【大数据 - Doris 实践】数据表的基本使用(三):数据模型
数据表的基本使用(三):数据模型
- 1.Aggregate 模型
- 1.1 例一:导入数据聚合
- 1.2 例二:保留明细数据
- 1.3 例三:导入数据与已有数据聚合
- 2.Uniq 模型
- 3.Duplicate 模型
- 4.数据模型的选择建议
- 5.聚合模型的局限性
Doris 的数据模型主要分为 3 类:Aggregate、Uniq、Duplicate。
1.Aggregate 模型
表中的列按照是否设置了 AggregationType,分为 Key(维度列)和 Value(指标列)。没有设置 AggregationType 的称为 Key,设置了 AggregationType 的称为 Value。
当我们导入数据时,对于 Key 列相同的行会聚合成一行,而 Value 列会按照设置的 AggregationType 进行聚合。AggregationType 目前有以下四种聚合方式:
SUM:求和,多行的 Value 进行累加。REPLACE:替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。REPLACE_IF_NOT_NULL:当遇到null值则不更新。MAX:保留最大值。MIN:保留最小值。
数据的聚合,在 Doris 中有如下三个阶段发生:
- 每一批次数据导入的 ETL 阶段。该阶段会在每一批次导入的数据内部进行聚合。
- 底层 BE 进行数据 Compaction 的阶段。该阶段,BE 会对已导入的不同批次的数据进行进一步的聚合。
- 数据查询阶段。在数据查询时,对于查询涉及到的数据,会进行对应的聚合。数据在不同时间,可能聚合的程度不一致。比如一批数据刚导入时,可能还未与之前已存在的数据进行聚合。但是对于用户而言,用户只能查询到聚合后的数据。即不同的聚合程度对于用户查询而言是透明的。用户需始终认为数据以最终的完成的聚合程度存在,而不应假设某些聚合还未发生。
1.1 例一:导入数据聚合
创建表:
CREATE TABLE IF NOT EXISTS test_db.example_site_visit
(`user_id` LARGEINT NOT NULL COMMENT "用户 id",`date` DATE NOT NULL COMMENT "数据灌入日期时间",`city` VARCHAR(20) COMMENT "用户所在城市",`age` SMALLINT COMMENT "用户年龄",`sex` TINYINT COMMENT "用户性别",`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",`last_visit_date_not_null` DATETIME REPLACE_IF_NOT_NULL DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10;
插入数据:
insert into test_db.example_site_visit
values (10000,'2017-10-01','北京',20,0,'2017-10-01 06:00:00','2017-10-01 06:00:00',20,10,10),(10000,'2017-10-01','北京',20,0,'2017-10-01 07:00:00','2017-10-01 07:00:00',15,2,2),(10001,'2017-10-01','北京',30,1,'2017-10-01 17:05:45','2017-10-01 07:00:00',2,22,22),(10002,'2017-10-02','上海',20,1,'2017-10-02 12:59:12',null,200,5,5),(10003,'2017-10-02','广州',32,0,'2017-10-02 11:20:00','2017-10-02 11:20:00',30,11,11),(10004,'2017-10-01','深圳',35,0,'2017-10-01 10:00:15','2017-10-01 10:00:15',100,3,3),(10004,'2017-10-03','深圳',35,0,'2017-10-03 10:20:22','2017-10-03 10:20:22',11,6,6);
注意:
insert into单条数据这种操作在 Doris 里只能演示不能在生产使用,会引发写阻塞。
查看表:
select * from test_db.example_site_visit;
最终,用户 10000 只剩下了一行聚合后的数据。而其余用户的数据和原始数据保持一致。经过聚合,Doris 中最终只会存储聚合后的数据。换句话说,即明细数据会丢失,用户不能够再查询到聚合前的明细数据了。
1.2 例二:保留明细数据
创建表:
CREATE TABLE IF NOT EXISTS test_db.example_site_visit2
(`user_id` LARGEINT NOT NULL COMMENT "用户 id",`date` DATE NOT NULL COMMENT "数据灌入日期时间",`timestamp` DATETIME COMMENT "数据灌入时间,精确到秒",`city` VARCHAR(20) COMMENT "用户所在城市",`age` SMALLINT COMMENT "用户年龄",`sex` TINYINT COMMENT "用户性别",`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间"
)
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10;
插入数据:
insert into test_db.example_site_visit2
