性能超越 Clickhouse | 物联网场景中的毫秒级查询案例
1 物联网应用场景简介
物联网(Internet of Things,简称 IoT)是指通过各种信息传感、通信和 IT 技术来实时连接、采集、监管海量的传感设备,从而实现对现实世界的精确感知和快速响应,继而实现自动化、智能化管理。在查询 IoT 设备状态的场景下,吞吐量和时延是两个重要的性能指标。
在工业物联网中,常见有以下几种设备时序数据的查询需求:
- 案例1:查询某个设备最近的记录
- 案例2:查询某个租户所有设备的最近一条记录
- 案例3:查询某个设备最近5分钟的统计信息
- 案例4:查询某个设备最近一天的秒级数据
本教程通过一个工业物联网的案例,来演示 DolphinDB 的序列查询性能,并对比测试了 DolphinDB TSDB 引擎、OLAP 引擎,以及 ClickHouse MergeTree 引擎在上述查询案例上的时延指标。总体来说,DolphinDB TSDB 引擎的性能(时延)对比 DolphinDB OLAP 引擎和 ClickHouse MergeTree 引擎有显著优势。
2 案例数据准备
2.1 数据集说明
本教程参考了某工业物联网 SaaS 平台服务商的数据集,模拟并使用一份高度仿真的数据。该SaaS服务商的主要业务是监控各个地区的噪声情况。表结构如下:
| 序号 | 字段名称 | 字段类型 | 注释 |
|---|---|---|---|
| 1 | tenantId | INT | 租户ID |
| 2 | deviceId | INT | 设备ID |
| 3 | soundPressureLevel | DOUBLE | 声音分贝 |
| 4 | soundPowerLevel | DOUBLE | 声音功率值 |
| 5 | ts | TIMESTAMP | 数据采集时间戳 |
| 6 | date | DATE | 日期 |
一行数据包含租户 ID、设备 ID、声压、噪声功率、采集时间戳和日期共计 6 列数据。每行记录占用 36 字节。该案例数据包含100 个租户,每个租户管理 100 个噪声监控设备,记录了从 2022-01-01 至 2022-01-12,12亿的噪声数据,共计 40G。
2.2 库表设计及数据模拟
使用 DolphinDB TSDB 引擎,创建一个名为 NoiseDB 的数据库,存储噪声数据。TSDB 引擎是 DolphinDB 自 2.00 版本起,专门为物联网场景设计研发的数据存储引擎,具备优秀的写入和序列查询性能。
在噪声监控的 SaaS 服务中,较为频繁的查询场景是以租户为维度,查询某一天某个设备的状态信息。因此设计 noise 表按日期、租户 ID 进行分区,可以有效利用分区剪枝。同时使用区分度较高的设备 ID 和数据采集时间戳作为排序键(查询索引),使查询时能够快速定位对应设备的数据,提升查询性能。具体实现脚本如下。
db1 = database(,VALUE,1000..2000)
db2 = database(, VALUE, 2022.01.01..2022.12.30) // TSDB for iot
dbNoise = database("dfs://NoiseDB",COMPO,[db1,db2], engine="TSDB") create table "dfs://NoiseDB"."noise"(tenantId INT,deviceId INT,soundPressureLevel INT,soundPowerLevel DOUBLE,ts TIMESTAMP,date DATE
)
partitioned by tenantId, date
sortColumns=[`deviceId,`ts]库表创建完成后,模拟 2022-01-01 至 2022-01-12 的数据,具体代码详见附录 DolphinDB 脚本。
可以通过 SQL 查询验证下数据集大小:
select count(*) from loadTable(database("dfs://NoiseDB"),"noise") where date between 2022.01.01:2022.01.102> 1260010000导入完成后,每个分区下生成3个level 0 file,未满足自动合并条件(大于等于10个 levelFile),需要进行手动合并。
chunkIds = exec chunkId from getChunksMeta() where type=1
for (x in chunkIds) {triggerTSDBCompaction(x)
}完成后将案例数据导出数据至 csv 文件,以便后续导入 OLAP 引擎、ClickHouse。在 ClickHouse 中使用OPTIMIZE TABLE noise 合并下 mergeTree。具体过程参照附录 ClickHouse 脚本。
3 SQL 查询
在 DolphinDB 中,可以使用 SQL 快速实现4个设备状态查询需求,并且代码十分简洁。
- 案例1:查询某个设备最近的100条记录:
noise = loadTable(database("dfs://NoiseDB"),"noise")
select * from noise
where date=2022.01.01 and tenantId=1055 and deviceId=10067
order by ts desc
limit 100# timer(10) select ...
Time elapsed: 24.33 ms脚本的 where 条件语句中指定了分区列 date 和 tenantId 进行过滤,便于 DolphinDB 系统通过分区剪枝快读定位到对应的分区。同时指定了数据库的 sort key (deviceId) 作为过滤字段,利用 TSDB 的索引机制,可以快速定位到数据块,并按时间顺序取回最新的100条记录。平均一次查询耗时 2ms,未命中缓存的首次查询耗时 14ms。
- 案例2:查询某个租户所有设备最新状态
noise = loadTable(database("dfs://NoiseDB"),"noise")
select * from noise
where date=2022.01.01 and tenantId=1055
context by deviceId
csort ts desc
limit 1# timer(10) select ...
