Linux实现原理 — I/O 处理流程与优化手段
Linux I/O 接口
Linux I/O 接口可以分为以下几种类型:
文件 I/O 接口:用于对文件进行读写操作的接口,包括 open()、read()、write()、close()、lseek() 等。

网络 I/O 接口:用于网络通信的接口,包括 socket()、connect()、bind()、listen()、accept() 等。
设备 I/O 接口:用于对设备(e.g. 字符设备、块设备)进行读写操作的接口,包括 ioctl()、mmap()、select()、poll()、epoll() 等。
其他 I/O 接口:如管道接口、共享内存接口、信号量接口等。
Linux I/O 处理流程
下面以最常用的 read() 和 write() 函数来介绍 Linux 的 I/O 处理流程。
read() 和 write()
read() 和 write() 函数,是最基本的文件 I/O 接口,也可用于在 TCP Socket 中进行数据读写,属于阻塞式 I/O(Blocking I/O),即:如果没有可读数据或者对端的接收缓冲区已满,则函数将一直等待直到有数据可读或者对端缓冲区可写。
函数原型:
fd 参数:指示 fd 文件描述符。
buf 参数:指示 read/write 缓冲区的入口地址。
count 参数:指示 read/write 数据的大小,单位为 Byte。
函数返回值:
-
返回实际 read/write 的字节数。
-
返回 0,表示已到达文件末尾。
-
返回 -1,表示操作失败,可以通过 errno 全局变量来获取具体的错误码。
#include <unistd.h>ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);处理流程
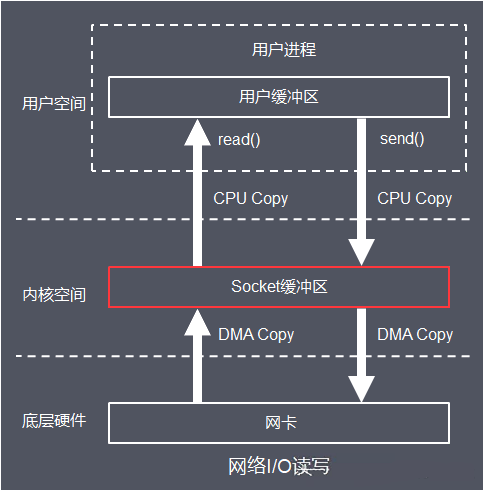
下面以同时涉及了 Storage I/O 和 Network I/O 的一次网络文件下载操作来展开 read() 和 write() 的处理流程。
read() 的处理流程:
-
Application 调用 read(),CPU 模式从用户态切换到内核态。
-
Kernel 根据 file fd 查表(进程文件符表),找到对应的 file 结构体(普通文件),从而找到此文件的 inode 编号。
-
Kernel 将 buf 和 count 参数、以及文件指针位置等信息传递给 Device Driver(磁盘驱动程序)。
-
Driver 将请求的数据从 Disk Device 中 DMA Copy 到 Kernel PageCache Buffer 中。
-
Kernel 将数据从 Kernel PageCache Buffer 中 CPU Copy 到 Userspace Buffer 中(Application 不能直接访问 Kernel space)。
-
read() 最终返回读取的字节数或错误代码给 Application,CPU 模式从内核态切换到用户态。
write() 的处理流程:
-
Application 调用 write(),CPU 模式从用户态切换到内核态。
-
Kernel 根据 socket fd 查表,找到对应的 file 结构体(套接字文件),从而找到该 Socket 的 sock 结构体。
-
Kernel 将 buf 和 count 参数、以及文件指针位置等信息传递给 Device Driver(网卡驱动程序)。
-
Driver 将请求的数据从 Userspace Buffer 中 CPU Copy 到 Kernel Socket Buffer 中。
-
Kernel 将数据从 Kernel Socket Buffer 中 DMA Copy 到 NIC Device。
-
write() 最终返回写入的字节数或错误代码给 Application,CPU 模式从内核态切换到用户态。
可见,在一次常规的 I/O(read/write)操作流程中 处理流程中,总共需要涉及到:
-
4 次 CPU 模式切换:当 Application 调用 SCI 时,CPU 从用户态切换到内核态;当 SCI 返回时,CPU 从内核态切换回用户态。
-
2 次 CPU Copy:CPU 执行进程数据拷贝指令,将数据从 User Process 虚拟地址空间 Copy 到 Kernel 虚拟地址空间。
-
2 次 DMA Copy:CPU 向 DMA 控制器下达设备数据拷贝指令,将数据从 DMA 物理内存空间 Copy 到 Kernel 虚拟地址空间。

相关视频推荐
90分钟搞定底层网络IO模型,linux开发必须要懂得10种模型
手写用户态协议栈以及零拷贝的实现
epoll的原理与使用,epoll比select/poll强在哪里?
免费学习地址:c/c++ linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