values (10000,'2017-10-01','2017-10-01 08:00:05','北京',20,0,'2017-10-01 06:00:00',20,10,10),(10000,'2017-10-01','2017-10-01 09:00:05','北京',20,0,'2017-10-01 07:00:00',15,2,2),(10001,'2017-10-01','2017-10-01 18:12:10','北京',30,1,'2017-10-01 17:05:45',2,22,22),(10002,'2017-10-02','2017-10-02 13:10:00','上海',20,1,'2017-10-02 12:59:12',200,5,5),(10003,'2017-10-02','2017-10-02 13:15:00','广州',32,0,'2017-10-02 11:20:00',30,11,11),(10004,'2017-10-01','2017-10-01 12:12:48','深圳',35,0,'2017-10-01 10:00:15',100,3,3),(10004,'2017-10-03','2017-10-03 12:38:20','深圳',35,0,'2017-10-03 10:20:22',11,6,6);
查看表:
select * from test_db.example_site_visit2;
存储的数据,和导入数据完全一样,没有发生任何聚合。这是因为,这批数据中,因为加入了 timestamp 列,所有行的 Key 都不完全相同。也就是说,只要保证导入的数据中,每一行的 Key 都不完全相同,那么即使在聚合模型下,Doris 也可以保存完整的明细数据。
1.3 例三:导入数据与已有数据聚合
往例一中继续插入数据:
insert into test_db.example_site_visit
values (10004,'2017-10-03','深圳',35,0,'2017-10-03 11:22:00',null,44,19,19),(10005,'2017-10-03','长沙',29,1,'2017-10-03 18:11:02','2017-10-03 18:11:02',3,1,1);
查看表:
select * from test_db.example_site_visit;
最终,用户 10004 的已有数据和新导入的数据发生了聚合。同时新增了 10005 用户的数据。
2.Uniq 模型
在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。因此,我们引入了 Uniq 的数据模型。该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。
创建表:
CREATE TABLE IF NOT EXISTS test_db.user
(`user_id` LARGEINT NOT NULL COMMENT "用户 id",`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",`city` VARCHAR(20) COMMENT "用户所在城市",`age` SMALLINT COMMENT "用户年龄",`sex` TINYINT COMMENT "用户性别",`phone` LARGEINT COMMENT "用户电话",`address` VARCHAR(500) COMMENT "用户地址",`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `username`)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 10;
插入数据
insert into test_db.user
values (10000,'wuyanzu','北京',18,0,12345678910,'北京朝阳区','2017-10-01 07:00:00'),(10000,'wuyanzu','北京',19,0,12345678910,'北京朝阳区','2017-10-01 07:00:00'),(10000,'zhangsan','北京',20,0,12345678910,'北京海淀区','2017-11-15 06:10:20');
查询表:
select * from test_db.user;
Uniq 模型完全可以用聚合模型中的 REPLACE 方式替代。其内部的实现方式和数据存储方式也完全一样。
3.Duplicate 模型
在某些多维分析场景下,数据既没有主键,也没有聚合需求。Duplicate 数据模型可以满足这类需求。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。 而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序。
创建表:
CREATE TABLE IF NOT EXISTS test_db.example_log
(`timestamp` DATETIME NOT NULL COMMENT "日志时间",`type` INT NOT NULL COMMENT "日志类型",`error_code` INT COMMENT "错误码",`error_msg` VARCHAR(1024) COMMENT "错误详细信息",`op_id` BIGINT COMMENT "负责人 id",`op_time` DATETIME COMMENT "处理时间"
)
DUPLICATE KEY(`timestamp`, `type`)
DISTRIBUTED BY HASH(`timestamp`) BUCKETS 10;
插入数据:
insert into test_db.example_log
values ('2017-10-01 08:00:05',1,404,'not found page', 101, '2017-10-01 08:00:05'),('2017-10-01 08:00:05',1,404,'not found page', 101, '2017-10-01 08:00:05'),('2017-10-01 08:00:05',2,404,'not found page', 101, '2017-10-01 08:00:06'),('2017-10-01 08:00:06',2,404,'not found page', 101, '2017-10-01 08:00:07');
查看表:
select * from test_db.example_log;
