Hadoop3教程(二十):MapReduce的工作机制总结
文章目录
- (109)MapTask工作机制
- (110)ReduceTask工作机制&并行度
- ReduceTask工作机制
- MapTask和ReduceTask的并行度决定机制
- (122)MapReduce开发总结
- 参考文献
(109)MapTask工作机制
MapTask的完整工作流程如图:
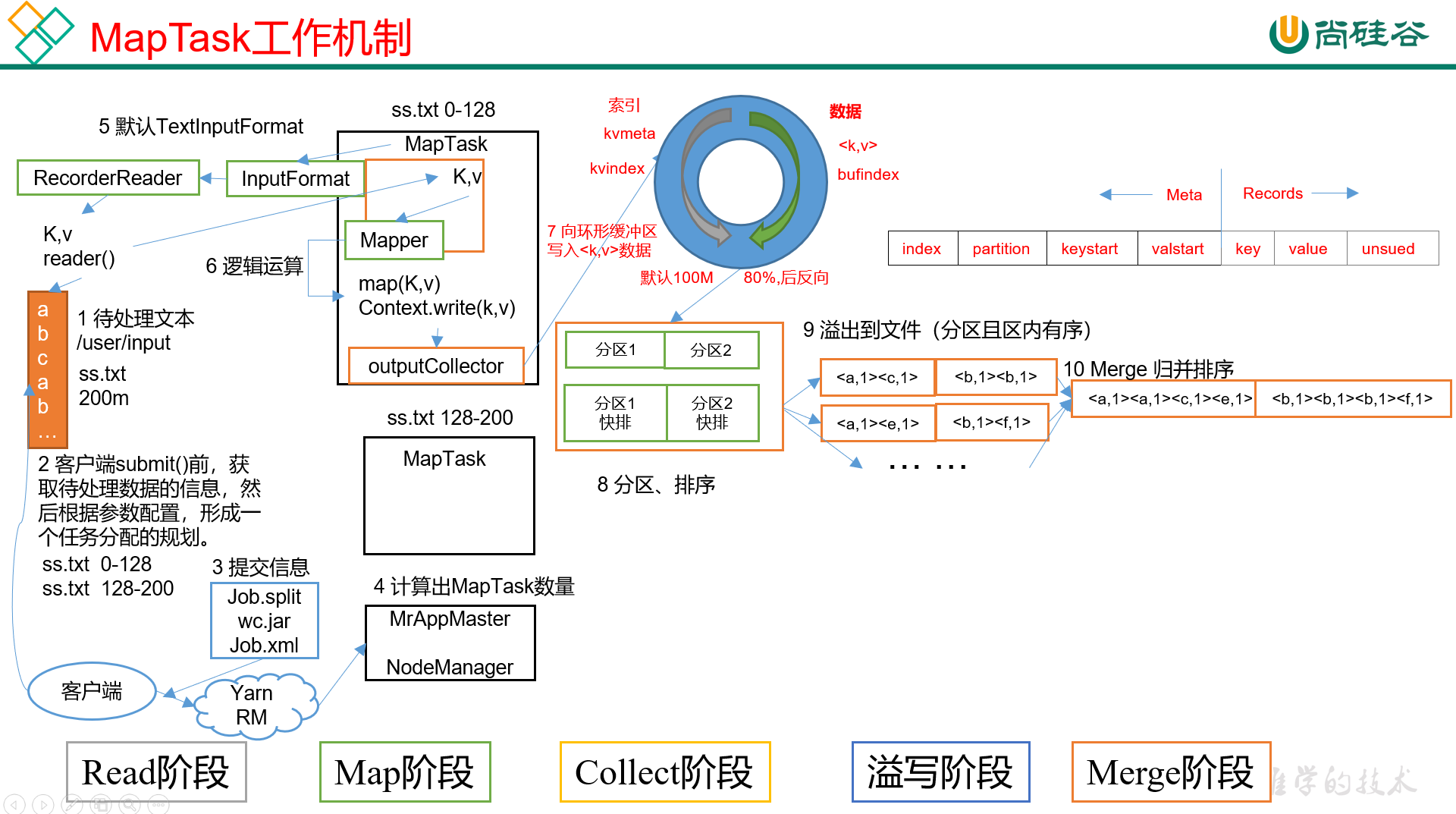
依图可见,MapTask一共分为5个阶段:
- Read阶段
- Map阶段
- Collect阶段
- 溢写阶段
- Merge阶段
1) Read阶段:首先是job的提交流程,客户端会读取待处理文件的信息,然后做切片规划,接着把信息和切片规划都提交到YARN,YARN会计算出所需要的MapTask的数量,之后才会正式进入MapTask;
MapTask会调用InputFormat读取数据,K是偏移量,v是这一行的文本,这就是Read阶段;
2) Map阶段,会进入自定义Mapper,执行我们在map()里定义的业务逻辑;
3) Collect阶段。把Map阶段处理的数据,通过调用OutputCollector.collect()来持续的发送到环形缓冲区,这个过程中会给每个KV对打上分区标记;
4) Spill阶段,即溢写阶段。当缓冲区写到80%之后,触发溢写,MR会将环形缓冲区的数据排序后写到本地磁盘上,生成一个临时文件。
4.1) 溢写时,首先使用快速排序算法,对缓冲区内的数据进行排序。排序的方式是,先按照分区编号Partition进行排序,然后再按照key进行排序。经过这样排序之后,数据以分区为单位聚集在一起,同时区内数据是按照key有序;
4.2) 按照分区编号从小到大依次将每个分区的数据写入临时文件output/spillN.out中,其中N表示当前溢写的次数。如果设置了Combiner,则会先进行分区内Combiner之后,再写入文件;
4.3) 将分区数据的元信息写到内存索引数据结构spillRecord中,其中每个分区数据的元信息包括:在临时文件中的偏移量、压缩前数据大小和压缩后数据大小。方便后续按照分区提取数据。如果当前内存索引大小占用超过1MB,则会将内存索引写到output/spillN.out.index里。
5) Merge阶段。当前MapTask的所有数据处理完成后,会对自己溢写输出的所有文件做归并,确保最终只生成一个数据文件。(避免小文件创建和读取的开销)
最终的大文件合并完成后,MapTask会将其保存到output/file.out里,同时生成相应的索引文件output/file.out.index。
在文件合并过程中,是以分区为单位进行合并。对于某个分区,采用多轮递归合并的方式,每轮合并mapreduce.task.io.sort.factor(默认为10)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件。
(110)ReduceTask工作机制&并行度
ReduceTask工作机制
ReduceTask的完整工作流程如下图:
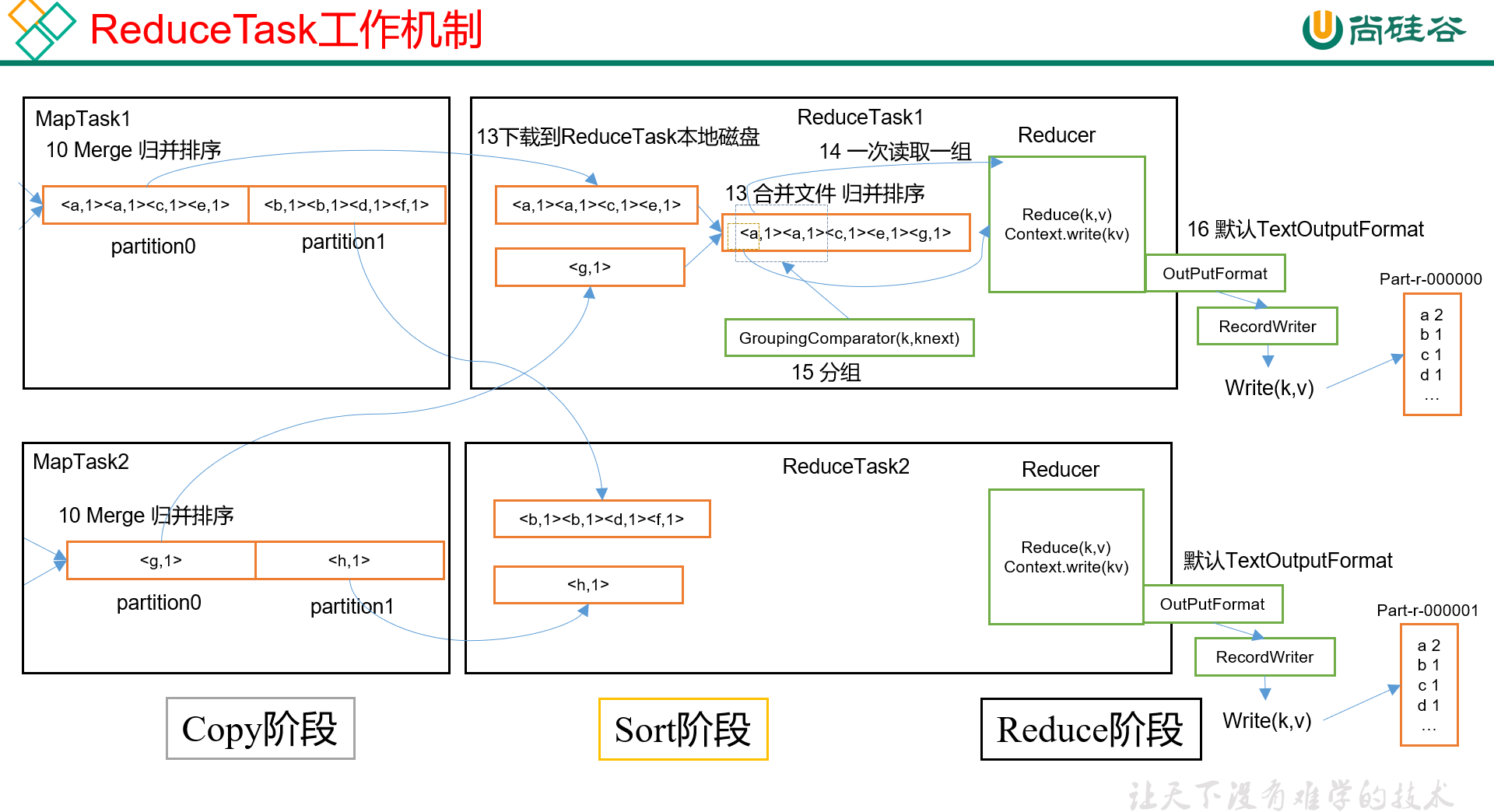
由图可知,ReduceTask分为3个阶段:
- Copy阶段
- Sort阶段(或者是merge + sort阶段)
- Reduce阶段
1) Copy阶段,每个ReduceTask负责处理一个分区的数据,首先每个ReduceTask会从各个MapTask归并完的文件里,将对应分区的数据拷贝过来。相当于是从每个MapTask都取一片数据,如果这片数据大小超过阈值,那么就写到磁盘上,否则就直接放进内存里。
2) 接下来进入Sort阶段,每个ReduceTask会对自己拉取过来的那堆数据,做归并排序。
ReduceTask在远程拷贝数据的同时,也会启动两个后台线程,对内存和磁盘上的文件进行合并,以防止内存中数据过多,或者磁盘上文件过多。由于每个MapTask对自己的数据已经进行了局部排序,因此ReduceTask只需要对拿到的所有数据进行一次归并排序即可。(子序列有序,合并多个子序列的算法)
3) 最后进入Reduce阶段,将上一阶段的文件送进Reduce()里,执行自定义的业务逻辑,并调用绑定的OutputFormat,将处理结果以指定形式输出到指定介质。
MapTask和ReduceTask的并行度决定机制
MapTask并行度是由切片个数决定的,而切片个数则是由输入文件和切片规则决定的。
那ReduceTask的并行度是由谁决定的?
ReduceTask的数量是可以手动设置的,通过在驱动类里编写如下代码:
job.setNumReduceTasks(4); // 设置为4个ReduceTask
设置ReduceTask数量=0的时候,表示没有reduce阶段,输出文件个数跟map阶段一致。
如果数据分布不均匀的话,就有可能在Reduce阶段产生数据倾斜(单个分区数据过多,导致与其对应的ReduceTask处理压力过大),这个可以实际观察一下。
如果分区数不是1,但是设置的ReduceTask数量是1,那么将不会执行分区阶段。因为分区的时候会先判断ReduceTaskNum是否大于1,不大于1就不会执行分区逻辑。这个其实之前的时候也有讲过来着。
既然ReduceTask的数量是需要人为指定的,那么这个数量设置多少比较合适?
只能说不一定,需要考虑业务的需求,还需要结合集群的性能,来综合评定。
在有的情况下,需要计算全局汇总结果,那就只有一个ReduceTask就够了。
教程里做了一个简单的测试,我直接贴一下:
实验环境:1个Master节点,16个Slave节点,CPU都是8GHZ,内存都是2G。
当处理1GB数据时,改变ReduceTask的数量,总处理时长的变化为:
| MapTask =16 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ReduceTask | 1 | 5 | 10 | 15 | 16 | 20 | 25 | 30 | 45 | 60 |
| 总时间 | 892 | 146 | 110 | 92 | 88 | 100 | 128 | 101 | 145 | 104 |
所以可以看到,一般来讲,ReduceTask的数量,不是越多越好,同样的,也不是越少越好。还是得视情况具体分析。
(122)MapReduce开发总结
接下来,按照执行的顺序,简单过一下MR处理过程中涉及到的一些组件,或者说一些环节:
1) 输入数据接口:InputFormat
默认的是TextInputFormat,输入的K是偏移量(功能上可简单理解成行号,但其实不是),V是对应的一行内容。但是一个文件至少占一片,因此处理不了大量小文件的场景。
处理大量小文件时应该用CombineTextInputFormat,可以把多个文件合并在一起统一切片,其中会涉及虚拟存储的概念;
2)逻辑处理接口:Mapper
数据进入Mapper之后,会按顺序执行下面三个方法:
setup(),负责初始化map(),用户的业务逻辑cleanup(),最后调用,关闭资源;
之后,数据进入到shuffle阶段。
3)分区:Partitioner
默认的是HashPartitioner,即按照key的hashcode值 % numReducer个数来计算key所属分区。
可根据业务需要,自定义分区类。
4)排序:Comparable
MR中的排序默认是字典排序,即按照字母或者数字,由小到大排序。
不同场景下的排序,拥有不同的名字:
- 部分排序:即每个输出的文件,内部有序,文件和文件之间无序;
- 全排序:相当于一个Reduce,对所有数据排序,慎用,所有数据放在一台节点上,容易OOM;
- 二次排序:即拥有两个排序条件,它属于自定义排序的范畴,需要实现WritableCompare接口,并重写其中的compareTo()来添加大小比较的逻辑;
5)合并:Combiner(可选阶段)
Combiner其实是一类运行在单个MapTask的Reducer。
通过在shuffle的几个阶段里做预聚合,如可以将(a,1)、(a,1)这样的数据聚合成(a,2),从而减少数据量,避免无谓的IO传输。
前提是不影响最终的业务逻辑(求和没啥问题),其实就是提前在map阶段聚合,这样算是降低了Reducer端的压力,这也是解决数据倾斜的一个方法。
同样的,Combiner也可以自定义,可编写自己需要的、同时不影响业务的聚合逻辑。
6)逻辑处理接口:Reducer
数据进入Reducer之后,会按顺序执行下面三个方法:
- setup() 初始化
- reduce() 用户的业务逻辑;
- clearup() 关闭清理资源
7)输出数据接口:OutputFormat
默认是TextOutputFormat,即将每个KV对,作为一行输出到目标文件;同样支持自定义。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
相关文章:
Hadoop3教程(二十):MapReduce的工作机制总结
文章目录 (109)MapTask工作机制(110)ReduceTask工作机制&并行度ReduceTask工作机制MapTask和ReduceTask的并行度决定机制 (122)MapReduce开发总结参考文献 (109)MapTask工作机制…...

