【文档智能】多模态预训练模型及相关数据集汇总
前言
大模型时代,在现实场景中或者企业私域数据中,大多数数据都以文档的形式存在,如何更好的解析获取文档数据显得尤为重要。文档智能也从以前的目标检测(版面分析)阶段转向多模态预训练阶段,本文将介绍目前一些前沿的多模态预训练模型及相关数据集。
多模要预训练模型导图
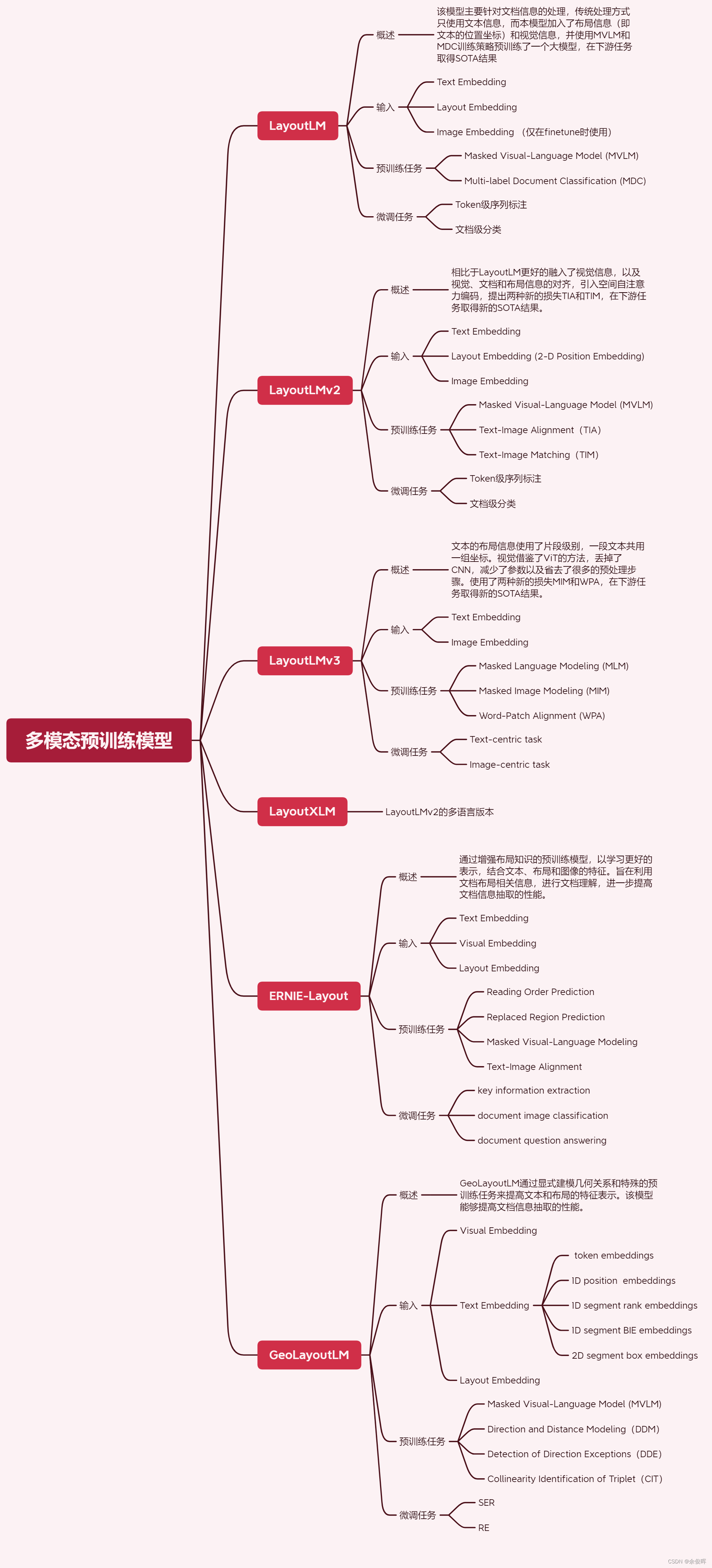
LayoutLM
概述:该模型主要针对文档信息的处理,传统的类Bert模型仅使用文本信息,该模型引入了布局信息(即文本的位置坐标)和视觉信息,并使用MVLM和MDC训练策略进行预训练。
paper:LayoutLM: Pre-training of Text and Layout for Document Image Understanding
link:https://arxiv.org/abs/1912.13318
code:https://github.com/microsoft/unilm/tree/master/layoutlm
模型结构
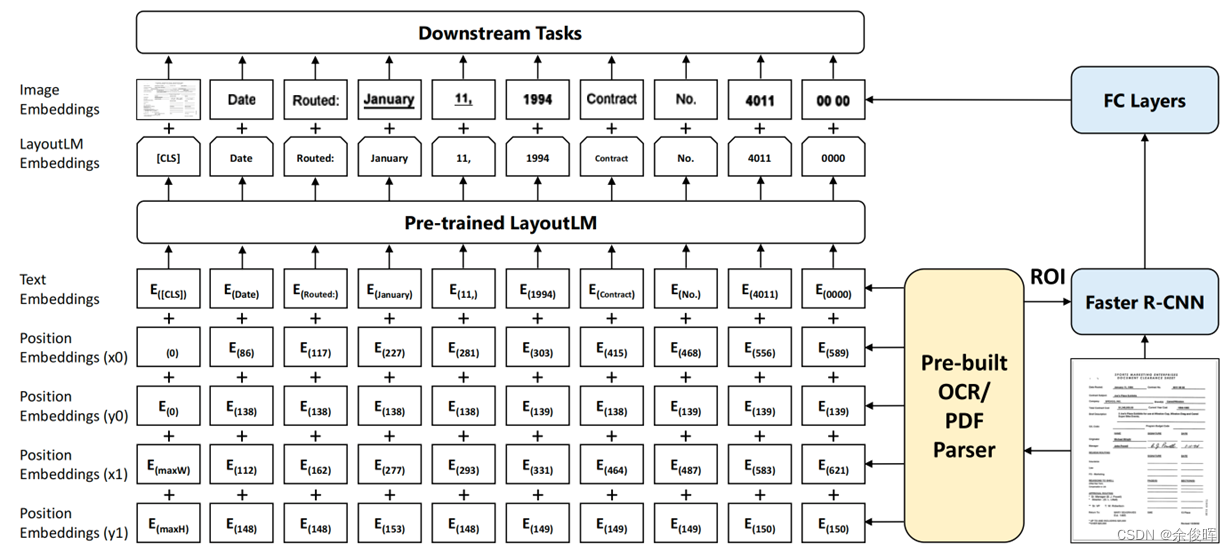
- 文本嵌入:Bert backbone
- 布局嵌入:(1)利用Bert的backbone,增加边界框嵌入( x 0 x_0 x0, y 0 y_0 y0, x 1 x_1 x1, y 1 y_1 y1),其中( x 0 x0 x0 , y 0 y_0 y0)对应于边界框中左上角的位置,( x 1 x_1 x1 , y 1 y_1 y1)表示右下角的位置;(2)[CLS]位置则用整个文本块的边界框坐标;
- 视觉嵌入(仅在finetune阶段使用):(1)用FasterRCNN提取扫描件的视觉特征,将其与bert的输出融合;(2)利用OCR获取文本和对应布局信息;(3)[CLS]使用Faster R-CNN模型来生成嵌入,使用整个扫描的文档图像作为感兴趣区域(ROI);
预训练任务
- Masked Visual-Language Model (MVLM):使用bert的MLM任务MASK掉token,但保留对应的布局信息,借助布局信息和上下文信息预测对应token。
- Multi-label Document Classification (MDC):一个可选策略,旨在对文档进行分类,模型可以对来自不同领域的知识进行聚类,并生成更好的文档级表示
LayoutLMv2
