搭建伪分布式Hadoop
文章目录
- 一、Hadoop部署模式
- (一)独立模式
- (二)伪分布式模式
- (三)完全分布式模式
- 二、搭建伪分布式Hadoop
- (一)登录虚拟机
- (二)上传安装包
- (三)配置免密登录
- 1、生成密钥对
- 2、将生成的公钥发送到本机
- 3、验证虚拟机是否能免密登录自己
- (四)配置JDK
- 1、解压到指定目录
- (1)解压到指定目录
- (2)查看java解压目录
- 2、配置JDK环境变量
- 3、让环境变量配置生效
- 4、查看JDK版本
- 5、玩一玩Java程序
- (五)配置Hadoop
- 1、解压hadoop安装包
- (1)解压到指定目录
- (2)查看hadoop解压目录
- (3)常用目录和文件
- 2、配置hadoop环境变量
- 3、让环境变量配置生效
- 4、查看hadoop版本
- 5、编辑Hadoop环境配置文件 - hadoop-env.sh
- 6、编辑Hadoop核心配置文件 - core-site.xml
- 7、编辑HDFS配置文件 - hdfs-site.xml
- 8、编辑MapReduce配置文件 - mapred-site.xml
- 9、编辑YARN配置文件 - yarn-site.xml
- 10、编辑workers文件确定数据节点
- (六)格式化名称节点
- (七)启动Hadoop服务
- 1、启动hdfs服务
- 2、启动yarn服务
- 3、查看Hadoop进程
- (八)查看Hadoop WebUI
- (九)关闭Hadoop服务
- 1、关闭hdfs服务
- 2、关闭yarn服务
一、Hadoop部署模式
(一)独立模式
- 在独立模式下,所有程序都在单个JVM上执行,调试Hadoop集群的MapReduce程序也非常方便。一般情况下,该模式常用于学习或开发阶段进行调试程序。
(二)伪分布式模式
- 在伪分布式模式下, Hadoop程序的守护进程都运行在一台节点上,该模式主要用于调试Hadoop分布式程序的代码,以及程序执行是否正确。伪分布式模式是完全分布式模式的一个特例。
(三)完全分布式模式
- 在完全分布式模式下,Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节点担任不同的角色,在实际工作应用开发中,通常使用该模式构建企业级Hadoop系统。
二、搭建伪分布式Hadoop
(一)登录虚拟机
- 登录ied虚拟机
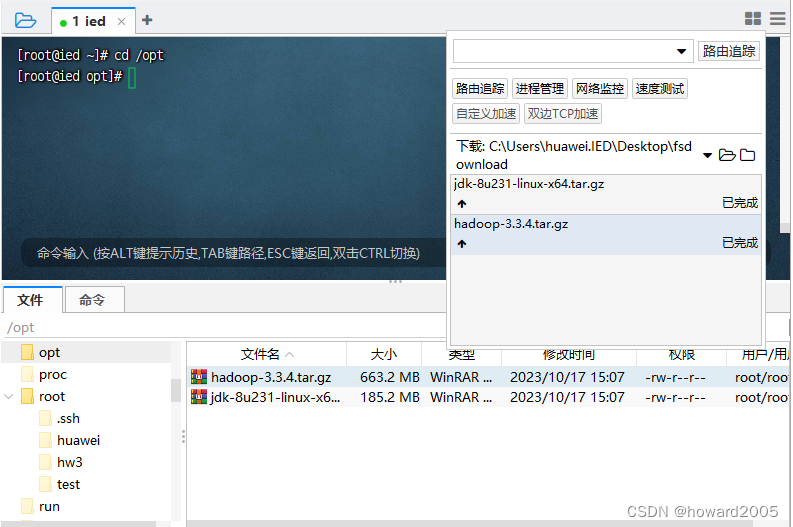
(二)上传安装包
-
上传jdk和hadoop安装包
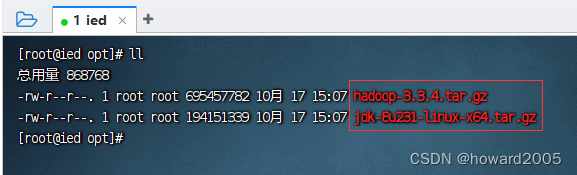
-
查看上传的安装包
(三)配置免密登录
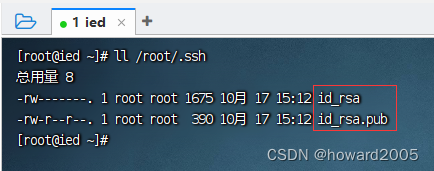
1、生成密钥对
- 执行命令:
ssh-keygen
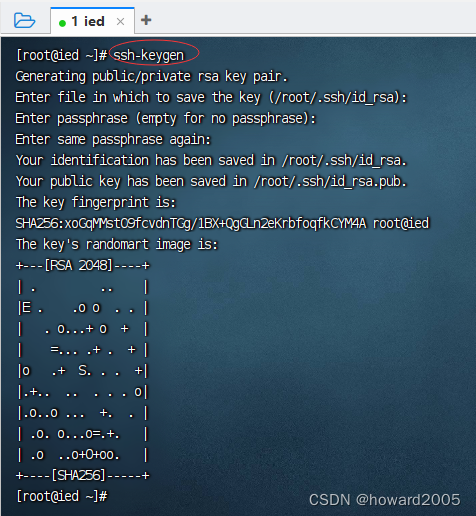
- 执行命令后,连续敲回车,生成节点的公钥和私钥,生成的密钥文件会自动放在/root/.ssh目录下。
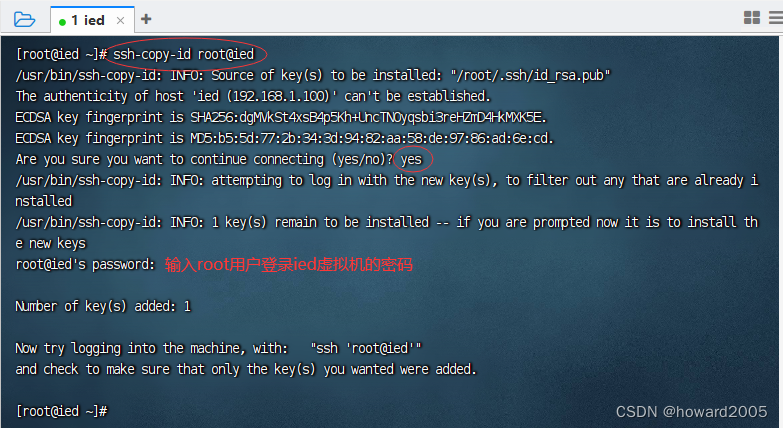
2、将生成的公钥发送到本机
- 执行命令:
ssh-copy-id root@ied
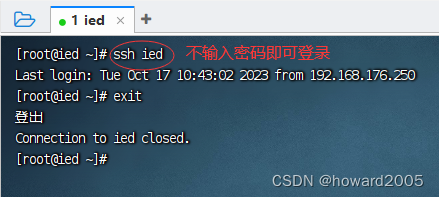
3、验证虚拟机是否能免密登录自己
- 执行命令:
ssh ied
(四)配置JDK
1、解压到指定目录
(1)解压到指定目录
- 执行命令:
tar -zxvf jdk-8u231-linux-x64.tar.gz -C /usr/local

