《动手学深度学习 Pytorch版》 9.2 长短期记忆网络(LSTM)
解决隐变量模型长期信息保存和短期输入缺失问题的最早方法之一是长短期存储器(long short-term memory,LSTM)。它与门控循环单元有许多一样的属性。长短期记忆网络的设计比门控循环单元稍微复杂一些,却比门控循环单元早诞生了近 20 年。
9.2.1 门控记忆元
为了记录附加的信息,长短期记忆网络引入了与隐状态具有相同的形状的记忆元(memory cell),或简称为单元(cell)。
为了控制记忆元又需要引入许多门:
-
输出门(output gate):用来从单元中输出条目,决定是不是使用隐藏状态。
-
输入门(input gate):用来决定何时将数据读入单元,决定是不是忽略掉输入数据。
-
遗忘门(forget gate):用来重置单元的内容,将值朝 0 减少。
这种设计的动机与门控循环单元相同, 能够通过专用机制决定什么时候记忆或忽略隐状态中的输入。
9.2.1.1 输入门、遗忘门和输出门
特征:
-
以当前时间步的输入和前一个时间步的隐状态为数据送入长短期记忆网络的门
-
由三个具有 sigmoid 激活函数的全连接层计算输入门、遗忘门和输出门的值
-
值都在的 ( 0 , 1 ) (0,1) (0,1) 范围内

它们的计算方法如下:
I t = σ ( X t W x i + H t − 1 W h i + b i ) F t = σ ( X t W x f + H t − 1 W h f + b f ) O t = σ ( X t W x o + H t − 1 W h o + b o ) \begin{align} \boldsymbol{I}_t&=\sigma(\boldsymbol{X}_t\boldsymbol{W}_{xi}+\boldsymbol{H}_{t-1}\boldsymbol{W}_{hi}+b_i)\\ \boldsymbol{F}_t&=\sigma(\boldsymbol{X}_t\boldsymbol{W}_{xf}+\boldsymbol{H}_{t-1}\boldsymbol{W}_{hf}+b_f)\\ \boldsymbol{O}_t&=\sigma(\boldsymbol{X}_t\boldsymbol{W}_{xo}+\boldsymbol{H}_{t-1}\boldsymbol{W}_{ho}+b_o) \end{align} ItFtOt=σ(XtWxi+Ht−1Whi+bi)=σ(XtWxf+Ht−1Whf+bf)=σ(XtWxo+Ht−1Who+bo)
参数列表:
-
X t ∈ R n × d \boldsymbol{X}_t\in\R^{n\times d} Xt∈Rn×d 表示小批量输入
-
n n n 表示批量大小
-
d d d 表示输入个数
-
-
H t − 1 ∈ R n × h \boldsymbol{H}_{t-1}\in\R^{n\times h} Ht−1∈Rn×h 表示上一个时间步的隐状态
- h h h 表示隐藏单元个数
-
I t ∈ R n × h \boldsymbol{I}_t\in\R^{n\times h} It∈Rn×h 表示输入门
-
F t ∈ R n × h \boldsymbol{F}_t\in\R^{n\times h} Ft∈Rn×h 表示遗忘门
-
O t ∈ R n × h \boldsymbol{O}_t\in\R^{n\times h} Ot∈Rn×h 表示输出门
-
W x i , W x f , W x o ∈ R d × h \boldsymbol{W}_{xi},\boldsymbol{W}_{xf},\boldsymbol{W}_{xo}\in\R^{d\times h} Wxi,Wxf,Wxo∈Rd×h 和 W h i , W h f , W h o ∈ R h × h \boldsymbol{W}_{hi},\boldsymbol{W}_{hf},\boldsymbol{W}_{ho}\in\R^{h\times h} Whi,Whf,Who∈Rh×h 表示权重参数
-
b i , b f , b o ∈ R 1 × h b_i,b_f,b_o\in\R^{1\times h} bi,bf,bo∈R1×h 表示偏重参数
9.2.1.2 候选记忆单元
候选记忆元(candidate memory cell) C t ~ ∈ R n × h \tilde{\boldsymbol{C}_t}\in\R^{n\times h} Ct~∈Rn×h 的计算与上面描述的三个门的计算类似,但是使用 tanh 函数作为激活函数,函数的值范围为 ( 0 , 1 ) (0,1) (0,1)。

