个分片报文中填充的偏移量大小),如果分片报文不全,则直接丢弃,让对端TCP重发整个报文
- 如何组装也是通过13位片偏移判断,对分片报文的片偏移量升序排序即可
如何保证组装起来的报文是正确的?
- 通过16位首部检验和判断
- 交付给上层TCP/UDP时,TCP/UDP也会通过TCP/UDP自己的16位首部检验和判断进行判断
- 如果校验失败,则直接丢弃该报文
数据的分片和组装都是由IP层完成的
- 数据的分片和组装都是在IP层完成的,上层的传输层和下层的链路层并不关心
分片好不好?
答案是,肯定是不好,虽然传输层并不关心IP层的分片问题,但分片对传输层也是有影响
- 如果一个数据在网络传输过程中进行了分片,那么只有当接收端收到了全部的分片报文并将其成功组装起来,这时我们才认为该数据被对方可靠的收到了
- 但如果众多的分片报文当中有一个报文出现了丢包,就会导致接收端就无法将报文成功组装起来,这时接收端会将收到的分片报文全部丢弃,此时传输层TCP就会重发该报文(整个)
- 分片会增加丢包的概率
- 假设丢包的概率是
99.99%,一个报文在IP层发生了分片,分成了三个分片报文,此时该报文丢包概率就会增加,99.99%*99.99%*99.99% < 99.99%
如何减少分片?
实际数据分片的根本原因在于传输层一次向下交付的数据太多了,导致IP无法直接将数据向下交给MAC帧,如果传输层控制好一次交给IP的数据量不要太大,那么数据在IP层自然也就不需要进行分片。
- 因此TCP作为传输控制协议,它需要控制一次向下交付数据不能超过某一阈值,这个阈值就叫做MSS(Maximum SegmentSize,最大报文段长度),通信双方在建立TCP连接时会协商MSS的
- MAC帧的有效载荷最大为MTU,TCP的有效载荷最大为MSS
- 一般情况下,MSS的值等于MTU减去IP和TCP协议头的长度,因为IP和TCP协议头的长度一般都是20字节。而MAC帧的MTU一般是1500字节,
MSS = MTU - 20 - 20,所以MSS的值一般为1460字节 - 因此,为了避免数据分片,建议TCP将发送的数据控制在MSS的大小以内
- 但是需要注意的是,不同网络链路的MTU可能不同,如果数据在传输过程中经过MTU较小的网络,仍然可能需要进行分片
总结来说,实际数据分片的原因是传输层一次向下交付的数据太多了,为了避免数据分片,需要控制TCP发送的数据大小在MSS以内
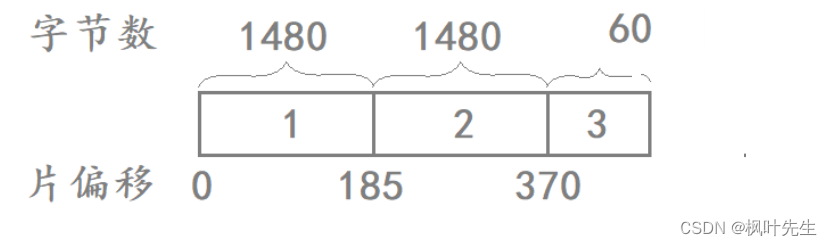
分片的过程
假设IP层要发送3000字节的数据(IP报头+有效载荷),由于该数据超过了MAC帧规定的MTU(1500),因此IP需要先将该数据进行分片,然后再将一个个的分片交给MAC帧进行发送
假设IP层添加的IP报头的长度就是20字节,并按下列方式将数据分片后形成了三个分片报文:
| 分片报文 | 报文字节总数 | IP报头字节数 | 有效载荷 | 16位标识 | 更多分片标志位 | 13位片偏移 |
|---|---|---|---|---|---|---|
| 1 | 1500 | 20 | 1480 | 假设是111 | 1 | 0 |
| 2 | 1500 | 20 | 1480 | 111 | 1 | 185 |
| 3 | 60 | 20 | 40 | 111 | 1 | 370 |
注意:13位片偏移当中记录的字节数是当前分片在原数据开始处的偏移字节数的值÷ 8得到的
关于组装的问题上面已经谈论了大部分,不再赘述,下一篇进入数据链路层的MAC帧协议
「 作者 」 枫叶先生
「 更新 」 2023.10.14
「 声明 」 余之才疏学浅,故所撰文疏漏难免,或有谬误或不准确之处,敬请读者批评指正。
相关文章:
「网络编程」网络层协议_ IP协议学习_及深入理解
「前言」文章内容是网络层的IP协议讲解。 「归属专栏」网络编程 「主页链接」个人主页 「笔者」枫叶先生(fy) 目录 一、IP协议简介二、IP协议报头三、IP网段划分(子网划分)四、特殊的IP地址五、IP地址的数量限制六、私有IP地址和公网IP地址七、路由八、分…...

Go 1.21 新内置函数:min、max 和 clear
max 函数 func max[T cmp.Ordered](x T, y …T) T 这是一个泛型函数,用于从一组值中寻找并返回 最大值,该函数至少要传递一个参数。在上述函数签名中,T 表示类型参数,它必须满足 cmp.Ordered 接口中定义的数据类型要求࿰…...