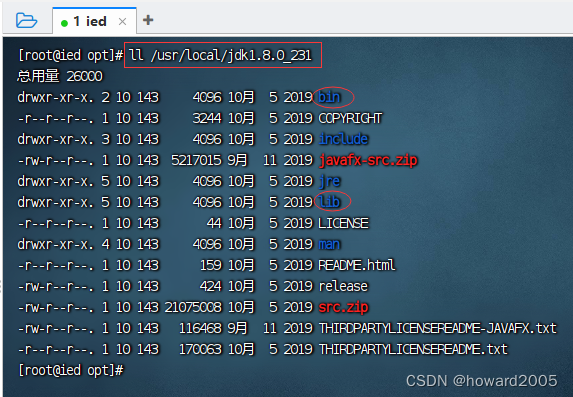
(2)查看java解压目录
- 执行命令:
ll /usr/local/jdk1.8.0_231
2、配置JDK环境变量
- 执行命令:
vim /etc/profile
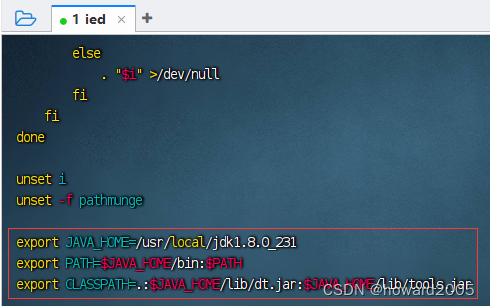
export JAVA_HOME=/usr/local/jdk1.8.0_231
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- 存盘退出
3、让环境变量配置生效
- 执行命令:
source /etc/profile
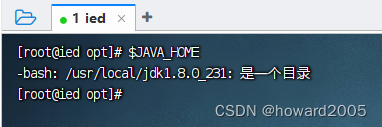
- 查看环境变量
JAVA_HOME
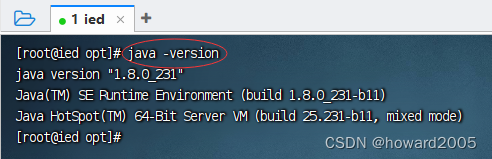
4、查看JDK版本
- 执行命令:
java -version
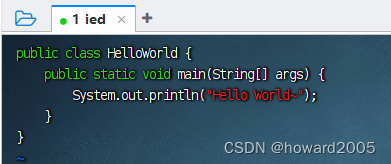
5、玩一玩Java程序
- 编写源程序,执行命令:
vim HelloWorld.java
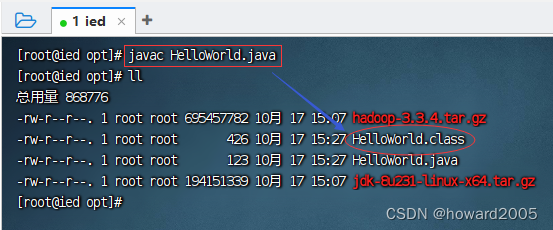
- 编译成字节码文件,执行命令:
javac HelloWorld.java
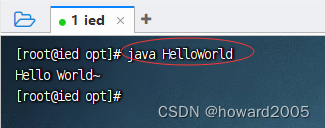
- 解释执行类,执行命令:
java HelloWorld
(五)配置Hadoop
1、解压hadoop安装包
(1)解压到指定目录
- 执行命令:
tar -zxvf hadoop-3.3.4.tar.gz -C /usr/local
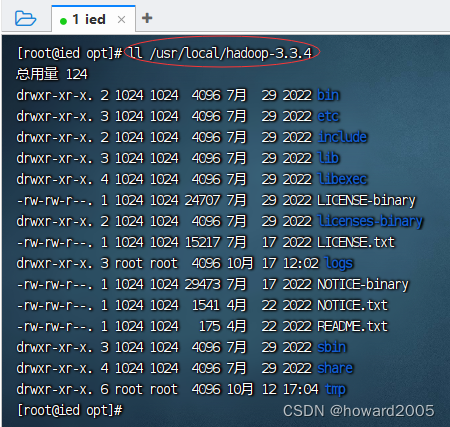
(2)查看hadoop解压目录
- 执行命令:
ll /usr/local/hadoop-3.3.4
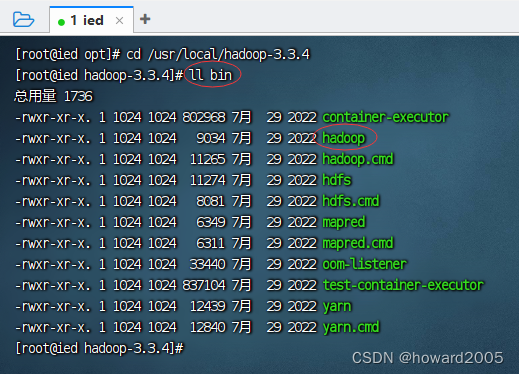
(3)常用目录和文件
- bin目录 - 存放命令脚本
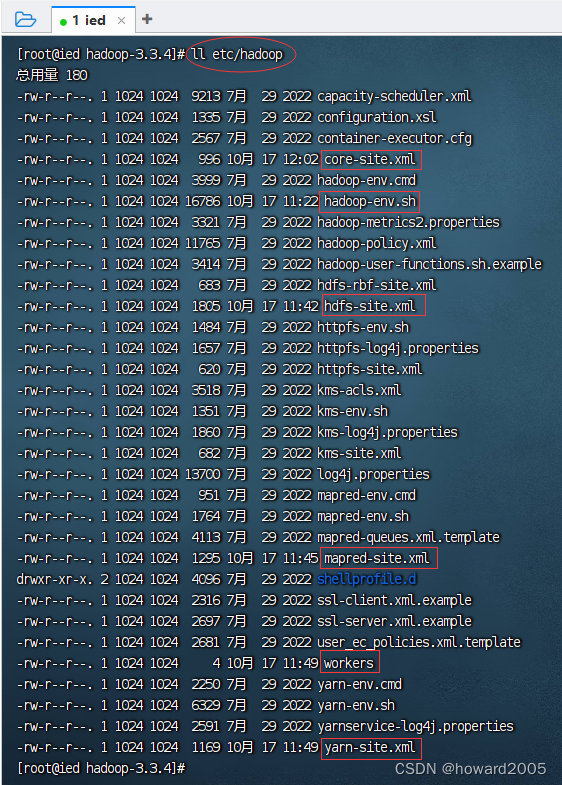
- etc/hadoop目录 - 存放hadoop的配置文件
- lib目录 - 存放hadoop运行的依赖jar包
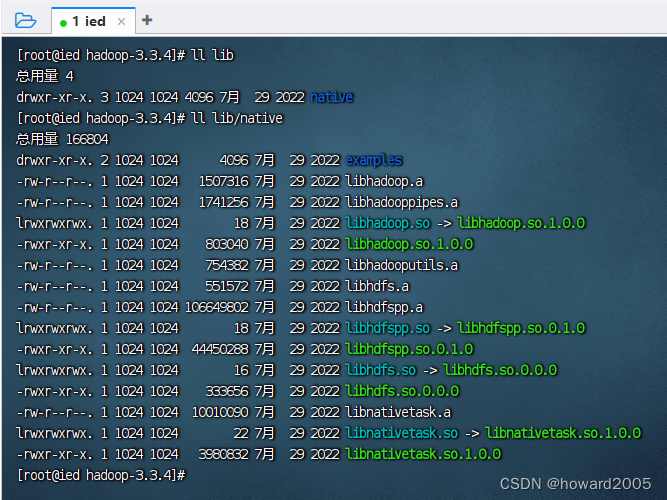
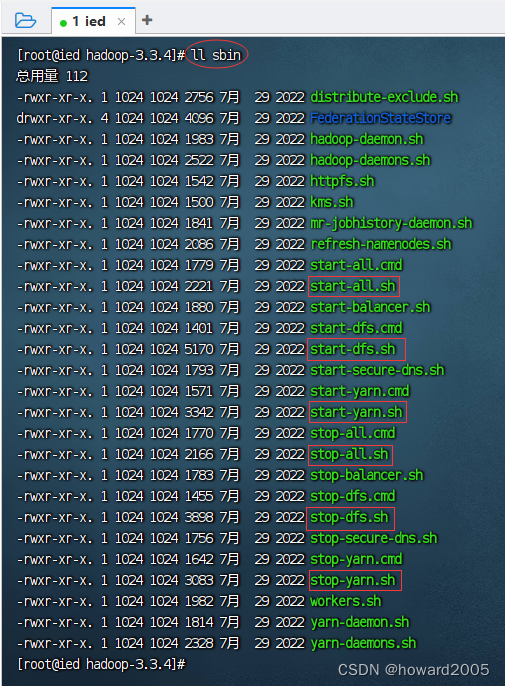
- sbin目录 - 存放启动和关闭Hadoop等命令
- libexec目录 - 存放的也是hadoop命令,但一般不常用
2、配置hadoop环境变量
- 执行命令:
vim /etc/profile
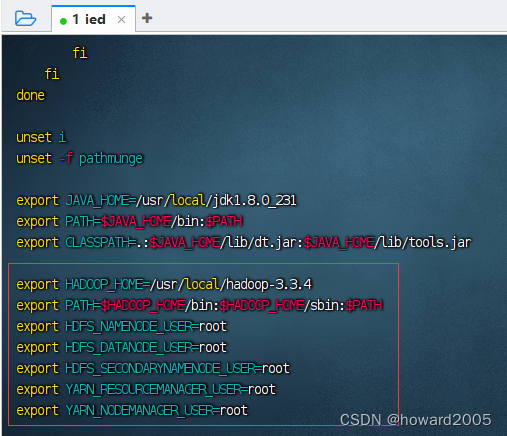
