MySQL的InnoDB存储引擎中的自适应哈希索引技术
一、自适应哈希索引的工作机制与优化策略
MySQL的InnoDB存储引擎使用了一种叫做自适应哈希索引(Adaptive Hash Indexes)的技术。在某些索引值被频繁访问的情况下,InnoDB会自动在内存中为这些值建立哈希索引,以加速查询操作。
何时使用哈希搜索
当一个索引值被频繁访问,并且对应的哈希索引已经被创建时,InnoDB就会通过哈希搜索来快速定位到相关的行。相比于传统的B-Tree索引搜索,哈希搜索可以提供更快的搜索性能。
如何优化哈希搜索
- 增加缓冲池大小:由于自适应哈希索引是存储在内存中的,因此增加InnoDB缓冲池的大小可以提供更多的空间给哈希索引,从而提高哈希搜索的效率。可以通过调整
innodb_buffer_pool_size参数来实现。 - 开启自适应哈希索引:确保
innodb_adaptive_hash_index参数已经被设定为ON,以启用自适应哈希索引功能。 - 合理设计数据模型和索引:如果发现某些查询无法利用到哈希搜索,可能需要重新审视你的数据模型和索引设计。例如,尽量避免全表扫描的查询,为经常被访问的列创建索引等。
- 监控和调优:可以通过SHOW ENGINE INNODB STATUS命令来查看自适应哈希索引的使用情况,并根据这些信息进行进一步的调整和优化。
虽然哈希搜索在某些情况下能提供更快的性能,但并不总是最好的选择。例如,在处理范围查询或排序操作时,B-Tree索引通常会比哈希索引更加高效。
二、innodb_adaptive_hash_index_parts配置项的作用与设置方法
innodb_adaptive_hash_index_parts是一个MySQL的配置参数,用于控制InnoDB存储引擎的自适应哈希索引分区的数量。InnoDB存储引擎使用这些分区存储自适应哈希索引的条目,并可以并发地访问这些分区。
作用
提高这个值可以在系统有大量并发查询时进一步减少由于内部争用而导致的性能下降。对于具有高并发读取的OLTP(在线事务处理)负载,增加innodb_adaptive_hash_index_parts的值可能会提升系统的整体性能。
如何设置
你可以在MySQL的配置文件(通常是my.cnf或my.ini)中,添加或修改以下行来设置这个参数:
[mysqld] innodb_adaptive_hash_index_parts = NUMBER其中,NUMBER应替换为你想要设置的分区数。注意,innodb_adaptive_hash_index_parts的默认值是8,其允许的范围是1到512。
然后,你需要重启MySQL服务器以使新的设置生效。
需要注意的是,调整innodb_adaptive_hash_index_parts的值应当根据实际测试和监测的性能数据进行。不合理的设置可能会导致性能问题,或者增加系统的内存使用量。
三、自适应哈希索引分区的工作原理与设置原则
自适应哈希索引分区的工作原理
InnoDB存储引擎的自适应哈希索引是一种优化策略,旨在提高对特定数据的访问速度。当InnoDB存储引擎检测到某些索引值被频繁地访问时,它会自动为这些值创建内存中的哈希索引。对于等值查询(即精确匹配查询),哈希索引通常比B-Tree索引更快。因此,自适应哈希索引可以有效地提高数据库的查询性能。
自适应哈希索引分区的作用:
在InnoDB中,自适应哈希索引的索引项被存储在一个或多个“分区”中。每个分区都有自己的锁,这意味着并发的查询可以同时访问不同的分区,而无需等待其他查询释放锁。因此,分区的主要作用是减少锁争用,从而在高并发情况下提高性能。
为什么需要设置分区数量:
innodb_adaptive_hash_index_parts配置参数用于设置自适应哈希索引的分区数。如果你的系统有大量的并发读取操作,增加该参数的值可能有助于提升整体性能,因为更多的分区可以减少锁争用。
但是,更多的分区也意味着更高的内存使用量以及可能的CPU缓存失效,因此需要根据实际情况和性能测试数据来适当地设置该参数。
四、关于自适应哈希索引分区的一些常见问题
为何每个分区需要有锁,没有锁会有何影响?
每个自适应哈希索引分区拥有一个锁,主要是为了在多线程环境下保证数据一致性和并发控制。如果没有适当的并发控制机制,多个线程(或者进程)同时尝试修改同一个数据项可能会导致数据的不一致。
如果没有锁,那么在并发环境下可能会出现以下问题:
- 数据不一致:如前所述,如果多个线程在没有适当并发控制的情况下同时修改同一个数据项,可能会导致数据不一致。
- 脏读、幻读等并发问题:在并发环境中,如果没有适当的锁机制,可能会引发各种并发问题,如脏读(一个事务读到了其他事务未提交的修改)、不可重复读(在同一事务中,多次读取同一数据返回的结果不一致)和幻读(在同一事务中,执行相同的查询两次,返回的结果集不一致)等。
MySQL如何将自适应哈希索引分配到不同的分区?不同表的哈希索引会共用一个分区吗?
MySQL的InnoDB存储引擎使用哈希函数确定将自适应哈希索引项放入哪个分区。具体来说,它会取索引值的哈希值,然后用这个哈希值对分区数求模(即取余数),得到的结果就是该索引项应该被放入的分区号。由于哈希函数的特性,不同表的哈希索引项可能会被分配到同一个分区。
如果同时访问的两个表的哈希索引都在一个分区,会造成锁争用吗?
确实,如果两个操作访问的不同表的哈希索引位于同一个分区,由于每个分区都有自己的锁,这可能会引发所谓的"锁争用"问题。但是,在某些高并发负载下,如果锁争用问题变得严重,可能需要采取额外的优化措施,例如增加分区数(通过调整innodb_adaptive_hash_index_parts配置参数)或者优化查询逻辑和数据模型等。
分区越多越好吗?
并不是分区越多越好。选择适当的分区数需要在性能优化和资源使用之间找到平衡。以下是一些需要考虑的因素:
- 并发性能:增加分区数可以减少锁争用,从而提高在高并发环境下的性能。每个分区都有自己的锁,这意味着更多的查询可以同时进行,而无需等待其他查询释放锁。
- 内存使用:但是,每增加一个分区,就会使用更多的内存来存储哈希索引和相关的元数据。如果分区数设置过高,可能会导致过多的内存被用于存储哈希索引,而不能用于其他重要的数据库操作,如缓存数据页。
- CPU缓存利用率:此外,如果分区数过多,可能会影响CPU缓存的利用率。因为CPU需要维护多个分区的锁,可能会导致CPU缓存频繁地在不同的锁之间切换,从而降低缓存效率。
因此,设置合适的分区数需要根据具体的工作负载、硬件配置以及性能监控数据来决定。如果你的系统在高并发情况下出现了性能瓶颈,并且通过监控发现存在明显的锁争用问题,那么增加分区数可能是一个有效的优化策略。否则,过多的分区可能会浪费资源,甚至降低性能。
相关文章:

MySQL的InnoDB存储引擎中的自适应哈希索引技术
一、自适应哈希索引的工作机制与优化策略 MySQL的InnoDB存储引擎使用了一种叫做自适应哈希索引(Adaptive Hash Indexes)的技术。在某些索引值被频繁访问的情况下,InnoDB会自动在内存中为这些值建立哈希索引,以加速查询操作。 何…...
交互设计主要做什么?新手入门必读
什么是交互设计?它涉及哪些内容?交互设计师是什么样的人群?他们到底是做什么的?他们身怀什么技能?他们工作的价值在哪里?交互设计行业的现状是怎样的?工作前景又是如何的? 如果你心…...
:门控制——自定义循环神经网络LSTM(长短期记忆网络)模型)
【深度学习实验】循环神经网络(三):门控制——自定义循环神经网络LSTM(长短期记忆网络)模型
目录 一、实验介绍 二、实验环境 1. 配置虚拟环境 2. 库版本介绍 三、实验内容 0. 导入必要的工具包 1. LSTM类 a.__init__(初始化) b. init_state(初始化隐藏状态) c. forward(前向传播) 2. RNNModel类 a.__init__&am…...

flutter 消息并发时处理,递归查询
收到新消息的时候执行receiveNewConversation方法 可以自己模拟一下两条数据插入,延时执行插入会话的操作 收到一条新的会话消息,先记录会话ID到列表,直到第一条处理完(插入数据库后清理这个会话ID),才处理…...
第五十八章 学习常用技能 - 查看查询缓存
文章目录 第五十八章 学习常用技能 - 查看查询缓存查看查询缓存建立索引使用调谐表工具 第五十八章 学习常用技能 - 查看查询缓存 查看查询缓存 对于 SQL(用作嵌入式 SQL 时除外),系统会生成可重用代码来访问数据,并将该代码放置…...

AI 辅助学 Java | 专栏 1 帮你学 Java
在利用 ChatGPT 辅助学 Java 之前,你得先知道,它到底能辅助你干什么?如何能帮你更好的学习 Java。 苍何:作为一个语言模型,你能给 Java 的初学者提供什么帮助?请罗列具体的点。 ChatGPT:当你是一个 Java 初学者时,我可以提供以下具体的帮助和指导: 基本语法和语言特…...

2023_Spark_实验十六:编写LoggerLevel方法及getLocalSparkSession方法
一、搭建Spark项目结构 在SparkProject模块的pom.xml文件中增加一下依赖,并等待依赖包下载完毕,如上图。 <!-- Spark及Scala的版本号 --><properties><scala.version>2.11</scala.version><spark.version>2.1.1</sp…...

彻底搞懂:防止表单重复提交,前端限制还是后端限制?
欢迎大家来到小米的技术分享专栏!今天我将为大家带来一个热门话题:如何有效地防止表单重复提交。在开发中,我们常常会遇到这样的问题:用户频繁点击提交按钮,导致数据重复提交,给系统和用户体验带来不必要的…...
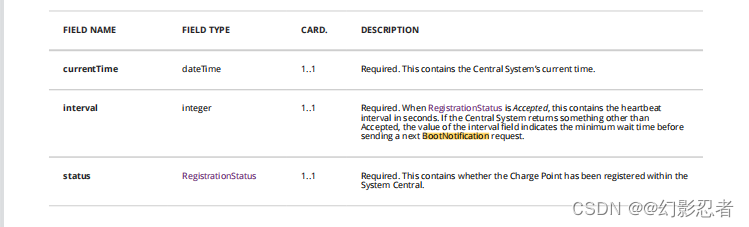
OCPP1.6协议
目录 导言 功能简介 本地授权列表 类型 IdToken IdTagInfo 授权状态 协议指令 1、授权 1.1 说明 1.2 Authorize.req 1.3 Authorize.conf 1.4 JSON格式 1.5 代码 2、启动通知 2.1 说明 2.2 BootNotification.req 2.3 BootNotification.conf 2.4 JSON格式 2…...

【数据存储:小端模式和大端模式】
一、引言 在计算机科学中,数据存储模式是指如何将数据存储在计算机内存中的方式。小端模式和大端模式是两种主要的字节序方式,它们决定了字节在内存中的排列顺序。这种字节顺序的选择对于跨平台编程和数据传输至关重要。在这篇博客中,我们将…...