4.数据模型的选择建议
因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要。
- Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对
count(*)查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。 - Uniq 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用 ROLLUP 等预聚合带来的查询优势(因为本质是
REPLACE,没有SUM这种聚合方式)。 - Duplicate 适合任意维度的
Ad-hoc查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)。
5.聚合模型的局限性
这里我们针对 Aggregate 模型(包括 Uniq 模型),来介绍下聚合模型的局限性。
在聚合模型中,模型对外展现的,是最终聚合后的数据。也就是说,任何还未聚合的数据(比如说两个不同导入批次的数据),必须通过某种方式,以保证对外展示的一致性。我们举例说明。
假设表结构如下:
| ColumnName | Type | AggregationType | Comment |
|---|---|---|---|
| user_id | LARGEINT | 用户 id | |
| date | DATE | 数据灌入日期 | |
| cost | BIGINT | SUM | 用户总消费 |
假设存储引擎中有如下两个已经导入完成的批次的数据:
batch 1
| user_id | date | cost |
|---|---|---|
| 10001 | 2017-11-20 | 50 |
| 10002 | 2017-11-21 | 39 |
batch 2
| user_id | date | cost |
|---|---|---|
| 10001 | 2017-11-20 | 1 |
| 10001 | 2017-11-21 | 5 |
| 10003 | 2017-11-22 | 22 |
可以看到,用户 10001 分属在两个导入批次中的数据还没有聚合。但是为了保证用户只能查询到如下最终聚合后的数据,在查询引擎中加入了聚合算子,来保证数据对外的一致性。
| user_id | date | cost |
|---|---|---|
| 10001 | 2017-11-20 | 51 |
| 10001 | 2017-11-21 | 5 |
| 10002 | 2017-11-21 | 39 |
| 10003 | 2017-11-22 | 22 |
另外,在聚合列(Value)上,执行与聚合类型不一致的聚合类查询时,要注意语意。比如我们在如上示例中执行如下查询:
SELECT MIN(cost) FROM table;
得到的结果是 5 5 5,而不是 1 1 1。
同时,这种一致性保证,在某些查询中,会极大的降低查询效率。
我们以最基本的 count(*) 查询为例:
SELECT COUNT(*) FROM table;
在其他数据库中,这类查询都会很快的返回结果。因为在实现上,我们可以通过如 “导入时对行进行计数,保存 count 的统计信息”,或者在查询时 “仅扫描某一列数据,获得 count 值” 的方式,只需很小的开销,即可获得查询结果。但是在 Doris 的聚合模型中,这种查询开销非常大。
上面的例子,select count(*) from table 的正确结果应该为 4 4 4。但如果我们只扫描 user_id 这一列,如果加上查询时聚合,最终得到的结果是 3 3 3(10001,10002,10003)。而如果不加查询时聚合,则得到的结果是 5 5 5(两批次一共 5 5 5 行数据)。可见这两个结果都是不对的。
为了得到正确的结果,我们必须同时读取 user_id 和 date 这两列的数据,再加上查询时聚合,才能返回 4 4 4 这个正确的结果。也就是说,在 count(*) 查询中,Doris 必须扫描所有的 AGGREGATE KEY 列(这里就是 user_id 和 date),并且聚合后,才能得到语意正确的结果。当聚合列非常多时,count(*) 查询需要扫描大量的数据。
因此,当业务上有频繁的 count(*) 查询时,我们建议用户通过增加一个值恒为 1 1 1 的,聚合类型为 SUM 的列来模拟 count()。如刚才的例子中的表结构,我们修改如下:
| ColumnName | Type | AggregateType | Comment |
|---|---|---|---|
| user_id | BIGINT | 用户 id | |
| date | DATE | 数据灌入日期 | |
| cost | BIGINT | SUM | 用户总消费 |
| count | BIGINT | SUM | 用于计算 count |
增加一个 count 列,并且导入数据中,该列值恒为 1 1 1。则 select count(*) from table 的结果等价于 select sum(count) from table。而后者的查询效率将远高于前者。不过这种方式也有使用限制,就是用户需要自行保证,不会重复导入 AGGREGATE KEY 列都相同的行。否则,select sum(count) from table 只能表述原始导入的行数,而不是 select count(*) from table 的语义。
另一种方式,就是将如上的 count 列的聚合类型改为 REPLACE,且依然值恒为 1。那么 select sum(count) from table 和 select count(*) from table 的结果将是一致的。并且这种方式,没有导入重复行的限制。
相关文章:
:数据模型)
【大数据 - Doris 实践】数据表的基本使用(三):数据模型
数据表的基本使用(三):数据模型 1.Aggregate 模型1.1 例一:导入数据聚合1.2 例二:保留明细数据1.3 例三:导入数据与已有数据聚合 2.Uniq 模型3.Duplicate 模型4.数据模型的选择建议5.聚合模型的局限性 Dori…...