I/O 性能优化机制
I/O buff/cache
Linux Kernel 为了提高 I/O 性能,划分了一部分物理内存空间作为 I/O buff/cache,也就是内核缓冲区。当 Kernel 接收到 read() / write() 等读写请求时,首先会到 buff/cache 查找,如果找到,则立即返回。如果没有则通过驱动程序访问 I/O 外设。
查看 Linux 的 buff/cache:
$ free -mhtotal used free shared buff/cache available
Mem: 7.6G 4.2G 2.9G 10M 547M 3.1G
Swap: 4.0G 0B 4.0G实际上,Cache(缓存)和 Buffer(缓冲)从严格意义上讲是 2 个不同的概念,Cache 侧重加速 “读”,而 Buffer 侧重缓冲 “写”。但在很多场景中,由于读写总是成对存在的,所以并没有严格区分两者,而是使用 buff/cache 来统一描述。
Page Cache
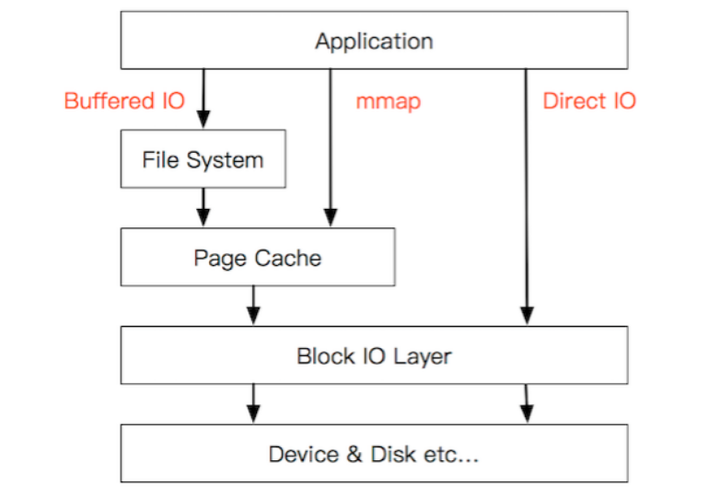
Page Cache(页缓存)是最常用的 I/O Cache 技术,以页为单位的,内容就是磁盘上的物理块,用于减少 Application 对 Storage 的 I/O 操作,能够令 Application 对文件进行顺序读写的速度接近于对内存的读写速度。
页缓存读策略:当 Application 发起一个 Read() 操作,Kernel 首先会检查需要的数据是否在 Page Cache 中:
-
如果在,则直接从 Page Cache 中读取。
-
如果不在,则按照原 I/O 路径从磁盘中读取。同时,还会根据局部性原理,进行文件预读,即:将已读数据随后的少数几个页面(通常是三个)一同缓存到 Page Cache 中。
页缓存写策略:当 Application 发起一个 write() 操作,Kernel 首先会将数据写到 Page Cache,然后方法返回,即:Write back(写回)机制,区别于 Write Through(写穿)。此时数据还没有真正的写入到文件中去,Kernel 仅仅将已写入到 Page Cache 的这一个页面标记为 “脏页(Dirty Page)”,并加入到脏页链表中。然后,由 flusher(pdflush,Page Dirty Flush)kernel thread(回写内核线程)周期性地将脏页链表中的页写到磁盘,并清理 “脏页” 标识。在以下 3 种情况下,脏页会被写回磁盘:
-
当空闲内存低于一个特定的阈值时,内核必须将脏页写回磁盘,以便释放内存。
-
当脏页在内存中驻留时间超过一个特定的阈值时,内核必须将超时的脏页写回磁盘。
-
当 Application 主动调用 sync、fsync、fdatasync 等 SCI 时,内核会执行相应的写回操作。
flusher 刷新策略由以下几个内核参数决定(数值单位均为 1/100 秒):
# flush 每隔 5 秒执行一次
$ sysctl vm.dirty_writeback_centisecs
vm.dirty_writeback_centisecs = 500# 内存中驻留 30 秒以上的脏数据将由 flush 在下一次执行时写入磁盘
$ sysctl vm.dirty_expire_centisecs
vm.dirty_expire_centisecs = 3000# 若脏页占总物理内存 10% 以上,则触发 flush 把脏数据写回磁盘
$ sysctl vm.dirty_background_ratio
vm.dirty_background_ratio = 10综上可见,Page Cache 技术在理想的情况下,可以在一次 Storage I/O 的流程中,减少 2 次 DMA Copy 操作(不直接访问磁盘)。
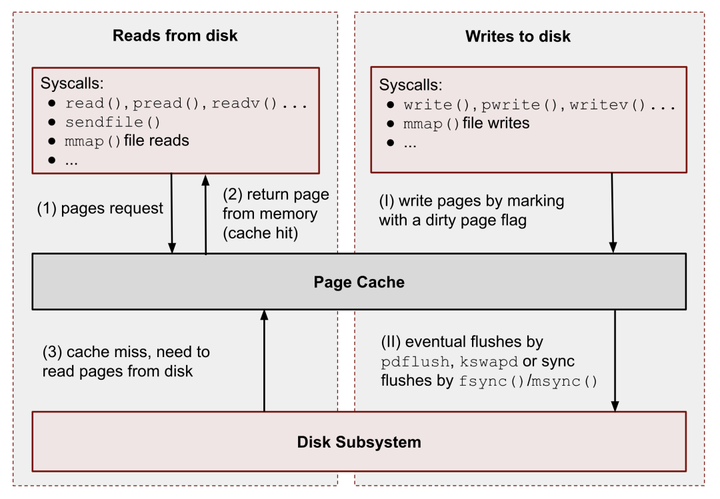
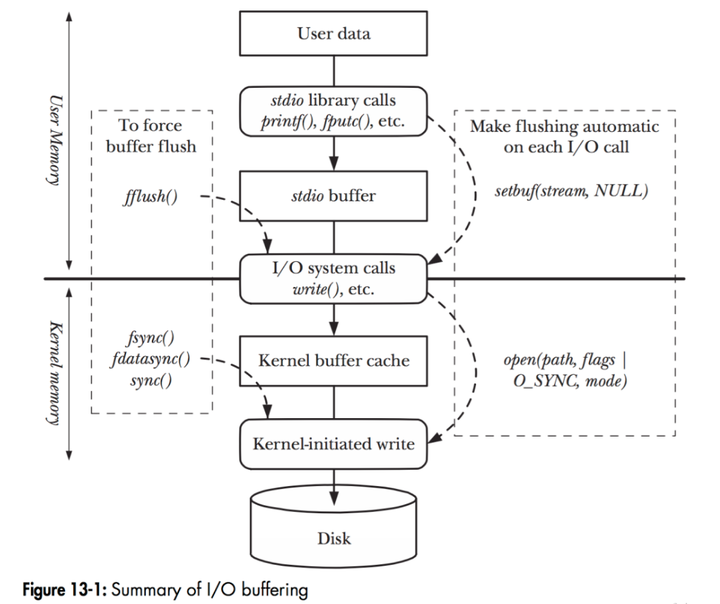
Buffered I/O
下图展示了一个 C 程序通过 stdio 库中的 printf() 或 fputc() 等输出函数来执行数据写入的操作处理流程。过程中涉及到了多处 I/O Buffer 的实现:
-
stdio buffer:在 Userspace 实现的 Buffer,因为 SCI 的成本昂贵,所以,Userspace Buffer 用于 “积累“ 到更多的待写入数据,然后再通过一次 SCI 来完成真正的写入。另外,stdio 也支持 fflush() 强制刷新函数。
-
Kernel buffer cache:处理包括上文以及提到的 Page Cache 技术之外,磁盘设备驱动程序也提供块级别的 Buffer 技术,用于 “积累“ 更多的文件系统元数据和磁盘块数据,然后在合适的时机完成真正的写入。
零拷贝技术(Zero-Copy)
零拷贝技术(Zero-Copy),是通过尽量避免在 I/O 处理流程中使用 CPU Copy 和 DMA Copy 的技术。实际上,零拷贝并非真正做到了没有任何拷贝动作,它更多是一种优化的思想。
下列表格从 CPU Copy 次数、DMA Copy 次数以及 SCI 次数这 3 个方面来对比了几种常见的零拷贝技术。可以看见,2 次 DMA Copy 是不可避免的,因为 DMA 是外设 I/O 的基本行为。零拷贝技术主要从减少 CPU Copy 和 CPU 模式切换这 2 个方面展开。
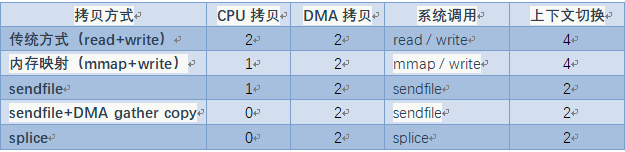
)
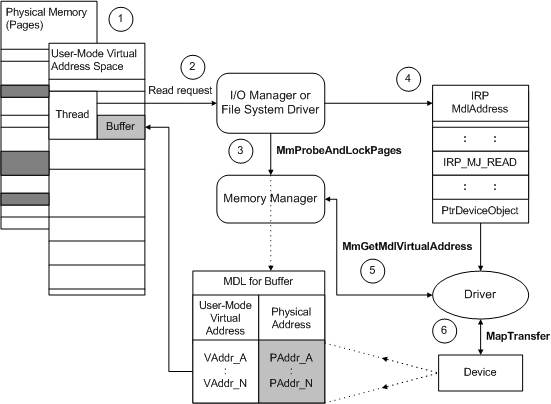
1、Userspace Direct I/O
Userspace Direct I/O(用户态直接 I/O)技术的底层原理由 Kernel space 中的 ZONE_DMA 支持。ZONE_DMA 是一块 Kernel 和 User Process 都可以直接访问的 I/O 外设 DMA 物理内存空间。基于此, Application 可以直接读写 I/O 外设,而 Kernel 只会辅助执行必要的虚拟存储配置工作,不直接参与数据传输。因此,该技术可以减少 2 次 CPU Copy。
Userspace Direct I/O 的缺点:
-
由于旁路了 要求 Kernel buffer cache 优化,就需要 Application 自身实现 Buffer Cache 机制,称为自缓存应用程序,例如:数据库管理系统。
-
由于 Application 直接访问 I/O 外设,会导致 CPU 阻塞,浪费 CPU 资源,这个问题需要结合异步 I/O 技术来规避。