【git】gitlab安装、备份
gitlab官网 官网:官网 中文官网:中文官网 作为一个英文不好的程序员,所以我都去中文网站去看了。下面也是带着大家去走走 安装gitlab 我不想写具体的安装方法,直接去逛网看下面是我的截图。步骤非常详细。 安装文档地址&…...
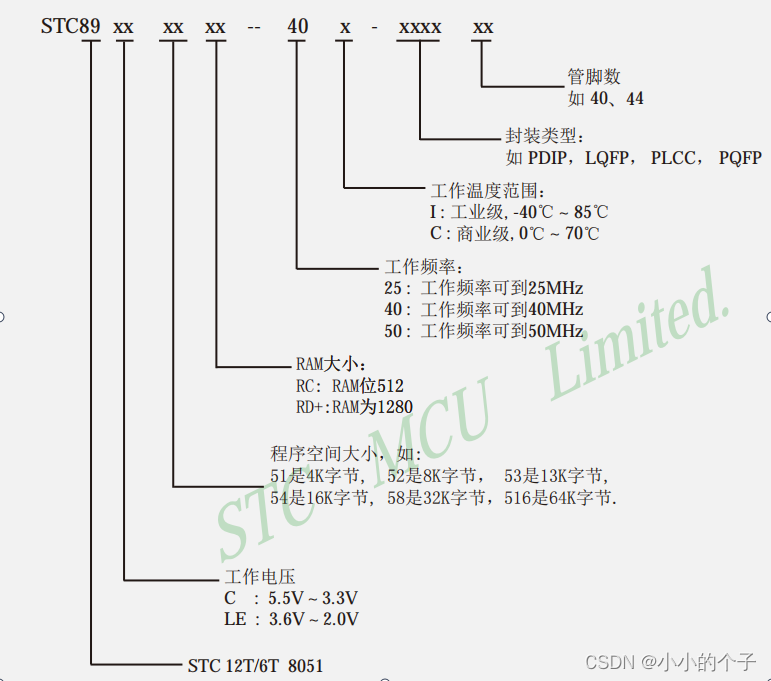
C51--基本认知
单片机基本认知: 1、什么是单片机 单片机是一种集成电路芯片。 把具有数据处理能力的中央处理器 CPU、随机存储器RAM、只读存储器ROM。 多种 I / O 口和中断系统、定时器/计数器等功能(可能还包括显示驱动电路、脉宽调制电路、模拟多路转换器、A/D转换器…...
centos7 安装 mysql 8.0
文章目录 环境介绍一、安装前准备 1.卸载MariaDB 1.1 查看是否安装mariadb1.2 卸载1.3 检查是否卸载干净 2.检查依赖 2.1 查看是否安装libaio2.2 查看是否安装numactl 二、安装MySQL 1.下载资源包 1.1 官网下载1.2 wget下载 2.解压3.重命名4.创建存储数据文件5.设置用户组并赋…...
)
Vue15 计算属性VS监视属性(侦听属性)
计算属性VS监视属性(侦听属性) computed和watch之间的区别: 1.computed能完成的功能,watch都可以完成。 2.watch能完成的功能,computed不一定能完成,例如:watch可以进行异步操作。 两个重要的小…...

快速全面掌握数据库系统核心知识点
快速全面掌握数据库系统核心知识点 一、数据库系统二、三级模式-两层映射三、三级模式-视图四、数据库设计过程五、E-R模型六、关系代数七、规范化理论八、函数依赖九、规范化理论-键十、规范化理论-求候选键十一、规范化理论-范式十二、规范化理论-第一范式十三、规范化理论-第…...

学习笔记 | 音视频 | 推流项目框架及细节
推流项目: 跑起来项目,再调,创造问题,注意项目跑起来包括哪些步骤 前期准备:环境的配置 依赖库要交叉编译,编译还需注意依赖的库对应的头文件(注意是绝对路径还是相对路径) Rv1126_lib、arm_libx264、arm_libx265、arm_libsrt、arm32_ffmpeg_srt、arm_openssl Ubuntu搭…...
拓扑几何学
目录 一,欧拉定理 1,平面图论图 2,单连通多面体 3,一般多面体 一,欧拉定理 1,平面图论图 在一个联通无向图中,点数-边数面数 1 如: 7-126 1 如果把最外面的五边形外面也算…...

1.12.C++项目:仿muduo库实现并发服务器之LoopThreadPool模块的设计
文章目录 一、LoopThreadPool模块二、实现思想(一)功能(二)意义(三)功能设计 三、代码 一、LoopThreadPool模块 1.线程数量可配置(0或多个) 2. 对所有的线程进行管理,其…...

SpringBoot介绍
一、什么是SpringBoot 在使用传统的Spring去做Java EE(Java Enterprise Edition)开发中,大量的 XML 文件存在于项目之中,导致JavaEE项目变得慢慢笨重起来,繁琐的配置和整合第三方框架的配置,导致了开发和部…...