概述:相比于LayoutLM更好的融入了视觉信息,以及视觉、文档和布局信息的对齐,引入空间自注意力编码,提出两种新的损失函数TIA和TIM进行预训练。LayoutLMv1仅在fine-tuning阶段用到视觉特征,pretraining阶段没有视觉特征与文本特征的跨模态交互。Pretraining阶段,提出multi-modal transformer,融合text、layout、visual information;在LayoutLMv1中MVLM基础上,新增text-image alignment与text-image matching两个预训练任务。
paper:LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Understanding
link:https://arxiv.org/abs/2012.14740
code:https://github.com/microsoft/unilm/tree/master/layoutlmv2
模型结构
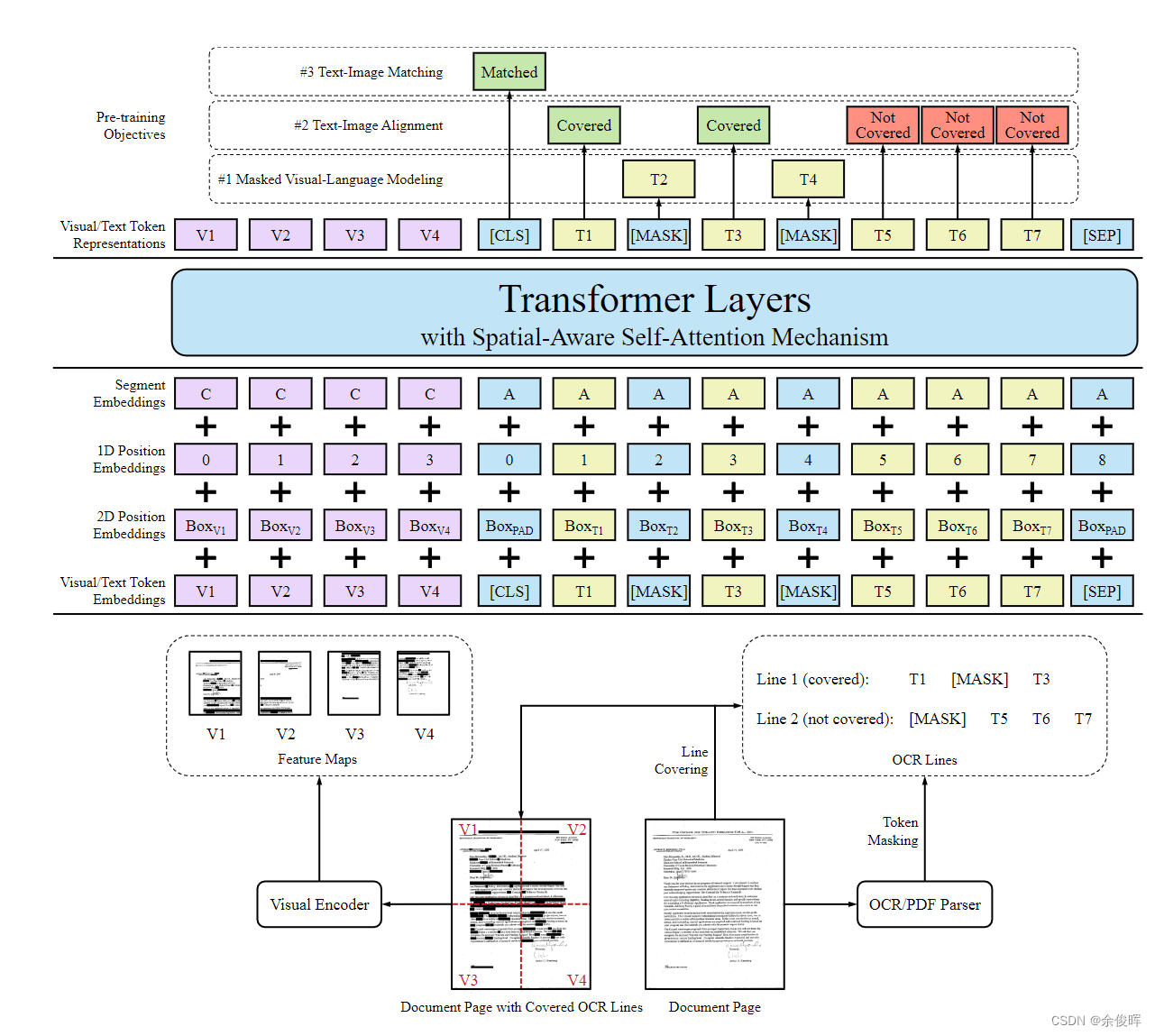
-
文本嵌入:Bert backbone
-
视觉嵌入 :
V i = P r o j ( V i s T o k E m b ( I ) i ) + P o s E m b 1 D ( i ) + S e g E m b ( [ C ] ) V_i=Proj(VisTokEmb(I)_i)+PosEmb1D(i)+SegEmb([C]) Vi=Proj(VisTokEmb(I)i)+PosEmb1D(i)+SegEmb([C])- 视觉特征提取backbone:ResNeXt-FPN
- 将图片统一缩放到224x224大小,经过backbone后平均池化成固定大小WxH(7x7),再展平得到长度为49的序列,再经过一个线性层映射到与文本嵌入相同的维度;
- 额外增加一维位置嵌入,与文本一维位置嵌入共享参数
-
布局嵌入:
-
除边界框嵌入( x 0 x_0 x0, y 0 y_0 y0, x 1 x_1 x1, y 1 y_1 y1)外,还增加宽w和高h嵌入;
-
布局嵌入与LayoutLM中四个坐标相加不同,这里拼接六个位置嵌入为一个输入,每个位置嵌入维度为隐层维度/6;
I i = C o n c a t ( P o s E m b 2 D x ( x m i n , x m a x , w i d t h ) , P o s E m b 2 D y ( y m i n , y m a x , h e i g h t ) ) I_i=Concat(PosEmb2D_x(x_{min},x_{max},width),PosEmb2D_y(y_{min},y_{max},height)) Ii=Concat(PosEmb2Dx(xmin,xmax,width),PosEmb2Dy(ymin,ymax,height)) -