- 说明:hadoop 2.x用不着配置用户,只需要前两行即可
3、让环境变量配置生效
- 执行命令:
source /etc/profile
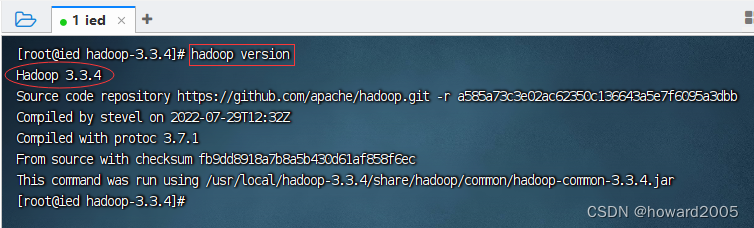
4、查看hadoop版本
- 执行命令:
hadoop version
5、编辑Hadoop环境配置文件 - hadoop-env.sh
- 执行命令:
cd etc/hadoop,进入hadoop配置目录
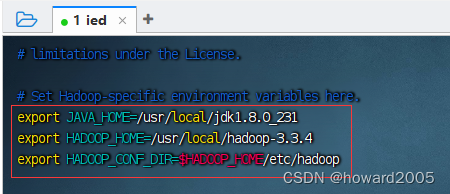
- 执行命令:
vim hadoop-env.sh,添加三条环境变量配置
- 存盘退出后,执行命令
source hadoop-env.sh,让配置生效
6、编辑Hadoop核心配置文件 - core-site.xml
- 执行命令:
vim core-site.xml
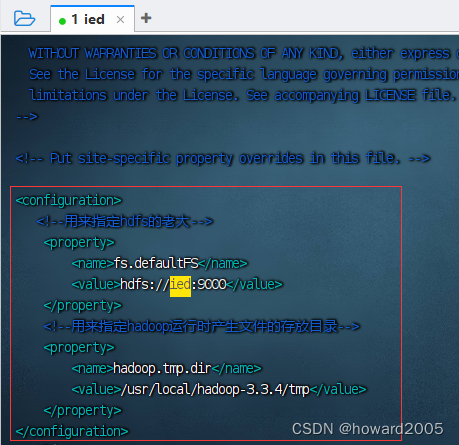
<configuration><!--用来指定hdfs的老大--><property><name>fs.defaultFS</name><value>hdfs://ied:9000</value></property><!--用来指定hadoop运行时产生文件的存放目录--><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop-3.3.4/tmp</value></property>
</configuration>
- 由于配置了IP地址主机名映射,因此配置HDFS老大节点可用
hdfs://ied:9000,否则必须用IP地址hdfs://192.168.1.100:9000
7、编辑HDFS配置文件 - hdfs-site.xml
- 执行命令:
vim hdfs-site.xml
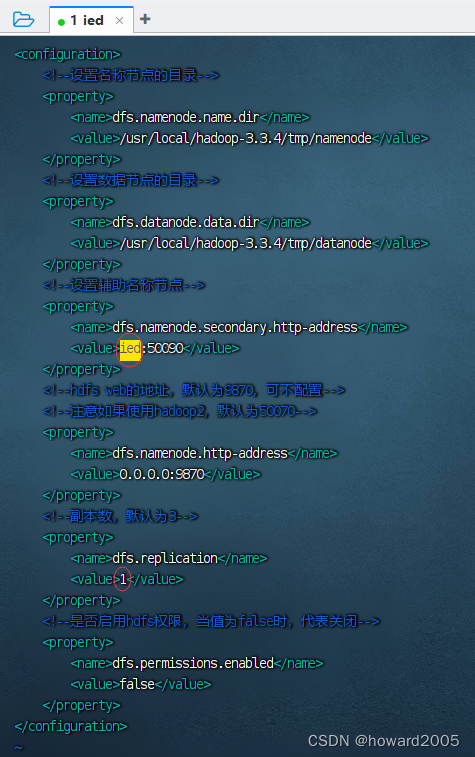
<configuration><!--设置名称节点的目录--><property><name>dfs.namenode.name.dir</name><value>/usr/local/hadoop-3.3.4/tmp/namenode</value></property><!--设置数据节点的目录--><property><name>dfs.datanode.data.dir</name><value>/usr/local/hadoop-3.3.4/tmp/datanode</value></property><!--设置辅助名称节点--><property><name>dfs.namenode.secondary.http-address</name><value>ied:50090</value></property><!