它的计算方式如下:
C t ~ = t a n h ( X t W x c + H t − 1 W h c + b c ) \tilde{\boldsymbol{C}_t}=tanh(\boldsymbol{X}_t\boldsymbol{W}_{xc}+\boldsymbol{H}_{t-1}\boldsymbol{W}_{hc}+\boldsymbol{b}_c) Ct~=tanh(XtWxc+Ht−1Whc+bc)
参数列表:
-
W x c ∈ R d × h \boldsymbol{W}_{xc}\in\R^{d\times h} Wxc∈Rd×h 和 W h c ∈ R h × h \boldsymbol{W}_{hc}\in\R^{h\times h} Whc∈Rh×h 表示权重参数
-
b c ∈ R 1 × h \boldsymbol{b}_c\in\R^{1\times h} bc∈R1×h 表示偏置参数
9.2.1.3 记忆元
-
输入门 I t I_t It 控制采用多少来自 C t ~ \tilde{\boldsymbol{C}_t} Ct~ 的新数据
-
遗忘门 F t F_t Ft 控制保留多少过去的记忆元 C t − 1 ∈ R n × h \boldsymbol{C}_{t-1}\in\R^{n\times h} Ct−1∈Rn×h 的内容。
计算方法:
C t = F t ⊙ C t − 1 + I t ⊙ C t ~ \boldsymbol{C}_t=\boldsymbol{F}_t\odot\boldsymbol{C}_{t-1}+\boldsymbol{I}_t\odot\tilde{\boldsymbol{C}_t} Ct=Ft⊙Ct−1+It⊙Ct~
如果遗忘门始终为 1 且输入门始终为 0,则过去的记忆元 C t − 1 \boldsymbol{C}_{t-1} Ct−1 将随时间被保存并传递到当前时间步。
引入这种设计是为了:
-
缓解梯度消失问题
-
更好地捕获序列中的长距离依赖关系。

9.2.1.4 隐状态
计算隐状态 H t ∈ R n × h \boldsymbol{H}_t\in\R^{n\times h} Ht∈Rn×h 是输出门发挥作用的地方。实际上它仅仅是记忆元的 tanh 的门控版本。 这就确保了 H t \boldsymbol{H}_t Ht 的值始终在区间 ( − 1 , 1 ) (-1,1) (−1,1)内:
H t = O t ⊙ t a n h ( C t ) \boldsymbol{H}_t=\boldsymbol{O}_t\odot tanh(\boldsymbol{C}_t) Ht=Ot⊙tanh(Ct)
只要输出门接近 1,我们就能够有效地将所有记忆信息传递给预测部分,而对于输出门接近 0,我们只保留记忆元内的所有信息,而不需要更新隐状态。

9.2.2 从零开始实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
9.2.2.1 初始化模型参数
def get_lstm_params(vocab_size, num_hiddens, device):num_inputs = num_outputs = vocab_sizedef normal(shape):return torch.randn(size=shape, device=device)*0.01def three():return (normal((num_inputs, num_hiddens)),normal((num_hiddens, num_hiddens)),torch.zeros(num_hiddens, device=device))W_xi, W_hi, b_i = three() # 输入门参数W_xf, W_hf, b_f = three() # 遗忘门参数W_xo, W_ho, b_o = three() # 输出门参数W_xc, W_hc, b_c = three() # 候选记忆元参数# 输出层参数W_hq = normal((num_hiddens, num_outputs))b_q = torch.zeros(num_outputs, device=device)# 附加梯度params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,b_c, W_hq, b_q]for param in params:param.requires_grad_(True)return params
9.2.2.2 定义模型
def init_lstm_state(batch_size, num_hiddens, device):return (torch.zeros((batch_size, num_hiddens), device=device), # 隐状态需要返回一个额外的单元的值为0形状为(批量大小,隐藏单元数)记忆元torch.zeros((batch_size, num_hiddens), device=device))
def lstm(inputs, state, params):[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,W_hq, b_q] = params(H, C) = stateoutputs = []for X in inputs:I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i) # 输入门运算F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f) # 遗忘门运算O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o) # 输出门运算C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c) # 候选记忆元运算C = F * C + I * C_tilda # 记忆元计算H = O * torch.tanh(C) # 隐状态计算Y = (H @ W_hq) + b_q # 输出计算outputs.append(Y)return torch.cat(outputs, dim=0), (H, C)
9.2.2.3 训练与预测
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_lstm_params,init_lstm_state, lstm)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
perplexity 1.1, 28093.3 tokens/sec on cuda:0
time traveller well pnatter ats sho in the geet on the battle of
traveller oft chat in all dore think of mowh of stace assio