Time elapsed: 246.619 ms该脚本在 where 条件语句中同样指定了分区列以快速定位到对应的数据分区。通过 context by 子句来根据设备 ID 将数据进行分组,每组数据通过 csort 子句按时间倒序排列(考虑到物联网存在消息乱序的情况,必须使用csort将数据按采集时间排序)。使用 limit 1 获取每个窗口内的最新的一条记录,从而获取该租户当日所有设备的最新状态。平均一次查询耗时 25ms,首次查询耗时 121ms。
- 案例3:查询某个设备5分钟内的噪声统计值
noise = loadTable(database("dfs://NoiseDB"),"noise")
selectmin(ts) as startTs,max(ts) as endTs,max(soundPressureLevel),avg(soundPressureLevel),max(soundPowerLevel) ,avg(soundPowerLevel)
from noise
where date=2022.01.01 and tenantId=1055 and deviceId=10067 and ts between 2022.01.01T00:50:15.518:2022.01.01T00:55:15.518
group by tenantId, deviceId# timer(10) select ...
Time elapsed: 22.168 ms该脚本首先根据 where 指定的过滤条件定位并扫描数据块,取出对应时间段的数据,并按 tenantId, deviceId 进行聚合计算,以获取声音分贝、功率的统计值。平均一次查询耗时 2ms,首次查询耗时 13ms。
- 案例4:查询某个设备最近一天的明细数据
noise = loadTable(database("dfs://NoiseDB"),"noise")
select *
from noise
where date=2022.01.01 and tenantId=1055 and deviceId=10067
order by ts# timer(10) select ...
Time elapsed: 23.261 ms该脚本首先根据 where 指定的过滤条件定位并扫描数据块,取出对应时间段的明细数据,并按采集时间排序。平均一次查询耗时 2ms,首次查询耗时 16ms。
注:首次查询指未命中数据库缓存及操作系统缓存的查询。
4 对比测试
进一步测试 DolphinDB TSDB 引擎与 OLAP 引擎,以及 ClickHouse MergeTree 引擎在上述数据集的时序查询性能。测试过程中尽可能地保持环境变量相同,以保证科学有效。具体测试脚本详见附录。
4.1 测试环境
- 测试机器配置
操作系统:CentOS 7
CPU: 2 cores
内存:10 G
磁盘:SSD
- 核心测试参数
对测试中影响性能的关键参数,保持对等一致。
| 软件信息 | 核心参数 | 库表设计 |
|---|---|---|
| DolphinDB:2.00.6 单节点 | memSize=8G TSDB引擎 / OLAP引擎 | partitioned by tenantId, datesortColumns = [deviceId,ts] |
| ClickHouse:22.6.1 单节点 | max_server_memory_usage=8GMergeTree引擎 | partition by tenantId, dateorder by deviceId, ts |
测试时,DolphinDB 和 ClickHouse 均采用单节点,并分配 8G 最大内存。在引擎方面,DolphinDB TSDB 引擎,ClickHouse MergeTree 引擎的内部实现都采用了 LSM-tree。并保持库表设计完全一致。
- 时间衡量标准
由于端到端的时间,容易受到网络抖动和客户端实现性能的影响,因此本次测试的测量时间设定为从查询引擎接收到请求至计算出结果为止。
4.2 测试结果
三者的具体测试结果为下表,表中数值为平均耗时/首次查询耗时(单位 ms),平均耗时的计算逻辑为:
平均耗时 = ( 首次耗时 + 9次缓存命中耗时 )/ 10
| 测试用例 | 场景 | DolphinDB TSDB | DolphinDB OLAP | ClickHouse |
|---|---|---|---|---|
| case1 | 查询某个设备最新100 条记录 | 2 / 14 | 34 / 51 | 14 / 150 |
| case2 | 查询某个租户所有设备的最新状态 | 25 /121 | 62 / 170 | 73 / 400 |
| case3 | 查询某个设备 5min的噪声统计值 | 2 / 13 | 15 / 136 | 12 / 82 |
| case4 | 查询某个设备最近一天的明细数据 | 2 / 16 | 24 / 220 | 22 / 200 |
可以看出,OLAP 引擎和 ClickHouse 在不同的查询场景下性能各有其优势和劣势。
而 TSDB 引擎性能均优于 ClickHouse,在相对复杂的点查场景性能差距更大。在场景4下 ,DolphinDB TSDB 引擎比 ClickHouse 的性能高 12.5 倍,首次查询高13倍。在该场景中,TSDB 引擎需要读取对应设备的10000条记录,压缩后的存储大小约为90K。存储在6个连续的Block中,读取效率非常高效。而 ClickHouse 则是 scan 了该分区下1000000条记录的数据块,因此两者的首次查询性能差距较大,而缓存后的性能差距主要取决于两者在计算性能上的差别 。
5 总结
DolphinDB TSDB 引擎在物联网场景有着卓越的点查性能,可以以毫秒级延时迅速响应设备的状态信息,其性能更优于 ClickHouse 的 MergeTree 引擎。
6 附录
- DolphinDB 脚本
- ClickHouse 脚本
相关文章:
性能超越 Clickhouse | 物联网场景中的毫秒级查询案例
1 物联网应用场景简介 物联网(Internet of Things,简称 IoT)是指通过各种信息传感、通信和 IT 技术来实时连接、采集、监管海量的传感设备,从而实现对现实世界的精确感知和快速响应,继而实现自动化、智能化管理。在查…...