--hdfs web的地址,默认为9870,可不配置--><!--注意如果使用hadoop2,默认为50070--><property><name>dfs.namenode.http-address</name><value>0.0.0.0:9870</value></property><!--副本数,默认为3--><property><name>dfs.replication</name><value>1</value></property><!--是否启用hdfs权限,当值为false时,代表关闭--><property><name>dfs.permissions.enabled</name><value>false</value></property>
</configuration>
8、编辑MapReduce配置文件 - mapred-site.xml
- 执行命令:
vim mapred-site.xml
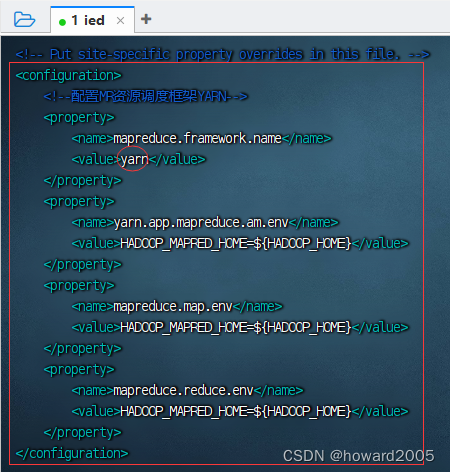
<configuration><!--配置MR资源调度框架YARN--><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property>
</configuration>
- 后三个属性如果不设置,在运行Hadoop自带示例的词频统计时,会报错:
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
9、编辑YARN配置文件 - yarn-site.xml
- 执行命令:
vim yarn-site.xml
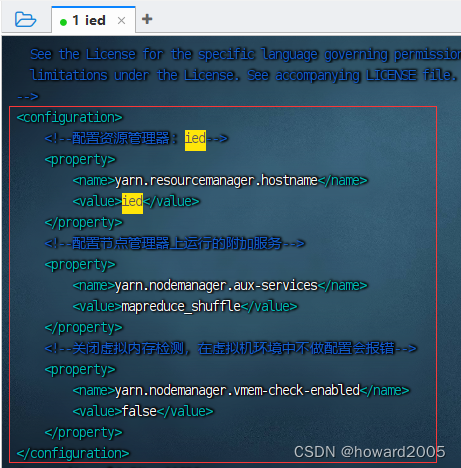
<configuration><!--配置资源管理器:ied--><property><name>yarn.resourcemanager.hostname</name><value>ied</value></property><!--配置节点管理器上运行的附加服务--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--关闭虚拟内存检测,在虚拟机环境中不做配置会报错--><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
</configuration>
10、编辑workers文件确定数据节点
- 说明:hadoop-2.x里配置
slaves文件,hadoop-3.x里配置workers文件 - 执行命令:
vim workers
- 只有1个数据节点,正好跟副本数配置的1一致
(六)格式化名称节点
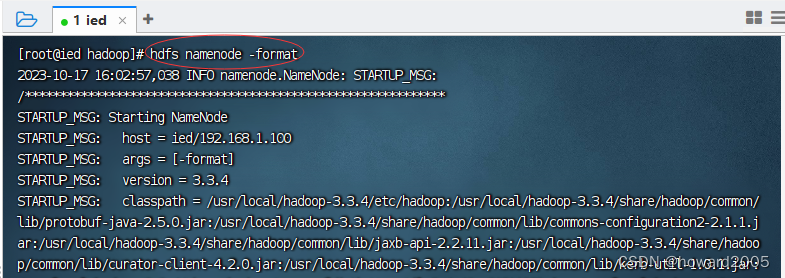
- 执行命令:
hdfs namenode -format