9.2.3 简洁实现
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
perplexity 1.0, 171500.8 tokens/sec on cuda:0
time travelleryou can show black is white by argument said filby
travelleryou can show black is white by argument said filby

练习
(1)调整和分析超参数对运行时间、困惑度和输出顺序的影响。
跟上一节类似,五个参数轮着换。
def test(Hyperparameters): # [batch_size, num_steps, num_hiddens, lr, num_epochs]train_iter_now, vocab_now = d2l.load_data_time_machine(Hyperparameters[0], Hyperparameters[1])lstm_layer_now = nn.LSTM(len(vocab_now), Hyperparameters[2])model_now = d2l.RNNModel(lstm_layer_now, len(vocab_now))model_now = model_now.to(d2l.try_gpu())d2l.train_ch8(model_now, train_iter_now, vocab_now, Hyperparameters[3], Hyperparameters[4], d2l.try_gpu())Hyperparameters_lists = [[64, 35, 256, 1, 500], # 加批量大小[32, 64, 256, 1, 500], # 加时间步[32, 35, 512, 1, 500], # 加隐藏单元数[32, 35, 256, 0.5, 500], # 减半学习率[32, 35, 256, 1, 200] # 减轮数
]for Hyperparameters in Hyperparameters_lists:test(Hyperparameters)
perplexity 4.3, 164389.7 tokens/sec on cuda:0
time traveller the the that the grome that he a thee tho ghith o
traveller the that that that this that the go that have the





(2)如何更改模型以生成适当的单词,而不是字符序列?
浅浅的改了一下预测函数和训练函数。
def predict_ch8_word(prefix, num_preds, net, vocab, device): # 词预测"""在prefix后面生成新字符"""state = net.begin_state(batch_size=1, device=device)outputs = [vocab[prefix[0]]] # 调用 vocab 类的 __getitem__ 方法get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1)) # 把预测结果(结果的最后一个)作为下一个的输入for y in prefix[1:]: # 预热期 把前缀先载进模型_, state = net(get_input(), state)outputs.append(vocab[y])for _ in range(num_preds): # 预测 num_preds 步y, state = net(get_input(), state)outputs.append(int(y.argmax(dim=1).reshape(1))) # 优雅return ''.join([vocab.idx_to_token[i] + ' ' for i in outputs]) # 加个空格分隔各词def train_ch8_word(net, train_iter, vocab, lr, num_epochs, device, # 词训练use_random_iter=False):loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',legend=['train'], xlim=[10, num_epochs])# 初始化if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(), lr)else:updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)predict = lambda prefix: predict_ch8_word(prefix, 50, net, vocab, device)# 训练和预测for epoch in range(num_epochs):ppl, speed = d2l.train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter)if (epoch + 1) % 10 == 0:print(predict(['time', 'traveller'])) # 使用 word 而非 charanimator.add(epoch + 1, [ppl])print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')print(predict(['time', 'traveller']))print(predict(['traveller']))class SeqDataLoader_word: # 词加载器def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):if use_random_iter:self.data_iter_fn = d2l.seq_data_iter_randomelse:self.data_iter_fn = d2l.seq_data_iter_sequentiallines = d2l.read_time_machine()tokens = d2l.tokenize(lines, token='word') # 使用 word 而非 charself.vocab_word = d2l.Vocab(tokens) # 构建 word 词表self.corpus_word = [self.vocab_word[token] for line in tokens for token in line]if max_tokens > 0:self.corpus_word = self.corpus_word[:max_tokens]self.batch_size, self.num_steps = batch_size, num_stepsdef __iter__(self):return self.data_iter_fn(self.corpus_word, self.batch_size, self.num_steps)train_iter_word = SeqDataLoader_word(64, 35, False, 10000)
vocab_word = train_iter_word.vocab_wordlstm_layer_word = nn.LSTM(len(vocab_word), 256)
model_word = d2l.RNNModel(lstm_layer_word, len(vocab_word))
model_word = model_word.to(d2l.try_gpu())
train_ch8_word(model_word, train_iter_word, vocab_word, 1.5, 1000, d2l.try_gpu())
困惑度 1.7, 40165.1 词元/秒 cuda:0
time traveller s his hand at last to me that with his own to the psychologist with his grew which i had said filby time travelling yes said the time traveller with his mouth full nodding his head i d give a shilling a line for a verbatim note said the editor
traveller and i was so the sun in my marble smote to the world for for the long pressed he was the little of the sun and presently for a certain heap of cushions and robes i saw on the sun in my confident anticipations it seemed a large figure of