PMP和CSPM证书,怎么选?
最近有宝子们在问,从事项目管理行业到底建议考什么证书?是不是CSPM证书一出来,PMP证书就没用了?其实不是。今天胖圆给大家解释一下二者都适合什么人群考~ PMP证书是什么? PMP项目管理专业人士资格认证,由…...

企业宣传为何要重视领军人物包装?领军人物对企业营销的价值和作用分析
在企业的完整形象中,产品、品牌、高管是最重要的组成部分。而大部分企业会把品牌形象放在首位,将公司所有的推广资源都倾斜在这一块,但其实,企业高管形象的塑造和传播也非常重要。小马识途建议中小企业在成长过程中提早对高管形象…...

什么是内存泄漏?JavaScript 垃圾回收机制原理及方式有哪些?哪些操作会造成内存泄漏?
1、什么是内存泄漏? 内存泄漏是前端开发中的一个常见问题,可能导致项目变得缓慢、不稳定甚至崩溃。内存泄漏是指不再用到的内存没有及时被释放,从而造成内存上的浪费。 2、 JavaScript 垃圾回收机制 1) 原理: JavaS…...

C++项目实战——基于多设计模式下的同步异步日志系统-⑫-日志宏全局接口设计(代理模式)
文章目录 专栏导读日志宏&全局接口设计全局接口测试项目目录结构整理示例代码拓展示例代码 专栏导读 🌸作者简介:花想云 ,在读本科生一枚,C/C领域新星创作者,新星计划导师,阿里云专家博主,C…...
京东数据接口:京东数据分析怎么做?
电商运营中数据分析的重要性不言而喻,而想要做数据分析,就要先找到数据,利用数据接口我们能够更轻松的获得比较全面的数据。因此,目前不少品牌商家都选择使用一些数据接口来获取相关电商数据、以更好地做好数据分析。 鲸参谋电商…...

使用Git在本地创建一个仓库并将其推送到GitHub
前记: git svn sourcetree gitee github gitlab gitblit gitbucket gitolite gogs 版本控制 | 仓库管理 ---- 系列工程笔记. Platform:Windows 10 Git version:git version 2.32.0.windows.1 Function: 使用Git在本地创建一个…...
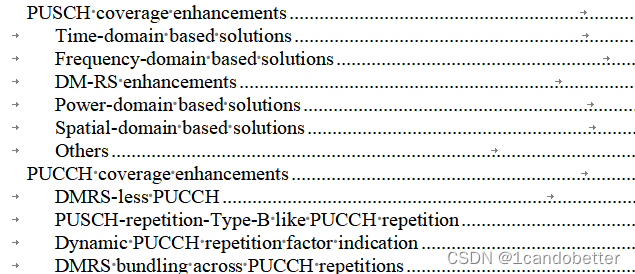
5.覆盖增强技术——PUCCHPUSCH
PUSCH增强方案的标准化工作 1.PUSCH重复传输类型A增强,包括两种增强机制:增加最大重复传输次数,以及基于可用上行时隙的重复传输次数技术方式。 2.基于频域的解决方案,包括时隙间/时隙内跳频的增强 3.支持跨多个时隙的传输块&…...

