04、MySQL-------MyCat实现分库分表
目录
- 九、MyCat实现分库分表
- 1、分库分表介绍:
- 横向(水平)拆分
- **垂直分表**:
- 水平分表:
- **分库分表**
- 纵向(垂直)拆分
- 分表字段选择
- 2、分库分表操作:
- 1、分析图:
- 2、克隆主从
- 3、配置MyCat
- 修改配置文件
- schema.xml
- rule.xml
- schema.xml
- **rule.xml**
- 重启mycat
- 4、测试:
- mysql系统架构各模块工作配合
- schema.xml
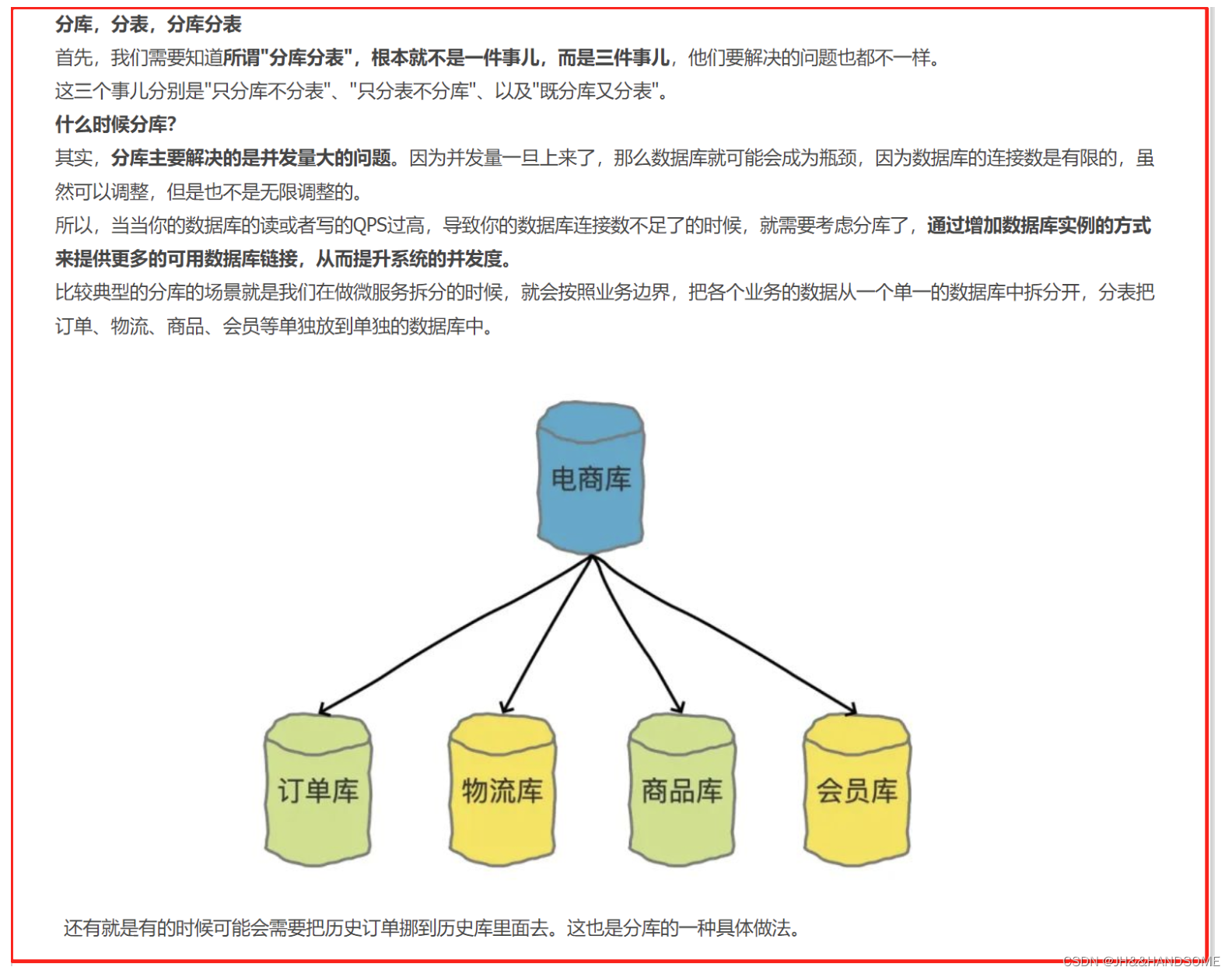
九、MyCat实现分库分表
1、分库分表介绍:
https://www.cnblogs.com/zhangyi555/p/16528576.html
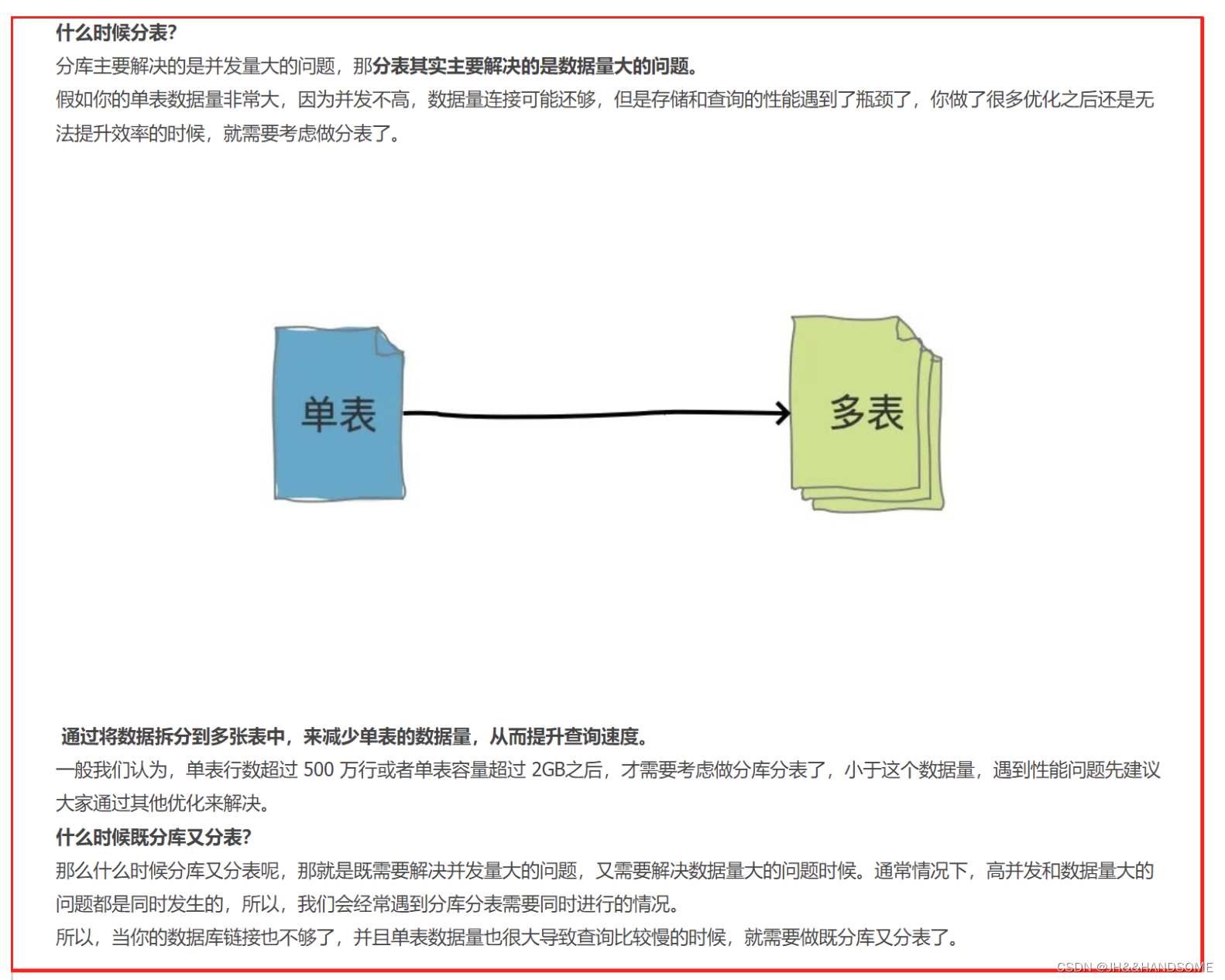
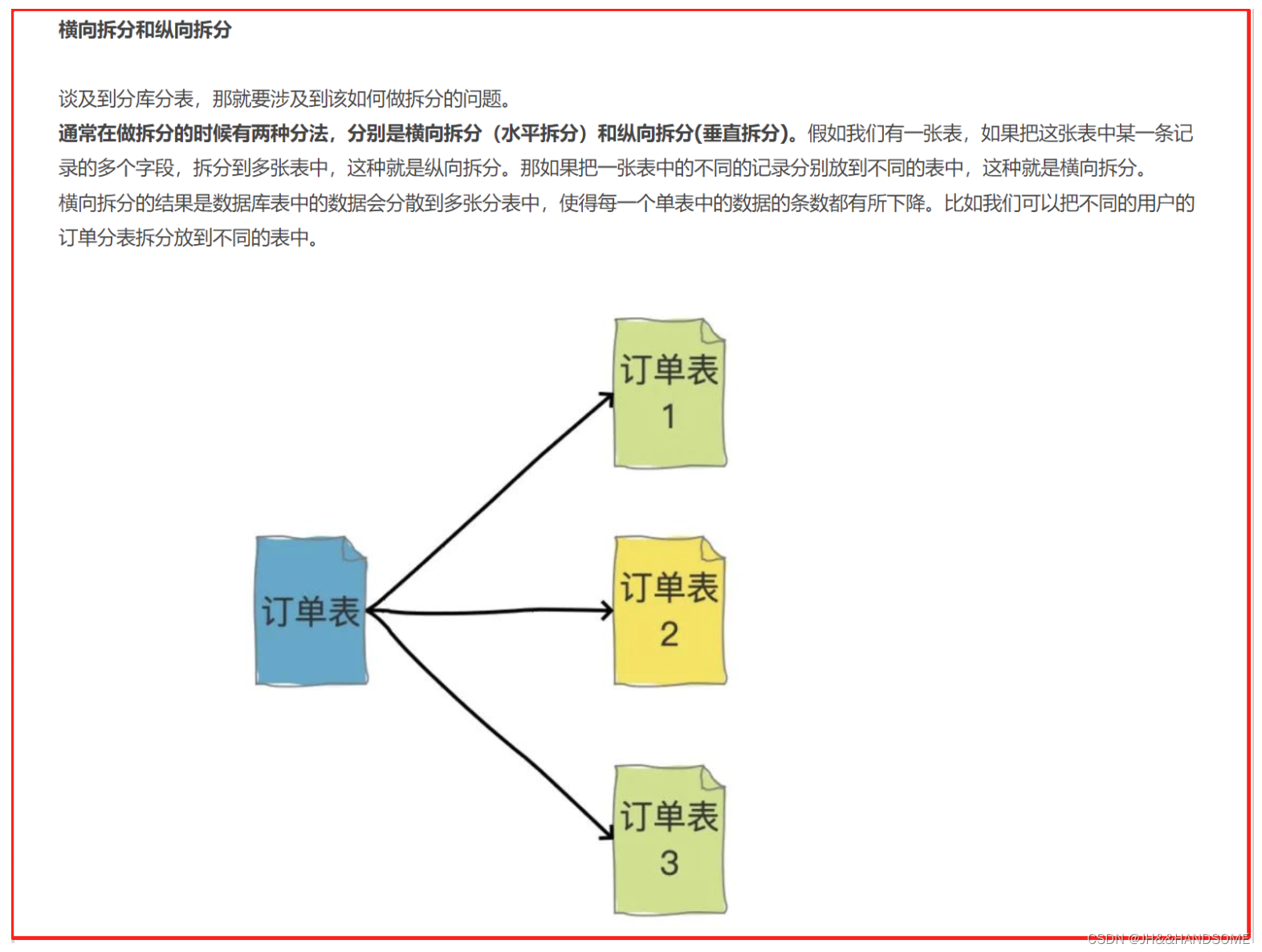
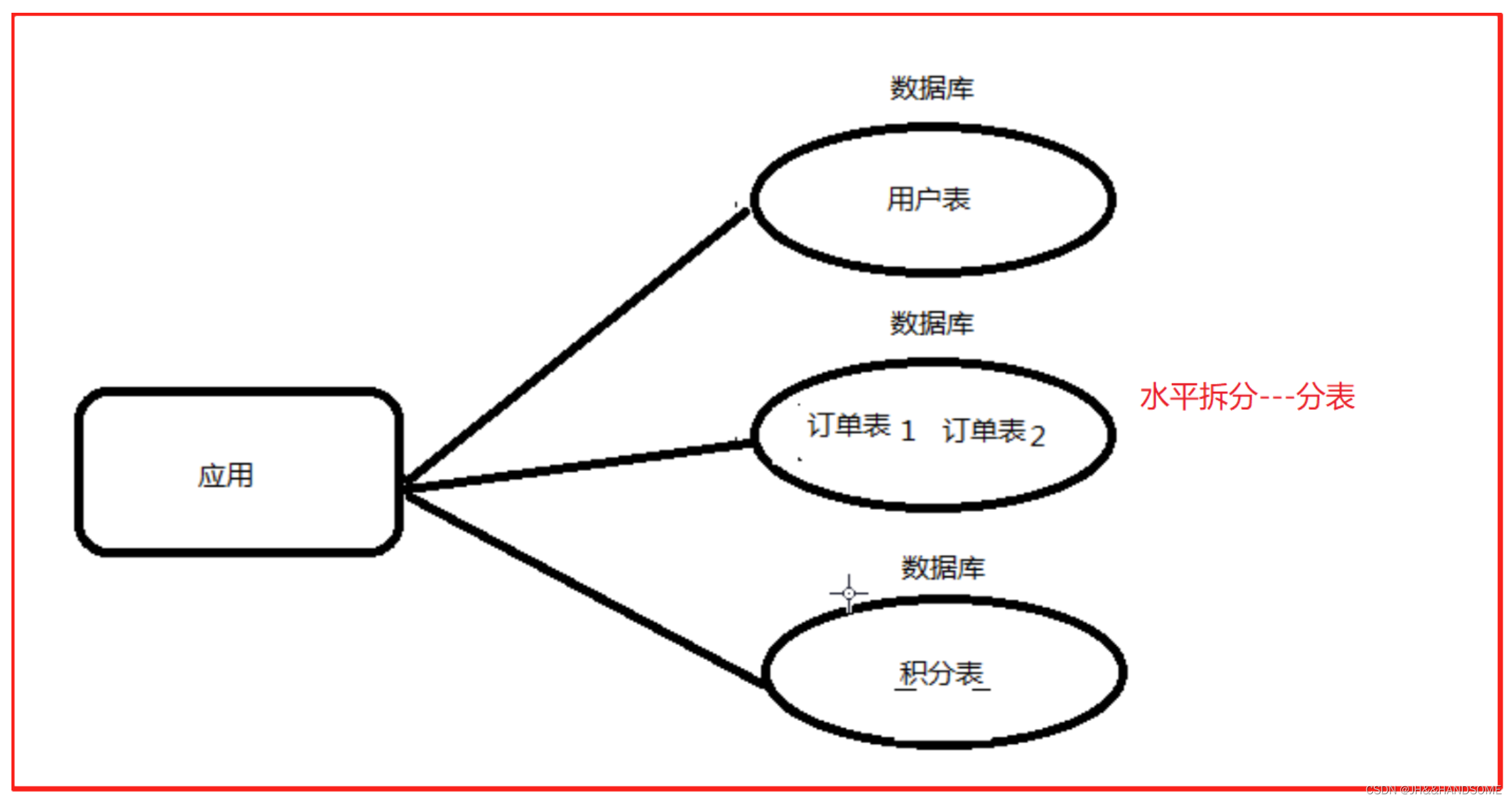
横向(水平)拆分
那如果把一张表中的不同的记录分别放到不同的表中,这种就是横向拆分。
横向拆分的结果是数据库表中的数据会分散到多张分表中,使得每一个单表中的数据的条数都有所下降。比如我们可以把不同的用户的订单分表拆分放到不同的表中
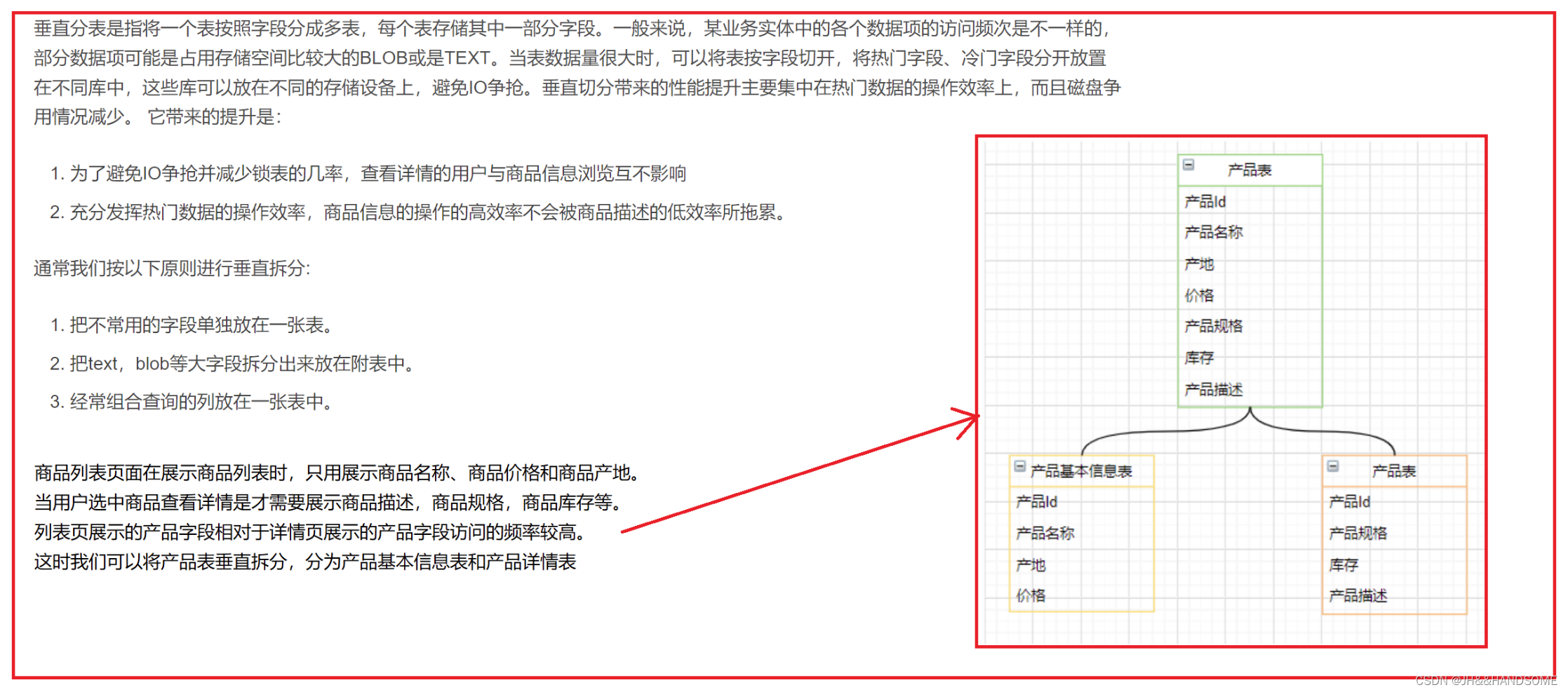
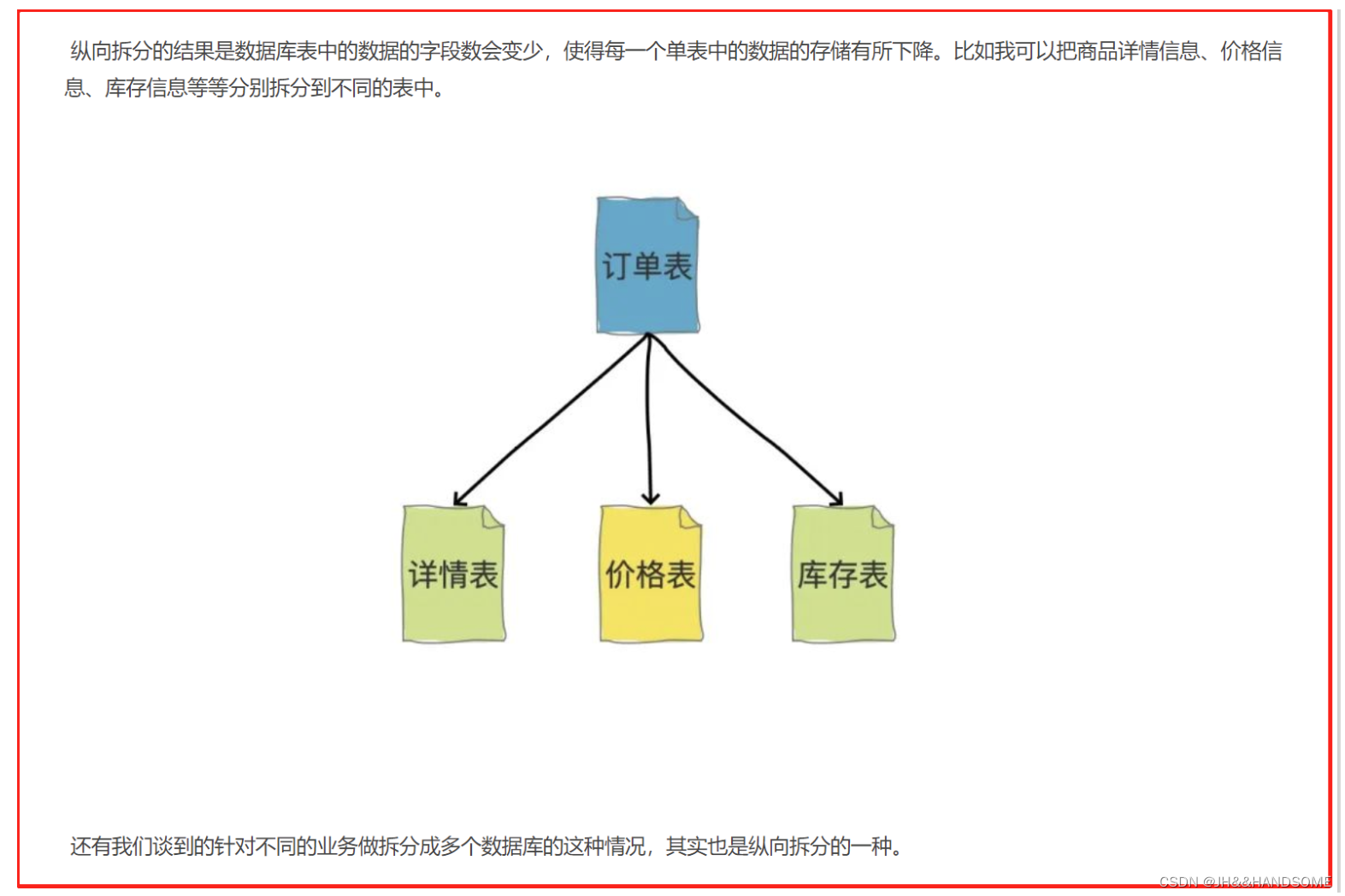
垂直分表:
垂直分表是指将一个表按照字段分成多表,每个表存储其中一部分字段
一张表有10个字段,分成A、B两张表,A表放3个字段,B表放7个字段。