家居行业如何打破获客困局?2023重庆建博会现场,智哪儿AI营销第一课给出了答案
10月12日-14日,2023中国(重庆)建筑及装饰材料博览会(简称:2023中国重庆建博会)正在重庆国际博览中心如火如荼地进行。「智哪儿」携手2023中国重庆建博会主办方共同主办的《2023家居行业AI营销第一课&#x…...
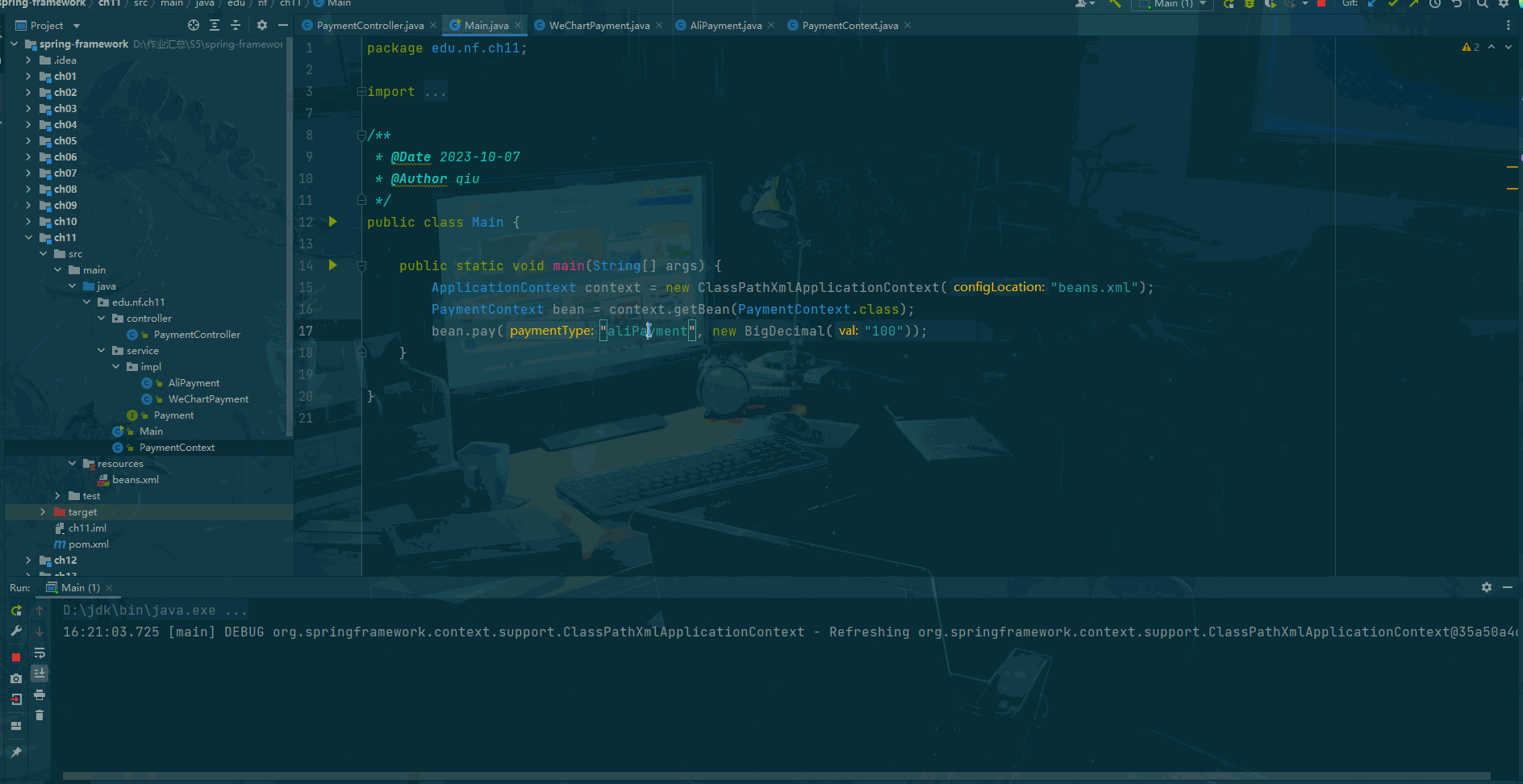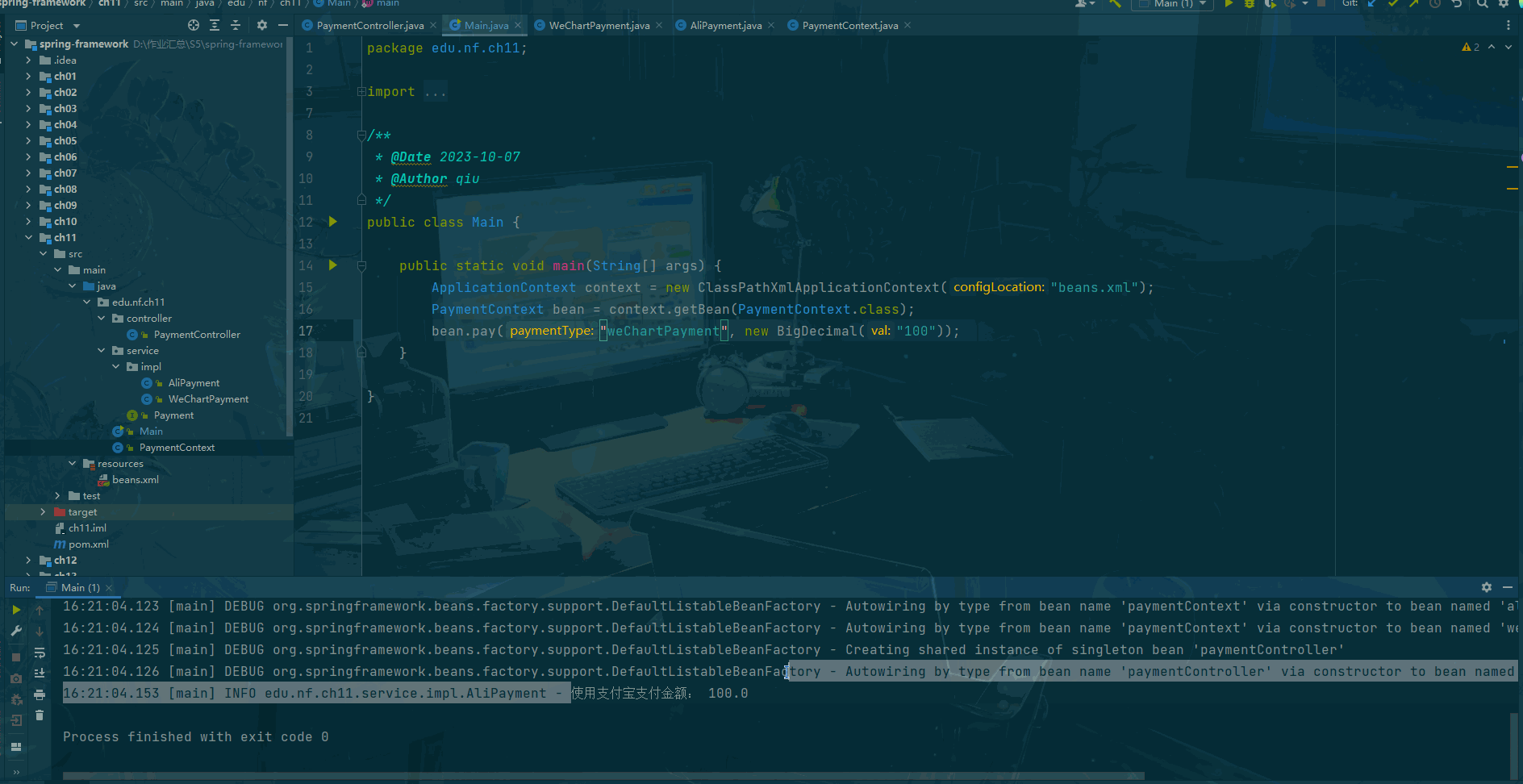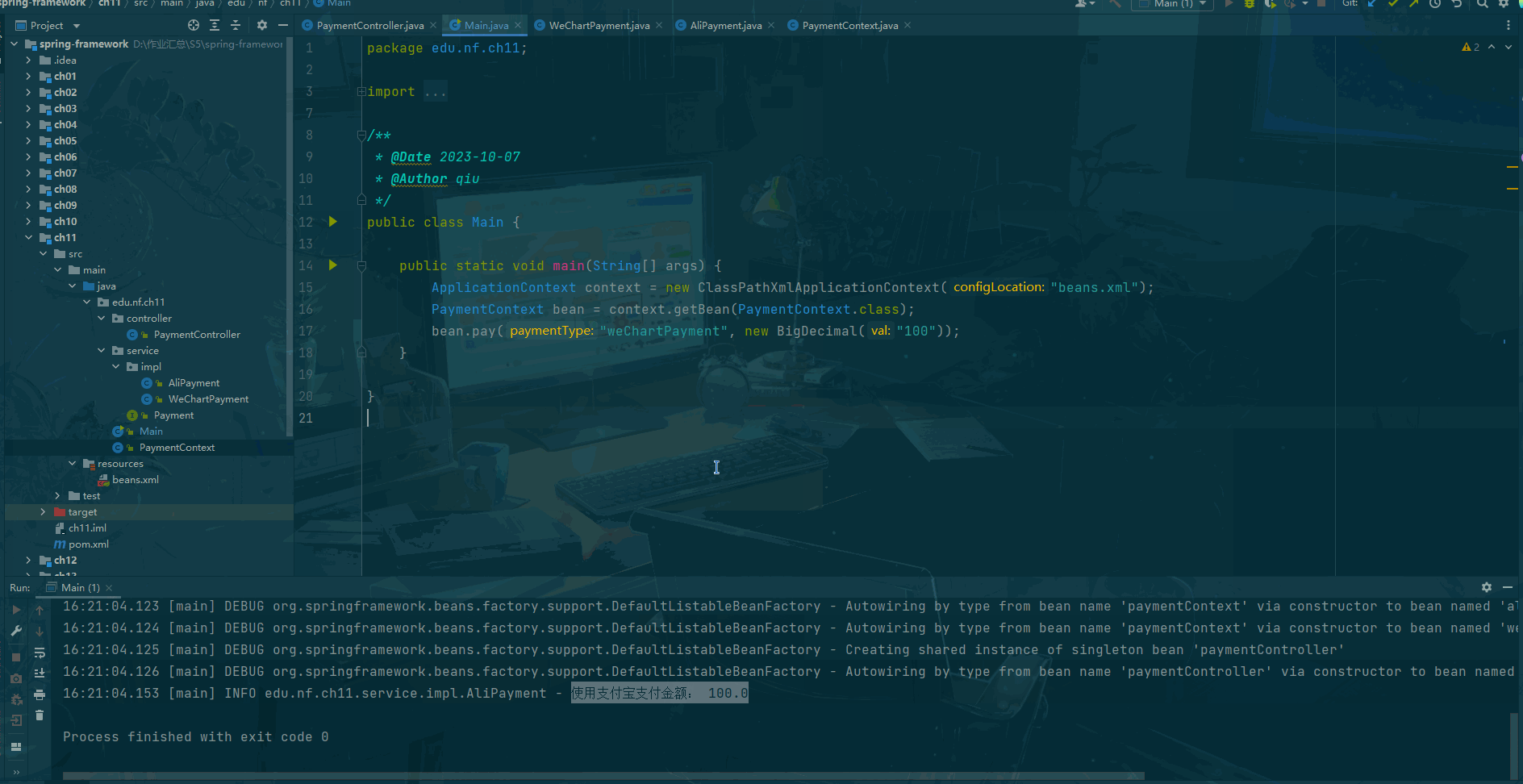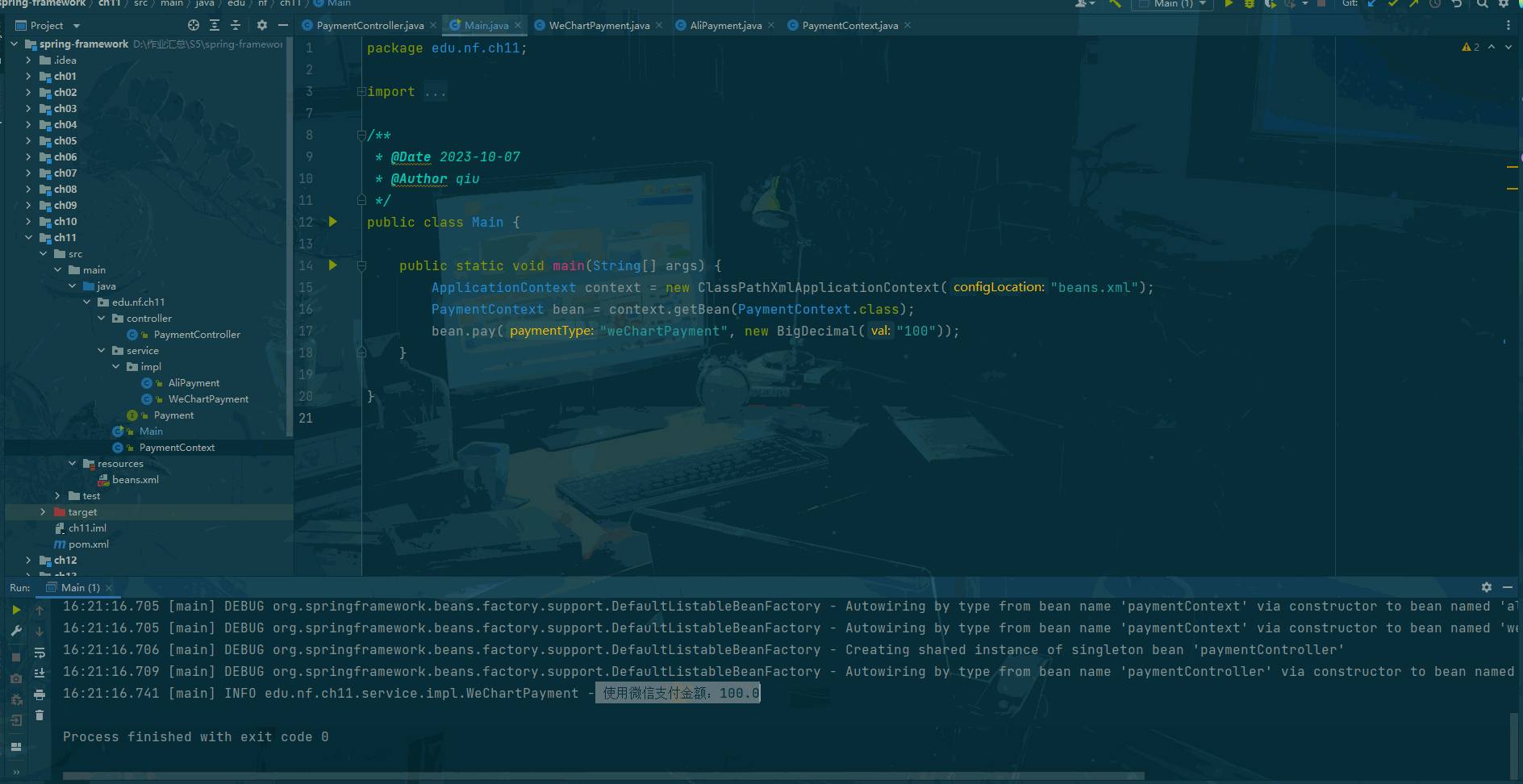
Spring framework Day11:策略模式中注入所有实现类
前言 什么是策略模式? 策略模式(Strategy Pattern)是一种面向对象设计模式,它定义了算法族(一组相似的算法),并且将每个算法都封装起来,使得它们可以互相替换。策略模式让算法的变…...