具体流程看下图:Using Direct I/O with DMA
2、mmap() + write()
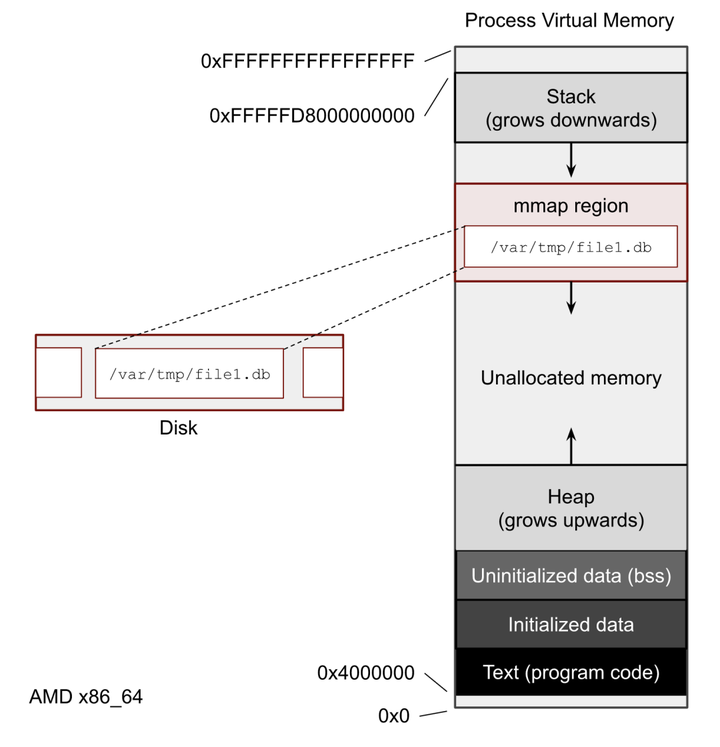
mmap() SCI 用于将 I/O 外设(e.g. 磁盘)中的一个文件、或一段内存空间(e.g. Kernel Buffer Cache)直接映射到 User Process 虚拟地址空间中的 Memory Mapping Segment,然后 User Process 就可以通过指针的方式来直接访问这一段内存,而不必再调用传统的 read() / write() SCI。
申请空间函数原型:
-
addr 参数:分配 MMS 映射区的入口地址,由 Kernel 指定,调用时传入 NULL。
-
length 参数:指示 MMS 映射区的大小。
-
prot 参数:指示 MMS 映射区的权限,可选:PROT_READ、PROT_WRITE、PROT_READ|PROT_WRITE 类型。
-
flags 参数:标志位参数,可选:
-
MAP_SHARED:映射区所做的修改会反映到物理设备(磁盘)上。
-
MAP_PRIVATE:映射区所做的修改不会反映到物理设备上。
-
fd 参数:指示 MMS 映射区的文件描述符。
-
offset 参数:指示映射文件的偏移量,为 4k 的整数倍,可以映射整个文件,也可以只映射一部分内容。
-
函数返回值:
-
成功:更新 addr 入口地址。
-
失败:更新 MAP_FAILED 宏。
void *mmap(void *adrr, size_t length, int prot, int flags, int fd, off_t offset);释放空间函数原型:
-
addr 参数:分配 MMS 映射区的入口地址,由 Kernel 指定,调用时传入 NULL。
-
length 参数:指示 MMS 映射区的大小。
-
函数返回值:
-
成功:返回 0。
-
失败:返回 -1。
int munmap(void *addr, size_t length)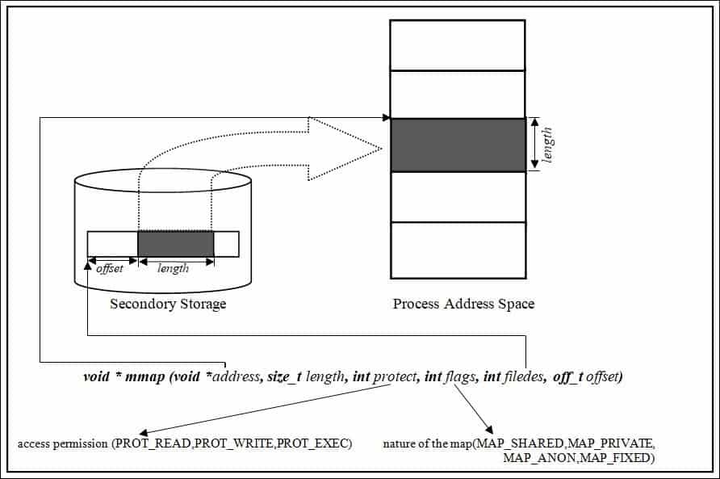
可见,mmap() 是一种高效的 I/O 方式。通过 mmap() 和 write() 结合的方式,可以实现一定程度的零拷贝优化。
// 读
buf = mmap(diskfd, len);
// 写
write(sockfd, buf, len);mmap() + write() 的 I/O 处理流程如下。
mmap() 映射:
-
Application 发起 mmap() 调用,进行文件操作,CPU 模式从用户态切换到内核态。
-
mmap() 将指定的 Kernel Buffer Cache 空间映射到 Application 虚拟地址空间。
-
mmap() 返回,CPU 模式从内核态切换到用户态。
-
在 Application 后续的文件访问中,如果出现 Page Cache Miss,则触发缺页异常,并执行 Page Cache 机制。通过已经建立好的映射关系,只使用一次 DMA Copy 就将文件数据从磁盘拷贝到 Application User Buffer 中。
write() 写入:
-
Application 发起 write() 调用,CPU 模式从用户态切换到内核态。
-
由于此时 Application User Buffer 和 Kernel Buffer Cache 的数据是一致的,所以直接从 Kernel Buffer Cache 中 CPU Copy 到 Kernel Socket Buffer,并最终从 NIC 发出。
-
write() 返回,CPU 模式从内核态切换到用户态。
可见,mmap() + write() 的 I/O 处理流程减少了一次 CPU Copy,但没有减少 CPU 模式切换的次数。另外,由于 mmap() 的进程间共享特性,非常适用于共享大文件的 I/O 场景。
mmap() + write() 的缺点:当 mmap 映射一个文件时,如果这个文件被另一个进程所截获,那么 write 系统调用会因为访问非法地址被 SIGBUS 信号终止,SIGBUS 默认会杀死进程并产生一个 coredump。解决这个问题通常需要使用文件租借锁实现。在 mmap 之前加锁,操作完之后解锁。即:首先为文件申请一个租借锁,当其他进程想要截断这个文件时,内核会发送一个实时的 RT_SIGNAL_LEASE 信号,告诉当前进程有进程在试图破坏文件,这样 write 在被 SIGBUS 杀死之前,会被中断,返回已经写入的字节数,并设置 errno 为 success。
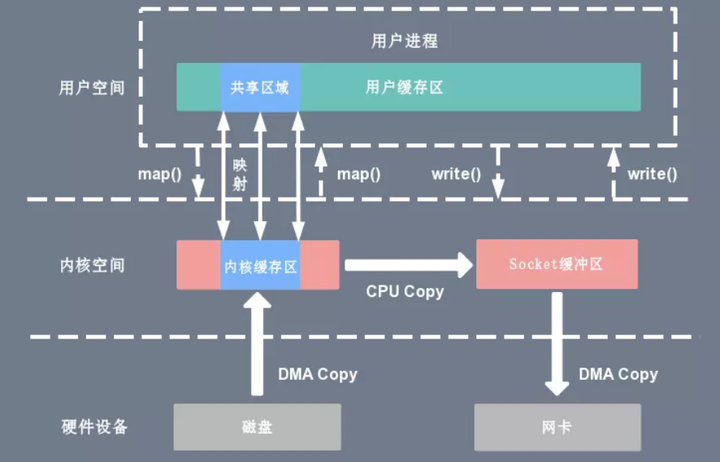
3、sendfile()
Linux Kernel 从 v2.1 开始引入了 sendfile(),用于在 Kernel space 中将一个 in_fd 的内容复制到另一个 out_fd 中,数据无需经过 Userspace,所以应用在 I/O 流程中,可以减少一次 CPU Copy。同时,sendfile() 比 mmap() 方式更具安全性。
函数原型:
-
out_fd 参数:目标文件描述符,数据输入文件。
-
in_fd 参数:源文件描述符,数据输出文件。该文件必须是可以 mmap 的。
-
offset 参数:指定从源文件的哪个位置开始读取数据,若不需要指定,传递一个 NULL。
-
count 参数:指定要发送的数据字节数。
-
函数返回值:
-
成功:返回复制的字节数。
-
失败:返回 -1,并设置 errno 全局变量来指示错误类型。
#include <sys/sendfile.h>ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);sendfile() 处理流程:
-
Application 调用 sendfile(),CPU 从用户态切换到内核态。
-
Kernel 将数据通过 DMA Copy 从磁盘设备写入 Kernel Buffer Cache。
-
Kernel 将数据从 Kernel Buffer Cache 中 CPU Copy 到 Kernel Socket Buffer。
-
Kernel 将数据从 Kernel Socket Buffer 中 DMA Copy 到 I/O 网卡设备。
-
sendfile() 返回,CPU 从内核态切换到用户态。