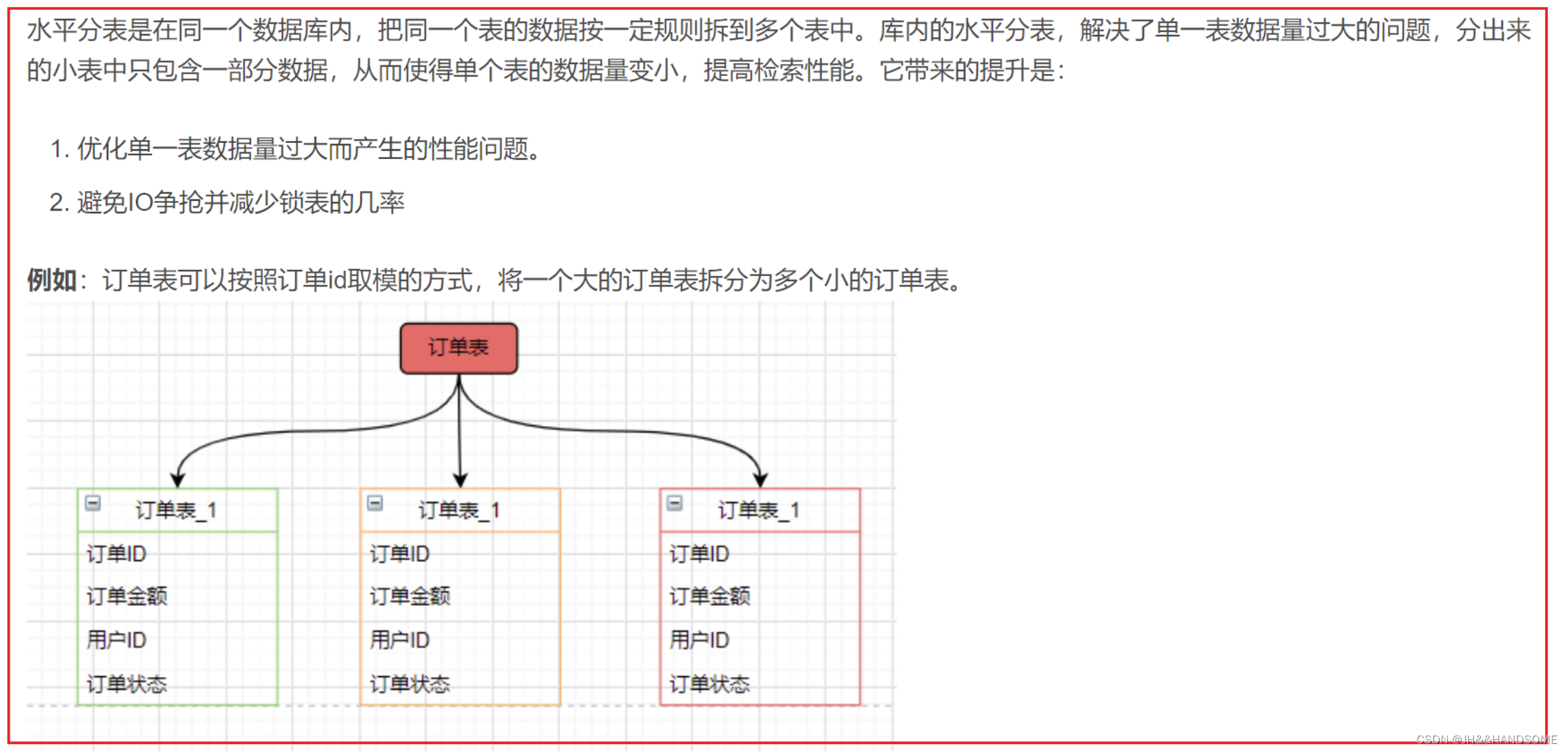
水平分表:
把10万条数据的表,分成两个5万数据的表,就是水平分表,字段都是一样的