图像经backbone得到长度为49的序列,将其视为把原图切分成49个块,视觉部分的布局嵌入使用每个块的布局信息;
-
对于[CLS], [SEP]和[PAD],布局信息使用(0,0,0,0,0,0)表示;
-
预训练任务
- Masked Visual-Language Model (MVLM):与LayoutLM相同,为了避免视觉信息泄露,在送入视觉backbone之前,将对应掩码token的视觉区域掩盖掉。
- Text-Image Alignment (TIA):作用:帮助模型学习图像和边界框坐标之间的空间位置对应关系。(1)随机选择一些文本行,覆盖对应图像区域;(2)在编码器最后一层设置一个分类层,预测是否被覆盖,分类标签为[Convered]、[Not Convered],计算二元交叉熵损失;当同时被mask和cover时,不计算TIA损失,为了防止学习到mask到cover的映射。
- Text-Image Matching (TIM):将[CLS]处的输出表示输入分类器,以预测图像和文本是否来自同一文档页面。帮助模型学习文档图像和文本内容之间的对应关系。
LayoutLMv3
概述:文本的布局信息使用了片段级别,一段文本共用一组坐标。视觉借鉴了ViT的方法替换CNN,减少了参数以及省去了很多的预处理步骤。使用了两种新的损失MIM和WPA进行预训练。
paper:LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking
link:https://arxiv.org/abs/2204.08387
code:https://github.com/microsoft/unilm/tree/master/layoutlmv3
模型结构
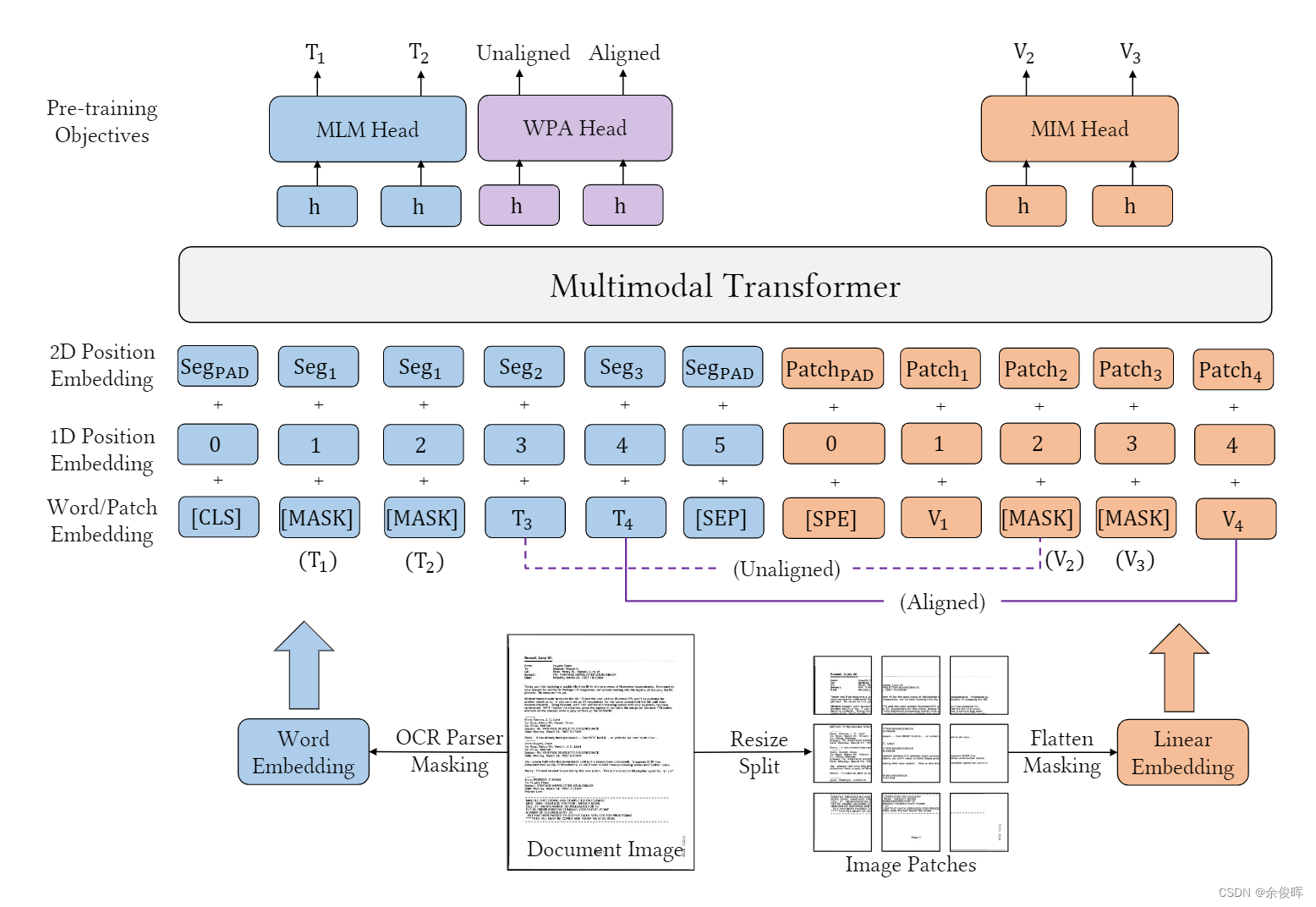
- 文本嵌入:RoBerta backbone
- 视觉嵌入:与layoutLMv2相同,与之前的单词级别的边界框不同,此处使用了片段级别的嵌入,即:块边界框。
- 布局嵌入:不再使用CNN网络,采用类似ViT思想的backbone,将图片切分成一个个的patches。
预训练任务
- Masked Language Modeling (MLM):使用span掩码策略,mask掉30%的文本token,maks的span长度服从泊松分布(λ=3)
- Masked Image Modeling (MIM):
- 用分块掩码策略随机掩盖掉40%的图像token,用交叉熵损失驱动其重建被掩盖的图像区域;