05、SpringBoot 集成 RocketMQ
目录 SpringBoot集成RocketMQ消息发送三种方式1、同步消息producer-springboot创建项目添加依赖配置文件同步消息发送代码启动类Test类 comsumer-springboot创建项目添加依赖配置文件同步消息消费代码 2、异步消息生产者消费者 3、一次性消息生产者消费者 消息消费两种方式1、集…...
PR2023中如何导入字幕
PR中如何导入字幕 方法一: 点开文本,字幕,新建字幕分段(点击右上角…三个点) 键入调整内容 方法二 点开基本图形,编辑,调整,拖动位置。...

读书笔记--华为数据之道有感
通过研读华为数据之道,了解到华为作为一家非数字原生企业,其业务涵盖研发、营销、制造、供应、采购、服务等,业务相当复杂。因此华为在开展数据治理过程中明确了由谁来对数据负责,特别是对数据质量负责,明确了数据质量的衡量或度量指标,并成立了数据管理部,确定其职能定…...

汽车数据安全事件频发,用户如何保护隐私信息?
面对日益增多的汽车数据安全事件,对于广大用户来说,有没有既廉价又安全的解决方案? 频发的汽车数据安全事件 随着汽车“新四化”大潮的来临,汽车用户从电动化、网联化、智能化、共享化中切实体验到了越来越多的便利,各…...

