模型的选择与调优(网格搜索与交叉验证)
1、为什么需要交叉验证
- 交叉验证目的:为了让被评估的模型更加准确可信
2、什么是交叉验证(cross validation)
- 交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成4份,其中一份作为验证集。然后经过4次(组)的测试,每次都更换不同的验证集。即得到4组模型的结果,取平均值作为最终结果。又称4折交叉验证。
- 训练集:训练集+验证集
- 测试集:测试集

问题:那么这个只是对于参数得出更好的结果,那么怎么选择或者调优参数呢?
3、超参数搜索-网格搜索(Grid Search)
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,网格搜索帮我们实现了这个调参过程,首先需要对模型预设几种超参数组合,每组超参数都采用交叉验证来进行评估,最后选出最优参数组合建立模型。

3.1、模型选择与调优 API
- sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
- 对估计器的指定参数值进行详尽搜索
- estimator:估计器对象
- param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
- cv:指定几折交叉验证
- fit:输入训练数据
- score:准确率
- 结果分析:
- bestscore:在交叉验证中验证的最好结果_
- bestestimator:最好的参数模型
- cvresults:每次交叉验证后的验证集准确率结果和训练集准确率结果
3.2、网格搜索与交叉验证代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler"""
用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证
:return:
"""
# 1)获取数据
iris = load_iris()# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=22)# 3)特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4)KNN算法预估器
estimator = KNeighborsClassifier()# 加入网格搜索与交叉验证
# 参数准备
param_dict = {"n_neighbors": [1, 2, 3, 4, 5, 6, 7, 8, 9, 11]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=10)
estimator.fit(x_train, y_train)# 5)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
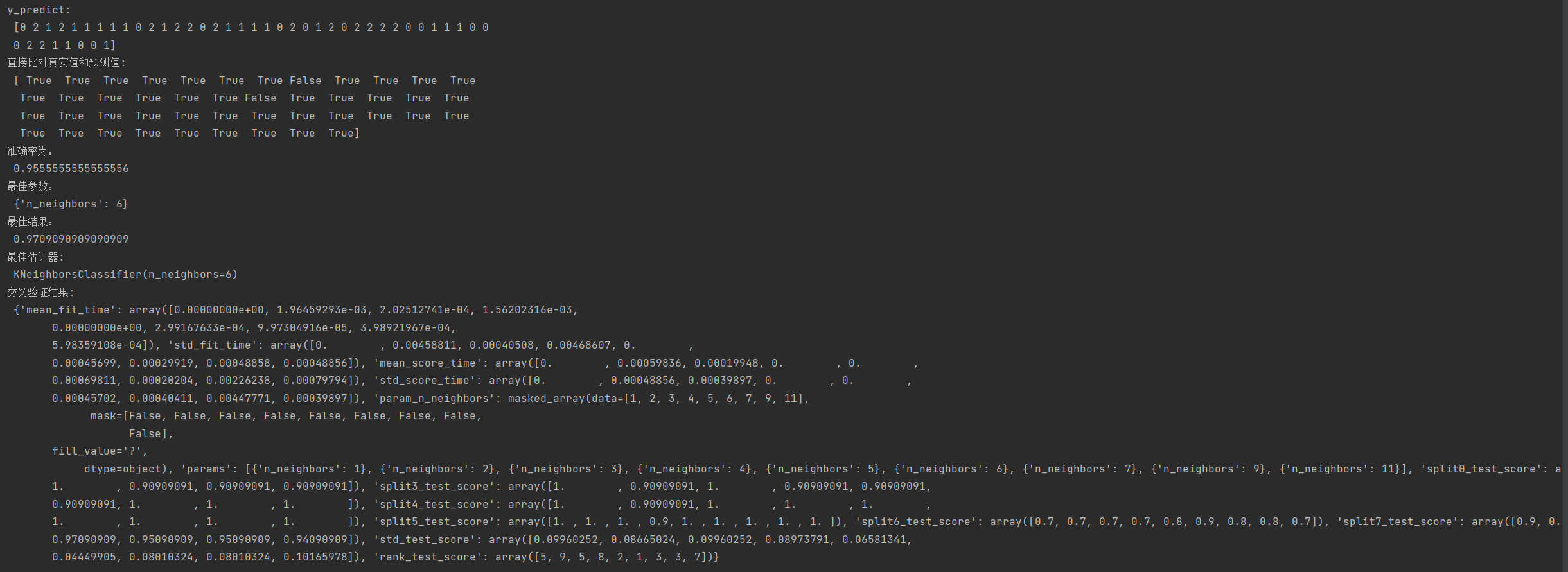
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)# 最佳参数:best_params_
print("最佳参数:\n", estimator.best_params_)
# 最佳结果:best_score_
print("最佳结果:\n", estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:\n", estimator.best_estimator_)
# 交叉验证结果:cv_results_
print("交叉验证结果:\n", estimator.cv_results_)
4、facebook 签到位置预测