- 图像token的标签来自一个图像tokenizer,通过图像vocab将密集图像的像素转化成离散token,相比于低级高噪声的细节部分,更促进学习高级特征;
- Word-Patch Alignment (WPA):学习文本单词和图像patches之间的细粒度对齐。WPA的目的是预测文本单词的相应图像补丁是否被屏蔽。具体地说,当对应的图像标记也被取消屏蔽时,为未屏蔽的文本标记分配一个对齐的标签[aligned]。否则,将指定一个未对齐的标签[unaligned]。
LayoutXLM
概述:该模型是LayoutLMv2的多语言版本,这里不再详细赘述。
paper:LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding
link:https://arxiv.org/abs/2104.08836
code:https://github.com/microsoft/unilm/tree/master/layoutxlm
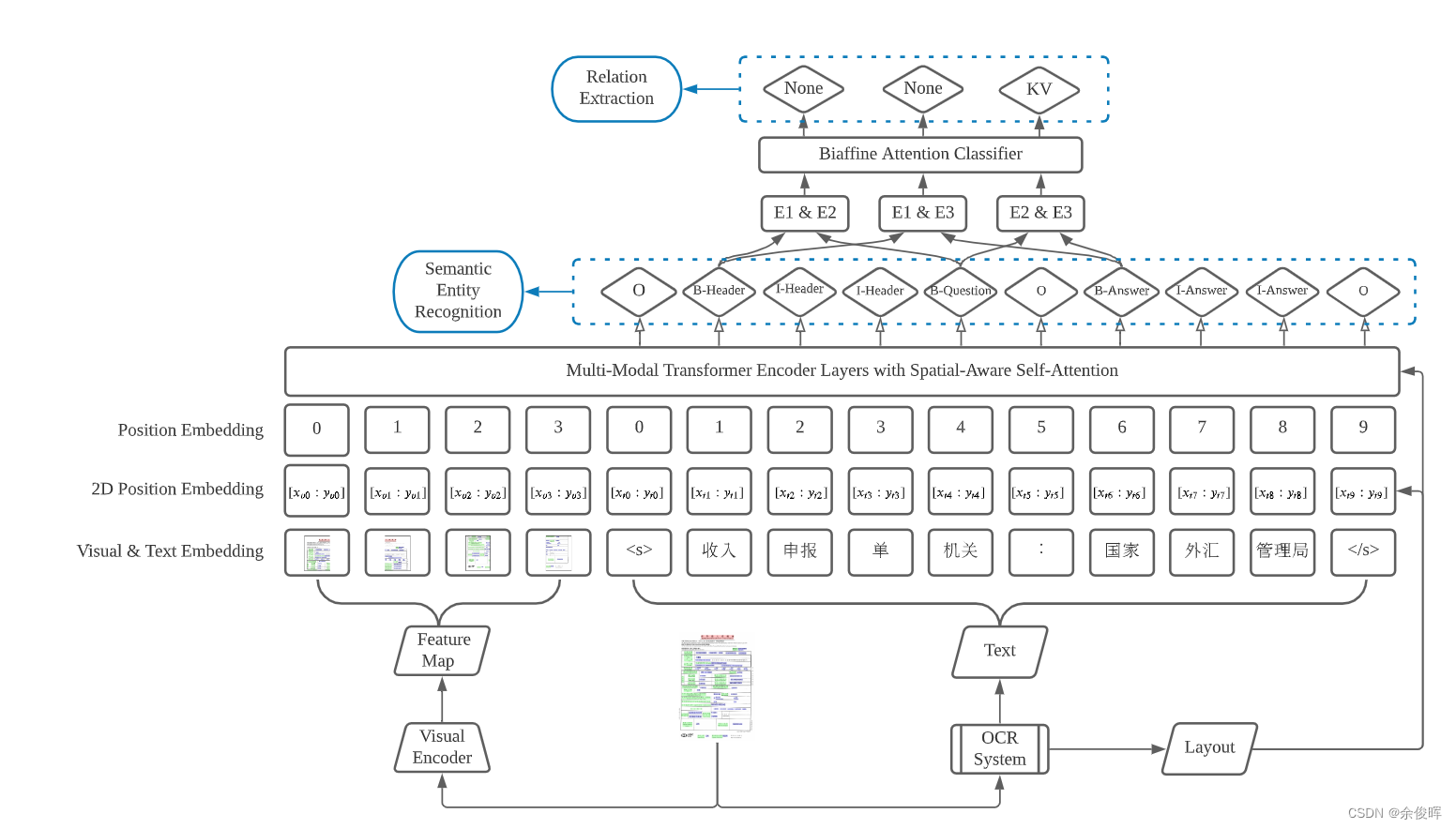
ERNIE-Layout
概述:通过增强布局知识的预训练模型,以学习更好的表示,结合文本、布局和图像的特征。旨在利用文档布局相关信息,进行文档理解,进一步提高文档信息抽取的性能。
paper:ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding
link:https://arxiv.org/abs/2210.06155
code:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout
该模型之前介绍过,详细请移步《文档智能:ERNIE-Layout》
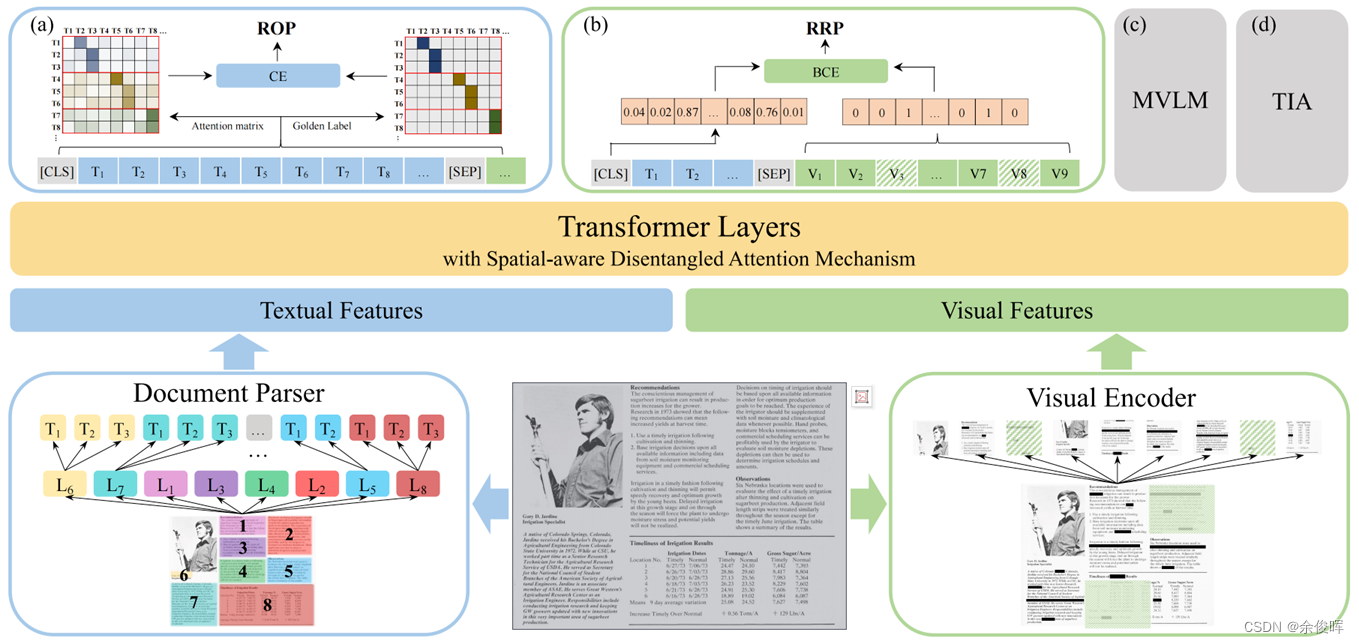
GeoLayoutLM
概述:GeoLayoutLM通过显式建模几何关系和特殊的预训练任务来提高文本和布局的特征表示。该模型能够提高文档信息抽取的性能。
paper:GeoLayoutLM: Geometric Pre-training for Visual Information Extraction
link:https://arxiv.org/abs/2304.10759
code:https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/GeoLayoutLM
该模型之前介绍过,详细请移步《【文档智能】:GeoLayoutLM:一种用于视觉信息提取(VIE)的多模态预训练模型》