4、sendfile() + DMA Gather Copy
上文知道 sendfile() 还具有一次 CPU Copy,通过结合 DMA Gather Copy 技术,可以进一步优化它。
DMA Gather Copy 技术,底层有 I/O 外设的 DMA Controller 提供的 Gather 功能支撑,所以又称为 “DMA 硬件辅助的 sendfile()“。借助硬件设备的帮助,在数据从 Kernel Buffer Cache 到 Kernel Socket Buffer 之间,并不会真正的数据拷贝,而是仅拷贝了缓冲区描述符(fd + size)。待完成后,DMA Controller,可以根据这些缓冲区描述符找到依旧存储在 Kernel Buffer Cache 中的数据,并进行 DMA Copy。
显然,DMA Gather Copy 技术依旧是 ZONE_DMA 物理内存空间共享性的一个应用场景。
sendfile() + DMA Gather Copy 的处理流程:
-
Application 调用 sendfile(),CPU 从用户态切换到内核态模式。
-
Kernel 将数据通过 DMA Copy 从磁盘设备写入 Kernel Buffer Cache。
-
Kernel 将数据的缓冲区描述符从 Kernel Buffer Cache 中 CPU Copy 到 Kernel Socket Buffer(几乎不费资源)。
-
基于缓冲区描述符,CPU 利用 DMA Controller 的 Gather / Scatter 操作直接批量地将数据从 Kernel Buffer Cache 中 DMA Copy 到网卡设备。
-
sendfile() 返回,CPU 从内核态切换到用户态。