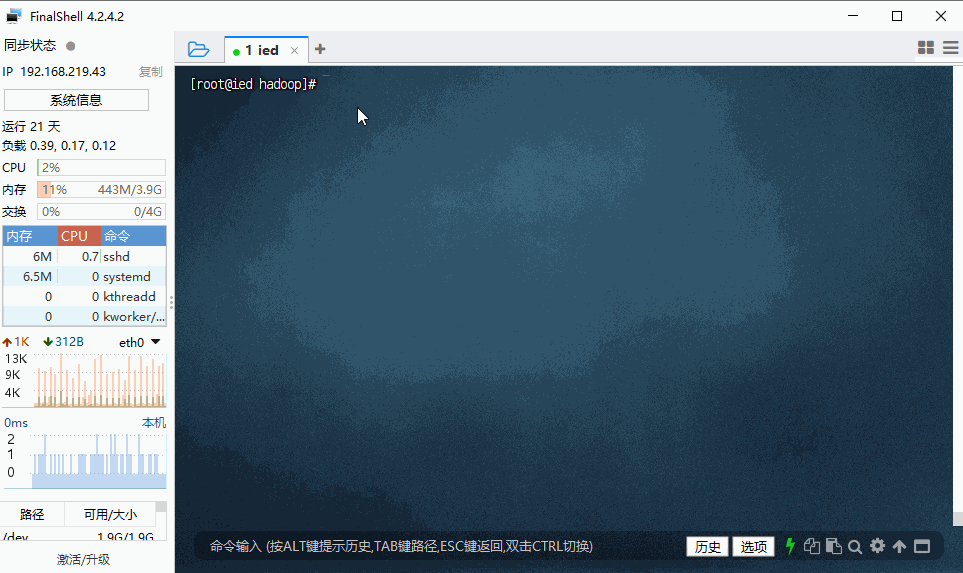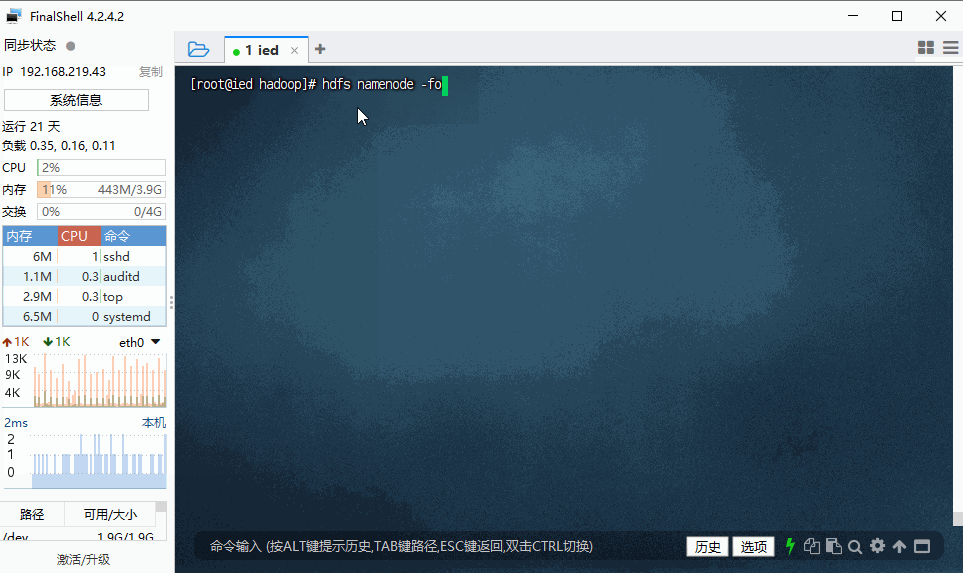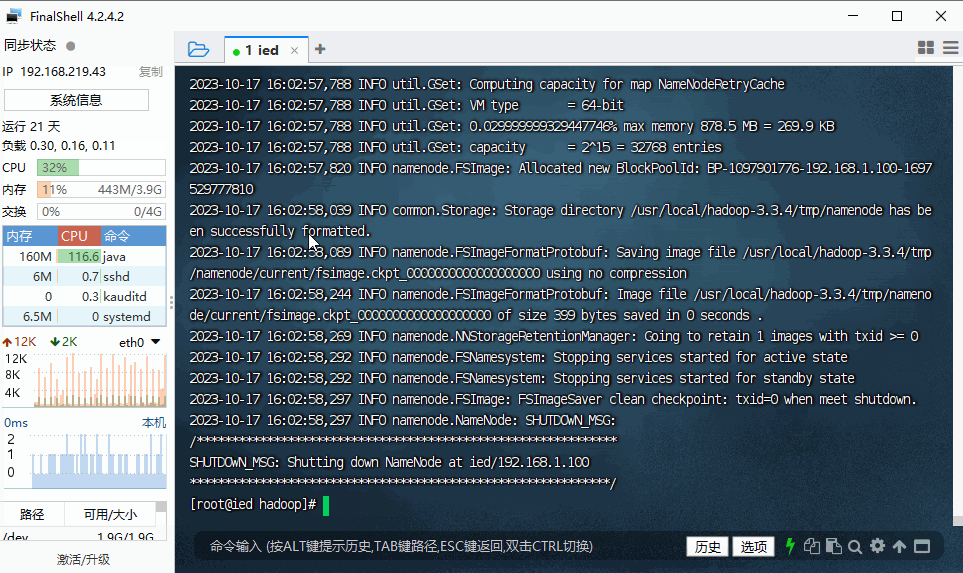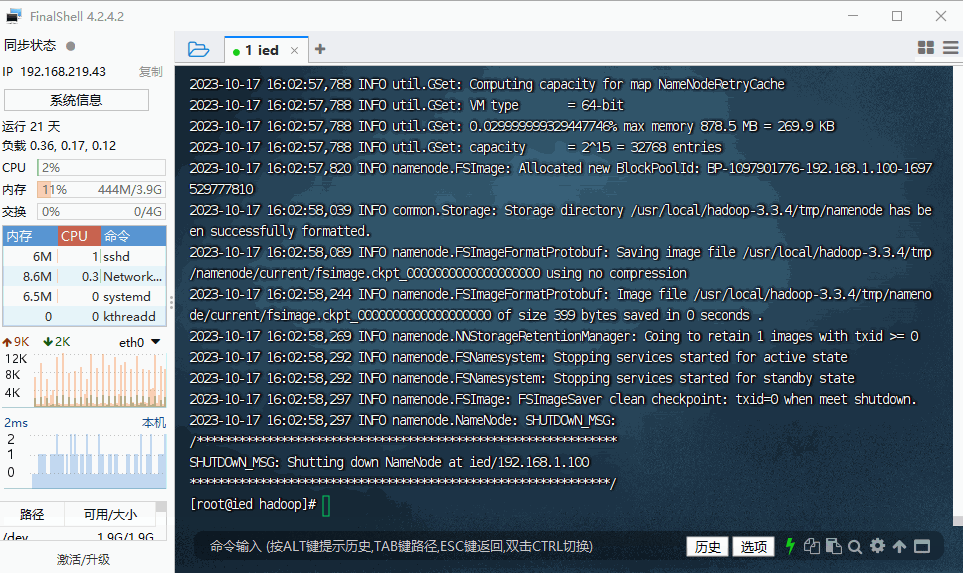
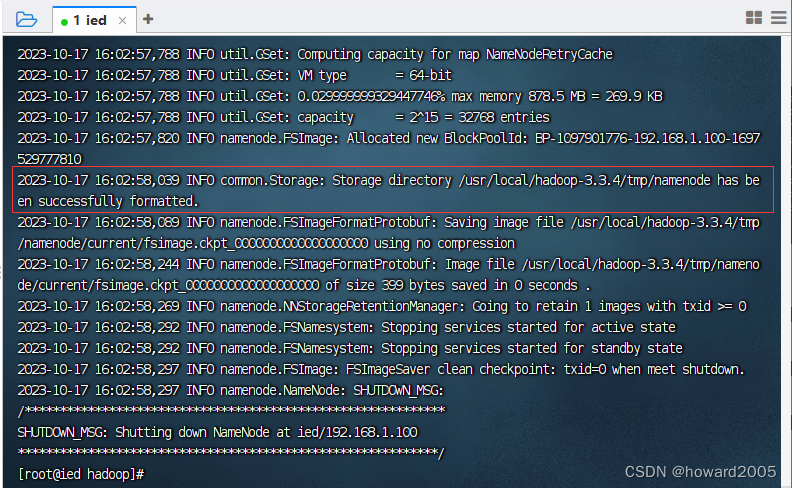
Storage directory /usr/local/hadoop-3.3.4/tmp/namenode has been successfully formatted.表明名称节点格式化成功。
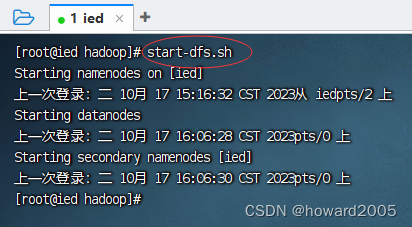
(七)启动Hadoop服务
1、启动hdfs服务
- 执行命令:
start-dfs.sh
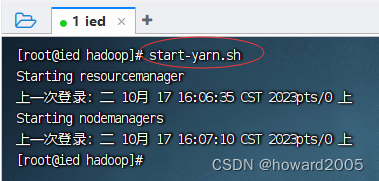
2、启动yarn服务
- 执行命令:
start-yarn.sh
3、查看Hadoop进程
-
执行命令:
jps
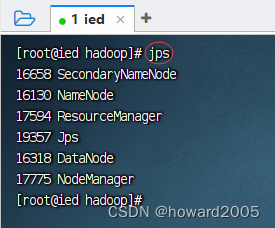
-
说明:
start-dfs.sh与start-yarn.sh可以用一条命令start-all.sh来替换
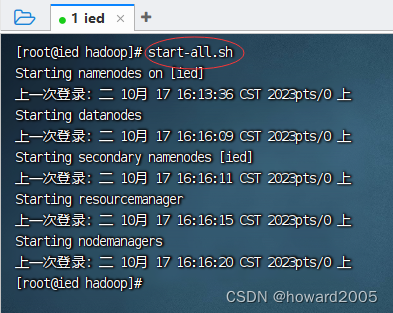
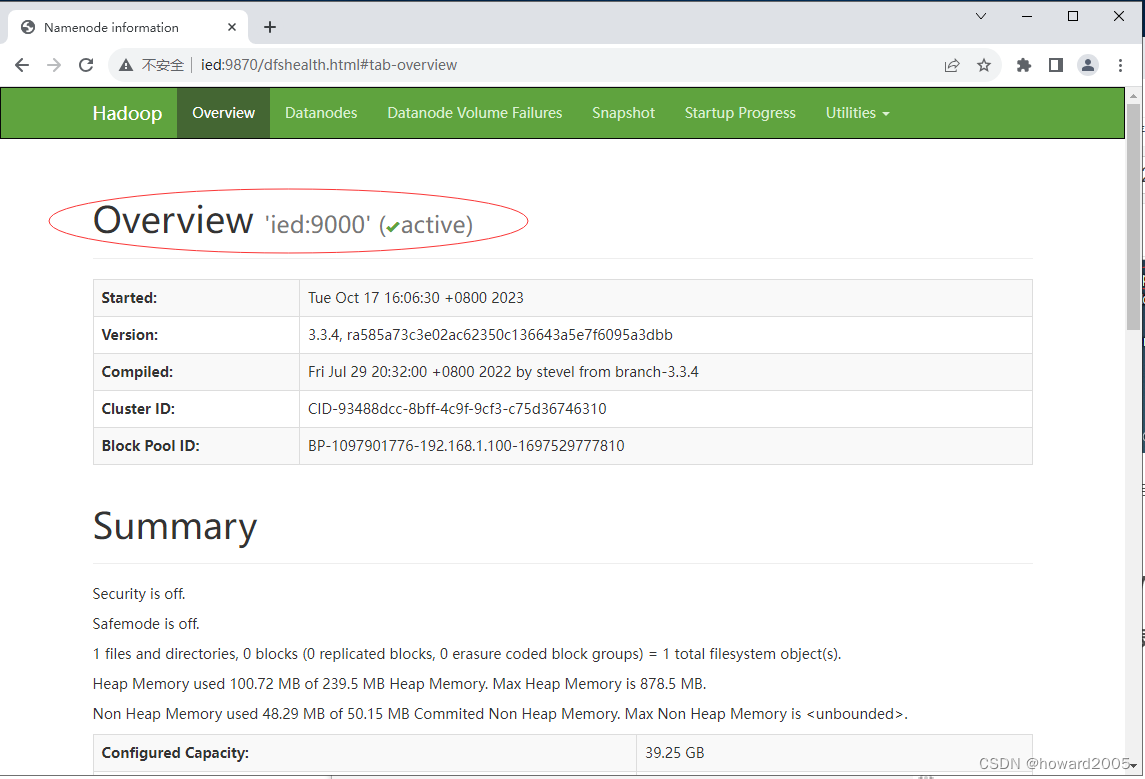
(八)查看Hadoop WebUI
- 在浏览器里访问
http://ied:9870
- 查看文件系统
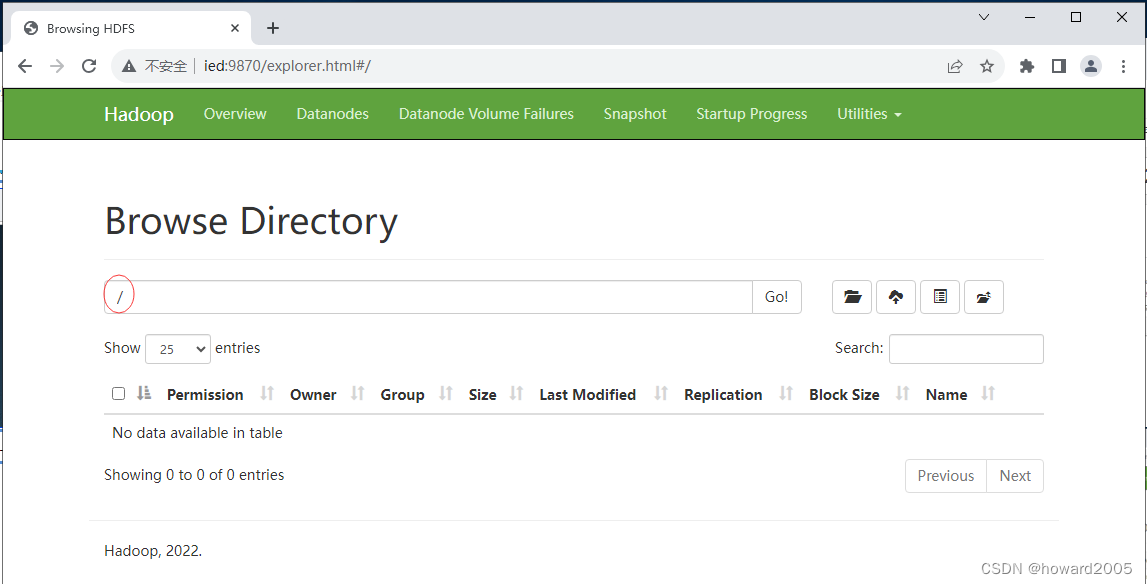
- 根目录下没有任何内容
(九)关闭Hadoop服务
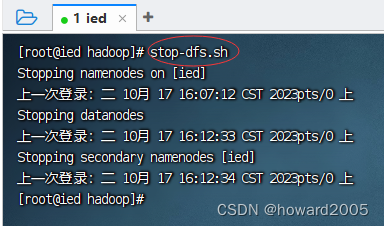
1、关闭hdfs服务
- 执行命令:
stop-dfs.sh
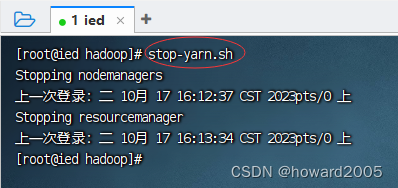
2、关闭yarn服务
-
执行命令:
stop-yarn.sh
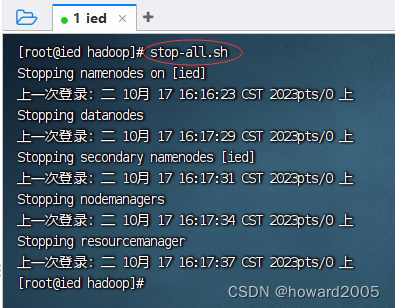
-
说明:
stop-dfs.sh与stop-yarn.sh可以用一条命令stop-all.sh来替换
相关文章:
搭建伪分布式Hadoop
文章目录 一、Hadoop部署模式(一)独立模式(二)伪分布式模式(三)完全分布式模式 二、搭建伪分布式Hadoop(一)登录虚拟机(二)上传安装包(三…...
【C++】特殊类的设计(只在堆、栈创建对象,单例对象)
🌏博客主页: 主页 🔖系列专栏: C ❤️感谢大家点赞👍收藏⭐评论✍️ 😍期待与大家一起进步! 文章目录 一、请设计一个类,只能在堆上创建对象二、 请设计一个类,只能…...