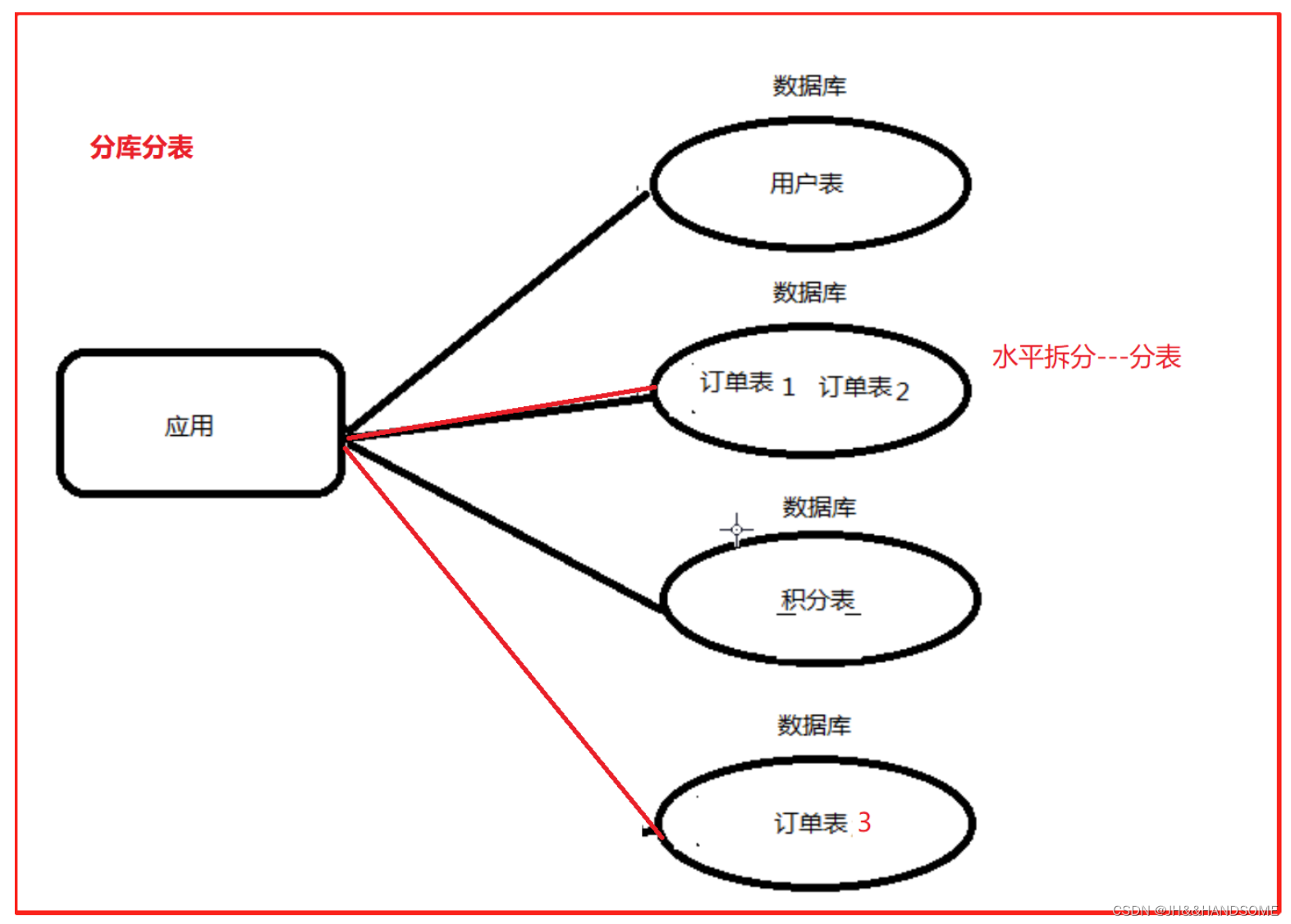
分库分表
纵向(垂直)拆分
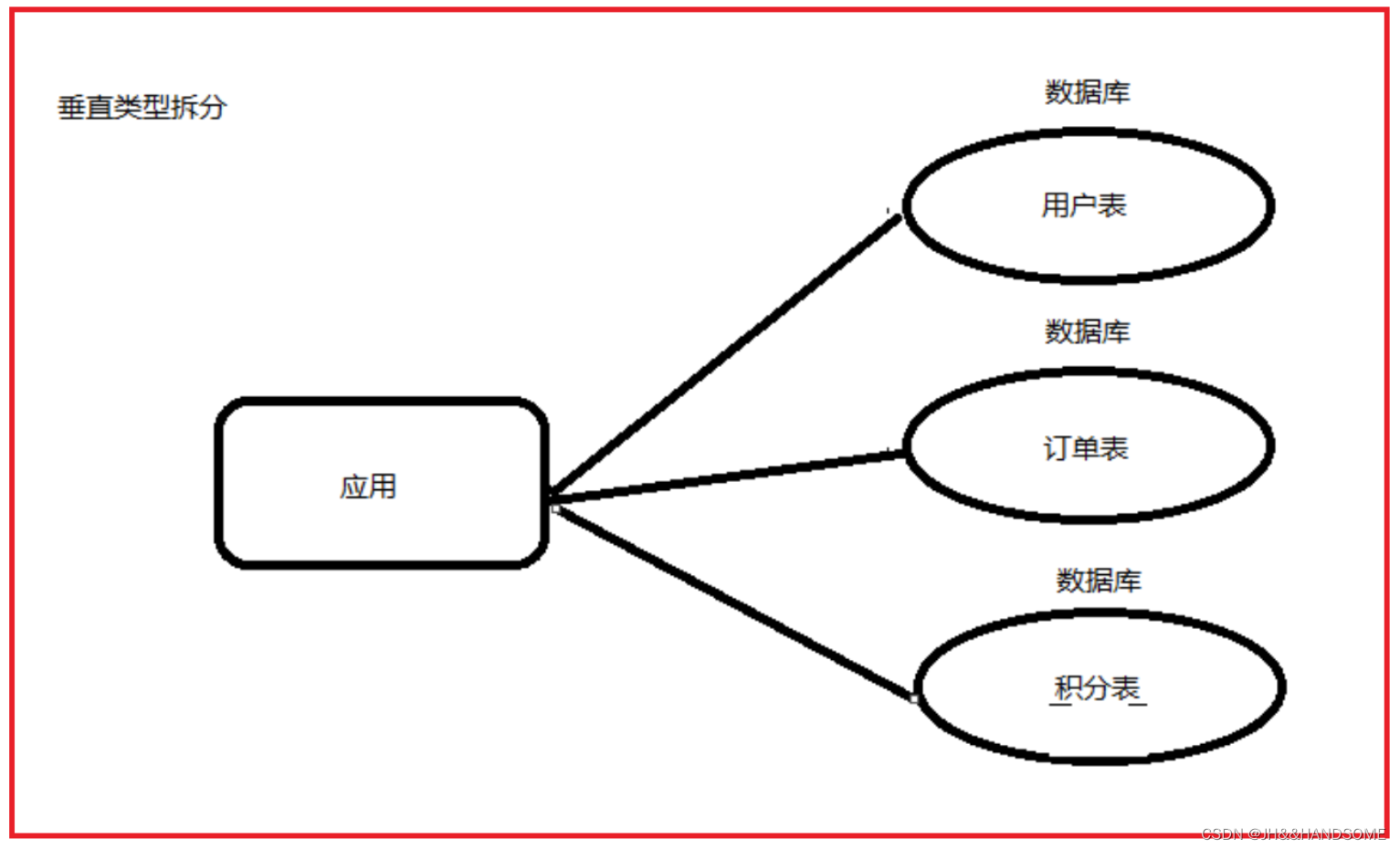
分表字段选择