(3)在给定隐藏层维度的情况下,比较门控循环单元、长短期记忆网络和常规循环神经网络的计算成本。要特别注意训练和推断成本。
咋好像每个都差不多。
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)num_inputs = len(vocab)
device = d2l.try_gpu()
num_hiddens = 256
num_epochs, lr = 500, 1
rnn_layer = nn.RNN(len(vocab), num_hiddens)
model_RNN = d2l.RNNModel(rnn_layer, vocab_size=len(vocab))
model_RNN = model_RNN.to(device)
d2l.train_ch8(model_RNN, train_iter, vocab, lr, num_epochs, device) # 34.3s
perplexity 1.3, 218374.6 tokens/sec on cuda:0
time travelleryou can show black is whith basimat very hu and le
travellerit so drawly us our dimsas absulladt nt havi gerea

gru_layer = nn.GRU(num_inputs, num_hiddens)
model_GRU = d2l.RNNModel(gru_layer, len(vocab))
model_GRU = model_GRU.to(device)
d2l.train_ch8(model_GRU, train_iter, vocab, lr, num_epochs, device) # 35.1s
perplexity 1.0, 199203.7 tokens/sec on cuda:0
time travelleryou can show black is white by argument said filby
travelleryou can show black is white by argument said filby

lstm_layer = nn.LSTM(num_inputs, num_hiddens)
model_LSTM = d2l.RNNModel(lstm_layer, len(vocab))
model_LSTM = model_LSTM.to(device)
d2l.train_ch8(model_LSTM, train_iter, vocab, lr, num_epochs, device) # 35.4s
perplexity 1.0, 199069.6 tokens/sec on cuda:0
time travelleryou can show black is white by argument said filby
travelleryou can show black is white by argument said filby