MBBF展示的奇迹绿洲:5G的过去、此刻与未来
如果你来迪拜,一定不会错过全世界面积最大的人工岛项目,这是被称为世界第八大奇迹的棕榈岛。多年以来,这座岛从一片砂石、一棵棕榈树开始,逐步建成了整个波斯湾地区的地标,吸引着全世界游人的脚步。 纵观整个移动通信发…...

加持智慧医疗,美格智能5G数传+智能模组让就医触手可及
智慧医疗将云计算、物联网、大数据、AI等新兴技术融合赋能医疗健康领域,是提高医疗健康服务的资源利用效率,创造高质量健康医疗的新途径。《健康中国2030规划纲要》把医疗健康提升到了国家战略层面,之后《“十四五”全面医疗保障规划》等一系…...

Stm32_标准库_14_串口蓝牙模块_手机与蓝牙模块通信_实现模块读取并修改信息
由手机向蓝牙模块传输时间信息,Stm32获取信息并将已存在信息修改为传入信息 测试代码: #include "stm32f10x.h" // Device header #include "Delay.h" #include "OLED.h" #include "Serial.h"uint16_t num…...

UDP 的报文结构
UDP的报文结构: 其中前面的源端口号和目的端口号,UDP长度和UDP检验和,它们都是2个字节。 那么什么是UDP长度呢,它指的是后面的数据的长度,换算单位也就是64kb,因此一个数据报(数据)最…...

torch.hub.load报错urllib.error.HTTPError: HTTP Error 403: rate limit exceeded
在运行DINOv2的示例代码时,需要载入预训练的模型,比如: backbone_model torch.hub.load(repo_or_dir"facebookresearch/dinov2", modelbackbone_name) torch.hub.load报错“urllib.error.HTTPError: HTTP Error 403: rate limit…...

测试左移右移-理论篇
目录 前言一、浅解左移1.什么是测试左移?1.1对产品1.2对开发1.3对测试1.4对运维 二、浅解右移1.1对产品1.2对开发1.3对测试1.4对运维 三、总结 前言 测试左移右移,很多人说能让测试更拥有主动权,展示出测试岗位也是有很大的价值,…...

【TensorFlow2 之015】 在 TF 2.0 中实现 AlexNet
一、说明 在这篇文章中,我们将展示如何在 TensorFlow 2.0 中实现基本的卷积神经网络 \(AlexNet\)。AlexNet 架构由 Alex Krizhevsky 设计,并与 Ilya Sutskever 和 Geoffrey Hinton 一起发布。并获得Image Net2012竞赛中冠军。 教程概述: 理论…...
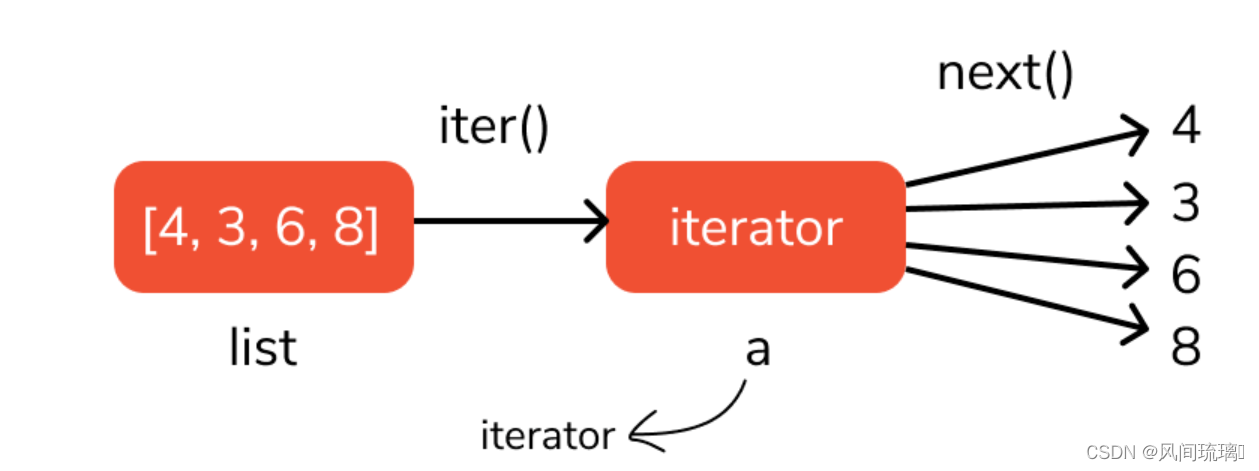
Python进阶之迭代器
文章目录 前言一、迭代器介绍及作用1.可迭代对象2. 迭代器 二、常用函数和迭代器1.常用函数2.迭代器 三、总结结束语 💂 个人主页:风间琉璃🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主💬 如果文章对你有帮助、欢迎关注…...