- 数据介绍:将根据用户的位置,准确性和时间戳预测用户正在查看的业务。
- train.csv
- row_id:登记事件的ID
- xy:坐标
- 准确性:定位准确性
- 时间:时间戳
- place_id:业务的ID,这是您预测的目标
官网:https://www.kaggle.com/navoshta/grid-knn/data
4.1、流程分析
对于数据做一些基本处理(这里所做的一些处理不一定达到很好的效果,我们只是简单尝试,有些特征我们可以根据一些特征选择的方式去做处理)
1、缩小数据集范围 DataFrame.query()(选择性处理!)
2、删除没用的日期数据 DataFrame.drop(可以选择保留)
3、将签到位置少于n个用户的删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
4、分割数据集
5、标准化处理
6、k-近邻预测
4.2、代码
import pandas as pd
# 1、获取数据
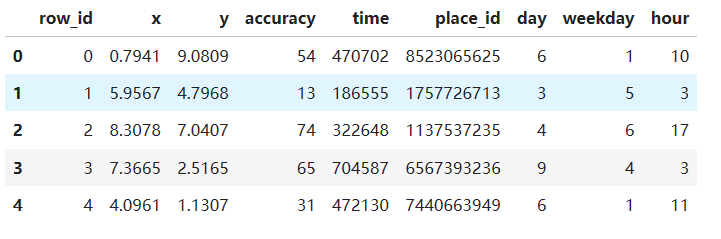
data = pd.read_csv("train.csv")
data.head()

# 1)处理时间特征
time_value = pd.to_datetime(data["time"], unit="s")
date = pd.DatetimeIndex(time_value)
data["day"] = date.day
data["weekday"] = date.weekday
data["hour"] = date.hour
data.head()
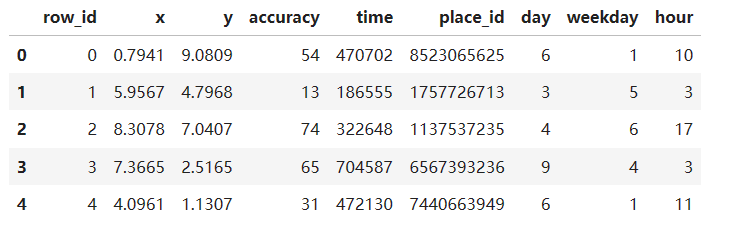
# 2)过滤签到次数少的地点
place_count = data.groupby("place_id").count()["row_id"]
data_final = data[data["place_id"].isin(place_count[place_count > 3].index.values)]
data_final.head()
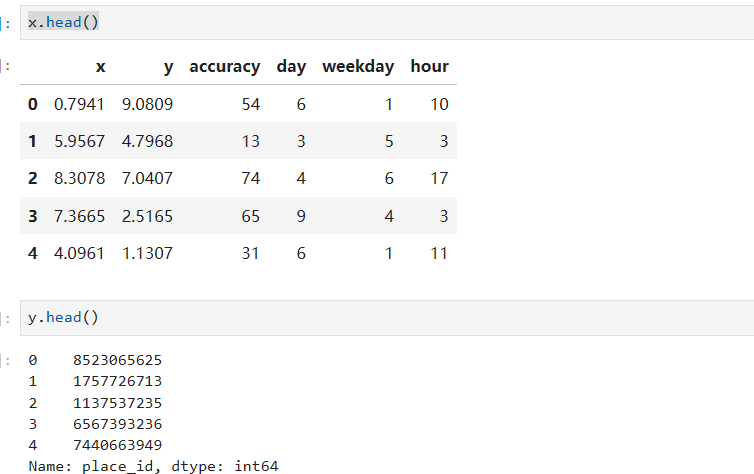
# 筛选特征值和目标值
x = data_final[["x", "y", "accuracy", "day", "weekday", "hour"]]
y = data_final["place_id"]
# 数据集划分
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y)
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV# 3)特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4)KNN算法预估器
estimator = KNeighborsClassifier()# 加入网格搜索与交叉验证
# 参数准备
param_dict = {"n_neighbors": [3, 5, 7, 9]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
estimator.fit(x_train, y_train)# 5)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)# 最佳参数:best_params_
print("最佳参数:\n", estimator.best_params_)
# 最佳结果:best_score_
print("最佳结果:\n", estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:\n", estimator.best_estimator_)
# 交叉验证结果:cv_results_
print("交叉验证结果:\n", estimator.cv_results_)
这个结果数据量比较大,毕竟两千万训练数据了,各位可自行试验及调参;
相关文章:
模型的选择与调优(网格搜索与交叉验证)
1、为什么需要交叉验证 交叉验证目的:为了让被评估的模型更加准确可信 2、什么是交叉验证(cross validation) 交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成4份,其中一份作为验证集。然后经过…...