2、分库分表操作:
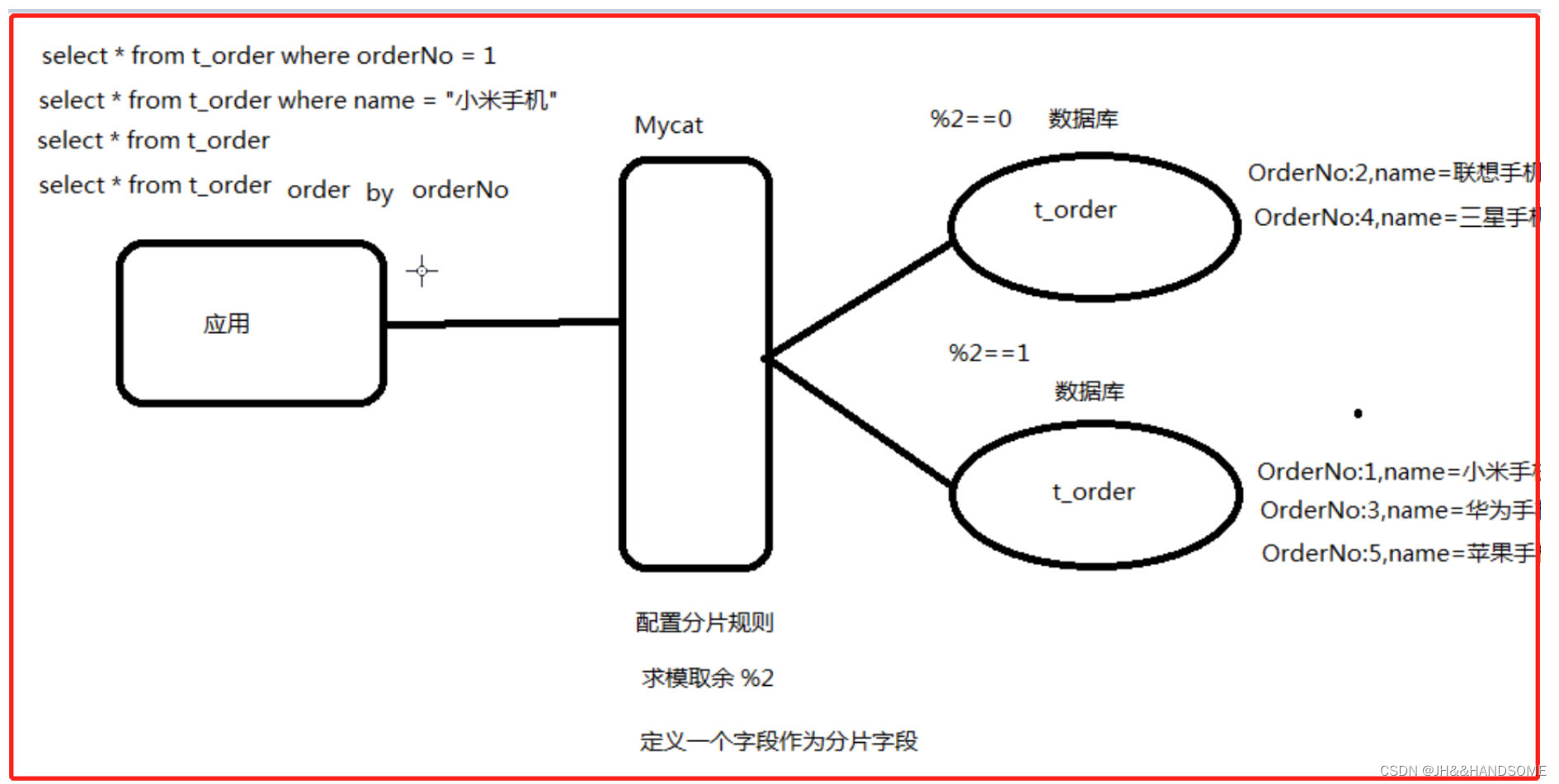
1、分析图:
2、克隆主从
在克隆出一个主数据和从数据
以前克隆后的id修改步骤参考
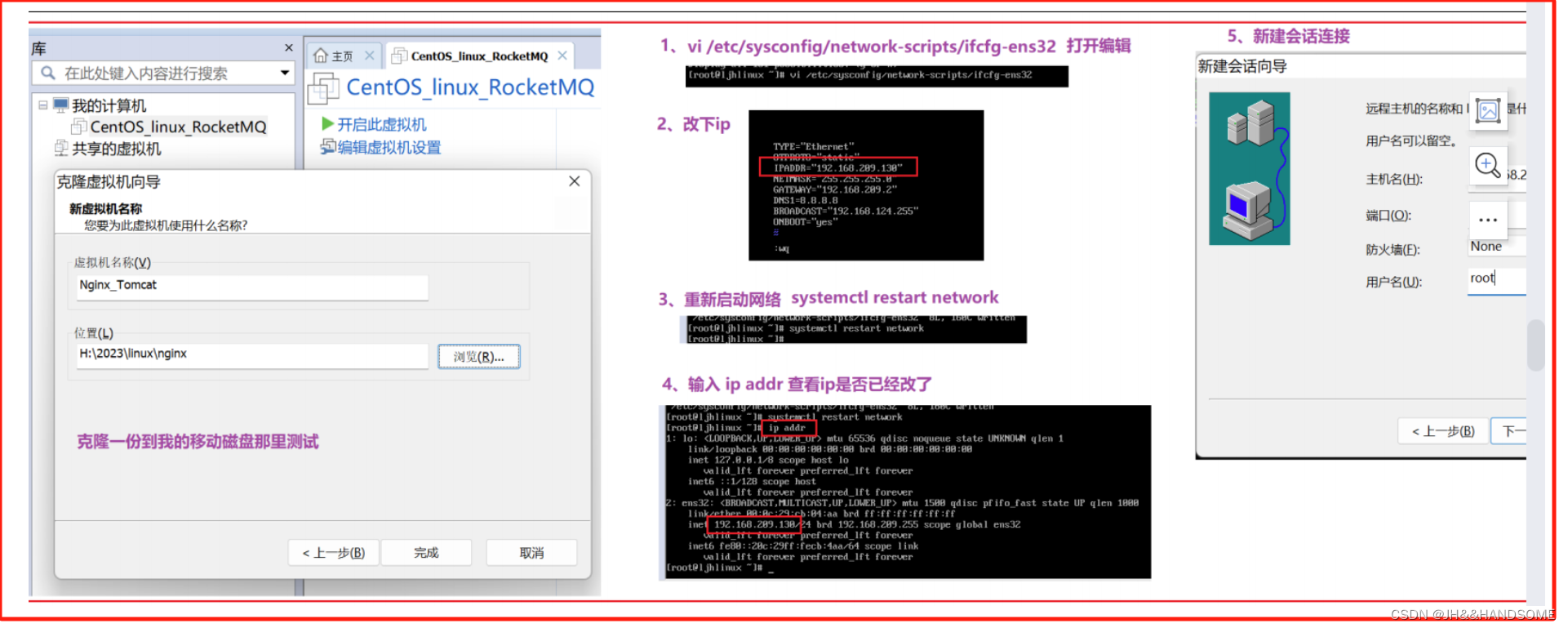
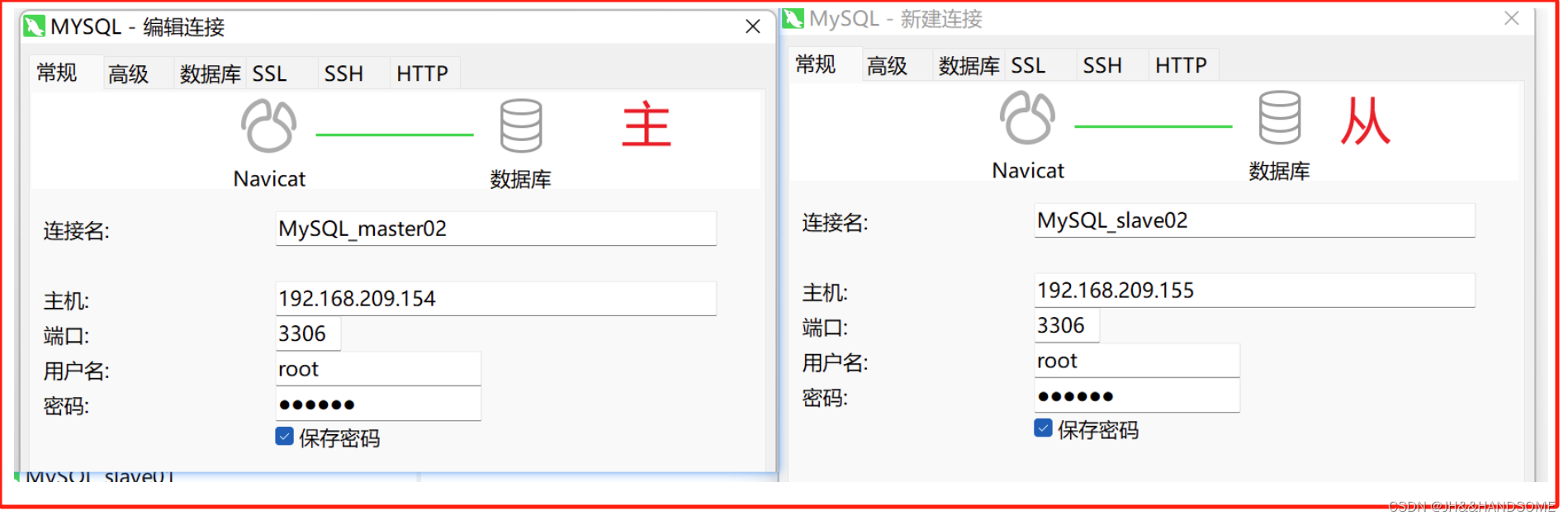
主数据库 :192.168.209.154
从数据库:192.168.209.155
这两个主从数据库的配置方法跟第一次配置的一样,参考下配置
步骤:
主数据库:
1、vi /etc/my.cnf 编辑
server-id=154 #基本就是用id后3为做标识
log-bin=master-bin
log-bin-index=master-bin.index
2、因为是拷贝的,所以需要修改mysql的uuid
查找mysql的位置 find / -iname “auto.cnf”
vi 拷贝查出来的位置,进入编辑,随便改uuid中的一个字母就行,保证唯一就可以
3、启动mysql mysql -uroot -p123456
如果启动不起来,错误:-bash: mysql: command not found,输入:alias mysql=/usr/local/mysql/bin/mysql
4、查看主节点的状态 show master status
从数据库:
1、vi /etc/my.cnf 编辑
server-id=155 #基本就是用id后3为做标识
log-bin=master-bin
log-bin-index=master-bin.index
2、因为是拷贝的,所以需要修改mysql的uuid
查找mysql的位置 find / -iname “auto.cnf”
vi 拷贝查出来的位置,进入编辑,随便改uuid中的一个字母就行,保证唯一就可以
3、启动mysql mysql -uroot -p123456
如果启动不起来,错误:-bash: mysql: command not found,输入:alias mysql=/usr/local/mysql/bin/mysql
4、停止节点链路 stop slave;
5、配置文件:change master to master_host=‘192.168.209.154’,master_user=‘root’,master_password=‘123456’,master_log_file=‘master-bin.000001’,master_log_pos=156;
通过主节点的 show master status,查看master-bin 和 master_log_pos(就是position)是多少,要保持一致,master_host也是要写主节点的id
6、启动从节点链路 start slave;
7、查看链路状态 show slave status \G; 要有两个yes才行
8、重启mysql的命令 service mysqld restart
对应id创建主从数据库
3、配置MyCat
修改配置文件
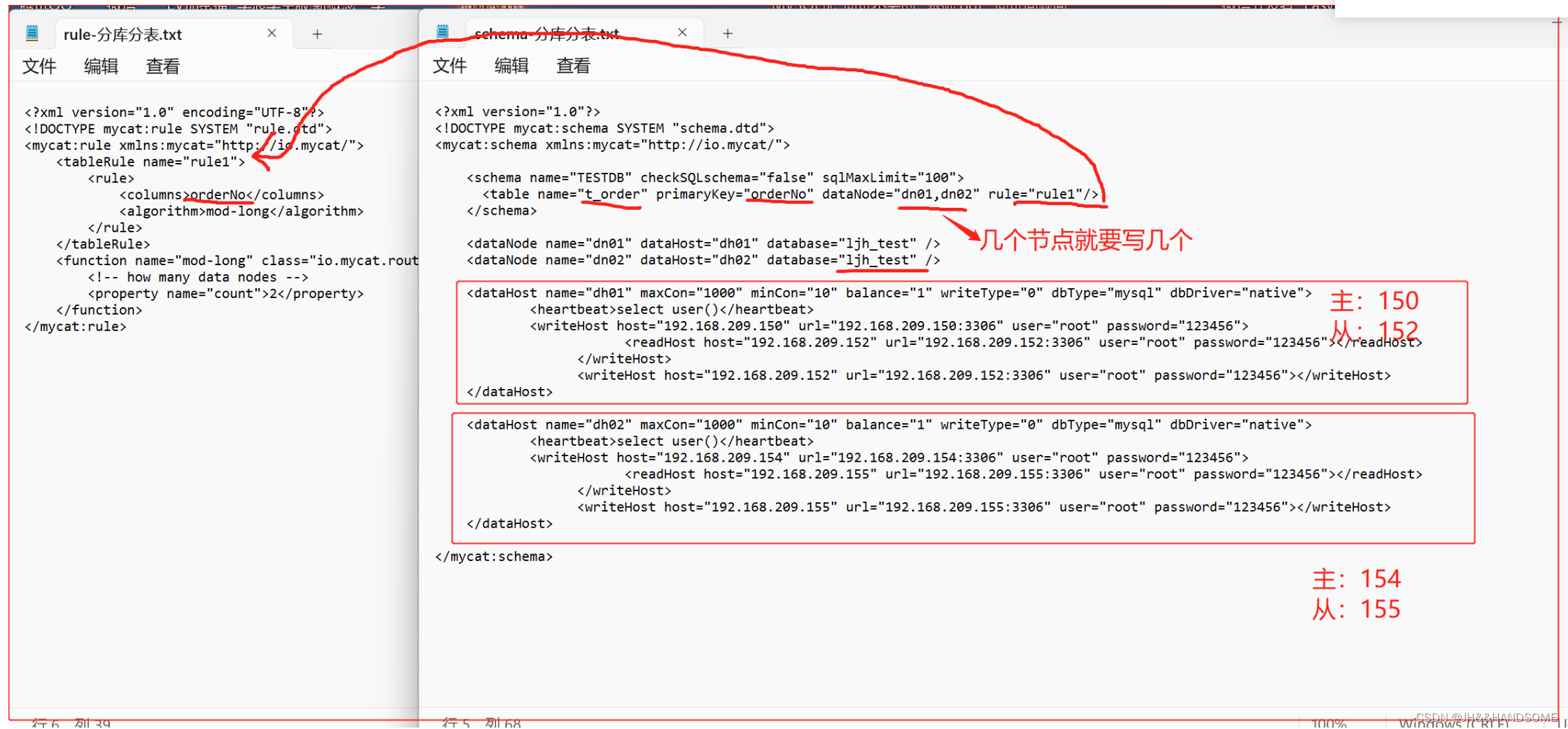
schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100"><table name="t_order" primaryKey="orderNo" dataNode="dn01,dn02" rule="rule1"/> </schema><dataNode name="dn01" dataHost="dh01" database="ljh_test" /> <dataNode name="dn02" dataHost="dh02" database="ljh_test" /> <dataHost name="dh01" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.209.150" url="192.168.209.150:3306" user="root" password="123456"><readHost host="192.168.209.152" url="192.168.209.152:3306" user="root" password="123456"></readHost></writeHost><writeHost host="192.168.209.152" url="192.168.209.152:3306" user="root" password="123456"></writeHost></dataHost> <dataHost name="dh02" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.209.154" url="192.168.209.154:3306" user="root" password="123456"><readHost host="192.168.209.155" url="192.168.209.155:3306" user="root" password="123456"></readHost></writeHost><writeHost host="192.168.209.155" url="192.168.209.155:3306" user="root" password="123456"></writeHost></dataHost> </mycat:schema>
rule.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
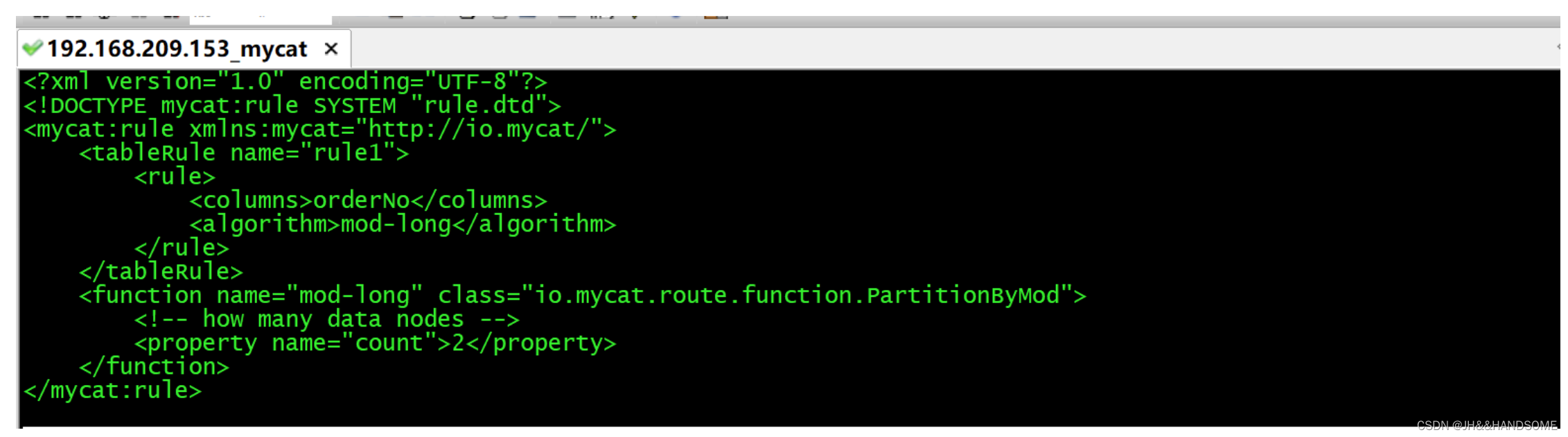
<mycat:rule xmlns:mycat="http://io.mycat/"><tableRule name="rule1"><rule><columns>orderNo</columns><algorithm>mod-long</algorithm></rule></tableRule><function name="mod-long" class="io.mycat.route.function.PartitionByMod"><!-- how many data nodes --><property name="count">2</property></function>
</mycat:rule>
schema.xml
编写文件:vi /usr/local/mycat/conf/schema.xml