Redis主从复制流程
前言 Redis 支持部署多节点,然后按照 1:n 的方式构建主从集群,即一个主库、n 个从库。主从库之间会自动进行数据同步,但是只有主库同时允许读写,从库只允许读。 搭建主从复制集群的目的: 从库可用于容灾备份从库可以…...
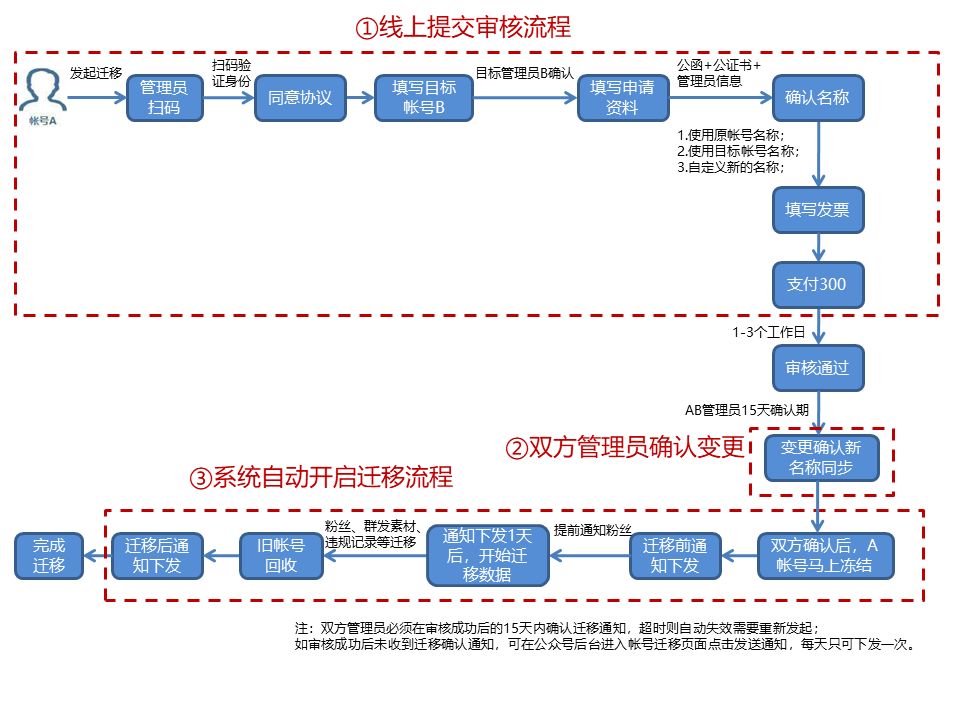
微信公众号如何变更为订阅号?
公众号迁移有什么作用?只能变更主体吗?大家都知道,微信公众号是不支持直接变更主体的;但是很多情况下,我们又不得不进行账号主体的更换;这时候,我么就可以通过账号迁移功能,将A公众号…...

竞赛选题 深度学习YOLO抽烟行为检测 - python opencv
文章目录 1 前言1 课题背景2 实现效果3 Yolov5算法3.1 简介3.2 相关技术 4 数据集处理及实验5 部分核心代码6 最后 1 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 基于深度学习YOLO抽烟行为检测 该项目较为新颖,适合作为竞赛课…...

mysql利用mysqldump方式搭建主从
背景:线上环境在主库不停服的情况下,利用mysqldump的方式搭建从库。 建议:在主库比较小的情况下(个人建议50G左右),主库不停服可以利用mysqldump搭建从库。如果主库很大,建议利用mysql热备份工…...

如何保护IP在线隐私,提高网络安全?
在数字时代,我们的在线IP隐私面临着越来越多的威胁。黑客、广告商和第三方机构都试图获取我们的个人信息和浏览习惯。因此,保护您的在线IP隐私至关重要。本文将介绍一些简单但有效的方法,帮助您保护自己的隐私。 使用防关联浏览器:…...