(4)既然候选记忆元通过使用 tanh 函数来确保值范围在 ( − 1 , 1 ) (-1,1) (−1,1) 之间,那么为什么隐状态需要再次使用 tanh 函数来确保输出值范围在 (-1,1) 之间呢?
候选记忆元和隐状态之间还有个记忆元呐,这个: C t = F t ⊙ C t − 1 + I t ⊙ C t ~ \boldsymbol{C}_t=\boldsymbol{F}_t\odot\boldsymbol{C}_{t-1}+\boldsymbol{I}_t\odot\tilde{\boldsymbol{C}_t} Ct=Ft⊙Ct−1+It⊙Ct~
很有可能出范围的。
(5)实现一个能够基于时间序列进行预测而不是基于字符序列进行预测的长短期记忆网络模型。
不会,略。
相关文章:
《动手学深度学习 Pytorch版》 9.2 长短期记忆网络(LSTM)
解决隐变量模型长期信息保存和短期输入缺失问题的最早方法之一是长短期存储器(long short-term memory,LSTM)。它与门控循环单元有许多一样的属性。长短期记忆网络的设计比门控循环单元稍微复杂一些,却比门控循环单元早诞生了近 2…...
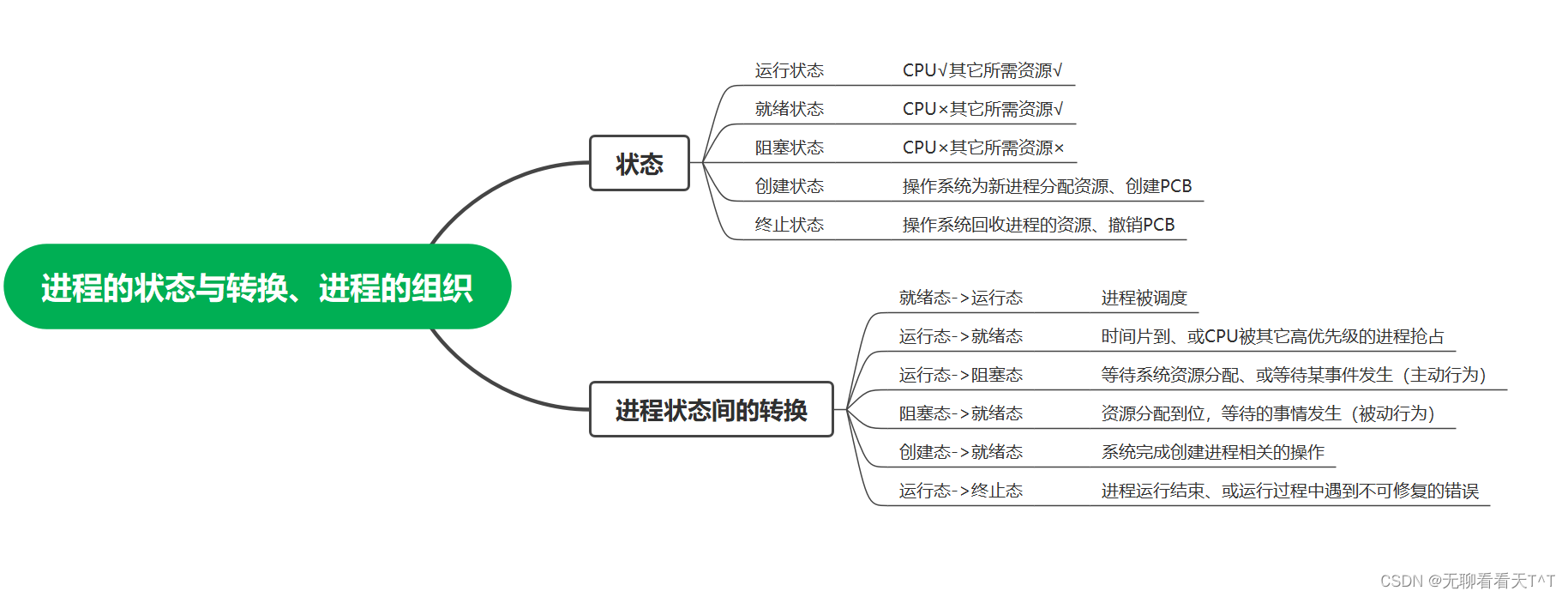
计算机操作系统-第十一天
目录 1、进程的状态 创建态与就绪态 运行态 终止态 新建态 结束态 进程状态的转换 进程的组织方式 链接方式(常见) 索引方式(少见) 本节思维导图 1、进程的状态 创建态与就绪态 1、进程正在被创建时,处于…...
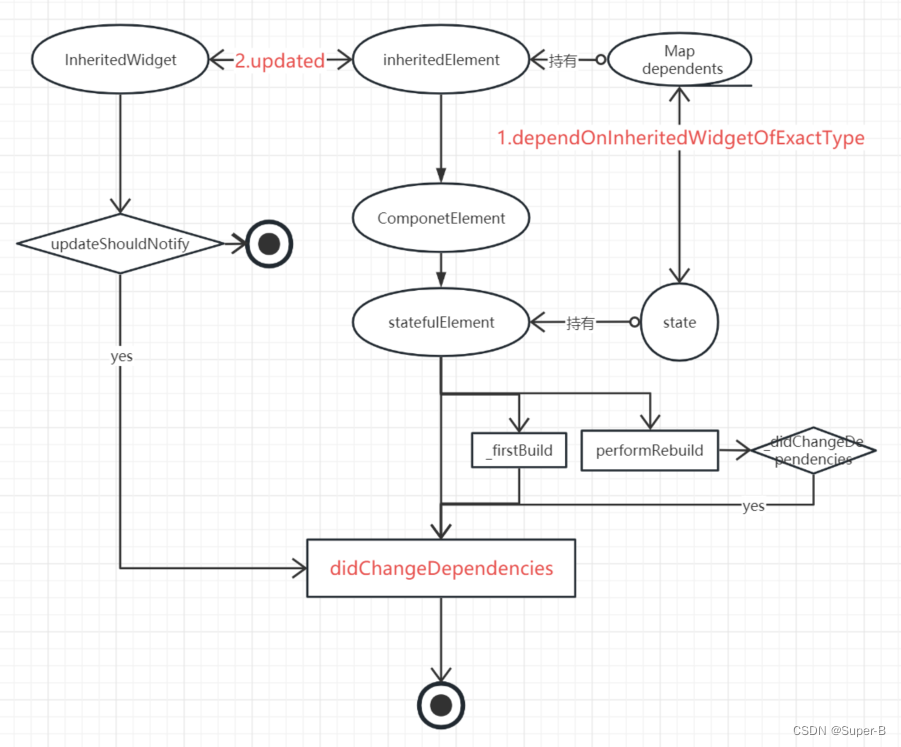
Flutter视图原理之StatefulWidget,InheritedWidget
目录 StatefulElement1. 构造函数2. build3. _firstBuild3. didChangeDependencies4. setState InheritedElement1. Element类2. _updateInheritance3. InheritedWidget数据向下传递3.1 dependOnInheritedWidgetOfExactType 4. InheritedWidget的状态绑定4.1. ProxyElement 在f…...