5、splice()
splice() 与 sendfile() 的处理流程类似,但数据传输方式有本质不同。
-
sendfile() 的传输方式是 CPU Copy,且具有数据大小限制;
-
splice() 的传输方式是 Pipeline,打破了数据范围的限制。但也要求 2 个 fd 中至少有一个必须是管道设备类型。
函数原型:
-
fd_in 参数:源文件描述符,数据输出文件。
-
off_in 参数:输出偏移量指针,表示从源文件描述符的哪个位置开始读取数据。
-
fd_out 参数:目标文件描述符,数据输入文件。
-
off_out 参数:输入偏移量指针,表示从目标文件描述符的哪个位置开始写入数据。
-
len 参数:指示要传输的数据长度。
-
flags:控制数据传输的行为的标志位。
#define _GNU_SOURCE /* See feature_test_macros(7) */#include <fcntl.h>ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);splice() 的处理流程如下:
-
Application 调用 splice(),CPU 从用户态切换到内核态。
-
Kernel 将数据通过 DMA Copy 从磁盘设备写入 Kernel Buffer Cache。
-
Kernel 在 Kernel Buffer Cache 和 Kernel Socket Buffer 之间建立 Pipeline 传输。
-
Kernel 将数据从 Kernel Socket Buffer 中 DMA Copy 到 I/O 网卡设备。
-
splice() 返回,CPU 从内核态切换到用户态。

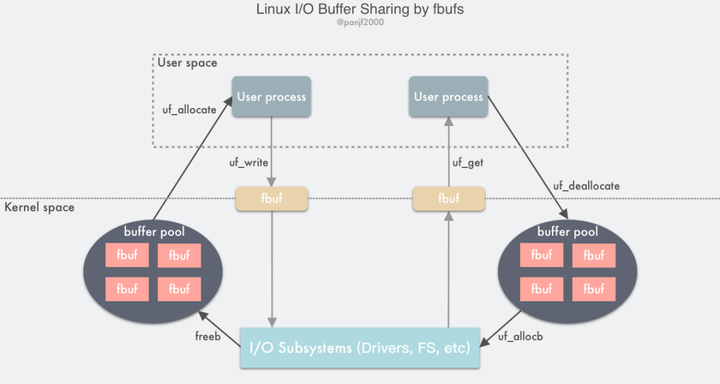
6、缓冲区共享技术
缓冲区共享技术,是对 Linux I/O 的一种颠覆,所以往往需要由 Application 和设备来共同实现。
其核心思想是:每个 Applications 都维护着一个 Buffer Pool,并且这个 Buffer Pool 可以同时映射到 Kernel 虚拟地址空间,这样 Userspace 和 Kernel space 就拥有了一块共享的空间。以此来规避掉 CPU Copy 的行为。
相关文章:
Linux实现原理 — I/O 处理流程与优化手段
Linux I/O 接口 Linux I/O 接口可以分为以下几种类型: 文件 I/O 接口:用于对文件进行读写操作的接口,包括 open()、read()、write()、close()、lseek() 等。 网络 I/O 接口:用于网络通信的接口,包括 socket()、conne…...

第 367 场 LeetCode 周赛题解
A 找出满足差值条件的下标 I 模拟 class Solution { public:vector<int> findIndices(vector<int> &nums, int indexDifference, int valueDifference) {int n nums.size();for (int i 0; i < n; i)for (int j 0; j < i; j)if (i - j > indexDiffe…...
最新百度统计配置图文教程,获取siteId、百度统计AccessToken、百度统计代码教程
一、前言 很多网友开发者都不知道百度统计siteId、百度统计token怎么获取,在网上找的教程都是几年前老的教程,因此给大家出一期详细百度统计siteId、百度统计token、百度统计代码获取详细步骤教程。 二、登录到百度统计 1.1 登录到百度统计官网 使用…...

【C++ 学习 ㉘】- 详解 C++11 的列表初始化
目录 一、C11 简介 二、列表初始化 2.1 - 统一初始化 2.2 - 列表初始化的使用细节 2.2.1 - 聚合类型的定义 2.2.2 - 注意事项 2.3 - initializer_list 2.3.1 - 基本使用 2.3.2 - 源码剖析 一、C11 简介 1998 年,C 标准委员会发布了第一版 C 标准࿰…...