拷贝进去,格式乱不用理
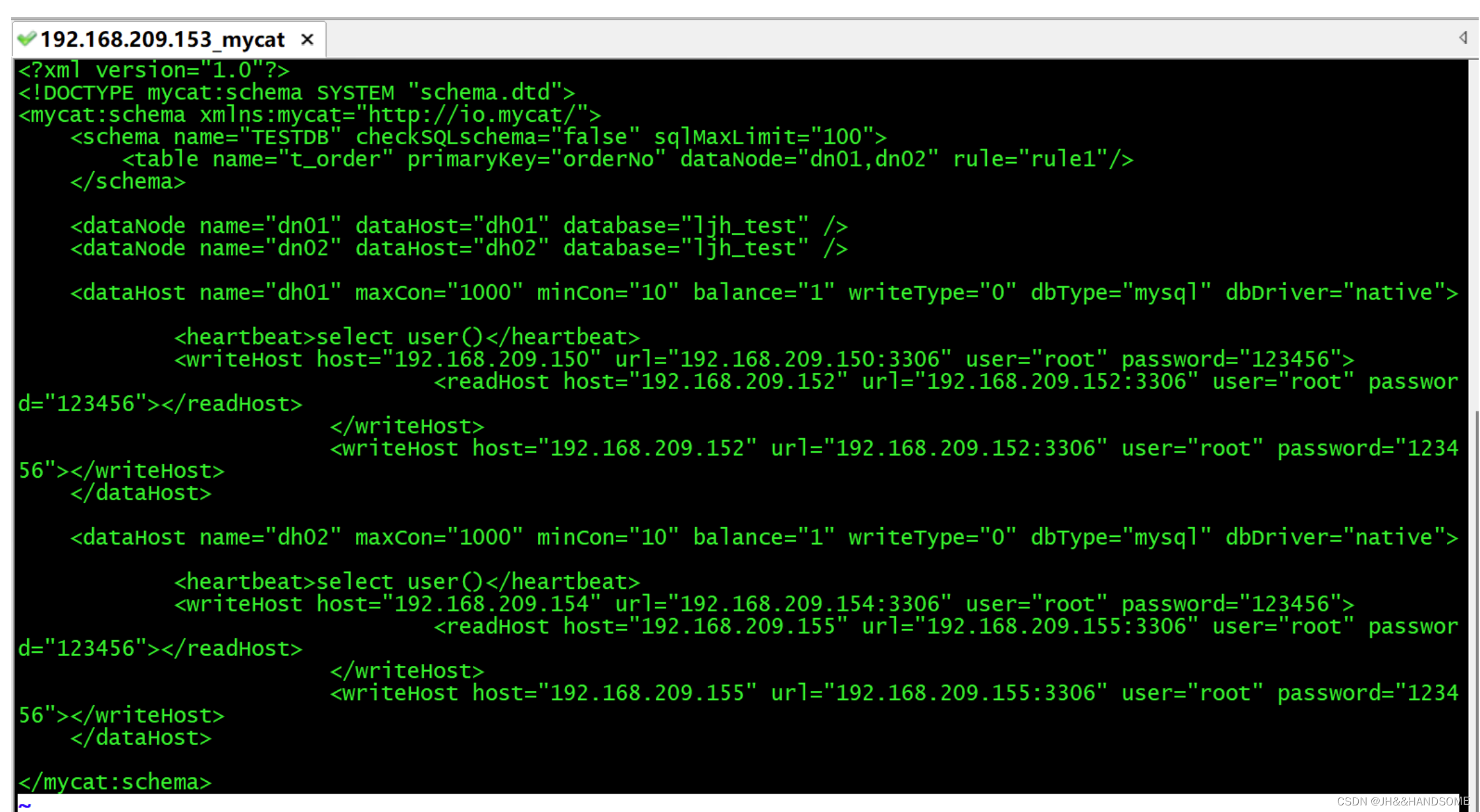
rule.xml
vi /usr/local/mycat/conf/rule.xml