观察者模式-对象间的联动
有个商城小程序,用户希望当有新品上市的时候能通知他们。这样用户就可以不要时刻盯着小程序了。在这个场景中,用户向小程序订阅了一个服务——发送新品短信。小程序在有新品上线时负责向订阅客户发出这个消息。 这就是发布-订阅模式,也称观察…...
Webpack十大缺点:当过度工程化遇上简单的静态页面
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...
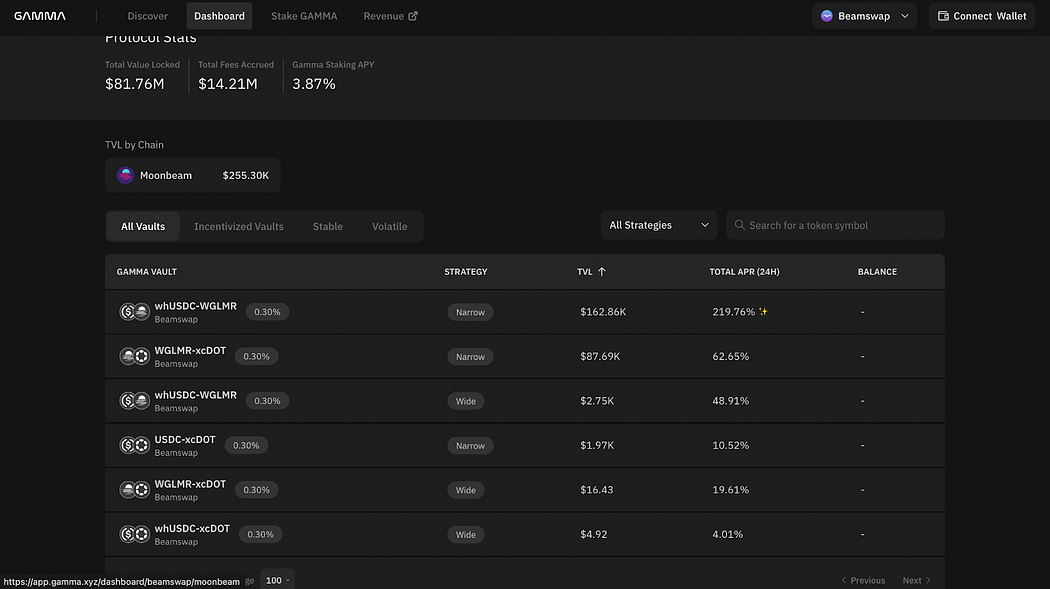
新手指南|如何快速参与Moonbeam Ignite
Moonbeam Ignite是社区熟悉的有奖链上交互活动,将有300万枚GLMR作为生态激励注入Moonbeam生态系统,体验MoonbeamMoonbeam生态的应用即可获取相应Token奖励。Beamex/Beamswap、Moonwell和Gamma作为首批参与Moonbeam Ignite的三家项目方,将在活…...

VR航天科普主题公园模拟太空舱体验馆vr航天模拟体验设备
VR航天航空体验馆巡展是一项非常受欢迎的展览活动,可以让公众在现场体验到航天飞行的乐趣。 普乐蛙VR展览组织者会设计一个航天航空主题的VR体验馆,并在馆内设置各种航天航空相关的展示内容,如太空舱、火箭发射、星际航行等。 其次࿰…...