2023-10-17 mysql-配置主从-记录
摘要: 2023-10-17 mysql-配置主从-记录 参考: mysql配置主从_mysql主从配置_Tyler唐的博客-CSDN博客 master: 环境: 192.168.74.128mysql8/etc/my.cnf.d/mysql-server.cnf # # This group are read by MySQL server. # Use it for options that only the server (but not cli…...
正向代理与反向代理
正向代理 客户端想要直接与目标服务器连接,但是无法直接进行连接,就需要先去访问中间的代理服务器,让代理服务器代替客户端去访问目标服务器 反向代理 屏蔽掉服务器的信息,经常用在多台服务器的分布式部署上,像一些大型…...
idea热加载,JRebel 插件是目前最好用的热加载插件,它支持 IDEA Ultimate 旗舰版、Community 社区版
1.如何安装 ① 点击 https://plugins.jetbrains.com/plugin/4441-jrebel-and-xrebel/versions 地址,下载 2022.4.1 版本。如下图所示: ② 打开 [Preference -> Plugins] 菜单,点击「Install Plugin from Disk…」按钮,选择刚下…...
0基础学习PyFlink——Map和Reduce函数处理单词统计
在很多讲解大数据的案例中,往往都会以一个单词统计例子来抛砖引玉。本文也不免俗,例子来源于PyFlink的《Table API Tutorial》,我们会通过几种方式统计不同的单词出现的个数,从而达到循序渐进的学习效果。 常规方法 # input.py …...

在 Ubuntu 22.04安装配置 Ansible
一、按官网指引安装 我使用的ubuntu22.04版本,使用apt安装。官网指引如下: $ sudo apt-get install software-properties-common $ sudo apt-add-repository ppa:ansible/ansible $ sudo apt-get update $ sudo apt-get install ansible 由于内部网络…...
:数据模型)
【大数据 - Doris 实践】数据表的基本使用(三):数据模型
数据表的基本使用(三):数据模型 1.Aggregate 模型1.1 例一:导入数据聚合1.2 例二:保留明细数据1.3 例三:导入数据与已有数据聚合 2.Uniq 模型3.Duplicate 模型4.数据模型的选择建议5.聚合模型的局限性 Dori…...

PMP和CSPM证书,怎么选?
最近有宝子们在问,从事项目管理行业到底建议考什么证书?是不是CSPM证书一出来,PMP证书就没用了?其实不是。今天胖圆给大家解释一下二者都适合什么人群考~ PMP证书是什么? PMP项目管理专业人士资格认证,由…...

企业宣传为何要重视领军人物包装?领军人物对企业营销的价值和作用分析
在企业的完整形象中,产品、品牌、高管是最重要的组成部分。而大部分企业会把品牌形象放在首位,将公司所有的推广资源都倾斜在这一块,但其实,企业高管形象的塑造和传播也非常重要。小马识途建议中小企业在成长过程中提早对高管形象…...