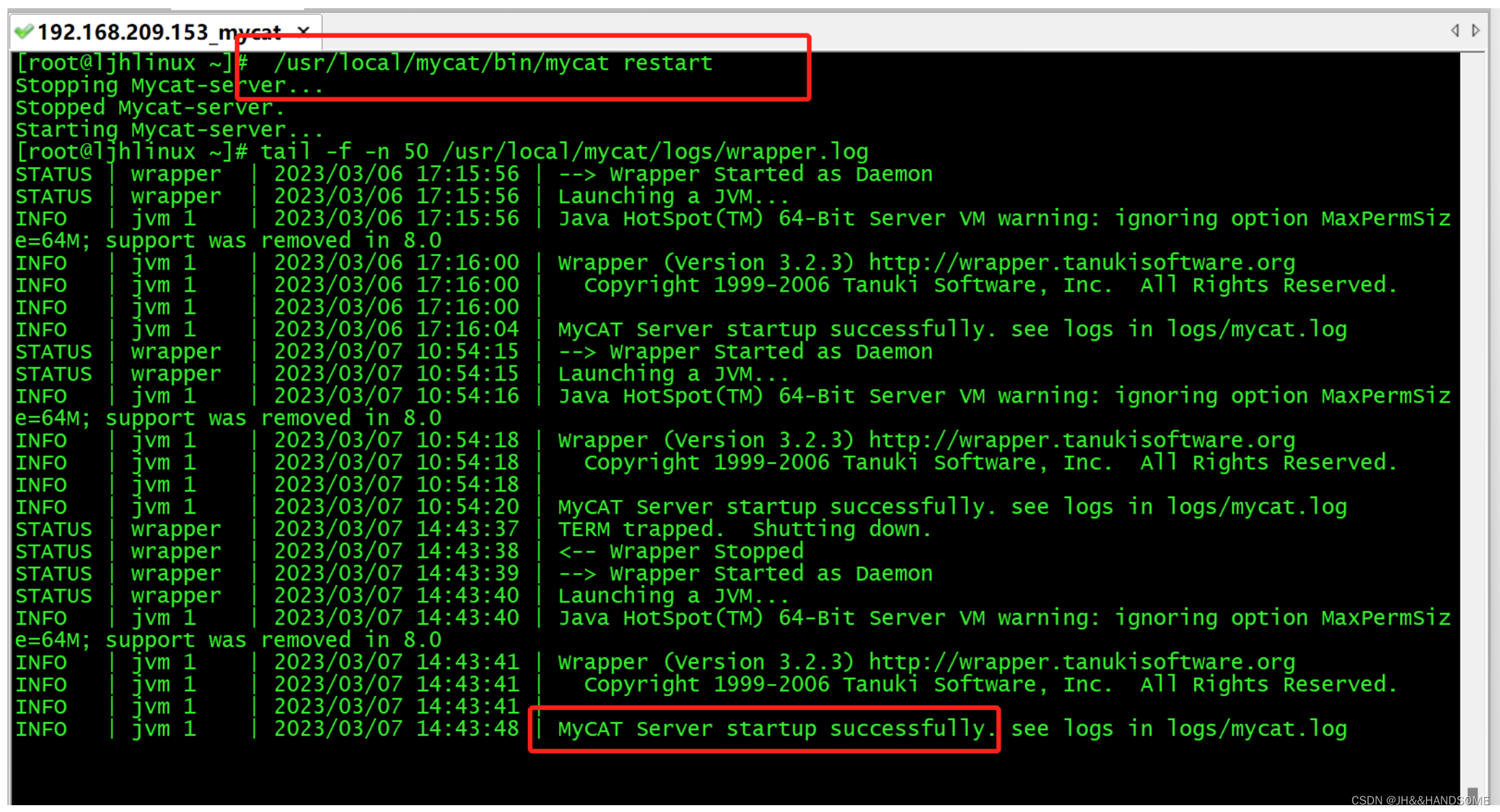
重启mycat
启动mycat: /usr/local/mycat/bin/mycat start
重启mycat:/usr/local/mycat/bin/mycat restart
查看mycat日志: tail -f -n 50 /usr/local/mycat/logs/wrapper.log
有successfully就是重启成功
4、测试:
**测试1:**把之前的数据都清空,插入五条数据,看是否会根据求模取余,把5条数据分别插在两个主数据库中(150和154)