浅谈AI大模型技术:概念、发展和应用
AI大模型技术是指使用超大规模的深度学习模型来解决各种复杂的人工智能问题,如自然语言处理、计算机视觉、多模态交互等。AI大模型技术具有强大的学习能力和泛化能力,可以在多种任务上取得优异的性能,但也面临着计算、存储、通信等方面的挑战…...
【Leetcode】212.单词搜索II(Hard)
一、题目 1、题目描述 给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words, 返回所有二维网格上的单词 。 单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中…...

146.LRU缓存
双向链表哈希表 class LRUCache { public://1、定义双向链表结构、容量、哈希表等LRU数据成员struct Node{int key,value;Node *left,*right;Node(int _key,int _value):key(_key),value(_value),left(NULL),right(NULL){}}*L,*R;int n;unordered_map<int,Node*> ump;//…...
使用transformers过程中出现的bug
1. The following model_kwargs are not used by the model: [encoder_hidden_states, encoder_attention_mask] (note: typos in the generate arguments will also show up in this list) 使用text_decoder就出现上述错误,这是由于transformers版本不兼容导致的 …...
Hadoop3教程(二十二):Yarn的基础架构与工作流程
文章目录 (126)基础架构(127)YARN的工作机制(128)作业全流程参考文献 (126)基础架构 之前基本介绍完了Hadoop的几个核心组件,接下来可以思考下,在MR程序运行…...
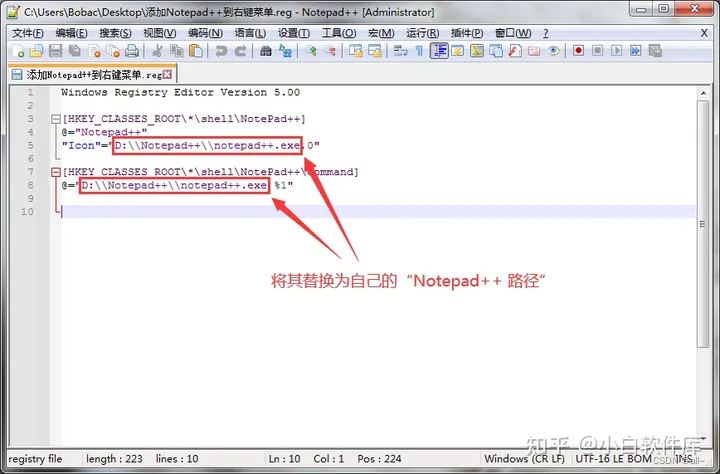
离线 notepad++ 添加到右键菜单
复制下面代码,修改文件后缀名为:reg Windows Registry Editor Version 5.00[HKEY_CLASSES_ROOT\*\shell\NotePad] "Notepad" "Icon""D:\\Notepad\\notepad.exe,0"[HKEY_CLASSES_ROOT\*\shell\NotePad\Command] "D:\…...