徐建鸿:深耕中医康养的“托钵行者”
为什么是“庄人堂”?杭州“庄人堂”医药科技公司董事长徐建鸿很乐意和别人分享这个名称的由来,一方面是庄子首先提出“养生”这个概念,接近上工治未病的上医,取名“庄人堂”代表庄子门生,向古哲先贤致敬!另…...

基于svg+js实现简单动态时钟
实现思路 创建SVG容器:首先,创建一个SVG容器元素,用于容纳时钟的各个部分。指定SVG的宽度、高度以及命名空间。 <svg width"200" height"200" xmlns"http://www.w3.org/2000/svg"><!-- 在此添加时钟…...
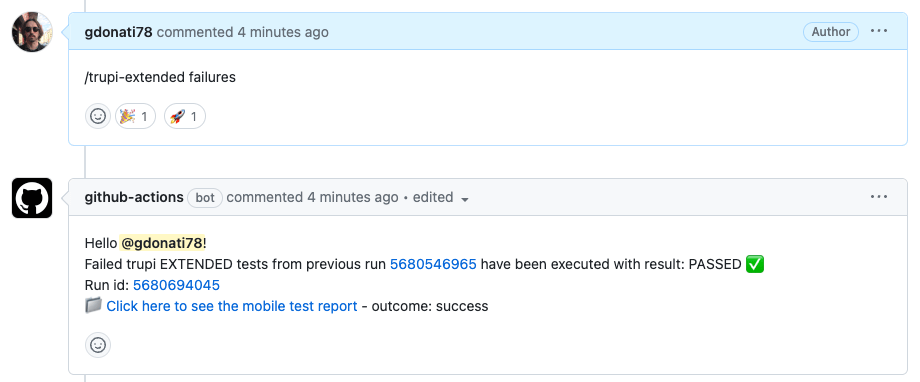
端到端测试(End-to-end tests)重试策略
作者|Giuseppe Donati,Trivago公司Web测试自动化工程师 整理|TesterHome 失败后重试,是好是坏? 为什么要在失败时重试所有测试?为什么不? 作为Trivago(德国酒店搜索服务平台&…...