Spring Boot OAuth 2.0整合详解
目录 一、Spring Boot 2.x 示例 1、初始化设置 2、设置重定向URI 3、配置 application.yml 4、启动应用程序 二、Spring Boot 2.x 属性映射 二、CommonOAuth2Provider 三、配置自定义提供者(Provider)属性 四、覆盖 Spring Boot 2.x 的自动配置…...
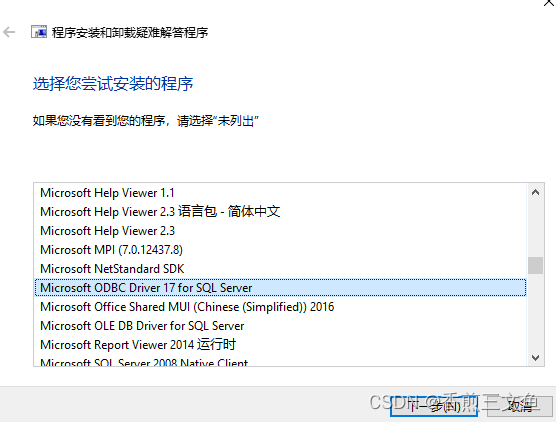
安装visual studio报错“无法安装msodbcsql“
在安装visual studio2022时安装完成后提示无法安装msodbcsql, 查看日志文件详细信息提示:指定账户已存在。 未能安装包“msodbcsql,version17.2.30929.1,chipx64,languagezh-CN”。 搜索 URL https://aka.ms/VSSetupErrorReports?qPackageIdmsodbcsql;PackageActi…...

webGL编程指南 第三章 矩阵平移三角形.translatedTriangle_Matrix
我会持续更新关于wegl的编程指南中的代码。 当前的代码不会使用书中的缩写,每一步都是会展开写。希望能给后来学习的一些帮助 git代码地址 :git 接着 上一节 中 我们使用矩阵进行旋转,这次我们使用矩阵实现位移 <!DOCTYPE html> <…...
修改echarts的tooltip样式 折线图如何配置阴影并实现渐变色和自适应
图片展示 一、引入echarts 这里不用多解释 vue里使用 import echarts from “echarts”; html页面引用js文件或用script标签引用 二、定义一个具有宽高的dom div <div id"echart-broken" style"width:400px;height: 200px;"></div>三、定义…...

[论文笔记] SurroundOcc: Multi-Camera 3D Occupancy Prediction for Autonomous Driving
Wei, Yi, et al. “Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023. 重点记录 将占用网格应用到多个相机构成的3D空间中; 使用BEVFormer中的方法获取3D特征, …...
-NOA 城市辅助系统-毫末智行)
辅助驾驶功能开发-功能对标篇(16)-NOA 城市辅助系统-毫末智行
1.横向对标参数 厂商毫末智行车型魏牌摩卡DHT-PHEV上市时间发布:2022年8月30日 上市:2022年底前方案12V5R2L+1DMS摄像头前视摄像头*3【800W】侧视摄像头*4后视摄像头*1【800W】环视摄像头*4DMS摄像头*1雷达毫米波雷达*54D毫米波雷达/超声波雷达*12激光雷达*2【速腾聚创 M1,1…...

H3C的IRF堆叠互联关系说明
H3C IRF堆叠互联说明48口交换机连接方式IRF Port 两台设备第一台的51口 第二台的51口irf-port 1/2 port group interface ten-gigabitethernet 1/0/51 port group interface ten-gigabitethernet 1/0/52第一台的52口第二台的52口irf-port 2/1 port group interface ten-gigabi…...
)
货物摆放(蓝桥杯)
货物摆放 题目描述 小蓝有一个超大的仓库,可以摆放很多货物。 现在,小蓝有 n 箱货物要摆放在仓库,每箱货物都是规则的正方体。小蓝规定了长、宽、高三个互相垂直的方向,每箱货物的边都必须严格平行于长、宽、高。 小蓝希望所有的…...

3782: 【C3】【穷举】弹珠游戏
目录 题目描述 输入 输出 样例输入 样例输出 题目描述 游戏的内容是:在一个 n*n 的矩阵里,有若干个敌人,你的弹珠可以摧毁敌人,但只能攻击你所在的行、列里的所有敌人,然后你就可以获得他们的分数之和࿰…...

leetcode 5
leetcode 5 题目是通过枚举字符串,然后判断是否子字符串满足回文。 引用传递和值传递相比,引用传递可以减少内存空间。提高代码运行效率。 https://www.cnblogs.com/yanlingyin/archive/2011/12/07/2278961.html...

