Flink日志收集到数据库/kafka
引言
我们做项目过程中发现flink日志不同模式启动,存放位置不同,查找任务日志很不方便,具体问题如下:
- 原始flink的日志配置文件log4j-cli.properties
appender.file.append = false,取消追加,直接覆盖掉上一次提交任务的信息。这里改为true解决。 - application模式启动任务失败/取消后,无法找到错误日志,需要用命令查找对应appId
yarn application -appId <Application ID> - flink session模式重启集群,导致之前提交任务信息全部删除,开启历史服务器:
historyserver.archive.fs.dir: hdfs:///completed-jobs/,其他配置参考官方文档
这些问题虽然都找到了对应的解决办法,但是仍然很不方便。所有我决定研究flink的log配置文件,将所有log写入数据库/kafka中。
在查找资料中发现log4j2配置都是xml方式,而flink是以properties的配置方式,网上也没有properties方式配置JDBCAppender的资料。注:log4j2在低版本是不支持properties的
log4j2.properties写数据库
先看官网,这里介绍了flink conf目录下的每个配置文件的作用,这里我们针对log4j2修改,logback 这里没有涉及,可以自行查看官网配置。
我们准备收集到所有相关日志,所以这四个文件都需要配置JDBCAppender。

我这里是连接的是mysql,将mysql-connector-java-8.0.28.jar放在lib目录下,
官方支持一下四种模式,以DriverManager为示例

rootLogger.appenderRef.jdbc.ref=JDBCAppender
appender.jdbc.name=JDBCAppender
appender.jdbc.type=JDBC
appender.jdbc.tableName=flink_logs
appender.jdbc.connectionSource.type=DriverManager
appender.jdbc.connectionSource.connectionString=jdbc:mysql://ip:port/database
appender.jdbc.connectionSource.userName=root
appender.jdbc.connectionSource.password=root
appender.jdbc.columnConfigs1.type=Column
appender.jdbc.columnConfigs1.name=source
appender.jdbc.columnConfigs1.pattern=%c
appender.jdbc.columnConfigs2.type=Column
appender.jdbc.columnConfigs2.name=type
appender.jdbc.columnConfigs2.pattern=%p
appender.jdbc.columnConfigs3.type=Column
appender.jdbc.columnConfigs3.name=create_time
appender.jdbc.columnConfigs3.pattern=%d{yyyy-MM-dd HH:mm:ss,SSS}
appender.jdbc.columnConfigs4.type=Column
appender.jdbc.columnConfigs4.name=massage
appender.jdbc.columnConfigs4.pattern=%m %throwable
JDBCAppender更多详细配置
log4j2.properties写kafka
将kafka-client.jar放在lib目录下,
官方具体配置说明:
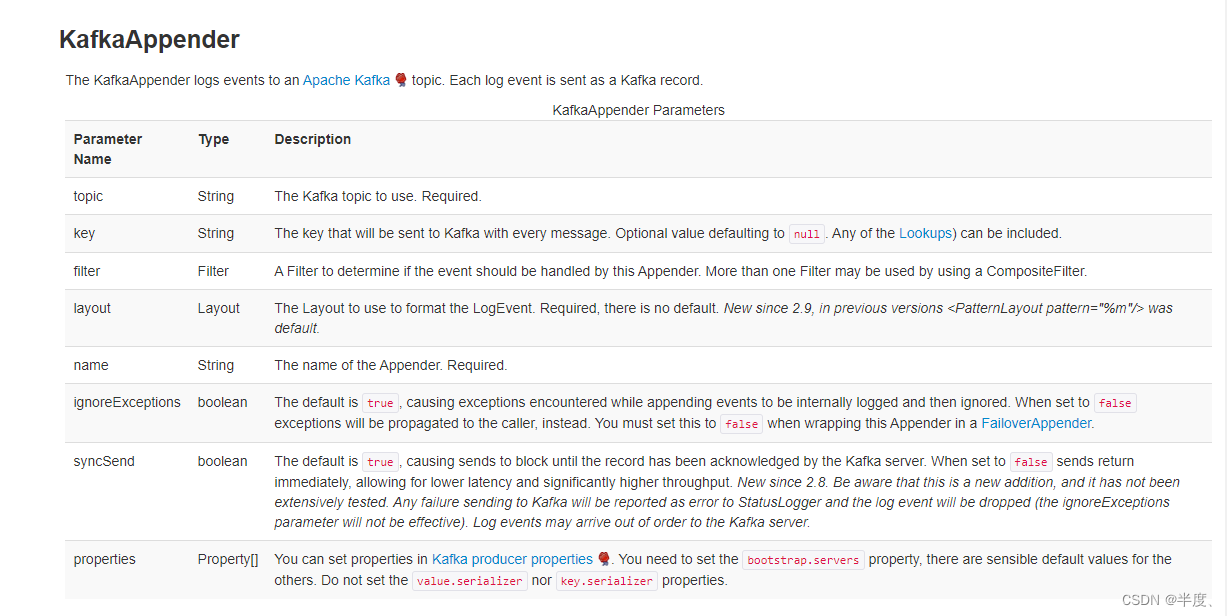
rootLogger.appenderRef.kafka.ref=KafkaAppender
appender.kafka.name=KafkaAppender
appender.kafka.type=Kafka
appender.kafka.syncSend=true
appender.kafka.ignoreExceptions=false
appender.kafka.topic=flink_log_test
appender.kafka.property.type=Property
appender.kafka.property.name=bootstrap.servers
appender.kafka.property.value=ip:9092
appender.kafka.layout.type = PatternLayout
appender.kafka.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
进阶
完成以上操作我们已经可以将日志写入mysql/kafka中了,但是我发现所有日志写入后,无法区分集群,任务分别是那些了,当然可以在配置中每一个配置文件写入不同的表,但是job任务如何区分呢?
我们可以设置环境变量或系统环境变量,让log4j从中获取自定义值
更详细内容参考官方地址