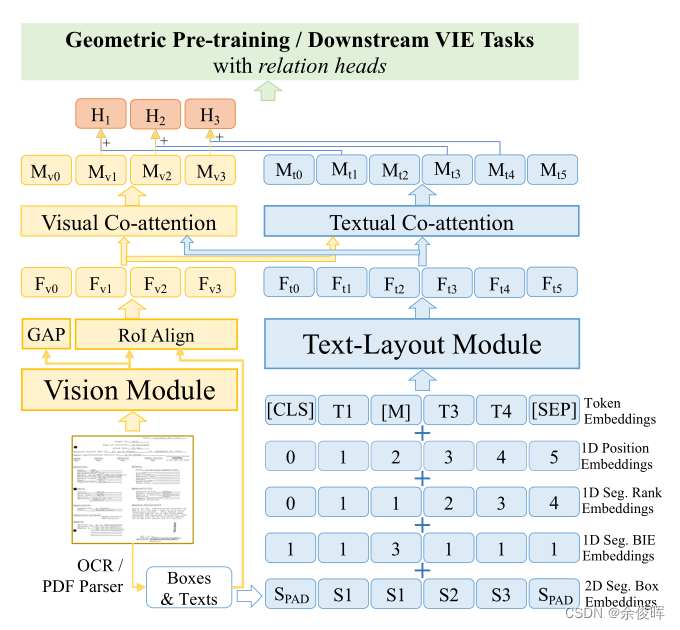
数据集
总结
本文简单介绍了文档智能领域关于多模态预训练语言模型相关内容及相关数据集,相对于基于目标检测(版面分析)的pipline形式,多模态预训练模型能够一定程度的实现端到端的提取文本内容。但实际应用还需要根据特定的场景进行进一步的研究。
参考文献
【1】https://mp.weixin.qq.com/s/cw5wCpJCYo7Wdi1PtsRgGw
【2】https://mp.weixin.qq.com/s/3l4NvGfy8LaKuj_3HGH5pg
【3】LayoutLM: Pre-training of Text and Layout for Document Image Understanding
【4】LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Understanding
【5】LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking
【6】LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding
【7】ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding
【8】GeoLayoutLM: Geometric Pre-training for Visual Information Extraction
相关文章:
【文档智能】多模态预训练模型及相关数据集汇总
前言 大模型时代,在现实场景中或者企业私域数据中,大多数数据都以文档的形式存在,如何更好的解析获取文档数据显得尤为重要。文档智能也从以前的目标检测(版面分析)阶段转向多模态预训练阶段,本文将介绍目…...
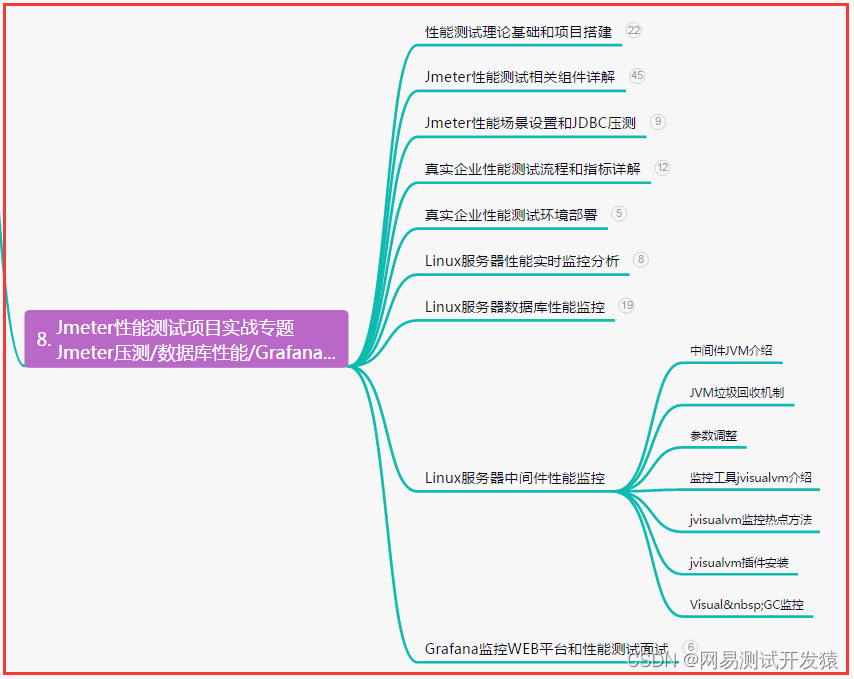
超全整理,性能测试——数据库索引问题定位+分析(详细)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、数据库服务器添…...
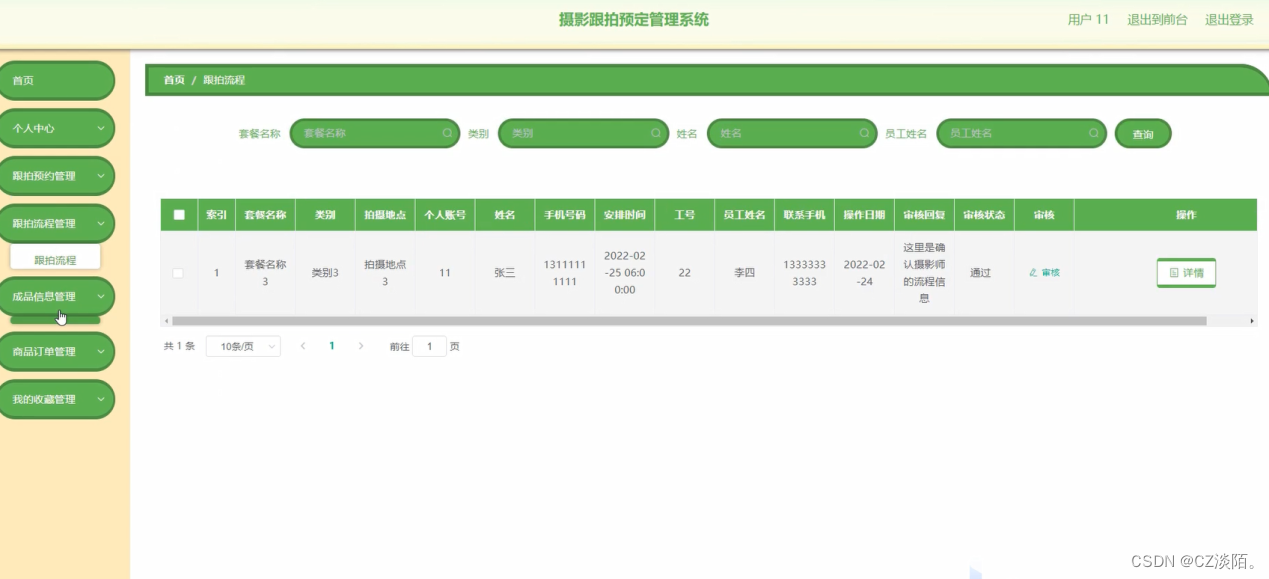
44springboot摄影跟拍预定管理系统
大家好✌!我是CZ淡陌。一名专注以理论为基础实战为主的技术博主,将再这里为大家分享优质的实战项目,本人在Java毕业设计领域有多年的经验,陆续会更新更多优质的Java实战项目,希望你能有所收获,少走一些弯路…...