怎么让英文大语言模型支持中文?--构建中文tokenization--继续预训练--指令微调
1 构建中文tokenization 参考链接:https://zhuanlan.zhihu.com/p/639144223 1.1 为什么需要 构建中文tokenization? 原始的llama模型对中文的支持不太友好,接下来本文将讲解如何去扩充vocab里面的词以对中文进行token化。 1.2 如何对 原始数…...
)
笙默考试管理系统-MyExamTest----codemirror(35)
笙默考试管理系统-MyExamTest----codemirror(35) 目录 一、 笙默考试管理系统-MyExamTest 二、 笙默考试管理系统-MyExamTest 三、 笙默考试管理系统-MyExamTest 四、 笙默考试管理系统-MyExamTest 五、 笙默考试管理系统-MyExamTest 笙默考试…...
)
MMKV(2)
API 初始化和实例获取: MMKV.initialize(Context context): 初始化MMKV库。通常在应用程序的入口点调用此方法。 MMKV.defaultMMKV(): 获取默认的MMKV实例。默认实例使用默认的存储路径和加密方式。 MMKV.mmkvWithID(String mmapID): 根据给定的ID获取MMKV实例。…...
Spring Boot项目中使用 TrueLicense 生成和验证License(附源码)
1、Linux 在客户linux上新建layman目录,导入license.sh文件, [rootlocalhost layman]# mkdir -p /laymanlicense.sh文件内容: #!/bin/bash # 1.获取要监控的本地服务器IP地址 IPifconfig | grep inet | grep -vE inet6|127.0.0.1 | awk {p…...