相关文章:
Flink日志收集到数据库/kafka
引言 我们做项目过程中发现flink日志不同模式启动,存放位置不同,查找任务日志很不方便,具体问题如下: 原始flink的日志配置文件log4j-cli.properties appender.file.append false,取消追加,直接覆盖掉上…...

Go项目踩坑:go get下载超时,goFrame框架下的go项目里将vue项目的dist同步打包发布,go项目打包并压缩
Go项目踩坑:go get下载超时,goFrame框架下的go项目里将vue项目的dist同步打包发布,go项目打包并压缩 go get下载超时goFrame打包静态资源vue项目打包gf pack生成go文件 静态资源使用打包发布go项目交叉编译,省略一些不必要的信息通…...

DataCon【签到题】挖矿流量检测
【签到题】挖矿流量检测 文章目录 答案【多选】1. 个人电脑中了挖矿病毒通常有以下哪些表现?【单选】2. 在典型挖矿场景中,矿工和矿池之间目前最常用的通信协议是哪一个?【单选】3. 目前的虚拟货币挖矿场景中,最常采用的是哪种共识…...
Vivado详细使用教程 | LED闪烁示例
文章目录 整体流程第一步:新建工程第二步:设计输入第三步:功能仿真第四步:分析与综合第五步:约束输入第六步:设计实现第七步:下载比特流 整体流程 打开软甲------>新建工程------->设计输…...
一些经典的神经网络(第17天)
1. 经典神经网络LeNet LeNet是早期成功的神经网络; 先使用卷积层来学习图片空间信息 然后使用全连接层来转到到类别空间 【通过在卷积层后加入激活函数,可以引入非线性、增加模型的表达能力、增强稀疏性和解决梯度消失等问题,从而提高卷积…...

Hadoop-HA-Hive-on-Spark 4台虚拟机安装配置文件
Hadoop-HA-Hive-on-Spark 4台虚拟机安装配置文件 版本号步骤hadoopcore-site.xmlhdfs-site.xmlmapred-site.xmlslavesworkersyarn-site.xml hivehive-site.xmlspark-defaults.conf sparkhdfs-site.xmlhive-site.xmlslavesyarn-site.xmlspark-env.sh 版本号 apache-hive-3.1.3-…...

Hutool工具类参考文章
Hutool工具类参考文章 日期: 身份证:...

【 Python ModuleNotFoundError: No module named ‘xxx‘可能的解决方案大全】
Python ModuleNotFoundError: No module named ‘xxx‘可能的解决方案大全 本文主要介绍了Python ModuleNotFoundError: No module named ‘xxx‘可能的解决方案大全,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值&#x…...