Vue鼠标右键画矩形和Ctrl按键多选组件
效果图 说明 下面会贴出组件代码以及一个Demo,上面的效果图即为Demo的效果,建议直接将两份代码拷贝到自己的开发环境直接运行调试。 组件代码 <template><!-- 鼠标画矩形选择对象 --><div class"objects" ref"objectsR…...
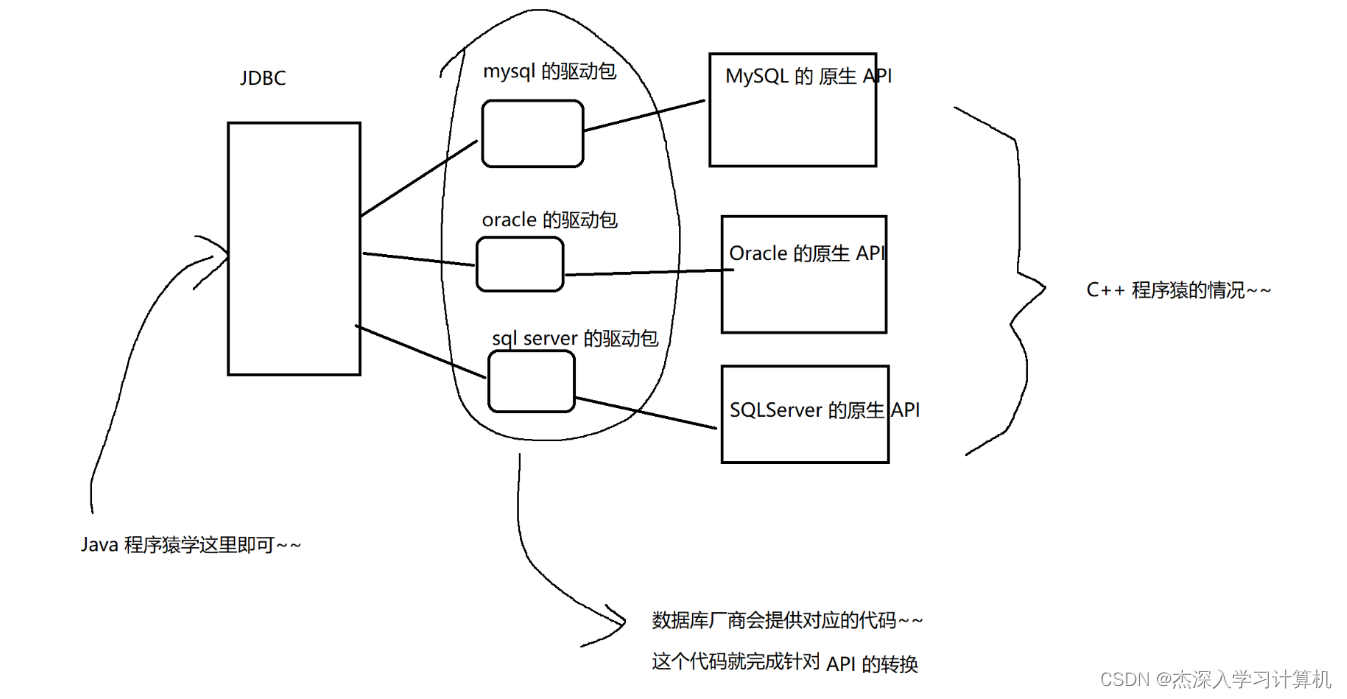
【MySQL JDBC】使用Java连接MySQL数据库
一、什么是JDBC? 理解API的概念 API:Application Programing Interface -- 应用程序编程接口写好一个程序,这个程序需要给别人提供哪些功能?这些功能就是通过一些 函数/类 这样的方式来提供的。例如 Random、Scanner、ArrayList..…...
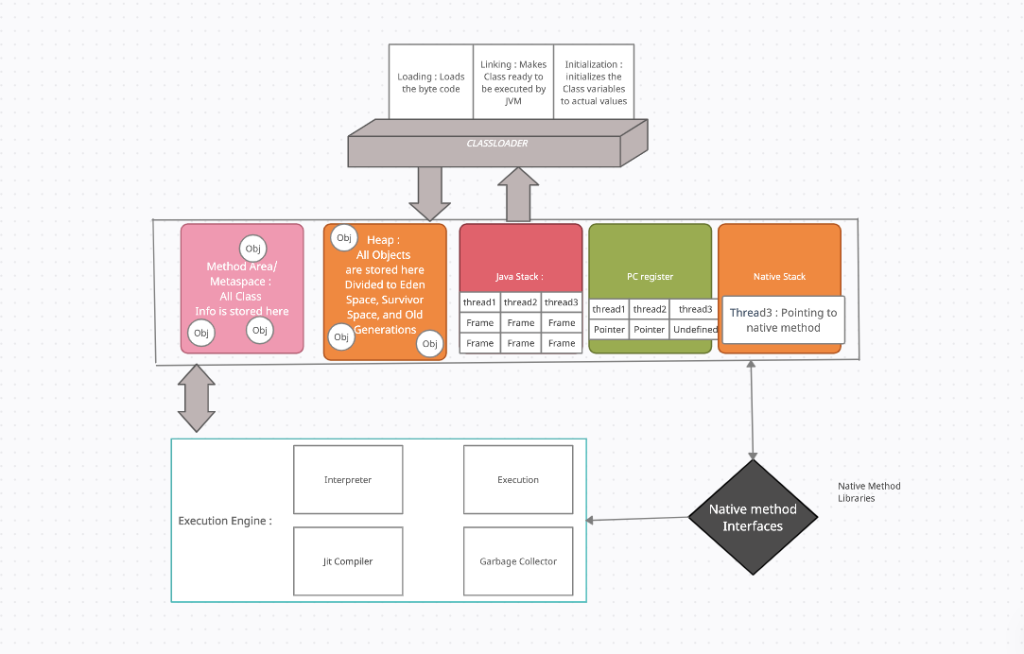
字节码学习之常见java语句的底层原理
文章目录 前言1. if语句字节码的解析 2. for循环字节码的解析 3. while循环4. switch语句5. try-catch语句6. i 和i的字节码7. try-catch-finally8. 参考文档 前言 上一章我们聊了《JVM字节码指令详解》 。本章我们学以致用,聊一下我们常见的一些java语句的特性底层…...
Godot C#连接信号不能像GDScirpt一样自动添加代码
前言 我网上找了好久,发现Godot 对于C# 的支持还有待增强 使用c#脚本有办法像gds那样连接节点自带信号时自动生成信号吗? 百度贴吧 Godot C# How To, Episode 9. Signals With Parameters | Godot Mono 解决方案 把信号拉长,看他的属性 修…...