ES6 Iterator 和 for...of 循环
1.iterator 概念 ES6 添加了Map和Set。这样就有了四种数据集合,需要一种统一的接口机制来处理所有不同的数据结构。遍历器(Iterator)就是这样一种机制。它是一种接口,为各种不同的数据结构提供统一的访问机制。任何数据结构只要部…...
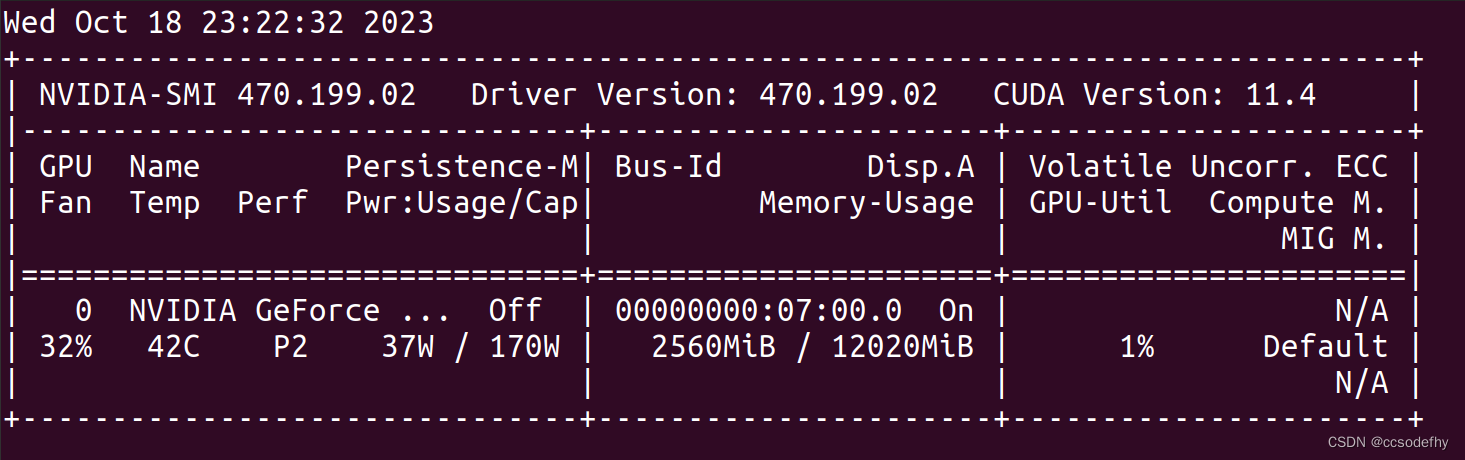
ubuntu20.04 nvidia显卡驱动掉了,变成开源驱动,在软件与更新里选择专有驱动,下载出错,调整ubuntu镜像源之后成功修复
驱动配置好,环境隔了一段时间,打开Ubuntu发现装好的驱动又掉了,软件与更新 那里,附加驱动,显示开源驱动,命令行输入 nvidia-smi 命令查找不到驱动。 点击上面的 nvidia-driver-470(专有&#x…...