eclipse 配置selenium环境
eclipse环境 安装selenium的步骤 配置谷歌浏览器驱动 Selenium安装-如何在Java中安装Selenium chrome驱动下载 eclipse 启动配置java_home: 在eclipse.ini文件中加上一行 1 配置java环境,网上有很多教程 2 下载eclipse,网上有很多教程 ps&…...
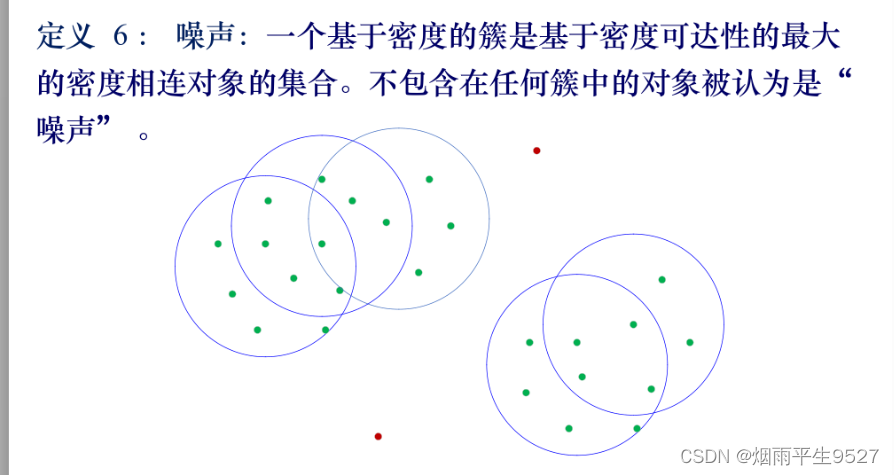
数据挖掘(6)聚类分析
一、什么是聚类分析 1.1概述 无指导的,数据集中类别未知类的特征: 类不是事先给定的,而是根据数据的相似性、距离划分的聚类的数目和结构都没有事先假定。挖掘有价值的客户: 找到客户的黄金客户ATM的安装位置 1.2区别 二、距离和相似系数 …...
在启智平台上安装anconda
安装Anaconda3-5.0.1-Linux-x86_64.sh python版本是3.6 在下面的网站上找到要下载的anaconda版本,把对应的.sh文件下载下来 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/ 把sh文件压缩成.zip文件,拖到启智平台的调试页面 上传到平台上 un…...

棒球省队建设实施办法·棒球1号位
棒球省队建设实施办法 1. 建设目标与原则 提升棒球省队整体竞技水平 为了提升棒球省队整体竞技水平,我们需要采取一系列有效的措施。 首先,我们应该加强对棒球运动的投入和关注。各级政府和相关部门应加大对棒球运动的经费投入,提高球队的…...

架构案例2017(五十二)
第5题 阅读以下关于Web系统架构设计的叙述,在答题纸上回答问题1至问题3.【说明】某电子商务企业因发展良好,客户量逐步增大,企业业务不断扩充,导致其原有的B2C商品交易平台己不能满足现有业务需求。因此,该企业委托某…...

给四个点坐标计算两条直线的交点
文章目录 1 chatgpt42、文心一言3、星火4、Bard总结 我使用Chatgpt4和文心一言、科大讯飞星火、google Bard 对该问题进行搜索,分别给出答案。先说结论,是chatgpt4和文心一言给对了答案, 另外两个部分正确。 问题是:python 给定四…...

从入门到进阶 之 ElasticSearch SpringData 继承篇
🌹 以上分享 从入门到进阶 之 ElasticSearch SpringData 继承篇,如有问题请指教写。🌹🌹 如你对技术也感兴趣,欢迎交流。🌹🌹🌹 如有需要,请👍点赞…...
中文编程开发语言工具编程案例:计时计费管理系统软件连接灯控器编程案例
中文编程开发语言工具编程案例:计时计费管理系统软件连接灯控器编程案例 中文编程开发语言工具编程案例:计时计费管理系统软件连接灯控器编程案例 中文编程系统化教程,不需英语基础。学习链接 https://edu.csdn.net/course/detail/39036...

YOLOv7改进:动态蛇形卷积(Dynamic Snake Convolution),增强细微特征对小目标友好,实现涨点 | ICCV2023
💡💡💡本文独家改进:动态蛇形卷积(Dynamic Snake Convolution),增强细长微弱的局部结构特征与复杂多变的全局形态特征,对小目标检测很适用 Dynamic Snake Convolution | 亲测在多个数据集能够实现大幅涨点 收录: YOLOv7高阶自研专栏介绍: http://t.csdnimg.…...