分类预测 | MATLAB实现基于GRU-AdaBoost门控循环单元结合AdaBoost多输入分类预测
分类预测 | MATLAB实现基于GRU-AdaBoost门控循环单元结合AdaBoost多输入分类预测 目录 分类预测 | MATLAB实现基于GRU-AdaBoost门控循环单元结合AdaBoost多输入分类预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.MATLAB实现基于GRU-AdaBoost门控循环单元结…...

【Spring Boot项目】根据用户的角色控制数据库访问权限
文章目录 简介方法一添加数据库依赖配置数据库连接创建用户角色表创建Spring Data JPA实体和仓库实现自定义的网关过滤器配置网关过滤器几个简单的测试API 方法二创建数据库访问接口实现数据库访问接口创建用户角色判断逻辑创建网关过滤器配置网关过滤器 总结 简介 在一些特定…...

EthernetIP 转MODBUS RTU协议网关连接FANUC机器人作为EthernetIP通信从站
远创智控YC-EIPM-RTU网关产品是一款高效的数据采集工具,它可以通过各种数据接口与工业领域的仪表、PLC、计量设备等产品连接,实时采集这些设备中的运行数据、状态数据等信息。采集到的数据经过整合和运算等操作后,可以被传输到其他设备或者云…...
如何注册微信小程序
如何注册微信小程序 前言 因为最近沉迷和朋友们一起下班去打麻将,他们推荐了一个计分的小程序,就不需要每局都转账或者用扑克牌记录了,但是这个小程序不仅打开有广告,各个页面都植入了广告,用起来十分不适。 于是我…...