掌握 C++ 编译过程:面试中常见问题解析
C是一种高级编程语言,但是计算机并不能直接理解它。因此,需要将C代码翻译成计算机可以理解的机器语言。这个过程就是编译过程,是C程序从源代码到可执行文件的转换过程,包括预处理、编译、汇编和链接四个阶段 预处理 在编译器开始…...

了解Qt QScreen的geometry ,size
目的 了解qt 对于屏幕的size, geometry含义, 更能有效实现最大化, 向下还原逻辑操作 Test 目前我有两个屏 ,1920x1080, 3840*2160. 检测当前程序所在screen(1920x1080)下属性 int screenNum…...
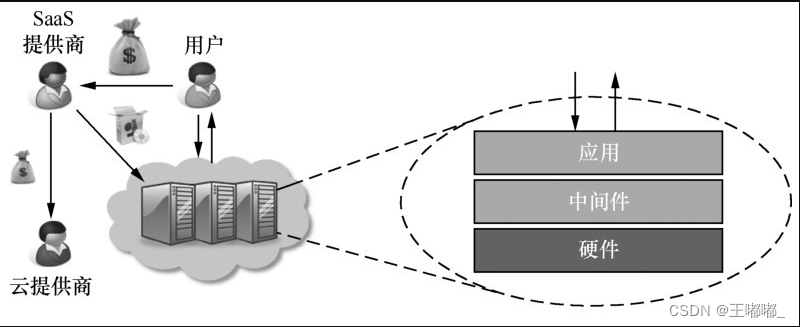
云安全—云计算基础
0x00 前言 学习云安全,那么必然要对云计算相关的内容进行学习和了解,所以云安全会分为两个部分来进行,首先是云计算先关的内容。 0x01 云计算 广泛传播 云计算最早大范围传播是2006年,8月,在圣何塞【1】举办的SES&a…...

【ARM Coresight Debug 系列 16 -- Linux 断点 BRK 中断使用详细介绍】
文章目录 1.1 ARM BRK 指令1.2 BRK 立即数宏定义介绍1.3 断点异常处理流程1.3.1 el1_sync_handler1.3.2 el1_dbg 跟踪 1.4 debug 异常处理函数注册1.4.1 brk 处理函数的注册 1.1 ARM BRK 指令 ARMv8 架构的 BRK 指令是用于生成一个软件断点的。当处理器执行到 BRK 指令时&…...
的作用-基础篇)
Rust星号(*)的作用-基础篇
在Rust中,*符号具有多种不同的用途,具体取决于它的使用方式。以下是Rust中*常见的用法. 1.解引用指针 当作为一元运算符放在指针变量之前时,*用于解引用指针并访问它指向的值。在Rust中,通常更推荐使用引用而不是原始指针。引用…...

企业该如何选择数字化转型工具?
对于希望在当今快速发展的商业环境中增强运营、提高效率并保持竞争力的公司来说,选择正确的数字化转型工具是一项关键决策。以下是选择数字化转型工具的关键步骤和注意事项: 1.定义业务目标: 清楚地阐明您的业务目的和目标。了解您希望通过数…...

element ui 中 el-button重新渲染后disabled属性失效
调试发现:disabled绑定的值和显示没有保持一致,发现是disabled属性失效 解决方式: 给标签添加key 比如:key“isOldVersion” <el-form-item><el-button type"primary" style"margin-left: 100px;" click"…...

WebRTC AIMD算法用处
WebRTC使用AIMD(Additive Increase Multiplicative Decrease)算法来进行码率控制。 在WebRTC中,码率控制的目标是优化音视频传输的质量和稳定性,以适应网络状况的变化。具体而言,AIMD算法通过监测网络的拥塞情况&…...

迁移kubelet、docker和containerd工作目录
文章目录 问题背景迁移Docker停止 Docker 服务修改配置移动文件重新启动 Docker 服务 containerd停止服务修改配置移动文件重新启动服务 kubelet(遇到问题待解决)停止服务修改配置移动文件(遇到问题待解决)重新启动服务 使用的版本…...