什么是内存泄漏?JavaScript 垃圾回收机制原理及方式有哪些?哪些操作会造成内存泄漏?
1、什么是内存泄漏? 内存泄漏是前端开发中的一个常见问题,可能导致项目变得缓慢、不稳定甚至崩溃。内存泄漏是指不再用到的内存没有及时被释放,从而造成内存上的浪费。 2、 JavaScript 垃圾回收机制 1) 原理: JavaS…...

C++项目实战——基于多设计模式下的同步异步日志系统-⑫-日志宏全局接口设计(代理模式)
文章目录 专栏导读日志宏&全局接口设计全局接口测试项目目录结构整理示例代码拓展示例代码 专栏导读 🌸作者简介:花想云 ,在读本科生一枚,C/C领域新星创作者,新星计划导师,阿里云专家博主,C…...
京东数据接口:京东数据分析怎么做?
电商运营中数据分析的重要性不言而喻,而想要做数据分析,就要先找到数据,利用数据接口我们能够更轻松的获得比较全面的数据。因此,目前不少品牌商家都选择使用一些数据接口来获取相关电商数据、以更好地做好数据分析。 鲸参谋电商…...

使用Git在本地创建一个仓库并将其推送到GitHub
前记: git svn sourcetree gitee github gitlab gitblit gitbucket gitolite gogs 版本控制 | 仓库管理 ---- 系列工程笔记. Platform:Windows 10 Git version:git version 2.32.0.windows.1 Function: 使用Git在本地创建一个…...
5.覆盖增强技术——PUCCHPUSCH
PUSCH增强方案的标准化工作 1.PUSCH重复传输类型A增强,包括两种增强机制:增加最大重复传输次数,以及基于可用上行时隙的重复传输次数技术方式。 2.基于频域的解决方案,包括时隙间/时隙内跳频的增强 3.支持跨多个时隙的传输块&…...

徐建鸿:深耕中医康养的“托钵行者”
为什么是“庄人堂”?杭州“庄人堂”医药科技公司董事长徐建鸿很乐意和别人分享这个名称的由来,一方面是庄子首先提出“养生”这个概念,接近上工治未病的上医,取名“庄人堂”代表庄子门生,向古哲先贤致敬!另…...