移动App安全检测的必要性,app安全测试报告的编写注意事项
随着移动互联网的迅猛发展,移动App已经成为人们日常生活中不可或缺的一部分。然而,虽然App给我们带来了便利和乐趣,但也伴随着一些潜在的安全风险。黑客、病毒、恶意软件等威胁着用户的隐私和财产安全,因此进行安全检测就显得尤为…...

DVWA-JavaScript Attacks
JavaScript Attacks JavaScript Attack即JS攻击,攻击者可以利用JavaScript实施攻击。 Low 等级 核心源码,用的是dom语法这是在前端使用的和后端无关,然后获取属性为phrase的值然后来个rot13和MD5双重加密在复制给token属性。 <script&…...

算法通关村第二关|白银|链表反转拓展【持续更新】
1.指定区间反转 1.1 头插法:将区间内遍历到的结点插入到起始处之前。 public ListNode reverseBetween(ListNode head, int left, int right) {ListNode dummyNode new ListNode(-1);dummyNode.next head;ListNode pre dummyNode;// 将pre移动到区间的前一位&a…...

开发者职场“生存状态”大调研报告分析 - 第四版
听人劝、吃饱饭,奉劝各位小伙伴,不要订阅该文所属专栏。 作者:不渴望力量的哈士奇(哈哥),十余年工作经验, 跨域学习者,从事过全栈研发、产品经理等工作,现任研发部门 CTO 。荣誉:2022年度博客之星Top4、博客专家认证、全栈领域优质创作者、新星计划导师,“星荐官共赢计…...
代码与细节(一)
在用到 Java17的新特性 Unmodifiable Lists 时不知道你是否和我有同样的惊讶 为什么弄了这么多重载方法? 先说结论:为了性能。 其实一细想,都能想明白:varargs(可变参数) 的背后是数组的内存分配和初始化,相比正常的…...
AI绘画使用Stable Diffusion(SDXL)绘制中国古代神兽
一、引言 说到神奇异兽,脑海中首先就会跳出我国古代神话传说中的各种神兽。比如青龙、白虎、朱雀、玄武,再比如麒麟、凤凰、毕方、饕餮等等,这些都是大家耳熟能详的的神兽。 这些神兽不仅体现了人们丰富的创造力和想象力,更是我…...
)
老卫带你学---leetcode刷题(148. 排序链表)
148. 排序链表 问题: 给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。 示例 1:输入:head [4,2,1,3] 输出:[1,2,3,4]示例 2:输入:head [-1,5,3,4,0] 输出:[-1…...
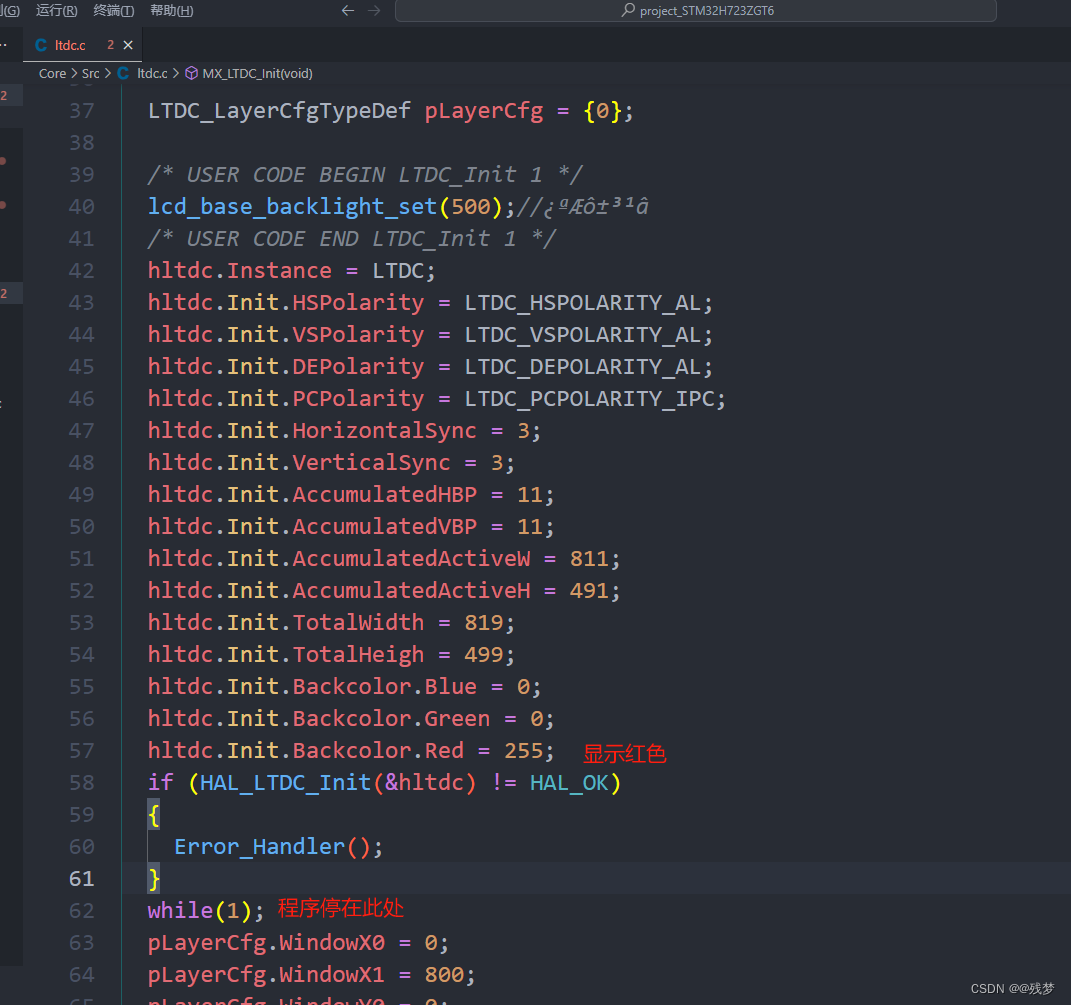
21.1 stm32使用LTDC驱动LCD--配置说明
本文讲解如何配置LTDC驱动LCD的参数配置,以及CubeMx参数配置说明 本文使用的是淘宝买的一块带电容触摸的液晶显示屏:5寸TFT液晶显示屏高清800*480免驱40P通用RGBIPS全视角彩屏GT911 说实话,价格还是相对挺便宜的,值得入手…...