从文心大模型4.0与FuncGPT:用AI为开发者打开新视界
今天,在百度2023世界大会上,文心大模型4.0正式发布,而在大洋的彼岸,因为大模型代表ChatGPT之类的AI编码工具来势汹汹,作为全世界每个开发者最爱的代码辅助网站,Stack Overflow的CEO Prashanth Chandrasekar…...
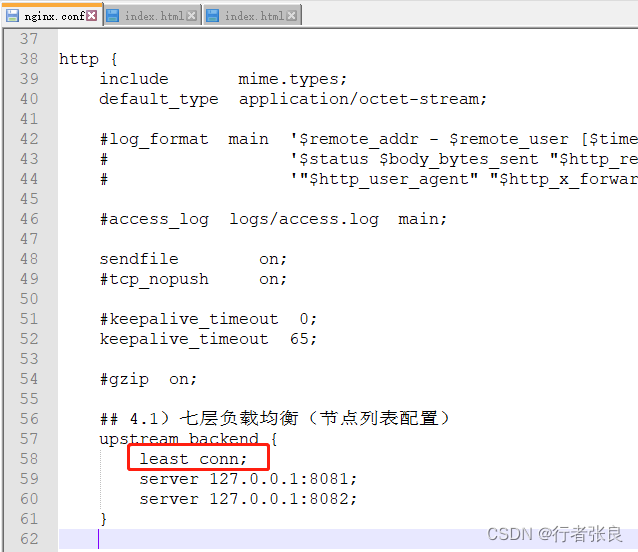
Nginx集群负载均衡配置完整流程
今天,良哥带你来做一个nginx集群的负载均衡配置的完整流程。 一、准备工作 本次搭建的操作系统环境是win11,linux可配置类同。 1)首先,下载nginx。 下载地址为:http://nginx.org/en/download.html 良哥下载的是&am…...

如何生成SSH服务器的ed25519公钥SHA256指纹
最近搭建ubuntu服务器,远程登录让确认指纹,研究一番搞懂了,记录一下。 1、putty 第一次登录服务器,出现提示: 让确认服务器指纹是否正确。 其中:箭头指向的 ed25519 :是一种非对称加密的签名方法…...

当我们谈论“防治养”时,我们谈论的是一种生活方式的重构
一、重新审视“健康”的定义在现代生活的快节奏中,健康常常被简化为一个医学指标,或是年度体检报告上的一串数字。然而,当我们谈论肿瘤“防治养”时,我们谈论的远不止于此。这不是三个孤立的概念,而是一个完整的循环—…...

Linux Idle 调度器的 cpuidle_reflect:Idle 状态统计更新
简介 在 Linux 内核电源管理与调度体系中,CPU Idle(空闲)调度器是实现 CPU 低功耗管理的核心模块,负责在 CPU 无任务可调度时,选择并进入合适的硬件空闲状态(C-state),在性能与功耗…...

高通手机刷机救砖不求人:搞懂这10个关键分区,自己就能救活黑砖
高通手机刷机救砖实战指南:10个致命分区解析与精准修复 当你的爱机突然变成一块"黑砖",屏幕再无反应,甚至连充电指示灯都彻底熄灭时,那种绝望感每个玩机爱好者都深有体会。不同于普通的系统崩溃,黑砖状态意…...
)
TVA智能体范式的工业视觉革命(7)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

SKNet核心机制解析与PyTorch实战:从Split-Fuse-Select到完整网络构建
1. SKNet核心机制解析:从Split-Fuse-Select到多尺度特征融合 SKNet(Selective Kernel Networks)是CVPR 2019提出的创新性网络结构,它在传统卷积神经网络的基础上引入了动态选择机制。这个机制的核心在于让网络能够自适应地选择不同…...


别再只用人体红外了!聊聊24.125GHz微波模块在智能家居中的另类玩法与局限
24.125GHz微波传感模块的智能家居创新应用与工程实践 在智能家居领域,人体感应技术早已从简单的红外探测走向多传感器融合时代。当大多数开发者还在依赖传统PIR红外传感器时,一种成本仅20元左右的24.125GHz微波模块正在小众硬件圈引发讨论。这种原本用于…...

Browser-Use 实战指南:让 AI 自己操控浏览器的 7 个实用场景
Browser-Use 实战指南:让 AI 自己操控浏览器的 7 个实用场景 你打开浏览器,搜索、填表、采集数据、截图、下载文件。这些每天重复的动作,能不能让 AI 替你干? Browser-Use 给了一个相当干脆的答案:把浏览器交给 AI&…...

一文说清:穿透式监管体系、穿透式监管平台、穿透式监管模型
最近这段时间,和不少央国企的财务、风控负责人交流,话题总绕不开穿透式监管。大家共识很强:穿透式监管必须做,也不得不做。穿透式监管建设本身,横跨了三个专业壁垒很高的领域:公司治理与风险管理、企业数字…...

15分钟搞定国标视频监控平台部署,wvp-GB28181-pro让安防系统搭建如此简单!
15分钟搞定国标视频监控平台部署,wvp-GB28181-pro让安防系统搭建如此简单! 【免费下载链接】wvp-GB28181-pro 基于GB28181-2016、部标808、部标1078标准实现的开箱即用的网络视频平台。自带管理页面,支持NAT穿透,支持海康、大华、…...