基于svg+js实现简单动态时钟
实现思路 创建SVG容器:首先,创建一个SVG容器元素,用于容纳时钟的各个部分。指定SVG的宽度、高度以及命名空间。 <svg width"200" height"200" xmlns"http://www.w3.org/2000/svg"><!-- 在此添加时钟…...
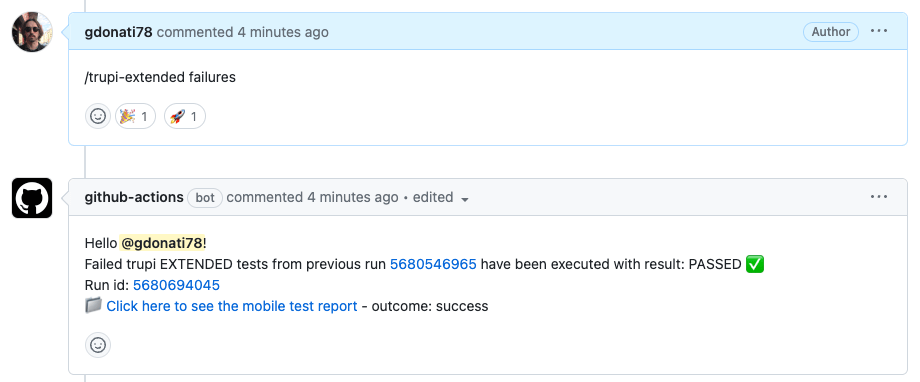
端到端测试(End-to-end tests)重试策略
作者|Giuseppe Donati,Trivago公司Web测试自动化工程师 整理|TesterHome 失败后重试,是好是坏? 为什么要在失败时重试所有测试?为什么不? 作为Trivago(德国酒店搜索服务平台&…...
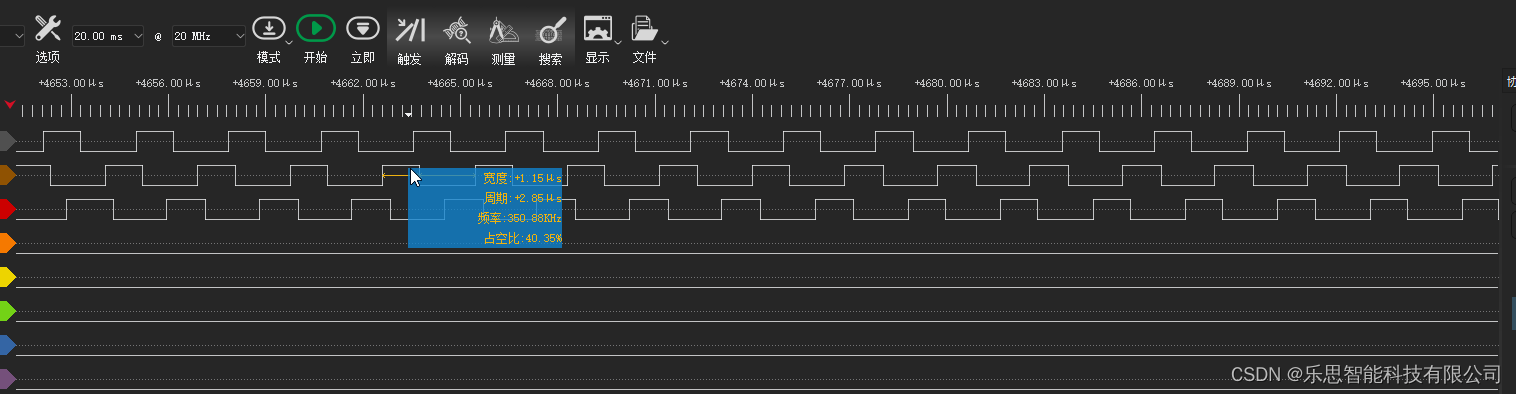
三相交错LLC软启动控制驱动波形分析--死区时间与占空比关系
三相交错LLC软启动控制驱动波形分析 文章目录 三相交错LLC软启动控制驱动波形分析一、电路原理二、时序分析三、环路分析四、控制策略1.软启动驱动波形趋势2.软启动驱动波形占空图3.软启动驱动波形详细图4.软启动代码分析5.Debug调试界面5.死区时间与实际输出5.1 死区时间50--对…...
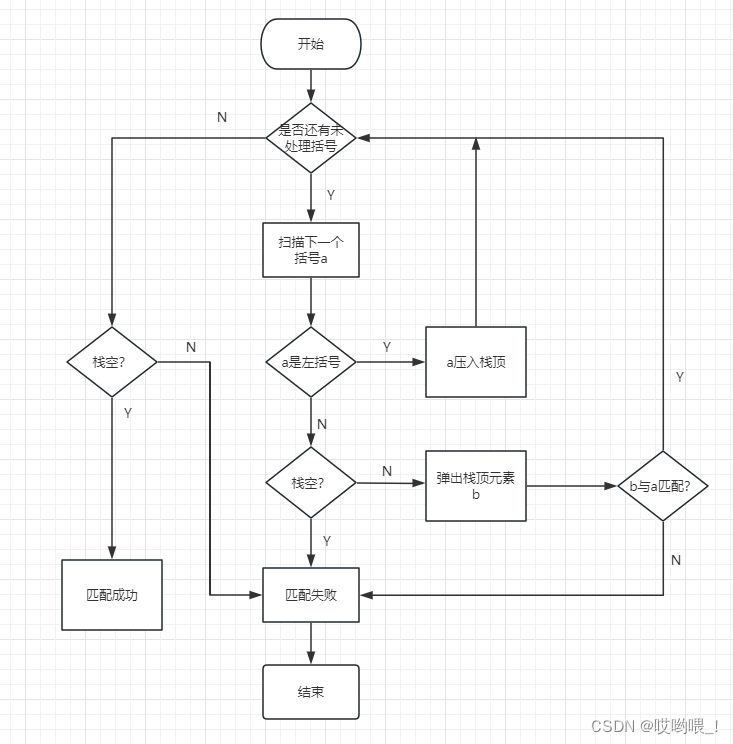
数据结构详细笔记——栈与队列
文章目录 栈的三要素逻辑结构(定义)数据的运算(基本操作)存储结构(物理结构)顺序栈(顺序存储)链栈(链式存储) 队列的三要素逻辑结构(定义…...