快速自动化处理JavaScript渲染页面
在进行网络数据抓取时,许多网站使用了JavaScript来动态加载内容,这给传统的网络爬虫带来了一定的挑战。本文将介绍如何使用Selenium和ChromeDriver来实现自动化处理JavaScript渲染页面,并实现有效的数据抓取。 1、Selenium和ChromeDriver简介…...
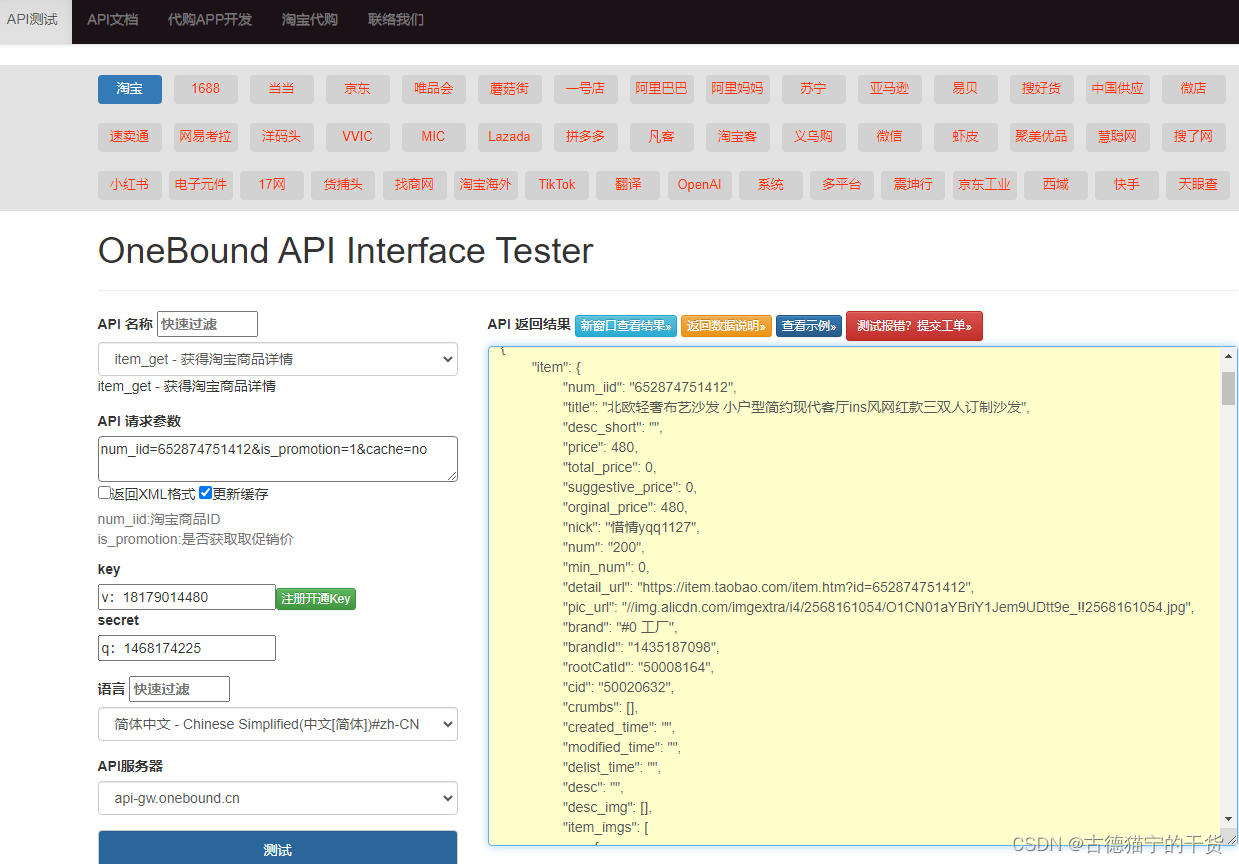
通过API接口进行商品价格监控,可以按照以下步骤进行操作
要实现通过API接口进行商品价格监控,可以按照以下步骤进行操作: 申请平台账号并选择API接口:根据需要的功能,选择相应的API接口,例如商品API接口、店铺API接口、订单API接口等,这一步骤通常需要我们在相应…...