OpenCV12-图像卷积
OpenCV12-图像卷积 图像卷积 图像卷积 OpenCV中提供了filt2D()函数用于实现图像和卷积模板之间的卷积运算: void filter2D(InputArray src, // 输入图像OutputArray dst, // 输出图像int ddepth, // 输出图像数据类型(深度)ÿ…...
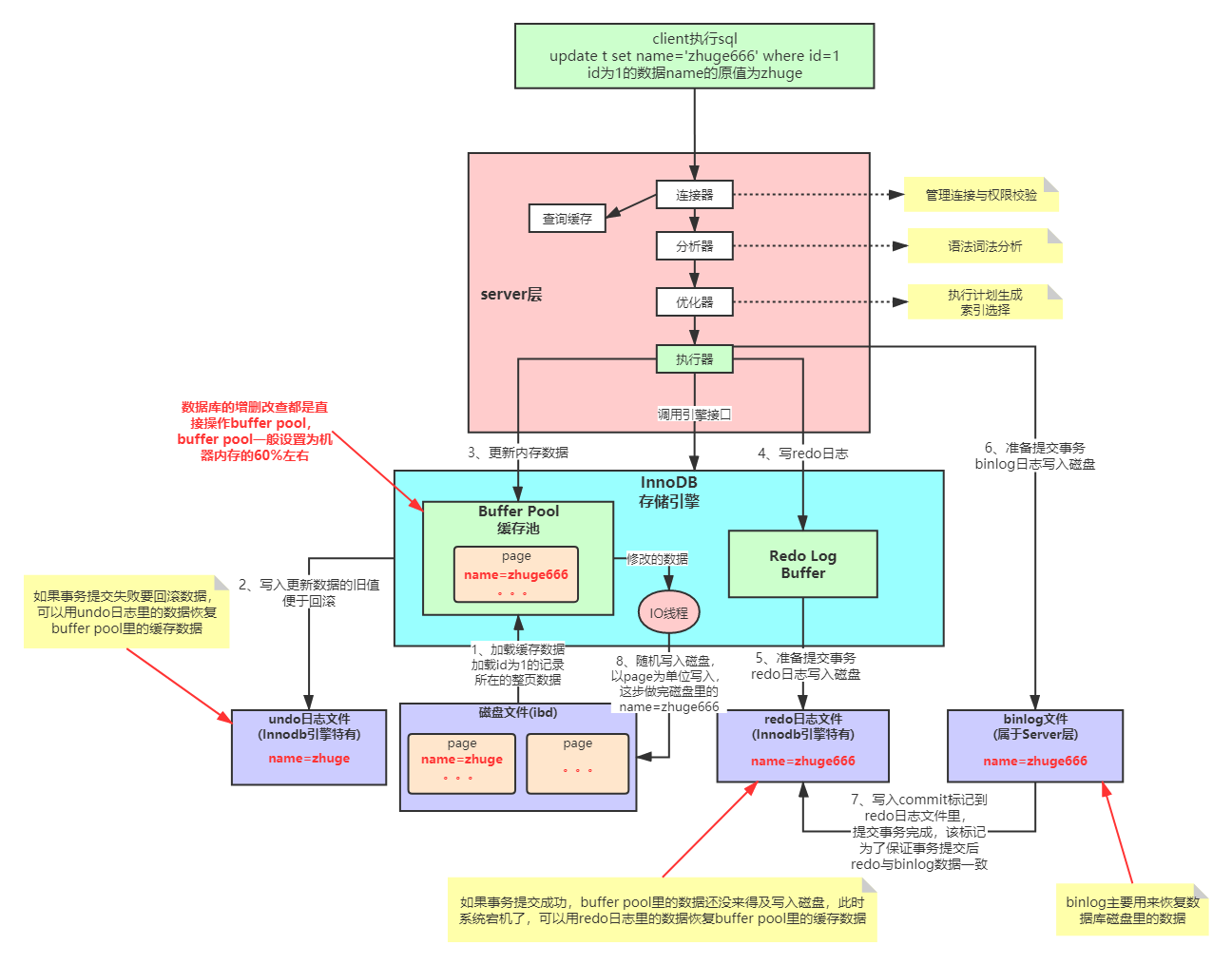
MVCC与BufferPool缓存机制
MVCC多版本并发控制机制 Mysql在可重复读隔离级别下如何保证事务较高的隔离性,我们上节课给大家演示过,同样的sql查询语句在一个事务里多次执行查询结果相同,就算其它事务对数据有修改也不会影响当前事务sql语句的查询结果。 这个隔离性就是…...
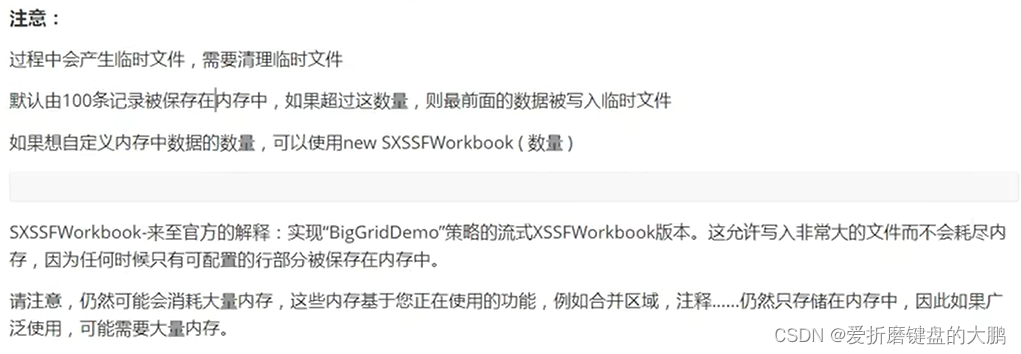
POI、Easy Excel操作Excel
文章目录 1.常用的场景2.基本功能3.Excel在Java中是一个对象4. 简单的写(07版本(.xlsx)Excel)大文件写HSSF大文件写XSSF大文件写SXSSF 5. Excel读5.1 读取遇到类型转化问题该怎么解决5.2 遇到Excel公式怎么办 6. Easy Excel6.1简单…...