JVM调试命令与调试工具
目录 一、JDK自带命令 1、jps 2、jstat(FullGC频繁解决方案) 3、jmap 4、jhat 5、jstack(cpu占用高解决方案) 6、jinfo 二、JDK的可视化工具JConsole 1、JConsole 2、VisualVM 一、JDK自带命令 Sun JDK监控和故障处理命令如: 1、jps JVM Proc…...

如何免费解锁Cursor AI Pro功能:终极三步激活指南
如何免费解锁Cursor AI Pro功能:终极三步激活指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial r…...

EVA-7M,支持GPS/GLONASS及低功耗省电模式的超紧凑型GNSS模块
简介今天我要向大家介绍的是 u-blox 的超紧凑型独立GNSS定位模块——EVA-7M。这是一款专为对成本和空间敏感的应用而设计的独立GNSS模块。该模块基于 u-blox 7 定位引擎(接收GPS、GLONASS、QZSS和SBAS信号)设计,采用行业最小的独立GNSS封装尺…...

Claude Code安装+配置国产大模型+CC Switch
Claude Code 是一个运行在终端(Terminal)里的 AI 程序员。 它不仅仅是一个聊天框,它拥有操作你电脑文件的权限 https://code.claude.com/docs/en/setup 安装 前提条件 需要 Node.js 18 或更新版本 macOS 用户推荐使用 nvm 或 Homebrew 安装…...

AI智能体开发实战:基于ai_agents_az框架构建数据分析助手
1. 项目概述与核心价值最近在探索AI智能体(AI Agent)的落地应用时,我偶然发现了一个名为gyoridavid/ai_agents_az的开源项目。这个项目名听起来就很有意思,ai_agents点明了主题,az则暗示了某种从A到Z的全面性或是一个特…...

STM32H743实战笔记:用SN65HVD230驱动14个伺服电机,1M波特率稳不稳?
STM32H743工业级CAN总线实战:14伺服电机集群控制与SN65HVD230极限测试 在工业机器人关节控制领域,多电机协同作业对总线通讯的实时性和稳定性提出严苛要求。最近完成的一个AGV底盘项目让我对STM32H743的CANopen主站性能有了全新认识——当需要同时驱动14…...
)
Cadence 16.6 新手避坑指南:从零搭建PCB设计库(OLB、焊盘、封装分类管理)
Cadence 16.6 新手避坑指南:从零搭建PCB设计库(OLB、焊盘、封装分类管理) 刚接触Cadence 16.6的PCB设计新手,往往会在库文件管理这个环节栽跟头。面对Allegro、Design Entry CIS和Pad Designer这三个核心工具,如何系统…...

基于MCP协议构建AI工具服务器:连接Web与AI的标准化适配器
1. 项目概述:一个连接Web与AI的“万能适配器”如果你正在尝试让AI助手(比如ChatGPT、Claude)去访问一个网站、查询实时天气、或者控制你的智能家居,你可能会发现一个核心难题:这些大模型本身是“离线”的,它…...

Arm Corstone SSE-300内存架构与安全设计解析
1. Arm Corstone SSE-300内存架构深度解析在嵌入式系统设计中,内存映射是连接软件与硬件的关键纽带。作为Arm最新推出的子系统解决方案,Corstone SSE-300通过精心设计的内存架构,为开发者提供了高性能、高安全性的开发平台。我在实际项目中使…...

STM32F407移植QP状态机踩坑实录:从编译报错到成功运行,我解决了这三个关键问题
STM32F407移植QP状态机踩坑实录:从编译报错到成功运行,我解决了这三个关键问题 在嵌入式开发中,状态机是一种极其重要的编程范式,它能有效管理复杂系统的行为逻辑。QP(Quantum Platform)作为一款轻量级的状…...

从零构建高性能技术博客:SSG选型、自动化部署与SEO优化实战
1. 项目概述:一个技术博客的诞生与演进“wangtunan/blog”,这看起来只是一个简单的GitHub仓库名,背后却是一个技术人持续输出、构建个人知识体系的完整实践。它不仅仅是一个存放Markdown文件的代码库,更是一个集成了现代前端技术栈…...