Go 重构:尽量避免使用 else、break 和 continue
今天,我想谈谈相当简单的事情。我不会发明什么,但我在生产代码中经常看到这样的事情,所以我不能回避这个话题。 我经常要解开多个复杂的 if else 结构。多余的缩进、过多的逻辑只会加深理解。首先,这篇文章的主要目的是让代码更透…...
)
文献综述怎么写?研一萌新用Scholaread三天搞定开题文献综述(附100+篇文献整合方法)
开题在即,你面对电脑屏幕上50个PDF发呆,复制粘贴了20页摘要却被导师批"毫无逻辑"。问题不在于你不努力,而在于缺少系统化的文献综述工具链。本文拆解用Scholaread完成高质量文献综述的完整流程,让你从"不知道怎么开…...

工业级Linux超长期支持方案:RZ/G平台与CIP SLTS内核实战解析
1. 项目概述:当工业设备遇上超长待机的Linux在工业自动化、能源控制、轨道交通这些领域摸爬滚打过的嵌入式开发者,心里都清楚一个“老大难”问题:软件的生命周期,尤其是操作系统的维护周期,远跟不上硬件的服役年限。一…...
—— 从漏检比例到多项式选择的工程权衡)
CRC校验码的检错性能(一)—— 从漏检比例到多项式选择的工程权衡
1. CRC校验码的检错性能基础 当你用手机发送一条消息,或者从硬盘读取文件时,数据在传输过程中可能会出错。这时候就需要一种"数据质检员"来检查错误,CRC校验码就是其中最常用的一种。它就像快递包裹上的防拆封条,能告诉…...

Seed-VC语音克隆指南:5分钟实现零样本实时语音转换的终极方案
Seed-VC语音克隆指南:5分钟实现零样本实时语音转换的终极方案 【免费下载链接】seed-vc zero-shot voice conversion & singing voice conversion, with real-time support 项目地址: https://gitcode.com/GitHub_Trending/se/seed-vc 你是否曾想过&…...

3分钟解锁QQ音乐加密文件:qmc-decoder终极使用指南
3分钟解锁QQ音乐加密文件:qmc-decoder终极使用指南 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾经遇到过这样的烦恼?在QQ音乐下载的歌曲…...

Perplexity学校信息检索终极手册:覆盖K12/高职/高校的12类典型场景+27个可复用Prompt模板
更多请点击: https://codechina.net 第一章:Perplexity学校信息检索终极手册导论 在教育数字化加速演进的今天,高校师生亟需一种高效、可信且语义精准的信息获取方式。Perplexity 作为融合实时网络检索与大语言模型推理能力的智能问答平台&…...

从开发板到工业边缘计算平台:UP Board二代的硬件解析与应用实战
1. 项目概述:从“开发板”到“边缘计算平台”的认知跃迁最近在整理手头的嵌入式设备,翻出了这块研扬的UP Board二代。说实话,第一次拿到它的时候,我下意识地还是把它归类为“一块性能不错的x86开发板”,就像树莓派之于…...

3个真实场景告诉你,Avogadro 2分子建模软件如何改变化学研究方式
3个真实场景告诉你,Avogadro 2分子建模软件如何改变化学研究方式 【免费下载链接】avogadroapp Avogadro is an advanced molecular editor designed for cross-platform use in computational chemistry, molecular modeling, bioinformatics, materials science, …...

别再只调库了!手写KNN算法识别MNIST数字,从距离计算到加权投票的完整实现与性能对比
从零构建KNN算法:MNIST手写数字识别的底层实现与深度优化 在机器学习入门阶段,K最近邻(KNN)算法往往是第一个接触的经典分类方法。大多数教程止步于调用sklearn的几行代码,却忽略了算法底层的精妙设计。本文将带您从数…...

前端工程化19:微前端架构实战,大型中台项目拆分落地方案
前端工程化19:微前端架构实战,大型中台项目拆分落地方案 文章目录 前端工程化19:微前端架构实战,大型中台项目拆分落地方案 前言 一、微前端核心概念 1. 什么是微前端 2. 核心优势 3. 企业主流使用场景 二、主流微前端方案选型对比 三、整体项目架构划分 四、实战搭建 Qian…...