网络安全(黑客)自学方向
每年报考网络安全专业的人数很多,但不少同学听说千万别学网络安全,害怕网络安全专业很难就业。下面就带大家深入了解一下网络安全专业毕业后可以干什么,包括网络安全专业的就业前景和方向等。 随着信息化时代的到来,网络安全行业…...

react写一个简单的3d滚轮picker组件
1. TreeDPicker.tsx文件 原理就不想赘述了, 想了解的话, 网址在: 使用vue写一个picker插件,使用3d滚轮的原理_vue3中支持3d picker选择器插件-CSDN博客 import React, { useEffect, useRef, Ref, useState } from "react"; import Animate from "../utils/an…...

Compose竖向列表LazyColumn
基础列表一 LazyColumn组件中用items加载数据,rememberLazyListState()结合rememberCoroutineScope()实现返回顶部。 /*** 基础列表一*/ Composable fun Items() {Box(modifier Modifier.fillMaxSize()) {val context LocalContext.currentval dataList arrayLi…...

6.自定义相机控制器
愿你出走半生,归来仍是少年! Cesium For Unity自带的Dynamic Camera,拥有优秀的动态展示效果,但是其对于场景的交互方式用起来不是很舒服。 通过模仿Cesium JS 的交互方式,实现在Unity中的交互: 通过鼠标左键拖拽实现场景平移通过…...
一文带你GO语言入门
什么是go语言? Go语言(又称Golang)是Google开发的一种静态强类型、编译型、并发型,并具有垃圾回收功能的编程语言。Go语言的主要特点包括:- 简洁和简单 - 语法简单明快,易于学习和使用 特点 高效 编译速度快,执行效率高 并发支持 原生支持并发,利用goroutine实现高效的并发…...

前后端小项目链接
1.vue的创建 vue的项目创建 1.1 vue create vue_name 1.2 Babel Router(路由) CSS Pre-processors 路由可通过:npm i vue-router3.5.2 -S 下载 1.3less 1.4 In dedicated config files 1.5 启动命令:npm run serve 端口号在vue.config。js中配置 devS…...
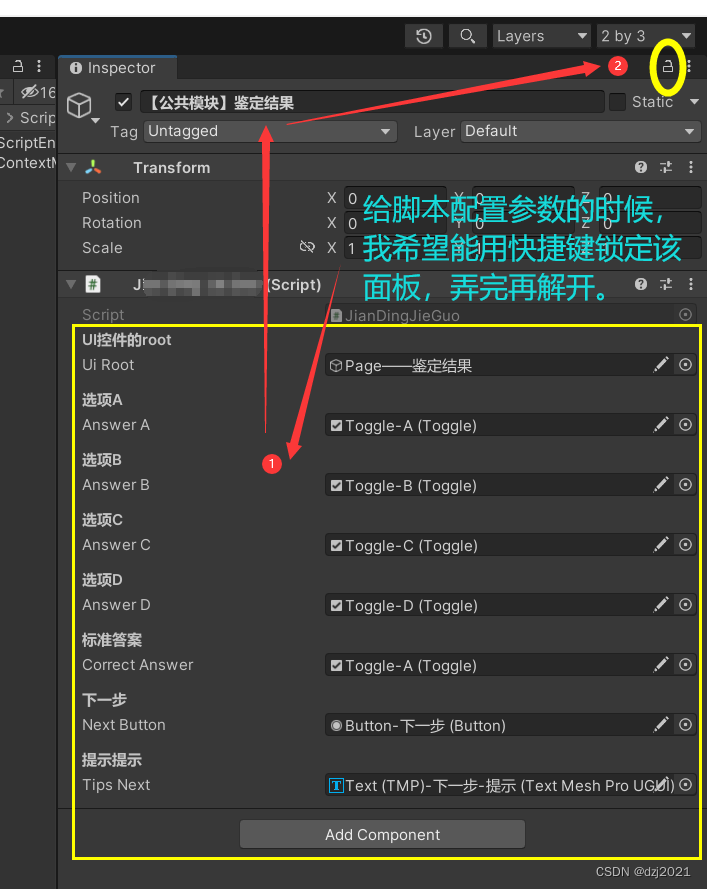
编辑器功能:用一个快捷键来【锁定】或【解开】Inspector面板
一、需求 我有一个脚本,上面暴露了许多参数,我要在场景中拖物体给它进行配置。 如果不锁定Inspector面板的话,每次点击物体后,Inspector的内容就是刚点击的物体的内容,而不是挂载脚本的参数面板。 二、 解决 &…...

Vue 网络处理 - axios 异步请求的使用,请求响应拦截器(最佳实践)
目录 一、axiox 1.1、axios 简介 1.2、axios 基本使用 1.2.1、下载核心 js 文件. 1.2.2、发送 GET 异步请求 1.2.3、发送 POST 异步请求 1.2.4、发送 GET、POST 请求最佳实践 1.3、请求响应拦截器 1.3.1、拦截器解释 1.3.2、请求拦截器的使用 1.3.3、响应拦截器的使…...
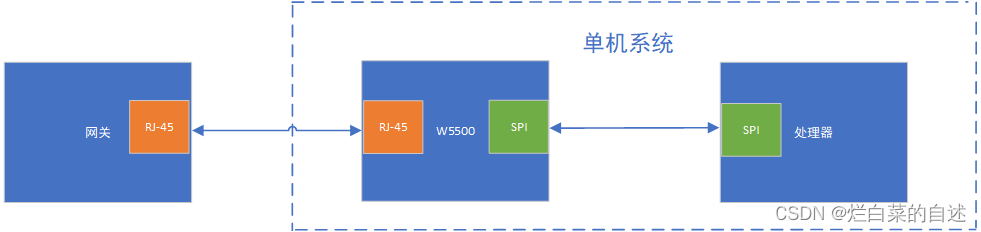
关于W5500网卡使用过程的部分问题记录
某个项目中用到了W5500这种自带网络协议栈的网卡芯片,由于该项目开发时间很紧,就临时网上买了一些模块拼凑到了一套系统,经过验证果真这种拼积木的方法只能用在学生实验开发中,真不能拿来做工程应用,硬件太不稳定很容易…...