Flink之窗口触发机制及自定义Trigger的使用
1 窗口触发机制 窗口计算的触发机制都是由Trigger类决定的,Flink中为各类内置的WindowsAssigner都设计了对应的默认Trigger. 层次结构如下: Trigger ProcessingTimeoutTriggerEventTimeTriggerCountTriggerDeltaTriggerNeverTrigger in GlobalWindowsContinuousEventTimeTrigge…...

蓝牙资讯|2024年智能家居新趋势,蓝牙助力智能家居发展
2024年将迎来变革,智能家居趋势不仅会影响我们的生活空间,还会提高我们的生活质量,让我们有更多时间享受属于自己的时光。 2024年智能家居新趋势 趋势一:多功能科技 2024年预示着多功能技术的趋势,创新将成为焦点。混…...

机器学习 | Python实现GA-XGBoost遗传算法优化极限梯度提升树特征分类模型调参
机器学习 | Python实现GA-XGBoost遗传算法优化极限梯度提升树特征分类 目录 机器学习 | Python实现GA-XGBoost遗传算法优化极限梯度提升树特征分类基本介绍模型描述程序设计参考资料基本介绍 XGBoost的核心算法思想基本就是: 不断地添加树,不断地进行特征分裂来生长一棵树,每…...
手部关键点检测3:Pytorch实现手部关键点检测(手部姿势估计)含训练代码和数据集
手部关键点检测3:Pytorch实现手部关键点检测(手部姿势估计)含训练代码和数据集 目录 手部关键点检测3:Pytorch实现手部关键点检测(手部姿势估计)含训练代码和数据集 1. 前言 2.手部关键点检测(手部姿势估计)方法 (1)Top-Down(自上而下)方法 (2)Bot…...
服务日志性能调优,由log引出的巨坑
只有被线上服务问题毒打过的人才明白日志有多重要! 谁赞成,谁反对?如果你深有同感,那恭喜你是个社会人了:) 日志对程序的重要性不言而喻,轻巧、简单、无需费脑,程序代码中随处可见…...
【VR】【Unity】如何调整Quest2的隐藏系统时间日期
【背景】 网络虽然OK,但是Oculus Quest要连上商店还必须调整好系统时间,不过在Quest系统中,时间对用户是不可见的,本篇介绍调整的方法。 【方法】 打开SideQuest,没有的话先去下载一个。打开后先登录,如…...