zabbix监控nginx的状态页面
zabbix监控nginx的状态页面 文章目录 zabbix监控nginx的状态页面1.环境说明2.所涉及到的知识点3.在nginx主机上安装zabbix_agent4.开启nginx状态显示页面5.进入zabbix的web页面配置主机,监控项,触发器5.1.添加主机5.2.创建监控项5.3.创建触发器 1.环境说…...
C语言初学者工具选择:vscode + MSYS2 + cmake 搭建 C环境
文章目录 前言1. MSYS2 安装1. 下载安装包2. 安装3. pacman 换清华大学源4. 安装 mingw-w64 toolchain 和 cmake ninja5. 将 toolchain 加入系统环境变量 2. 设置 vscode1. 必要的插件2. 一个简单的 vscode cmake 项目 最后C数据结构与算法CMake 前言 网上关于使用 vscode 配…...

【四:httpclient的使用】
目录 1、Demo案例2、请求一个带cookies的get请求3、请求一个带cookies的post请求案例一,案例二的properties的配置 1、Demo案例 public class MyHttpClient {Testpublic void test1() throws IOException {//用来存放我们的结果String result;HttpGet get new Htt…...
、count(1)、count(主键)、count(字段)哪个性能最高?)
在innodb引擎中,count(*)、count(1)、count(主键)、count(字段)哪个性能最高?
在InnoDB引擎中,这四种计数值的效率高低取决于具体的数据库和数据表结构,无法一概而论哪个性能最高。不过,一般情况下可以按照以下顺序进行选择: count():统计所有行的数量。由于InnoDB引擎的行锁是锁住整行ÿ…...
【java】B卷)
华为OD 跳格子2(200分)【java】B卷
华为OD统一考试A卷B卷 新题库说明 你收到的链接上面会标注A卷还是B卷。目前大部分收到的都是B卷。 B卷对应20022部分考题以及新出的题目,A卷对应的是新出的题目。 我将持续更新最新题目 获取更多免费题目可前往夸克网盘下载,请点击此链接进入:…...

javascript/python 笔记: folium feature group自动切换
1 python部分 python部分只能是静态的结果 1.1 导入库 import folium import math 1.2 数据 cell_lst表示基站位置,location_lst表示 用户实际位置(均为伪数据) cell_lst[[1.341505, 103.682498],[1.342751, 103.679604],[1.341505, 10…...

AI CRM 2.0时代:SaaS厂商的生死局
今天的SaaS厂商,要么彻底重构底层架构,要么被时代抛弃。原创:首席数智官 封面:AI“未来每一家SaaS公司都会成为AaaS(Agentic as a Service)公司。”这是英伟达创始人、CEO黄仁勋在GTC 2026演讲中给出的判断…...

藏在化橘红里的数字农业隐喻:拼多多将“地方风物”做成了新爆款
图片 2026年两会期间,化橘红因为一个点赞意外“出圈”。 不少人将化橘红的“走红”归结为偶然的流量红利,只要深入化橘红的产业肌理,就会发现并非是一场单纯的“流量造神”,而是电商供应链、新农人回流、产业化升级交织下的必然。…...

3大核心能力+2套配置方案:obsidian-i18n终极汉化指南
3大核心能力2套配置方案:obsidian-i18n终极汉化指南 【免费下载链接】obsidian-i18n 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-i18n 面对全英文的应用界面,你是否曾因语言障碍而错失高效工具?当专业术语晦涩难懂&#…...

Mod Loader:重新定义GTA系列模组管理的技术架构与实践指南
Mod Loader:重新定义GTA系列模组管理的技术架构与实践指南 【免费下载链接】modloader Mod Loader for GTA III, Vice City and San Andreas 项目地址: https://gitcode.com/gh_mirrors/mo/modloader 一、核心痛点解析:传统模组管理的三大技术瓶颈…...

如何快速掌握Outfit字体:5个简单技巧打造专业级设计
如何快速掌握Outfit字体:5个简单技巧打造专业级设计 【免费下载链接】Outfit-Fonts The most on-brand typeface 项目地址: https://gitcode.com/gh_mirrors/ou/Outfit-Fonts Outfit字体是一款专业的开源无衬线字体,提供从Thin到Black的9种完整字…...

Citra模拟器全方位指南:从安装到优化的3DS游戏体验提升方案
Citra模拟器全方位指南:从安装到优化的3DS游戏体验提升方案 【免费下载链接】citra A Nintendo 3DS Emulator 项目地址: https://gitcode.com/gh_mirrors/cit/citra Citra作为一款开源高性能的Nintendo 3DS模拟器,为Windows、Linux和macOS用户提供…...

Nature重磅:量子生物学重大突破
来源:一直奇怪2026 年 3 月 18 日,斯坦福大学的研究人员在国际顶尖学术期刊 Nature 上发表了题为:Magnetic resonance control of spin-correlated radical pair dynamics in vivo 的研究论文。该研究首次在活体多细胞动物中利用磁共振技术精…...

从RGB合并到多传感器融合:深入拆解AXI4-Stream Combiner IP在Zynq平台上的两种典型应用
从RGB合并到多传感器融合:深入拆解AXI4-Stream Combiner IP在Zynq平台上的两种典型应用 在FPGA开发中,数据流的高效处理一直是工程师面临的核心挑战之一。当系统需要同时处理多个并行数据源时,如何将这些数据流有序、高效地合并为单一数据流…...

5个突破点:解锁时空数据金矿的ST-DBSCAN实战指南
5个突破点:解锁时空数据金矿的ST-DBSCAN实战指南 【免费下载链接】st_dbscan ST-DBSCAN: Simple and effective tool for spatial-temporal clustering 项目地址: https://gitcode.com/gh_mirrors/st/st_dbscan 问题发现:被忽视的时空关联密码 为…...

MiniCPM-V-2_6政务场景应用:身份证/营业执照图像识别+结构化提取
MiniCPM-V-2_6政务场景应用:身份证/营业执照图像识别结构化提取 1. 引言:让政务文档处理更智能高效 在日常政务工作中,工作人员经常需要处理大量的身份证和营业执照图像。传统的人工录入方式不仅效率低下,还容易出错。一张身份证…...