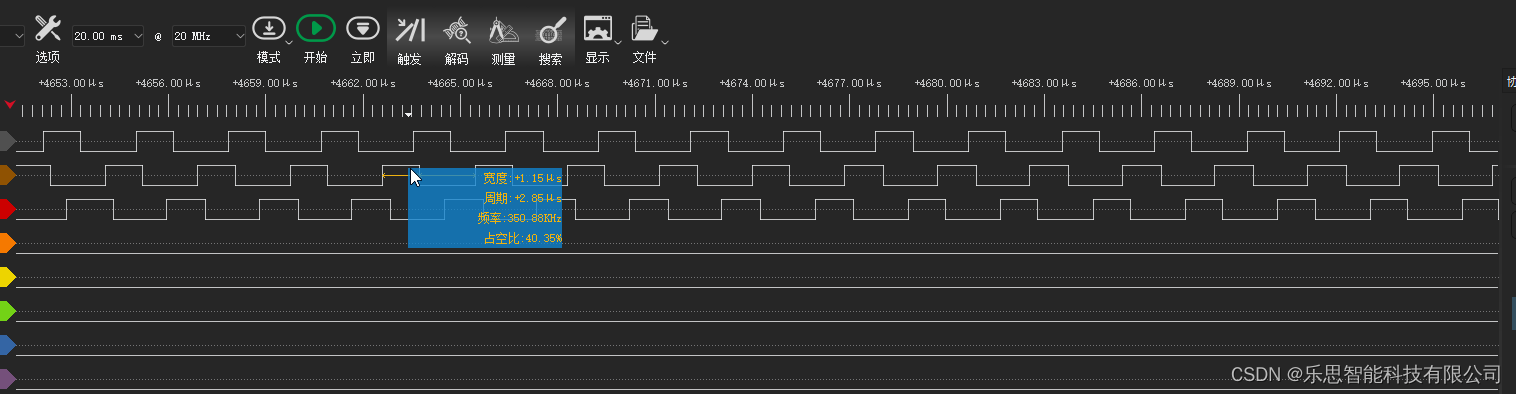
三相交错LLC软启动控制驱动波形分析--死区时间与占空比关系
三相交错LLC软启动控制驱动波形分析 文章目录 三相交错LLC软启动控制驱动波形分析一、电路原理二、时序分析三、环路分析四、控制策略1.软启动驱动波形趋势2.软启动驱动波形占空图3.软启动驱动波形详细图4.软启动代码分析5.Debug调试界面5.死区时间与实际输出5.1 死区时间50--对…...
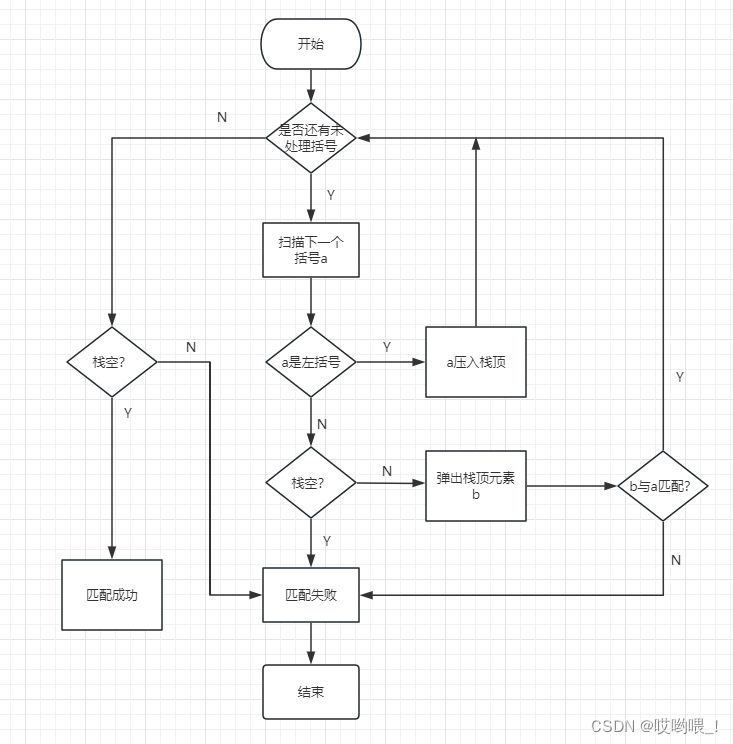
数据结构详细笔记——栈与队列
文章目录 栈的三要素逻辑结构(定义)数据的运算(基本操作)存储结构(物理结构)顺序栈(顺序存储)链栈(链式存储) 队列的三要素逻辑结构(定义…...