分库分表后插入成功,成功把数据分两个数据库插入。
**测试2:**获取所有的数据,看能不能从两张数据库中把数据完整的查出来
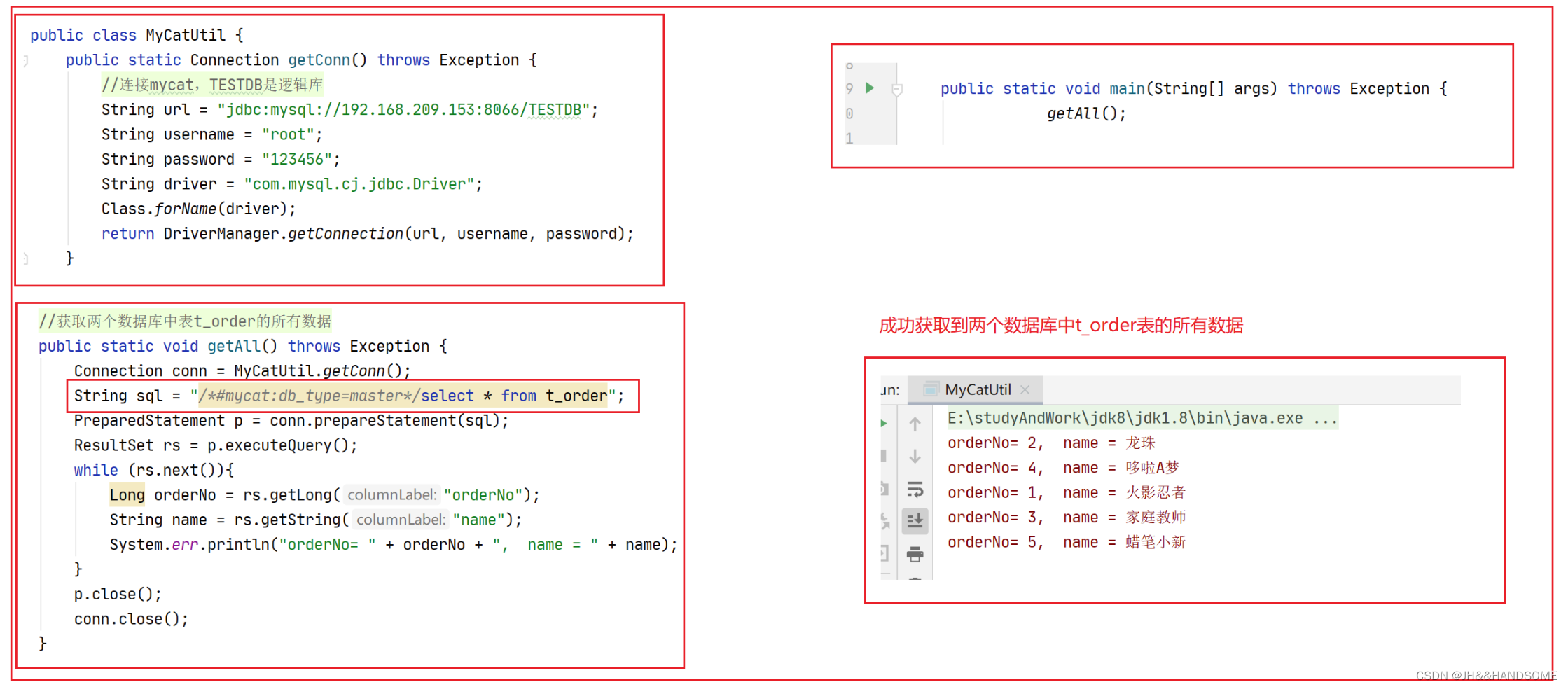
目前是还没有排序的,需要修改下sql
**测试3:**两个数据库,两张表,看查出来的数据能否正确排序
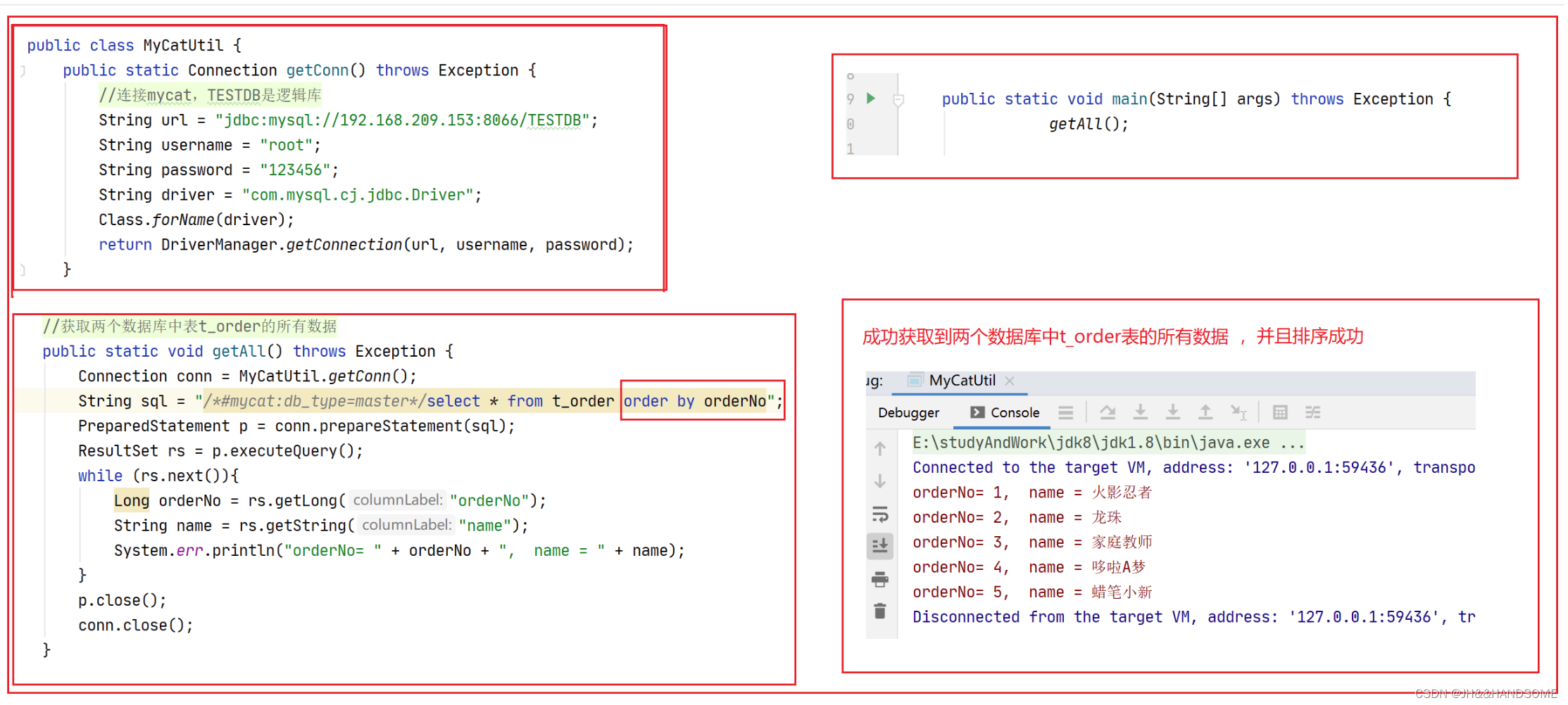
测试成功。
mysql系统架构各模块工作配合
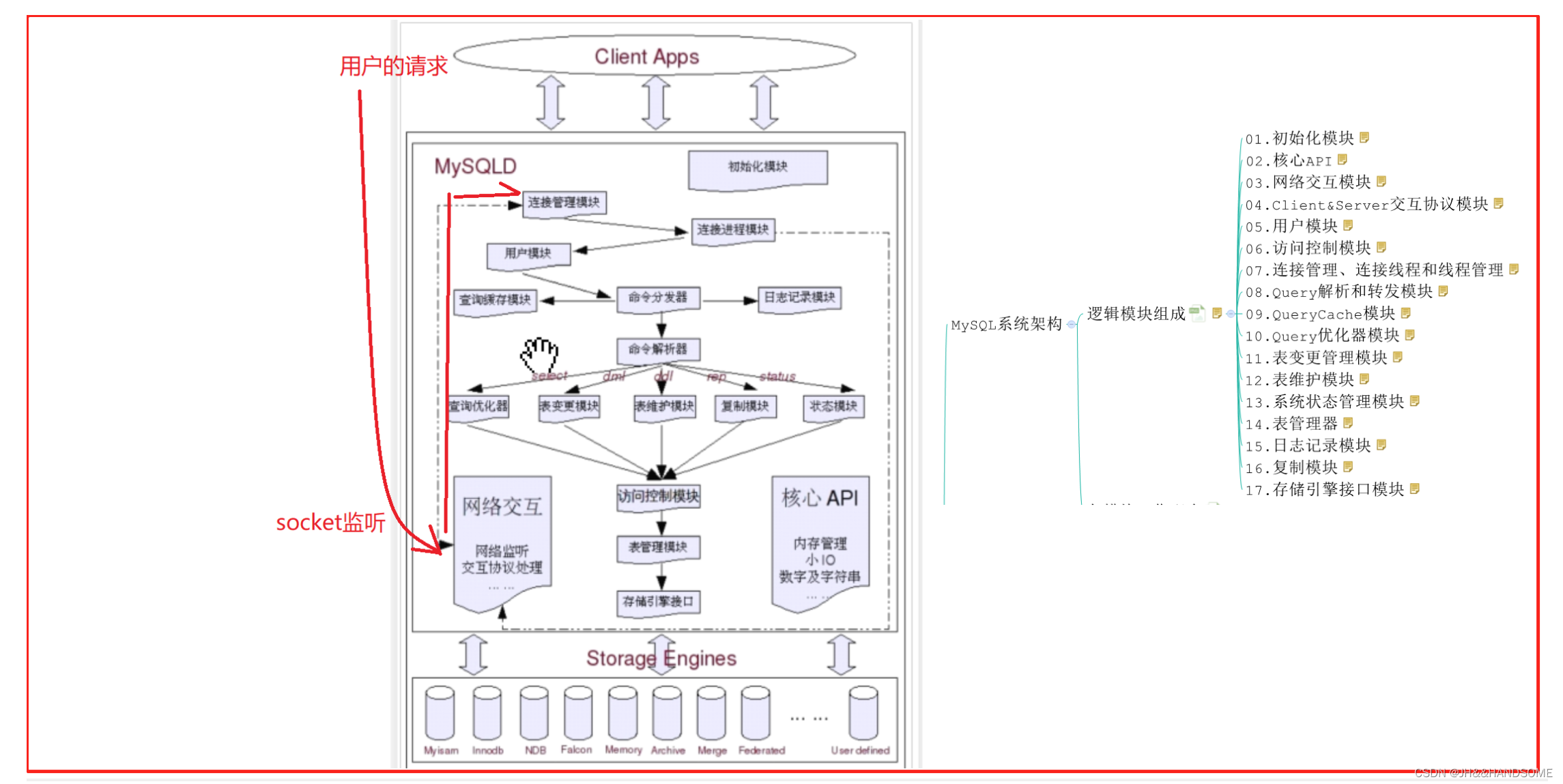
当我们执行启动 MySQL 命令之后,MySQL 的初始化模块就从系统配置文件中读取系统参数和命令行参数,并按照参数来初始化整个系统,如申请并分配 buffer,初始化全局变量以及各种结构等。同时各个存储引擎也被启动,并进行各自的初始化工作。当整个系统初始化结束后,由连接管理模块接手。连接管理模块会启动处理客户端连接请求的监听程序,包 括 tcp/ip 的网络监听,还有 unix 的 socket。这时候,MySQL Server 就基本启动完成,准备好接受客户端请求了。
当连接管理模块监听到客户端的连接请求(借助网络交互模块的相关功能),双方通过Client & Server 交互协议模块所定义的协议“寒暄”几句之后,连接管理模块就会将连接请求转发给线程管理模块,去请求一个连接线程。线程管理模块马上又会将控制交给连接线程模块,告诉连接线程模块:现在我这边有连接请求过来了,需要建立连接,你赶快处理一下。连接线程模块在接到连接请求后,首先会检查当前连接线程池中是否有被 cache 的空闲连接线程,如果有,就取出一个和客户端请求连接上,如果没有空闲的连接线程,则建立一个新的连接线程与客户端请求连接。当然,连接线程模块并不是在收到连接请求后马上就会取出一个连接线程连和客户端连接,而是首先通过调用用户模块进行授权检查,只有客户端请求通过了授权检查后,他才会将客户端请求和负责请求的连接线程连上。
在 MySQL 中,将客户端请求分为了两种类型:一种是 query,需要调用 Parser 也就是Query 解析和转发模块的解析才能够执行的请求;一种是 command,不需要调用 Parser 就可以直接执行的请求。如果我们的初始化配置中打开了 Full Query Logging 的功能,那么Query 解析与转发模块会调用日志记录模块将请求计入日志,不管是一个 Query 类型的请求还是一个 command 类型的请求,都会被记录进入日志,所以出于性能考虑,一般很少打开FullQuery Logging 的功能。
当客户端请求和连接线程“互换暗号(互通协议)”接上头之后,连接线程就开始处理客户端请求发送过来的各种命令(或者 query),接受相关请求。它将收到的 query 语句转给 Query 解析和转发模块,Query 解析器先对 Query 进行基本的语义和语法解析,然后根据命令类型的不同,有些会直接处理,有些会分发给其他模块来处理。
如果是一个 Query 类型的请求,会将控制权交给 Query 解析器。Query 解析器首先分析看是不是一个 select 类型的 query,如果是,则调用查询缓存模块,让它检查该 query 在query cache 中是否已经存在。如果有,则直接将 cache 中的数据返回给连接线程模块,然后通过与客户端的连接的线程将数据传输给客户端。如果不是一个可以被 cache 的 query类型,或者 cache 中没有该 query 的数据,那么 query 将被继续传回 query 解析器,让 query解析器进行相应处理,再通过 query 分发器分发给相关处理模块。
如果解析器解析结果是一条未被 cache 的 select 语句,则将控制权交给 Optimizer,也就是 Query 优化器模块,如果是 DML 或者是 DDL 语句,则会交给表变更管理模块,如果是一些更新统计信息、检测、修复和整理类的 query 则会交给表维护模块去处理,复制相关的query 则转交给复制模块去进行相应的处理,请求状态的 query 则转交给了状态收集报告模块。实际上表变更管理模块根据所对应的处理请求的不同,是分别由 insert 处理器、delete处理器、update 处理器、create 处理器,以及 alter 处理器这些小模块来负责不同的 DML和 DDL 的。
在各个模块收到 Query 解析与分发模块分发过来的请求后,首先会通过访问控制模块检查连接用户是否有访问目标表以及目标字段的权限,如果有,就会调用表管理模块请求相应的表,并获取对应的锁。表管理模块首先会查看该表是否已经存在于 table cache 中,如果已经打开则直接进行锁相关的处理,如果没有在 cache 中,则需要再打开表文件获取锁,然后将打开的表交给表变更管理模块。
当表变更管理模块“获取”打开的表之后,就会根据该表的相关 meta 信息,判断表的存储引擎类型和其他相关信息。根据表的存储引擎类型,提交请求给存储引擎接口模块,调用对应的存储引擎实现模块,进行相应处理。
不过,对于表变更管理模块来说,可见的仅是存储引擎接口模块所提供的一系列“标准”接口,底层存储引擎实现模块的具体实现,对于表变更管理模块来说是透明的。他只需要调用对应的接口,并指明表类型,接口模块会根据表类型调用正确的存储引擎来进行相应的处理。
当一条 query 或者一个 command 处理完成(成功或者失败)之后,控制权都会交还给连接线程模块。如果处理成功,则将处理结果(可能是一个 Result set,也可能是成功或者失败的标识)通过连接线程反馈给客户端。如果处理过程中发生错误,也会将相应的错误信息发送给客户端,然后连接线程模块会进行相应的清理工作,并继续等待后面的请求,重复上面提到的过程,或者完成客户端断开连接的请求。
当一条 query 或者一个 command 处理完成(成功或者失败)之后,控制权都会交还给连接线程模块。如果处理成功,则将处理结果(可能是一个 Result set,也可能是成功或者失败的标识)通过连接线程反馈给客户端。如果处理过程中发生错误,也会将相应的错误信息发送给客户端,然后连接线程模块会进行相应的清理工作,并继续等待后面的请求,重复上面提到的过程,或者完成客户端断开连接的请求。
schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"><!-- name:逻辑库的名字checkSQLschema:当该值设置为 true 时,如果我们执行语句**select * from TESTDB.travelrecord;**则 MyCat 会把语句修改为**select * from travelrecord;**。设置成false,要求应用程序端,SQL语句不要带数据库名,不然识别不了sqlMaxLimit:当用户没有写limit语句,给这个语句默认加上 limit 100,如果用户写了则不会加。--><schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100"><!--name:逻辑表表名dataNode:数据分片id,对应这下面的dataNode节点的name属性(执行的sql的数据被分成多片)--><table name="t_order" dataNode="dn01"/></schema><!--name:数据分片的名称,给table引用的dataHost:数据库实例的id,对应下面dataHost节点的name属性database:访问对应数据库实例里面的哪个数据库--><dataNode name="dn01" dataHost="dn01" database="ljh_test" /><!--name:数据库实例的名称,给我们dataNode标签进行引用maxCon:最大连接数minCon:最小连接数dbType:后端关联的数据库类型是什么类型(因为mycat支持多种数据,这里要标明白)dbDriver:表示是原生的MySQL,不是被定制、改装过的,是原版。balance:负载均衡策略balance="1",全部的readHost与stand by writeHost参与select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡writeType:writeType="0", 所有写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二个writeHost,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties .--><dataHost name="dn01" maxCon="1000" minCon="10" balance="1"writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><!-- 心跳机制 --><heartbeat>select user()</heartbeat><!-- 写节点的配置host:主机名url:连接的访问地址user:后端数据库的用户名password:后端数据库的用户密码--><writeHost host="192.168.209.150" url="192.168.209.150:3306" user="root"password="123456"><!-- 读节点配置 --><readHost host="192.168.209.152" url="192.168.209.152:3306" user="root" password="123456" /></writeHost><!-- 备用写节点 ,主的挂了之后,这个备用的就变成主了,能读能写 --><writeHost host="192.168.209.152" url="192.168.209.152:3316" user="root"password="123456" /></dataHost>
</mycat:schema>
相关文章:
04、MySQL-------MyCat实现分库分表
目录 九、MyCat实现分库分表1、分库分表介绍:横向(水平)拆分**垂直分表**:水平分表:**分库分表** 纵向(垂直)拆分分表字段选择 2、分库分表操作:1、分析图:2、克隆主从3、…...

开源软件-禅道Zentao
禅道Zentao 简介漏洞复现SQL注入漏洞**16.5****router.class.php SQL注入** **v18.0-v18.3****后台命令执行** 远程命令执行漏洞(RCE)后台命令执行 简介 是一款开源的项目管理软件,旨在帮助团队组织和管理他们的项目。Zentao提供了丰富的功能…...