C++之设计模式
C23种设计模式 https://blog.csdn.net/qq_40309341/article/details/120318957 设计模式可以同时使用多个。在软件开发中,通常会根据需求和问题的复杂性,结合多种设计模式来构建应用程序,以提高代码的可维护性、可扩展性和重用性。不同的设计…...

Django ORM查询
文章目录 1 增 -- 向表内插入一条数据2 删 -- 删除表内数据(物理删除)3 改 -- update操作更新某条数据4 查 -- 基本的表查询(包括多表、跨表、子查询、联表查询)4.1 基本查询4.2 双下划线查询条件4.3 逻辑查询:or、and…...

如何在CentOS 7中卸载Python 2.7,并安装3.X
Python是一种常用的编程语言,但是如果您不需要在服务器上使用Python 2.7,那么本文将详细介绍如何在CentOS 7上卸载Python 2.7。 一、检查Python版本 在卸载Python 2.7之前,必须检查系统上的Python版本。 在终端中执行以下命令:…...

10.17七段数码管单个多个(部分)
单个数码管的实现 第一种方式 一端并接称为位码;一端分别接收电平信号以控制灯的亮灭,称为段码 8421BCD码转七段数码管段码是将BCD码表示的十进制数转换成七段LED数码管的7个驱动段码, 段码就是LED灯的信号 a为1表示没用到a,a为…...
linux静态库与动态库
库是一种可执行的二进制文件,是编译好的代码。使用库可以提高开发效率。在Linux 下有静态库和动态库。 静态库在程序编译的时候会被链接到目标代码里面。所以程序在运行的时候不再需要静态库了。因此编译出来的体积就比较大。以 lib 开头,以.a 结尾。…...

LeetCode 面试题 10.03. 搜索旋转数组
文章目录 一、题目二、C# 题解 一、题目 搜索旋转数组。给定一个排序后的数组,包含n个整数,但这个数组已被旋转过很多次了,次数不详。请编写代码找出数组中的某个元素,假设数组元素原先是按升序排列的。若有多个相同元素ÿ…...

SpringCloudSleuth异步线程支持和传递
场景 在使用Sleuth做链路跟踪时,默认情况下异步线程会断链,需要进行代码调整支持。 调整内容 方式一 使用Async实现异步线程 开启异步线程池 EnableAsync SpringBootApplication public class LizzApplication {public static void main(String[] a…...
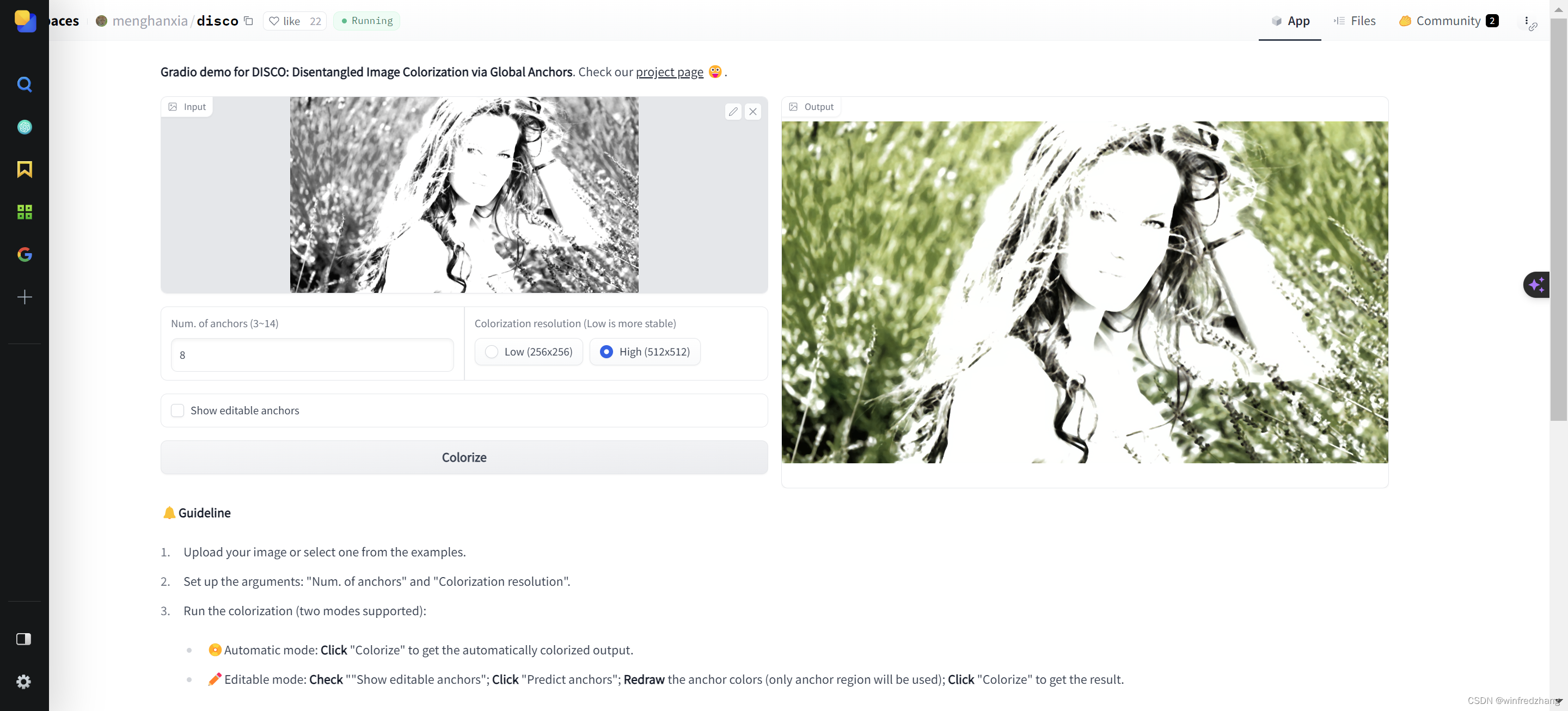
如何使用 Disco 将黑白照片彩色化
Disco 是一个基于视觉语言模型(LLM)的图像彩色化工具。它使用 LLM 来生成彩色图像,这些图像与原始黑白图像相似。 本文将介绍如何使用 Disco 将黑白照片彩色化。 使用 Disco 提供了一个简单的在线演示,可以用于测试模型。 访问…...