centos中nacos设置开机自启动
以下实践亲测有效! 1、在以下目录编辑新建nacos.service文件 vim /lib/systemd/system/nacos.service [Unit] Descriptionnacos Afternetwork.target [Service] Typeforking ExecStart/usr/local/nacos/bin/startup.sh -m standalone ExecReload/usr/local/nacos/b…...
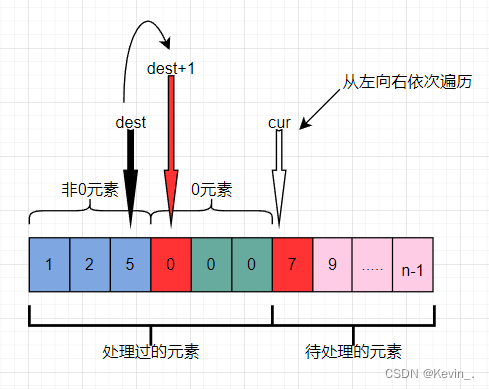
双指针——移动零
一,题目要求: 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。 示例 1: 输入: nums [0,1,0,3,12] 输出: [1,3,12,0,0…...
WPF中在MVVM模式下实现导航功能
WPF中在MVVM模式下实现导航功能 一、利用TabControl 使用场景:项目小,不用考虑内存开销的问题。 实现方式1-手动指定ViewModel 分别定义3个UserControl作为View用于演示 <UserControl...><Grid><StackPanel Orientation"Vertic…...

一次慢改表引发的线上死锁事故复盘
一次慢改表引发的线上死锁事故复盘 一、事故背景 在一次常规的数据库表结构变更过程中,对某核心业务表执行了慢改表操作(使用 pt-online-schema-change)。操作开始后,短时间内触发报警: 部分接口响应时间显著上升出现请…...
Pixel Aurora Engine部署案例:边缘计算设备(Jetson Orin)轻量化部署
Pixel Aurora Engine部署案例:边缘计算设备(Jetson Orin)轻量化部署 1. 项目背景与价值 Pixel Aurora Engine是一款基于AI扩散模型的创意工具,专为生成复古像素艺术设计。其独特的8-bit游戏风格界面和高效生成能力,使…...

告别命令行恐惧:FastbootEnhance如何让Android刷机变得像点菜一样简单?
告别命令行恐惧:FastbootEnhance如何让Android刷机变得像点菜一样简单? 【免费下载链接】FastbootEnhance A user-friendly Fastboot ToolBox & Payload Dumper for Windows 项目地址: https://gitcode.com/gh_mirrors/fa/FastbootEnhance 还…...

自动化工具赋能工作流:如何用KeymouseGo提升效率与降低错误率
自动化工具赋能工作流:如何用KeymouseGo提升效率与降低错误率 【免费下载链接】KeymouseGo 类似按键精灵的鼠标键盘录制和自动化操作 模拟点击和键入 | automate mouse clicks and keyboard input 项目地址: https://gitcode.com/gh_mirrors/ke/KeymouseGo 在…...

OpenClaw镜像体验:Qwen3.5-9B云端部署避坑指南
OpenClaw镜像体验:Qwen3.5-9B云端部署避坑指南 1. 为什么选择云端镜像而非本地部署 去年冬天,当我第一次尝试在本地MacBook Pro上部署OpenClaw时,整整浪费了两个周末的时间。Node版本冲突、Python依赖缺失、CUDA驱动不兼容——这些看似简单…...

2026指纹浏览器技术升级:从环境隔离到风控对抗
2026 年,互联网平台的风控技术迎来质的飞跃,传统的 “IP 切换”“参数修改” 已无法应对多维度的检测体系。指纹浏览器作为多账号运营的核心支撑,其技术迭代速度远超以往 —— 从简单的参数修改,到内核级虚拟化;从单一…...

Awoo Installer:破解Switch游戏安装限制的高性能解决方案
Awoo Installer:破解Switch游戏安装限制的高性能解决方案 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为破解…...

哔咔漫画下载器:多线程极速下载完整指南
哔咔漫画下载器:多线程极速下载完整指南 【免费下载链接】picacomic-downloader 哔咔漫画 picacomic pica漫画 bika漫画 PicACG 多线程下载器,带图形界面 带收藏夹,已打包exe 下载速度飞快 项目地址: https://gitcode.com/gh_mirrors/pi/pi…...

Legacy-iOS-Kit:让旧设备重获新生的开源解决方案
Legacy-iOS-Kit:让旧设备重获新生的开源解决方案 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit 当你的…...

Java TCC到底要不要用?90%团队踩坑的4个认知误区,今天一次性说透
第一章:Java TCC到底要不要用?90%团队踩坑的4个认知误区,今天一次性说透TCC(Try-Confirm-Cancel)作为分布式事务的一种经典模式,在 Java 生态中常被误认为“高可用银弹”或“微服务标配”。但真实生产实践中…...