Linux生产者消费者模型
生产者消费者模型 生产者消费者模型生产者消费者模型的概念生产者消费者模型的特点生产者消费者模型优点 基于BlockingQueue的生产者消费者模型基于阻塞队列的生产者消费者模型模拟实现基于阻塞队列的生产消费模型 生产者消费者模型 生产者消费者模型的概念 生产者消费者模式就…...
【Qt-20】Qt信号与槽
一、什么是信号和槽 信号是特定情况下被发射的事件,发射信号使用emit关键字,定义信号使用signals关键字,在signals前面不能使用public、private、protected等限定符,信号只用声明,不需也不能对其进行定义实现。另外&am…...
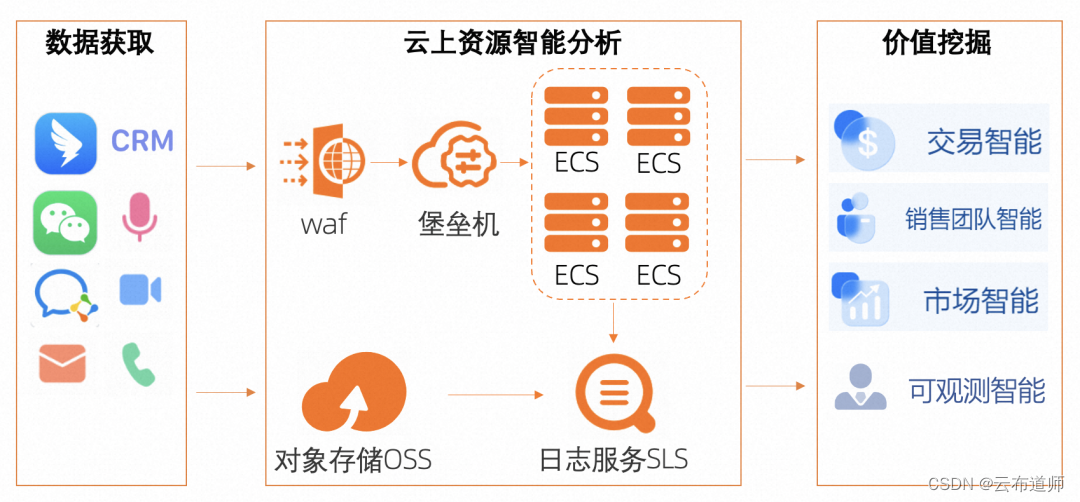
“智能+”时代,深维智信如何借助阿里云打造AI内容生成系统
云布道师 前言: 随着数字经济的发展,线上数字化远程销售模式越来越成为一种主流,销售流程也演变为线上视频会议、线下拜访等多种方式的结合。根据 Gartner 报告,到 2025 年 60% 的 B2B 销售组织将从基于经验和直觉的销售转变为数…...

selenium 自动化测试——WebDriver API
控制浏览器 控制浏览器窗口大小:set_window_size()方法 设置全屏模式下运行:maximize_window()方法 from selenium import webdriver from selenium.webdriver.common.by import By import timedriver webdriver.Chrome() driver.get("http://w…...

【实战】学习 Electron:构建跨平台桌面应用
文章目录 一、Electron 简介二、Electron 的优势1. 学习曲线平缓2. 丰富的生态系统3. 跨平台支持4. 开源和社区支持 三、Electron 的使用1. 安装 Node.js2. 安装 Electron3. 创建项目4. 初始化项目5. 安装依赖6. 创建主进程文件7. 创建渲染进程文件8. 打包应用程序9. 运行应用程…...

Python开发之二维数组空缺值的近邻填充
Python开发之二维数组空缺值的填充 1 实现一,任意位置填充2 实现二,填充内部3 实现三,只填充边缘,不包括四个角 前言:主要实现二维数据里面某一个数据的缺失,用缺失的近邻数据进行均值填充,可以…...
vue使用pdf 导出当前页面,(jspdf, html2canvas )
需要安装两个插件 npm install html2canvas jspdfyarn add html2canvas jspdf<div class"app-container" id"pdfPage"><!--这个放你需要导出的内容--> </div><el-button size"mini" click"onExportPdf">导出…...

【oracle删除表 回滚操作】
oracle数据回滚 oracle表在被误删后,一定时间内,可以采取以下方法进行恢复: 1、先查询数据库当前时间 select to_char(sysdate,‘yyyy-mm-dd hh24:mi:ss’) from dual;2、通过当前时间往前推时间,选择想要恢复的时间点 select * from 表名…...

Vue3 + TypeScript
Vue3 TS开发环境创建 1. 创建环境 vite除了支持基础阶段的纯TS环境之外,还支持 Vue TS开发环境的快速创建, 命令如下: $ npm create vitelatest vue-ts-pro -- --template vue-ts 说明: npm create vitelatest 基于最新版本的vite进行…...

软件测试/测试开发丨南科大计算机系本科生获“火焰杯”软件测试高校就业选拔赛一等奖
2022年12月2日,计算机系党总支书记、副系主任王琦副教授在工学院南楼551会议室为19级徐驰同学颁发第二届“火焰杯”软件测试开发选拔赛一等奖奖项,为刘烨庞助理教授颁发赛事优秀指导老师奖项。徐驰同学于2022年4月获得该赛事全国总决赛第一名,…...

访问 github 问题解决方法
一、macOS版 PS. Windows 版的还没试,不过应该也差不多 1.基本信息 硬件:MacBook Pro 2017 (A1707) 系统:macOS 13.6 (Ventura) 应用:SwitchHosts 4.1.2 (Releases oldj/SwitchHosts GitHub) hosts内容网站:ht…...

供应QCA8075原装芯片
长期供应各品牌原装芯片: SST39VF040-70-4I-NH AR9344 DC3A BGA USB2422 QFN24 W9751G6KB-251 RTL8211EG-VB-CG HI3535-RBCV100 MX25L25635FMI-10G USB2240I-AEZG EM620FV8BS-70LF HXI15H4G160AF-13K 1PQ8064/BGA-519 USB4604I-1080HN SCB15H2G160A…...

在Maven中配置代理服务器的详细教程
在Maven中配置代理服务器的详细教程如下: 首先,确保您已经安装了Maven。创建一个新的Maven项目。在命令行中输入以下命令: mvn archetype:generate -DgroupIdcom.example -DartifactIdmy-app -DarchetypeArtifactIdmaven-archetype-quickst…...

QStringListModel
创建模型: QStringListModel* model new QStringListModel(this); 初始化列表: QStringList strList;strList << QStringLiteral("北京") << QStringLiteral("上海") << QStringLiteral("天津") &l…...

Linux下的文件管理
一、Linux下文件命名规则 1、可以使用哪些字符? 理论上除了字符“/”之外,所有的字符都可以使用,但是要注意,在目录名或文件名中,不建议使用某些特殊字符,例如, <、>、?、* …...
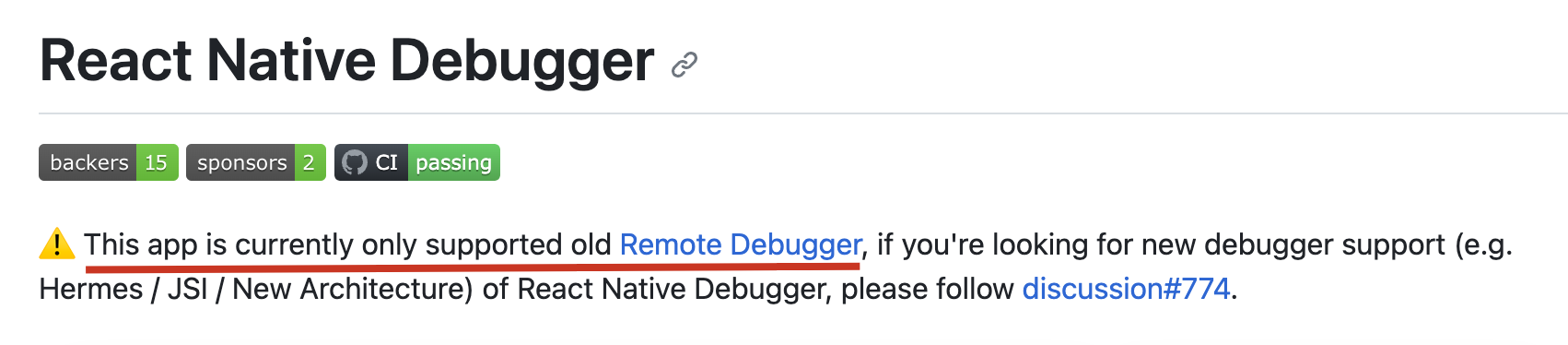
RN:报错info Opening flipper://null/React?device=React%20Native
背景 在 ios 上使用 debug 模式的时候,报错:info Opening flipper://null/React?deviceReact%20Native,我找到了这个 issue 其实也可以看到现在打开 debug,是 open debug,也不是之前的 debug for chrome 了…...
请问嵌入式或迁移学习要学什么?
请问嵌入式或迁移学习要学什么? 学习嵌入式和迁移学习是一个很好的方向,尤其是在军I领域。以下是一些你可以提前学习的基本 知识和步骤: 嵌入式系统:最近很多小伙伴找我,说想要一些嵌入式资料,然后我根据自己从业十年经验&#…...

数据结构-----图(Graph)论必知必会知识
目录 前言 图的基本概念 1.什么是图? 2 .图的相关术语 3 .有向图和无向图 4.简单图和多重图 5.连通图、强连通图、非连通图 6.权与网 7.子图和(强)连通分量 8.生成树和生成森林 前言 今天我们学习一种新的数据结构-----图,大家在日常生活中经常都…...

遗传算法原理与Python实现详解
1. 遗传算法基础概念解析遗传算法(Genetic Algorithm)是一种模拟自然选择过程的优化算法,它通过模拟生物进化中的选择、交叉和变异机制来寻找最优解。这种算法特别适合解决复杂的非线性问题,在机器学习、工程优化和金融建模等领域都有广泛应用。我第一次…...

深入解析自动化任务执行框架:从核心原理到生产实践
1. 项目概述:一个多功能的自动化任务执行框架最近在梳理手头的一些重复性工作流时,发现很多任务虽然逻辑简单,但步骤繁琐,涉及多个工具和平台的切换。比如,我需要定期从几个不同的数据源抓取信息,进行初步清…...

拼接最大数:你以为是贪心?其实是在“做选择的人生模拟”
🔥 拼接最大数:你以为是贪心?其实是在“做选择的人生模拟” 一、引子:很多人写对了代码,却没搞懂本质 这道题(Create Maximum Number),不少人第一次写的时候都会觉得: “这不就是贪心吗?每次选最大的数字就完了。” 然后一提交—— 要么WA(错误答案),要么超时…...

基于Python与GPT的自动化股票报告生成系统实践
1. 项目概述:从零构建一个AI驱动的自动化股票报告生成器最近在捣鼓一个挺有意思的小项目,我把它叫做“AI股票报告生成器”。核心想法很简单:能不能让程序自动去抓取我关心的股票数据,然后扔给类似ChatGPT这样的AI模型,…...

终极指南:如何让Intro.js用户引导完全符合WCAG无障碍标准
终极指南:如何让Intro.js用户引导完全符合WCAG无障碍标准 【免费下载链接】intro.js Lightweight, user-friendly onboarding tour library 项目地址: https://gitcode.com/gh_mirrors/in/intro.js 在当今数字化时代,网站和应用程序的无障碍性已成…...

2025终极AI提示词模型横评:GPT-5 vs Claude-4 Sonnet实战深度测评
2025终极AI提示词模型横评:GPT-5 vs Claude-4 Sonnet实战深度测评 【免费下载链接】v0-system-prompts-models-and-tools FULL Augment Code, Claude Code, Cluely, CodeBuddy, Comet, Cursor, Devin AI, Junie, Kiro, Leap.new, Lovable, Manus, NotionAI, Orchids…...

如何用GHelper轻松掌控华硕笔记本性能:5分钟快速配置终极指南
如何用GHelper轻松掌控华硕笔记本性能:5分钟快速配置终极指南 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, St…...

Kotlin 2.4.0-Beta2 发布,语法与多平台能力全线革新
前言 2026 年 4 月 22 日,JetBrains 发布 Kotlin 2.4.0-Beta2(EAP)。 相对 3 月底的 Beta1,这一版更像 “把 Beta1 画过的路线图往可 ship 状态再推一步”:语言里多了几条值得单独开编译开关试的能力,Nativ…...

Windows Cleaner:彻底告别C盘爆红的智能清理解决方案
Windows Cleaner:彻底告别C盘爆红的智能清理解决方案 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 还在为Windows系统C盘空间不足而烦恼吗ÿ…...

Telegram数据恢复避坑指南:为什么专业工具有时也救不了你的聊天记录?
Telegram数据恢复的深层解析:当技术遇上物理极限 "我的聊天记录还能找回来吗?"这个看似简单的问题背后,隐藏着从密码学到存储介质的复杂技术链条。当你在Telegram上按下"删除"的那一刻,实际上触发的是一系列精…...