ChatGPT AIGC 制作大屏可视化分析案例
第一部分提示词prompt: 商品 价格 p1 13 p2 41 p3 42 p4 53 p5 19 p6 28 p7 92 p8 62 城市 销量 北京 69 上海 13 南京 18 武汉 66 成都 70 你现在是一名非常专业的数据分析师,请结合上述数据完成下列几件事情 1:第一部分数…...

2023年9款好用的在线流程图软件推荐!
随着互联网技术和基础设施的发展,人们能用上比过去更加稳定的网络,因此在使用各类工具软件时,越来越倾向于选择在线工具,或是推出了网页版的应用。 就流程图软件而言,过去想要绘制流程图,我们得在电脑上安…...

剑指Offer || 044.在每个树行中找最大值
题目 给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。 示例1: 输入: root [1,3,2,5,3,null,9] 输出: [1,3,9] 解释:1/ \3 2/ \ \ 5 3 9 示例2: 输入: root [1,2,3] 输出: [1,3] 解释:1/ \2 3示例3ÿ…...

3大核心功能解密:HS2-HF_Patch如何让Honey Select 2游戏体验焕然一新
3大核心功能解密:HS2-HF_Patch如何让Honey Select 2游戏体验焕然一新 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 如果你正在玩Honey Select 2却…...

如何像管理代码一样构建个人技能树:从知识管理到职业发展
1. 项目概述与核心价值最近在整理个人知识库和技能树时,发现了一个挺有意思的项目,叫mxyhi/ok-skills。乍一看,这像是一个个人仓库,但深入探究后,我发现它远不止是一个简单的代码托管。它更像是一个结构化的个人能力发…...

5步构建智能建筑通信系统:BACnet4J纯Java协议栈的架构师指南
5步构建智能建筑通信系统:BACnet4J纯Java协议栈的架构师指南 【免费下载链接】BACnet4J BACnet/IP stack written in Java. Forked from http://sourceforge.net/projects/bacnet4j/ 项目地址: https://gitcode.com/gh_mirrors/ba/BACnet4J 在智能建筑和工业…...

别再只盯着NXP和Impinj了!盘点5款国产超高频RFID芯片的‘独门绝技’
国产超高频RFID芯片的五大技术突围路径 在供应链安全与核心技术自主可控的背景下,国产超高频RFID芯片正从"能用"向"好用"快速演进。不同于早期简单模仿进口芯片的方案,如今头部厂商已形成独特的技术路线——有的在抗金属性能上实现突…...

告别‘数据孤岛’的幻想:深入拆解联邦学习Non-IID问题的根源与EMD度量
告别“数据孤岛”的幻想:联邦学习Non-IID问题的本质与实战应对 当企业兴奋地部署联邦学习系统时,常会遭遇这样的尴尬:模型在各方本地数据上表现优异,聚合后却性能骤降。这背后隐藏着一个被低估的真相——数据天然独立同分布&#…...

蓝桥杯备赛别死磕理论!用DFS实战迷宫、八皇后,5分钟搞懂回溯模板
蓝桥杯算法实战:用DFS破解迷宫与八皇后问题的5个黄金法则 在算法竞赛的战场上,深度优先搜索(DFS)就像一把瑞士军刀——看似简单却能在关键时刻解决各类难题。许多选手在备战蓝桥杯时陷入理论泥潭,反复背诵模板却难以应…...

Cursor Free VIP:三步破解AI编程助手试用限制的专业解决方案
Cursor Free VIP:三步破解AI编程助手试用限制的专业解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached yo…...

Arm DynamIQ PMU架构解析与性能监控实战
1. Arm DynamIQ PMU架构概览 在Armv8-A架构的DynamIQ多核设计中,性能监控单元(PMU)作为硬件性能分析的核心组件,提供了对微架构事件的精确计数能力。与传统PMU设计不同,DynamIQ的Cluster级PMU寄存器组位于共享单元(DSU)中,可监控跨…...

开源补丁工具包OpenClaw-Patchkit:无侵入式热更新与二进制修改实战
1. 项目概述:一个开源补丁工具包的深度解析最近在整理一些老项目的维护工具链时,又翻出了mahsumaktas/openclaw-patchkit这个仓库。这名字乍一看有点神秘,“OpenClaw”配上“Patchkit”,让人联想到某种模块化的修补工具。实际上&a…...

终极Windows离线语音识别指南:打造企业级隐私安全的实时字幕系统
终极Windows离线语音识别指南:打造企业级隐私安全的实时字幕系统 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 在数字化办公和远程协作日益普及的今天,实时语音转文字技术已成为提升工作效…...