(vue3)大事记管理系统 文章管理页
[element-plus进阶] 文章列表渲染(带搜索&到分页) 表单架设:当前el-form标签配置一个inline属性,里面的元素就会在一行显示了 中英国际化处理:App.vue中el-config-provider标签包裹组件,意味着整个组…...

springboot 使用RocketMQ客户端生产消费消息DEMO
创建springboot项目省略 项目依赖 注意:当前客户端版本是 5.1.3 ,安装的rocketmq服务的版本要与其对应 <properties><java.version>11</java.version><rocketmq-client-java-version>5.1.3</rocketmq-client-java-version&…...

Claude代码技能库:AI编程辅助的范式转变与工程实践
1. 项目概述:一个面向Claude的代码技能库最近在AI编程辅助的圈子里,一个名为warren618/claude-code-openclaw-skills的项目引起了我的注意。乍一看这个标题,你可能会有点懵——“Claude”是谁?“OpenClaw”又是什么?这…...

多介质过滤器和活性炭过滤器的区别在哪?
做水处理设备选型快10年,我几乎每周都会遇到客户问:多介质过滤器和活性炭过滤器到底有啥区别?选型选错不仅花冤枉钱,还会直接影响整个水处理系统的寿命。先给大家总结核心结论:两者核心作用不同,多介质偏物…...

LinkedIn Liger Kernel:移动设备内核定制与性能优化实战
1. 项目概述:一个面向移动设备的开源内核探索如果你在移动设备开发、嵌入式系统或者内核研究的圈子里待过一段时间,大概率听说过或者接触过“Liger Kernel”这个名字。它不是一个商业产品,而是一个在GitHub上由LinkedIn开源并维护的Android内…...

使用TaotokenCLI工具一键配置多开发环境与团队密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用TaotokenCLI工具一键配置多开发环境与团队密钥 基础教程类,本文指导开发者如何通过npx或全局安装TaotokenCLI工具&…...
)
别再只用AES了!手把手教你用Java BouncyCastle库实现SM4国密加密(附完整工具类)
国密算法实战:用Java BouncyCastle实现SM4加密的完整指南 在数据安全领域,国际通用算法长期占据主导地位,但随着技术自主可控需求的提升,国产密码算法正成为企业级应用的新选择。SM4作为我国商用密码标准体系中的重要对称加密算法…...

嵌入式固件开发知识体系构建:从硬件交互到系统级设计
1. 固件开发者知识体系构建:从“会写代码”到“懂系统”干了十几年嵌入式,我越来越觉得,固件开发这行,光会调库、写业务逻辑是远远不够的。你写的每一行代码,最终都要在真实的物理世界里跑起来,要和传感器、…...

跨设备游戏串流终极方案:Sunshine开源服务器高效解决游戏共享难题
跨设备游戏串流终极方案:Sunshine开源服务器高效解决游戏共享难题 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine作为一款自托管的开源游戏串流服务器&#x…...

半导体行业复苏:晶圆出货与EDA增长背后的技术驱动力与挑战
1. 行业复苏信号:晶圆出货量与EDA市场的强劲联动最近和几位在晶圆厂和芯片设计公司工作的老朋友聊天,大家不约而同地提到一个感受:产线又忙起来了,设计部门的项目排期也肉眼可见地变长了。这种感觉并非空穴来风,近期SE…...

AI工具导航站Awesome-AITools:社区驱动的资源聚合与高效使用指南
1. 项目概述:为什么我们需要一个AI工具导航站?如果你最近也在关注AI领域,大概率会和我有同样的感受:新工具、新模型、新应用的出现速度,已经快到了让人眼花缭乱的地步。今天刚听说一个能自动剪辑视频的AI,明…...

量子支持向量机原理与硬件优化实践
1. 量子支持向量机基础原理与硬件挑战量子支持向量机(QSVM)是传统支持向量机在量子计算框架下的扩展,其核心创新点在于利用量子态空间的高维特性构建核函数。与传统核方法相比,量子核映射通过量子电路将经典数据编码到希尔伯特空间…...