华为FAT模式无线AP配置实例
硬件:AP3010DN 软件版本:VRP software, Version 5.170 (AP3010DN-V2 FAT V200R010C00SPCf02) [Huawei]dis ver Huawei Versatile Routing Platform Software VRP (R) software, Version 5.170 (AP3010DN-V2 FAT V200R010C00SPCf02) Copyright (C) 2011…...
nodejs基于vue 学生论坛设计与实现
随着网络技术的不断成熟,带动了学生论坛,它彻底改变了过去传统的管理方式,不仅使服务管理难度变低了,还提升了管理的灵活性。 是本系统的开发平台 系统中管理员主要是为了安全有效地存储和管理各类信息, 这种个性化的平…...

017 基于Spring Boot的食堂管理系统
部分代码地址: https://github.com/XinChennn/xc017-stglxt 基于Spring Boot的食堂管理系统 项目介绍 本项目是基于Java的管理系统。采用前后端分离开发。前端基于bootstrap框架实现,后端使用Java语言开发,技术栈包括但不限于SpringBoot、…...
-C++)
常用的二十种设计模式(下)-C++
设计模式 C中常用的设计模式有很多,设计模式是解决常见问题的经过验证的最佳实践。以下是一些常用的设计模式: 单例模式(Singleton):确保一个类只有一个实例,并提供一个全局访问点。工厂模式(…...
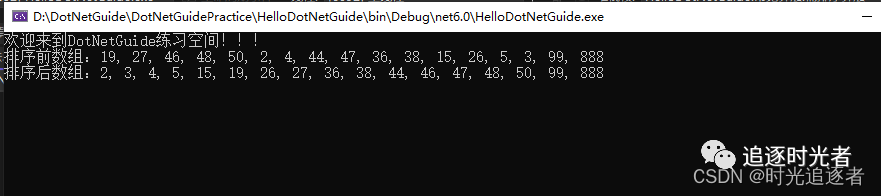
C#桶排序算法
前言 桶排序是一种线性时间复杂度的排序算法,它将待排序的数据分到有限数量的桶中,每个桶再进行单独排序,最后将所有桶中的数据按顺序依次取出,即可得到排序结果。 实现原理 首先根据待排序数据,确定需要的桶的数量。…...
快速了解服务器单CPU与双CPU
在当今快节奏的技术环境中,用户们对功能强大且高效的服务器配置需求不断增长。CPU作为构成任何计算基础设施的骨干,服务器的“大脑”,负责执行计算、控制数据流并协调各个组件之间的任务,是服务器选择硬件中的重要一环。因此…...

c# Dictionary、ConcurrentDictionary的使用
Dictionary Dictionary 用于存储键-值对的集合。如果需要高效地存储键-值对并快速查找,请使用 Dictionary。 注意,键必须是唯一的,值可以重复。 using System; using System.Collections.Generic; using System.Linq;class Program {stati…...