Unity DOTS World Entity ArchType Component EntityManager System概述
最近DOTS终于发布了正式的版本, 我们来分享以下DOTS里面地几个关键概念,方便大家上手学习掌握Unity DOTS开发。 Unity DOTS 中所有的Entities 都是被放到World世界中。每个Entity在它所在的World里面有唯一不同的ID号来区分。DOTS项目中可以同时有多个World。每个W…...
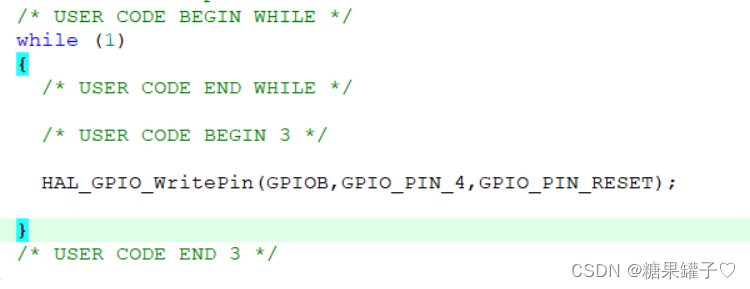
最详细STM32,cubeMX 点亮 led
这篇文章将详细介绍 如何在 stm32103 板子上点亮一个LED. 文章目录 前言一、开发环境搭建。二、LED 原理图解读三、什么是 GPIO四、cubeMX 配置工程五、解读 cubeMX 生成的代码六、延时函数七、控制引脚状态函数点亮 LED 八、GPIO 的工作模式九、为什么使用推挽输出驱动 LED总结…...
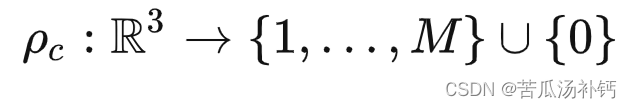
论文阅读:Image-to-Lidar Self-Supervised Distillation for Autonomous Driving Data
目录 摘要 Motivation 整体架构流程 技术细节 雷达和图像数据的同步 小结 论文地址: [2203.16258] Image-to-Lidar Self-Supervised Distillation for Autonomous Driving Data (arxiv.org) 论文代码:GitHub - valeoai/SLidR: Official PyTorch implementati…...

前端版本控制工具,常见的Git 和SVN
目录 前言GitGit简介Git的优势Git常用指令常见的Git服务 SVN (Subversion)SVN简介SVN的优势SVN常用指令SVN与Git的区别 👍 点赞,你的认可是我创作的动力! ⭐️ 收藏,你的青睐是我努力的方向! ✏️ 评论,你…...

HoRain云--Skills 基本结构
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

Real-is-Sim框架:动态数字孪生在机器人控制中的创新应用
1. Real-is-Sim框架概述:动态数字孪生的创新实践在机器人控制领域,仿真到现实的迁移(sim-to-real)一直是个棘手难题。传统方法往往面临"仿真太完美,现实太复杂"的困境——在虚拟环境中训练的策略,…...

如何在macOS上免费解锁百度网盘SVIP下载限速?终极解决方案
如何在macOS上免费解锁百度网盘SVIP下载限速?终极解决方案 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS BaiduNetdiskPlugin-macOS是一款…...

避坑指南:用TensorFlow 2.x和HuggingFace Transformers搞定中文NER,我踩过的这些坑你别再踩
中文NER实战避坑手册:TensorFlow 2.x与HuggingFace Transformers的进阶技巧 在自然语言处理领域,命名实体识别(NER)一直是核心任务之一。对于中文文本而言,由于语言特性的差异,开发者往往会遇到比英文NER更…...

深度学习嵌入操作优化与DAE架构实践
1. 嵌入操作与DAE架构的核心挑战在深度学习推荐系统和图神经网络中,嵌入操作(Embedding Operations)占据了超过60%的计算时间。这类操作本质上是一种特殊的稀疏-密集张量乘法(SpMM),其计算模式具有两个显著…...

星际探险队
目录 星际探险队 游戏目标 游戏准备 核心玩法 沟通技能 星际探险队 2-5人的合作桌游 游戏目标 合作完成任务卡目标,如赢得特定牌墩、特定卡牌或特定数量牌墩 游戏准备 牌组:共 40 张牌,含 4 种颜色(1-9)和王…...

Habitat-Lab:Meta开源具身AI仿真平台,从零搭建智能体训练场
1. 项目概述:从虚拟到现实的智能体训练场如果你对机器人、具身智能或者强化学习感兴趣,那么“Habitat-Lab”这个名字你大概率不会陌生。简单来说,Habitat-Lab是一个由Meta AI(前Facebook AI Research)开源的、用于具身…...
)
学一下PLC2--软件PLC(TODO)
既然你手头有 Raspberry Pi Pico,你甚至不需要买任何新的 PLC 硬件,可以直接把它变成一个标准的工业 PLC! 实现原理: OpenPLC 是一个开源的符合 IEC 61131-3 国际标准的 PLC 软件系统。 它完美支持 Raspberry Pi Pico (RP2040)。…...

终极Koikatu游戏增强补丁:200+模组与完整汉化一键安装指南
终极Koikatu游戏增强补丁:200模组与完整汉化一键安装指南 【免费下载链接】KK-HF_Patch Automatically translate, uncensor and update Koikatu! and Koikatsu Party! 项目地址: https://gitcode.com/gh_mirrors/kk/KK-HF_Patch KK-HF Patch是专为Koikatu&a…...

二叉搜索树:高效查找与增删详解
引言在上一篇树结构开篇文章中,我们建立了树的基本概念、二叉树的定义和四种遍历方式。本文将继续深入,讲解二叉搜索树(Binary Search Tree,BST)——它是最基础的"有组织"二叉树,也是后续学习 AV…...