JVM调试命令与调试工具
目录 一、JDK自带命令 1、jps 2、jstat(FullGC频繁解决方案) 3、jmap 4、jhat 5、jstack(cpu占用高解决方案) 6、jinfo 二、JDK的可视化工具JConsole 1、JConsole 2、VisualVM 一、JDK自带命令 Sun JDK监控和故障处理命令如: 1、jps JVM Proc…...
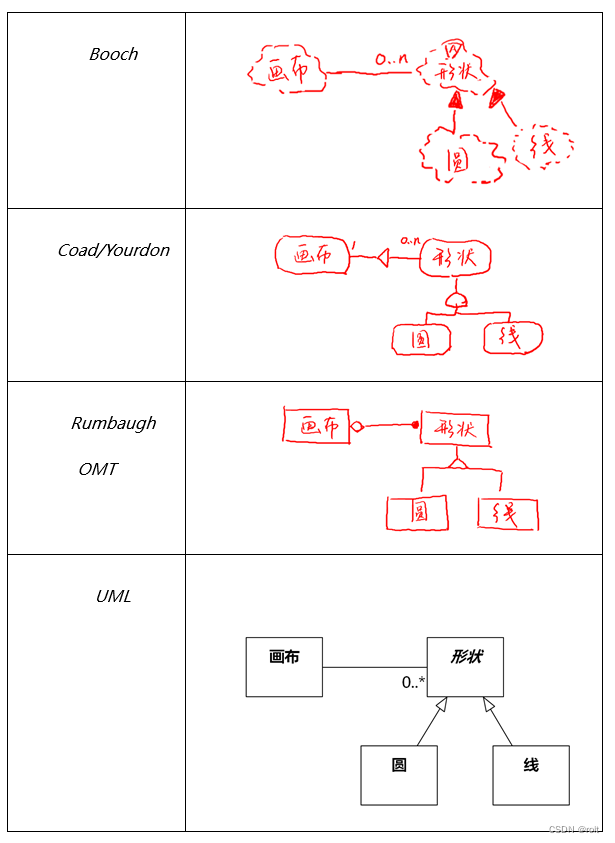
《软件方法》第1章2023版连载(07)UML的历史和现状
DDD领域驱动设计批评文集 做强化自测题获得“软件方法建模师”称号 《软件方法》各章合集 1.3 统一建模语言UML 1.3.1 UML的历史和现状 上一节阐述了A→B→C→D的推导是不可避免的,但具体如何推导,有各种不同的做法,这些做法可以称为“方…...
)
chromium 54 chrome 各个版本发布功能列表(109-119)
chromium Features 109-119 From https://chromestatus.com/features chromium109 Features:12 Auto range support for font descriptors inside font-face rule Auto range support for variable fonts in ‘font-weight’, ‘font-style’ and ‘font-stretch’ descrip…...
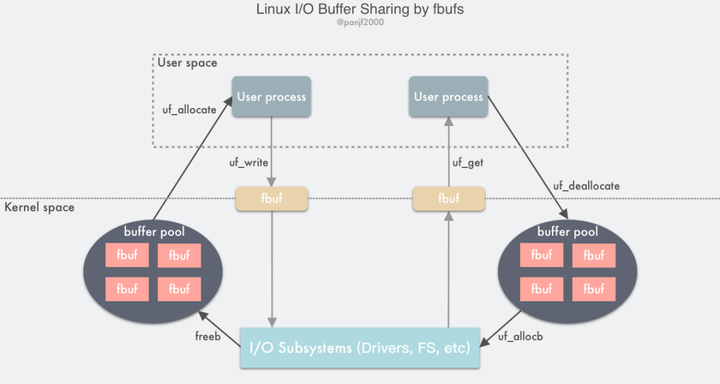
Linux实现原理 — I/O 处理流程与优化手段
Linux I/O 接口 Linux I/O 接口可以分为以下几种类型: 文件 I/O 接口:用于对文件进行读写操作的接口,包括 open()、read()、write()、close()、lseek() 等。 网络 I/O 接口:用于网络通信的接口,包括 socket()、conne…...

第 367 场 LeetCode 周赛题解
A 找出满足差值条件的下标 I 模拟 class Solution { public:vector<int> findIndices(vector<int> &nums, int indexDifference, int valueDifference) {int n nums.size();for (int i 0; i < n; i)for (int j 0; j < i; j)if (i - j > indexDiffe…...
最新百度统计配置图文教程,获取siteId、百度统计AccessToken、百度统计代码教程
一、前言 很多网友开发者都不知道百度统计siteId、百度统计token怎么获取,在网上找的教程都是几年前老的教程,因此给大家出一期详细百度统计siteId、百度统计token、百度统计代码获取详细步骤教程。 二、登录到百度统计 1.1 登录到百度统计官网 使用…...