多模态交互概念展示:LFM2.5-1.2B-Thinking-GGUF如何理解并处理图像描述文本
多模态交互概念展示:LFM2.5-1.2B-Thinking-GGUF如何理解并处理图像描述文本 1. 当文本模型遇见视觉世界 你可能好奇,一个纯文本模型如何参与多模态交互?关键在于语义桥梁的搭建。LFM2.5-1.2B-Thinking-GGUF虽然不能直接处理图像,…...

如何用JSON Crack将复杂数据一键转化为交互式图表:新手必备的可视化指南
如何用JSON Crack将复杂数据一键转化为交互式图表:新手必备的可视化指南 【免费下载链接】jsoncrack.com ✨ Innovative and open-source visualization application that transforms various data formats, such as JSON, YAML, XML, CSV and more, into interacti…...

5分钟快速上手:Rufus免费工具制作Windows启动盘终极指南
5分钟快速上手:Rufus免费工具制作Windows启动盘终极指南 【免费下载链接】rufus The Reliable USB Formatting Utility 项目地址: https://gitcode.com/GitHub_Trending/ru/rufus 还在为系统安装而烦恼吗?Rufus作为一款完全免费的USB格式化工具&a…...

腾讯音乐开源的SuperSonic到底强在哪?手把手教你配置专属数据分析Agent
腾讯音乐SuperSonic深度解析:如何打造智能数据问答Agent 当企业数据量呈指数级增长时,传统BI工具已经难以满足实时决策的需求。腾讯音乐开源的SuperSonic作为新一代AIBI平台,通过融合Chat BI与Headless BI两大范式,正在重新定义数…...

M5Stack舵机驱动库:PCA9685硬件PWM控制与多平台移植
1. 项目概述M5Hat-8Servos 是专为 M5Stack 生态设计的硬件驱动库,用于控制 M5Stack 官方推出的HAT-8SERVO扩展模块。该模块基于PCA9685 16通道12位PWM LED与伺服驱动芯片,通过 IC 总线与主控(如 M5Stack Core2、M5Stamp C3、M5Paper 等&#…...

GLM-4.1V量化模型实测:NPU部署精度仅差0.17%
GLM-4.1V量化模型实测:NPU部署精度仅差0.17% 【免费下载链接】GLM-4.1V-9B-Thinking-w8a8s-310 项目地址: https://ai.gitcode.com/Eco-Tech/GLM-4.1V-9B-Thinking-w8a8s-310 导语:近日,基于GLM-4.1V-9B-Thinking模型的量化版本GLM-4…...
)
用Python+WeChatOpenDevTools搞定微信小程序数据抓取:以‘六六找房’为例(附完整源码)
Python逆向解析微信小程序数据实战:以租房平台为例 微信小程序因其便捷性已成为许多服务的主要入口,但数据获取却常让开发者头疼。不同于传统网页爬虫,小程序的数据接口往往经过加密处理,常规请求难以直接获取有效信息。本文将分享…...

BlueDot BME280库深度解析:嵌入式多传感器驱动实践
1. BlueDot BME280 库技术解析:面向嵌入式工程师的多传感器驱动实践指南BME280 是博世(Bosch)推出的高精度环境传感器,集成温度、相对湿度与气压三参数测量能力,广泛应用于气象站、IoT终端、无人机姿态补偿及室内环境监…...

模型微调加速:OpenClaw对接nanobot的LoRA训练
模型微调加速:OpenClaw对接nanobot的LoRA训练 1. 为什么选择OpenClawnanobot进行模型微调 去年我在尝试用Qwen3-4B模型处理专业领域任务时,发现直接使用基础模型的效果总差强人意。模型要么对专业术语理解不到位,要么生成的回答缺乏领域特性…...
)
5分钟搞定!用PySide2+Python快速搭建串口助手(附完整源码)
5分钟搞定!用PySide2Python快速搭建串口助手(附完整源码) 1. 为什么选择PySide2开发串口工具? 在嵌入式开发和物联网项目中,串口调试工具就像工程师的"瑞士军刀"。传统方案如C/QT开发周期长,而Py…...