2022最新版-李宏毅机器学习深度学习课程-P17 卷积神经网络CNN
一、CNN 用于图像分类 需要图片大小统一 彩色图像分为R G B 三层,展平后首尾相接 值代表着颜色的强度 图像识别中不需要全连接的,参数太多了 观测1:通过判断多个小局部图像就能判断出图片标签 感受野的定义 简化1 感受野可以重叠ÿ…...
)
从命令行到自动化:用xrandr和Bash脚本打造你的Linux多屏工作流(附常用场景脚本)
从命令行到自动化:用xrandr和Bash脚本打造你的Linux多屏工作流 在Linux系统中管理多显示器配置,xrandr无疑是最强大的命令行工具之一。但每次手动输入复杂的xrandr命令来调整显示器布局,对于追求效率的高级用户来说,无疑是一种时间…...

数据可视化:使用D3.js创建交互式图表
数据可视化:使用D3.js创建交互式图表 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊数据可视化这个话题。作为一个全栈开发者,我经常需要将复杂的数据以直观的方式展示给用户。D3.js是一个功能强大的数据可视化库&am…...

Vivado工程实战:在ZCU102上配置MIG控制器时,SLEW属性设置成SLOW还是FAST?
Vivado工程实战:ZCU102平台MIG控制器SLEW属性深度解析 在Xilinx ZCU102开发板上进行DDR4接口设计时,MIG控制器的配置往往成为项目成败的关键。许多工程师能够顺利完成基础配置,却在面对诸如SLEW属性这类"细微"参数时陷入选择困境。…...

如何快速完成Windows系统部署:高效自动化工具完整指南
如何快速完成Windows系统部署:高效自动化工具完整指南 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat Wind…...

AI驱动个人网站生成器:基于Next.js与OpenAI的配置化数字名片
1. 项目概述:一个AI驱动的个人数字名片最近在折腾个人品牌和在线展示,发现了一个挺有意思的开源项目:zachlagden/iamjarvis.xyz。这本质上是一个基于AI的个人网站生成器,或者说,是一个高度定制化的“数字名片”。它的核…...
:数据集版本管理实战,保证每次训练数据可追溯、可回滚)
Pytorch图像去噪实战(九十三):数据集版本管理实战,保证每次训练数据可追溯、可回滚
Pytorch图像去噪实战(九十三):数据集版本管理实战,保证每次训练数据可追溯、可回滚 一、问题场景:模型效果变好了,但不知道用了哪批数据训练 图像去噪项目进入迭代阶段后,数据会不断变化: 新增用户反馈样本 新增真实噪声数据 删除低质量图片 加入OCR场景样本 加入低光…...

Lyrebird常见问题排查手册:解决无法启动和音频延迟的终极方案
Lyrebird常见问题排查手册:解决无法启动和音频延迟的终极方案 【免费下载链接】lyrebird 🦜 Simple and powerful voice changer for Linux, written with Python & GTK 项目地址: https://gitcode.com/gh_mirrors/lyr/lyrebird Lyrebird是一…...

扔掉KVM切换器!GitHub 25.7K Star的Deskflow:用一套键鼠无缝控制多台电脑的软件KVM方案
两台电脑两套键鼠,桌面杂乱、切换繁琐,硬件KVM切换器又贵得离谱?Deskflow 是一款开源跨平台的软件KVM方案,它允许用一套键鼠无缝穿梭于不同设备之间,让一台电脑的鼠标光标直接“穿越”到另一台电脑的屏幕上。本文将从技…...

嵌入式Python库CI/CD实战:Travis CI自动化测试与发布
1. 项目概述与核心价值 如果你正在维护一个开源项目,或者在一个小团队里负责核心模块的开发,那么你一定对“这次改动会不会把别人的代码搞坏”这个问题感到头疼。尤其是在嵌入式开发领域,比如我们常用的CircuitPython库,代码最终要…...

SQL 中 OR 与 UNION ALL选择指南
一句话总结普通小表、无索引场景:用 OR 更简单、代码更短大表、有索引场景:用 UNION ALL 性能远优于 OR需要去重:必须用 UNION(性能比 UNION ALL 差)核心区别只扫描一次表 / 索引数据库需要同时判断两个条件致命问题&a…...