【C++ 学习 ㉘】- 详解 C++11 的列表初始化
目录 一、C11 简介 二、列表初始化 2.1 - 统一初始化 2.2 - 列表初始化的使用细节 2.2.1 - 聚合类型的定义 2.2.2 - 注意事项 2.3 - initializer_list 2.3.1 - 基本使用 2.3.2 - 源码剖析 一、C11 简介 1998 年,C 标准委员会发布了第一版 C 标准࿰…...

如何重新定义macOS兼容性:OpenCore Legacy Patcher的完整实践指南
如何重新定义macOS兼容性:OpenCore Legacy Patcher的完整实践指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 在技术快速迭代的时代ÿ…...

Linux主机资产标识实战指南
Linux主机资产标识实战指南本文面向具备一定 Linux 基础的技术人员,围绕主机资产标识展开,重点讨论主机命名、标签规范和资产映射。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在一起…...

Linux挖矿木马Linux.BtcMine.174技术剖析与防御实战
1. 新型Linux挖矿木马深度剖析:从Linux.BtcMine.174看现代恶意软件的演进最近安全圈里一个来自俄罗斯Dr.Web公司的分析报告引起了我的注意,他们披露了一个代号为Linux.BtcMine.174的新型木马。这玩意儿可不是什么小打小闹的脚本小子作品,而是…...

企业微信消息监听实战:如何实时接收客户消息回调?
自动回复、AI 客服、CRM 联动的核心,其实都是“消息回调”。很多开发者在接入企业微信自动化时,第一个遇到的问题就是:“为什么收不到客户消息?”实际上,企业微信的大部分自动化能力,都是基于“消息监听 消…...

SecureCRT 9.1.0不止是安装:揭秘高级功能如会话日志、脚本自动化与安全配置最佳实践
SecureCRT 9.1.0高阶实战:从会话审计到自动化运维的全栈指南 SecureCRT早已超越基础终端工具的范畴,成为运维工程师手中的瑞士军刀。当大多数教程还在反复讲解安装步骤时,真正的高阶用户已经在用会话日志构建操作审计体系,通过脚本…...

从Mid360到自主移动:基于Fast-LIO与Move_Base的机器人导航实战拆解
1. Mid360激光雷达与Fast-LIO的适配实战 第一次拿到Livox Mid360激光雷达时,我完全被它36059的超大视场角惊艳到了。这款固态激光雷达不仅体积小巧,而且完全不用担心传统机械式雷达的电机磨损问题。但真正开始用它做SLAM时,才发现实物开发和仿…...

2026年最新实测 目前哪款英语教学软件功能更全面好用?
行业深度痛点:功能冗余≠好用,核心场景适配才是关键我们团队做了5年英语教学技术测评,每年都会测市面上主流的教学工具,2026年我们抽测了12款覆盖公立校、教培机构、个人使用的英语教学软件,发现行业普遍存在一个共性问…...

英雄联盟内存换肤神器:R3nzSkin全攻略
英雄联盟内存换肤神器:R3nzSkin全攻略 【免费下载链接】R3nzSkin Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3n/R3nzSkin 想要在英雄联盟中体验所有皮肤却担心账号安全?R3nzSkin为你提供了一种安全可…...

终极指南:如何使用FlicFlac快速完成Windows音频格式转换
终极指南:如何使用FlicFlac快速完成Windows音频格式转换 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 在Windows平台上处理音频文件时&…...

逆向工程ChatGPT:开源社区如何解构大语言模型黑盒
1. 项目概述:当开源精神“撞上”闭源巨兽最近在GitHub上闲逛,发现一个叫Zai-Kun/reverse-engineered-chatgpt的项目热度不低。光看名字就挺有意思的,“逆向工程ChatGPT”。这可不是什么破解软件或者绕过付费墙的小把戏,它背后代表…...